Vision industrielle (4) - Application de vision industrielle
table des matières
Un, la reconnaissance faciale
La reconnaissance faciale doit déterminer la position, la taille et la posture du visage (s'il existe) dans l'image d'entrée et est souvent utilisée dans des applications telles que la reconnaissance biométrique, la surveillance vidéo et l'interaction homme-ordinateur. En 2001, Viola et Jones ont proposé un algorithme de détection d'objet classificateur en cascade basé sur les fonctionnalités de Haar, qui a été amélioré par Lienhart et Maydt en 2002, fournissant une méthode efficace pour des applications de détection de visage rapides et fiables. OpenCV a intégré l'implémentation open source de l'algorithme, en utilisant les fonctionnalités Haar d'un grand nombre d'échantillons pour la formation des classificateurs, puis en appelant la cascade de classificateurs en cascade formée pour la correspondance de modèles.
L'algorithme de reconnaissance faciale d'OpenCV convertit d'abord l'image acquise en niveaux de gris et effectue le traitement des contours et le filtrage du bruit; puis l'image est réduite, l'histogramme est égalisé et le classificateur correspondant est agrandi du même multiple jusqu'à ce qu'il corresponde au classificateur. Si la taille est plus grande que l'image détectée, le résultat correspondant sera renvoyé. Dans le processus d'appariement, l'appariement peut être effectué selon différents types dans le classificateur en cascade, tels que la face avant et la face latérale.
OpenCV a intégré l'algorithme de reconnaissance faciale, il suffit d'appeler l'interface correspondante d'OpenCV pour réaliser la fonction de reconnaissance faciale.
Réalisation du code source
1. Partie
initialisation La partie initialisation complète principalement le paramétrage des nœuds ROS, des images et des paramètres de reconnaissance.
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 获取haar特征的级联表的XML文件,文件路径在launch文件中传入
cascade_1 = rospy.get_param("~cascade_1", "")
cascade_2 = rospy.get_param("~cascade_2", "")
# 使用级联表初始化haar特征检测器
self.cascade_1 = cv2.CascadeClassifier(cascade_1)
self.cascade_2 = cv2.CascadeClassifier(cascade_2)
# 设置级联表的参数,优化人脸识别,可以在launch文件中重新配置
self.haar_scaleFactor = rospy.get_param("~haar_scaleFactor", 1.2)
self.haar_minNeighbors = rospy.get_param("~haar_minNeighbors", 2)
self.haar_minSize = rospy.get_param("~haar_minSize", 40)
self.haar_maxSize = rospy.get_param("~haar_maxSize", 60)
self.color = (50, 255, 50)
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
2. Fonction de rappel d'image ROS Après avoir
reçu les données d'image RVB libérées par la caméra, le nœud de routine entre dans la fonction de rappel, convertit l'image au format de données OpenCV, puis commence à appeler la fonction de reconnaissance faciale après le prétraitement, et publie enfin la reconnaissance résultat.
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
grey_image = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 创建平衡直方图,减少光线影响
grey_image = cv2.equalizeHist(grey_image)
# 尝试检测人脸
faces_result = self.detect_face(grey_image)
# 在opencv的窗口中框出所有人脸区域
if len(faces_result)>0:
for face in faces_result:
x, y, w, h = face
cv2.rectangle(cv_image, (x, y), (x+w, y+h), self.color, 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(cv_image, "bgr8"))
3.
Reconnaissance faciale La reconnaissance faciale appelle directement l'interface de reconnaissance faciale fournie par OpenCV pour faire correspondre les caractéristiques faciales de la base de données.
def detect_face(self, input_image):
# 首先匹配正面人脸的模型
if self.cascade_1:
faces = self.cascade_1.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
# 如果正面人脸匹配失败,那么就尝试匹配侧面人脸的模型
if len(faces) == 0 and self.cascade_2:
faces = self.cascade_2.detectMultiScale(input_image,
self.haar_scaleFactor,
self.haar_minNeighbors,
cv2.CASCADE_SCALE_IMAGE,
(self.haar_minSize, self.haar_maxSize))
return faces
Certains paramètres et noms de rubrique dans le code doivent être définis dans le fichier de lancement, vous devez donc également écrire un fichier de lancement pour exécuter la routine.
<launch>
<node pkg="test2" name="face_detector" type="face_detector.py" output="screen">
<remap from="input_rgb_image" to="/usb_cam/image_raw" />
<rosparam>
haar_scaleFactor: 1.2
haar_minNeighbors: 2
haar_minSize: 40
haar_maxSize: 60
</rosparam>
<param name="cascade_1" value="$(find robot_vision)/data/haar_detectors/haarcascade_frontalface_alt.xml" />
<param name="cascade_2" value="$(find robot_vision)/data/haar_detectors/haarcascade_profileface.xml" />
</node>
</launch>
2. Suivi d'objets
Le suivi et la reconnaissance d'objets présentent des similitudes et la même méthode de détection des points caractéristiques est utilisée, mais le focus est différent. L'objet pour la reconnaissance d'objet peut être statique ou dynamique, et le modèle établi sur la base des points caractéristiques de l'objet est utilisé comme base de données pour la reconnaissance; le suivi d'objet met l'accent sur le positionnement précis de la position de l'objet, et l'image d'entrée doit généralement ont des caractéristiques dynamiques.
La fonction de suivi d'objet échantillonne d'abord les points caractéristiques de l'objet dans l'image actuelle de l'image en fonction du flux d'image d'entrée et de l'objet sélectionné à suivre; puis compare la valeur de gris de l'image actuelle et de l'image suivante pour estimer les caractéristiques de l'objet suivi dans l'image actuelle La position du point dans l'image suivante de l'image; puis filtrez les points caractéristiques avec la même position, les points restants sont les points caractéristiques de l'objet de suivi dans le deuxième cadre de l'image, et le le cluster de points caractéristiques est l'emplacement de l'objet de suivi. Cette fonction est toujours basée sur l'algorithme de traitement d'image fourni par OpenCV.
Essayez de choisir un objet de test avec un arrière-plan de couleur unie et une grande différence de couleur. Déplacez l'objet reconnu dans l'écran, vous pouvez voir que le cadre rectangulaire identifie la position en temps réel de l'objet en mouvement, et la zone de reconnaissance, le seuil et d'autres paramètres peuvent être ajustés pour l'environnement expérimental.
Réalisation du code source
1. Partie
initialisation La partie initialisation complète principalement le paramétrage des nœuds ROS, des images et des paramètres de reconnaissance.
def __init__(self):
rospy.on_shutdown(self.cleanup);
# 创建cv_bridge
self.bridge = CvBridge()
self.image_pub = rospy.Publisher("cv_bridge_image", Image, queue_size=1)
# 设置参数:最小区域、阈值
self.minArea = rospy.get_param("~minArea", 500)
self.threshold = rospy.get_param("~threshold", 25)
self.firstFrame = None
self.text = "Unoccupied"
# 初始化订阅rgb格式图像数据的订阅者,此处图像topic的话题名可以在launch文件中重映射
self.image_sub = rospy.Subscriber("input_rgb_image", Image, self.image_callback, queue_size=1)
2. Une fois que le
nœud de routine de traitement d'image reçoit les données d'image RVB libérées par la caméra, il entre dans la fonction de rappel pour convertir l'image au format OpenCV; une fois le prétraitement d'image terminé, les deux cadres d'images sont comparés et l'objet en mouvement est identifié en fonction de la différence d'image, pour identifier les résultats de reconnaissance et les publier.
def image_callback(self, data):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
cv_image = self.bridge.imgmsg_to_cv2(data, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except CvBridgeError, e:
print e
# 创建灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (21, 21), 0)
# 使用两帧图像做比较,检测移动物体的区域
if self.firstFrame is None:
self.firstFrame = gray
return
frameDelta = cv2.absdiff(self.firstFrame, gray)
thresh = cv2.threshold(frameDelta, self.threshold, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.dilate(thresh, None, iterations=2)
binary, cnts, hierarchy= cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in cnts:
# 如果检测到的区域小于设置值,则忽略
if cv2.contourArea(c) < self.minArea:
continue
# 在输出画面上框出识别到的物体
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x + w, y + h), (50, 255, 50), 2)
self.text = "Occupied"
# 在输出画面上打当前状态和时间戳信息
cv2.putText(frame, "Status: {}".format(self.text), (10, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# 将识别后的图像转换成ROS消息并发布
self.image_pub.publish(self.bridge.cv2_to_imgmsg(frame, "bgr8"))
Certains paramètres et noms de rubrique dans le code doivent être définis dans le fichier de lancement, vous devez donc également écrire un fichier de lancement pour exécuter la routine.
<launch>
<node pkg="test2" name="motion_detector" type="motion_detector.py" output="screen">
<remap from="input_rgb_image" to="/usb_cam/image_raw" />
<rosparam>
minArea: 500
threshold: 25
</rosparam>
</node>
</launch>
Trois, reconnaissance de code QR
Les codes bidimensionnels sont de plus en plus utilisés dans les scènes de la vie. Qu'il s'agisse de faire du shopping dans les centres commerciaux ou de partager des vélos, les codes bidimensionnels ont été largement utilisés comme panneau d'entrée. ROS fournit une variété de packages de fonctions de reconnaissance de code QR - (ar_track_alvar)
1. Package de fonctions ar_track_alvar
L'installation du package de fonctions ar_track_alvar est très simple, utilisez simplement la commande suivante:
sudo apt-get install ros-kinetic-ar-track-alvar
Une fois l'installation terminée, recherchez le package de fonctions ar_track_alvar dans le répertoire d'installation par défaut de ROS. Ouvrez le dossier de lancement sous le package de fonctions, vous pouvez voir plusieurs fichiers de lancement. Ce sont les routines de reconnaissance de code QR utilisées par le robot PR2, qui peuvent être modifiées sur la base de ces fichiers, afin que votre vision industrielle ait la fonction de reconnaissance de code QR.
2. Créer un code QR Le
package de fonctions ar_track_alvar fournit la fonction de génération d'étiquettes de code QR. Vous pouvez utiliser les commandes suivantes pour créer des étiquettes de code QR avec les étiquettes correspondantes:
rosrun ar_track_alvar createMarker AR_ID
L'AR_ID peut être n'importe quel nombre compris entre 0 et 65535, par exemple:
rosrun ar_track_alvar createMarker 0
Vous pouvez créer une image d'étiquette de code QR avec une étiquette de 0, la nommer MarkerData_0.png et la placer sous le chemin actuel du terminal. Vous pouvez également utiliser directement la visionneuse d'images système pour ouvrir le fichier de code QR.
L'outil createMarker possède également de nombreux paramètres qui peuvent être configurés. Utilisez la commande suivante pour consulter l'aide.
rosrun ar_track_alvar createMarker
createMarker peut non seulement utiliser des étiquettes numériques pour générer des étiquettes de code QR, mais également utiliser des chaînes, des noms de fichiers, des URL, etc., et peut également utiliser le paramètre -s pour définir la taille du code QR généré.
Vous pouvez utiliser les commandes suivantes pour créer une série d'étiquettes de code QR:
roscd robot_vision/config
rosrun ar_track_alvar createMarker -s 5 0
rosrun ar_track_alvar createMarker -s 5 1
rosrun ar_track_alvar createMarker -s 5 2
3. Le
package de fonction de reconnaissance de la caméra QR code ar_track_alvar prend en charge la caméra USB ou la caméra RVB-D comme capteur visuel pour reconnaître le code QR, correspondant aux deux nœuds de reconnaissance différents de individualNoKinect et individualMarkers respectivement.
4. Kinect reconnaît les
codes bidimensionnels Les caméras RVB-D telles que Kinect peuvent également être utilisées pour reconnaître les codes bidimensionnels.
Quatrièmement, la reconnaissance d'objets
ROS intègre un puissant cadre de reconnaissance d'objets - Object Recognition Kitchen (ORK), qui contient une variété de méthodes de reconnaissance d'objets en trois dimensions.
1. Package de fonctions ORK
L'opération est effectuée sous Ubuntu 16.04 Puisque cette version de cinetic n'intègre pas tous les packages de fonctions ORK, les étapes suivantes sont nécessaires pour installer le code source.
Installez d'abord les bibliothèques dépendantes à l'aide de la commande suivante:
sudo apt-get install meshlab
sudo apt-get install libosmesa6-dev
sudo apt-get install python-pyside.qtcore
sudo apt-get install python-pyside.qtgui
Téléchargez le fichier rosinstall et compilez le
lien du fichier: https://github.com/wg-perception/object_recognition_core
Créez un nouvel espace de travail ork_ws, téléchargez le fichier ork.rosinstall.kinetic.plus directement sur ork_ws, puis procédez comme suit:
cd ork_ws
wstool init src [文件路径]/ork.rosinstall.kinetic.plus
Télécharger le code source de la fonction:
cd src
wstool update -j8
git clone https://github.com/jbohren/xdot.git
cd ..
rosdep install --from-paths src -i -y
Compiler:
cd ork_ws
catkin_make
Processus de reconnaissance d'objets:
(1) Créer un modèle d'objet qui doit être reconnu
(2) Former le modèle pour générer un modèle de reconnaissance
(3) Utiliser le modèle de reconnaissance formé pour la reconnaissance d'objets
2. Construire une bibliothèque de modèles d'objets
Créer une base de données
Installer CouchDB outils:
sudo apt-get install couchdb
Testez si l'installation a réussi:
curl -X GET http://localhost:5984
Créez un morceau de données de modèle Coke:
rosrun object_recognition_core object_add.py -n "coke " -d "A universal can of coke " --commit
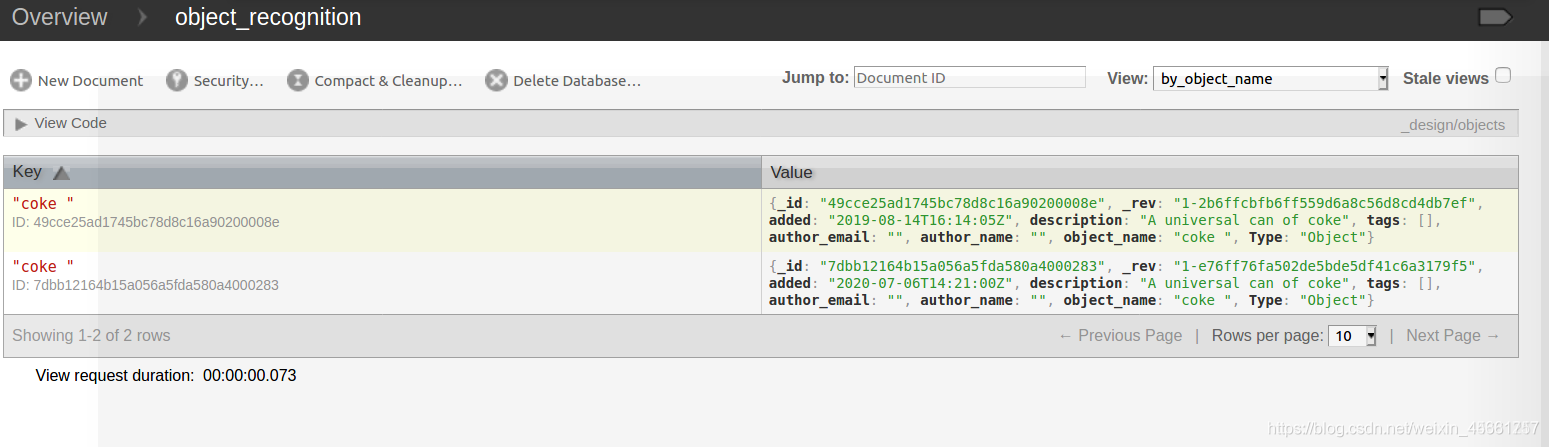
Chargez le modèle 3D
Téléchargez le modèle coke.stl existant et téléchargez-le via github:
git clone https://github.com/wg-perception/ork_tutorials
Téléchargez dans le fichier src,
puis chargez le modèle Coke dans la base de données:
rosrun object_recognition_core mesh_add.py 49cce25ad1745bc78d8c16a90200008e [path]/ork_tutorials/data/coke.stl --commit
Voir le modèle:
sudo pip install git+https://github.com/couchapp/couchapp.git
rosrun object_recognition_core push.sh
Cliquez sur object_listing:
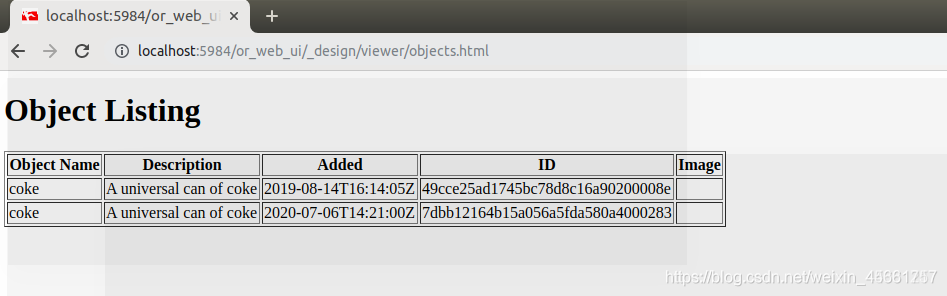
cliquez sur meshes:
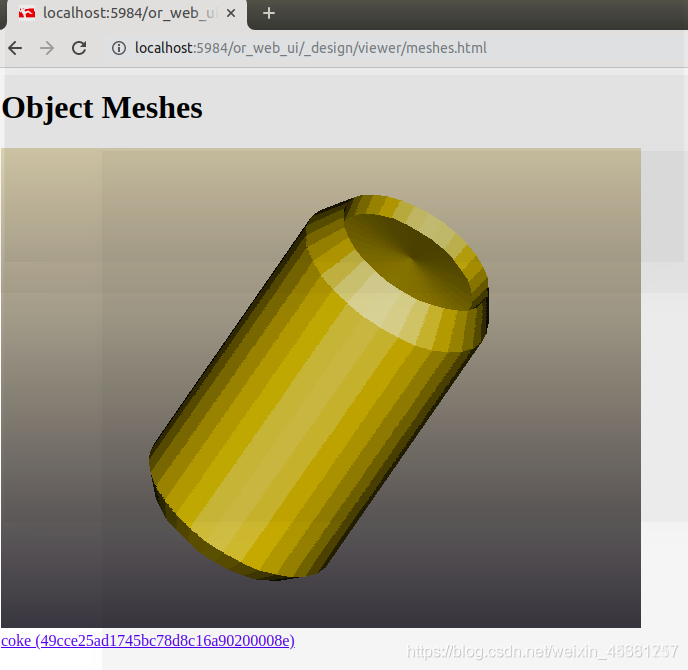
3. Formation des modèles
Il existe de nombreux modèles chargés dans la base de données, et nous devons nous entraîner pour générer des modèles correspondants.
La commande est la suivante:
sudo object_recognition_core training -c `rospack find object_recognition_linemod`/conf/training.ork
4. Reconnaissance d'objets en trois dimensions