Cet article n'est que ma compréhension, veuillez me corriger s'il y a des écarts et des erreurs
Régression: la régression est la première à proposer un modèle expérimental, mais les paramètres clés du modèle sont inconnus. Une grande quantité de données est utilisée pour trouver le modèle expérimental qui correspond le mieux aux données de test, c'est-à-dire pour trouver les paramètres clés de le modèle. Ensuite, utilisez un exemple de la conférence de Li Hongyi. Voyez précisément ce qu'est la régression
Ceci est un exemple très intéressant pour évaluer la capacité de combat (PC) de Pokémon après évolution
Il contient d'autres attributs, Xcp, Xs, Xhp, Xw, Xh, etc.

La première étape consiste à déterminer un modèle (modèle). Ici, un modèle linéaire est déterminé ![]() . On peut également exprimer que
. On peut également exprimer que ![]() b, w sont des paramètres et peuvent être des données quelconques, Xi est divers attributs de Pokemon, w peut être compris comme poids, et b peut être compris est l'écart.
b, w sont des paramètres et peuvent être des données quelconques, Xi est divers attributs de Pokemon, w peut être compris comme poids, et b peut être compris est l'écart.

La deuxième étape consiste à déterminer lesquelles de ces fonctions sont bonnes, en fait, il s'agit de déterminer b, w, d'abord collecter les données d'évolution de Pokemon,

Vous trouverez ci-dessous les 10 données collectées (se sentant si peu nombreuses), et leurs graphiques bidimensionnels de données avant et après l'évolution. Est-ce que cela ressemble à une chose à apprendre en théorie des probabilités? points autant que possible. Est proche, la méthode des moindres carrés est utilisée;

Utilisez la méthode des moindres carrés pour résoudre b, w; utilisez la fonction de perte L, en fait c'est l'erreur quadratique moyenne, la plus petite est la meilleure; la solution b, w est L
Le processus de minimisation est appelé l'estimation des paramètres de la méthode des moindres carrés du modèle de régression linéaire;

Chaque point de la figure représente une fonction du modèle, la couleur représente l'erreur quadratique moyenne, le bleu représente une bonne et le rouge représente une mauvaise

La troisième étape consiste à sélectionner la meilleure fonction, qui est la valeur minimale de L, qui utilise la dérivation différentielle. La méthode utilisée ici est la méthode de descente de gradient.
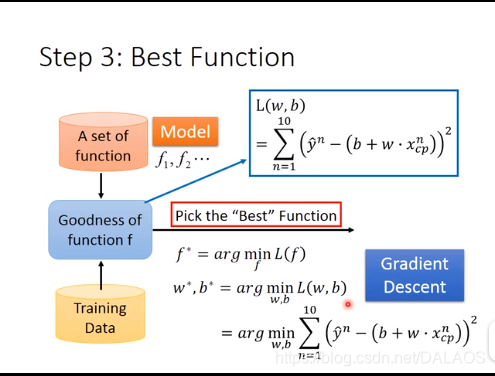
Descente de gradient: ici on calcule d'abord dans une dimension, il n'y a qu'une seule inconnue w
1. Sélectionnez au hasard un point initial
2. Calculez la dérivée.![]() S'il s'agit d'un nombre négatif, augmentez la valeur de w, s'il s'agit d'un nombre positif, diminuez w. En fait, cela détermine la direction du déclin.
S'il s'agit d'un nombre négatif, augmentez la valeur de w, s'il s'agit d'un nombre positif, diminuez w. En fait, cela détermine la direction du déclin. ![]() C'est ce qu'on appelle le taux d'apprentissage. ou diminue dépend de la dérivée et du taux d'apprentissage.
C'est ce qu'on appelle le taux d'apprentissage. ou diminue dépend de la dérivée et du taux d'apprentissage.
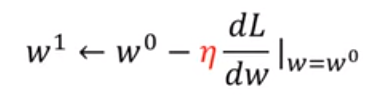 Alors obtenez le deuxième point
Alors obtenez le deuxième point
3. Répétez la deuxième étape pour trouver une optique locale,
En fait, tout le monde est très perplexe que seul l'optimal local puisse être trouvé de cette manière. En fait, il n'y a aucun optimal local dans ce modèle.

Sous deux paramètres: des dérivées partielles sont utilisées, et les autres sont fondamentalement identiques à un paramètre. Voyez-le par vous-même (haha).

Ceci est une illustration des étapes pour résoudre le problème


J'ai donc trouvé ce modèle: Calculez le taux d'erreur moyen  , c'est la somme de la distance verticale entre l'échantillon et la ligne droite; nous sommes plus préoccupés par le taux d'erreur moyen du test, le taux d'erreur moyen du test est légèrement supérieur au taux d'erreur moyen, alors nous devrions Comment faire mieux:
, c'est la somme de la distance verticale entre l'échantillon et la ligne droite; nous sommes plus préoccupés par le taux d'erreur moyen du test, le taux d'erreur moyen du test est légèrement supérieur au taux d'erreur moyen, alors nous devrions Comment faire mieux:


La première: en utilisant la forme quadratique, l'effet est évidemment meilleur que celui de la première fois, et il faut faire mieux, on utilise la troisième puissance, la quatrième puissance et la cinquième puissance:




Il n'est pas difficile de constater que les résultats de l'entraînement s'améliorent de plus en plus, mais les résultats des quatrième et cinquième tests se sont détériorés, et les résultats sont déraisonnables à la cinquième puissance, et des nombres négatifs apparaissent. En fait, il s'agit d'un surajustement .


Nous avons mentionné ci-dessus que nous collectons trop peu de données. Maintenant, nous collectons beaucoup de données: il n'est pas difficile de trouver que notre travail ci-dessus semble être vain. Ce n'est pas une simple relation linéaire. Nous pouvons également constater que leur distribution est également liés à leurs types. Il est lié, ce qui signifie que nous ne regardons qu'un seul de ses attributs (cp) ne suffit pas:

Nous avons une autre façon de traiter, en utilisant la structure linéaire suivante:


Selon 0 et 1, les équations suivantes sont utiles pour comprendre

Trouver le modèle suivant n'est pas difficile de trouver que l'effet est meilleur que celui ci-dessus, mais il y a encore des points au-dessus et en dessous de la ligne droite que nous devons considérer d'autres attributs:


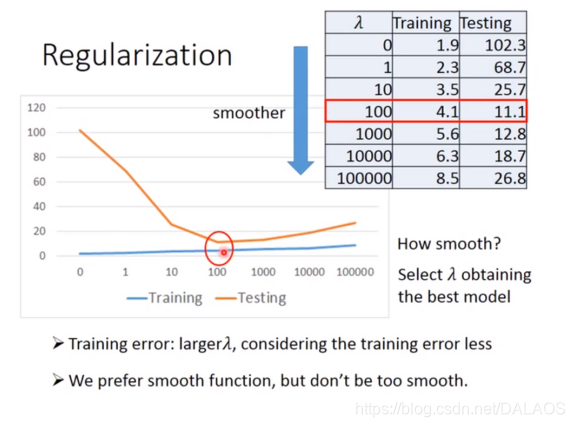
Nous pouvons remplir tous les attributs auxquels nous pensons, mais nous constatons que l'effet d'entraînement est bon et que l'effet de test est très faible. Nous utilisons une autre méthode pour ajuster:

Plus le wi est petit, mieux c'est, ce qui rend le résultat plus fluide, qui ![]() est un certain nombre.
est un certain nombre.

Voici le résultat du test: voyez si vous pouvez comprendre, je suis trop paresseux pour écrire

############## Laissez-moi vous montrer le code ########################
C'est le code ajouté plus tard
##李弘毅线性回归模型demo
#y_data = b + w*x_data
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np
x_data = [338.,333.,328.,207.,226.,25.,179.,60.,208.,606.]
y_data = [640.,633.,619.,393.,428.,27.,193.,66.,226.,1591.]
b = -120
w = -4
lr = 1##学习率//这个是添加lr_b,lr_w之后随意设置的
iteration = 100000###迭代次数
##求值过程之中b,w的保存用于画图
b_history = [b]
w_history = [w]
############添加lr_b,lr_w效果更好一些,这涉及到一个方法以后会写
lr_b = 0.0
lr_w = 0.0
############
for i in range(iteration):
##偏导
b_grad = 0.0;
w_grad = 0.0;
for n in range(len(x_data)):
b_grad = b_grad-2.0*(y_data[n]-b-w*x_data[n])*1.0
w_grad = w_grad-2.0*(y_data[n]-b-w*x_data[n])*x_data[n]
#################################
lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2
################################
##更新b,w的值 b0->b1 w0->w1
b = b - lr/(np.sqrt(lr_b))*b_grad
w = w - lr/(np.sqrt(lr_w))*w_grad
##将数据保存,用于画图
b_history.append(b)
w_history.append(w)
#################作图准备工作########################
x = np.arange(-200,-100,1)##bias
y = np.arange(-5,5,0.1)##weight
Z =np.zeros((len(x),len(y)))
X,Y = np.meshgrid(x,y)
for i in range(len(x)):
for j in range(len(y)):
b= x[i]
w = y[j]
Z[j][i] = 0
for n in range(len(x_data)):
Z[j][i] = Z[j][i] + (y_data[n] -b -w*x_data[n])**2
Z[j][i] = Z[j][i]/len(x_data)
###########################作图###########################
plt.contourf(x,y,Z,50,alpha=0.5,cmap=plt.get_cmap('jet'))
plt.plot([-188.4],[2.67],'x',ms=12,markeredgewidth=3,color='orange')
plt.plot(b_history,w_history,'o-',ms=3,lw=1.5,color='black')
plt.xlim(-200,-100)
plt.ylim(-5,5)
plt.xlabel(r'$b$',fontsize=16)
plt.ylabel(r'$w$',fontsize=16)
plt.show()
Image d'effet: