Introduction: Qu'est-ce que le DevOps natif du cloud? Nous pensons que le DevOps natif du cloud consiste à utiliser pleinement l'infrastructure native du cloud, basée sur des systèmes d'architecture microservices / sans service et des normes open source, indépendamment du langage et du cadre, avec une livraison continue et des capacités d'auto-fonctionnement et de maintenance intelligentes, Afin d'atteindre une qualité de service DevOps supérieure à celle du service DevOps traditionnel et des coûts de développement et d'exploitation inférieurs, la R&D se concentre sur une itération commerciale rapide.
1. Qu'est-ce que le DevOps natif du cloud?
Prenons d'abord un exemple simple pour comprendre ce qu'est le DevOps natif du cloud et en quoi il est différent du DevOps.

La photo ci-dessus est un étal de nourriture. Le chef sur la photo travaille très dur pour couper, faire frire, préparer divers types de nourriture et les vendre. De l'achat des matières premières à la transformation en passant par la vente et l'après-vente, une ou deux personnes le complètent. Il s'agit d'un scénario DevOps très typique où l'équipe gère tout de bout en bout. Dans ce cas, lorsque le chef a un niveau relativement élevé et une forte capacité de vente, une efficacité élevée et un faible gaspillage peuvent être obtenus. Mais le problème est qu'il sera difficile à mettre à l'échelle. Parce que ses processus ne sont pas standard, le chef doit avoir une forte capacité personnelle.

Regardons cette photo des stands de nourriture de Nanjing. Bien qu'il y ait des stands de nourriture dans le nom, ce ne sont évidemment pas les stands de nourriture que nous avons mentionnés ci-dessus. Lorsque nous entrons dans n'importe quel stand de nourriture de Nanjing, nous pouvons constater que les chefs de l'étal de nourriture de Nanjing peuvent se concentrer sur la fourniture de meilleurs plats aux clients, développer et tester de nouveaux plats, et essayer de les promouvoir auprès de petits groupes d'utilisateurs. Que le nombre d'utilisateurs augmente ou diminue, ils peuvent s'adapter rapidement. L'expansion de la boutique peut également être rapide. Nous pouvons comprendre cela comme un DevOps natif du cloud.
Alors, qu'est-ce que le DevOps natif du cloud? Nous pensons que le DevOps natif du cloud consiste à utiliser pleinement l'infrastructure native du cloud, basée sur des systèmes d'architecture microservices / sans service et des normes open source, indépendamment du langage et du cadre, avec une livraison continue et des capacités d'auto-fonctionnement et de maintenance intelligentes, Afin d'obtenir une qualité de service DevOps supérieure à celle des services DevOps traditionnels et des coûts de développement et d'exploitation inférieurs, la R&D se concentre sur une itération commerciale rapide .
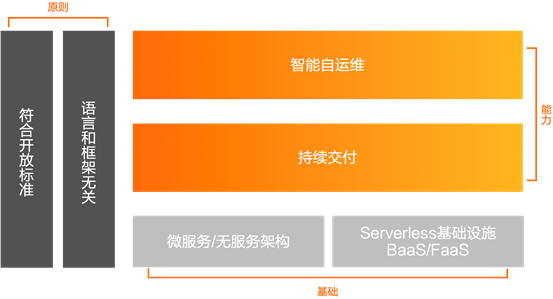
Comme le montre la figure ci-dessus, le DevOps cloud natif repose sur deux principes: la conformité aux standards ouverts, le langage et le framework n'ont rien à voir, il y a deux fondements: architecture microservice / no-service, infrastructure sans serveur BaaS / FaaS, offrant deux capacités : auto-fonctionnement et maintenance intelligents, livraison continue.
Conforme aux normes ouvertes, le langage et le cadre n'ont rien à voir avec lui. Par rapport à un langage ou un cadre spécifique, il peut avoir une plus grande flexibilité, un meilleur développement et une meilleure vitalité lors des mises à niveau ou des itérations technologiques, et former une meilleure écologie.
Deux fondements: Basé sur des microservices et une architecture sans service, le DevOps peut être rendu possible; L'infrastructure sans serveur est orientée ressources et orientée demande pour obtenir une meilleure flexibilité.
Sur la base de ces deux principes et de ces deux fondations, deux capacités sont atteintes: la livraison continue et l'auto-exploitation et la maintenance intelligentes.
2. Cas de mise à niveau DevOps natif du cloud Alibaba
Examinons d'abord un cas de transformation DevOps native du cloud d'une équipe Alibaba.
Contexte: une équipe de commerce électronique à l'étranger d'Ali fait face à de nombreux défis sur les marchés étrangers, tels que de nombreux sites, des coûts de construction de site élevés, des changements rapides de la demande, une livraison lente et des coûts d'exploitation et de maintenance élevés. Comment passer en douceur au cloud natif DevOps pour résoudre ces problèmes et améliorer l'efficacité de la livraison de l'entreprise Quoi? Ceci est ce que nous faisons.
(1) Sidecar et maillage de la gouvernance des services de mise à niveau de l'architecture

La première étape consiste à mettre à niveau l'architecture. Tout d'abord, le code de gouvernance de service est immergé dans la partie side-car à l'extérieur de l'application, et la grille de service est utilisée pour transporter des fonctionnalités telles que le routage environnemental. Comme le montre la figure ci-dessus, chaque point vert représente un code d'application de service et chaque point orange représente un code de gestion de service Ces codes sont stockés dans ce conteneur sous la forme d'un package à deux. Avec la construction du système de gouvernance des services, il contient beaucoup de choses, comme la collecte des journaux, le suivi des points d'enfouissement, les interventions d'exploitation et de maintenance, etc. On appelle ce type de conteneur riche en conteneurs. Le problème est évident: même s'il s'agit d'une mise à niveau ou d'un ajustement de la collecte de journaux, nous devons mettre à niveau, créer et déployer à nouveau l'application. Cependant, cela n'a rien à voir avec l'application elle-même. Dans le même temps, comme les préoccupations ne sont pas séparées, un bogue dans la collecte de journaux affectera l'application elle-même.

Afin de permettre à l'application de se concentrer davantage sur l'application elle-même, la première chose que nous avons faite a été de séparer tout le code de gouvernance de service du conteneur d'application et de le placer dans le sidecar, de sorte qu'il y ait deux codes de gouvernance de service et d'application. le conteneur. Dans le même temps, nous avons transféré certaines des tâches de gestion des services d'origine, telles que le routage de test et le suivi des liens, au side-car Mesh. De cette façon, l'application est mince et l'application n'a besoin de se soucier que du code de l'application lui-même.
L'avantage de ceci est que l'entreprise peut se concentrer sur le code d'application lié à l'entreprise sans s'appuyer sur la gouvernance des services.
C'est la première étape, et cette étape est fluide, car on peut progressivement migrer la gouvernance de service vers le side-car sans se soucier du coût excessif d'une migration.
(2) Mise à niveau de l'architecture - du découplage de la construction, du découplage des rejets au découplage de l'exploitation et de la maintenance Dans la
deuxième étape, nous avons effectué trois niveaux de découplage: le découplage de la construction, le découplage des rejets et le découplage de l'exploitation et de la maintenance.
Ceux qui comprennent les microservices et les architectures sans service doivent savoir que ce n'est que lorsqu'une entreprise peut être développée, testée, publiée et exploitée indépendamment qu'elle peut fonctionner plus vite et mieux. Parce que cela minimise le couplage avec d'autres personnes.
Mais nous savons aussi qu'au fur et à mesure que les services deviennent de plus en plus complexes et que les applications continuent d'évoluer, les applications contiendront de plus en plus de codes métier. Par exemple, dans l'application de la figure ci-dessous, certains codes sont destinés à une entreprise spécifique. Par exemple, en tant qu'application de paiement, certains sont destinés aux besoins spécifiques de Hema, d'autres aux besoins spécifiques de Tmall et certains sont codes généraux., Ou code de plate-forme, est pour tous les scénarios d'entreprise.

De toute évidence, du point de vue de l'amélioration de l'efficacité du développement, les parties commerciales peuvent modifier leurs codes commerciaux connexes pour réduire les coûts de communication et améliorer l'efficacité de la R&D. Mais cela entraîne un nouveau problème: si une certaine entreprise a besoin de changements, mais n'implique pas de logique métier générale, il est également nécessaire de revenir complètement à toutes les activités de l'application entière. S'il y a d'autres changements commerciaux pendant cette période, ils besoin d'intégrer et de publier ensemble. S'il y a de nombreux changements dans l'entreprise, tout le monde doit faire la queue pour l'intégration. Dans ce cas, le coût des tests d'intégration, de la communication et de la coordination est très élevé.
Notre objectif est que chaque entreprise puisse être développée, lancée et exploitée indépendamment. Afin d'atteindre cet objectif en douceur, la première chose à faire est de les découpler en phase de construction. Par exemple, pour une entreprise relativement indépendante, nous la construisons séparément en tant qu'image de conteneur et la plaçons dans le conteneur d'initialisation du pod via l'orchestration. Lorsque le pod démarre, il est ensuite monté sur l'espace de stockage du conteneur d'application principal.
Mais pour le moment, la version et l'exploitation et la maintenance de l'application sont toujours réunies, nous devons les séparer.
Nous savons que l'intimité des applications peut être à peu près divisée en trois catégories:
1. Ultra-intimité, qui communique via des appels de fonction dans le même processus.
2. Différents conteneurs situés dans le même Pod communiquent via IPC.
3. Dans le même réseau Grâce à la communication RPC,
nous pouvons progressivement diviser certains codes métier en services RPC ou IPC en fonction des caractéristiques de l'entreprise, afin qu'ils puissent être libérés et exploités indépendamment.
Jusqu'à présent, nous avons terminé le découplage de la construction, le découplage des rejets et le découplage de l'exploitation et de la maintenance du conteneur d'application.
(3) IAC et GitOps
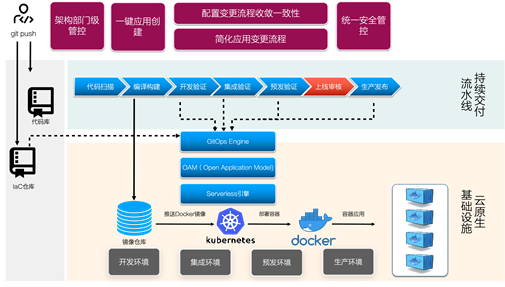
La troisième étape, nous examinons l'état du développement et de l'exploitation et de la maintenance. Dans de nombreux scénarios de R&D, un problème épineux est le suivant: différents environnements et entreprises auront beaucoup de leurs propres configurations uniques. Lors de la version, de l'exploitation et de la maintenance, il est souvent nécessaire de modifier et de sélectionner la configuration correcte en fonction de la situation et de cette configuration et le code de l'application. Il fait en fait partie de la version elle-même, et le coût de la maintenance traditionnelle via la console sera très élevé.
Dans le contexte du cloud natif, nous pensons que IaC (Infrastructure as Code) et GitOps sont de meilleurs choix. En plus d'une base de code pour chaque application, nous avons également un référentiel IaC. Ce référentiel contiendra la version image de l'application et toutes les informations de configuration associées. Lorsque des modifications de code doivent être publiées ou des modifications de configuration, elles sont toutes transmises à l'entrepôt IaC sous la forme de code push. Le moteur GitOps peut détecter automatiquement les modifications IaC et les traduire automatiquement en configurations conformes aux spécifications OAM, puis appliquer les modifications à l'environnement correspondant en fonction du modèle OAM. Qu'il s'agisse de développement ou d'exploitation et de maintenance, vous pouvez connaître les changements survenus dans le système via la version de code I aC, et chaque version est terminée.
(4) BaaSisation des ressources

La dernière étape est la BaaSisation des ressources.
Imaginons comment utiliser les ressources dans l'application. En général, nous nous rendons d'abord sur la console correspondante pour soumettre une application de ressources, décrivons les spécifications et exigences de ressources dont nous avons besoin, puis obtenons la chaîne de connexion et les informations d'authentification de la ressource après avoir passé l'approbation. Ajoutez la configuration des ressources à la configuration de l'application. En cas de modification ultérieure, accédez à la console correspondante pour la faire fonctionner et coopérez avec la version de code pour approbation. Bien entendu, l'exploitation, la maintenance et la surveillance de telles ressources sont généralement réalisées dans une console indépendante.
Lorsque nous avons de plus en plus de types de ressources, les coûts d'exploitation et de maintenance sont très élevés, notamment lors de la construction d'un nouveau site.
Partant du principe de la description des ressources de manière déclarative et de leur utilisation à la demande, nous simplifions l'utilisation des ressources par toutes les applications en définissant ces ressources dans IaC. Toutes les ressources sont décrites de manière déclarative, permettant une gestion intelligente et une utilisation à la demande des ressources. Dans le même temps, toutes nos ressources utilisent des ressources communes et des protocoles standard sur le cloud, ce qui réduit considérablement les coûts de migration. De cette manière, nous migrons progressivement l'équipe commerciale vers l'infrastructure native du cloud.
Par conséquent, les deux points clés de la BaaSization des ressources sont:
- Décrivez de manière déclarative les besoins en ressources, la gestion intelligente et l'utilisation à la demande
- Utilisez des ressources communes sur le cloud pour aligner les protocoles standard
3. L'efficacité du cloud stimule la mise en œuvre efficace des DevOps natifs du cloud
Ce que nous avons partagé ci-dessus est la pratique interne d'Ali, qui s'appuie sur la plate-forme de collaboration R&D interne d'Ali, Aone. La version cloud public d'Aone est l'effet cloud Aliyun. Comment pouvons-nous implémenter DevOps cloud natif via les effets cloud Alibaba Cloud?
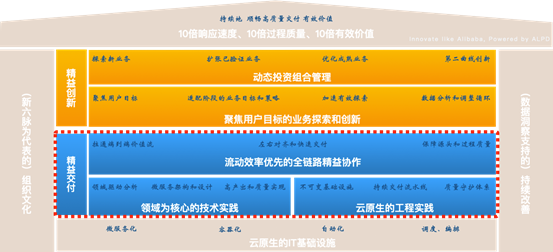
À partir des cas précédents, nous pouvons voir que la mise en œuvre de DevOps natif du cloud est un projet systématique, comprenant les méthodes, l'architecture, la collaboration et l'ingénierie. Parmi eux, la mise en œuvre de DevOps cloud natif appartient à la catégorie du lean delivery.

L'image ci-dessus est un diagramme de solution DevOps natif cloud avec effet cloud.
Ici, nous divisons les utilisateurs en 2 rôles:
- Chef technique ou architecte
- Ingénieurs, y compris le développement, les tests, l'exploitation et la maintenance, etc.
En tant que directeur technique ou architecte, il doit définir et contrôler le comportement R&D de l'entreprise dans son ensemble. D'un point de vue large, le processus de R&D comprend quatre aspects: exploitable, observable, gérable et modifiable.
Tout d'abord, il définira le modèle de collaboration R&D de l'entreprise, par exemple s'il faut adopter la R&D agile ou le lean Kanban. Deuxièmement, il doit maîtriser l'architecture globale du produit, par exemple quels produits cloud doivent être utilisés et comment ces produits cloud sont coordonnés et gérés. Ensuite, il décidera du modèle R&D de l'équipe: comment faire de la collaboration R&D, comment contrôler la qualité R&D, etc. Dans la troisième étape, il doit déterminer la stratégie de publication, s'il faut utiliser la version en niveaux de gris ou le déploiement bleu-vert, quelle est la stratégie en niveaux de gris, etc. Enfin, il s'agit de la stratégie de surveillance du service, comme les plates-formes de surveillance auxquelles le service doit accéder, comment détecter l'état du service, la configuration de surveillance globale, etc.
Les ingénieurs de développement, de test, d'exploitation et de maintenance de première ligne se concentrent sur des processus de travail fluides et efficaces. Une fois que la plateforme de collaboration de projet d'effet cloud a reçu une exigence ou une tâche, elle peut être codée, soumise, construite, intégrée, publiée et testée via l'effet cloud, et déployée dans l'environnement de pré-version et de production, ainsi que dans le mode et la version de R&D configuré par l'administrateur La stratégie a vraiment atterri. En même temps, chaque environnement est automatiquement déclenché et diffusé, sans coordination ni traction humaine.
Les données générées pendant tout le processus de R&D sont un tout organique, qui peut générer une grande quantité d'informations sur les données et conduire l'équipe à faire des améliorations continues. Lorsque l'équipe rencontre des goulots d'étranglement ou de la confusion dans le processus de R&D, elle peut également obtenir des conseils de diagnostic professionnels et des conseils en R&D de la part de l'équipe d'experts en efficacité du cloud.
En résumé, la solution DevOps cloud native de Cloud Efficacy est guidée par la méthodologie ALPD, basée sur les meilleures pratiques recommandées par des experts, et profondément intégrée dans la chaîne d'outils DevOps complète pour aider les entreprises à passer progressivement au cloud DevOps natif.
Ensuite, nous examinons un cas spécifique.
Une société Internet dispose d'une équipe de recherche et développement d'une trentaine de personnes et pas de personnel d'exploitation et de maintenance à plein temps.Ses produits comprennent plus de 20 microservices et des dizaines d'applications frontales (web, applets, applications, etc.). Son activité se développe très rapidement. Face à une clientèle en croissance rapide et à une demande croissante, la méthode de déploiement basée sur des scripts basée sur Jenkins + ECS a progressivement échoué à répondre aux demandes, en particulier au problème du déploiement et de la mise à niveau sans temps d'arrêt. En conséquence, j'ai commencé à avoir besoin de l'aide de l'efficacité du cloud et j'ai finalement entièrement migré vers le cloud DevOps natif.
Cette équipe R&D est confrontée à trois problèmes majeurs:
- Un grand nombre de clients et de nombreux besoins urgents
- Pas d'exploitation et de maintenance à plein temps, la technologie native cloud telle que K8S a un seuil d'apprentissage élevé
- Infrastructure informatique complexe, version longue et laborieuse
En réponse à ces problèmes, l'efficacité du cloud repose sur trois aspects: les capacités de base, les capacités de publication et les capacités d'exploitation et de maintenance.
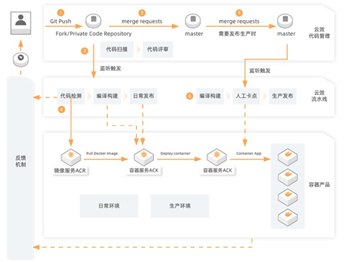
Tout d'abord, introduisez Alibaba Cloud ACK pour mettre à niveau l'infrastructure en plus des ressources ECS existantes et transformer l'application en conteneurisation. En termes de gouvernance de service et d'architecture d'application, le bucket de la famille Spring Cloud est simplifié en SpringBoot, et la découverte et la gouvernance des services sont prises en charge via les fonctionnalités standard K8S.
Deuxièmement, le déploiement automatique des conteneurs est réalisé via le pipeline d'effet cloud, et la stratégie de déploiement en niveaux de gris peut être utilisée pour obtenir une extension en ligne en échelle de gris, une extension automatique et un redémarrage automatique en cas de panne. sur le pipeline d'efficacité du cloud, il peut atteindre zéro temps d'arrêt et réduire rapidement tous les coûts, ce qui permet d'économiser les coûts de la machine. Dans le même temps, le problème de l'absence de personnel d'exploitation et de maintenance à plein temps dans l'entreprise est résolu.
Troisièmement, grâce à la ligne d'assemblage automatisée et au modèle standard de recherche et de développement de protection des succursales, y compris la révision du code, l'inspection du code, les points de carte de test, etc., pour améliorer l'efficacité des commentaires et la qualité des versions.
La figure ci-dessous est le schéma d'architecture de la solution globale.
4. Chemin de mise à niveau de DevOps Cloud native
Nous divisons la mise en œuvre de DevOps cloud natif en 5 étapes.

La première étape: toute la livraison manuelle et l'exploitation et la maintenance. Il s'agit de notre première étape. L'architecture de l'application n'a pas encore subi de transformation de service, elle n'a pas non plus utilisé d'infrastructure cloud ou uniquement IaaS. Il n'y a pas d'intégration continue, d'automatisation des tests, de déploiement manuel, de version et d'exploitation et de maintenance manuelles. Je pense que peu d'entreprises restent à ce stade.
La deuxième étape: la livraison, l'exploitation et la maintenance à l'aide d'outils. La première chose à faire est de servir l'architecture de l'application et d'utiliser l'architecture de microservice pour améliorer la qualité du service; deuxièmement, d'introduire des outils de recherche et développement, tels que gitlab, jenkins et d'autres outils de style insulaire pour résoudre certains problèmes. Dans le même temps, nous avons commencé à implémenter l'intégration continue de modules uniques, mais en général, il n'y a pas de point de blocage de la qualité automatisé, et la publication est souvent assistée par des outils automatisés.
La troisième étape: une livraison continue limitée et un fonctionnement et une maintenance automatisés. Nous avons encore amélioré nos capacités de base et transformé notre infrastructure en conteneurs basés sur CaaS. D'autre part, il a commencé à introduire une chaîne d'outils complète pour ouvrir les données de recherche et développement, comme l'utilisation d'une plate-forme d'outils telle que DevOps à effet cloud pour réaliser une intercommunication complète de toutes les données. Un déploiement continu peut être réalisé en termes de capacités de lancement, mais une certaine intervention manuelle est nécessaire. À l'heure actuelle, les tests automatisés sont devenus courants, le service dans son ensemble peut être observé, et l'exploitation et la maintenance peuvent être orientées service et déclaratives.
La quatrième étape: la livraison continue et l'auto-fonctionnement et la maintenance assistés manuellement. Nous avons en outre laissé nos étudiants en développement se concentrer sur le développement commercial. Premièrement, nous avons commencé à adopter un grand nombre d'architectures sans service dans l'architecture de l'application, et avons réalisé un déploiement continu sans surveillance; l'échelle de gris et la restauration des versions peuvent être automatisées autant que possible avec une intervention. La capacité d'observation est mise à niveau du niveau de l'application au niveau de l'entreprise, réalisant l'observabilité de l'entreprise et pouvant faire une partie de l'auto-opération et de la maintenance avec une assistance manuelle.
La cinquième étape: la livraison continue à travers la liaison et l'auto-exploitation et la maintenance. C'est le but ultime que nous recherchons. À ce stade, toutes nos applications et notre infrastructure adoptent une architecture sans service et permettent une livraison continue sans assistance de bout en bout, y compris la restauration des versions et les niveaux de gris sont également automatisés; les installations et services techniques sont entièrement autonomes et maintenus. Les développeurs n'ont vraiment besoin de se soucier que du développement commercial et de l'itération.
Cependant, le diable est dans les détails. Bien sûr, il reste encore beaucoup de problèmes à résoudre lorsque nous atterrissons vraiment. Avec l'aide d'une plateforme d'outils comme Cloud Effect et la consultation d'experts d'ALPD, nous pouvons éviter les détours et réaliser nos objectifs plus rapidement.
Auteur: petite attaque Cloud Raiders
Cet article est le contenu original d'Alibaba Cloud et ne peut être reproduit sans autorisation