Analyse probabiliste et statistique de la variance
1. Qu'est-ce que l'analyse de la variance
Un indicateur a plusieurs facteurs d'influence possibles et chaque facteur a plusieurs niveaux (niveau de catégorie, valeur discontinue). Lorsque le niveau du facteur de test a un impact sur l'indicateur, on parle d'analyse de variance. Ici, si le niveau du facteur est une valeur continue, il peut s'agir d'une analyse de régression.
- Résumé: L'indicateur est une variable continue et le type de changement du facteur influant est une variable catégorielle. La méthode permettant de vérifier si différents niveaux de facteurs ont un impact significatif sur l'indicateur s'appelle l'analyse de la variance.
Notez que la méthode d'analyse de la variance fait l'hypothèse de l'existence d'une différence entre la variance au sein du groupe de test et la variance entre les groupes. La méthode a une hypothèse nulle et des statistiques de test.
L'analyse de la variance peut être divisée comme suit:

analyse de la covariance
L'analyse de covariance prend des facteurs de contrôle difficiles à contrôler par l'homme comme covariables, et analyse l'effet des variables de contrôle (contrôlables) sur les variables d'observation sous la condition d'exclure l'influence des covariables sur les variables d'observation, afin de réaliser plus précisément les facteurs de contrôle Évaluation.
L'hypothèse nulle dans l'analyse de variance est la suivante: l'effet linéaire de la covariable sur la variable observée n'est pas significatif; sous la condition de déduire l'effet de la covariable, il n'y a pas de différence significative dans la moyenne globale de la variable observée à chaque niveau de la variable de contrôle. Les effets des variables sont nuls en même temps. Les statistiques de test utilisent toujours les statistiques F, qui sont le rapport de chaque carré moyen et le carré moyen causé par des facteurs aléatoires.
2 Méthode d'inspection
2.1 Principes de base
- Hypothèses de base de l'analyse de la variance:
-
Chaque population doit se conformer à une distribution normale;
-
La variance σ2 de chaque population doit être la même;
-
L'observation est indépendante.
La distribution des indicateurs à chaque niveau est une distribution normale. C'est une bonne compréhension. La distribution des quantités affectées par de nombreux facteurs est généralement une distribution normale. L'observation est indépendante et la compréhension personnelle est que chaque échantillon ne s'influencera pas. Alors pourquoi la variance doit-elle être la même?
En effet, la distribution statistique que nous utilisons est la distribution F, le numérateur et le dénominateur sont tous chi-carré et la variance de la distribution chi-carré est de 2n.
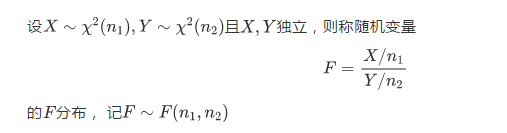
Cela nous indique qu'avant l'analyse de la variance, nous devons d'abord effectuer une variance homogène Test de sexe.
Peut-être que certains amis sont sur le point de demander, enseignant, enseignant, si je compare la variance et constate que la variance de chaque niveau est très différente, que dois-je faire?
- Enseignant: Je dois demander. Regardez ces mots: L'essence de l'analyse de la variance est de tester si les valeurs moyennes de plusieurs niveaux sont significativement différentes. Si la variance des valeurs d'observation à chaque niveau est trop différente, seule la différence entre les valeurs moyennes ne sera pas testée. Sens
- Étudiant: Combien de mots appelez-vous cette chose?
Oui, effectuer le test d'homogénéité de la variance, c'est renforcer notre confiance dans les résultats.Si ce n'est pas fait, en fait, c'est aussi possible, mais après avoir soumis le rapport, ce sera plus imaginaire. Mon résultat est-il fiable? Est-il convaincant? Le patron l'acceptera-t-il? Sera-t-il expulsé? Pourquoi la fleur est-elle rouge? Y a-t-il une fin des temps ...
- L'hypothèse nulle et l'hypothèse alternative d'analyse de la variance:
Supposons que les facteurs aient k niveaux et que la valeur moyenne de chaque niveau soit μ1, μ2, ..., μk, vérifiez si les valeurs moyennes sont égales,
H0: μ1 = μ2 = ⋯ = μk
H1: μ1, μ2, ..., μk ne sont pas tous égaux
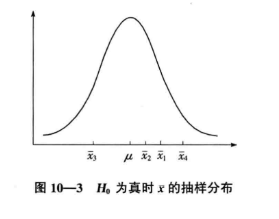
Selon les hypothèses de base, si l'hypothèse nulle est vraie, la distribution d'échantillonnage de 4 moyennes d'échantillon tirées de 4 populations doit être comme indiqué dans la figure:
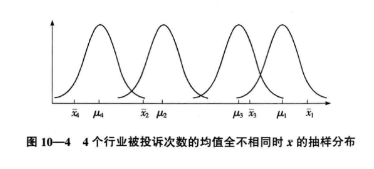
Si l'hypothèse nulle n'est pas vraie, la distribution d'échantillonnage de 4 moyennes d'échantillon est:
2.2 Statistiques de test
La statistique de test est construite en décomposant la variance globale ST en la variance inter-groupe SA, la variance intra-groupe SE, et parfois une variance supplémentaire de l'effet d'interaction, puis en divisant l'erreur quadratique moyenne MSA et l'erreur quadratique moyenne intra-groupe MSE pour obtenir Les statistiques du test F.
- Étudiant: Vraiment ou faux, si simple?
- Enseignant: Oui, c'est aussi simple que cela. Si vous ne me croyez pas, voyez ci-dessous.









- Étudiant: Vous êtes le premier enseignant à m'avoir enseigné l'analyse de la variance, ainsi que le théorème de décomposition de Hullen, professeur ss. Merci.
- L'étudiant est décédé au cours des dix-huit et soixante derniers mois.
2.3 Tableau d'analyse des variances
Il n'y a pas de règles ni de rayon. Lors de l'analyse de la variance, vous devez répertorier le tableau suivant, ce qui est une pratique relativement courante.
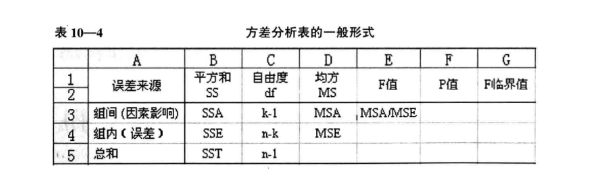
Les éléments de base comprennent la colonne des sources de variance, écrire les noms: facteur A, facteur B, facteur C ... Somme des carrés SSA, SSB, SSC ..., erreur SSE, degrés de liberté, carré moyen MSA, MSB, MSE, statistiques de test MSA / MSE, MSB / MSE. Le reste peut ajouter une valeur critique et une valeur p.
Exemple d'analyse du tableau de variance 2:
| projet | SS SS S S | Degré de liberté | MS MS M S | FF Rapport F | Importance |
|---|---|---|---|---|---|
| AA UNE | SSA SS_A S SA | k - 1 k-1 k-1 | MSA MS_A M SA | MSA / MS et MS_A / MS_e M SA/ M Se | *, ** ou aucun |
| BB B | SSB SS_B S SB | l - 1 l-1 l-1 | MSB MS_B M SB | MSB / MS et MS_B / MS_e M SB/ M Se | |
| Erreur | SS et SS_e S Se | (k - 1) (l - 1) (k - 1) (l - 1) ( k-1 ) ( l-1 ) | MS et MS_e M Se | ||
| somme | SS SS S S | kl - 1 kl-1 k l-1 |
- Enseignant: L'avez-vous appris?
- Étudiant: Wow, il y a des modèles! Maman n'a plus à se soucier de mon analyse de la variance.
- prof:. . .
3. implémentation de python
3.1 Statsmodels Analyse de la variance
L'analyse de variance Python peut utiliser le package de fonctions stats.anova dans statsmodels
import pandas as pd
import numpy as np
from statsmodels.formula.api import ols
from statsmodels.graphics.api import interaction_plot, abline_plot
from statsmodels.stats.anova import anova_lm
#先构造数据集,这里我们构造一个两个因素的数据,为双因素组内方差分析
data = pd.DataFrame([[1, 1, 32],
[1, 2, 35],
[1, 3, 35.5],
[1, 4, 38.5],
[2, 1, 33.5],
[2, 2, 36.5],
[2, 3, 38],
[2, 4, 39.5],
[3, 1, 36],
[3, 2, 37.5],
[3, 3, 39.5],
[3, 4, 43]],
columns=['A', 'B', 'value'])
model = ols('value~C(A) + C(B)', data=data[['A', 'B', 'value']]).fit()
anovat = anova_lm(model)
print(model.summary())
print(anovat)
Résultats de l'analyse de la variance:

voici le problème du trop petit volume de données.
Voici un aperçu des résultats d'ajustement du modèle des moindres carrés ols:

vous pouvez voir que les résultats des statsmodels sont toujours très professionnels et beaux.
Analyser l'effet d'interaction: On
peut voir que les principaux effets de A et B ci-dessus ont une forte influence, et les deux ont une influence significative (la valeur P est inférieure à 0,01).
Ensuite, ajoutez l'effet d'interaction et voyez le résultat de l'effet d'interaction.
model2 = ols('value~C(A) + C(B)+C(A):C(B)', data=data[['A', 'B', 'value']]).fit()
anova2=anova_lm(model2)
print(anova2)
#交互效应影响看不出来,不知怎么回事,F值都变为0了。

- Étudiant: Pourquoi F = 0?
- Enseignant: Lors de l'analyse de l'effet d'interaction, les exigences en matière de données sont différentes de ne pas tenir compte de l'effet d'interaction. Dans ces données, il n'y a qu'un seul xij pour les données aux niveaux Ai et Bj. Lors de l'examen de l'effet d'interaction, xij a besoin de plusieurs ensembles de données, sinon le calcul SSA * B aura des problèmes. Voici juste un exemple d'utilisation de fonction, l'effet d'interaction est représenté par A: B.
- Étudiant: Je comprends vraiment cette fois!
3.2 Ajustement de la fonction statsmodels
import matplotlib.pyplot as plt
import statsmodels.api as sm
x=np.linspace(0,10,30)
x2=np.square(x)
y=3*x*x+3*x+np.random.normal(0,1,(30,))
df=pd.DataFrame({
'y':y,'x1':x})
df['x2']=x2
model_new=ols('y~x1+x2',data=df).fit()
y_pred = model_new.predict(df['x1'])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(x, y, c='b')
ax.plot(x, y_pred, c='r')
plt.show()
print(model_new.summary())


L'effet de montage est excellent.
- Description du résultat de l'évaluation

- Blogger: Le mot de code n'est pas facile, demandez un like, pas trop.
- Touristes: certainement la prochaine fois, la prochaine fois
référence
1. Analyse de la variance
2. Comment comprendre et utiliser l'analyse de la variance?