1. Introduction
Transformer améliore les lacunes de la formation la plus critiquée de RNN, qui utilise le mécanisme d'auto-attention pour obtenir un parallélisme rapide. Et Transformer peut être augmenté à une profondeur très profonde, explorer pleinement les caractéristiques du modèle DNN et améliorer la précision du modèle. Un facteur clé du succès de BERT est le rôle puissant de Transformer.
Transformer a été proposé par le document "Attention, c'est tout ce dont vous avez besoin" et est maintenant le modèle de référence recommandé par Google Cloud TPU.
L'attention est tout ce dont vous avez besoin: https: //arxiv.org/abs/1706.03762
2. Partir d'une perspective macro
Considérez d'abord ce modèle comme une opération de boîte noire. En traduction automatique, il s'agit de saisir une langue et de sortir une autre langue.

Ensuite, ouvrez cette boîte noire, nous pouvons voir qu'elle est composée de composants d'encodage, de composants de décodage et des connexions entre eux.

La partie composant l'encodage se compose d'un tas d' encodeurs (dans le papier, 6 encodeurs sont empilés ensemble - le nombre 6 n'a rien de magique, vous pouvez également essayer d'autres nombres). La partie composante de décodage est également composée du même nombre de décodeurs ( correspondant aux codeurs ).

Tous les encodeurs sont de structure identique , mais ils ne partagent aucun paramètre .
Chaque décodeur peut être décomposé en deux sous-couches.
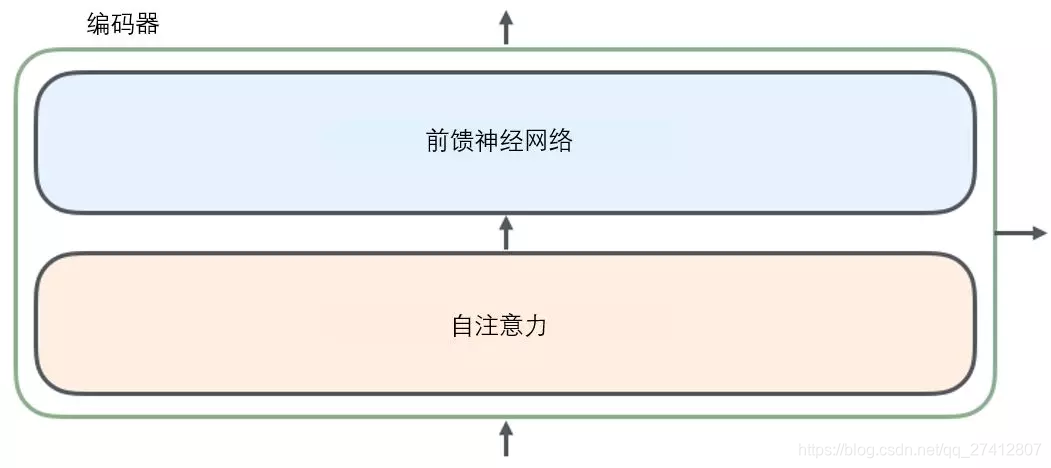
Les phrases entrées par l' encodeur passeront d' abord par une couche d'auto-attention (auto-attention) , qui aide l'encodeur à se concentrer sur les autres mots de la phrase d'entrée lors de l'encodage de chaque mot. Nous étudierons l'auto-attention plus en profondeur dans un article ultérieur.
La sortie de la couche d'attention est transmise au réseau neuronal à action directe . Le réseau de neurones à action directe correspondant au mot à chaque position est exactement le même (annotation: une autre interprétation est un réseau de neurones à convolution unidimensionnel avec une fenêtre d'un mot).
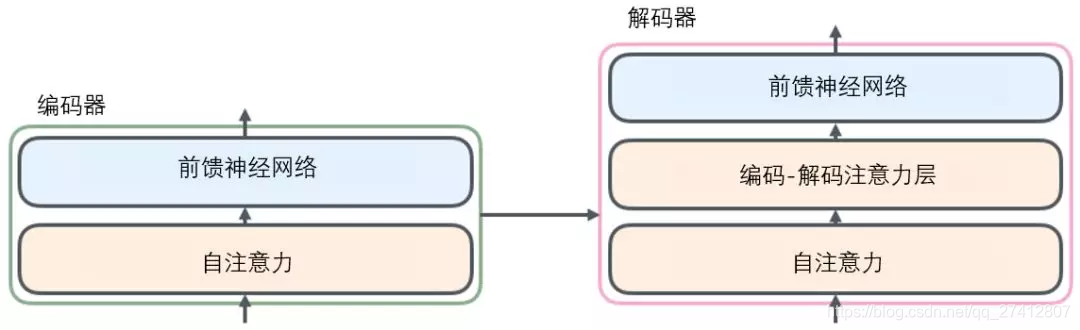
Le décodeur possède également les couches d' auto-attention et de rétroaction de l'encodeur . En outre, il existe une couche d'attention entre ces deux couches, qui est utilisée pour se concentrer sur les parties pertinentes de la phrase d'entrée (similaire à la fonction d'attention du modèle seq2seq).
3. Introduisez le tenseur dans l'image
Maintenant que nous avons compris l'essentiel du modèle, regardons différents vecteurs ou tenseurs. Comment convertir une entrée en sortie dans différentes parties du modèle.
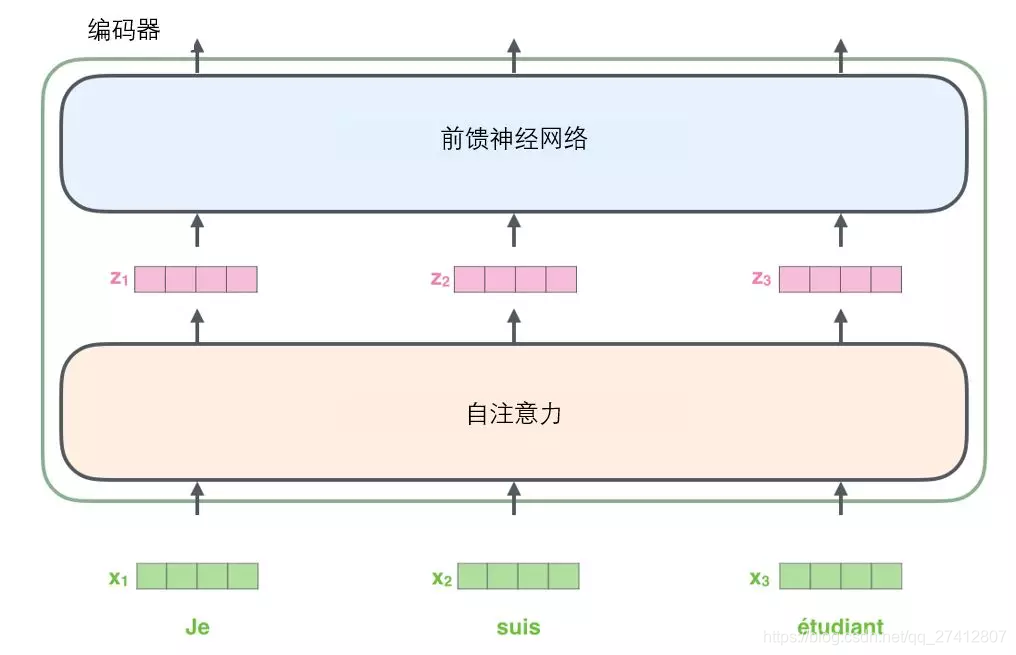
Comme la plupart des applications PNL, nous convertissons d'abord chaque mot d'entrée en un vecteur de mots via un algorithme d'intégration de mots .

Chaque mot est intégré comme un vecteur à 512 dimensions . Nous utilisons ces simples boîtes pour représenter ces vecteurs.
Le processus d'intégration de mots se produit uniquement dans l'encodeur le plus bas .
Tous les encodeurs ont la même fonctionnalité, c'est-à-dire qu'ils reçoivent une liste de vecteurs, et chaque vecteur de la liste a une taille de 512 dimensions. Dans l'encodeur inférieur (initial), c'est le vecteur de mots, mais dans d'autres encodeurs, c'est la sortie de l'encodeur dans la couche suivante (également une liste de vecteurs). La taille de la liste des vecteurs est un hyperparamètre que nous pouvons définir, généralement la longueur de la phrase la plus longue de notre ensemble d'entraînement.
Une fois que le mot a incorporé la séquence d'entrée, chaque mot passe par deux sous-couches dans l'encodeur.
Ensuite, jetons un coup d'œil à une caractéristique principale de Transformer, où les mots à chaque position de la séquence d'entrée ont leur propre chemin unique dans l'encodeur. ** Dans la couche d'auto-attention, il existe une relation de dépendance entre ces chemins. La couche feed-forward n'a pas ces dépendances. ** Par conséquent, différents chemins peuvent être exécutés en parallèle au niveau de la couche de rétroaction.
Ensuite, nous prendrons une phrase plus courte comme exemple pour voir ce qui se passe dans chaque sous-couche de l'encodeur.
4. Maintenant, nous commençons à "coder"
Comme déjà mentionné ci-dessus, un codeur reçoit la liste de vecteurs en entrée , puis transmet les vecteurs de la liste de vecteurs à la couche d'auto-attention pour traitement, puis la transmet à la couche de réseau neuronal à action directe, transmettant le résultat de sortie au codage suivant器 中.

Chaque mot de la séquence d'entrée subit un processus d'auto-encodage . Ensuite, ils passent chacun par le réseau de neurones à propagation directe - exactement le même réseau , et chaque vecteur le traverse séparément.
5. Voir le mécanisme d'auto-attention d'un point de vue macro
Ne soyez pas dérouté par le mot attention personnelle, il semble que tout le monde devrait être familier avec ce concept. En fait, je n'ai pas vu ce concept avant d'avoir lu Attention, c'est tout ce dont vous avez besoin. Affinons son fonctionnement.
Par exemple, la phrase suivante est la phrase d'entrée que nous voulons traduire:
L' animal n'a pas traversé la rue parce qu'il était trop fatigué
Que signifie ce «ça» dans cette phrase? Fait-il référence à la rue ou à l'animal? C'est un problème simple pour les humains, mais pas pour les algorithmes.
Lorsque le modèle traite le mot "il", le mécanisme d'auto-attention permettra à "il" d'établir une connexion avec "animal" .
Au fur et à mesure que le modèle traite chaque mot de la séquence d'entrée, l'auto-attention se concentrera sur tous les mots de la séquence d'entrée entière, ce qui aidera le modèle à mieux coder le mot.
Si vous connaissez le RNN (Recurrent Neural Network), rappelez-vous comment il maintient la couche cachée. RNN combinera la représentation de tous les mots / vecteurs précédents qu'il a traités avec le mot / vecteur actuel qu'il traite. Le mécanisme d'auto-attention intégrera la compréhension de tous les mots liés dans les mots avec lesquels nous avons affaire .
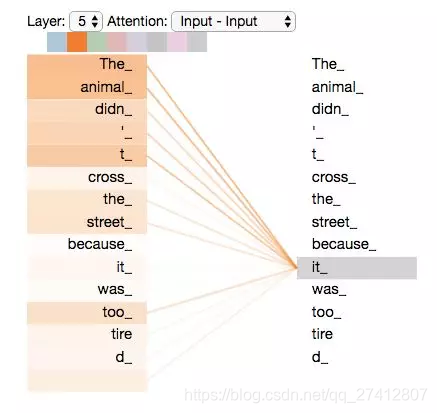
Lorsque nous encodons le mot "it" dans l'encodeur # 5 (l'encodeur le plus haut de la pile), la partie du mécanisme d'attention fera attention à "The Animal" et encodera une partie de sa représentation en "it" Codage.
Veuillez vous assurer de vérifier le bloc-notes Tensor2Tensor, où vous pouvez télécharger un modèle Transformer et le vérifier avec une visualisation interactive.
6. Voir le mécanisme d'auto-attention dans une micro perspective
Commençons par comprendre comment utiliser les vecteurs pour calculer l'auto-attention, puis voyons comment il peut être implémenté à l'aide d'une matrice.
(1) La première étape du calcul de l'attention personnelle consiste à générer trois vecteurs à partir du vecteur d'entrée de chaque codeur (vecteur de mots pour chaque mot).
En d'autres termes, pour chaque mot, nous créons un vecteur de requête, un vecteur clé et un vecteur valeur . Ces trois vecteurs sont créés par incorporation de mots et multiplication par trois matrices de poids.
On peut constater que ces nouveaux vecteurs sont de dimension inférieure aux vecteurs d'intégration de mots. Leur dimension est 64, et la dimension du mot incorporé et du vecteur d'entrée / sortie de l'encodeur est 512. Cependant, il n'est pas nécessaire qu'il soit plus petit. Ce n'est qu'un choix architectural, ce qui peut rendre l'attention à plusieurs têtes (attention à plusieurs têtes) ) La plupart des calculs restent inchangés.
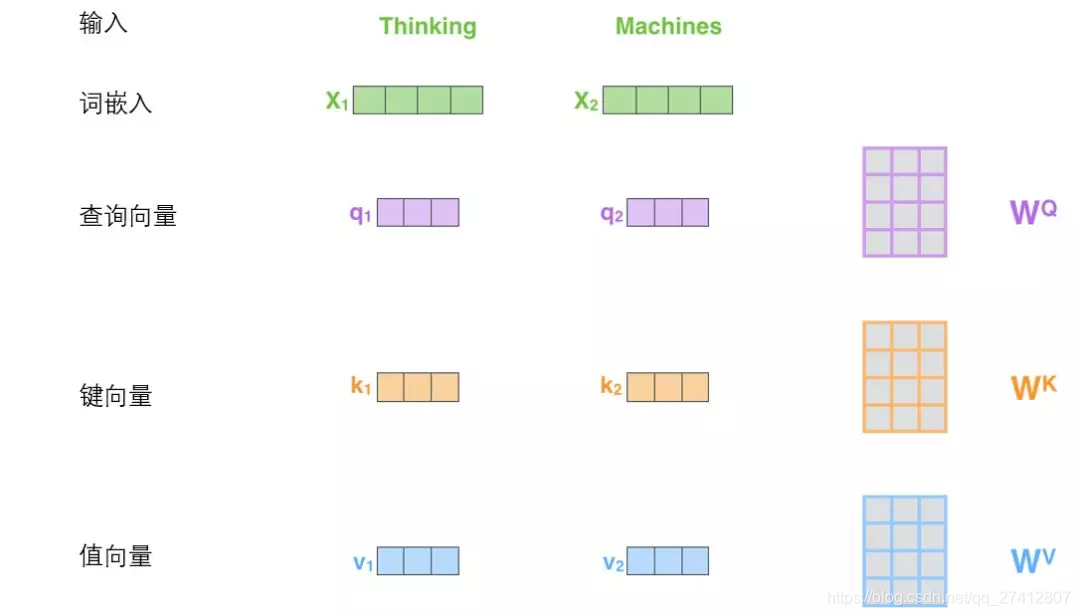
Les matrices de poids X1 et Wq sont multipliées pour obtenir q1, qui est le vecteur de requête lié à ce mot. Enfin, chaque requête de la séquence d'entrée crée un vecteur de requête, un vecteur clé et un vecteur valeur.
Que sont les vecteurs de requête, les vecteurs clés et les vecteurs de vecteur de valeur?
Ce sont tous des concepts abstraits qui aident à calculer et à comprendre le mécanisme d'attention. Veuillez continuer à lire ci-dessous, vous saurez quel rôle joue chaque vecteur dans le calcul du mécanisme d'attention.
(2) La deuxième étape du calcul de l'attention personnelle consiste à calculer le score.
Supposons que nous calculons le vecteur d'auto-attention pour le premier mot "Pensée" dans cet exemple, nous devons marquer "Pensée" pour chaque mot de la phrase d'entrée. Ces scores déterminent le degré d'attention accordé aux autres parties de la phrase lors du codage du mot "Pensée".
Ces scores sont calculés par le produit scalaire du vecteur clé des mots notés (tous les mots dans la phrase d'entrée) et le vecteur de requête "Pensée". ** Donc, si nous avons affaire à l'auto-attention du premier mot, le premier score est le produit scalaire de q1 et k1, et le second score est le produit scalaire de q1 et k2.
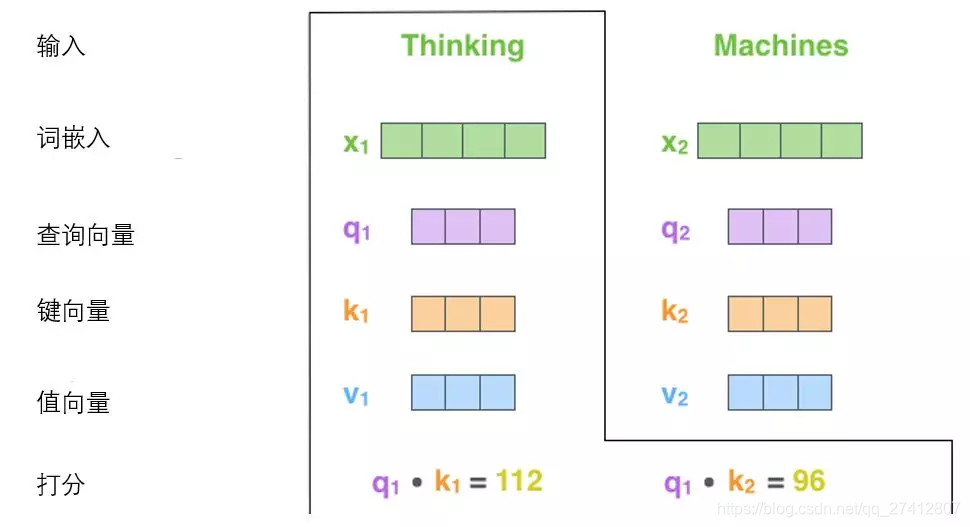
(3) Les troisième et quatrième étapes consistent à diviser le score par 8 (8 est la racine carrée de la dimension 64 du vecteur clé utilisé dans le document, ce qui rend le gradient plus stable. D'autres valeurs peuvent également être utilisées ici, 8 est la valeur par défaut ), Puis passez le résultat via softmax. La fonction de softmax est de normaliser les scores de tous les mots, et les scores obtenus sont positifs et la somme est 1.
Ce score softmax détermine la contribution de chaque mot à la position actuelle du code ("Thinking"). De toute évidence, le mot déjà dans cette position obtiendra le score softmax le plus élevé, mais il peut parfois être utile de se concentrer sur un autre mot lié au mot actuel.
(4) La cinquième étape consiste à multiplier chaque vecteur de valeur par le score softmax (il s'agit de les résumer après préparation). L'intuition ici est que vous souhaitez vous concentrer sur les mots sémantiquement liés et affaiblir les mots non pertinents (par exemple, multipliez-les par une décimale telle que 0,001).
(5) La sixième étape consiste à additionner les vecteurs de valeur pondérés. Par le produit scalaire de la représentation du mot (vecteur clé) et de la représentation du mot codé (vecteur de requête) et obtenu par softmax.), Alors la sortie de la couche d'auto-attention à cette position est obtenue (dans notre exemple, elle est Mots).
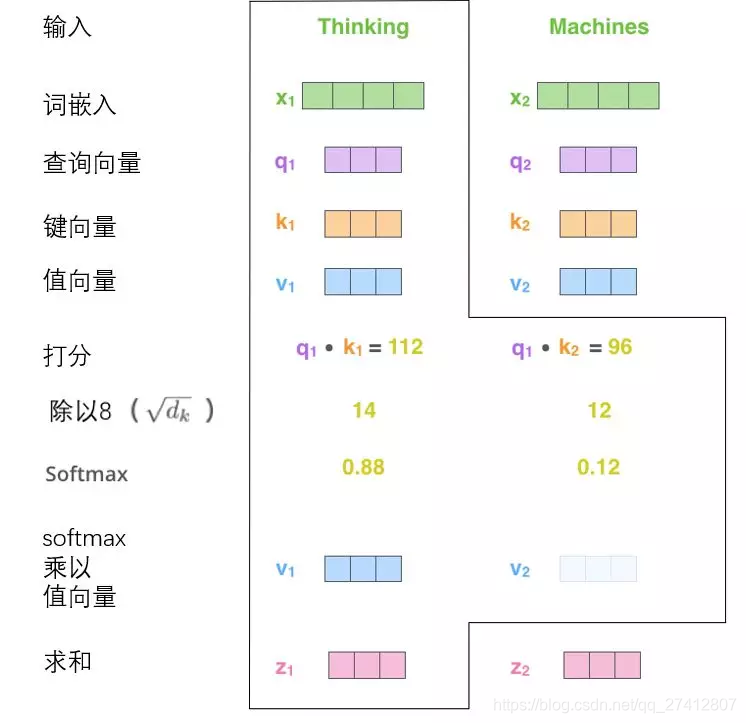
Ceci termine le calcul de l'attention personnelle. Le vecteur résultant peut être transmis au réseau neuronal à action directe. Cependant, en pratique, ces calculs sont effectués sous forme matricielle afin de calculer plus rapidement. Voyons ensuite comment utiliser la matrice.
7. Mécanisme d'auto-attention grâce au fonctionnement matriciel
(1) La première étape consiste à calculer la matrice de requête, la matrice de clé et la matrice de valeur. À cette fin, nous allons intégrer les mots de la phrase d'entrée dans la matrice X et la multiplier par la matrice de poids (Wq, Wk, Wv) que nous avons formée.
** Chaque ligne de la matrice x correspond à un mot dans la phrase d'entrée. ** Nous voyons à nouveau la différence de taille entre le mot vecteur d'intégration (512, ou 4 grilles sur la figure) et le vecteur q / k / v (64, ou 3 grilles sur la figure).
(2) Enfin, étant donné qu'il s'agit de matrices, nous pouvons combiner les étapes 2 à 6 en une formule pour calculer la sortie de la couche d'auto-attention .
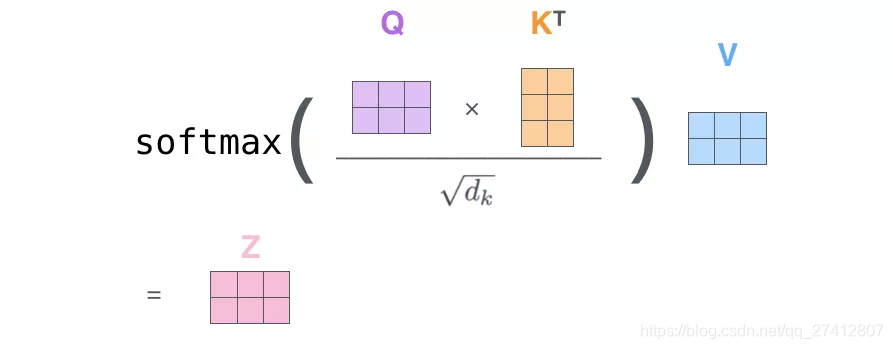
Formulaire d'opération de matrice d'auto-attention
8. "Guerre contre les taureaux"
En ajoutant un mécanisme appelé "attention à plusieurs têtes", le papier perfectionne davantage la couche d'auto-attention et améliore les performances de la couche d'attention de deux manières:
1. Il étend la capacité du modèle à se concentrer sur différents emplacements.
Dans l'exemple ci-dessus, bien que chaque code soit plus ou moins reflété dans z1, il peut être dominé par le mot lui-même. Si nous traduisons une phrase, comme "L'animal n'a pas traversé la rue parce qu'il était trop fatigué", nous aimerions savoir à quel mot "il" fait référence, puis le mécanisme d'attention "long" du modèle fonctionnera.
2. Il donne plusieurs "sous-espaces de représentation" de la couche d'attention.
Ensuite, nous verrons que pour le mécanisme d'attention "multi-têtes", nous avons plusieurs ensembles de matrices de pondération requête / clé / valeur (Transformer utilise huit têtes d'attention, nous avons donc huit ensembles de matrices pour chaque encodeur / décodeur ). Chacun de ces ensembles est initialisé de façon aléatoire et après la formation, chaque ensemble est utilisé pour incorporer les mots d'entrée (ou vecteurs provenant d'encodeurs / décodeurs inférieurs) dans différents sous-espaces de représentation.
Dans le cadre du mécanisme d'attention "multi-têtes", nous maintenons une matrice de pondération requête / clé / valeur indépendante pour chaque tête, ce qui donne des matrices requête / clé / valeur différentes . Comme précédemment, nous multiplions X par la matrice Wq / Wk / Wv pour générer la matrice requête / clé / valeur.
Si nous faisons le même calcul d'auto-attention que ci-dessus, nous n'avons besoin que de huit opérations de matrice de poids différentes et nous obtiendrons huit matrices Z différentes.
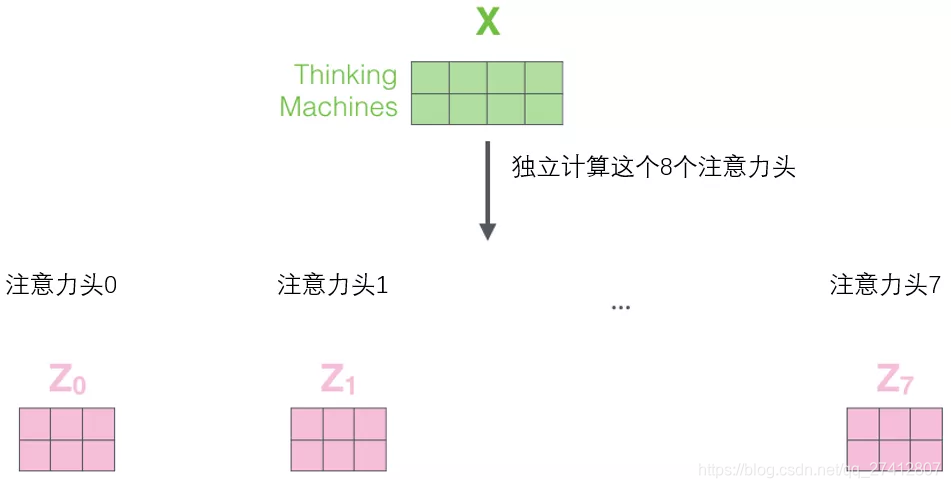
Cela nous amène un petit défi. La couche feedforward n'a pas besoin de 8 matrices, elle n'a besoin que d'une matrice (constituée du vecteur de représentation de chaque mot). Nous avons donc besoin d'un moyen de compresser ces huit matrices en une seule matrice. Que dois-je faire? En fait, ces matrices peuvent être directement épissées ensemble puis multipliées par une matrice de poids supplémentaire W.
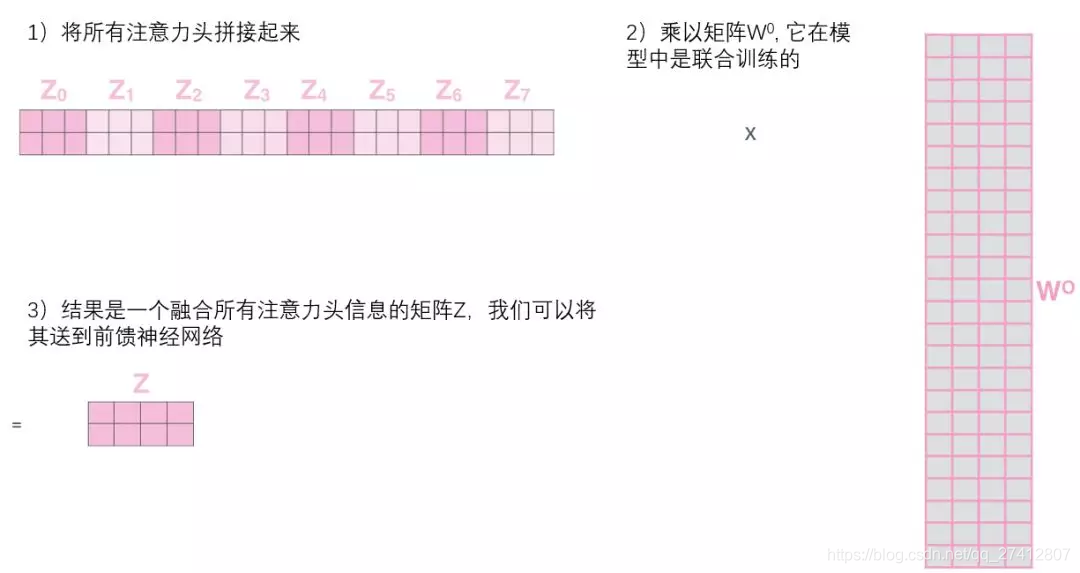
C'est presque toute l'attention des taureaux. Il y a en effet beaucoup de matrices, nous essayons de les assembler dans une image, pour que vous puissiez voir en un coup d'œil.
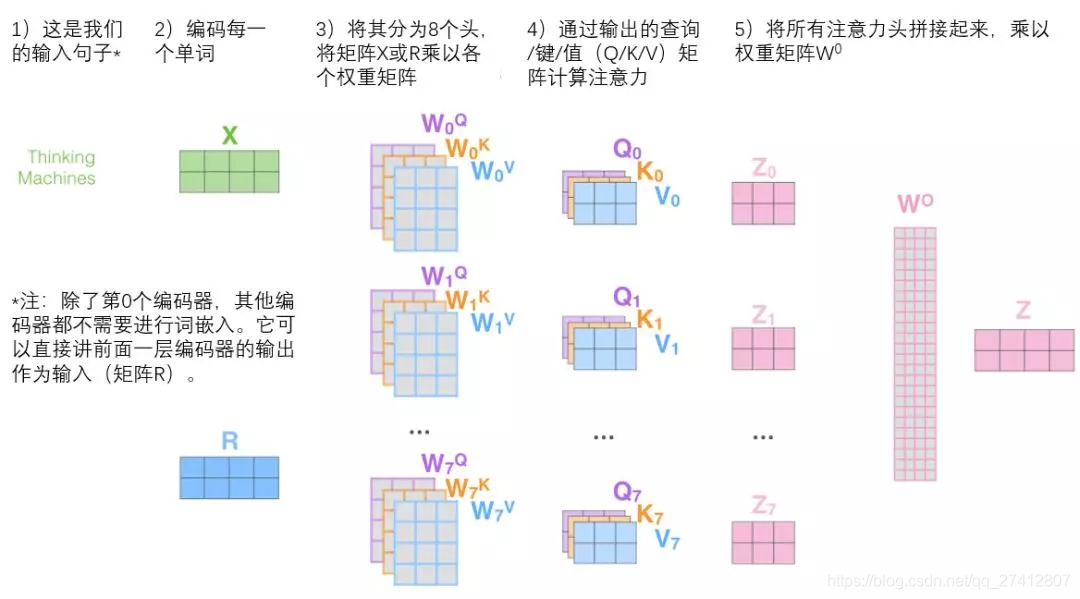
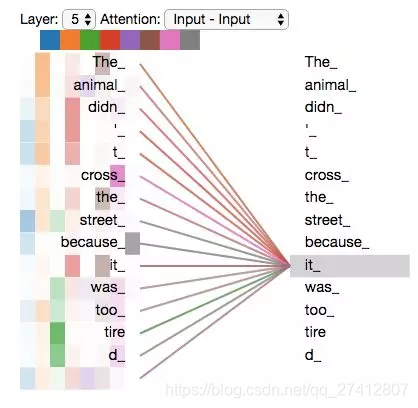
Maintenant que nous avons touché tant de "têtes" du mécanisme d'attention, revenons à l'exemple précédent et voyons où nous nous sommes concentrés sur les différentes "têtes" d'attention lorsque nous avons codé le mot "il" dans la phrase d'exemple:
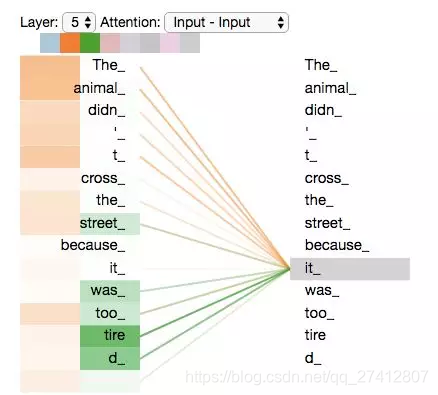
Lorsque nous codons le mot «it», un accent est mis sur «animal» et l'autre sur «fatigué». Dans un sens, le modèle exprime le mot «it» Dans une certaine mesure, c'est le représentant de "l'animal" et du "fatigué".
Cependant, si nous ajoutons toute l'attention à l'illustration, les choses sont plus difficiles à expliquer:
9. Utilisez des codes de position pour indiquer l'ordre des séquences
Jusqu'à présent, notre description du modèle manque d'un moyen de comprendre l'ordre des mots d'entrée.
Pour résoudre ce problème, Transformer ajoute un vecteur à chaque incorporation de mot d'entrée. Ces vecteurs suivent des modèles spécifiques appris par le modèle, ce qui permet de déterminer l'emplacement de chaque mot ou la distance entre les différents mots de la séquence. L'intuition ici est que l'ajout de vecteurs de position aux incorporations de mots leur permet de mieux exprimer la distance entre les mots dans les opérations suivantes .
Afin que le modèle comprenne l'ordre des mots, nous avons ajouté des vecteurs d'encodage de position dont les valeurs suivent un modèle spécifique.
Si nous supposons que la dimension de l'incorporation de mots est 4, le code de position réel est le suivant:
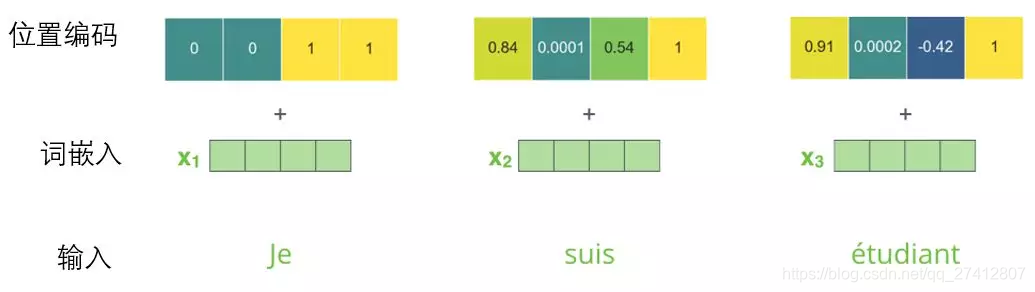
Exemple d'encodage de position pour des mini-mots de taille 4
À quoi ressemblera ce modèle?
Dans la figure ci-dessous, chaque ligne correspond au code de position d'un vecteur de mot, donc la première ligne correspond au premier mot de la séquence d'entrée. Chaque ligne contient 512 valeurs, chaque valeur étant comprise entre 1 et -1. Nous les avons codés par couleur, donc le motif est visible.
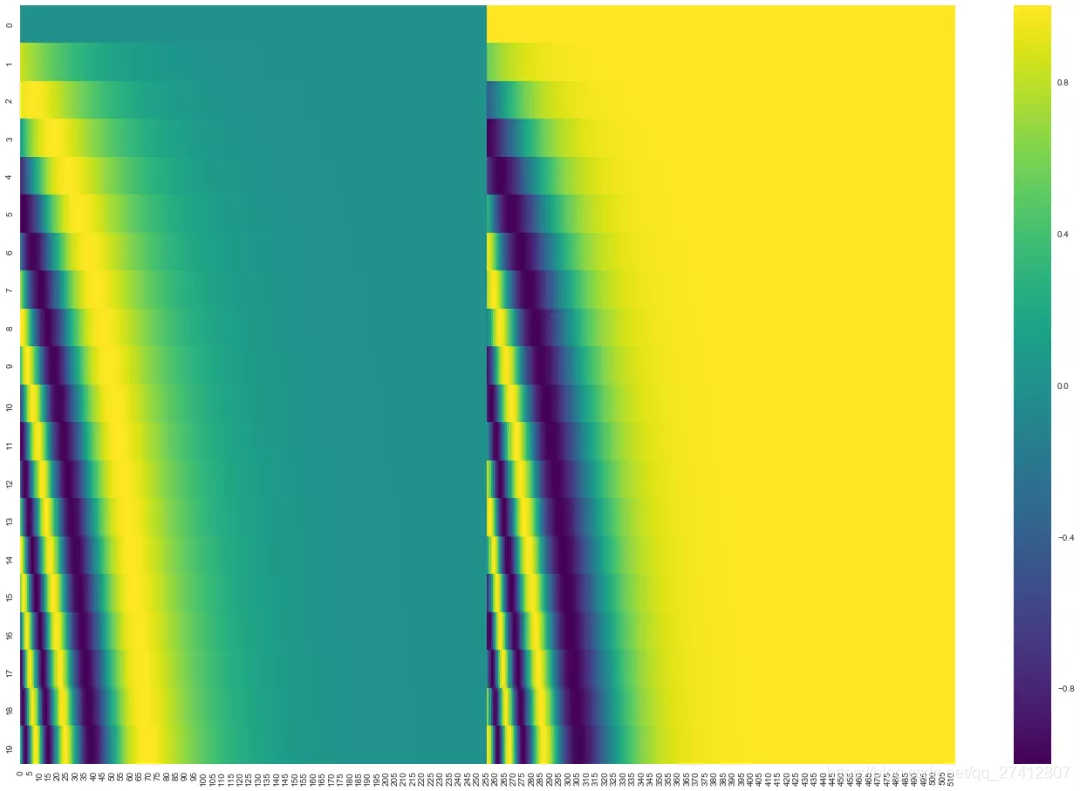
Exemple de codage de position sur 20 mots (ligne), la taille d'intégration du mot est 512 (colonne). Vous pouvez le voir divisé en deux par le milieu. En effet, la moitié gauche de la valeur est générée par une fonction (en utilisant le sinus), tandis que la moitié droite est générée par une autre fonction (en utilisant le cosinus). Ensuite, assemblez-les pour obtenir chaque vecteur d'encodage de position.
L'article original décrit la formule de codage de position (section 3.5). Vous pouvez voir le code qui génère le code de position dans get_timing_signal_1d (). Ce n'est pas la seule méthode de codage de position possible. Cependant, son avantage est qu'il peut être étendu à une longueur de séquence inconnue (par exemple, lorsque le modèle que nous formons doit traduire des phrases beaucoup plus longues que les phrases de l'ensemble d'apprentissage).
10. Module résiduel
Avant de continuer, nous devons mentionner les détails d'une architecture de codeur: il y a une connexion résiduelle autour de chaque sous-couche (auto-attention, réseau à action directe) dans chaque codeur , et tous suivent Une étape de " normalisation des calques ".
Étapes de normalisation des couches: https://arxiv.org/abs/1607.06450
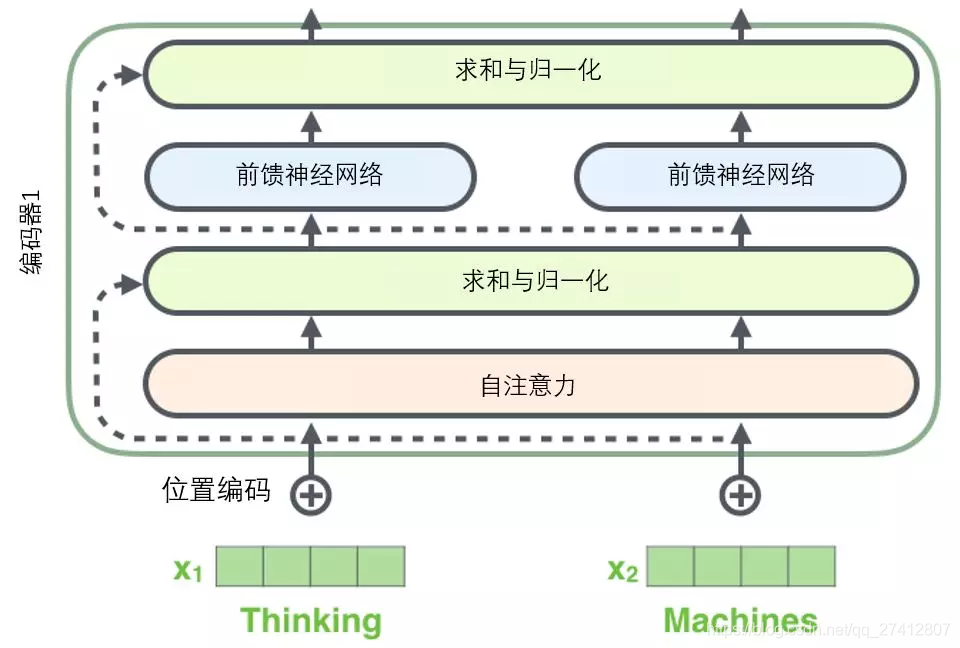
Si nous visualisons ces vecteurs et l'opération de normalisation des couches associée à l'auto-attention, cela ressemble à l'image suivante:
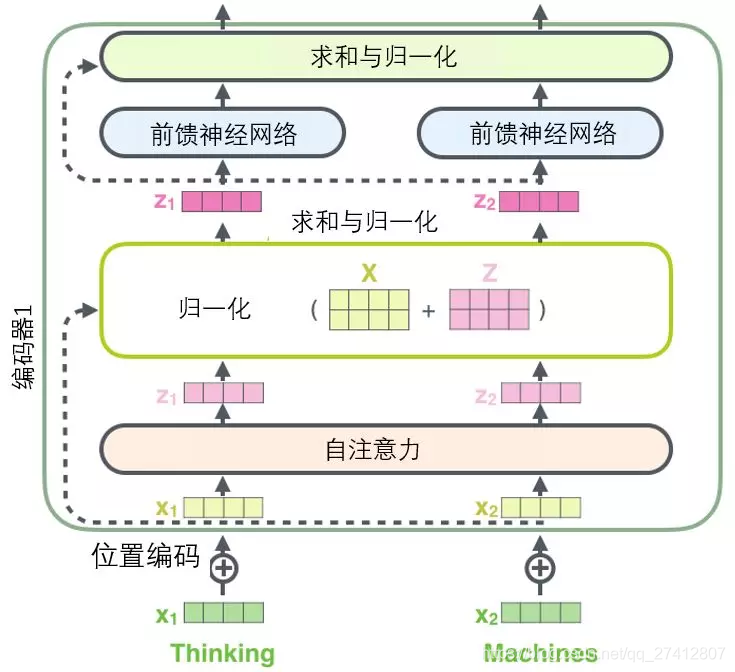
La sous-couche du décodeur est la même. Si nous imaginons un transformateur avec une structure de codage-décodage à 2 couches, il ressemblera à l'image suivante:
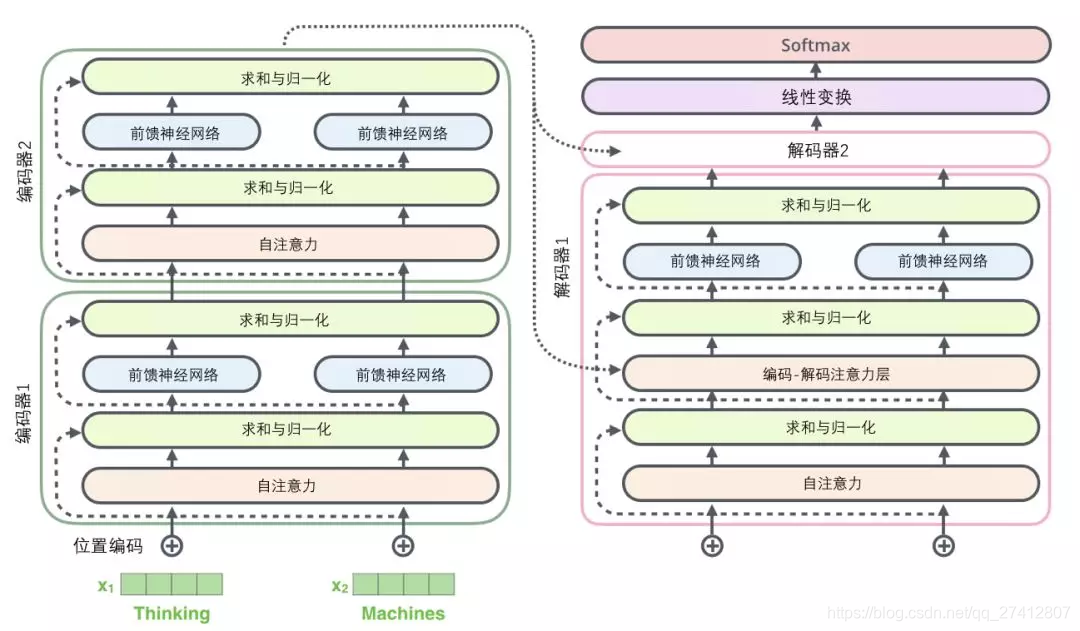
11. Composant de décodage
Maintenant que nous avons parlé du concept de la plupart des encodeurs, nous savons essentiellement comment fonctionne le décodeur. Mais il est préférable de regarder les détails du décodeur.
L'encodeur commence à fonctionner en traitant la séquence d'entrée. La sortie de l'encodeur supérieur sera ensuite transformée en un ensemble de vecteurs d'attention contenant les vecteurs K (vecteur clé) et V (vecteur valeur) . Ces vecteurs seront utilisés par chaque décodeur pour sa propre "couche d'attention au codage-décodage", et ces couches peuvent aider le décodeur à se concentrer sur l'endroit où la séquence d'entrée convient:
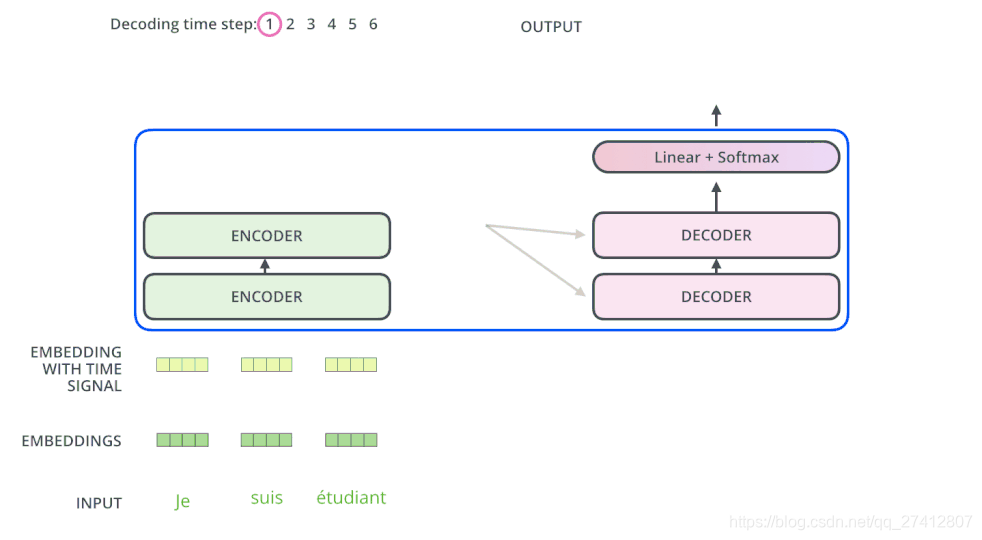
Après avoir terminé la phase de codage, la phase de décodage commence. Chaque étape de l'étage de décodage produit des éléments d'une séquence de sortie (dans cet exemple, une phrase traduite en anglais)
L'étape suivante répète ce processus jusqu'à ce qu'il atteigne un symbole de terminaison spécial, ce qui indique que le décodeur du transformateur a terminé sa sortie. La sortie de chaque étape est fournie au décodeur bas de gamme au pas de temps suivant, et comme le codeur l'a fait auparavant, ces décodeurs sortiront leurs résultats de décodage. De plus, tout comme nous l'avons fait avec l'entrée de l'encodeur, nous allons intégrer et ajouter des codes de position à ces décodeurs pour représenter la position de chaque mot.
src = "https://v.qq.com/txp/iframe/player.html?vid=m13563cy49o" allowfullscreen = "true" width = "600" height = "400">
et l'attention de soi dans ces décodeurs Le mode de représentation des couches est différent de celui du codeur: dans le décodeur, la couche d'auto-attention n'est autorisée qu'à traiter les positions plus haut dans la séquence de sortie . Avant l'étape softmax, il masquera ces dernières positions (définissez-les sur -inf).
Cette "couche d'attention d'encodage-décodage" fonctionne essentiellement comme une couche d'auto-attention à plusieurs têtes, sauf qu'elle crée une matrice de requête à travers les couches en dessous et obtient la matrice clé / valeur de la sortie de l'encodeur.
12. La transformation linéaire finale et la couche Softmax
Le composant de décodage sortira finalement un vrai vecteur. Comment transformer les nombres à virgule flottante en un seul mot? C'est le travail de la couche de transformation linéaire, qui est suivie par la couche Softmax.
La couche de transformation linéaire est un simple réseau neuronal entièrement connecté qui peut projeter le vecteur généré par la composante de décodage dans un vecteur appelé logits qui est beaucoup plus grand que lui.
Supposons que notre modèle apprenne 10 000 mots anglais différents de l'ensemble d'apprentissage (le «vocabulaire de sortie» de notre modèle). Par conséquent, le vecteur de probabilité logarithmique est un vecteur de 10 000 longueurs de cellule - chaque cellule correspond au score d'un certain mot.
La prochaine couche Softmax transformera ces scores en probabilités (toutes deux positives, avec une limite supérieure de 1,0). La cellule avec la probabilité la plus élevée est sélectionnée et son mot correspondant est utilisé comme sortie de ce pas de temps.
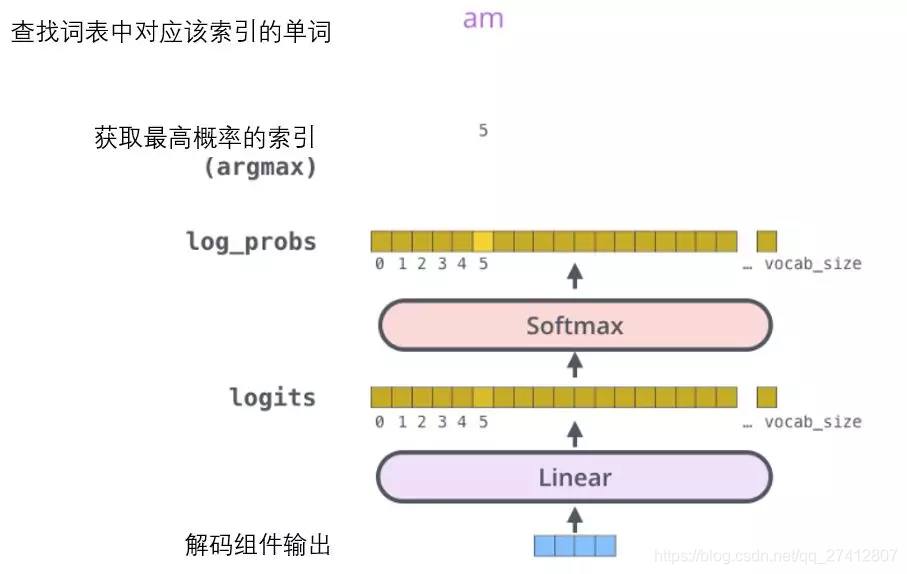
Cette image commence en bas avec le vecteur de sortie généré par le composant décodeur. Ensuite, il convertira un mot de sortie.
13. Résumé de la formation
Maintenant que nous avons traversé le processus de propagation vers l'avant du transformateur complet, nous pouvons expérimenter intuitivement son processus de formation.
Pendant l'entraînement, un modèle non formé se propagera exactement de la même manière. Mais parce que nous l'entraînons avec un ensemble d'apprentissage étiqueté, nous pouvons utiliser sa sortie pour la comparer avec la sortie réelle.
Pour visualiser ce processus, supposons que notre vocabulaire de sortie ne contient que six mots: "a", "am", "i", "thanks", "student" et "" (forme abrégée de fin de phrase).
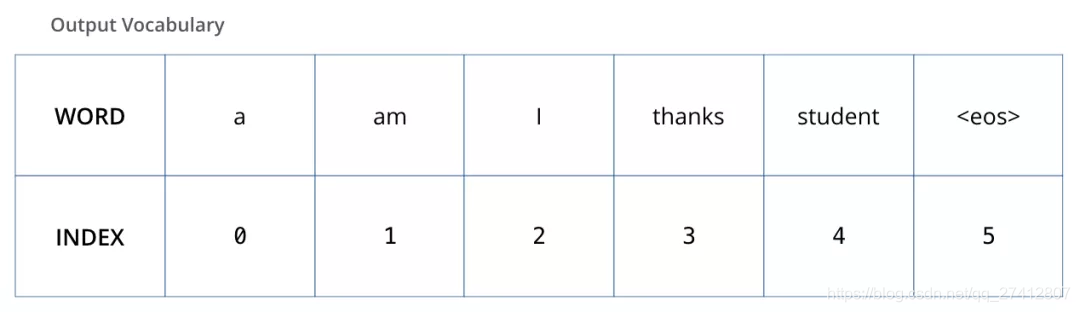
Le vocabulaire de sortie de notre modèle est défini dans le processus de prétraitement avant notre formation.
Une fois que nous avons défini notre vocabulaire de sortie, nous pouvons utiliser un vecteur de même largeur pour représenter chaque mot de notre vocabulaire. Ceci est également considéré comme un codage à chaud. Par conséquent, nous pouvons utiliser le vecteur suivant pour représenter le mot "am":
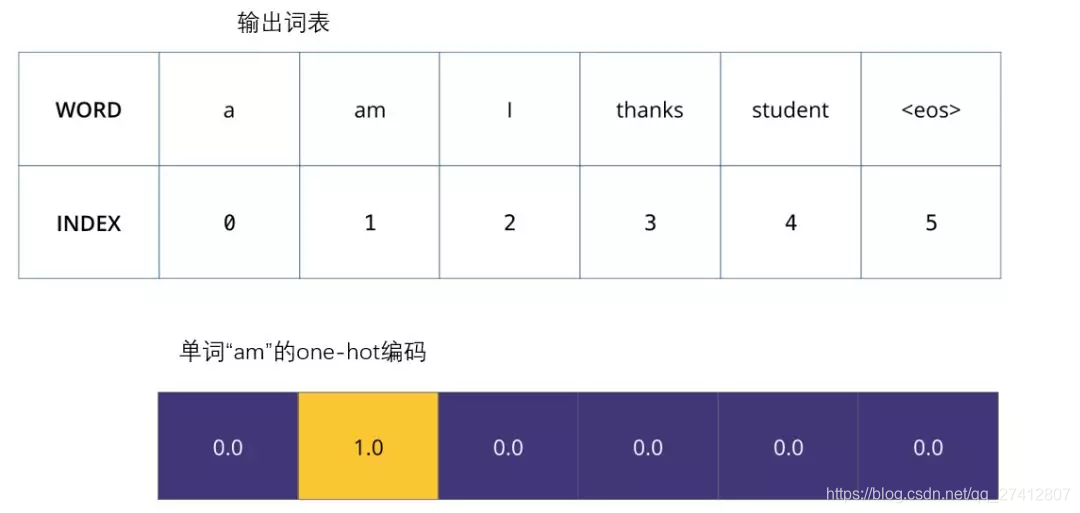
Exemple: codage instantané de notre vocabulaire de sortie
Ensuite, nous discutons de la fonction de perte du modèle - c'est le critère que nous utilisons pour optimiser pendant le processus de formation. Il peut être utilisé pour former un modèle avec un résultat aussi précis que possible.
14. Fonction de perte
Par exemple, nous formons le modèle, c'est maintenant la première étape, un simple exemple-traduire "merci" en "merci".
Cela signifie que nous voulons une sortie qui représente la distribution de probabilité du mot "merci". Mais parce que ce modèle n'a pas été bien formé, il est peu probable que ce résultat apparaisse maintenant.
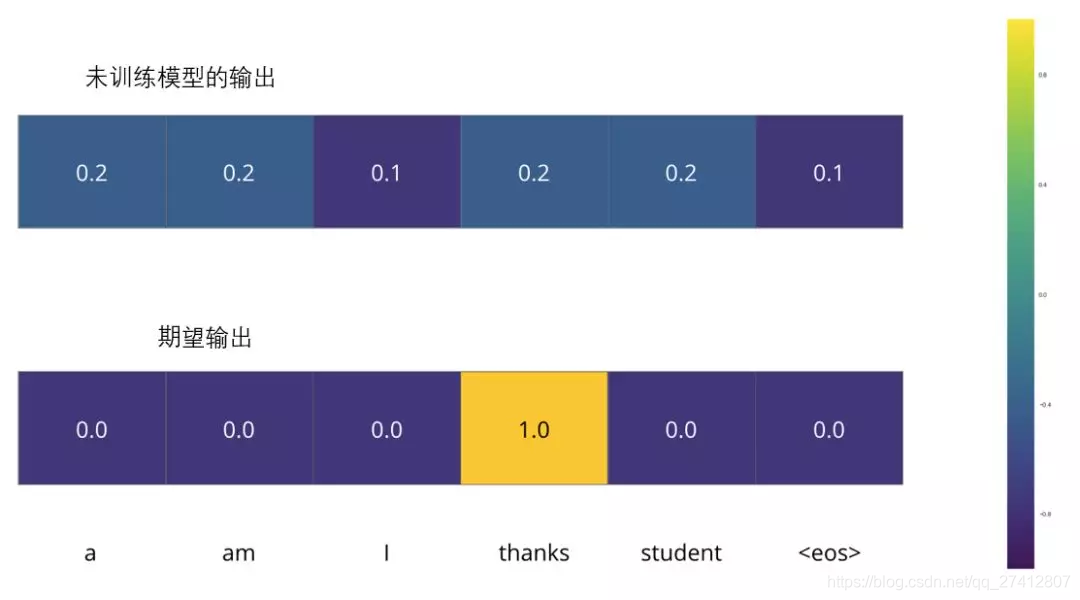
Étant donné que les paramètres (poids) du modèle sont générés de manière aléatoire, la distribution de probabilité générée par le modèle (non formé) reçoit une valeur aléatoire dans chaque cellule / mot. Nous pouvons le comparer avec la sortie réelle, puis utiliser l'algorithme de rétropropagation pour ajuster légèrement les poids de tous les modèles afin de générer une sortie plus proche du résultat.
Comment compareriez-vous deux distributions de probabilité? Nous pouvons simplement soustraire l'un de l'autre. Pour plus de détails, veuillez vous référer à Cross Entropy et KL Divergence.
Entropie croisée: https://colah.github.io/posts/2015-09-Visual-Information/
Dispersion KL: https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
Mais notez qu'il s'agit d'un exemple simplifié à l'excès. La situation la plus réaliste consiste à traiter une peine. Par exemple, entrez "je suis étudiant" et attendez-vous à ce que la sortie soit "je suis un étudiant". Ensuite, nous espérons que notre modèle pourra produire avec succès la distribution de probabilité dans ces cas:
Chaque distribution de probabilité est représentée par un vecteur dont la largeur est la taille du vocabulaire (6 dans notre exemple, mais en réalité il est généralement de 3000 ou 10000).
La première distribution de probabilité a la probabilité la plus élevée dans la cellule associée à "i"
La deuxième distribution de probabilité a la probabilité la plus élevée dans la cellule associée à "am"
Par analogie, la distribution de la cinquième sortie indique que la cellule associée à "" a la probabilité la plus élevée
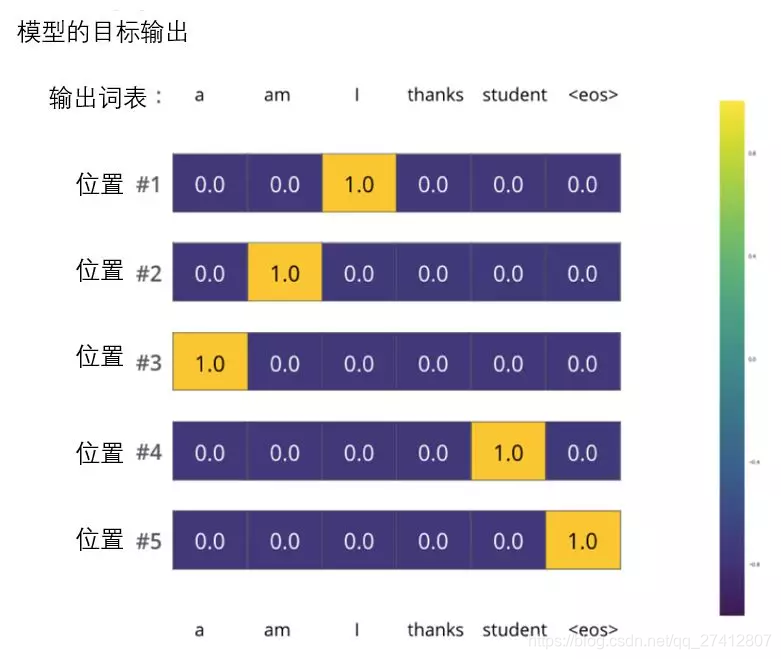
Distribution de probabilité cible obtenue en entraînant un modèle selon un exemple
Après une formation complète sur un ensemble de données suffisamment grand, nous voulons que la distribution de probabilité de la sortie du modèle ressemble à ceci:
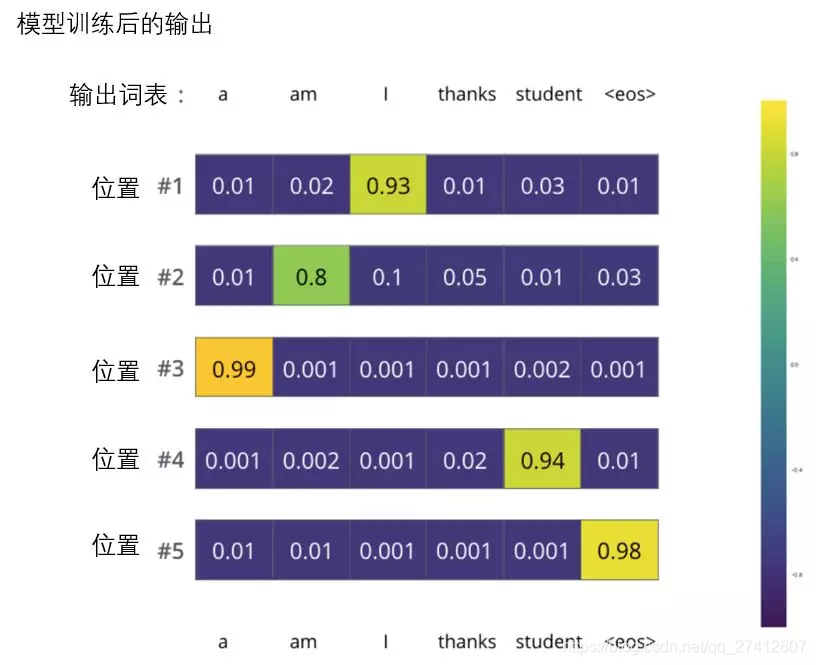
Nous nous attendons à ce qu'après la formation, le modèle produise la traduction correcte. Bien sûr, si ce paragraphe provient entièrement de l'ensemble de formation, ce n'est pas un bon indicateur d'évaluation (référence: validation croisée, lien https://www.youtube.com/watch?v=TIgfjmp-4BA). Notez que chaque position (mot) obtient une petite probabilité, même s'il est peu probable qu'elle soit la sortie de ce pas de temps - c'est une propriété utile de softmax, qui peut aider à modéliser la formation.
Étant donné que ce modèle ne produit qu'une sortie à la fois, on peut supposer que ce modèle ne sélectionne que le mot ayant la probabilité la plus élevée et supprime les mots restants. C'est l'une des méthodes (appelée décodage gourmand). Une autre façon d'accomplir cette tâche consiste à conserver les deux mots avec la probabilité la plus élevée (par exemple, I et a), puis à l'étape suivante, exécutez le modèle deux fois: l'un d'eux suppose que la première sortie de position est le mot "I" Une autre hypothèse est que la première sortie de position est le mot "moi", et peu importe la version qui produit le moins d'erreur, les deux résultats de traduction avec la probabilité la plus élevée sont conservés. Ensuite, nous répétons cette étape pour les deuxième et troisième positions. Cette méthode est appelée recherche de faisceau. Dans notre exemple, la largeur du faisceau est de 2 (car les résultats de deux faisceaux sont conservés, tels que les première et deuxième positions), et les résultats des deux faisceaux sont également renvoyés (top_beams vaut également 2). Ce sont des paramètres qui peuvent être définis à l'avance.
Étant donné que ce modèle ne produit qu'une sortie à la fois, on peut supposer que ce modèle ne sélectionne que le mot ayant la probabilité la plus élevée et supprime les mots restants. C'est l'une des méthodes (appelée décodage gourmand). Une autre façon d'accomplir cette tâche consiste à conserver les deux mots avec la probabilité la plus élevée (par exemple, I et a), puis à l'étape suivante, exécutez le modèle deux fois: l'un d'eux suppose que la première sortie de position est le mot "I" Une autre hypothèse est que la première sortie de position est le mot "moi", et peu importe la version qui produit le moins d'erreur, les deux résultats de traduction avec la probabilité la plus élevée sont conservés. Ensuite, nous répétons cette étape pour les deuxième et troisième positions. Cette méthode est appelée recherche de faisceau. Dans notre exemple, la largeur du faisceau est de 2 (car les résultats de deux faisceaux sont conservés, tels que les première et deuxième positions), et les résultats des deux faisceaux sont également renvoyés (top_beams vaut également 2). Ce sont des paramètres qui peuvent être définis à l'avance.
