Avant d'introduire le protocole de cohérence, nous pouvons d'abord comprendre le système distribué. Il s'avère que lorsque nous étions à l'école, les projets d'entraînement étaient définitivement des déploiements centralisés. Par exemple, un Tomcat a été résolu, y compris de nombreux petits projets maintenant, comme suit:
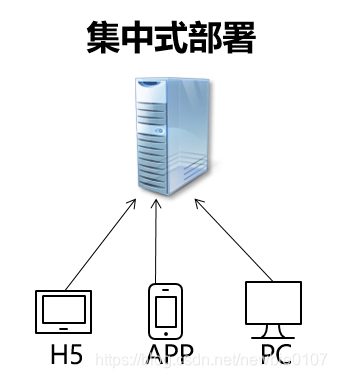
Cependant, avec la fourniture d'exigences de performance de service, ou afin d'éviter des problèmes tels que des points de défaillance uniques, le déploiement centralisé peut ne pas être en mesure de répondre à nos besoins.Un système dans lequel les composants matériels ou logiciels sont distribués sur différents ordinateurs du réseau, et ils communiquent et se coordonnent entre eux uniquement par le passage de messages, Il s'agit d'un système distribué.
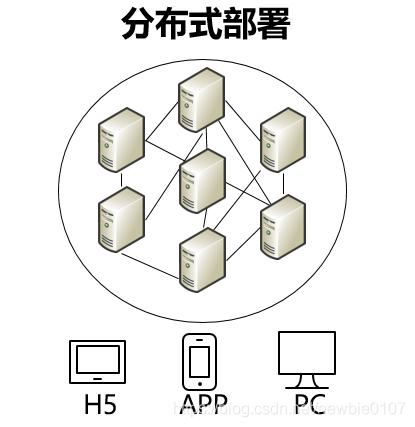
Ses caractéristiques sont les suivantes:
- Distribution
- Équivalence
- Accès simultané
- Absence d'horloge mondiale
- L'échec se produit à tout moment
Distribution
Puisqu'il s'agit d'un système distribué, la caractéristique la plus évidente doit être la distribution. D'un simple point de vue, en supposant qu'un projet est relativement important, nous pouvons diviser l'ensemble du projet en différentes fonctions et en microservices avec différents points professionnels, tels que les microservices utilisateur. Les microservices de produits, les microservices de commande, ces services sont déployés dans différents Tomcats, différents serveurs, ou même différents clusters, l'architecture entière est distribuée à différents endroits, est aléatoire dans l'espace et augmentera à tout moment , Supprimez le nœud du serveur, etc.
Équivalence
L'équivalence est un objectif de la conception distribuée. Pour compléter une architecture de système distribué, il ne s'agit certainement pas simplement de diviser un grand système unique en microservices, puis de le déployer sur différents clusters de serveurs. Chaque microservice terminé après la division peut rencontrer des problèmes, ce qui peut entraîner des problèmes pour l'ensemble du projet.
Par exemple, le service de commande, afin d'éviter les problèmes de service de commande, doit généralement avoir une sauvegarde, peut remplacer le service de commande d'origine lorsqu'il y a un problème avec le service de commande, ce que nous avons dit ci-dessus, afin d'éviter un seul point de défaillance.
Cela nécessite que les deux (ou plus de deux) services de commande soient complètement égaux et que les fonctions soient totalement cohérentes. En fait, il s'agit d'une sorte de redondance des copies de service.
L'autre est la redondance des copies de données, telles que les bases de données, les caches, etc., qui sont les mêmes que le service de commande mentionné ci-dessus. Pour des raisons de sécurité, il doit y avoir exactement la même sauvegarde, ce qui signifie l'équivalence.
Accès simultané
La concurrence n'est pas nouvelle pour nous. Lors de l'apprentissage de la programmation simultanée, le multithreading est le fondement de la concurrence. Mais maintenant, nous ne sommes pas en contact avec la perspective multi-thread, car lorsque nous introduisons le codage simultané, nous sommes tous sur la même machine et la même perspective JVM, nous pouvons ici du point de vue de plusieurs JVM, par exemple, dans une distribution Plusieurs nœuds du système peuvent exploiter simultanément certaines ressources partagées et d'autres problèmes, ce qui implique le problème des verrous distribués.
Absence d'horloge mondiale
Dans un système distribué, les nœuds peuvent être placés dans n'importe quelle position, et chaque emplacement, chaque nœud a son propre système de temps, donc dans un système distribué, il est difficile de définir les deux transactions enchevêtrées en premier, et la raison C'est en raison de l'absence d'une séquence d'horloge globale à contrôler, bien sûr, que nous pouvons résoudre le problème en appelant le serveur de temps.
Les échecs peuvent survenir à tout moment
N'importe quel nœud peut subir des pannes de courant, des pannes, etc. Plus il y a de clusters de serveurs, plus les risques de défaillance augmentent. À mesure que le nombre de clusters augmente, les défaillances deviennent même un état normal.
Nous avons brièvement présenté les caractéristiques du système distribué ci-dessus, alors quels problèmes simples notre système distribué réel apportera-t-il? 通信异常Sont: 网络分区, 三态,,节点故障
Communication anormale
L'anomalie de communication est en fait une anomalie de réseau et le système de réseau lui-même n'est pas fiable. Comme le système distribué a besoin de transmettre des données à travers le réseau, la fibre du réseau, le routeur et d'autres matériels auront inévitablement des problèmes. Tant qu'il y aura un problème avec le réseau, cela affectera le processus d'envoi et de réception du message, donc la perte ou l'extension des messages de données deviendra très courante.
Partition réseau
Le partitionnement du réseau est en fait un phénomène de split-brain. Il y avait un leader pour gérer la coordination de tout le système. Tout était en ordre. Soudain, il y a eu un problème de réseau. Certains nœuds n'ont pas pu recevoir les instructions du leader. Peut-être que dans ce cas, Un nouveau leader apparaîtra pour coordonner le système. Mais le leader d'origine est toujours là, et il n'y a pas de plantage, mais le système de réseau est temporairement interrompu. À ce moment, il y aura des problèmes. Dans le même système, différents leaders se coordonnent, ce qui entraînera inévitablement le chaos dans ce système.
Ce type de schizophrénie survient lorsqu'il y a deux personnes responsables en conflit dans la même zone (cluster distribué) en raison de divers problèmes. Ici, on parle de division du cerveau, également appelée partitionnement de réseau.
Tristate
Quels sont trois états? Les trois états sont en fait le succès et le troisième état autre que l'échec est appelé 超时态. Dans une machine virtuelle Java, l'application obtiendra une réponse claire après avoir appelé une fonction de méthode, que ce soit un succès ou un échec, et dans un système distribué, bien que la réponse au succès ou à l'échec puisse être acceptée dans la plupart des cas, mais une fois le réseau Si une exception se produit, il est très probable qu'un délai se produise. Lorsqu'un tel délai se produit, l'initiateur de la communication réseau ne peut pas déterminer si la demande a été traitée avec succès.
Échec du nœud
Ceci est en fait introduit dans les fonctionnalités. La défaillance d'un nœud est un problème relativement courant dans les systèmes distribués. Elle fait référence au phénomène de temps d'arrêt ou de «zombie» qui se produit dans les nœuds qui forment le cluster de serveurs. Ce phénomène se produit souvent.
Théorie de la PAC
Ok, après avoir compris les problèmes ci-dessus, comment les résoudre? Tout d'abord, nous pouvons généralement résoudre les problèmes ci-dessus sous trois angles. C'est le nôtre CAP理论. CAP est en fait la cohérence, la disponibilité et la tolérance de partition.
Cohérence
La cohérence est une caractéristique de la transaction ACID [atomicité, cohérence, isolation, durabilité], qui a été introduite en détail lors de l'introduction de MySQL, et la cohérence ici est essentiellement Similaire, mais maintenant l'environnement distribué est pris en compte, il ne peut donc pas s'agir d'une seule base de données.
Dans un système distribué, la cohérence consiste à garantir la cohérence des données entre plusieurs copies. La cohérence ici est similaire à l'équivalence mentionnée précédemment. Si les modifications apportées à un certain élément de données peuvent être exécutées avec succès dans un système distribué, tous les utilisateurs peuvent immédiatement lire la dernière valeur, alors un tel système est considéré comme ayant une forte cohérence
Convivialité
La disponibilité signifie que le système fournit des services qui doivent toujours être disponibles et que la demande d'opération de l'utilisateur peut toujours accéder aux résultats dans un temps limité . Pour atteindre un temps limité, vous devrez peut-être utiliser le cache et devrez peut-être utiliser la charge. À ce stade, le nœud ajouté par le serveur est pour des considérations de performances; pour renvoyer les résultats, vous devez considérer le maître et la sauvegarde du serveur. Peut être remplacé dès que possible pour éviter des problèmes tels que des points de défaillance uniques.
Tolérance aux pannes de partition
Lorsqu'un système distribué rencontre une défaillance de partition réseau, il doit toujours être en mesure de fournir des services qui répondent à la cohérence et à la disponibilité, sauf si l'environnement réseau entier a échoué.
Théorie de BASE
Alors, pouvons-nous répondre aux trois exigences de la théorie CAP ci-dessus dans un système distribué en même temps, désolé, c'est impossible, au plus seulement deux d'entre elles peuvent être satisfaites, nous devons donc avoir quelques choix, Comme suit:
| Compromis | La description |
|---|---|
| Abandonnez P (rencontrez AC) |
Mettre les données et les services sur un seul nœud pour éviter l'impact négatif causé par le réseau, garantir pleinement la disponibilité et la cohérence du système mais renoncer à P moyens de renoncer à l'évolutivité du système |
| Abandonner A (Meet PC) |
Lorsque le nœud tombe en panne ou le réseau tombe en panne, le service affecté doit attendre un certain temps. Par conséquent, pendant le temps d'attente, le système ne peut pas fournir de services normaux à l'extérieur, il n'est donc pas disponible. |
| Abandonnez C (rencontrez PA) |
Le système ne peut pas garantir la cohérence en temps réel des données, mais promet que les données finiront par garantir la cohérence. Par conséquent, il y a une période de fenêtre d'incohérence des données, et la longueur de la période de fenêtre dépend de la conception du système |
Mais nous avons constaté que puisque nous sommes un système distribué, si nous abandonnons P, nous ne revenons pas à un seul nœud, nous pensons donc à abandonner A ou C, mais nous ne pouvons pas abandonner complètement, nous ne pouvons donc que selon l'entreprise Besoins, dans la mesure du possible, de faire certains compromis, ainsi est venue notre théorie BASE
Fondamentalement disponible
Lorsqu'une défaillance imprévue se produit dans un système distribué, la disponibilité partielle peut être perdue, garantissant la "disponibilité de base" du système, reflétée par la "perte de temps" et la "perte de fonction". Par exemple, certains utilisateurs peuvent geler ou rétrograder leur page Taobao pendant la période de double onze pics.
État doux
Les données du système peuvent exister dans un état intermédiaire, c'est-à-dire qu'il y a un retard dans le processus de synchronisation des données entre les copies de données des différents nœuds du système, et on pense que ce retard n'affectera pas la disponibilité du système. Par exemple: lors de la billetterie du site Web du Festival du Printemps 12306, la demande peut entrer dans la file d'attente.
Éventuellement cohérent
Après une période de synchronisation des données, toutes les données peuvent finalement atteindre un état cohérent. Par exemple, le montant du virement sur l'APP bancaire est temporairement incohérent
