tener conocidos Web de rastreadores
- Cómo ver y cómo instalar el módulo de función del módulo
- Lo rastreador web es?
- rastreadores web pueden hacer nada?
# 如何查看模块功能以及如何安装模块
'''
当新接触到一个模块的时候,如何了解这个模块的功能。主要方法有:
1.help()--输入对应的模块名
2.阅读该模块的文档,一些大型的模块都有,比如scrapy
3.查看模块的源代码,分析各方法的作用,也可以从名字进行相应的分析
'''
# 网络爬虫是什么?
'''
网络爬虫就是自动从互联网中定向或不定向地采集信息的一种程序。
网络爬虫有很多类型,常用的有通用网络爬虫、聚焦网络爬虫等。
'''
# 网络爬虫能做什么事情?
'''
通用网络爬虫可以应用在搜索引擎中,聚焦网络爬虫可以从互联网中自动采集信息并代替我们筛选出相关的数据。
具体来说,网络爬虫经常可以应用在以下方面:
1. 搜索引擎
2. 采集金融数据
3. 采集商品数据
4. 自动过滤广告
5. ……
'''
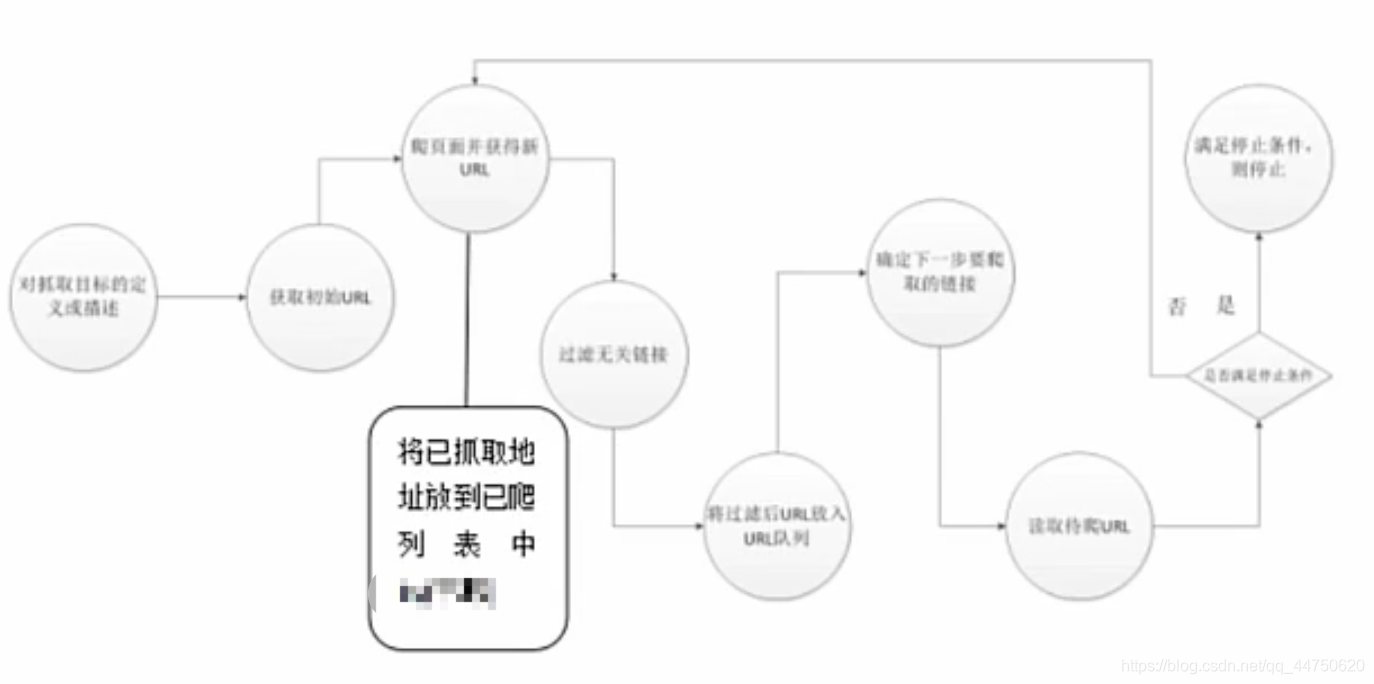
las obras que se detallan rastreador web
Principios generales de funcionamiento de la red y el rastreador enfocado siguiente:

Las expresiones regulares
- ¿Qué es una expresión regular
- átomo
- metacaracteres
- Los modificadores de patrones
- Modo codiciosos y perezosos
- Funciones para expresiones regulares
- Los ejemplos más comunes de regularidad
- reptiles simples
# 什么是正则表达式
'''
正则表达式就是一种进行数据筛选的表达式。
'''
# 原子
'''
原子是正则表达式中最基本的组成单位,每个正则表达式中至少要包含一个原子。常见的原子类型有:
a普通字符作为原子
b非打印字符作为原子,例如:\n 换行符,\t 制表符
c通用字符作为原子,例如:
\w 匹配任意一个字母、数字、下划线;
\W 匹配除字母、数字、下划线外的任意一个字符
\d 匹配十进制数
\D 匹配出十进制数外的任意一个数字
\s 匹配任意一个空白字符
\S 匹配出空白字符外的任意一个字符
d原子表
[xyz]从原子表中选出一个原子,原子表中原子地位都相等
[^xyz]除了原子表中的字符,其他都可以
import re
# 普通字符作为原子
string = "renshengkuduanwoxuepython"
pat = "xue" # 正则表达式
rst = re.search(pat, string)
#print(rst) # 提取出的结果<re.Match object; span=(16, 19), match='xue'> 未提取出的结果 None
# 非打印字符作为原子
string = "renshengkuduanwoxuepython
baidu
"
pat = "\n"
rst = re.search(pat, string)
#print(rst) # <re.Match object; span=(25, 26), match='\n'>
# 通用字符作为原子
string = "renshengkuduan 2021woxuepython"
pat = "\w\s\d\d"
rst = re.search(pat, string)
#print(rst) # <re.Match object; span=(13, 17), match='n 20'>
# 原子表
string = "renshengkuduanwoxuepython"
pat = "[xyz]ue" # 正则表达式
pat = "[^abc]ue"
rst = re.search(pat, string)
print(rst) # <re.Match object; span=(16, 19), match='xue'>
'''
# 元字符
'''
所谓元字符,就是正则表达式中具有一些特殊含义的字符,比如重复N次前面的字符等。
. 匹配除换行符以外的任意一个字符
^ 不在原子表的话,表示匹配开始位置,在原子表中代表非
$ 匹配结束位置
* 前面原子出现0次、1次、多次
?前面原子出现0次、1次
+ 前面原子出现1次、多次
{n} 前面原子恰好出现n次
{n,} 前面原子至少出现n次
{n, m} 前面原子至少出现n次,至多出现m次
| 表示模式选择符或
() 表示模式单元
import re
string = "renshengkuduan20081221woxuepython"
pat = "kud.an" # <re.Match object; span=(8, 14), match='kuduan'>
pat = "^ren" # 可以 ^en则不可以,因为e不是字符串开头的字母
pat = "200812{2}"
rst = re.search(pat, string)
print(rst)
'''
# 模式修正符
'''
所谓模式修正符,即可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整等功能。
I 匹配时候忽略大小写 *
M 多行匹配 *
L 本地化识别匹配
U 根据Unicode识别
S 让.匹配包括换行符 *
import re
string = "Python"
pat = "pyt"
rst = re.search(pat, string) # None
rst = re.search(pat, string, re.I) # <re.Match object; span=(0, 3), match='Pyt'>
print(rst)
'''
# 贪婪模式与懒惰模式
'''
贪婪模式的核心点就是尽可能多的匹配,而懒惰模式的核心点就是尽可能少的匹配
贪婪模式:比较模糊
懒惰模式:比较精确
默认是贪婪模式
import re
string = "Pythony"
pat1 = "p.*y" # 默认贪婪模式
pat2 = "p.*?y" # ?代表懒惰模式
rst1 = re.search(pat1, string, re.I) # <re.Match object; span=(0, 7), match='Pythony'>
rst2 = re.search(pat2, string, re.I) # <re.Match object; span=(0, 2), match='Py'>
print(rst1)
print(rst2)
'''
# 正则表达式函数
'''
正则表达式函数有re.match()函数、re.search()函数、全局匹配函数、re.sub()函数
1.match
match只能从头开始匹配,如果要匹配的不在开头则为None
2.search(已学)
可以从任意一个位置开始匹配
3.全局匹配函数
格式:re.compile(正则).findall(字符串)
import re
string = "Pythony"
pat1 = "p.*?y" # <re.Match object; span=(0, 2), match='Py'>
pat1 = "o.*?y" # None
rst1 = re.match(pat1, string, re.I)
#print(rst1)
string = "pythonypoyghpny"
pat = "p.*?y"
rst = re.compile(pat).findall(string)
print(rst) # ['py', 'poy', 'pny']
'''
# 常见正则实例
'''
如何匹配.com或者.cn网址,以及如何匹配电话号码
import re
string = "<a href='http://www.baidu.com'>百度首页</a>"
pat = "[a-zA-Z]+://[^\s]*[.com|.cn]"
rst = re.compile(pat).findall(string)
print(rst)
string1 = "test021-47112345testre0371-123456789"
pat1 = "\d{4}-\d{7}|\d{3}-\d{8}"
rst1 = re.compile(pat1).findall(string1)
print(rst1) # ['021-47112345', '0371-1234567']
'''
# 简单的爬虫
'''
直接使用urllib即可编写
import urllib.request
data = urllib.request.urlopen("http://edu.csdn.net").read()
#print(data)
# 如何爬取某大学的主页,并自动提取出邮箱
import urllib.request
import re
data = urllib.request.urlopen("https://www.tsinghua.edu.cn/publish/thu2018/index.html").read().decode("utf-8")
pat = "<span><i class=\"icon-mail\"></i>(\s[a-z]{4,}@[a-z]{4,}.[a-z]{3}.[a-z]{2}?)</span>"
rst = re.compile(pat).findall(data)
print(rst[0]) # [email protected]
# 出版社爬取
import urllib.request
import re
url = "https://read.douban.com/provider/all"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
ret = urllib.request.Request(url, headers = headers)
data = urllib.request.urlopen(ret).read().decode("utf-8")
pat = "<div class=\"name\">(.*?)</div>"
rst = re.compile(pat).findall(data)
fh = open("./chubanshe.txt", "w")
for i in range(0, len(rst)):
fh.write(rst[i]+"\n")
fh.close()
'''
