Haga clic en " Python Crawler and Data Mining " arriba para prestar atención
Responda a " Libros " para obtener un total de 10 libros electrónicos sobre Python desde básico hasta avanzado
ahora
Día
pollo
Sopa
Las formalidades de la carta vulgar continuaron, contando las infinitas cosas en mi corazón.
Hola a todos, soy Pippi.
I. Introducción
Hace unos días en el grupo del rey más fuerte de Python [鶏 ah 鶏. ] Hice una Pythonpregunta sobre un rastreador web y la compartiré con ustedes aquí.
Aquí está su código:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from PIL import Image
import ddddocr
ocr = ddddocr.DdddOcr()
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36')
options.add_argument("--disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(options=options)
# 打开目标网页
driver.get('https://sol.sinosure.com.cn')
time.sleep(5)
driver.maximize_window()
# 定位验证码图片元素并模拟鼠标悬停以加载图片
yanzhengma = driver.find_element(By.CSS_SELECTOR, '.pass-form-item.pass-form-item-code')
captcha_element = yanzhengma.find_element(By.CSS_SELECTOR, '.pass-label-img')
webdriver.ActionChains(driver).move_to_element(captcha_element).perform()
time.sleep(5)
# 获取验证码图片元素的位置和大小
location = captcha_element.location
size = captcha_element.size
print(location)
print(size)
# 截取整个网页的截图
driver.save_screenshot('screenshot.png')
# 根据验证码图片元素的位置和大小,从整个网页截图中裁剪出验证码图片
left = int(location['x'])
top = int(location['y'])
right = int(location['x'] + size['width'])
bottom = int(location['y'] + size['height'])
captcha_screenshot = Image.open('screenshot.png').crop((left, top, right, bottom))
print(left)
print(top)
print(location)
print(bottom)
# 保存裁剪后的验证码图片,并进行识别
captcha_screenshot.save('captcha.png')
with open('captcha.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print('识别的验证码是:' + res)La idea básica es que no tiene nada de malo. De hecho, puede obtener capturas de pantalla de la interfaz correspondiente, pero hay una ligera desviación en la ubicación del código de verificación, lo que hace que el código de verificación no se reconozca correctamente.
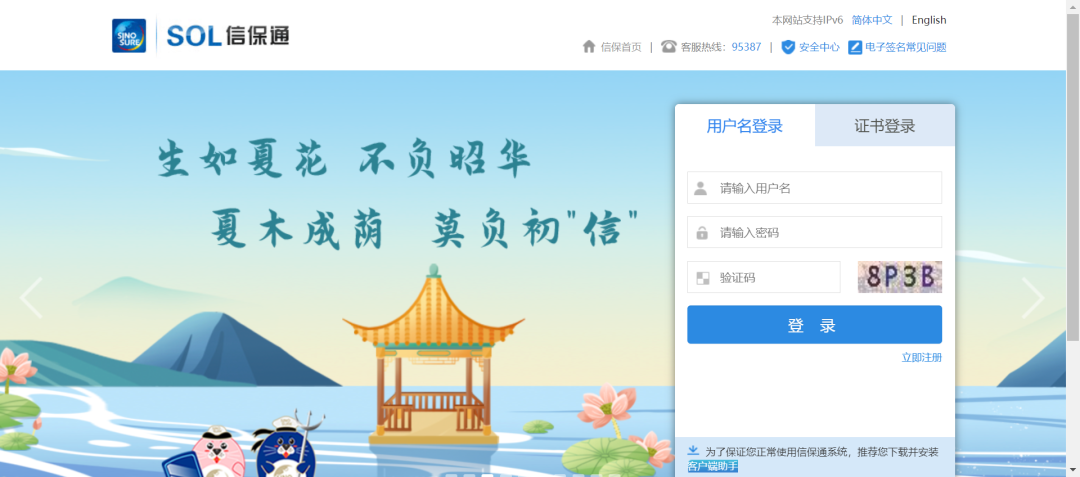
El siguiente código es para obtener la posición y el tamaño del elemento de imagen captcha:
location = captcha_element.location
size = captcha_element.sizeEn esta parte, creo que la introducción debería devolver la posición del elemento posicionado. Simplemente arrastré la posición antes de recortarla e imprimirla, y de hecho se ha ido a la posición cerca de la contraseña de entrada, pero el elemento que posicioné es el lugar donde está el código de verificación, y también traté de ubicar y verificar el elemento grande en esa ubicación primero, y luego ubicar la ubicación específica de la imagen del código de verificación, y el problema aún persiste.
Las anteriores son las dudas de los fanáticos, echemos un vistazo a las soluciones.
2. Proceso de implementación
Aquí [el hermano Wei] probó el siguiente código, pero ocurrió el siguiente error:
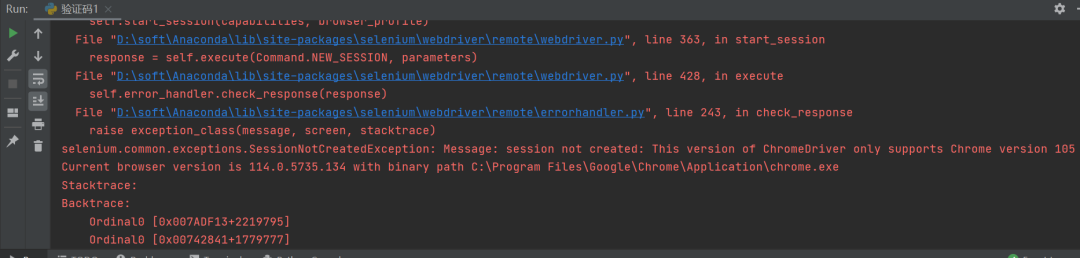
Este informe de error es bastante común. Para aquellos que usan a menudo sel, este informe de error es común. El motivo del informe de error es que el controlador del navegador local no coincide con la versión de Google Chrome, y el controlador del navegador local debe ser reemplazado. .
La solución a este problema es ir a la página web para descargar el controlador correspondiente de la versión del navegador correspondiente, colocarlo en una carpeta local específica y asegurarse de que la ruta de la carpeta se agregue a la variable de entorno. La solución a este problema también se menciona en el artículo oficial del historial de la cuenta, y hay muchos tutoriales de solución en Internet, por lo que no los repetiré aquí.
Más cerca de casa, seguir para volver a la solución a este problema. Aquí [Classmate Ning] dio una idea, busque directamente la URL de la imagen del código de verificación, use solicitudes para solicitar el .content del código de verificación y use ocr.classification (.content del código de verificación). No es necesario guardar la imagen y leer el flujo binario en abierto. El código se ve así:
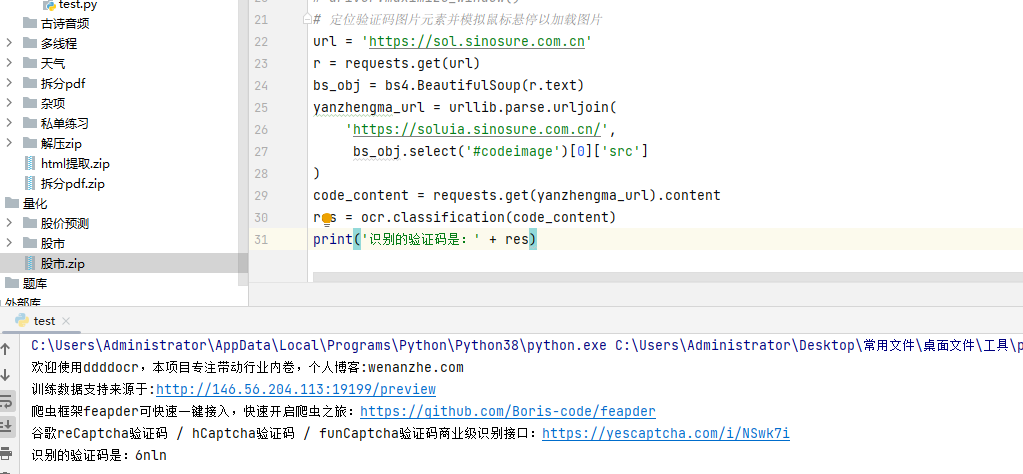
Resolvió con éxito el problema de los fanáticos. Si no está familiarizado con las solicitudes y Beautiful, puede ser más difícil de aceptar.
Este es solo uno de los métodos, otro método, leamos juntos el próximo artículo, ¡así que estad atentos!
3. Resumen
Hola a todos, soy Pippi. Este artículo analiza principalmente Pythonel problema de un rastreador web que pasa códigos de verificación. Apuntando a este problema, el artículo brinda un análisis específico y la implementación del código para ayudar a los fanáticos a resolver el problema sin problemas.
Finalmente, me gustaría agradecer a los fanáticos [鶏啊鶏] por hacer preguntas, agradecer a [Classmate Ning] y [Brother Wei] por sus ideas y análisis de código, y agradecer a [Ineverleft] y a otros por participar en el intercambio de aprendizaje.
[Preguntas complementarias] Cálido recordatorio, cuando haga preguntas en el grupo. Puede prestar atención a los siguientes puntos: si se trata de datos de archivos grandes, puede insensibilizar los datos, enviar algunos datos de demostración (es decir, archivos pequeños) y luego pegar algún código (del tipo que se puede copiar) y recordar enviar la captura de pantalla del informe de error (corte completo). Si no hay muchos códigos, simplemente envíe el texto del código directamente.Si el código supera las 50 líneas, simplemente envíe un archivo .py.

Si tiene algún problema durante el proceso de aprendizaje, no dude en ponerse en contacto conmigo para resolverlo (mi WeChat: pdcfighting1).A pedido de los fanáticos, he creado algunos grupos de intercambio de aprendizaje pagados de Python de alta calidad y grupos de recepción de pedidos pagados. ¡Bienvenidos a todos a unirse al grupo de intercambio de aprendizaje de Python y al grupo de recepción de pedidos!

¡Amigos, apúrense y practíquenlo! Si encuentra algún problema durante el proceso de aprendizaje, agrégueme como amigo y lo llevaré al grupo de intercambio de aprendizaje de Python para discutir el aprendizaje juntos.

--- -- --- --- --- -- --- Fin --- -- --- -- --- --- -- -
Recomendaciones para artículos maravillosos pasados:

Bienvenidos a todos a dar me gusta, dejar un mensaje, reenviar, volver a publicar, gracias por su compañía y apoyo
Si desea unirse al grupo de aprendizaje de Python, responda en segundo plano [ únase al grupo ]
Miles de ríos y miles de montañas siempre están enamorados, puedes hacer clic en [ Buscando ]
/Tema del mensaje de hoy/
Solo di unas pocas palabras~~