CTR serie de notas de estudio primer artículo, resumió el LR clásico, FM, modelo FFM antes de que el modelo de profundidad rey, estos modelos clásicos, sino también como un componente del modelo de seguimiento para cada profundidad. La costumbre Keras modelo de capa y estimador de ser implementadas, ja uno es viejo amor un nuevo amor. características de ingeniería dependen dan cuenta feature_column, es relativamente simple de hacer aquí en la parte de atrás de nuevo, para participar en el modelo de profundidad. El código completo aquí https://github.com/DSXiangLi/CTR
Definición del problema
CTR es esencialmente un problema de clasificación binaria, $ X \ in R ^ N $ es un usuario y características relacionados con la publicidad, \ (la Y- \ in (0, 1) \) es si se hace clic en cada anuncio, el modelo de base es un simple Logística regresión
\ [P (Y =. 1) = \ {FRAC. 1 exp {} {1+ (W 0 + \ sum_ {I} = ^ Nw_ix_i. 1)}} \]
Después de considerar la logística marco TF puede ser simplemente expresada por activación, hemos simplificado la porción de núcleo es menor
\ [y (x) = w_0 + \ sum_ {i = 1} ^ Nw_ix_i \]

modelo de RL
2010 modelo convencional CTR es generalmente el más fácil de regresión logística, el modelo de interpretabilidad fuerte, rápido y fácil de implementar en el proyecto. Pero el mayor problema depende de un montón de características trabajos manuales.
Los estudiantes nuevos a las características del proyecto pueden preguntarse por qué es necesario calcular una combinación de características?
Al principio simplemente que cuanto menor sea el más fino características agregadas Bias. Después de contacto con el razonamiento causal, creo que es más adecuado para Simpson Paradox en el sesgo Confusor de explicar, la polimerización puede ser ruidosa entre las diferentes funciones, como clics hombres de todas las edades fueron inferiores a las mujeres, pero CTR general de los hombres las mujeres. Interesados pueden leer este blog razonamiento causal de la secuencia de la primavera de serie - Minería de datos de confusión, Collidar, Mediación Bias
Si es decir, para simplificar las funciones de ingeniería, y combinaciones de características que desee unirse, sin duda pensar en la violencia siguientes características combinaciones. Este modelo poly2 también denominado
\ [y (x) = w_0 + \ sum_ {i = 1} ^ N w_ix_i + \ sum_ {i = 1} ^ N \ sum_ {j = i + 1} ^ N w_ {i , j} x_ix_j \]
Sin embargo, lo anterior \ (w_ {i, j} \) necesidad de aprender \ (\ frac {n (n -1)} {2} \) parámetros, en la alta complejidad por un lado, en el otro lado que aparezca Funcion dispersos de alta dimensión grande \ (w_ {i, j} \) es 0, el modelo no puede aprender las muestras de características no se encontraron en el patrón de combinación, pobre modelo de generalización.
Por lo tanto reducir la complejidad, la selección automática de combinaciones eficaces de características, y un modelo de generalización se convierte en tres períodos sucesivos de dirección principal mejora.
modelo GBDT + LR
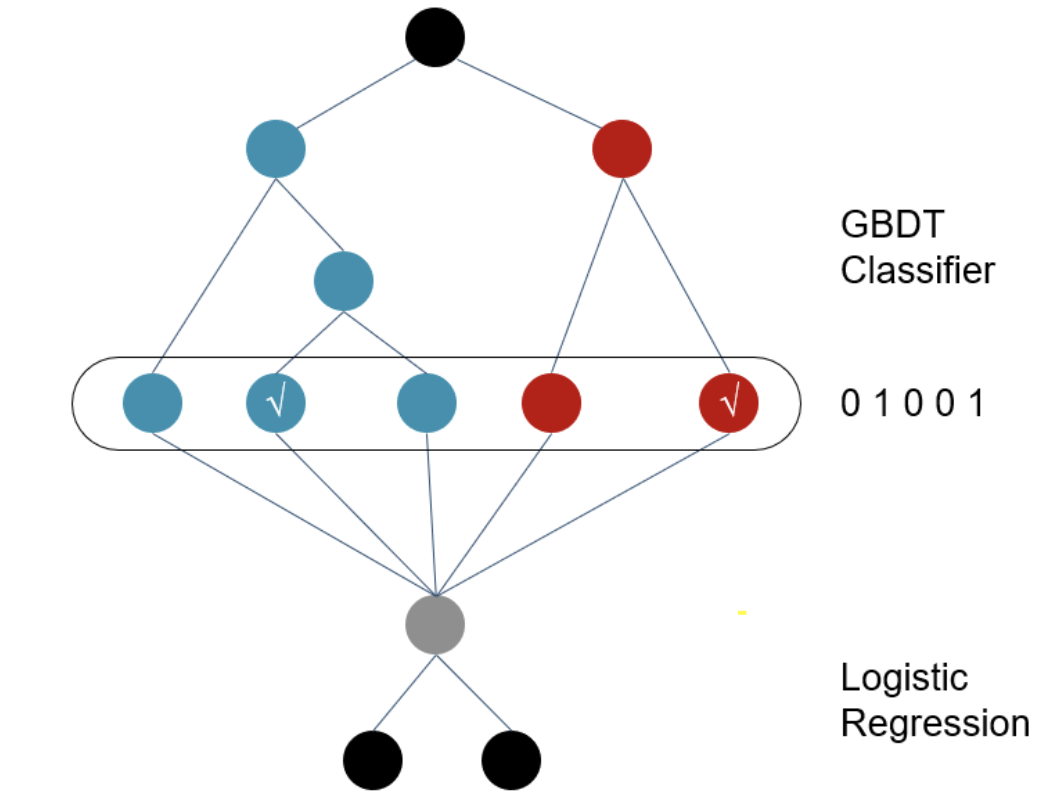
2014 propone un método en el GBDT Facebook superposición de LR, golpeando función de modelado funciona la puerta. GBDT no predice la probabilidad de salida, pero cada muestra cae en una matriz 0/1 cada uno de los cuales un subárbol nodos hoja. Si bien dejando sólo el objetivo y un eficaz combinaciones de características relevantes, evitando el coste de hacer negocio y apreciado que la combinación de características necesarias manual.
En comparación con combinaciones de características, prefiero GBDT salida vector de características, entendida como objetivo, el agrupamiento de muestras / reducción de la dimensión, la salida es una combinación de varios grupos específicos de la muestra pertenece, cada una corresponde a un subárbol tipos de personas combinan.
Pero! GBDT problema generalización todavía existe, porque la elección de todos los nodos de hoja dependen de muestras de entrenamiento, y GBDT en las características discretas efecto más limitado. También existe el problema a través de características GBDT transformar las características todavía dispersos de alta dimensión.
modelo FM
2010 Rendall propuso factorización modelo de máquina (FM) para reducir la complejidad computacional, a fin de aumentar el modelo de generalización proporciona una pauta
principio
modelo FM por encima de combinación violencia de características resolver directamente la totalidad de los momentos ponderados \ (w_ij \ en R & lt ^ {N * N} \) , vector implícita transformado en la resolución de la matriz de peso \ (V \ en R & lt ^ {N * K} \) , este paso aumentaría enormemente la capacidad de modelar la generalización, debido a que la matriz de peso ya no es totalmente dependiente de la combinación particular de características en la muestra, pero se puede obtener a través de correlación indirecta entre características. Al mismo tiempo el número de parámetros de vectores implícita en el modelo de aprender de la \ (\ frac {n (n -1)} {2} \) se reduce a \ (NK \) un
\ [\ begin {align} y (x) & = w_0 + \ sum_ {i = 1} ^ Nw_i x_i + \ sum_ {i = 1} ^ N \ sum_ {j = i + 1} ^ N w_ {i, j} x_ix_j \\ & = w_0 + \ sum_ {i = 1} ^ Nw_i x_i + \ sum_
{i = 1} ^ N \ sum_ {j = i + 1} ^ N <v_i, v_j> x_ix_j \\ \ end {align} \] mientras que el siguiente truco FM, la propuesta de la complejidad computacional del proceso desde el acoplamiento (O (n ^ 2k) \ ) \ reduce a complejidad lineal \ (O (nk) \)
\ [\ Begin {align} & \ sum_ {i = 1} ^ N \ sum_ {j = i + 1} ^ N <v_i, v_j> x_ix_j \\ = & \ frac {1} {2} (\ sum_ { i = 1} ^ N \ sum_ {j = 1} ^ N <v_i, v_j> x_ix_j - \ sum_ {i = 1} ^ N <v_i, v_i> x_ix_i) \\ = & \ frac {1} {2} (\ sum_ {i = 1} ^ N \ sum_ {j = 1} ^ N \ sum_ {f = 1} ^ K v_ {if} v_ {jf} x_ix_j - \ sum_ {i = 1} ^ N \ sum_ { f = 1} ^ Kv_ {if} ^ 2x_i ^ 2) \\ = & \ frac {1} {2} \ sum_ {f = 1} ^ K (\ sum_ {i = 1} ^ N \ sum_ {j = 1} ^ v_ N {if} v_ {jf} x_ix_j - \ sum_ {i = 1} ^ Nv_ {if} ^ 2x_i ^ 2) \\ = & \ frac {1} {2} \ sum_ {f = 1} ^ K ((\ sum_ {i = 1} ^ N v_ {ij} x_i) ^ 2 - \ sum_ {i = 1} ^ Nv_ {if} ^ 2x_i ^ 2) \\ = & \ text {square_of_sum} - \ sum_of_square texto {} \ end {align} \]
la implementación del código - Capa personalizada Keras
class FM_Layer(Layer):
"""
Input:
factor_dim: latent vector size
input_shape: raw feature size
activation
output:
FM layer output
"""
def __init__(self, factor_dim, activation = None, **kwargs):
self.factor_dim = factor_dim
self.activation = activations.get(activation) # if None return linear, else return function of identifier
self.InputSepc = InputSpec(ndim=2) # Specifies input layer attribute. one Inspec for each input
super(FM_Layer,self).__init__(**kwargs)
def build(self, input_shape):
"""
input:
tuple of input_shape
output:
w: linear weight
v: latent vector
b: linear Bias
func:
define all the necessary variable here
"""
assert len(input_shape) >=2
input_dim = int(input_shape[-1])
self.w = self.add_weight(name = 'w0', shape = (input_dim, 1),
initializer = 'glorot_uniform',
trainable = True)
self.b = self.add_weight(name = 'bias', shape = (1, ),
initializer = 'zeros',
trainable = True)
self.v = self.add_weight(name = 'hidden_vector', shape = (input_dim, self.factor_dim),
initializer = 'glorot_uniform',
trainable = True)
super(FM_Layer, self).build(input_shape)# set self.built=True
def call(self, x):
"""
input:
x(previous layer output)
output:
core calculation of the FM layer
func:
core calculcation of layer goes here
"""
linear_term = K.dot(x, self.w) + self.b
# Embedding之和,Embedding内积: (1, input_dim) * (input_dim, factor_dim) = (1, factor_dim)
sum_square = K.pow(K.dot(x, self.v),2)
square_sum = K.dot(K.pow(x, 2), K.pow(self.v, 2))
# (1, factor_dim) -> (1)
quad_term = K.mean( (sum_square - square_sum), axis=1, keepdims = True) #
output = self.activation((linear_term+quad_term))
return output
def compute_output_shape(self, input_shape):
# tf.keras回传input_shape是tf.dimension而不是tuple, 所以要cast成int
return (int(input_shape[0]), self.output_dim)
La relación entre FM y MF
Factorizaton de máquinas y factorización de la matriz suena, MF es de hecho un caso especial de FM. MF se obtiene mediante la factorización de la matriz para obtener el vector implícita, pero ya que sólo se aplica a una matriz caracterizado porque solamente una de dos dimensiones, es común (user_id, item_id) combinaciones de los mismos. Lo mismo vector implícita, FM aplanar la matriz de características discretas hacer de una sola caliente, y por lo tanto compatible con cualquier número de entidades de entrada.

La relación entre la FM e incrustación
Embedding NLP más común en la palabra característica de alta dimensional escasa mapeado hasta integración de la matriz de bajo dimensional después se trató con una función de interfuncionamiento, por ejemplo, al producto del vector representa el grado de similitud entre las palabras y de palabras. FM implícitamente vectores son en realidad calculan incrustación también un método de ajuste y límites sólo como un producto interno de vectores de la función de interacción. Por encima de \ (X * V \ in R ^ {K} \) obtenido es vectores de incrustación mismos.
FFM
FFM modelo propuesto en 2015 se unió al campo sobre la base de la FM conceptual
principio
El FM descrito anteriormente aprendió matriz de ponderación V es un implícito que corresponde a cada vector de características para expresar una combinación de dos características en la forma de vector implícita producto interior. Propuesta de una FFM con diferentes características y combinaciones de características de campo de vector implícita debe tener diferente, así \ (V \ in R ^ { N * K} \) se convierte en \ (V \ in R ^ { N * F * K} \ ) donde F es el número de características pertenece campo. El siguiente país de datos, de datos, el tipo de anuncio es Field, \ ((F. =. 3) \)

FM porciones interactivas de los dos características se reescribe o menos, el número de parámetros que aprender de n- K se convierte en n- F * K. Y no se puede utilizar en la complejidad truco descrito anteriormente de la conexión al proceso y por lo tanto de la FM \ (O (nk) \) se eleva a \ (O (KN ^ 2) \) .
\ [\ Begin {align} \ sum_ {i = 1} ^ N \ sum_ {j = i + 1} ^ N <v_i, v_j> x_ix_j \ a & \ sum_ {i = 1} ^ N \ sum_ {j = i + 1} ^ N <v_ {i, f_j}, v_ {j, f_i}> x_ix_j \ end {align} \]
la implementación del código - model_fn personalizada
def model_fn(features, labels, mode, params):
"""
Field_aware factorization machine for 2 classes classification
"""
feature_columns, field_dict = build_features()
field_dim = len(np.unique(list(field_dict.values())))
input = tf.feature_column.input_layer(features, feature_columns)
input_dim = input.get_shape().as_list()[-1]
with tf.variable_scope('linear'):
init = tf.random_normal( shape = (input_dim,2) )
w = tf.get_variable('w', dtype = tf.float32, initializer = init, validate_shape = False)
b = tf.get_variable('b', shape = [2], dtype= tf.float32)
linear_term = tf.add(tf.matmul(input,w), b)
tf.summary.histogram( 'linear_term', linear_term )
with tf.variable_scope('field_aware_interaction'):
init = tf.truncated_normal(shape = (input_dim, field_dim, params['factor_dim']))
v = tf.get_variable('v', dtype = tf.float32, initializer = init, validate_shape = False)
interaction_term = tf.constant(0, dtype =tf.float32)
# iterate over all the combination of features
for i in range(input_dim):
for j in range(i+1, input_dim):
interaction_term += tf.multiply(
tf.reduce_mean(tf.multiply(v[i, field_dict[j],: ], v[j, field_dict[i],:])) ,
tf.multiply(input[:,i], input[:,j])
)
interaction_term = tf.reshape(interaction_term, [-1,1])
tf.summary.histogram('interaction_term', interaction_term)
with tf.variable_scope('output'):
y = tf.math.add(interaction_term, linear_term)
tf.summary.histogram( 'output', y )
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'predict_class': tf.argmax(tf.nn.softmax(y), axis=1),
'prediction_prob': tf.nn.softmax(y)
}
return tf.estimator.EstimatorSpec(mode = tf.estimator.ModeKeys.PREDICT,
predictions = predictions)
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( labels=labels, logits=y ))
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.AdamOptimizer(learning_rate = params['learning_rate'])
train_op = optimizer.minimize(cross_entropy,
global_step = tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss = cross_entropy, train_op = train_op)
else:
eval_metric_ops = {
'accuracy': tf.metrics.accuracy(labels = labels,
predictions = tf.argmax(tf.nn.softmax(y), axis=1)),
'auc': tf.metrics.auc(labels = labels ,
predictions = tf.nn.softmax(y)[:,1]),
'pr': tf.metrics.auc(labels = labels,
predictions = tf.nn.softmax(y)[:,1],
curve = 'PR')
}
return tf.estimator.EstimatorSpec(mode, loss = cross_entropy, eval_metric_ops = eval_metric_ops)
material de referencia
- S. Rendle, “máquinas Factorización”, en Actas de la IEEE Conferencia Internacional sobre Minería de Datos (ICDM), pp. 995-1000, 2010
- Yuchin Juan, Yong Zhuang, Wei Sheng-Chin, Campo-conscientes Máquinas factorización de Predicción CTR.
- estudio en profundidad de inventario antes de la era de Ali, Google, modelo de predicción CTR de Facebook
- Evolución de la carretera antes de que el modelo de predicción CTR de aprendizaje profundo de los tiempos: desde LR a FFM
- sistema recomendado de recuerdo cuatro modelos: todo poderoso modelo FM
- modelos convencionales comparativos y la evolución estimada CTR
- Profundidad Principios y Práctica FFM