Hoy en día, tenemos principalmente para resolver el siguiente problema: una lista negra de los datos almacenados en Excel, debido a la gran cantidad de datos, los datos duplicados ahora tenemos que encontrar una columna de osos panda, los procesa y se almacena para sobresalir en.
pandas NumPy es una herramienta, la herramienta para resolver tareas de análisis de datos creado en base a dos clases principales estructuras de datos:
trama de datos: se puede entender como una mesa, similar a las tablas de Excel pandas.core.frame.DataFrame
Serie: representa una sola columna. Trama de datos contiene varias columnas, es decir, varias series, cada serie tiene un nombre. pandas.core.series.Series
Tipo de datos (dtype) pandas apoyado:
1. un flotador (float64)
2. int (Int64, UInt64)
3. BOOL
4. datetime64 [NS] (01/02/2013)
5. El datetime64 [NS, TZ]
6.. timedelta [NS]
7. la categoría
8. el objeto (cadena)
el tipo de datos predeterminado es Int64, float64
El siguiente es el archivo de Excel original

Para ver los archivos en el tipo de datos de cada columna de la serie
import pandas as pd
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx')
change_data_type()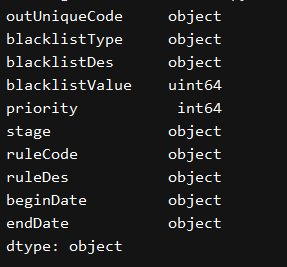
Encontramos por defecto blacklistValue es de tipo int, pero sabemos que la tarjeta de identidad 18, cuando se almacena detrás de varios Excel vuelve a ser 0, por lo que necesitamos para convertir tipos de datos de estas columnas. Hay dos ideas, uno está leyendo conversión de Excel, otra lectura después de la conversión.
En primer lugar, leídas por todos los convierte en una cadena, dtype = 'objeto' o dtype = 'str'
import pandas as pd
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx',dtype='object') # dtype='str'
change_data_type()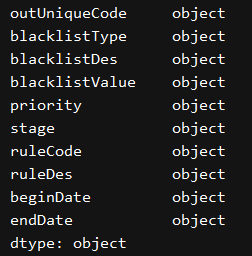
En segundo lugar, la columna designada se convierte en una cadena, objeto o str lectura
# 更改数据类型
def change_data_type():
print(excel_df.dtypes)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx',dtype = {'blacklistValue' : object,'priority':str}) # dtype='str'
change_data_type()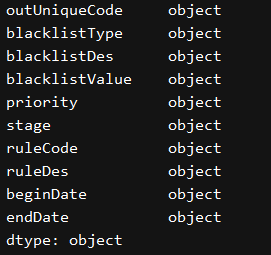
En tercer lugar, después de la lectura se convierte en una cadena: astype (str), no usar astype (objeto) -> a Excel cuando se almacena o int.
import pandas as pd
# 更改数据类型
def change_data_type():
excel_df[['blacklistValue','priority']] = excel_df[['blacklistValue','priority']].astype(str)
print(excel_df.dtypes)
excel_df.to_excel('excel_to_python.xls',sheet_name='sheet', index=False)
if __name__ == '__main__':
excel_df = pd.read_excel('E:\zenglingwei\\test\\5.xlsx') # dtype='str'
change_data_type()
