Creo que después de leer un blog anterior "se lleva a reconocer rápidamente NamenodeHA e hilado de HA, a sentar las bases para la construcción de racimo HadoopHA!" Después, hay que respetar muchas ganas de cómo construir HA grupo 9 (1❛ᴗ❛1) 6 No se asuste, esto entrada en el blog traerá un tutorial detallado para construir clúster de alta disponibilidad para todo el mundo!
La palabra en clave no es fácil, alabar después de la primera mirada!

Directorio artículo
- Construir Hadoop HA Cluster
- <1> configuración de la instalación de clúster Hadoop
- ① clúster de reserva
- ② extraer el nuevo clúster
- ③ Configuración HDFS
- ④ modificar el núcleo-site.xml
- ⑤ modificación hdfs-site.xml
- ⑦ modificar mapred-site.xml
- ⑧ hilo site.xml modificado
- ⑨ modificar esclavos
- ⑩ libre configuración densa Login
- <2> para iniciar el proceso de
- ① comenzar cúmulo empleado del zoológico
- ② iniciar manualmente journalnode
- ③ NameNode formatear
- ④ formato ZKFC (se puede realizar en el activo)
- ⑤ comenzar HDFS (ejecutado en node01)
- ⑥ comenzar HILO
- <3> Acceso Browser
- <4> ampliar
Construir Hadoop HA Cluster
consejos
Todas las siguientes operaciones se llevan a cabo allí, sobre la base de un cluster Hadoop . Le recomendamos que instale por primera vez los amigos de racimo para ver este blog "Hadoop (CDH) para construir un entorno distribuido" , para construir un clúster normales disponibles, vistazo a este blog "empleado del zoológico detallada de instalación" instalado en el clúster y luego mirar el Zookeeper esta avanzada blog.
<1> configuración de la instalación de clúster Hadoop
① clúster de reserva
Debido a que ya había construido un grupo bueno, por lo que necesitamos antes de la primera hadoop grupo cerrado .
stop-all.sh
Entonces directorio hadoop donde la copia de seguridad anterior (tres nodos)
cd /export/servers/
mv mv hadoop-2.6.0-cdh5.14.0 hadoop-2.6.0-cdh5.14.0_bk
② extraer el nuevo clúster
Hadoop en el directorio en el que el paquete de instalación, re-extracción.
cd /export/softwares/
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz -C ../servers/
③ Configuración HDFS
Tenga en cuenta que, hadoop2.0 todos los archivos de configuración se encuentran en el hadoop $ HADOOP_HOME / etc / directorio
Este paso se supone que debe hacer operaciones como la adición de algunas de las variables de entorno del sistema, sino porque estamos ante el cluster se ha completado estas operaciones, por lo que este paso se puede omitir el contenido - es por eso que te recomiendo primero buena razón para construir un clúster.
④ modificar el núcleo-site.xml
En el directorio especificado:
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
Editar núcleo-site.xml, agregar la siguiente configuración
vim core-site.xml
<configuration>
<!-- 集群名称在这里指定!该值来自于hdfs-site.xml中的配置 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<!-- 这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/HAhadoopDatas/tmp</value>
</property>
<!-- ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
</configuration>
⑤ modificación hdfs-site.xml
vim hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为cluster1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<!-- cluster1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1</name>
<value>node01:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nn1</name>
<value>node01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2</name>
<value>node02:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nn2</name>
<value>node02:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/cluster1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定该集群出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
⑦ modificar mapred-site.xml
Una primera copia de seguridad
cp mapred-site.xml.template mapred-site.xml
Editar mapred-site.xml, añada la siguiente
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑧ hilo site.xml modificado
Modificar hilo site.xml, añada la siguiente:
vim yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node02</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
⑨ modificar esclavos
vim slaves
node01
node02
node03
Copiar el software en todos los nodos
Aquí comando scp es, por supuesto, xsyncpero posible -
scp -r hadoop-2.6.0-cdh5.14.0 node02:/$PWD
scp -r hadoop-2.6.0-cdh5.14.0 node03:/$PWD
⑩ libre configuración densa Login
Debe estar en el nodo en espera densa libre de configuración conectado, pero ya que cuando instalamos el clúster original se ha configurado, por lo que este paso se puede omitir ~
# En primer lugar, configure node01 a node01, node02, node03 los sin contraseña de inicio de sesión
# producen un par de teclas en node01
SSH-keygen
# copiar la clave pública a otros nodos, incluido el propio
SSH-coyp el mencionado Identificación node01
SSH-coyp-lo anterior Identificación del mencionado node02
SSH node03 lo anterior Identificación del mencionado - coyp
# Nota: entre dos NameNode a configurar ssh ssh el cuchillo cuando sea necesario sin contraseña de inicio de sesión remoto
# node02 en la producción de un par de claves
keygen-ssh
# copiar la clave pública a node01
ssh-coyp-la node01 mencionado de id
<2> para iniciar el proceso de
En estricta conformidad con el siguiente procedimiento, o no podemos garantizar el éxito
① comenzar cúmulo empleado del zoológico
Comience empleado del zoológico, respectivamente, en node01, node02, nodo node03
bin/zkServer.sh start
#查看状态:一个leader,两个follower
bin/zkServer.sh status
② iniciar manualmente journalnode
Respectivamente ejecutado el node01, node02, node03
hadoop-daemon.sh start journalnode
#运行jps命令检验,node01、node02、node03上多了JournalNode进程
③ NameNode formatear
#在node01上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置的目录下生成个hdfs初始化文件,
hadoop.tmp.dir配置的目录下所有文件拷贝到另一台namenode节点所在的机器
scp -r tmp/ node02:/home/hadoop/app/hadoop-2.6.4/
④ formato ZKFC (se puede realizar en el activo)
hdfs zkfc -formatZK
⑤ comenzar HDFS (ejecutado en node01)
start-dfs.sh
⑥ comenzar HILO
start-yarn.sh
还需要手动在standby上手动启动备份的 resourcemanager
yarn-daemon.sh start resourcemanager
<3> Acceso Browser
Después de configurar la anterior, con una jpsvista del proceso actual
[root@node01 helloworld]# jps
14305 QuorumPeerMain
15186 NodeManager
14354 JournalNode
14726 DataNode
20887 Jps
15096 ResourceManager
15658 NameNode
14991 DFSZKFailoverController
Por último se puede acceder al explorador -
node01 acceso
http://node01:50070
Se puede encontrar en el estado actual de la NameNode nodoActive
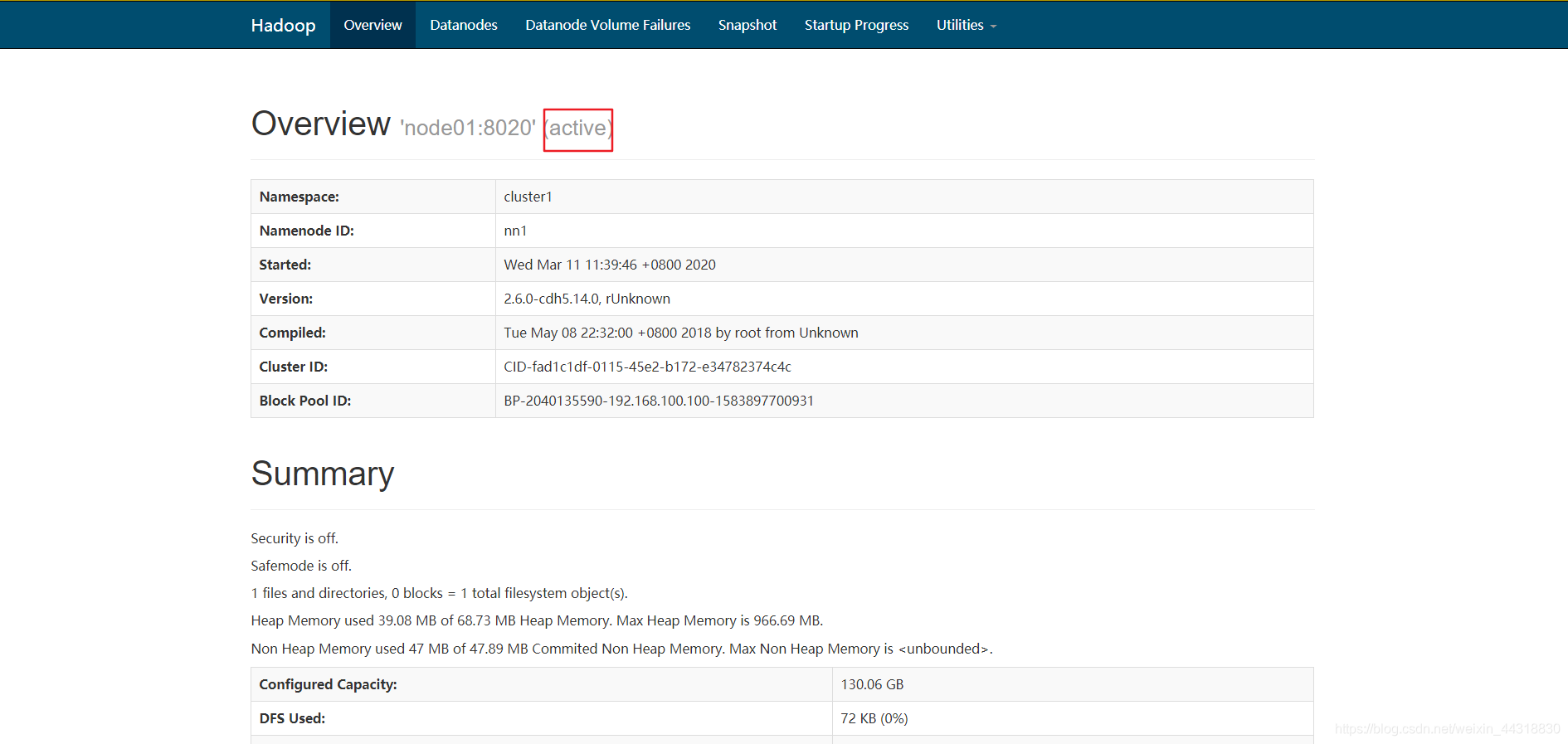
node02 acceso
http://node02:50070
Se puede encontrar en el estado actual de la NameNode nodo para (standby)
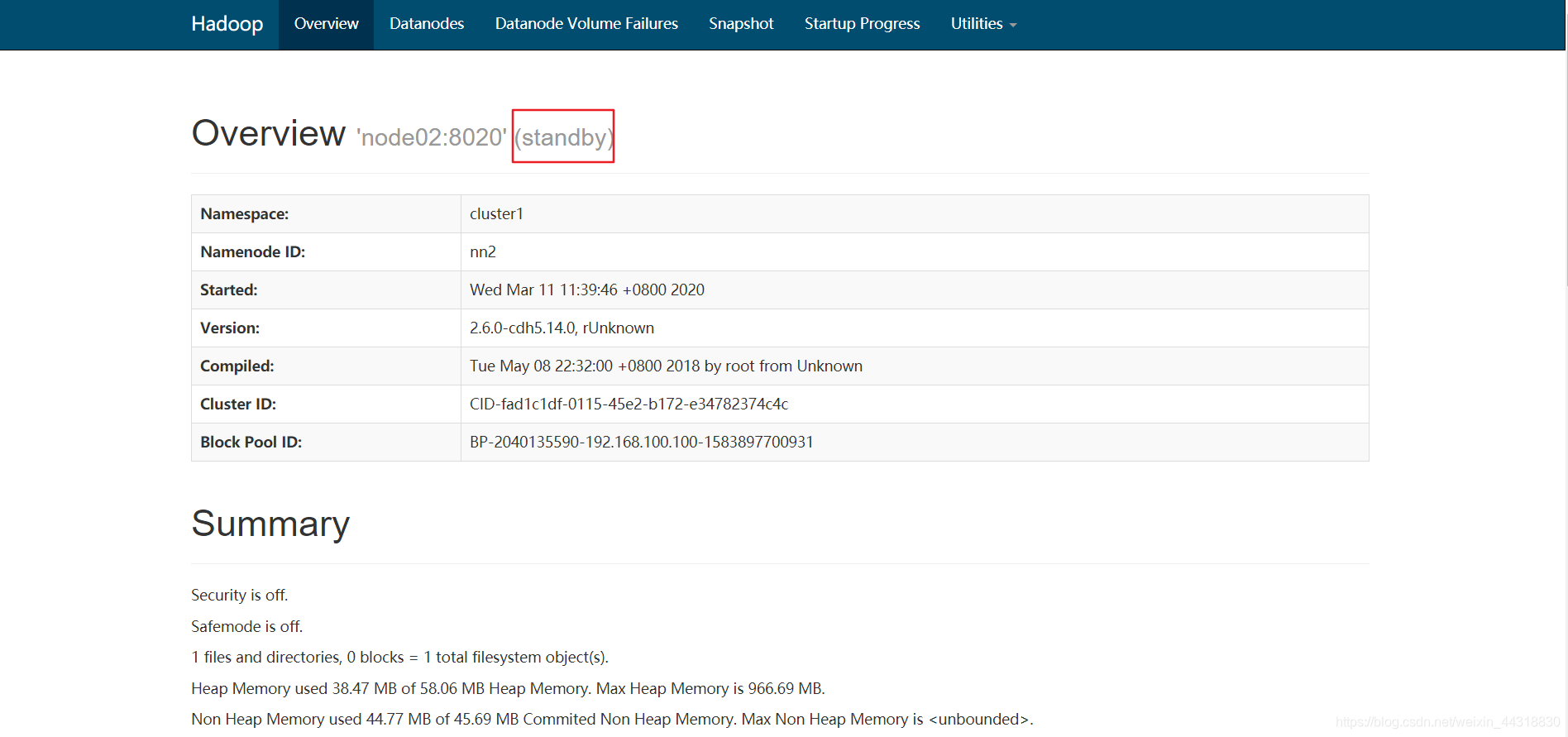
ilustrar el despliegue de nuestro éxito clúster HA ~
A continuación se carga un archivo en hdfs
hadoop fs -put /etc/profile /profile
A través de la interfaz de la interfaz de usuario se puede ver la nueva carga de archivos se van a plantear
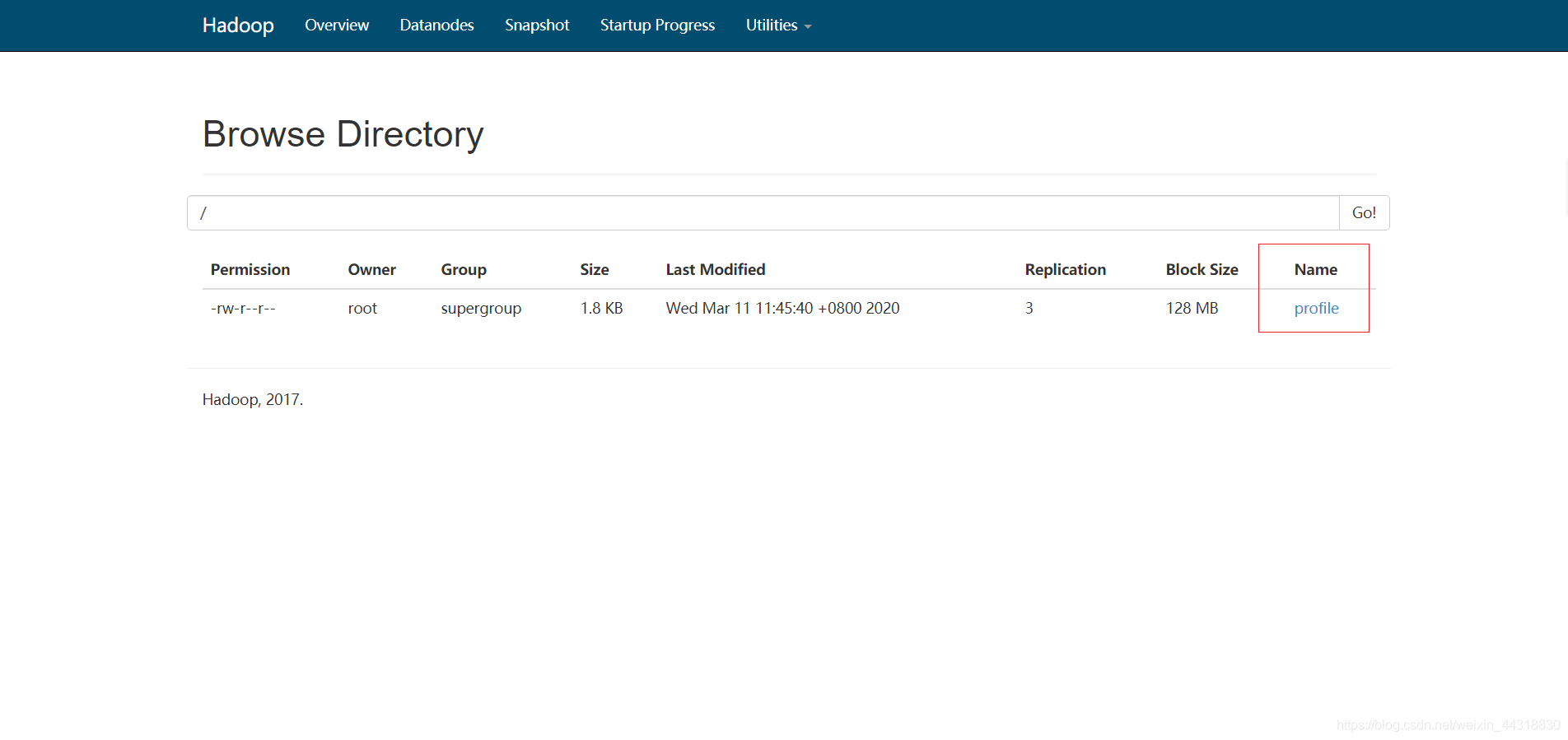
Y luego acabar con el estado de los ganglios activo (es decir node01) de NameNode
kill -9 <pid of NN>
Esta vez la visita de navegador node02
http://node02:50070
Después del descubrimiento node01 "hacia abajo", NameNode node02 en el Activeestado!
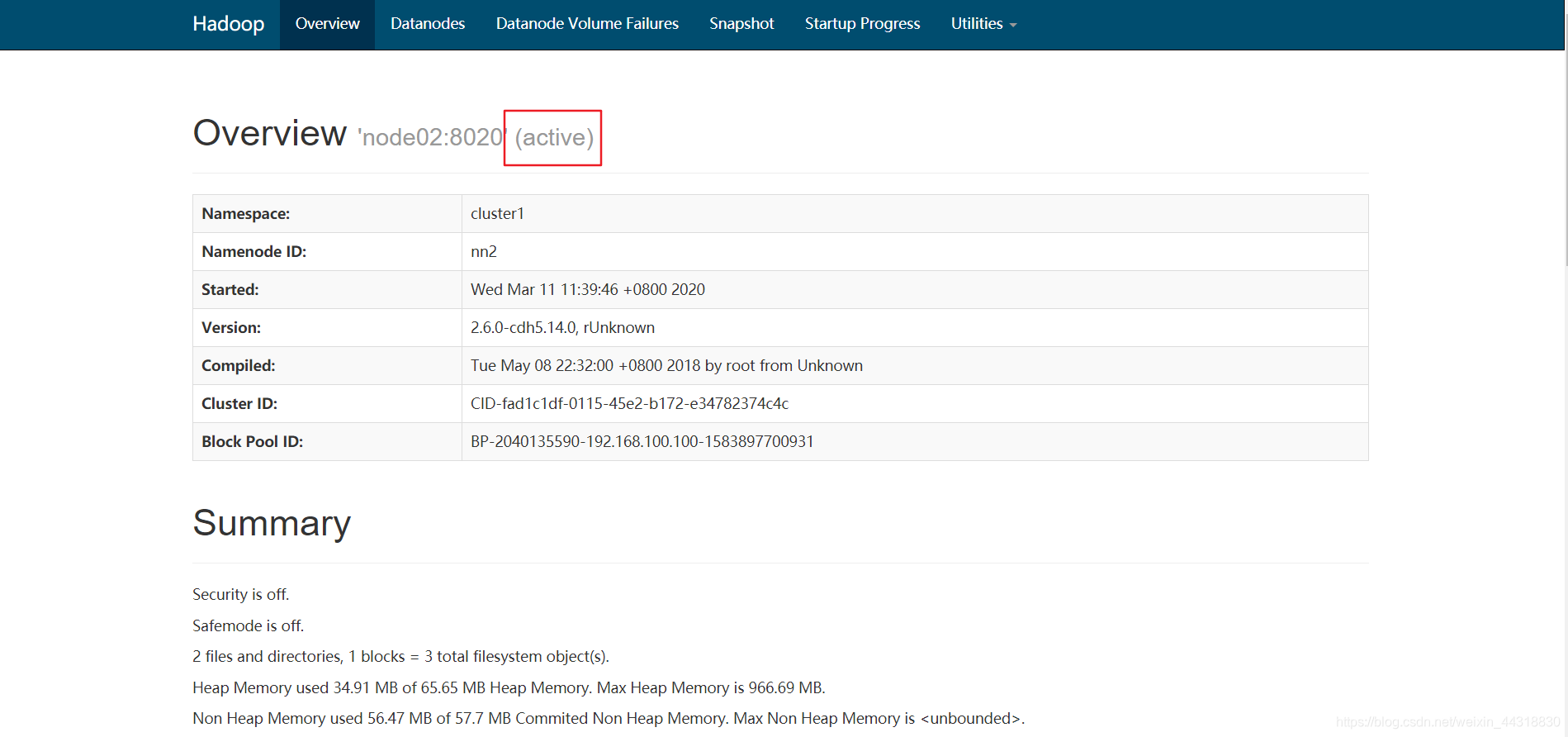
Ejecutar el siguiente comando en el nodo node02, los datos se pueden encontrar en racimos con el ex node01 tiempo de inactividad es el mismo.
hadoop fs -ls /
-rw-r--r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
Acabamos de forma manual "matar" NameNode en el nodo node01, y ahora empezamos de forma manual.
hadoop-daemon.sh start namenode
Frente verificar la HA, y ahora esperamos para autenticar hilado!
nodo arbitrario, ejecute el programa de demostración hadoop WordCount se ofrece en:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar wordcount /profile /out
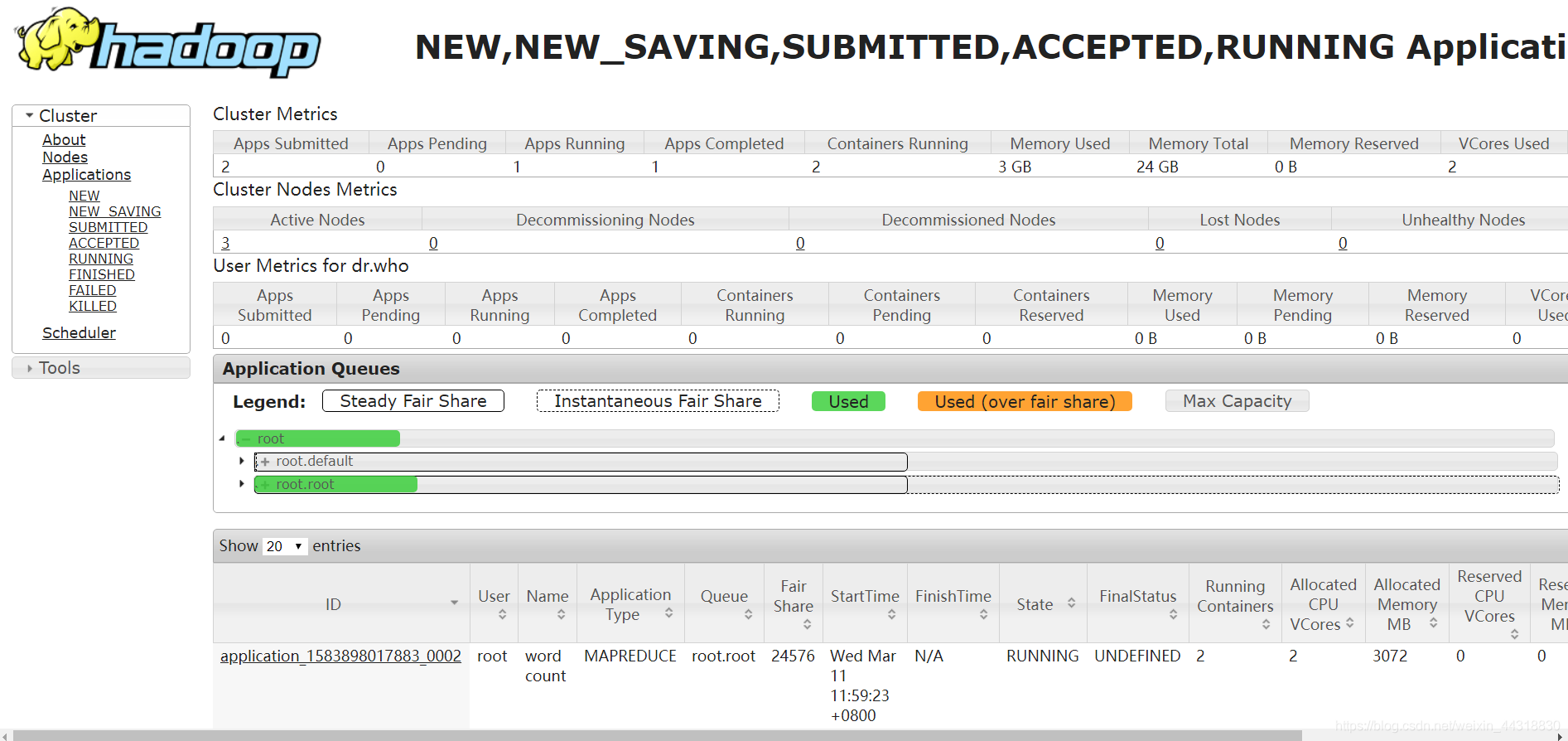
Ver más arriba representaciones, que construimos el clúster HA considerado un éxito !!!
<4> ampliar
Aceptar y ya está! Aquí ampliar alguna prueba de HA de comandos de grupo
hdfs dfsadmin -report 查看hdfs的各节点状态信息
hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
Comparte esta aquí, para beneficio de los socios tecnológicos de datos pequeño o grande y amigos interesados pueden desear bloggers mirada - aprender unos de otros y progresar juntos!

