Resumen EDITORIAL:
1. parámetro recomendado innodb_file_per_table en ON, por lo que una tabla se almacena como un único archivo, mediante el comando tabla de la gota, el sistema eliminará el archivo. Y si está en el espacio de tabla compartida, incluso si la tabla eliminada, el espacio no se recupera
2. Eliminar toda la tabla, puede utilizar el comando drop table para recuperar espacio en la mesa.
3.Borrar comando de recuperación de espacio no sólo la etiqueta reutilizable
4. Eliminar registros de datos y las páginas que se pueden reutilizar el espacio, pero el registro sólo pueden ser reutilizados dentro de un rango específico, y la página de datos ilimitado.
5. vacíos CRUD pueden ocasionar que los datos que deban ser reparados mediante la reconstrucción de la tabla. (5.5 y anteriores versiones no se puede hacer en línea, 5.6 más últimos, que pueden reconstruir [en línea] datos de escritura sin bloquear, pero para mayor seguridad, en línea gh-ost recomendado)
Relaciones 6.Online y inplace de: DDL Si el proceso está en línea, debe ser in-situ de; no necesariamente contraria (por ejemplo, agregar la indización de texto y el espacio de índice)
7. Por último, habló mesa Optimizar, analizar mesa y mesa de alter tres maneras de reconstruir la diferencia mesa
¿Se ha encontrado debido a ocupar demasiado espacio en la base de datos, los datos de tabla se elimina la mitad, pero se encontró que el tamaño del archivo de tabla todavía no se ha cambiado el problema?
En este artículo se habla de la recuperación del espacio de tabla de base de datos para ver cómo resolver este problema.
Discutimos para el motor InnoDB de MySQL más ampliamente utilizado.
la tabla A InnoDB consta de dos partes, a saber: la definición estructura de la tabla y los datos .
En las versiones anteriores de MySQL 8.0, la estructura de la tabla está presente en el sufijo de archivo .frm. Y MySQL versión 8.0, ha permitido definir la estructura de tabla en la tabla de datos del sistema. Debido a que las define la estructura de la tabla del espacio ocupado por pequeñas, por lo que hoy nos ocupa es el principal datos de la tabla.
datos de la tabla se pueden compartir existe espacio de tabla, también puede ser un archivo separado. Este comportamiento se debe a parámetros innodb_file_per_table de control:
1. Este parámetro está establecido en OFF indica que la tabla de datos en un sistema de intercambio de espacio de tabla, es decir, junto con el diccionario de datos;
2. Este parámetro está establecido en ON indica que los datos de cada tabla InnoDB se almacenan en un archivo con la extensión a la .ibd.
A partir de MySQL versión 5.6.6, que es el valor por defecto es ON. (Recomendado independientemente de la versión de MySQL, este valor se establece en ON)
Porque, una tabla se almacena como un archivo separado gestión más fácil por el comando tabla de la gota, el sistema eliminará el archivo. Y si está en el espacio de tabla compartida, incluso si la tabla eliminada, el espacio no se recupera .
La siguiente discusión se basa en esta configurar una implantación.
Se mencionó anteriormente, borrar toda la tabla, puede utilizar el comando drop table al espacio de tablas de recuperación .
Sin embargo, la escena es de datos más borrar filas de borrado, entonces usted tiene un problema al principio: los datos de la tabla se borran, pero el espacio de tabla no se ha recuperado.
proceso de borrado de datos
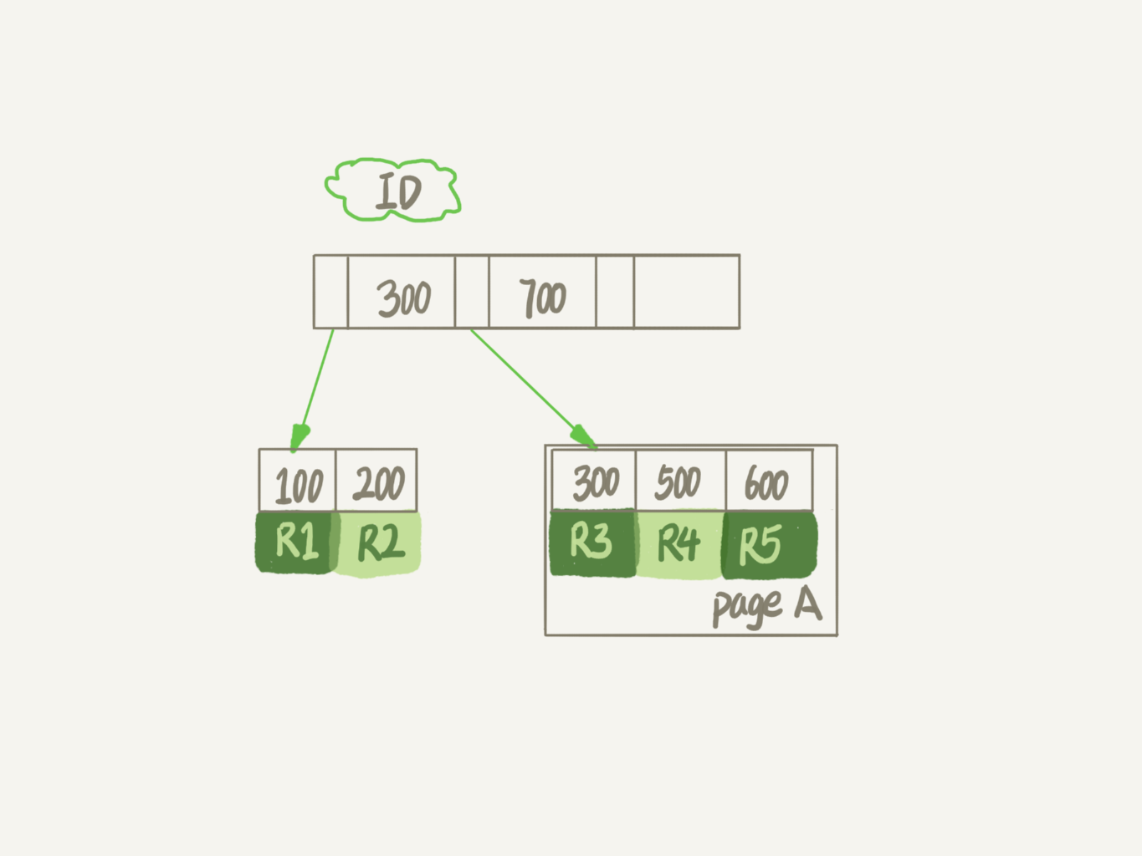
Cuando se desea eliminar este registro motor de R4, R4 InnoDB solamente este registro marcado para su eliminación. Si después de la inserción de un ID, se registra otra vez entre 300 y 600, esta posición puede ser multiplexada. Sin embargo, el tamaño del archivo de disco y no se encogerá.
datos InnoDB es almacenada por la página, si se eliminan todos los registros en una página de datos, una página entera de datos puede ser reutilizada .
Sin embargo, multiplexado con la grabación de las páginas de datos multiplexados es diferente .
Multiplexación de grabación, datos que se ajusten condición limitada gama. En el ejemplo anterior, R4 Después de este registro se suprime, si un ID se inserta en la línea 400, pueden ser multiplexados. Sin embargo, si una ID es insertado es la línea 800, no puede ser reutilizado.
Cuando una página entera después de despegar de un árbol B + que se pueden multiplexar en cualquier posición.
Si dos páginas adyacentes de la utilización de los datos es muy pequeño, este sistema cabe en dos páginas de datos en una página, la otra página de datos se marca como reutilizable.
Además, si ponemos toda la tabla de datos con el comando de borrado para borrar todas las páginas de datos se marcarán como reutilizable. Pero en el disco, el archivo no se reduce.
Obvia del sistema, elimine sólo la posición del registro, o la página de datos de marcado para "reutilizable", pero el tamaño del archivo de disco no va a cambiar.
En otras palabras, por el comando de borrado no se puede recuperar espacio en la mesa. Estos pueden ser reutilizados, mientras que no se está utilizando el espacio, se ve como un "agujero".
De hecho, los datos no sólo eliminados pueden causar caries, insertar los datos serán .
Si los datos se inserta en orden ascendente de acuerdo con el índice, el índice es compacto. Pero si los datos se insertan aleatoriamente, puede hacer que la página de datos de índice de división.
Las cifras anteriores página A completa, entonces tengo que insertar una fila, ¿qué pasará?
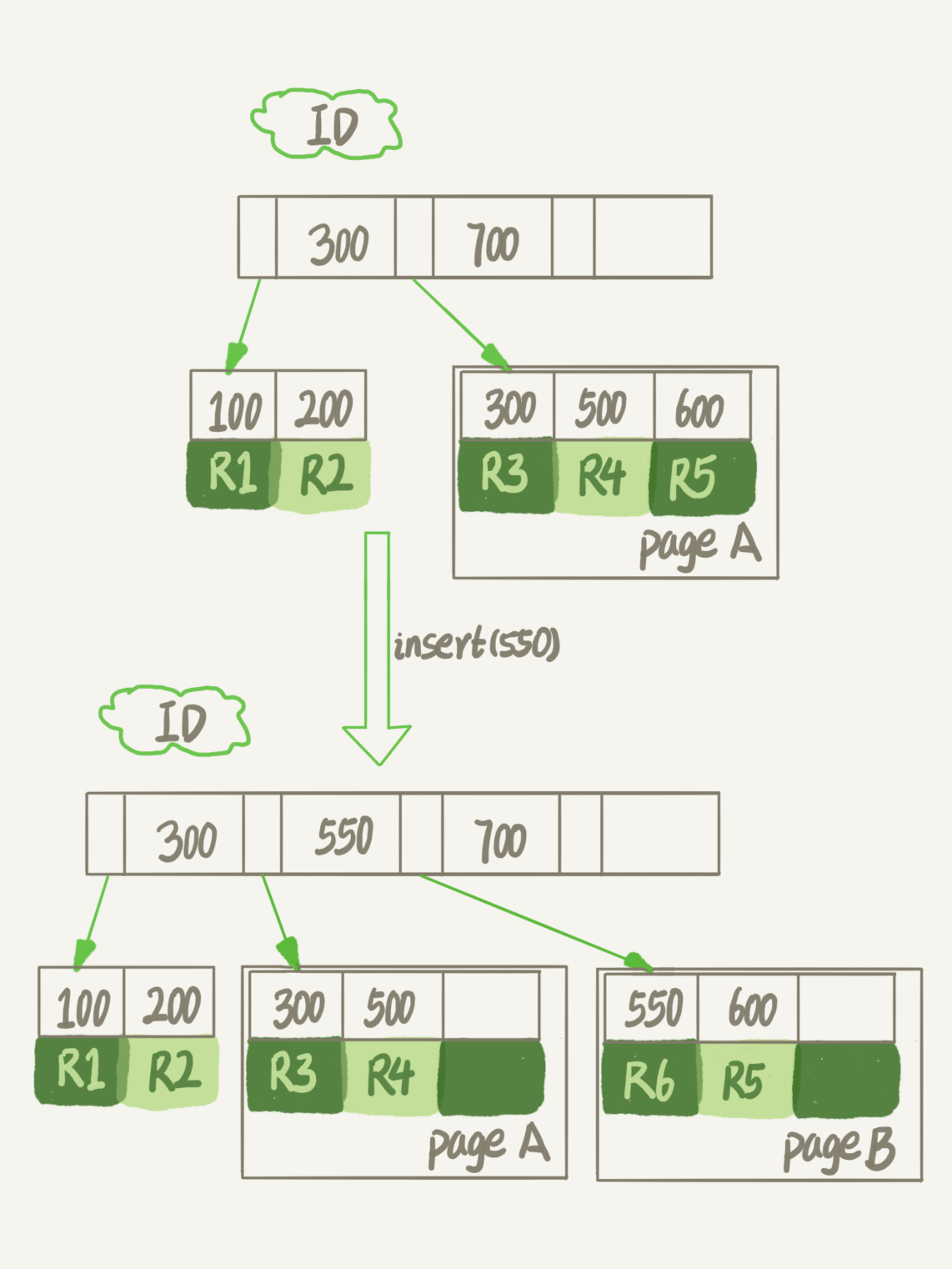
Se puede ver que a causa de la página A plena, a continuación, insertar un ID de datos es de 550, su longitud no deberá solicitar una nueva página de la página B para guardar los datos.
Después de la finalización de las páginas divididas, página A en el extremo izquierdo del hueco (Nota: En realidad, la posición puede ser más de un registro está vacío).
Además, el valor actualizado del índice puede entenderse como para eliminar un valor antiguo y, a continuación, insertar un nuevo valor. Es comprensible que esta es la causa vacía.
Así, después de una gran cantidad de adiciones y supresiones para cambiar la mesa, es que puede estar vacío.
mesa de reconstrucción
Si ahora tiene una tabla A, reducir las necesidades de espacio que hacer, con el fin de retirar la mesa vacía existe, ¿cómo puede hacerlo?
Se puede crear una estructura igual que en la Tabla A Tabla B, y el ID de clave primaria en orden ascendente, los datos leídos línea por línea y luego insertarse en la Tabla A Tabla B.
Dado que la nueva tabla es la tabla B, de modo que el agujero en la clave principal índice de la tabla A, el cuadro B, que no existe. Obviamente, las páginas, los datos de utilización más altos también la clave principal índice de la tabla B más compactos. Si ponemos la tabla temporal ya que el cuadro B, los datos de importación de la Tabla A Tabla B después de que se complete la operación, la sustitución de A con el cuadro B, en efecto, que sirve como una contracción de la tabla A del espacio.
Puede alterar la tabla A del motor = InnoDB comando para reconstruir la tabla. Antes de MySQL versión 5.5, ejecutar este comando con el proceso que hemos descrito es similar a la diferencia es sólo temporal, el cuadro B no es necesario para crear su propio, MySQL volcará automáticamente el intercambio de datos nombre de la tabla, eliminar la tabla de edad.

Figura 3
Obviamente, pasar el paso más tiempo es el proceso de inserción de datos en una tabla temporal , si en el proceso, hay nuevos datos que se escriben en la tabla A, causaría la pérdida de datos.
Por lo tanto, todo el DDL proceso, la Tabla A no puede ser actualizado. En otras palabras, esto no es una línea de DDL.
En línea DDL MySQL 5.6 versión introducida en el inicio de los procesos operativos optimizados.
Después de la introducción de la línea DDL, el proceso de reconstrucción tabla:
1. Crear un archivo temporal, todas las páginas de datos Una clave primaria mesa de exploración;
2. Los datos de grabación de generación de tablas de páginas Un árbol B + se almacena en el archivo temporal;
3. El proceso de generación de un archivo temporal, todas las operaciones de la A registrados en un archivo de registro (log fila), las cifras correspondientes son estado estado2;
se genera 4. archivo temporal, el archivo de registro de la operación en un archivo temporal en la aplicación, para obtener un conjunto de datos lógicos en la Tabla A el mismo archivo de datos, la cifra correspondiente es el estado Estado3;
El archivo de datos de sustitución de archivos temporales Cuadro A.
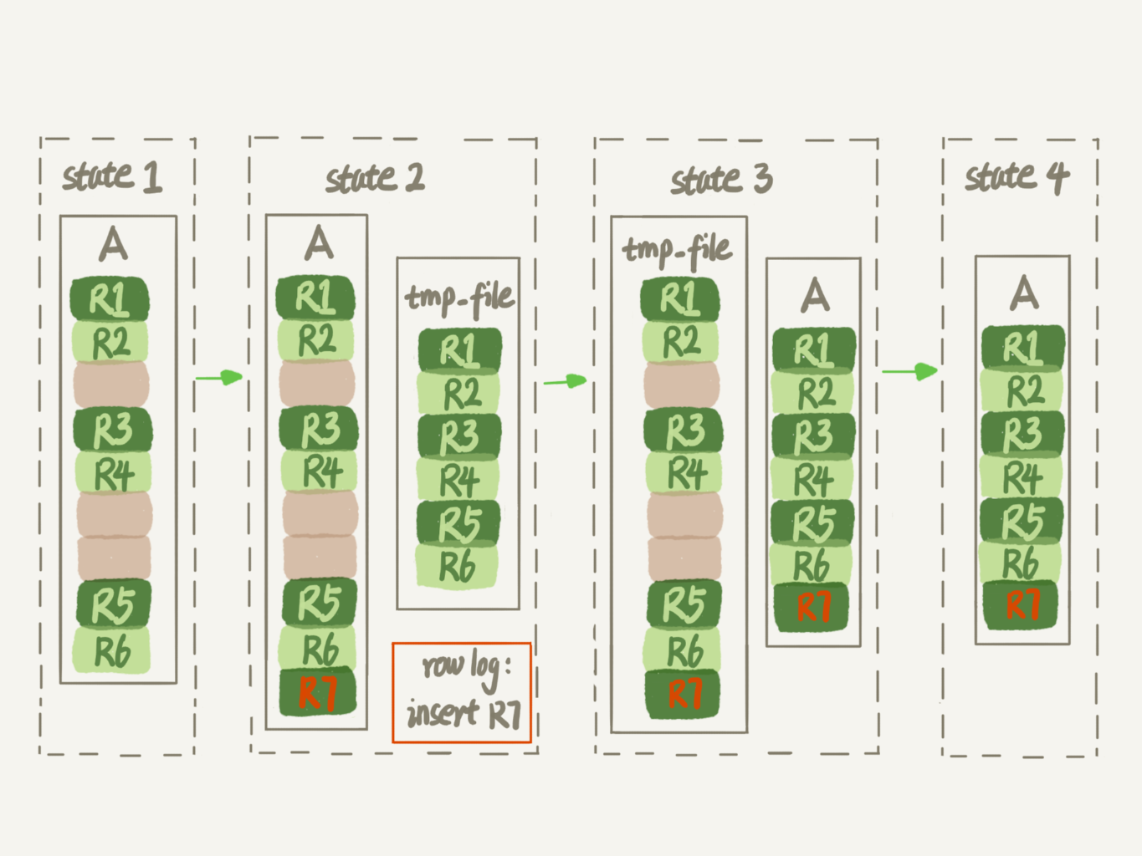
Figura 4
Se puede ver, diferente del procedimiento anterior versión 5.5 es que, desde la grabación y reproducción de archivo de registro de la operación está presente esta característica, el programa de reconstrucción en la tabla, la tabla A no permiten adiciones y supresiones a la operación. Este es el origen de los nombres de DDL en línea.
Algunos pueden preguntarse, es traerlo antes de que el bloqueo de escritura de DDL MDL, para que pueda llamar en línea DDL?
De hecho, las declaraciones de modificar en el momento del arranque necesidad de bloqueo de escritura adquieren MDL, pero la cerradura antes de escribir copia de datos a degenerar en un bloqueo de lectura.
¿Por qué debe degenerar? Con el fin de lograr en línea, leer MDL bloqueo no bloquea las operaciones CRUD.
¿Por qué no simplemente desbloquearlo? Para protegerse, prohíbe otros hilos en esta mesa do DDL mismo tiempo.
Para una gran mesas, en línea DDL es el proceso que consume más tiempo de copiar los datos en la tabla temporal puede aceptar operaciones CRUD durante la ejecución de este paso.
Así, en relación con todo el proceso de DDL, el tiempo de bloqueo es muy corta. Para las empresas, se puede considerar la línea.
El método de reconstrucción descrito anteriormente explora la tabla de datos y construye el archivo temporal originales. Para tablas de gran tamaño, esta operación es muy CPU y recursos IO consumiendo. En consecuencia, si los servicios en línea, el tiempo de operación a ser cuidadosamente controlado. Si desea comparar la seguridad de la operación, le recomiendo que utilice GitHub de código abierto gh-ost hacer.
Línea 和 inplace
En la Figura 3, tenemos los datos de la Tabla A se denomina posición de almacenamiento resultó tabla llamada tmp_table. Esta es una tabla temporal se crea en la capa de servidor.
En la Figura 4, la Tabla A la reconstrucción de los datos está en el interior "tmp_file", este archivo temporal se crea InnoDB a cabo internamente.
toda DDL proceso se realiza en el local InnoDB. Para la capa de servidor, no hay datos para mover en una tabla temporal, un "in situ" el funcionamiento, que es la fuente del nombre "inplace".
Q: Si hay una mesa de 1 TB, ahora está entre 1,2 TB de disco, un DDL no puede hacer in-situ de la misma?
La respuesta es no. Porque, tmp_file también para ocupar espacio temporal.
Esta tabla alter declaración para reconstruir la tabla de t = motor InnoDB, de hecho, la implicación es:
alter tabla t motor = innodb, ALGORITMO = inplace;
Con inplace copia de la tabla correspondiente es el camino, el uso es:
alter tabla t motor = innodb, ALGORITMO = copiar;
Cuando se utiliza ALGORITMO = copia, la copia es obligatoria tabla indica, el proceso es la operación correspondiente a la Fig. 3.
Pero todavía se puede sentir, con in-situ en línea no es que un significado?
Bueno, no exactamente, pero en la mesa de la reconstrucción es exactamente esta lógica sería la misma.
Por ejemplo, añadir un índice de texto campo si voy a tablas InnoDB, redacción es:
alter tabla t añadir FULLTEXT (nombre_campo);
Este proceso es in-situ, pero bloqueará un mantenimiento, la no-Online.
Si usted dice ¿cuál es la relación entre estos dos es lógico, entonces, se pueden resumir en:
1. Proceso de DDL en línea si lo es, debe ser in-situ de;
2. A su vez necesariamente, que es in-situ de DDL, probablemente no hay línea. En MySQL 8.0, añadir la indización de texto (índice FULLTEXT) y el índice espacial (índice espacial) Este es el caso.
Optimizar mesa diferencia, analizar mesa y mesa de alter tres maneras de reconstruir la tabla
1. De principio MySQL versión 5.6, el motor de la tabla t alter = InnoDB (es decir, el recreate) el valor predeterminado es el flujo de la figura 4 anterior.;
2.analyze tabla t en realidad no reconstruir la tabla, pero la tabla de información de índice de recuento no, no modifica los datos, el proceso añade MDL bloqueo de lectura;
tabla 3.optimize T igual a recrear + analizar.