
Aprenda a visualizar el uso de memoria de las conexiones MySQL.
Autor: Benjamín Dicken
Fuente de este artículo y portada: https://planetscale.com/blog/, traducido por la comunidad de código abierto de Axon.
Este artículo tiene aproximadamente 3000 palabras y se espera que demore 10 minutos en leerlo.
introducción
Al considerar el rendimiento de cualquier software, existe una compensación típica entre tiempo y espacio. En el proceso de evaluación del rendimiento de las consultas MySQL, a menudo nos centramos en el tiempo de ejecución (o latencia de la consulta) como principal indicador del rendimiento de las consultas. Esta es una buena métrica a utilizar porque, en última instancia, queremos obtener resultados de la consulta lo más rápido posible.
Recientemente publiqué una publicación de blog sobre Cómo identificar y analizar consultas MySQL problemáticas , que se centró en medir el rendimiento deficiente en términos de tiempo de ejecución y lecturas de filas. Sin embargo, el consumo de memoria se ha ignorado en gran medida en esta discusión.
Aunque puede que no sea necesario con frecuencia, MySQL también tiene mecanismos integrados para proporcionar información sobre cuánta memoria utilizan las consultas y para qué se utiliza esa memoria. Profundicemos en esta función y veamos cómo puede monitorear el uso de memoria de las conexiones MySQL en tiempo real.
Estadísticas de memoria
En MySQL, hay muchos componentes del sistema que se pueden instrumentar individualmente. La performance_schema.setup_instrumentstabla enumera cada componente y hay bastantes:
SELECT count(*) FROM performance_schema.setup_instruments;
+----------+
| count(*) |
+----------+
| 1255 |
+----------+
Esta tabla contiene muchas herramientas que se pueden utilizar para el análisis de la memoria. Para ver qué hay disponible, intente seleccionar de la tabla y filtrar por memory/.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%';
Deberías ver cientos de resultados. Cada uno de estos representa una categoría diferente de memoria y se puede detectar individualmente en MySQL. Algunas de estas categorías incluyen un breve párrafo documentationque describe qué representa o para qué se utiliza esa categoría de memoria. Si solo desea ver tipos de memoria con valores no nulos documentation, puede ejecutar:
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%'
AND documentation IS NOT NULL;
Cada una de estas clases de memoria se puede muestrear con varias granularidades diferentes. Se almacenan diferentes niveles de granularidad en varias tablas:
SELECT table_name
FROM information_schema.tables
WHERE table_name LIKE '%memory_summary%'
AND table_schema = 'performance_schema';
+-----------------------------------------+
| TABLE_NAME |
+-----------------------------------------+
| memory_summary_by_account_by_event_name |
| memory_summary_by_host_by_event_name |
| memory_summary_by_thread_by_event_name |
| memory_summary_by_user_by_event_name |
| memory_summary_global_by_event_name |
+-----------------------------------------+
- Memory_summary_by_account_by_event_name: resume los eventos de memoria por cuenta (la cuenta es una combinación de usuario y host)
- Memory_summary_by_host_by_event_name: resume los eventos de memoria en la granularidad del host
- Memory_summary_by_thread_by_event_name: resume los eventos de memoria en la granularidad del hilo MySQL
- Memory_summary_by_user_by_event_name: resume los eventos de memoria según la granularidad del usuario
- Memory_summary_global_by_event_name: resumen global de estadísticas de memoria
Tenga en cuenta que no existe un seguimiento específico del uso de la memoria en cada nivel de consulta. Sin embargo, eso no significa que no podamos analizar el uso de memoria de nuestras consultas. Para lograr esto, podemos monitorear el uso de memoria en cualquier conexión que esté ejecutando la consulta de interés. Por lo tanto, nos centraremos en el uso de tablas memory_summary_by_thread_by_event_nameporque existe un mapeo conveniente entre las conexiones y los subprocesos de MySQL.
Encuentra el propósito de la conexión.
En este punto, debes configurar dos conexiones separadas al servidor MySQL en la línea de comando. La primera es la consulta que ejecuta la consulta para la que desea monitorear el uso de la memoria. El segundo se utilizará con fines de seguimiento.
En la primera conexión, ejecute estas consultas para obtener el ID de la conexión y el ID del hilo.
SET @cid = (SELECT CONNECTION_ID());
SET @tid = (SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=@cid);
Luego obtenga estos valores. Por supuesto, el suyo puede verse diferente al que ve aquí.
SELECT @cid, @tid;
+------+------+
| @cid | @tid |
+------+------+
| 49 | 89 |
+------+------+
A continuación, ejecute algunas consultas de larga duración para las que desee analizar el uso de la memoria. Para este ejemplo, voy a realizar una operación grande desde una tabla con 100 millones de filas, lo que debería llevar un tiempo porque aliasno hay ningún índice en la columna SELECT:
SELECT alias FROM chat.message ORDER BY alias DESC LIMIT 100000;
Ahora, mientras se ejecuta, cambie a otra conexión de consola y ejecute el siguiente comando, reemplazando el ID del hilo con el ID del hilo de su conexión:
SELECT
event_name,
current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = YOUR_THREAD_ID
ORDER BY current_number_of_bytes_used DESC
Debería ver resultados similares a este, aunque los detalles dependen en gran medida de su consulta y sus datos:
+---------------------------------------+------------------------------+
| event_name | current_number_of_bytes_used |
+---------------------------------------+------------------------------+
| memory/sql/Filesort_buffer::sort_keys | 203488 |
| memory/innodb/memory | 169800 |
| memory/sql/THD::main_mem_root | 46176 |
| memory/innodb/ha_innodb | 35936 |
...
Esto indica la cantidad de memoria que utiliza cada categoría al ejecutar esta consulta. Si SELECT alias...ejecuta esta consulta varias veces mientras ejecuta otra consulta, es posible que vea resultados diferentes porque el uso de memoria de la consulta no es necesariamente constante durante su ejecución. Cada ejecución de esta consulta representa una muestra en algún momento. Entonces, si queremos entender cómo cambia el uso con el tiempo, necesitamos tomar muchas muestras.
memory/sql/Filesort_buffer::sort_keysdocumentationfalta en la mesa performance_schema.setup_instruments.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory%sort_keys';
+---------------------------------------+---------------+
| name | documentation |
+---------------------------------------+---------------+
| memory/sql/Filesort_buffer::sort_keys | <null> |
+---------------------------------------+---------------+
Sin embargo, el nombre indica que es la memoria utilizada para ordenar los datos del archivo. Esto tiene sentido ya que la mayor parte del costo de esta consulta será ordenar los datos para que puedan mostrarse en orden descendente.
Recopilar el uso a lo largo del tiempo
A continuación, debemos poder muestrear el uso de la memoria a lo largo del tiempo. Esto no será tan útil para consultas cortas, ya que solo podemos ejecutar esta consulta una vez o una pequeña cantidad de veces mientras ejecutamos la consulta analítica. Esto es más útil para consultas de ejecución más larga (consultas que tardan segundos o minutos). De todos modos, estos son los tipos de consultas que queremos analizar, ya que es probable que estas consultas utilicen la mayor parte de la memoria.
Esto se puede implementar completamente en SQL y llamarse mediante procedimientos almacenados. Sin embargo, en este caso utilizamos un script independiente en Python para proporcionar supervisión.
#!/usr/bin/env python3
import time
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY current_number_of_bytes_used DESC LIMIT 4
'''
parser = argparse.ArgumentParser()
parser.add_argument('--thread-id', type=int, required=True)
args = parser.parse_args()
dbc = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
c = dbc.cursor()
ms = 0
while(True):
c.execute(MEM_QUERY, (args.thread_id,))
results = c.fetchall()
print(f'\n## Memory usage at time {ms} ##')
for r in results:
print(f'{r[0][7:]} -> {round(r[1]/1024,2)}Kb')
ms+=250
time.sleep(0.25)
Este es un primer intento simple con este tipo de script de monitoreo. En resumen, este código hace lo siguiente:
- Obtenga el ID del hilo proporcionado para monitorear a través de la línea de comando
- Configurar una conexión a la base de datos MySQL
- Ejecute una consulta cada 250 ms para obtener las 4 categorías de memoria más utilizadas e imprimir la lectura
Esto se puede adaptar de diversas formas según sus necesidades de análisis. Por ejemplo, ajuste la frecuencia de los pings al servidor o cambie la cantidad de clases de memoria enumeradas por iteración. Ejecutar este comando mientras se ejecuta una consulta proporciona los siguientes resultados:
...
## Memory usage at time 4250 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4500 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4750 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 5000 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
...
Es genial, pero tiene algunas debilidades. Es bueno ver algo más allá de las primeras 4 categorías de uso de memoria, pero aumentar ese número aumentará el tamaño de este volcado de salida que ya es grande. Sería bueno si hubiera una manera más sencilla de comprender el uso de la memoria de un vistazo con alguna visualización. Esto se puede hacer haciendo que el script descargue los resultados en CSV o JSON y luego los cargue en el visualizador. Aún mejor, podemos trazar resultados en tiempo real a medida que fluyen los datos. Esto proporciona una vista actualizada y nos permite observar el uso de la memoria a medida que ocurre en tiempo real, todo en una sola herramienta.
Trazar el uso de la memoria
Para que la herramienta sea más útil y proporcione visualización, se realizarán algunos cambios.
- El usuario proporcionará el ID de la conexión en la línea de comando y el script será responsable de encontrar el hilo subyacente.
- La frecuencia con la que el script solicita datos de la memoria también se puede configurar a través de la línea de comando.
- Esta
matplotlibbiblioteca se utilizará para generar visualizaciones del uso de la memoria. Contendrá un gráfico de pila con una leyenda que muestra la categoría de uso de memoria más alta y mantendrá las últimas 50 muestras.
Esto es bastante código, pero se incluye aquí para que esté completo.
#!/usr/bin/env python3
import matplotlib.pyplot as plt
import numpy as np
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY event_name DESC'''
TID_QUERY='''
SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=%s'''
class MemoryProfiler:
def __init__(self):
self.x = []
self.y = []
self.mem_labels = ['XXXXXXXXXXXXXXXXXXXXXXX']
self.ms = 0
self.color_sequence = ['#ffc59b', '#d4c9fe', '#a9dffe', '#a9ecb8',
'#fff1a8', '#fbbfc7', '#fd812d', '#a18bf5',
'#47b7f8', '#40d763', '#f2b600', '#ff7082']
plt.rcParams['axes.xmargin'] = 0
plt.rcParams['axes.ymargin'] = 0
plt.rcParams["font.family"] = "inter"
def update_xy_axis(self, results, frequency):
self.ms += frequency
self.x.append(self.ms)
if (len(self.y) == 0):
self.y = [[] for x in range(len(results))]
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
self.y[i].append(usage)
if (len(self.x) > 50):
self.x.pop(0)
for i in range(len(self.y)):
self.y[i].pop(0)
def update_labels(self, results):
total_mem = sum(map(lambda e: e[1], results))
self.mem_labels.clear()
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
mem_type = results[i][0]
# Remove 'memory/' from beginning of name for brevity
mem_type = mem_type[7:]
# Only show top memory users in legend
if (usage < total_mem / 1024 / 50):
mem_type = '_' + mem_type
self.mem_labels.insert(0, mem_type)
def draw_plot(self, plt):
plt.clf()
plt.stackplot(self.x, self.y, colors = self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.xlabel("milliseconds since monitor began")
plt.ylabel("Kilobytes of memory")
def configure_plot(self, plt):
plt.ion()
fig = plt.figure(figsize=(12,5))
plt.stackplot(self.x, self.y, colors=self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.tight_layout(pad=4)
return fig
def start_visualization(self, database_connection, connection_id, frequency):
c = database_connection.cursor();
fig = self.configure_plot(plt)
while(True):
c.execute(MEM_QUERY, (connection_id,))
results = c.fetchall()
self.update_xy_axis(results, frequency)
self.update_labels(results)
self.draw_plot(plt)
fig.canvas.draw_idle()
fig.canvas.start_event_loop(frequency / 1000)
def get_command_line_args():
'''
Process arguments and return argparse object to caller.
'''
parser = argparse.ArgumentParser(description='Monitor MySQL query memory for a particular connection.')
parser.add_argument('--connection-id', type=int, required=True,
help='The MySQL connection to monitor memory usage of')
parser.add_argument('--frequency', type=float, default=500,
help='The frequency at which to ping for memory usage update in milliseconds')
return parser.parse_args()
def get_thread_for_connection_id(database_connection, cid):
'''
Get a thread ID corresponding to the connection ID
PARAMS
database_connection - Database connection object
cid - The connection ID to find the thread for
'''
c = database_connection.cursor()
c.execute(TID_QUERY, (cid,))
result = c.fetchone()
return int(result[0])
def main():
args = get_command_line_args()
database_connection = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
connection_id = get_thread_for_connection_id(database_connection, args.connection_id)
m = MemoryProfiler()
m.start_visualization(database_connection, connection_id, args.frequency)
connection.close()
if __name__ == "__main__":
main()
Con esto podremos realizar un seguimiento detallado de la ejecución de consultas MySQL. Para usarlo, primero obtenga el ID de la conexión que desea analizar:
SELECT CONNECTION_ID();
Luego, al ejecutar el siguiente comando se iniciará la sesión de monitoreo:
./monitor.py --connection-id YOUR_CONNECTION_ID --frequency 250
Al ejecutar consultas en la base de datos, podemos observar el aumento en el uso de memoria y ver qué categorías contribuyen más a la memoria.
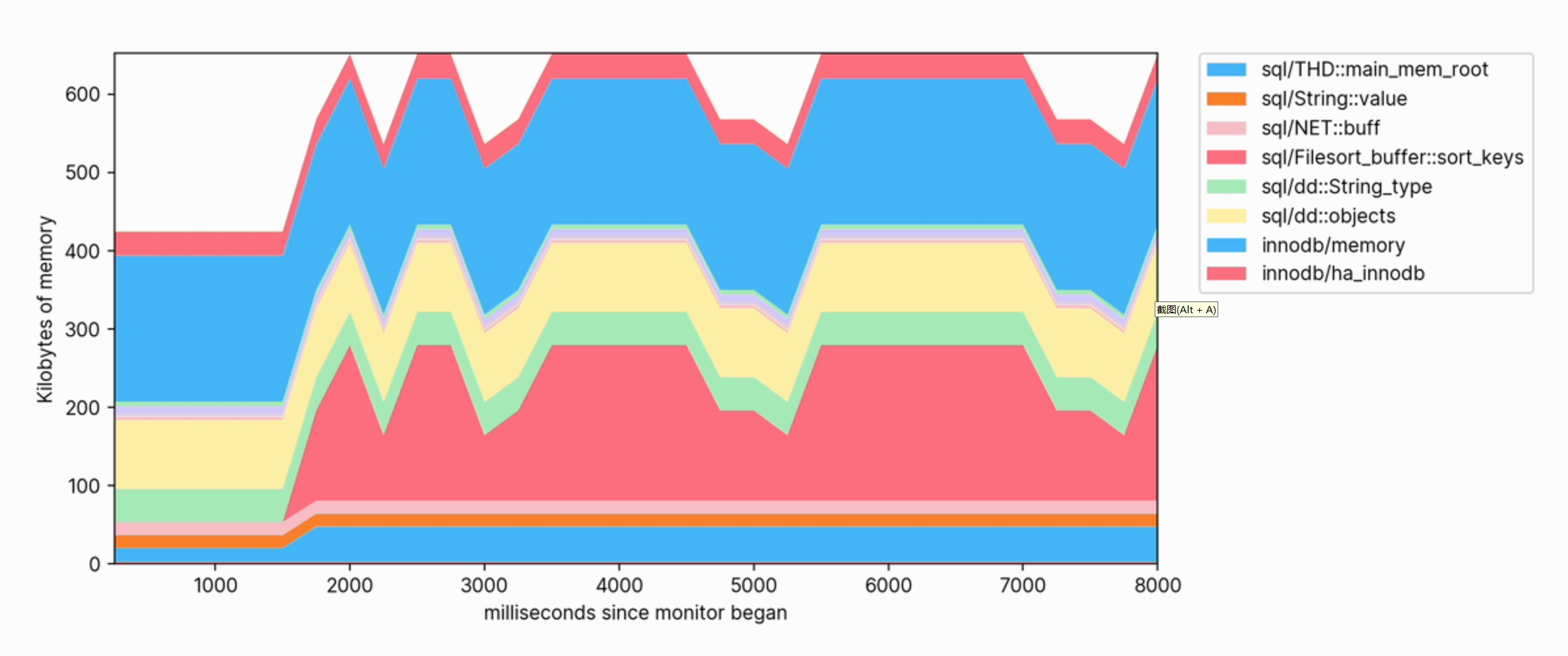
Esta visualización también nos ayuda a ver claramente qué operaciones consumen memoria. Por ejemplo, el siguiente es un fragmento del perfil de memoria utilizado para crear un índice de TEXTO COMPLETO en una tabla grande:
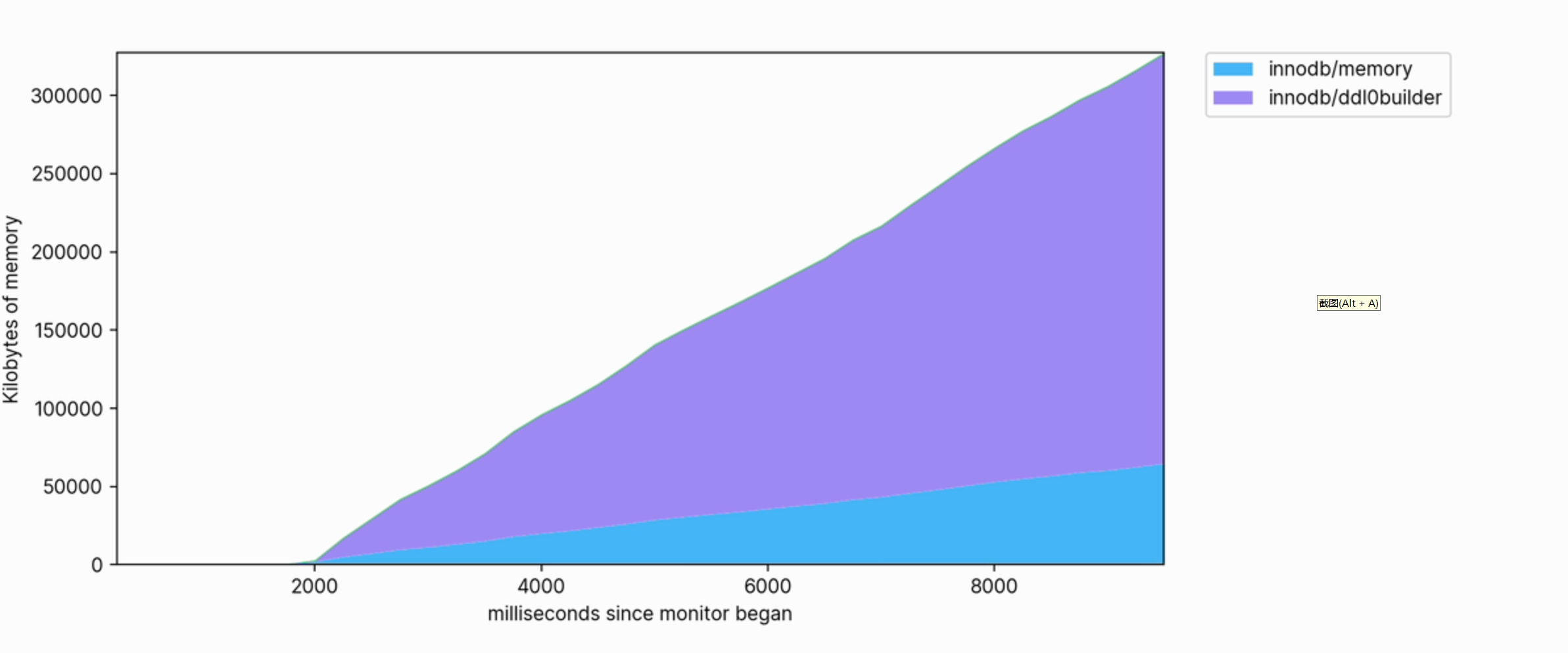
El uso de memoria es grande y continúa creciendo hasta utilizar cientos de megabytes mientras se ejecuta.
en conclusión
Aunque puede que no sea necesario con frecuencia, la capacidad de obtener información detallada sobre el uso de la memoria puede ser extremadamente valiosa cuando se requiere una optimización detallada de las consultas. Hacerlo puede revelar cuándo y por qué MySQL está ejerciendo presión sobre la memoria del sistema, o si se necesita una actualización de la memoria en el servidor de la base de datos. MySQL proporciona muchas primitivas a partir de las cuales puede desarrollar herramientas analíticas para sus consultas y cargas de trabajo.
Para obtener más artículos técnicos, visite: https://opensource.actionsky.com/
Acerca de SQLE
SQLE es una plataforma integral de gestión de calidad de SQL que cubre la auditoría y gestión de SQL desde los entornos de desarrollo hasta los de producción. Admite bases de datos nacionales, comerciales y de código abierto convencionales, proporciona capacidades de automatización de procesos para el desarrollo, operación y mantenimiento, mejora la eficiencia en línea y mejora la calidad de los datos.
obtener SQLE
| tipo | DIRECCIÓN |
|---|---|
| Repositorio | https://github.com/actiontech/sqle |
| documento | https://actiontech.github.io/sqle-docs/ |
| noticias de lanzamiento | https://github.com/actiontech/sqle/releases |
| Documentación de desarrollo del complemento de auditoría de datos | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |