
La semana pasada, anunciamos la hoja de ruta de GreptimeDB 2024, que revela varios planes de versiones importantes para GreptimeDB este año. Con la llegada de principios de primavera en marzo, la primera versión de código abierto de GreptimeDB adecuada para el nivel de producción también llegó según lo previsto durante la temporada "Jingzhe", cuando todo se recupera. La versión 0.7 marca un paso importante hacia una versión lista para producción y damos la bienvenida a todos los miembros de la comunidad para que participen activamente y brinden comentarios valiosos.
Desde la v0.6 a la v0.7, el equipo de Greptime ha logrado avances significativos: se han fusionado un total de 184 confirmaciones, se han modificado 705 archivos, incluidas 82 mejoras de funciones, 35 correcciones de errores, 19 refactorizaciones de código y una gran cantidad de trabajo de prueba. Durante este período, un total de 8 contribuyentes independientes participaron en la contribución de código de GreptimeDB. Un agradecimiento especial a Eugene Tolbakov, como el primer responsable de GreptimeDB, que continúa activo en la contribución de código de GreptimeDB y crece con nosotros.
Aspectos destacados de la actualización (versión para guardar secuencias) Motor de métricas : se recomienda un nuevo motor diseñado para escenarios observables que puede manejar una gran cantidad de tablas pequeñas, adecuado para escenarios de monitoreo nativo de la nube Migración de región : optimiza la experiencia de uso y se puede ejecutar fácilmente a través de SQL; Migración de región; índice invertido : ubique de manera eficiente los segmentos de datos involucrados en las consultas de los usuarios, reduzca significativamente las operaciones de IO necesarias para escanear archivos de datos y acelere el proceso de consulta.
v0.7 es una de las pocas actualizaciones de versión importantes desde que GreptimeDB fue de código abierto. Esta vez también la transmitiremos en vivo en la cuenta de video. Para obtener más información sobre los detalles funcionales, ver demostraciones o tener conversaciones en profundidad con nuestro equipo de desarrollo central, bienvenido a unirse a la transmisión en vivo a las 19:30 p. m. el próximo jueves (14 de marzo).
Migración de región
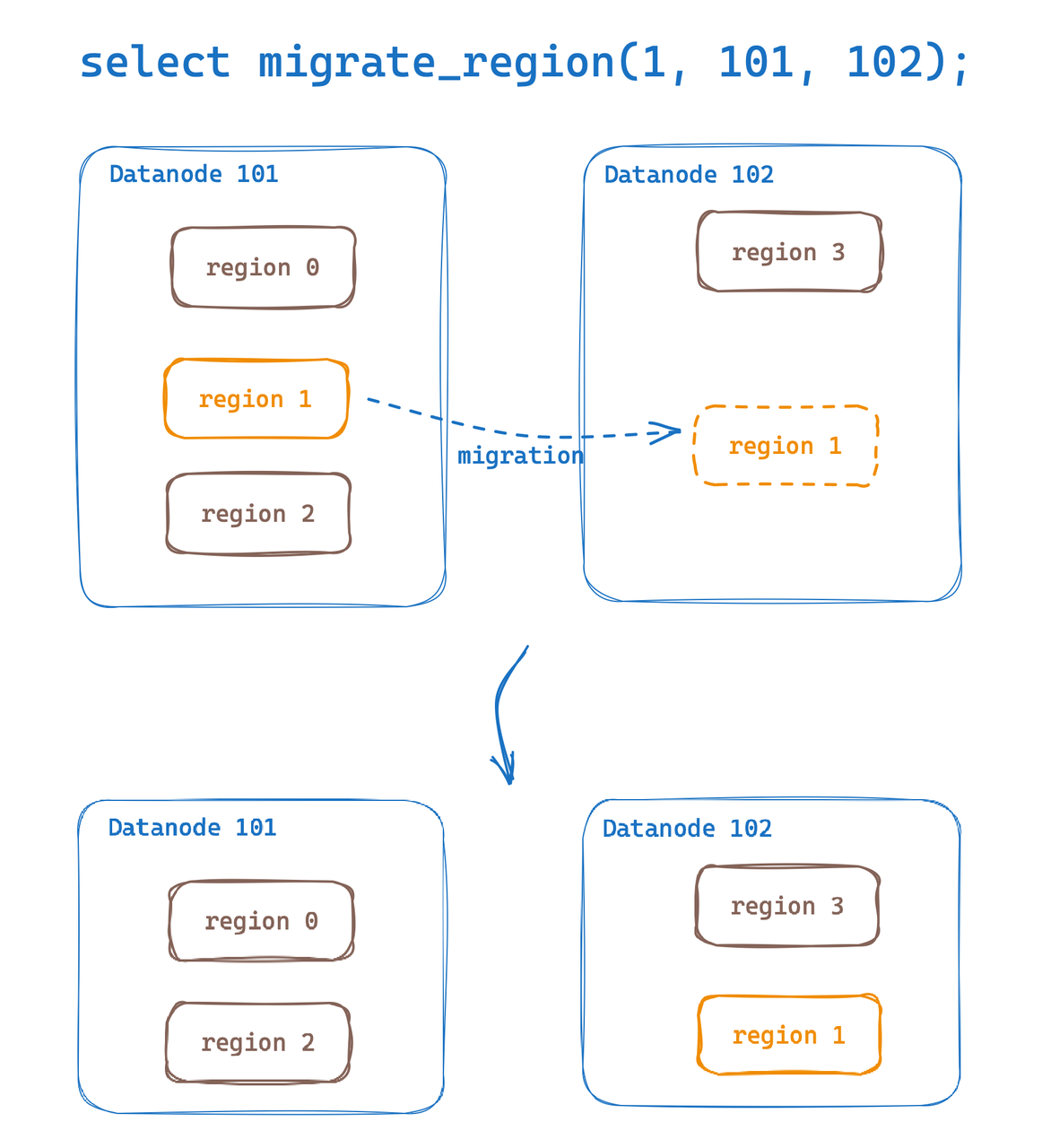
La migración de regiones brinda la capacidad de migrar regiones de tablas de datos entre Datanodes. Con esta capacidad, podemos implementar fácilmente la migración de datos de puntos de acceso y la expansión horizontal del equilibrio de carga. GreptimeDB mencionó que la migración de región se implementó inicialmente cuando se lanzó la versión 0.6. Esta actualización de versión mejora y optimiza la experiencia del usuario.
Ahora podemos realizar fácilmente la migración de región a través de SQL:
select migrate_region(
region_id,
from_dn_id,
to_dn_id,
[replay_timeout(s)]);
Motor métrico
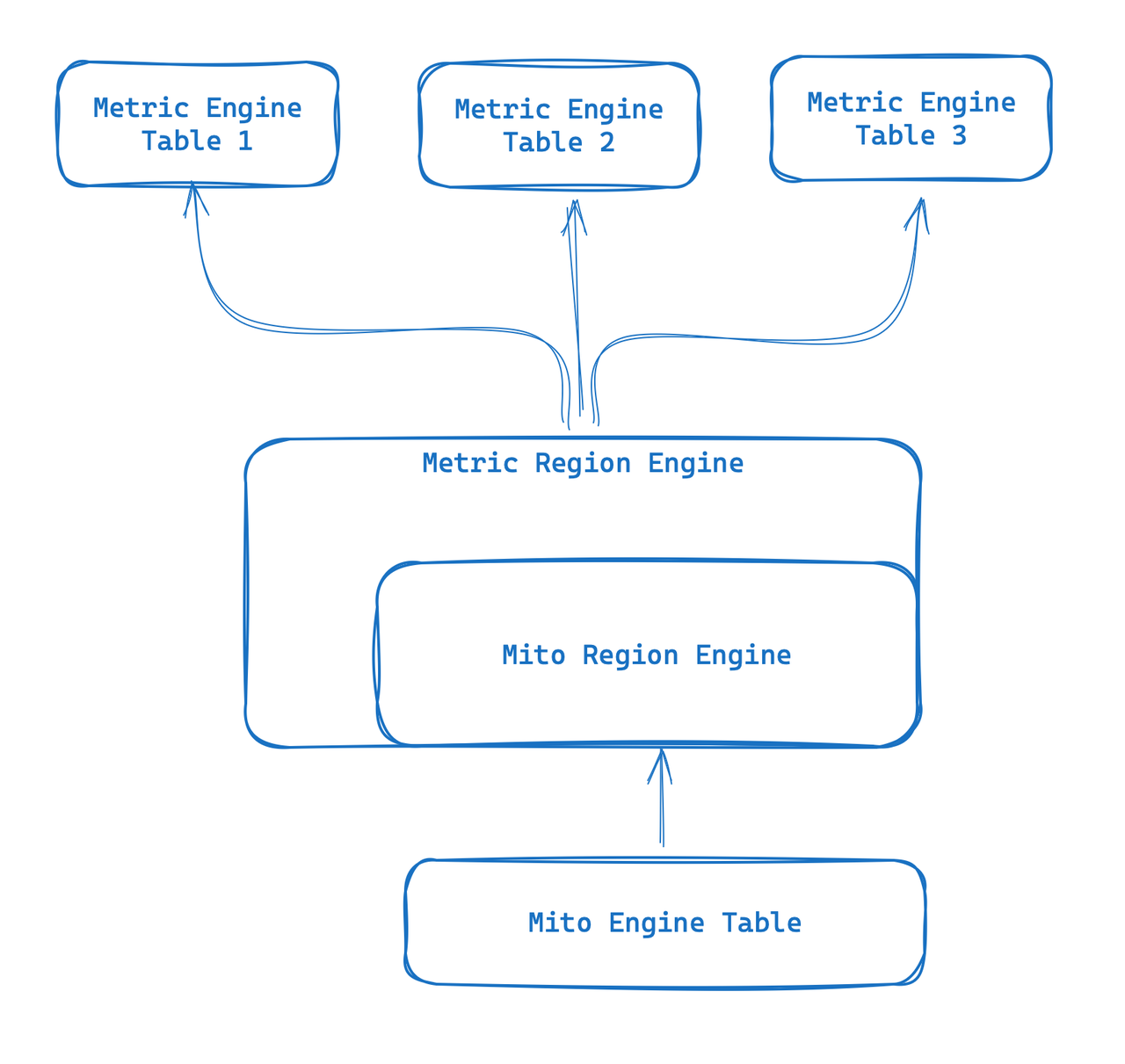
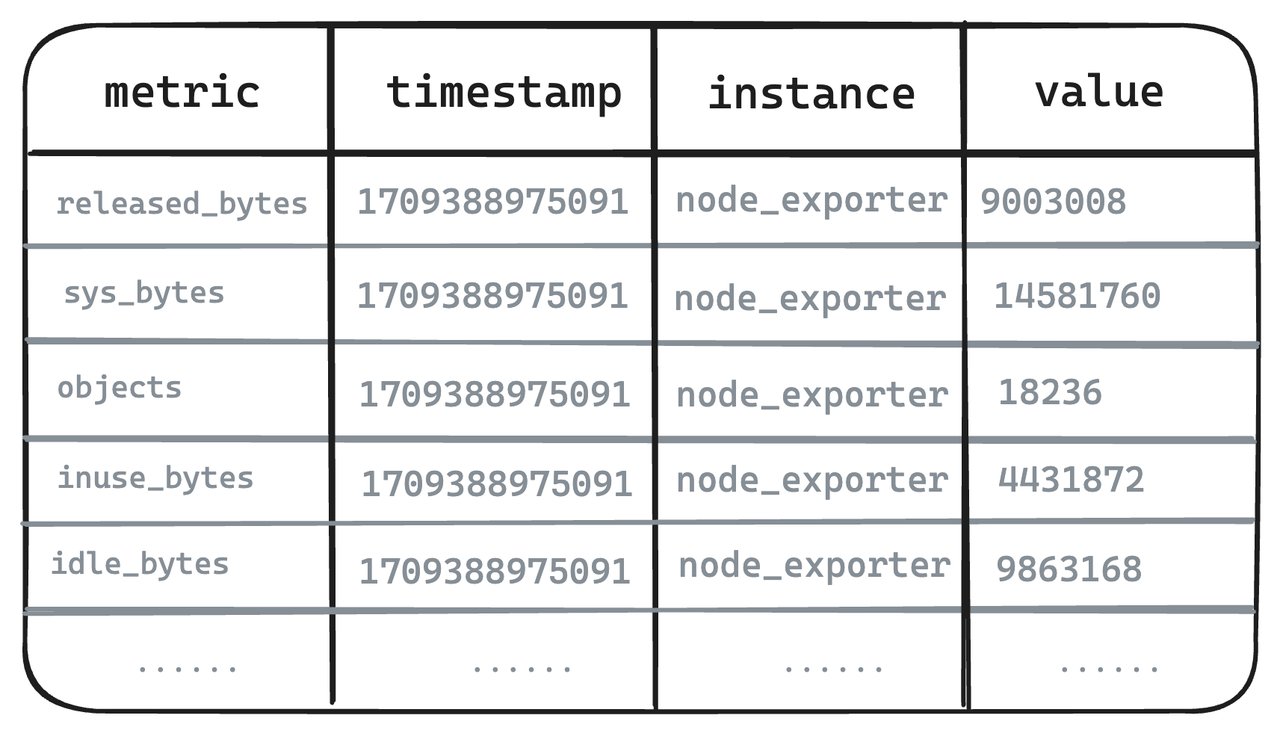
Metric Engine es un motor completamente nuevo diseñado para escenarios observables. Su objetivo principal es poder manejar una gran cantidad de tablas pequeñas y es especialmente adecuado para escenarios de monitoreo nativos de la nube, como el uso de Prometheus. Al utilizar tablas amplias sintéticas, este nuevo motor brinda la capacidad de almacenar datos de indicadores y reutilizar metadatos. La "tabla" se vuelve más liviana y puede superar algunos de los límites de tablas del motor Mito existentes que son demasiado pesados.
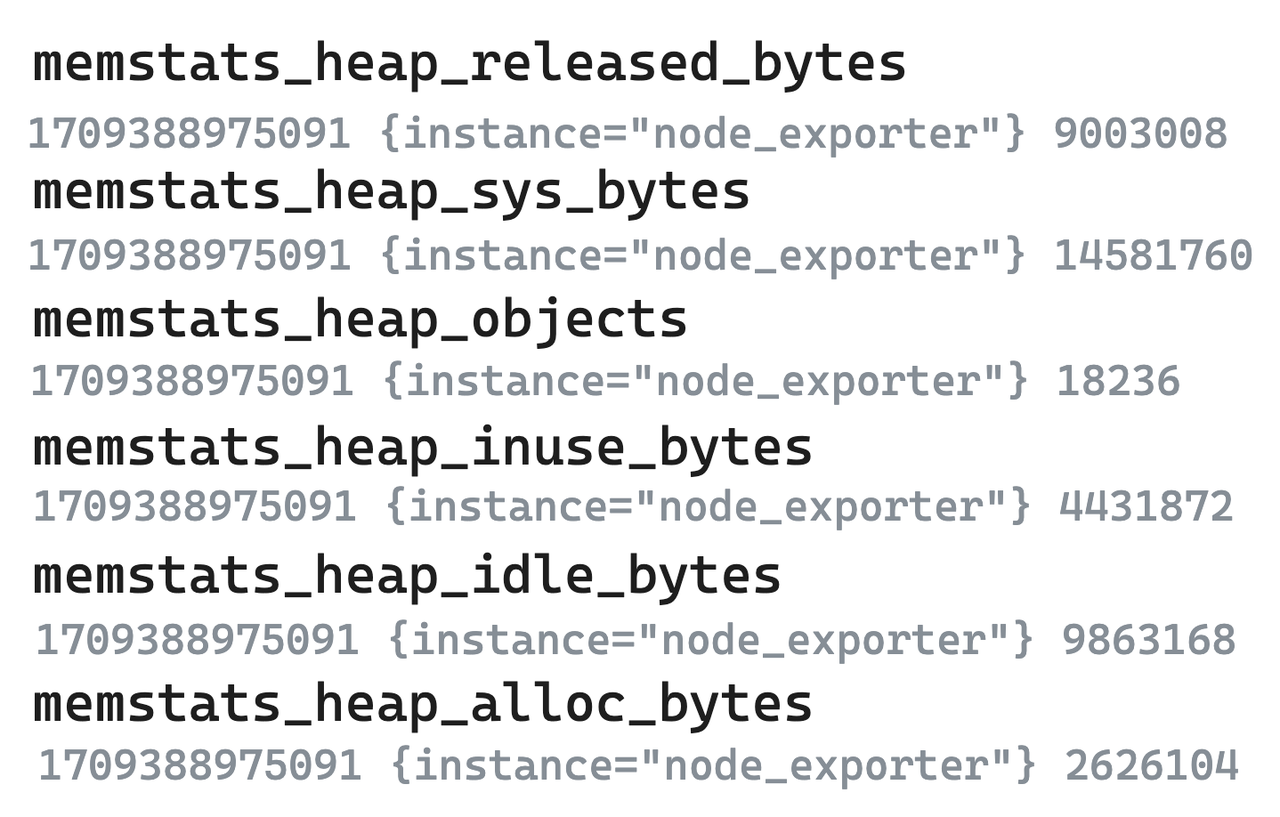
-
Leyenda: datos de métricas sin procesar
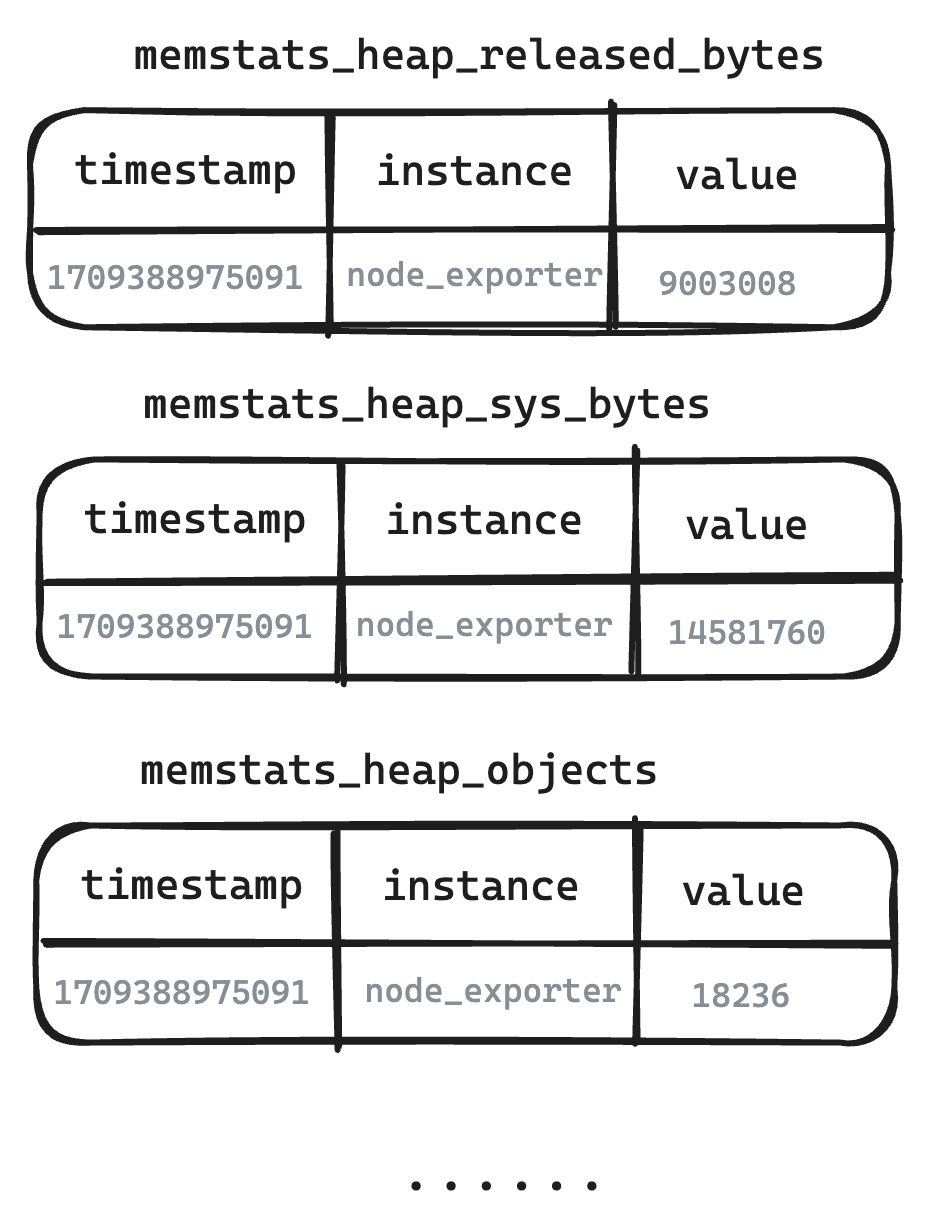
- Se toman como ejemplos las siguientes métricas de los seis exportadores de nodos. En los sistemas modelo de valor único representados por Prometheus, incluso los indicadores altamente correlacionados deben dividirse en varios y almacenarse por separado.
-
Leyenda: tabla lógica desde la perspectiva del usuario
- Metric Engine restaura auténticamente la estructura de las métricas y lo que ven los usuarios es la estructura de las métricas escrita.
-
Leyenda: la tabla física que almacena la perspectiva.
- En la capa de almacenamiento, Metric Engine realiza mapeo y utiliza una tabla física para almacenar datos relacionados, lo que puede reducir los costos de almacenamiento y admitir el almacenamiento de métricas a mayor escala.
-
Leyenda - Próximo plan I+D: Agrupación automática de campos
- La mayoría de las Métricas generadas en escenarios reales son relevantes. GreptimeDB puede derivar automáticamente indicadores relacionados y fusionarlos, lo que no solo reduce la cantidad de líneas de tiempo entre métricas, sino que también es compatible con consultas relacionadas.

-
Optimización de costos de almacenamiento
La prueba de costos se realizó en función del backend de almacenamiento de AWS S3. Cada dato se escribió durante aproximadamente 30 minutos y el volumen de escritura total fue de aproximadamente 30 w fila/s. Cuente la cantidad de veces que ocurre cada operación en el proceso y calcule el costo según la cotización de AWS. La función de índice se habilitó durante la prueba.
Para cotizaciones, consulte el nivel Estándar en https://aws.amazon.com/s3/pricing/
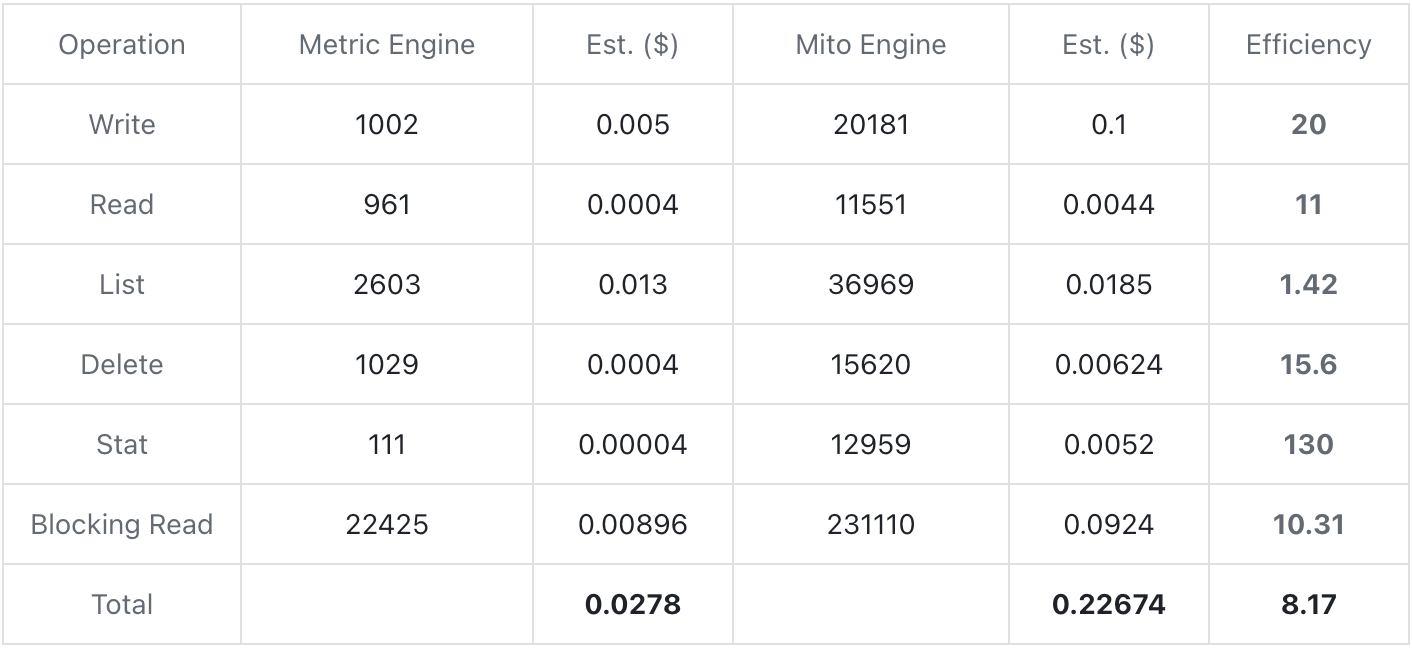
Como se puede ver en la tabla de prueba anterior, Metric Engine puede reducir significativamente los costos de almacenamiento al reducir la cantidad de tablas físicas y la cantidad de operaciones en cada etapa. El costo integral convertido se puede reducir en más de ocho. veces en comparación con Mito Engine.
Índice invertido
Como módulo de índice recientemente introducido, Inverted Index está diseñado para localizar de manera eficiente los segmentos de datos involucrados en las consultas de los usuarios, reducir significativamente las operaciones de E/S necesarias para escanear archivos de datos y acelerar el proceso de consulta. En el escenario de prueba TSBS, el rendimiento de la escena mejora en un 50% en promedio y, en algunos escenarios, el rendimiento mejora casi un 200%. Las principales ventajas del índice invertido incluyen:
- Listo para usar: el sistema genera automáticamente índices apropiados y los usuarios no necesitan especificar índices adicionales;
- Funciones prácticas: admite igualdad, rango y coincidencia regular de valores de varias columnas, lo que garantiza que los datos se puedan ubicar y filtrar rápidamente en la mayoría de los escenarios;
- Adaptación flexible: ajuste automáticamente los parámetros internos para equilibrar los costos de construcción y la eficiencia de las consultas, respondiendo de manera efectiva a las necesidades de indexación de diferentes escenarios.
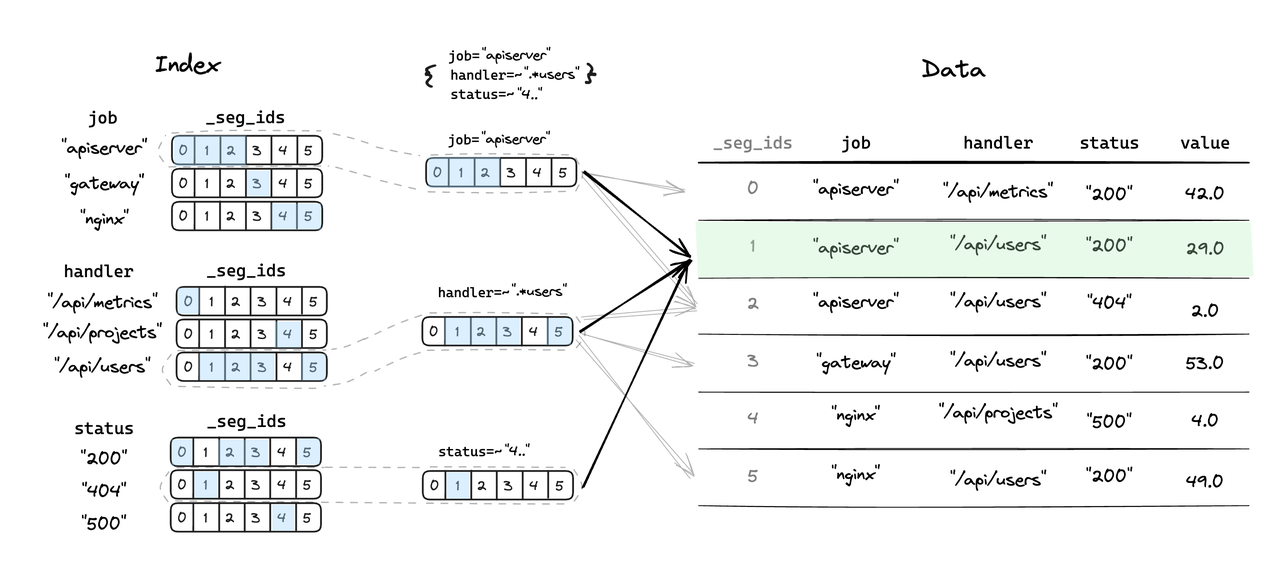
- Leyenda: representación lógica del índice invertido y proceso de posicionamiento de datos
- Los usuarios especifican las condiciones de filtrado en varias columnas y, mediante el posicionamiento rápido del índice invertido, se pueden eliminar la mayoría de los segmentos de datos no coincidentes, lo que da como resultado menos segmentos de datos para escanear y lograr una aceleración de las consultas.
Otras actualizaciones
1. Las funciones de gestión de la base de datos se han mejorado significativamente.
Hemos complementado significativamente la tabla information_schema, agregando nueva información como SCHEMATA y PARTITIONS. Además, la nueva versión introduce muchas funciones SQL nuevas para implementar operaciones de administración de bases de datos. Por ejemplo, ahora puede activar el vaciado de regiones, realizar la migración de regiones y consultar el estado de ejecución de los procedimientos a través de SQL.
2. Mejora del rendimiento
En la versión v0.7, Memtable se reconstruyó para mejorar la velocidad de escaneo de datos y reducir el uso de memoria. Al mismo tiempo, también hemos realizado muchas mejoras y optimizaciones en el rendimiento de lectura y escritura del almacenamiento de objetos.
Guía de actualización
Debido a algunos cambios importantes en la nueva versión, esta versión v0.7 requiere tiempo de inactividad para la actualización. Se recomienda utilizar la herramienta de actualización oficial. El proceso de actualización general es el siguiente:
- Crear un nuevo clúster v0.7
- Cierre la antigua entrada de tráfico del grupo (deje de escribir)
- Exporte la estructura de la tabla y los datos a través de la herramienta de actualización CLI de GreptimeDB
- Importe datos al nuevo clúster a través de la herramienta de actualización CLI de GreptimeDB
- El tráfico de entrada cambia al nuevo clúster
Para obtener una guía de actualización detallada, consulte:
- Chino: https://docs.greptime.cn/user-guide/upgrade
- Inglés: https://docs.greptime.com/user-guide/upgrade
perspectiva del futuro
Nuestro próximo gran hito será en abril, cuando se lanzará la versión 0.8. Esta versión presentará GreptimeFlow, una solución informática de flujo optimizada diseñada específicamente para realizar operaciones de agregación continua en flujos de datos GreptimeDB. Teniendo en cuenta la necesidad de flexibilidad, GreptimeFlow puede integrarse en la capa informática de GreptimeDB e implementarse juntos, o puede implementarse como un servicio independiente.
Además de las actualizaciones continuas a nivel funcional, también continuamos optimizando el rendimiento de la versión. Aunque el rendimiento de la versión 0.7 ha mejorado mucho en comparación con el anterior, todavía existe una cierta brecha entre esta y algunas soluciones principales en escenarios observables. Esta también será nuestra próxima dirección clave de optimización.
Bienvenido a leer la hoja de ruta de GreptimeDB 2024 para obtener una comprensión integral de nuestro plan de actualización de versiones durante todo el año. También puede participar en contribuciones de código o comentarios y debates sobre funciones y rendimiento. Unamos nuestras manos para presenciar el crecimiento y la mejora continuos de GreptimeDB.
Acerca de Greptime:
Greptime Greptime Technology se compromete a proporcionar servicios de análisis y almacenamiento de datos eficientes y en tiempo real para campos que generan grandes cantidades de datos de series temporales, como automóviles inteligentes, Internet de las cosas y observabilidad, ayudando a los clientes a extraer el profundo valor de los datos. Actualmente existen tres productos principales:
-
GreptimeDB es una base de datos de series temporales escrita en lenguaje Rust. Es distribuida, de código abierto, nativa de la nube y altamente compatible. Ayuda a las empresas a leer, escribir, procesar y analizar datos de series temporales en tiempo real al tiempo que reduce los costos de almacenamiento a largo plazo.
-
GreptimeCloud puede proporcionar a los usuarios servicios DBaaS totalmente gestionados, que pueden integrarse altamente con la observabilidad, el Internet de las cosas y otros campos.
-
GreptimeAI es una solución de observabilidad diseñada para aplicaciones LLM.
-
La solución integrada de vehículo-nube es una solución de base de datos de series de tiempo que profundiza en los escenarios comerciales reales de las empresas automotrices y resuelve los puntos débiles comerciales reales después de que los datos de los vehículos de la empresa crecen exponencialmente.
GreptimeCloud y GreptimeAI han sido probados oficialmente. ¡Bienvenido a seguir la cuenta oficial o el sitio web oficial para conocer los últimos desarrollos! Si está interesado en la versión empresarial de GreptimDB, puede comunicarse con el asistente (busque greptime en WeChat para agregar el asistente).
Sitio web oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentación: https://docs.greptime.cn/
Gorjeo: https://twitter.com/Greptime
Holgura: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
Un programador nacido en los años 90 desarrolló un software de portabilidad de vídeo y ganó más de 7 millones en menos de un año. ¡El final fue muy duro! Los estudiantes de secundaria crean su propio lenguaje de programación de código abierto como una ceremonia de mayoría de edad: comentarios agudos de los internautas: debido al fraude desenfrenado, confiando en RustDesk, el servicio doméstico Taobao (taobao.com) suspendió los servicios domésticos y reinició el trabajo de optimización de la versión web Java 17 es la versión Java LTS más utilizada. Cuota de mercado de Windows 10. Alcanzando el 70%, Windows 11 continúa disminuyendo. Open Source Daily | Google apoya a Hongmeng para hacerse cargo de los teléfonos Android de código abierto respaldados por Docker; Electric cierra la plataforma abierta Apple lanza el chip M4 Google elimina el kernel universal de Android (ACK) Soporte para la arquitectura RISC-V Yunfeng renunció a Alibaba y planea producir juegos independientes para plataformas Windows en el futuro