Gesamtarchitekturprozess
Papieradresse: https://openaccess.thecvf.com/content/CVPR2023/papers/Feng_AeDet_Azimuth-Invariant_Multi-View_3D_Object_Detection_CVPR_2023_paper.pdf
Startseite: https://fcjian.github.io/aedet
Code: https://github.com/ fcjian /AeDet
In diesem Artikel wird ein azimutal invarianter Detektor namens AeDet vorgestellt, der eine Azimutinvarianz für die 3D-Zielerkennung mit mehreren Ansichten erreichen kann. Wie in der folgenden Abbildung gezeigt, erzeugen bestehende Methoden (am Beispiel von BEVDepth) unter der Annahme, dass Kameras mit unterschiedlicher Ausrichtung dieselbe Szene zu unterschiedlichen Zeiten erfassen, unterschiedliche BEV-Merkmale und Vorhersageergebnisse für denselben Bus in unterschiedlichen Ausrichtungen, während AeDet Derselbe Bus Unter verschiedenen Ausrichtungen werden nahezu die gleichen BEV-Eigenschaften und Vorhersageergebnisse erzielt.

Frage
Aktuelle Multi-View-3D-Objektdetektoren (wie BEVDepth), die auf Lift-Splat-Shoot (LSS) basieren, bestehen normalerweise aus einem Bildansicht-Encoder, einem Ansichtstransformator, einem BEV-Encoder und einem Erkennungskopf.
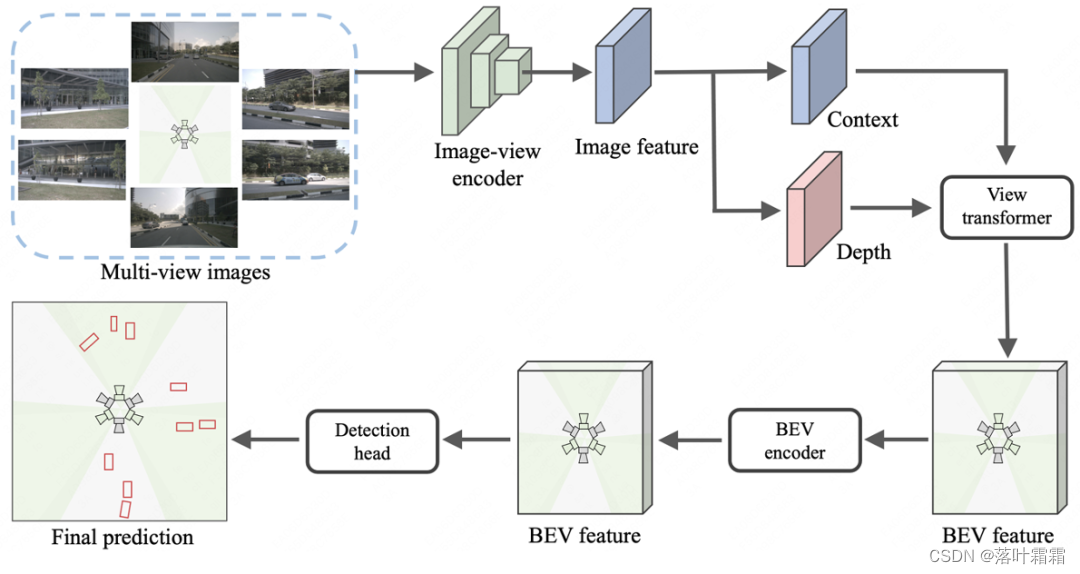
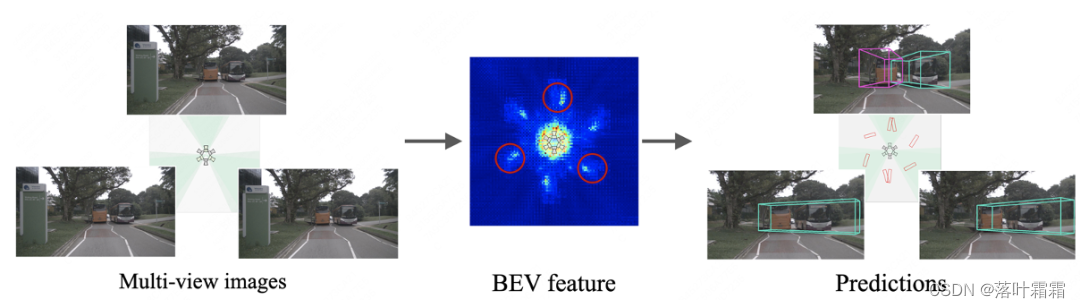
Wir haben ein einfaches Experiment basierend auf BEVDepth durchgeführt. Wir gehen davon aus, dass Kameras aus unterschiedlichen Ausrichtungen dieselbe Szene zu unterschiedlichen Zeiten aufnehmen und dasselbe Bild als Eingabe für 6 Ansichten verwenden (der Einfachheit halber werden in diesem Artikel nur 3 Ansichten gezeigt). Überraschenderweise generierte BEVDepth unterschiedliche BEV-Merkmale und Erkennungsergebnisse für dasselbe Objekt (d. h. den Bus im Bild unten) in unterschiedlichen Ausrichtungen.
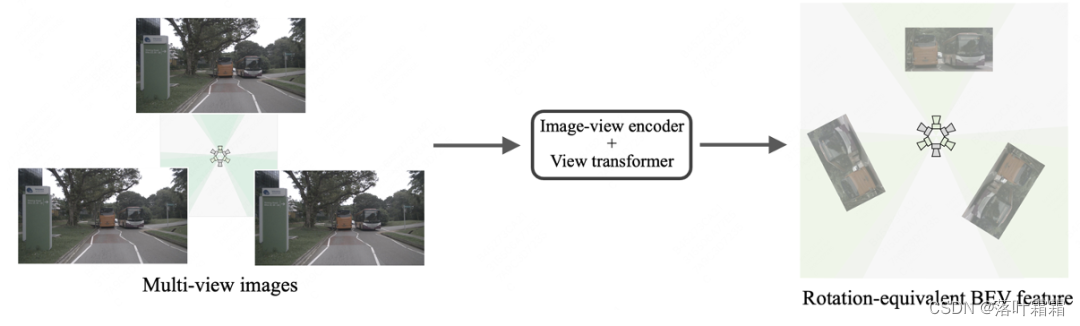
Wir werden die Gründe für die oben genannten Ergebnisse Modul für Modul analysieren. Der Bildencoder und der Perspektivkonverter verarbeiten Bilder jeweils in unterschiedlichen Ausrichtungen, sodass das Bild in BEV-Merkmale mit Rotationsäquivarianz (d. h. radialer Symmetrie) umgewandelt werden kann, wie in der folgenden Abbildung dargestellt: Der
BEV-Encoder und der Erkennungskopf verwenden jedoch traditionelle Faltungs- und ankerfreie Detektionsköpfe für die BEV-Erkennung. Dieses Design ignoriert die radiale Symmetrie von BEV-Merkmalen, was zu unterschiedlichen Features und Vorhersagen für dasselbe Objekt in unterschiedlichen Ausrichtungen führt.
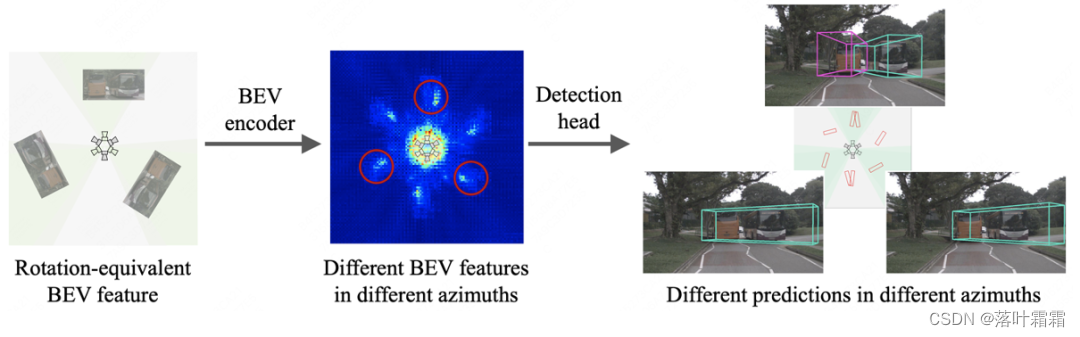
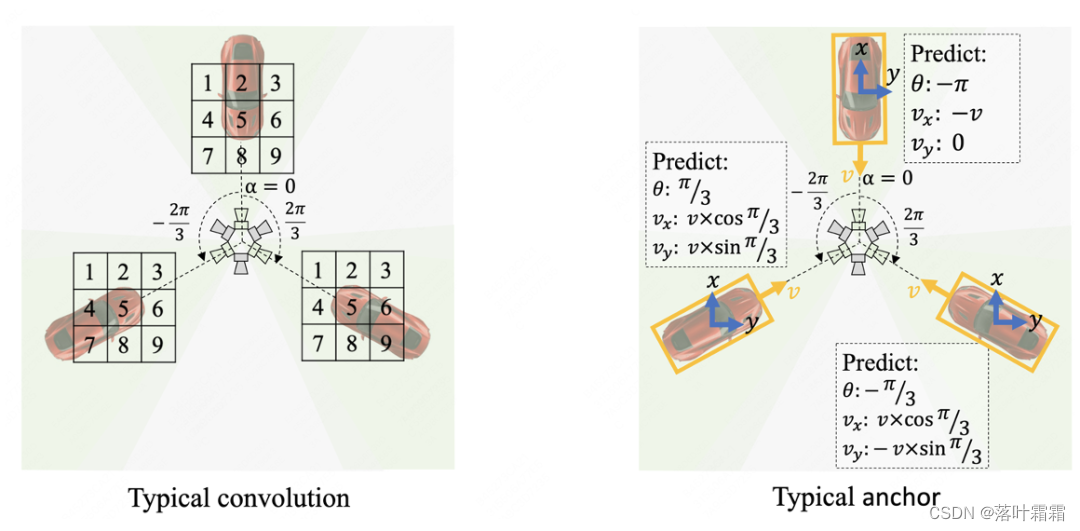
Insbesondere weisen herkömmliche Faltungscodierer und ankerfreie Erkennungsköpfe die folgenden zwei Probleme bei der BEV-Wahrnehmung auf:
1) Wie in der linken Abbildung unten dargestellt, verwenden herkömmliche Faltungscodierer dasselbe Abtastgitter, sodass für rotationsäquivariante BEV-Merkmale abgetastet wird und verschiedene BEV-Merkmale in unterschiedlichen Ausrichtungen erzeugen.
2) Wie in der rechten Abbildung unten dargestellt, sagt der herkömmliche Erkennungskopf die Richtung und Geschwindigkeit des Objekts entlang der Richtung des kartesischen Koordinatensystems (blauer Pfeil) voraus, was dazu führt, dass der Erkennungskopf verschiedene Ziele für dasselbe Objekt vorhersagen muss in verschiedenen Ausrichtungen.
Methode
In diesem Artikel wird ein orientierungsäquivarianter 3D-Objektdetektor mit mehreren Ansichten namens AeDet vorgeschlagen, der darauf abzielt, die BEV-Wahrnehmung (d. h. Repräsentationslernen und -vorhersage) unter verschiedenen Orientierungen zu vereinheitlichen und dadurch die Erkennungsleistung zu verbessern. Diese Methode verarbeitet Mehransichtsbilder über einen Bildencoder und einen Ansichtskonverter, um BEV-Merkmale mit radialer Symmetrie zu erzeugen. Anschließend wird das BEV-Netzwerk basierend auf der azimutäquivarianten Faltung (AeConv) verwendet, um die orientierungsinvarianten BEV-Merkmale weiter zu kodieren, und die orientierungsinvarianten Erkennungsergebnisse werden basierend auf dem azimutäquivarianten Anker vorhergesagt. Die spezifische Struktur ist wie folgt: 2.1
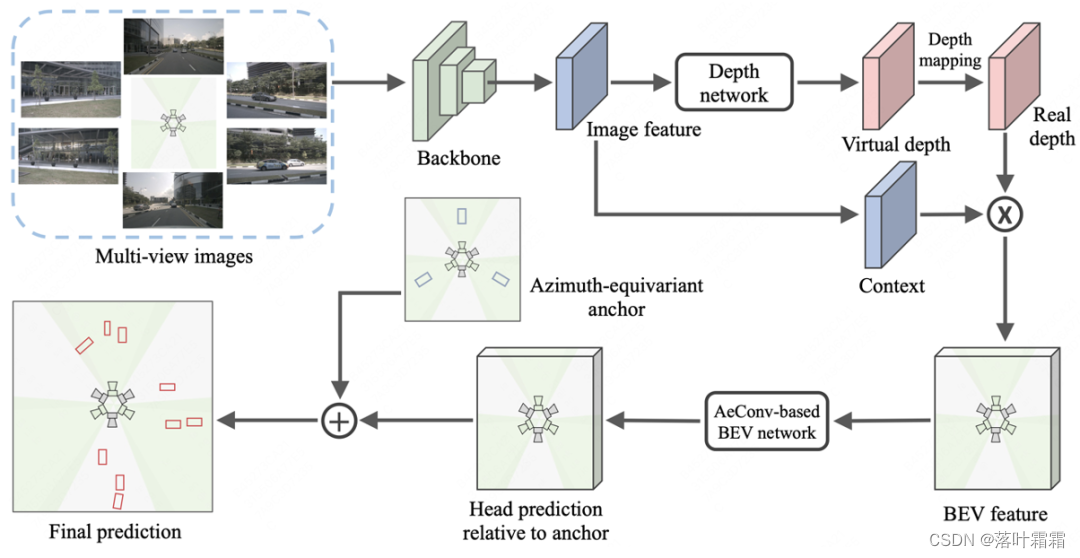
Lernen Orientierungsinvariante BEV-Merkmale
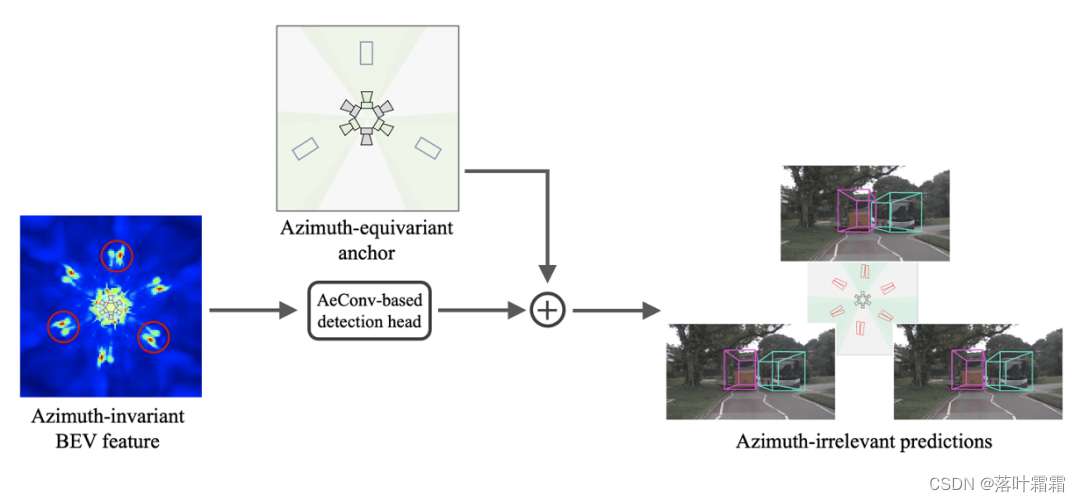
Im Hinblick auf das Lernen orientierungsinvarianter BEV-Merkmale schlägt dieser Artikel eine Methode namens Azimuth Equivariante Convolution (AeConv) vor. AeConv zielt darauf ab, das Lernen von BEV-Features in verschiedenen Ausrichtungen zu vereinheitlichen und die BEV-Darstellung entlang der radialen Richtung der Kamera zu extrahieren. Konkret drehen wir entsprechend dem Azimutwinkel jeder Position das reguläre Abtastgitter der herkömmlichen Faltung entsprechend und führen die Faltungsoperation basierend auf dem gedrehten Abtastgitter durch, wie unten gezeigt:
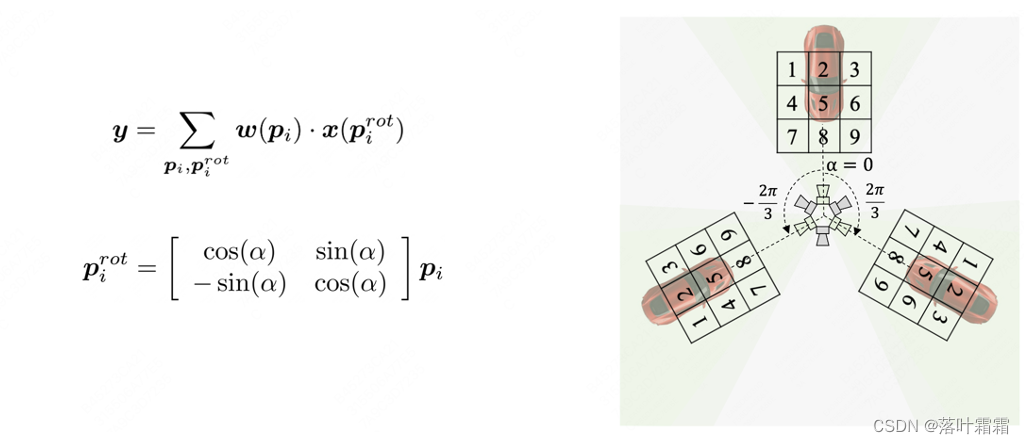
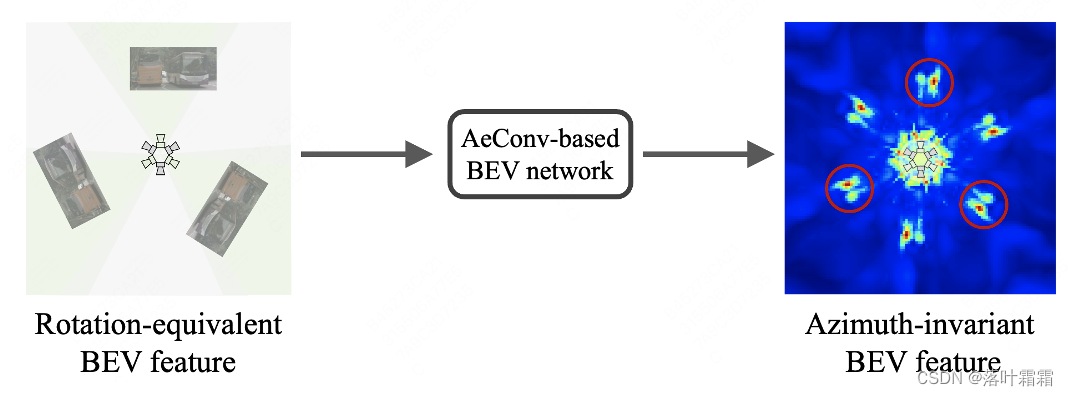
Es ist zu beachten, dass das gedrehte Abtastgitter bei der AeConv-Methode immer entlang der radialen Richtung der Kamera verläuft (wie in der Abbildung oben gezeigt). Daher ist AeConv in der Lage, unabhängig von unterschiedlichen Ausrichtungen dieselben BEV-Merkmale abzutasten und zu lernen, d. h. eine Darstellung mit Azimut-Invarianz. Wir verwenden AeConv anstelle herkömmlicher Faltungsoperationen und bauen ein AeConv-basiertes BEV-Netzwerk auf, um orientierungsinvariante BEV-Merkmale weiter zu kodieren. Diese Methode kann die Genauigkeit und Robustheit der 3D-Objekterkennung mit mehreren Ansichten verbessern.
2.2 Vorhersage des azimutäquivariablen
Ankers des Ziels mit konstantem Azimut: Wir definieren den azimutäquivariablen Anker entsprechend dem Azimutwinkel jeder Position neu und berechnen dann den Erkennungsrahmen und die Geschwindigkeit basierend auf der Richtung des azimutäquivariablen Ankers (blauer Pfeil). Restfehler So erhalten Sie ein azimutunabhängiges vorhergesagtes Ziel:
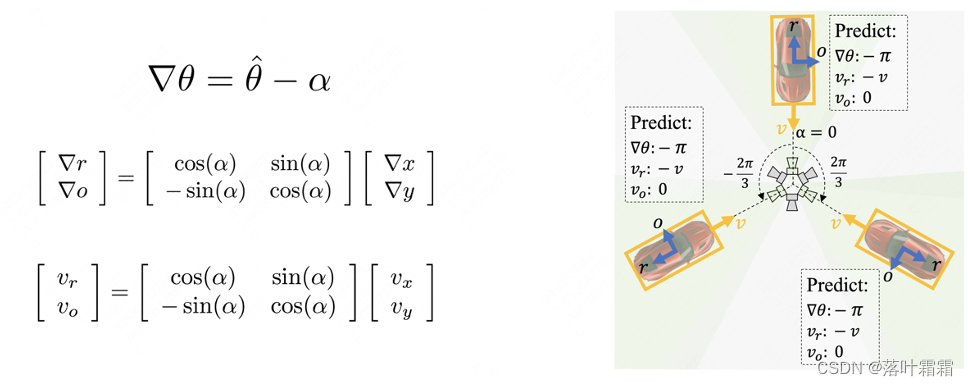
Es ist zu beachten, dass die Richtung des azimutalen äquivariablen Ankers immer in der radialen Richtung der Kamera liegt. Daher kann der Erkennungskopf die Ausrichtung, den Mittenversatz und die Geschwindigkeit des Ziels entsprechend der Richtung der Azimutänderung vorhersagen und so das vorhergesagte Ziel und Ergebnisse unabhängig vom Azimut erhalten:
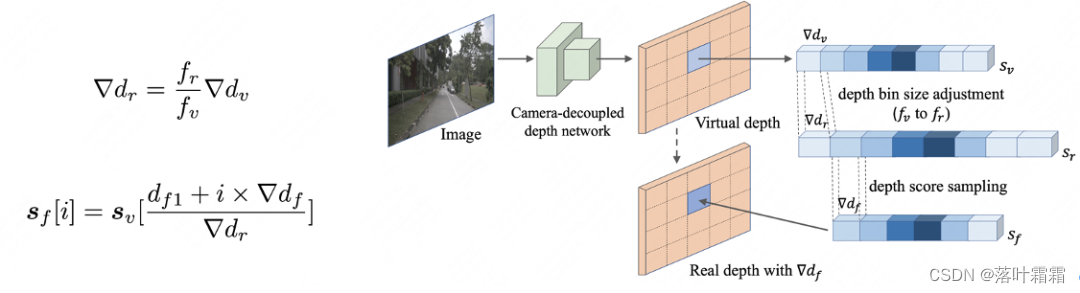
2.3 Die von der Kamera entkoppelte virtuelle Tiefe ist eine neue Methode zur Tiefenvorhersage, nämlich die Kamera Es ist unabhängig von intrinsischen Parametern und kann eine einheitliche Tiefenvorhersage für Bilder mit unterschiedlichen intrinsischen Kameraparametern durchführen. Die spezifische Implementierungsmethode besteht darin, zunächst ein kameraentkoppeltes Tiefennetzwerk zu verwenden, um die virtuelle Tiefe basierend auf der virtuellen Brennweite vorherzusagen. Anschließend wird entsprechend dem klassischen Kameramodell die virtuelle Tiefe in reale Tiefe umgewandelt, sodass die vorhergesagte Tiefe an verschiedene kamerainterne Parameter und Blickwinkel angepasst werden kann. Diese Methode kann die Robustheit und Generalisierungsfähigkeit der Tiefenvorhersage effektiv verbessern.
Experiment
3.1 Vergleich mit SOTA
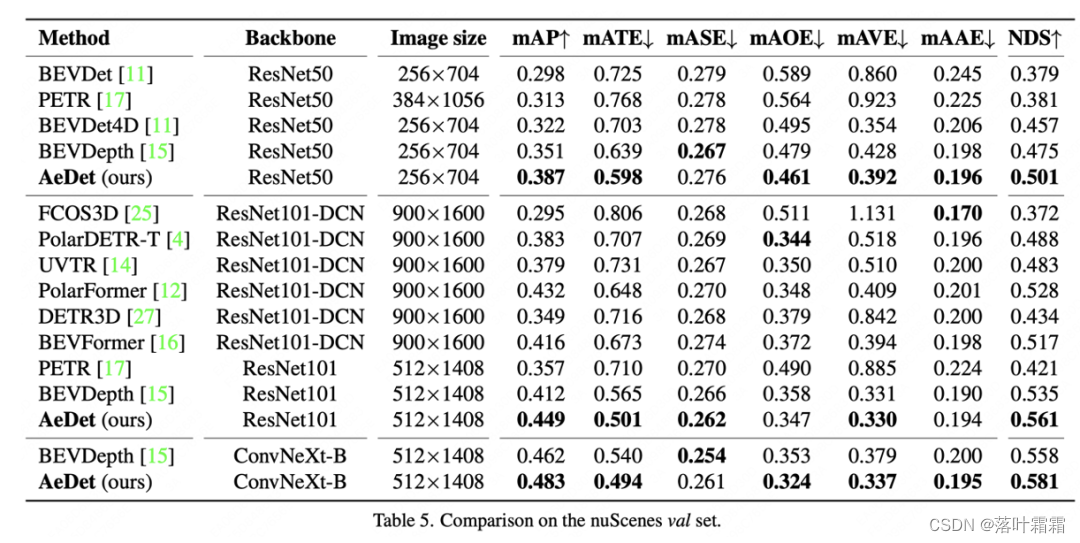
Im Vergleich mit dem nuScenes-Validierungssatz erreichte AeDet 50,1 % NDS und 56,1 % NDS mit ResNet-50 bzw. ResNet-101 und übertraf damit die Leistung des aktuellen Multi-View-3D-Objektdetektors wie BEVFormer (über 4,4). %) und BEVDepth (über 2,6 %).
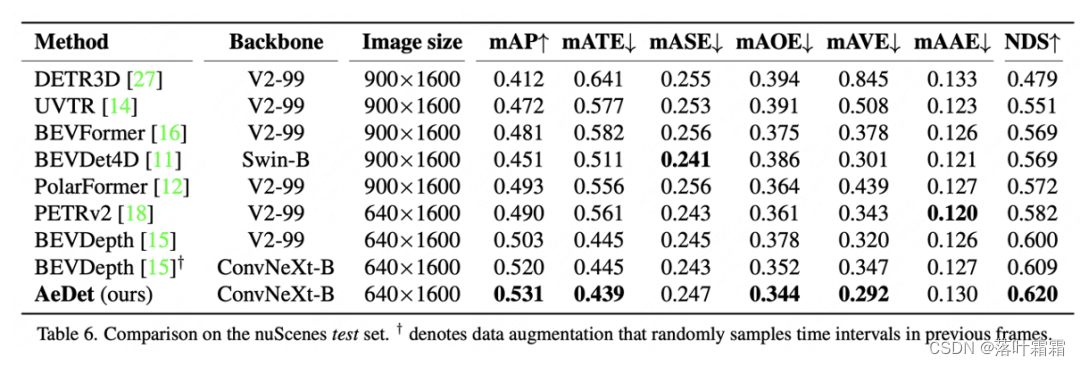
Im Vergleich mit dem nuScenes-Testset verbesserte AeDet mAOE und mAVE um 3,4 % bzw. 2,8 % und erzielte mit 53,1 % mAP und 62,0 % NDS die neuesten fortschrittlichen Ergebnisse bei der Multi-View-3D-Objekterkennung.
3.2 Ablationsexperiment
Im Vergleich zum Basislinien-BEVDepth erhöhte AeNet (Azimut-äquivariante Faltung und Azimut-äquivarianter Anker) die FLOPs nur um 1,7 % und verbesserte NDS um 2 Prozentpunkte (von 44,2) bei gleicher Parameteranzahl. % stieg auf 46,2 %. Darüber hinaus kann das kameraentkoppelte Deep Network (CDN) mAP um 1,5 % und NDS um 1,2 % verbessern.

3.3 Rotationstest
Die Erkennungsrobustheit unterschiedlicher Ausrichtungen ist für autonome Fahrsysteme sehr wichtig, da das Fahrzeug manchmal große Kurven fahren kann. Beispielsweise wird an kleinen Kreisverkehren oder Kurven der Lenkwinkel des Fahrzeugs größer, wodurch sich die Kamerarichtung dramatisch ändert. Autonome Fahrzeuge sollten in verschiedenen Ausrichtungen eine genaue Erkennungsleistung aufrechterhalten. Um die Robustheit des Detektors zu überprüfen, schlagen wir einen Rotationstest vor, um diese Situation zu simulieren: Wir drehen das Fahrzeug um 60 Grad im Uhrzeigersinn, erhalten eine gedrehte Ansicht und bewerten den Detektor in dieser Ansicht. Wie in der Tabelle/Abbildung unten gezeigt, erzeugt BEVDepth in der gedrehten Ansicht andere Vorhersageergebnisse als die Originalansicht und seine Leistung sinkt um 4,6 % NDS, während AeDet in der Originalansicht und der gedrehten Ansicht fast die gleichen Vorhersageergebnisse liefert.


Zusammenfassung
Zusammenfassend wird in diesem Artikel ein Detektor namens AeDet vorgeschlagen, der eine orientierungsinvariante 3D-Zielerkennung mit mehreren Ansichten erreichen soll. Es nutzt eine Vielzahl innovativer Technologien wie Azimut-äquivariante Faltung (AeConv) und Azimut-äquivariante Anker, um eine orientierungsinvariante BEV-Wahrnehmung zu erreichen, und vereinheitlicht die Tiefenvorhersagen verschiedener Kameras durch kameraentkoppelte virtuelle Tiefe. Beim nuScenes-Datensatz erzielt AeDet erhebliche Leistungsverbesserungen und erreicht einen NDS von 62,0 %, übertrifft bestehende Methoden und zeigt überlegene Verbesserungen bei der Objektorientierung und Geschwindigkeitsvorhersage. Diese Arbeit unterstreicht die Wirksamkeit der azimutalen äquivarianten Faltung und der azimutalen äquivarianten Anker bei der Verbesserung der 3D-Objekterkennungsleistung, insbesondere bei Ansichten mit mehreren Kameras.