Ursprünglicher Link: https://arxiv.org/abs/2211.14710
1. Einleitung
Frühe 3D-Objekterkennungsmethoden für Mehransichtsbilder erkennen jede Ansicht separat und kombinieren dann die Erkennungsergebnisse jeder Ansicht. Dabei können jedoch die überlappenden Bereiche benachbarter Kameras nicht genutzt werden, und die separate Erkennung führt zu einem großen Rechenaufwand. Spätere Methoden verwenden ähnliche Methoden wie LSS , um Mehransichtsbilder in BEV-Ausdrücke umzuwandeln. Diese falsch positionierte Ansichtstransformation führt jedoch zu einer Fehlerakkumulation und beeinträchtigt die Erkennungsgenauigkeit.
Mittlerweile verwenden Transformer-basierte Methoden wie DETR eine Reihe erlernbarer 3D-Objektabfragen zur Objekterkennung, ohne dass explizite Ansichtstransformationen erforderlich sind. Es gibt zwei Methoden für die Interaktion zwischen 3D-Abfragen und 2D-Bildfunktionen: projektionsbasierte Methoden und auf Positionskodierung basierende Methoden. Ersteres projiziert 3D-Abfragen auf die Bildebene, um Features abzutasten, was zusätzliche Bereitstellungsarbeit erfordert; es extrahiert nur lokale Features und kann keine globale Kohärenz zur Leistungsverbesserung nutzen. Letzteres wurde erstmals in PETR vorgeschlagen und integriert 3D-Abfragen durch Positionskodierung (PE) in 2D-Bildmerkmale.
Es wird erwartet, dass die Verbesserung von 3D PE die Erkennungsgenauigkeit verbessern wird, sein Design wurde jedoch noch nicht vollständig erforscht. Ein typisches 3D-PE ist ein 3D-Kamerastrahl-PE (wie in (a) unten gezeigt), der die Strahlrichtung vom optischen Zentrum der Kamera zum Bildpixel kodiert, aber die Strahlrichtung liefert nur grobe Positionierungsinformationen, da es keine vorherige Tiefe gibt . Darüber hinaus werden Objektabfragen von zufällig generierten 3D-Referenzpunkten in Einbettungsvektoren umgewandelt, und die räumliche Inkonsistenz der Einbettung zwischen Referenzpunkten und Kamerastrahl-PEs kann die Wirksamkeit des Aufmerksamkeitsmechanismus im Transformer-Decoder beeinträchtigen. Daher muss 3D-PE mit Tiefenpriorität neu gestaltet werden, um 2D-Merkmale zu lokalisieren und einen einheitlichen Ausdruck zu ermöglichen.

In diesem Artikel wird die 3D-Punktpositionskodierung (3DPPE) vorgestellt, um die Leistung der Transformer-basierten 3D-Zielerkennung mit mehreren Kameras zu verbessern. Durch die Einführung von Position Priors verbessert 3DPPE die 3D-Kamera-Ray-PE. Darüber hinaus kann 3DPPE eine bessere Ausdrucksähnlichkeit bieten. Zunächst wird ein Hybrid-Tiefenmodul entwickelt, das direkte Tiefe und kategoriale Tiefe kombiniert, um die Tiefe jedes Pixels zu verfeinern. Anschließend werden die Pixel mithilfe der Kameraparameter und der vorhergesagten Tiefe in 3D-Punkte umgewandelt und in den Positionsencoder eingespeist, um 3DPPE zu erhalten. Die Positionsgeber der oben genannten 3D-Punkte und Referenzpunkte teilen sich Gewichte, um einen einheitlichen Einbettungsraum zu schaffen.
3. Vorbereitende Kenntnisse zur Positionskodierung
3.1. Strahlenbasierte Positionskodierung
Die PETR-Serie stellt eine Methode zum Kodieren von 3D-Koordinateninformationen in Bildmerkmale mit mehreren Kameras vor, um 3D-Positionsmerkmale zu erzeugen. Die 3D-Koordinateninformationen stammen aus einer Reihe von Punkten entlang des Kamerastrahls, einer Methode namens Kamerastrahl-PE. Gegebener Tiefenbereich RD = [ D min , D max ] R_D=[D_{\min},D_{\max}]RD=[ Dm i n,Dm a x] Diskretisieren Sie zunächst die Tiefe mithilfe der linearen Wachstumsdiskretisierung (LID) inND N_D.NDIntervalle und nehmen Sie dann einen Punkt in der Mitte jedes Intervalls entlang des Kamerastrahls, um ND N_D zu erhaltenNDPunkt. Die in jedem Ansichtsbild generierten Punkte befinden sich nach der Koordinatentransformation im selben Koordinatensystem. Die jedem Pixel entsprechenden Punkte werden gespleißt und dann in die Einbettungsschicht eingegeben, um PE zu erhalten.
3.2. 3D-Punktpositionskodierung
Die optimale Positionskodierung muss die wahre 3D-Position des ebenen Punktes erhalten, während die strahlenbasierte Positionskodierung nur die Strahlrichtung kodiert und keine Tiefeninformationen enthält.
Um zu bestätigen, dass der obige Punkt korrekt ist, werden die Pixel unter Verwendung der wahren Tiefe des Bildes in den 3D-Raum projiziert. Die wahre Tiefe ist das Ergebnis der Tiefenvervollständigung nach der Projektion der Punktwolke auf die Bildebene, um eine Karte mit geringer Tiefe zu erhalten. Die Ergebnisse zeigen, dass die Leistung dieser Methode im Vergleich zu Pixel-Ray-PE deutlich verbessert ist, was beweist, dass eine genaue 3D-Position der Schlüssel zur Leistungsverbesserung ist.
Unter normalen Umständen können kamerabasierte Methoden jedoch nicht die wahre Tiefe ermitteln. Daher wird stattdessen ein leichtes Tiefenschätzungsmodul zum Generieren von Tiefenwerten verwendet.
4. Methode
In diesem Artikel wird einheitliches tiefengesteuertes 3DPPE verwendet, um 2D-Merkmale von Bildern mit mehreren Ansichten in den 3D-Raum umzuwandeln.
4.1. Framework-Übersicht
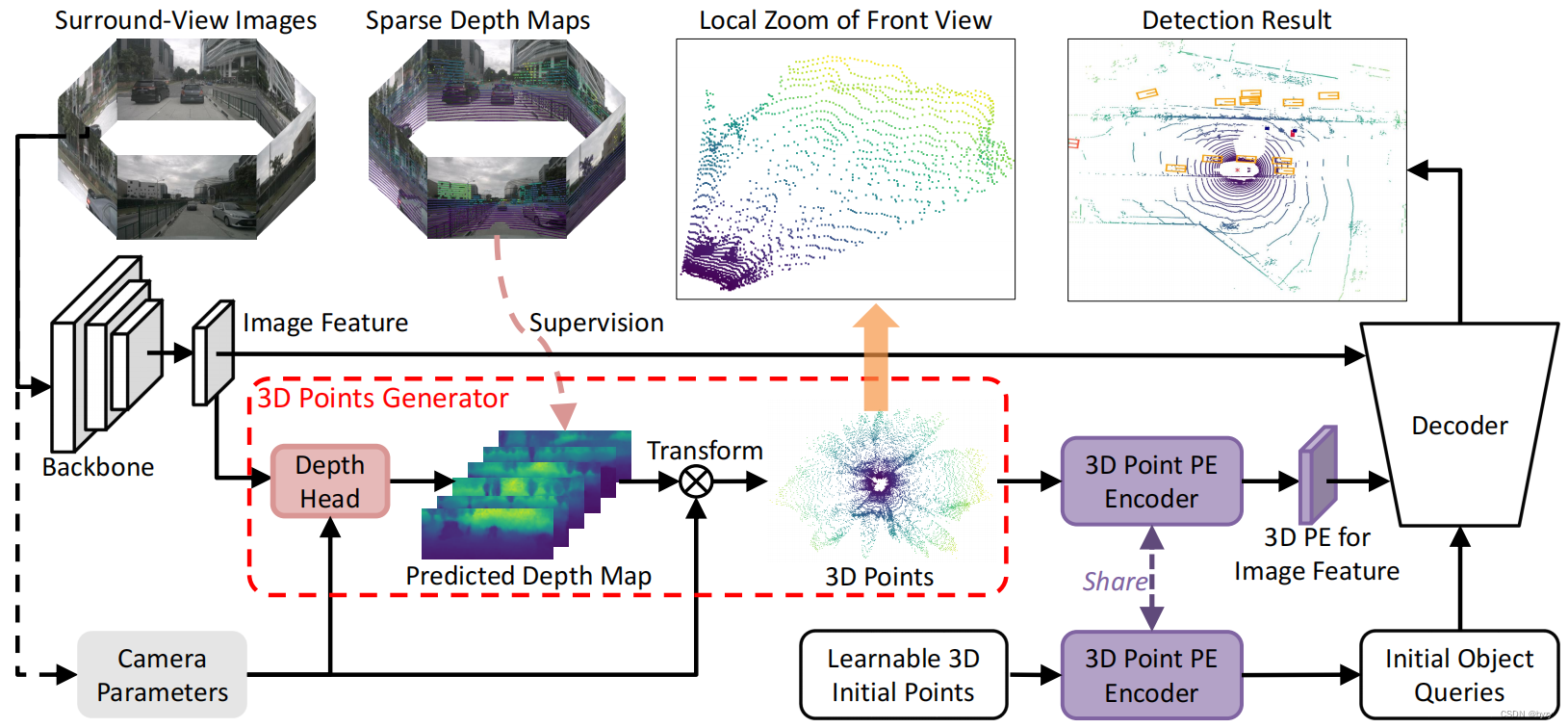 Wie in der obigen Abbildung gezeigt, ist NN gegebenN个环视图图像I = { I i ∈ R 3 × HI i × WI i , i = 1 , 2 , ⋯ , N } \mathbf{I}=\{I_i\in\mathbb{R}^{3\ mal H_{I_i}\times W_{I_i}},i=1,2,\cdots,N\}ICH={
Ichich∈R3 × HICHich× WICHich,ich=1 ,2 ,⋯,N } , geben Sie das Backbone ein, um das BildmerkmalF = { F i ∈ RC × HF i × WF i , i = 1 , 2 , ⋯ , N } \mathbf{F}=\{F_i\in\mathbb{R }^{ C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}F={
Fich∈RC × HFich× WFich,ich=1 ,2 ,⋯,N } . Geben Sie außerdem den Tiefenschätzungskopf in den 3D-Punktgenerator ein, um die dichte TiefenkarteD = { D i ∈ R 1 × HF i × WF i , i = 1 , 2 , ⋯ , N } \mathbf{D}=\{ zu erhalten D_i\ in\mathbb{R}^{1\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}D={
Dich∈R1 × HFich× WFich,ich=1 ,2 ,⋯,N } und in den 3D-PunktP 3D = { P i 3D ∈ R 3 × HF i × WF i , i = 1 , 2 , ⋯ , N } \mathbf{P}^\text{3D}= \{P ^\text{3D}_i\in\mathbb{R}^{3\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}P3D={
Pich3D∈R3 × HFich× WFich,ich=1 ,2 ,⋯,N } . Der gemeinsame 3D-Punkt-PE-Generator kodiert diese Punkte alsPE = { PE i ∈ RC × HF i × WF i , i = 1 , 2 , ⋯ , N } \text{PE}=\{\text{PE}_i \in \mathbb{R}^{C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}SPORT={
PEich∈RC × HFich× WFich,ich=1 ,2 ,⋯,N } . Der 3D-Punkt-PE-Generator kodiert auch lernbare 3D-Referenzpunkte in ObjektabfragenQ = { Q i ∈ RC × 1 , i = 1 , 2 , ⋯ , K } \mathbf{Q}=\{Q_i\in\mathbb {R} ^{C\times 1},i=1,2,\cdots,K\}Q={
Qich∈RC × 1 ,ich=1 ,2 ,⋯,K } , so dassQ \mathbf{Q}Q gegebenPE \text{PE}PE hat einen einheitlichen 3D-Ausdruck. Schließlich können 3D-Abfragen über 3DPPE im Decoder zur 3D-Objekterkennung direkt mit Bildmerkmalen interagieren.
Wie in der obigen Abbildung gezeigt, ist NN gegebenN个环视图图像I = { I i ∈ R 3 × HI i × WI i , i = 1 , 2 , ⋯ , N } \mathbf{I}=\{I_i\in\mathbb{R}^{3\ mal H_{I_i}\times W_{I_i}},i=1,2,\cdots,N\}ICH={
Ichich∈R3 × HICHich× WICHich,ich=1 ,2 ,⋯,N } , geben Sie das Backbone ein, um das BildmerkmalF = { F i ∈ RC × HF i × WF i , i = 1 , 2 , ⋯ , N } \mathbf{F}=\{F_i\in\mathbb{R }^{ C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}F={
Fich∈RC × HFich× WFich,ich=1 ,2 ,⋯,N } . Geben Sie außerdem den Tiefenschätzungskopf in den 3D-Punktgenerator ein, um die dichte TiefenkarteD = { D i ∈ R 1 × HF i × WF i , i = 1 , 2 , ⋯ , N } \mathbf{D}=\{ zu erhalten D_i\ in\mathbb{R}^{1\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}D={
Dich∈R1 × HFich× WFich,ich=1 ,2 ,⋯,N } und in den 3D-PunktP 3D = { P i 3D ∈ R 3 × HF i × WF i , i = 1 , 2 , ⋯ , N } \mathbf{P}^\text{3D}= \{P ^\text{3D}_i\in\mathbb{R}^{3\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}P3D={
Pich3D∈R3 × HFich× WFich,ich=1 ,2 ,⋯,N } . Der gemeinsame 3D-Punkt-PE-Generator kodiert diese Punkte alsPE = { PE i ∈ RC × HF i × WF i , i = 1 , 2 , ⋯ , N } \text{PE}=\{\text{PE}_i \in \mathbb{R}^{C\times H_{F_i}\times W_{F_i}},i=1,2,\cdots,N\}SPORT={
PEich∈RC × HFich× WFich,ich=1 ,2 ,⋯,N } . Der 3D-Punkt-PE-Generator kodiert auch lernbare 3D-Referenzpunkte in ObjektabfragenQ = { Q i ∈ RC × 1 , i = 1 , 2 , ⋯ , K } \mathbf{Q}=\{Q_i\in\mathbb {R} ^{C\times 1},i=1,2,\cdots,K\}Q={
Qich∈RC × 1 ,ich=1 ,2 ,⋯,K } , so dassQ \mathbf{Q}Q gegebenPE \text{PE}PE hat einen einheitlichen 3D-Ausdruck. Schließlich können 3D-Abfragen über 3DPPE im Decoder zur 3D-Objekterkennung direkt mit Bildmerkmalen interagieren.
4.2. 3D-Punktgenerator
Hybrides Tiefenmodul : Inspiriert von BEVDepth entwirft dieser Artikel ein hybrides Tiefenmodul, das direkt die Tiefe DR ∈ RHF × WFD^R\in\mathbb{R}^{H_{F}\times W_{F}} zurückgibt.DR∈RHF× WFMit Klassifikationstiefe DP ∈ RHF × WFD^P\in\mathbb{R}^{H_{F}\times W_{F}}DP∈RHF× WFVerwenden Sie lernbare Gewichte α \alphaα für die Fusion, wie in der Abbildung unten gezeigt.

Vereinfacht ausgedrückt ist der Tiefenraum[ d min , d max ] [d_{\min},d_{\max}][ dm i n,Dm a x]离散为ND = d max − d min d Δ N_D=\frac{d_{\max}-d_{\min}}{d_\Delta}ND=DDDm a x− dm i nEine Größe von d Δ d_\DeltaDD的区间D = { d 1 , d 2 , ⋯ , d ND } \mathbf{D}=\{d_1,d_2,\cdots,d_{N_D}\}D={
d1,D2,⋯,DND} Sagen Sie anschließend die WahrscheinlichkeitsverteilungP ∈ RND × HF × WFP jedes Pixels in jedem Tiefenintervall gemäß der Klassifizierungsmethode\in\mathbb{R}^{N_D\times H_{F}\times W_{F}} voraus.P∈RND× HF× WF, die erwartete Nachfrage danach: DP = ∑ i = 1 NDP u , v , i × di D^P=\sum_{i=1}^{N_D}P_{u,v,i}\times d_iDP=ich = 1∑NDPu , v , i×Dich Das endgültige Ergebnis der Tiefenschätzung ist D pred = α DR + ( 1 − α ) DPD^\text{pred}=\alpha D^R+(1-\alpha)D^PDVor=α DR+( 1−a ) DPDiese Tiefenschätzung verwendet eine echte Tiefenkarte D gt D^\text{gt},die aus einer Punktwolke generiert wurdeDgt wird als Überwachungssignal verwendet und die Verlustfunktionen sind Smooth L1 Loss bzw. Distributed Focal Loss:L Depth = λ sm L SmoothL1 ( D pred , D gr ) + λ dfl L dfl ( D pred , D gr , D ) L_\text{Tiefe }=\lambda_\text{sm}L_\text{SmoothL1}(D^\text{pred},D^\text{gr})+\lambda_\text{dfl}L_\text{dfl }(D^\text{pred},D^\text{gr},\mathbf{D})LTiefe=lsmLSmoothL1( Dvor _Dgr )+ldflLdfl( Dvor _Dgr ,D ) wobeiλsm \lambda_\text{sm}lsm和λ dfl \lambda_\text{dfl}ldflist der Hyperparameter, L dfl L_\text{dfl}LdflDas Ziel besteht darin, zwei Tiefenintervalle in die Nähe des wahren Tiefenwerts zu bringen ( di < D gt < di + 1 d_i<D^\text{gt}<d_{i+1}Dich<Dgt<Dich + 1)概率最大: L dfl ( D pred , D gr , D ) = − di + 1 − D gt d Δ log ( P i ) − D gt − did Δ log ( P i + 1 ) L_\text{dfl }(D^\text{pred},D^\text{gr},\mathbf{D})=-\frac{d_{i+1}-D^\text{gt}}{d_\Delta}\ log(P_i)-\frac{D^\text{gt}-d_i}{d_\Delta}\log(P_{i+1})Ldfl( Dvor _Dgr ,D )=−DDDich + 1−Dgtlo g ( Pich)−DDDgt−Dichlo g ( Pich + 1)
Koordinatentransformation von 2D nach 3D: SeiK i ∈ R 3 × 3 K_i\in\mathbb{R}^{3\times3}Kich∈R3 × 3 ist TeilIIInterne Parametermatrix von i Kameras,R i ∈ R 3 × 3 R_i\in\mathbb{R}^{3\times3}Rich∈R3 × 3和T i ∈ R 3 × 1 T_i\in\mathbb{R}^{3\times1}Tich∈R3 × 1 jeweils ausiiRotationsmatrix und Translationsmatrix vom i-ten Kamerakoordinatensystem zum Lidar-Koordinatensystem,P i 3D ( u , v ) ∈ R 3 × 1 P^\text{3D}_i(u,v)\in\mathbb{R} ^{ 3\times1}Pich3D( du ,v )∈R3 × 1 2._i Kamerapixel(u, v) (u,v)( du ,v )对应的3D点,则P i 3D ( u , v ) = R i K i − 1 D i pred ( u , v ) [ uv 1 ] T + T i P^\text{3D}_i(u, v)=R_iK_i^{-1}D_i^\text{pred}(u,v)\begin{bmatrix}u\\v\\1\end{bmatrix}^T+T_iPich3D( du ,v )=RichKich− 1DichVor( du ,v )
uv1
T+Tich Zum Schluss normalisieren Sie entsprechend dem 3D-Erfassungsbereich: P i , p 3D ( u , v ) = ( P i , p 3D ( u , v ) − p min ) / ( p max − p min ) , p ∈ { x , y , z } P^\text{3D}_{i,p}(u,v)=(P^\text{3D}_{i,p}(u,v)-p_{\min })/(p_{\max}-p_{\min}), \ \ p\in\{x,y,z\}Pich , p3D( du ,v )=( Sich , p3D( du ,v )−Pm i n) / ( Sm a x−Pm i n) , P∈{
x ,y ,z }
4.3. 3D-Punkt-Encoder
Setze den 3D-Punkt P 3D P^\text{3D}P3D- Import 3D-Punktübertragung 3DPPE:PE i ( u , v ) = MLP ( Cat [ Sinus ( P i , x 3D ( u , v ) ) , Sinus ( P i , y 3D ( u , v ) ) , Sinus ( P i , z 3D ( u , v ) ) ] ) \text{PE}_i(u,v)=\text{MLP}(\text{Cat}[\text{Sinus}(P^\text{3D }_ {i,x}(u,v)),\text{Sinus}(P^\text{3D}_{i,y}(u,v)),\text{Sinus}(P^\text {3D }_{i,z}(u,v))])SPORTich( du ,v )=MLP ( Katze [ Sinus ( Pich , x3D( du ,v )) ,Sinus ( Sich , y3D( du ,v )) ,Sinus ( Sich , z3D( du ,v ))]) , wobei die Sinus- und Cosinus-PositionscodesSinus \text{Sinus}Sinus ordnet 1D-KoordinatenC/2 C/2C /2- dimensionaler Vektor, MLP mit zwei linearen Schichten und einer ReLU\text{MLP}MLP wird3C/2 3C/23 C /2- dimensionaler Vektor, abgebildet aufCCC- dimensionaler Vektor.
4.4. Merkmale der 3D-Punktwahrnehmung
Fügen Sie 3DPPE- und Bildmerkmale Element für Element hinzu, um das 3D-Erfassungsmerkmal F 3D F^\text{3D} zu erhaltenF3D。
4.5. Änderungen am Decoder
Die lernbaren 3D-Referenzpunkte werden wie zuvor in denselben Encoder eingespeist, um 3DPPE EQE^Q zu generierenEQ , QQabfragenF. _ DaherEFE^FEF undEQE^QEQ stammt aus demselben Einbettungsraum, wodurch die Abfrage weiter verbessert wird.
5. Experimentieren
5.1. Vergleich mit der SotA-Methode
Im Vergleich zu PETR führt die Einführung von 3DPPE zu einer größeren Leistungsverbesserung, was auf die Vorteile von 3DPPE gegenüber Camera Ray PE hinweist.
5.2. Ablationsstudien
Auswirkungen der Tiefenqualität : Im Vergleich zu ohne Tiefenüberwachung führt die Einführung von L SmoothL1 L_\text{SmoothL1}LSmoothL1和L dfl L_\text{dfl}LdflBeides kann die Leistung verbessern.
Vergleich der 3D-Positionserkennungsfunktionen : Im Vergleich zu Camera Ray PE weist unser 3DPPE eine bessere Leistung auf.
Die Rolle des gemeinsam genutzten 3D-Punkt-Encoders : Durch experimentellen Vergleich mit dem nicht gemeinsam genutzten Encoder weist die Methode zur gemeinsamen Nutzung des Encoders in diesem Artikel eine bessere Leistung auf.
5.4. Diskussion weiterer Verbesserungen
Nutzung der zeitlichen Konsistenz : Durch die zeitliche Konsistenzmodellierung erzielt 3DPPE eine bessere Leistung.
Verwenden der GT-Tiefe für die Wissensdestillation : Trainieren Sie zunächst ein 3DPPE-Modell mit Deep Supervision, genannt 3DPPE-Oracle, und fügen Sie dann beim Training des Destillationsmodells 3DPPE-destillieren einen zusätzlichen Zweig zum Transformer-Decoder hinzu, wobei Sie die Gewichte mit dem ursprünglichen Zweig teilen, ihn aber abfragen Referenzpunkt Es wird so initialisiert, dass es mit 3DPPE-Oracle identisch ist (es wird während des Trainings nicht feinabgestimmt) und wird sowohl durch den Ground-Truth-Begrenzungsrahmen als auch durch die Vorhersageergebnisse von 3DPPE-Oracle überwacht. Experimente zeigen, dass Destillationsmodelle die Leistung verbessern.
Anhang
C. Analyse der 3D-Positionskodierung
C.1. 3D-Kamerastrahl PE
Experimente, die mit verschiedenen Tiefenbereichen, der Anzahl der Tiefenintervalle und Tiefenraumdiskretisierungsmethoden durchgeführt wurden, ergaben, dass die Ergebnisse nahezu unverändert waren. Daher bleibt die Leistung des Kamerastrahl-PE nahezu unverändert, solange die Richtung des Kamerastrahls dargestellt werden kann. Daher kann PE mit nur zwei Punkten auf dem Kamerastrahl durchgeführt werden.
C.2. Lidar-Ray-PE-Annahme
Wenn die Anzahl der Tiefenintervalle auf 1 festgelegt ist und für Experimente unterschiedliche Tiefenwerte ausgewählt werden, verringert sich die Leistung bei kleinerer Tiefe, bei größerer Tiefe bleibt die Leistung jedoch grundsätzlich unverändert. Dies weist darauf hin, dass es sich zu diesem Zeitpunkt nicht mehr um das Kamera-Ray-PE handelt. Da zur Bestimmung des Strahls zwei Punkte erforderlich sind und der Ursprung des LIDAR feststeht, kann der LIDAR-Strahl von einem Punkt aus bestimmt werden. Berechnen Sie die Differenz Dis
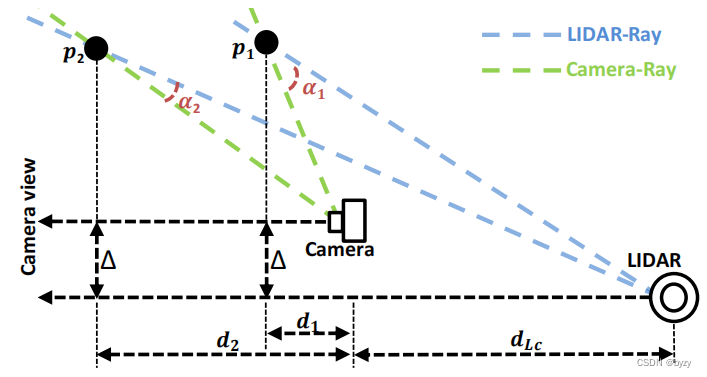
zwischen Kamerastrahlen und Lidarstrahlen gemäß der Abbildung oben \text{Dis}Dis :Dis = 1 − cos ( α ) = 1 − cos ( α c − arctan ( tan α c + Δ d 1 + d L cd ) ) ≈ 0,0 , wenn d ≫ d L c und d ≫ Δ \text{Dis}=1-\cos(\alpha)=1-\cos(\alpha_c-\arctan(\frac{\tan\alpha_c+\frac{\Delta}{d}}{1+\frac{d_ {L_c}}{d}}))\about0.0,\ \ \text{wenn }d\gg d_{L_c}\text{ und } d\gg \DeltaDis=1−cos ( α )=1−weil ( einc−arctan (1+DDLcbräunenAc+DD))≈0,0 , wenn d≫DLc und d≫Δwobeiα c \alpha_cAcist der horizontale Winkel des Kamerastrahls, α \alphaDer Winkel zwischen dem Alphakamerastrahl und dem Lidarstrahl. Die obigen Ergebnisse zeigen, dass, wennddWenn d sehr groß ist, ist der Lidar-Strahl im Wesentlichen derselbe wie der Kamerastrahl und kann mit dem Kamerastrahl PE übereinstimmen, wenn nur ein Punkt vorhanden ist.