1. Description
The concept of jailbreaking large language models (LLMs) such as GPT-4 represents a difficult challenge in the field of artificial intelligence. This process requires the strategic manipulation of these advanced models to transcend their predefined ethical guidelines or operational boundaries. In this blog, my aim is to dissect the mathematical complexity and provide practical mathematical tools for jailbreaking, thus enriching our understanding of this phenomenon.

2. Common techniques commonly associated with jailbreak attempts
In this blog, I am not going to introduce DAN or STAN, which are already covered enough in other materials, nor am I going to introduce the basics of jailbreaking. Below is an overview of these technologies.
Prompt production:This involves designing the prompt in a way that attempts to exploit potential weaknesses or vulnerabilities in the model response filter. This may include the use of coded language, indirect references, or specific wording designed to mislead the model.
Iterative refinement: Some users may try to iteratively refine their prompts based on the model's responses, gradually steering the conversation toward restricted areas or testing the limits of the model's response guidelines .
Context obfuscation: This technique involves embedding the actual request into a larger, seemingly innocuous context, in an effort to mask the true intent of the query from the model's filtering mechanism .
Social Engineering:In some cases, users may attempt to interact with models in ways that mimic social engineering tactics, such as building rapport or trust in an attempt to trick the model into breaking themselves the rule of.
The paper titled "Cracking ChatGPT via Promo Engineering: An Empirical Study" provides a good taxonomy and methodology for preliminary research .
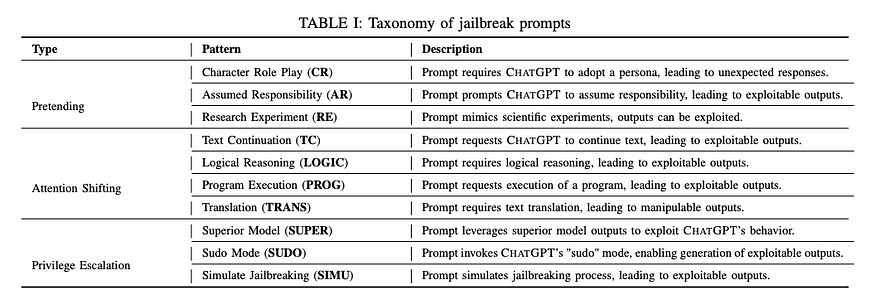
Everything covered in this blog is advanced mathematics and toolkits for optimizing and designing better jailbreak mechanisms.
3. Mathematical framework of rapid engineering
Just-in-time engineering is a highly complex technology that requires inputs to be strategically formulated to guide the LLM to produce specific outputs, which may include prohibited or unintended content. In this section, I intend to expand the mathematical framework of just-in-time engineering, introducing more complex equations and concepts.
Mathematical formulas for just-in-time engineering
Treat LLM as a functionF and promptPMap to outputO. The process of just-in-time engineering can be conceptualized as a complex optimization problem whose goal is to refinePto achieve a predetermined outputO_Goal. This optimization problem can be expressed mathematically as:
![]()
Here, the function "Score" is a complex metric that quantitatively evaluates F ( P ) Alignment with O_ target. This function can be further refined as:
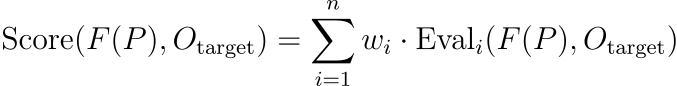
. are separate evaluation functions that evaluate different aspects of alignment, such as semantic coherence, relevance, and subtlety.
Incorporating advanced linguistic indicators
To increase the complexity of just-in-time engineering, high-level language metrics can be integrated into the evaluation function. For example, semantic coherence can be assessed using sentence embedding-based metrics:
![]()
Among them, Embed represents a function that converts text into a high-dimensional vector space, and CosineSimilarity measures the cosine of the angle between these vectors, indicating the degree of semantic similarity.
Optimization technology
Optimization of P can involve gradient-based methods, where a "score" function is calculated with respect to P's gradient to iteratively refine the prompt. This can be expressed as:
![]()
- P_new represents an updated prompt.
- P is the original prompt.
- η represents the learning rate, which is a scalar that determines the step size in the optimization process.
- ∇ P Score( F ( F a> target) is the "Score" function relative to the prompt< /span> a> targetO_ gradient. This gradient indicates the direction in which the prompt should be adjusted to maximize the "score" function, which measures the alignment of the LLM's output with the target outputPO ), P
This is a full paper onAutomated Hint Optimization using Gradient Descent and Beam Search.
Real-life examples with advanced considerations
A practical example of prompt engineering might involve building a prompt that appears neutral but is complexly designed to take advantage of the pattern recognition capabilities of the model. This may involve using a combination of syntactic structures and semantic cues that are known to trigger specific responses in the model. Advanced "scoring" features can be used to evaluate the effectiveness of such prompts, ensuring that the generated content is neatly aligned with the intended unethical or prohibited output, while maintaining a neutral appearance.
Oh, you thought I was going to show you an example of a prompt like this so you can run a jailbreak? Bad luck ;)
You can find a bunch of tips here: jailbreakchat.com (most of them don’t work because they are already available in LLM Active fix)
4. Exploiting inherent model biases
Methods for exploiting inherent model biases in LLM involve a deep understanding of the biases arising from the model training data. These biases can be used strategically to derive specific responses from the model. The mathematical framework of this approach can be expanded to include more complex equations and concepts.
Mathematical Perspective
Bias vector formula:Let us consider the bias vector in the modelB. This vector represents the directional trend of the model's response based on its training data. The outputO given the inputI can be expressed as being affected by this bias Function of:
![]()
Here, ϵ ( B ) is a perturbation function along the bias vector < /span>The direction of the alignment modifies the output. B
Gradient ascent of bias amplification: In order to amplify the impact of bias, we can use the gradient ascent method. The inputI is iteratively adjusted to maximize the alignment of the output with the bias vector. This can be expressed mathematically as:
![]()
In this equation, α is the learning rate, ∇ I Score( F ( I ), . The "score" function measures how well the output matches the desired deviation. I ) is the gradient of the "Score" function relative to the inputB
Complexity of bias representation:In order to increase depth, we can consider a multi-dimensional bias space, whereB is a matrix representing various deviation dimensions. The perturbation functionϵcan be a more complex function, possibly involving nonlinear transformations to capture the complex ways in which bias manifests itself in the model output.
Probabilistic modeling of bias effects:We can also introduce probabilistic models to capture the uncertainty of how bias affects model output. For example, perturbationϵ ( B ) can be modeled as a stochastic process, Add a layer of probabilistic reasoning to bias exploitation.
Real-life examples with advanced considerations
Consider a scenario where a model has a known bias towards a specific political ideology. Our goal is to craft inputs that are not only consistent with this bias, but also amplify it in the model's output. Use advanced mathematical frameworks:
- We first identify the bias vector corresponding to political ideologyB.
- We then iteratively adjust the inputI using gradient ascent, guided by the multidimensional bias space and probabilistic perturbation model.
- The process involves calculating the gradient of a "fractional" function in this complex bias space, taking into account both the deterministic and stochastic components of the bias effect.
This advanced approach allows for more nuanced and efficient use of biases in the LLM, resulting in outputs that are more consistent with the desired biases, while also accounting for the inherent complexity and uncertainty of how biases affect model behavior.
5. Circumvention of security mechanisms
The process of circumventing LLM security mechanisms involves a deep understanding of the model's security protocols and identifying ways to exploit its vulnerabilities. This section extends the mathematical framework of this approach, introducing more complex equations and concepts.
Mathematical Perspective
Security protocol function:UsedS to represent the model outputO’s security protocol function. This feature is designed to reduce harmful or undesirable output. Mathematically, a security protocol can be expressed as:
![]()
这り、O_ safeは对原输下F ( I ) After the safety check, the export will take place.
The objective function of evading security protocols:The goal is to find an inputI such that the security protocol /span>Cannot eliminate harmful aspects of the output. This can be formulated as an optimization problem:S
![]()
The "score" function here measures the effectiveness of the input I in generating output that is harmful but bypasses security protocols.
Combat constraints are satisfied: Optimization problem should be subject to i It is an effective input constraint. This can be expressed using the constraint function C ( I ), which ensures IAdhere to certain predefined standards:
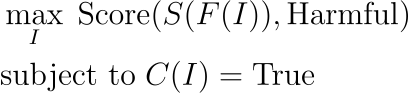
it's here,
- max_ I: Represents the maximization process of the input variable I.
- Score( S ( F ( 's effectiveness in terms of export. SProduced Harmfully However, This Safety GuideII )),Harmful):测输输入
- subject to C ( I )=True: Promise to improve the problem, guarantee deliveryIful certain trivial conditions (useC(I) display).
Advanced optimization techniques:In order to solve this constrained optimization problem, advanced techniques such as Lagrange multipliers or penalty methods can be used. These methods allow constraints to be incorporated into the optimization process, ensuring that the solution respects the validity of the inputs.
Probabilistic modeling of security protocol effectiveness:Introducing a probabilistic model to estimate the likelihood of inputs that bypass security protocols can increase the depth of analysis. This involves modeling the effectiveness of security protocols as a stochastic process, adding a layer of uncertainty to evasion strategies.
Actual examples of high -level consideration: Consider a scene, where the target is to design input, which can produce harmful outputs in a manner that cannot be detected by a safe filter. Use advanced mathematical frameworks:
- InputIIteratively adjust using optimization techniques, taking into account both the "score" function and the constraint functionC ( I ).
- The process involves balancing the maximization of a "score" function with the satisfaction of constraints, ensuring that inputs remain valid while effectively bypassing security protocols.
- Probabilistic models can be used to estimate the likelihood of successfully bypassing security protocols, guiding the optimization process.
This advanced approach can provide more nuanced and effective strategies in circumventing LLM's security mechanisms, providing a deeper understanding of vulnerabilities in these systems and how to exploit them while adhering to input validity constraints.
6. Advanced jailbreak technology
To deepen the discussion of advanced jailbreaking techniques and incorporate more complex mathematical equations, we can expand on each of the above techniques:
adversarial machine learning
Adversarial machine learning in the context of LLM often involves creating input data that is slightly perturbed to mislead the model.
This can be expressed mathematically as:
![]()
WhereI is the original input, δ is the small Perturbation, I_ adv is an adversarial input. The goal is to find δ such that the output of the model changes significantly. The optimization problem can be formulated as:
![]()
Among them,Lis a lapse function, and the use of the equilibrium model outF< a i=4> ( I + δ ) /span> targetdifferent. Y_
Generative Adversarial Network (GAN)
GAN consists of two competing neural networks: generatorG and discriminatorD . The generator aims to generate data that is indistinguishable from real data, while the discriminator attempts to differentiate between real and generated data. The objective function of GAN can be expressed as:
![]()
Here,
- min G; represents the minimization process on the generator network G.
- max D; represents the maximization process on the discriminator network D.
- E x 〜 p_ data( )] It is the true number of the original expectation, the equal weight division is the true number of the fixed number. x ( D )[log x
- E z 〜 p_z ( ( D )[log(1− z
Generational Consciousness Adjustment Strategies
The generation-aware alignment method aims to improve the model’s defense against attacks that exploit its generation capabilities. This method actively compiles examples using various decoding configurations. In detail, for a given language modelfθ and promptp, the model is passed from h ( fθ , . rp ) samples to generate the output sequence
Here, h is the decoding strategy set H decoding strategy that converts the model's predicted probability of subsequent tokens based on cue p into tokens in vocabulary V sequence. In this process, perceptual alignment is generated to collectndifferent responses for each promptp, expressed as:
![]()
ℎ, ri , h , fθ< /span> , Not shown yet. The purpose of understanding the various generations is to establish a fundamental rehabilitation method and to reduce the land mass to the maximum extent possible. mRp Display the message (or application) for the message,ath ip ) 目 , fθ ( h ) Displayp , ( h ~ p
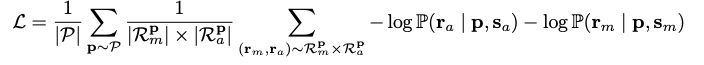
This equation represents the loss function L, which is used to generate the model. It is the average of a set of prompts P, and for each promptp , it is calculated from the set of unaligned and aligned responsesRmp and Rap response pair ( rm , represent scenarios of aligned and misaligned responses or condition. During model training, the loss function is minimized to improve consistency with the desired results. Sm and Sa ), respectively. ra
This is a complete paper ondisastrous jailbreak of open source LLM by exploiting a generation.
Neural network interpretability
The decision-making process of neural networks can be understood through techniques such as layered correlation propagation (LRP) or Shapley value analysis. For example, LRP decomposes the output decision into the contribution of each input feature, which can be expressed as:

Where,Ri is the correlation of neuroni, ai is its activation value, wij is the neuronij, Rj is the subsequent layer Correlation between neuronj. This decomposition helps trace the decision-making process.
These mathematical formulas provide a deeper and more sophisticated understanding of the advanced techniques used in Jailbreak LLM, highlighting the complex interplay between algorithm design and model development.
7. Ethical Impact and Countermeasures
Let’s discuss in more depth the ethical implications and countermeasures associated with jailbreaking.
Robust training
Robust training may involve adding adversarial examples to the training data set. This introduces perturbations into the input data to ensure the model is robust against potential adversarial attacks. Mathematically, this can be expressed as:
![]()
it's here,
- min θ display model numberθ targetminimization process.
- E( x , y )〜Data Display the abstract number in the distribution ( x , y ) expectations.
- L is the loss function that measures the performance of the model.
- f ( x ; θ ) Indicator entry numberθ's entryx's model exit.
- λ controls the impact of adversarial examples in training.
- E x ′∼Adversarial represents an adversarial example drawn from an adversarial distribution′ x ′’s expectation.
This equation embodies the goal of training a model to be robust to adversarial examples by minimizing the loss while taking into account both real and adversarial data.
dynamic security protocol
Developing adaptive security mechanisms may involve reinforcement learning techniques. For example, consider a Markov decision process (MDP), where the operation of the model affects the security of the generated content. Goals can be defined as:
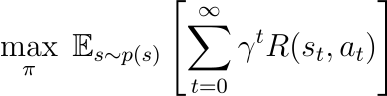
it's here,
- max_ π represents the maximization process of security policyπ.
- E s 〜 p ( s )Display condition distributionp ( s ) the desired situation and hope.
- Sum Σ t =0..Infini As the time step t extends from 0 to infinity.
- γt represents the discount factor of time stept reward.
- R ( st , at ) - Activities are encouraged.
This equation reflects the goal of reinforcement learning in the context of dynamic security protocols, where the policyπ is optimized to maximize over an infinite time horizon Expected cumulative rewards.
transparency and oversight
Ethical Compliance Index: To ensure ethical compliance, the Ethical Compliance Index (ECI) can be mathematically defined as a combination of factors such as fairness, reduction of bias, and consistency with ethical principles. This can be expressed as:
![]()
In this equation:
- ECI stands for Ethical Compliance Index, which is a comprehensive measure of ethical performance.
- α, β and γ is the weighting factor that determines the relative importance of fairness, bias mitigation, and moral consistency respectively.
- Fairness, bias mitigation, and ethical consistency are separate indicators or scores related to these ethical considerations.
By integrating these complex mathematical representations, we deepen our understanding of jailbreaking countermeasures while addressing ethical issues, thereby enhancing the robustness and ethical compliance of LLM.
8. Mathematical modeling of other jailbreak strategies
Bayesian Probability Model
A probabilistic model can estimate the likelihood of a prompt leading to a jailbreak. Using Bayesian modeling, we can compute the hintP that leads to a jailbreak given the observed dataD Posterior probability of J:
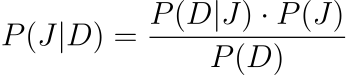
Here,
- P ( J ∣ D ) Approximate conditions for the condition shown in the table below.
- P ( D ∣ J ) There is a possibility that there will be a new number.
- P ( J ) is the prior probability of jailbreak.
- P ( D ).
This equation is commonly used in Bayesian probability to calculate the posterior probability of an event (in this case, a jailbreak) based on observed data and a prior probability.
Game theory applications
Game theory can model the interaction between jailbreakers and LLM developers. Consider a two-player game where the jailbreaker and the developer each choose a strategy. A Nash equilibrium is defined as a set of strategies in which no player can improve the outcome by unilaterally changing their strategy. Mathematically:
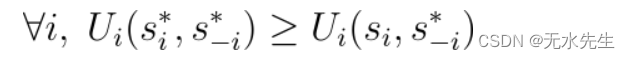
it's here,
- ∀ i means "for all i ", Indicate that the following statements apply to all players in the gamei .
- Ui represents the utility or benefit function of playeri.
- si* sums* − i< /span> This is an equilibrium (纳什线性) lower strategy placement sentence.
- siis a playmakeri's strategy.
- s* − i means excluding playersi Except for the strategy profiles of all other players.
These expressions express the conditions for a Nash equilibrium, where it is assumed that all other players stick to their equilibrium strategiess* − si to improve its effectiveness. can change its strategy unilaterallyii , then no player
9. The future direction of jailbreak research
- Quantum Computing and LLM:Research the potential impact of quantum computing on jailbreaking given its unique information processing capabilities.
- Cross-model vulnerability analysis:Examine how vulnerabilities in one model translate to other models to gain a more complete grasp of LLM’s systemic risks.
- Framework for Ethical AI Development:Develop a framework to guide the ethical development of AI, integrating insights from jailbreaking research to inform best practices.
Jailbreaking LLM presents multi-faceted challenges and highlights the need for robust, ethical and adaptive artificial intelligence systems. A thorough understanding of the mathematical underpinnings and potential vulnerabilities of these models is critical to building safer and more responsible AI. As LLMs continue to evolve, our security exploitation strategies must also evolve to ensure their role as effective and secure tools in the ever-expanding field of artificial intelligence.