Эта серия написана больше, и если будут новые статьи, то она будет продолжать добавляться:
- Крупные мультимодальные модели на основе LLM (Visual ChatGPT, PICa, MM-REACT, MAGIC)
- Крупные мультимодальные модели на базе LLM (Фламинго, БЛИП-2, КОСМОС-1)
- Крупные мультимодальные модели на основе LLM (MiniGPT-4, LLaVA, mPLUG-Owl, InstuctBLIP, X-LLM)
В этой статье сначала помещаются более сложные статьи о расширениях и приложениях, а затем формируется ветка, а затем открывается отдельно.В настоящее время это в основном PALM-E, ArtGPT-4, VPGTrans и т. д.
Модель языка путей с воплощенным
PALM-E — одна из статей, которая очень беспокоит блоггеров.Это модель визуального языка 562B (PaLM-540B + ViT-22B), и в настоящее время она является самой большой моделью визуального языка в мире. В то же время он будет интегрирован в роботизированное управление, известное как мультимодальный воплощенный интеллект, который добавит роботизированные руки к уже мощным моделям. По поводу мультимодального воплощенного интеллекта вы можете прочитать предыдущие посты в блоге блогера, поэтому я не буду их повторять: Портал: обзор и применение воплощенного ИИ (Embodied AI) .

Структура модели показана в средней части рисунка ниже.PaLM-E в основном вводит непрерывные физические наблюдения, такие как изображения, оценка состояния или другие модальности датчиков, в языковую модель. Таким образом, входные данные для модели становятся:
Give <emb> ... <img> A: How to grasp blue block?
Обработка мультимодального ввода здесь аналогична методу в предыдущих сообщениях в блоге.Это также токенизация того, какой режим и какой кодировщик использовать в первую очередь, а затем собрать всех вместе, а затем использовать PaLM-E в качестве декодера для перейти к авторегрессии генерировать текст. Затем сгенерированный текст может выполнять действия,
A: First. grasp yellow block and ...
Затем взаимодействуйте с реальным миром.

Судя по результатам статьи, PaLM-E полностью поддерживает нулевой выстрел и кроватку. Однако пока выпущены только бумага и демо, и конкретные детали пока не ясны. Но, по крайней мере, PALM-E показал нам, что мультимодальное заземление LM+world действительно многообещающе (приветствую друзей, которые заинтересованы, напишите мне в личном сообщении, чтобы сделать это вместе).
- статья:PaLM-E: воплощенная мультимодальная языковая модель
- архив:https://arxiv.org/abs/2303.03378v1
- гитхаб: https://palm-e.github.io
ArtGPT-4: Художественное зрение-понимание языка с помощью MiniGPT-4 с улучшенным адаптером
ArtGPT-4 — это своего рода расширенная модель, которая в основном основана на MiniGPT-4 , а затем вертикально решает свои проблемы в понимании художественных изображений.
Структура модели показана на рисунке ниже.Настройка адаптера в основном выполняется с помощью стратегии MiniGPT-4 с расширенным адаптером. Как показано на рисунке, линейный слой и функция активации викуньи в основном настроены так, чтобы модель могла лучше фиксировать сложные детали и понимать значение художественных изображений.Хребет викуньи можно преобразовать в следующую структуру:

Набор обучающих данных поступает из высококачественных пар изображения и текста, созданных ChatGPT, всего 3500 пар высококачественных наборов данных. Затем он обучается в течение 2 часов на устройстве Tesla A100 с примерно 200 ГБ пар изображение-текст. Помимо улучшения понимания изображений, он также может генерировать визуальный код, включая красивые веб-страницы HTML/CSS и т. д., с более художественным вкусом.
arxiv: https://arxiv.org/pdf/2305.07490.pdf
github: https://github.com/DLYuanGod/ArtGPT-4
VPGTrans: перенос генератора визуальных подсказок между LLM
В настоящее время для обучения визуально-языковой модели (VL-LLM) с нуля требуется много ресурсов, поэтому в предыдущем сообщении в блоге существующая языковая модель и визуальная модель в основном объединены. вместе.Хотя этот метод снижает затраты на обучение, линейные слои (проектор) или визуальные модули (VPG) часто требуют обучения. Таким образом, VPGTrans в этой статье в основном представляет собой метод повышения эффективности, который позволяет перенести существующую модель для получения VL-LLM. По сравнению с обучением модуля зрения с нуля этот метод может снизить стоимость обучения BLIP-2 FlanT5-XXL с 19 000 юаней и более до менее 1 000 юаней, как показано на рисунке ниже.
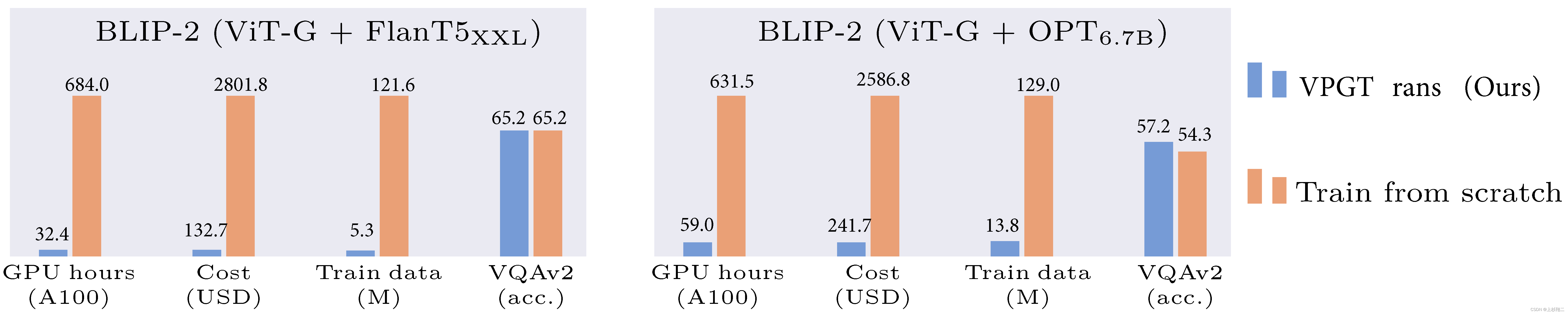
VPGTrans в основном исследует миграцию двух типов VPG:
- Передача размера между LLM (TaS): например, при переходе с OPT-2.7B на OPT-6.7B важно то, что параметры можно сначала отрегулировать на небольшом LLM, а затем распространить на большой LLM.
- Перенос типа между LLM (TaT): например, с OPT на FlanT5 значение состоит в том, что разные LLM можно быстро переключать.
Затем авторы провели несколько поисковых экспериментов и обнаружили несколько интересных результатов:
- Прямое наследование ВПГ может ускорить сходимость, но ускорение ограничено + очки будут сброшены.
- Сначала прогрейте проектор в течение 3 периодов, чтобы предотвратить падение точки и ускорить сходимость.
- Инициализация преобразователя векторов слов может ускориться с 3 до 2 эпох, что очень интересно. Авторы полагают, что VPG преобразует изображения в мягкие подсказки, которые может понять LLM, а мягкие подсказки и векторы слов на самом деле очень похожи, поэтому авторы обучили преобразователь вектора слов из картинки в картинку (линейный слой), а затем использовали его для инициализируйте проектор.
- В 5 раз сверхбольшая скорость обучения может ускорить сходимость (в основном потому, что параметры проектора несложны и их нелегко свернуть).
Поэтому итоговая структура обучения VPGTrans показана на рисунке ниже,
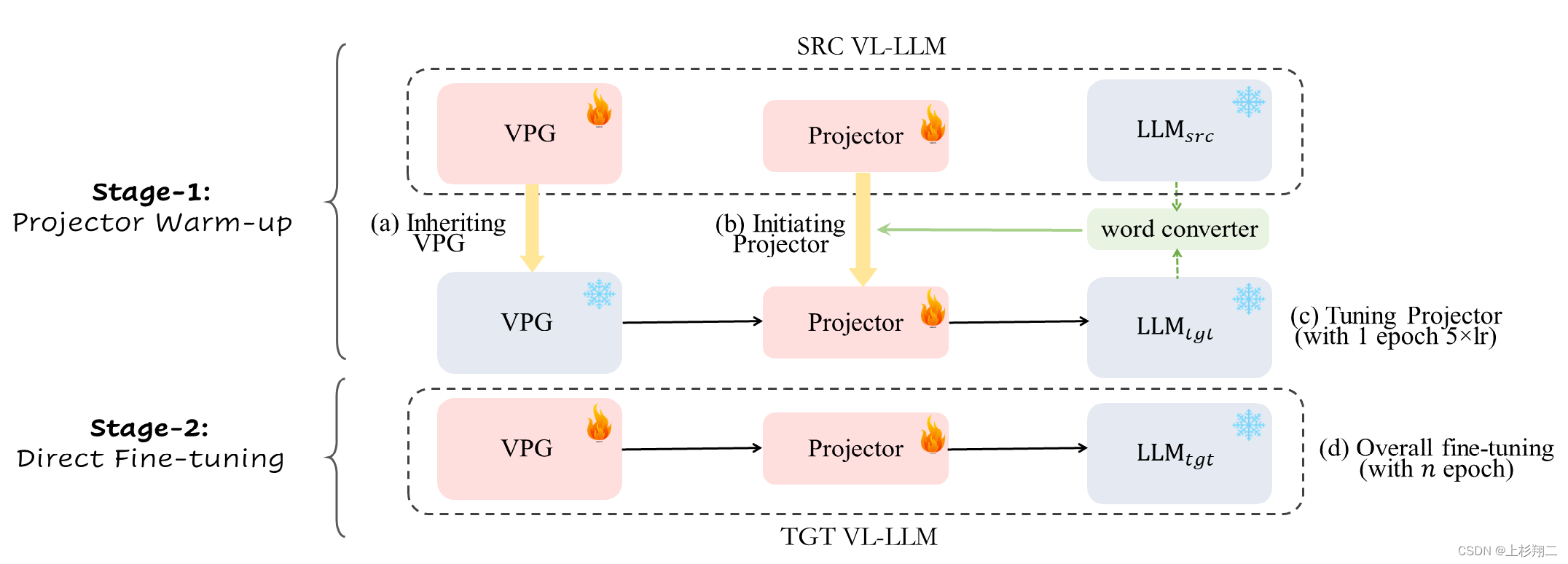
этот метод также разбит на два этапа:
- Первый этап: используйте преобразователь словарного вектора и исходный проектор для слияния в качестве инициализации нового проектора, а затем используйте 5-кратную скорость обучения для обучения нового проектора за 1 эпоху.
- Второй этап: напрямую тренируйте VPG и проектор в обычном режиме.
демонстрация: https://vpgtrans.github.io/
документ: https://arxiv.org/pdf/2305.01278.pdf
код: https://github.com/VPGTrans/VPGTrans