Успех больших моделей, таких как chatgpt, зависит от прорывного алгоритма, который является механизмом внимания. Этот механизм позволяет нейронной сети более эффективно извлекать и идентифицировать присущие языку правила. В то же время он поддерживает многоканальные параллельные операции. Следовательно, по сравнению с исходным алгоритмом обработки естественного языка, он может ускорить обучение за счет одновременного обучения. Он был усовершенствован сотни раз, поэтому можно использовать большие объемы обучающих данных в сочетании со сверхкрупномасштабными вычислительными мощностями, а также использовать сверхкрупномасштабные параллельные вычисления для содействия обучению сети. До того, как этот механизм был изобретен, исходный алгоритм вообще не мог достичь параллельных вычислений.Поэтому эффективность обучения сети чрезвычайно низка, поэтому способность сети использовать механизм внимания намного превышает способность исходной модели.
Так что же такое механизм внимания? Если вы поищите в Интернете, вы найдете много соответствующего контента, но я думаю, что очень немногие могут объяснить это ясно. Если вы хотите понять его принципы, вам нужно иметь хороший математическое основание. Я здесь. Попытайтесь использовать более популярный язык, чтобы объяснить это. В отсутствие строгого математического логического вывода логическое описание на обычном языке неизбежно не попадет в цель, но главная цель - дать каждому базовое перцептивное понимание. Позже мы воспользуемся методом практики кода. Улучшим наше рациональное понимание алгоритма.
Так называемый механизм внимания – это, по сути, своего рода «гармония». Поскольку компьютер основан на двоичном коде 0,1, результат равен либо 0, либо 1, и серая зона отсутствует. Однако этот вывод «одно слово и одно слово» не может быть применен к глубокому обучению. Студенты, имеющие опыт глубокого обучения можно увидеть, что дает сеть Ответы часто основаны на вероятности В приложении мы выбираем вывод с наибольшей вероятностью в качестве конечного результата. Суть механизма внимания состоит в том, чтобы присвоить соотношение нескольким возможным ответам, затем умножить эти отношения на соответствующие ответы и, наконец, сложить, чтобы получить окончательный ответ.
Приведите конкретный пример. Предположим, мы хотим спрогнозировать рост детей пары в возрасте 10 лет. Во-первых, нам нужно использовать математический метод для описания так называемого «статуса роста».В глубоком обучении мы часто используем векторы для представления объектов, которые необходимо описать. Поэтому мы используем вектор для описания «статуса роста» ребенка, например, V (ребенок) = {рост, вес, форма лица, частота сердечных сокращений, психическое состояние, состояние здоровья...}, то есть мы используйте вектор, состоящий из ряда показателей.Опишите ситуацию ребенка. Теперь вопрос в том, как нам получить значения каждой компоненты вектора V (ребёнок 10 лет). Простой метод - взять соответствующие векторы отца, матери, дедушки, бабушки, дедушки, бабушки, дяди, тети, дяди, тети, тети и т. д. ребенка в возрасте 10 лет и сравнить эти векторы по «определенное соотношение» Подводя итог, полученный вектор можно использовать в качестве вектора «состояния роста» ребенка в возрасте 10 лет.
Проблема теперь в том, как определить «определенную пропорцию», какая доля вектора соответствует отцу, какая доля вектора соответствует матери и какая доля векторов соответствует бабушке, дедушке и другим родственникам? Очевидно, что в качестве прямых родителей доля отца и матери определенно будет больше. Чем дальше биологическое родство, тем пропорция, естественно, соответственно уменьшится. Другая проблема здесь заключается в том, является ли ребенок, которого мы хотим вывести, мальчиком или девочкой. Если пол ребенка другой, соотношение векторов, соответствующее каждому родственнику, должно измениться соответствующим образом. Мы используем переменную query для представления информации о ребенке, которую необходимо предполагать. Например, query(boy) представляет рост мальчика в возрасте 10 лет, а query(girl) представляет рост девочки в возрасте 10 лет.
Предположим, что теперь у нас есть функция f, которая может вычислить соотношение соответствующих относительных векторов, например, f(query(boy), V(father)) = a1, что означает, что когда мы хотим предсказать рост мальчика в десять лет, отца. Доля вектора «ситуации роста» в возрасте 10 лет равна a1, поэтому мы вычисляем f(query(boy), v(mother))=a2,.. .f(query(boy),v(aunt))=a11, где a1 + a2 +… + a11 = 1, поэтому мы можем вычислить вектор «ситуации роста» мальчика, когда ему исполнится 10 лет, как a1 V (отец) + a2 V(мать)+…+a11*V(тетя).
В приведенном выше алгоритме мы используем ключ для представления векторов, таких как v(отец) и v(мать), используемых для расчета пропорции в f. v(отец) и v((Mom) и другие векторы мы используем значение для представляют его. Очевидно, что объект коллекции, соответствующий ключу, и объект коллекции, соответствующий значению, одинаковы. Эта ситуация называется самообслуживанием. Во многих сценариях приложений объекты, соответствующие ключу и значению, сильно различаются. Они могут быть разными. Для обработки естественного языка, например, Chatgpt, используется механизм самообслуживания, то есть ключ и значение имеют один и тот же набор.
На самом деле в приведенном выше алгоритме еще есть большие проблемы, то есть много влияющих факторов, которые не учтены. Например, ряд факторов, таких как страна мальчика, этническая принадлежность, эпоха, социально-экономическое развитие, национальная культура, национальность родителей и родственников, финансовое положение семьи, уровень образования семьи и т. д. Мы прогнозируем, что ребенок, выросший в Швейцарии, будет отличаться от ребенка, выросшего в Афганистане.Результаты детей должны быть очень разными.Эти различия вызваны различными внешними факторами.Вопрос в том, как рассчитать влияние этих различий? Первая проблема заключается в том, как мы узнаем, какие внешние факторы повлияют на рост ребенка? Поскольку мы не можем тщательно исчерпать все внешние факторы, в алгоритмах глубокого обучения обычно используется матрица для представления размера матрицы. Чем она больше , тем больше вероятность того, что будут учтены возможные воздействия и, следовательно, тем точнее будут прогнозы. Мы используем Wq для представления влияния неизвестных факторов на ребенка. Эти факторы определенно повлияют на коэффициент воздействия соответствующих родственников, поэтому мы используем Wk для представления влияния, получаемого соответствующими родственниками при расчете коэффициента, поэтому приведенное выше f( query(boy) , v (отец)) становится f (Wqquery (boy), Wkv (отец)), а вычисления соотношений для других родственники должны быть одинаковыми.Умножьте соответствующую матрицу. Наконец, эти факторы также будут влиять на процесс «перемешивания грязи». Мы используем Wv для представления воздействия связанных факторов на грязь, поэтому a1*(WvV(Dad))+ a2(Wv*V(тетя))V(мать))+…+a11(Wv
Описанный выше процесс представляет собой «человеческое» описание механизма внимания. Задача алгоритма — рассчитать Wq, Wk и Wv на основе большого объема данных.После определения этих переменных мы можем получить соответствующие результаты с помощью операций. При обработке естественного языка понимание слов в предложении фактически зависит от других слов в том же предложении. Например, слово «яблоко», как вы думаете, оно должно соответствовать фруктовому яблоку или технологическому гигантскому яблоку? Очевидно, нам нужно судить по контексту предложения. Соответствующее предложение: пожалуйста, купите мешок яблока и апельсина. Яблоко здесь — это фрукт. Почему мы можем быть так уверены? Потому что существование пакета и апельсина определяет его значение. Здесь яблоко Соответствующее слово — запрос, а все остальные слова соответствуют ключу и значению. Среди них яблоко имеет наибольшую связь с ошибкой и оранжевым, а другие слова имеют с ним мало связи. Поэтому мы хотим, чтобы компьютер здесь понимал яблоко, то есть пусть компьютер вычислит a1v(пожалуйста) + a2v(купить)+…a4v( мешок)+…a6V(apple)+…+a8*(оранжевый), поскольку такие слова, как «пожалуйста» и «купи», очень мало влияют на значение слова «яблоко», соответствующие им значения коэффициента влияния должно быть маленьким, но слова «мешок», «оранжевый» Влияние очень велико, поэтому соответствующий коэффициент будет относительно большим. Само слово «яблоко» не очень помогает компьютеру понять его, поэтому соответствующий коэффициент будет очень большим. маленький. Точно так же в предложении «Яблоко выпустило новый телефон» слово «телефон» оказывает большое влияние на понимание слова «яблоко». Благодаря этому слову мы можем определить, что яблоко здесь соответствует технологической компании, а не фрукту. Поэтому, когда « Гармония», коэффициент, соответствующий телефону, будет очень большим.
Основываясь на приведенном выше обсуждении, мы моделируем весь процесс алгоритма самообслуживания с помощью кода. Во-первых, мы используем векторы для представления слов в предложениях. В предыдущей главе мы видели, что длина вектора, соответствующего слову, может быть очень большой. Здесь нам нужно только понять принцип, поэтому мы используем вектор длины 4 представлять слово:
import numpy as np
print("步骤 1,随机生成 3 个长度为 4 的向量来表示含有三个单词的句子")
#向量的数值不重要
x = np.array(
[
[1.0, 0.0, 1.0, 0.0],
[0.0, 2.0, 0.0, 2.0],
[1.0, 1.0, 1.0, 1.0]
]
)
print(x)
Результат после запуска приведенного выше кода:
步骤 1,随机生成 3 个长度为 4 的向量来表示含有三个单词的句子
[[1. 0. 1. 0.]
[0. 2. 0. 2.]
[1. 1. 1. 1.]]
Мы используем графику для выражения связанных процессов. Благодаря изменениям в графике мы можем легче понять процесс алгоритма. Во-первых, инициализируем три вектора слов:
Вторая часть инициализирует описанные ранее Wq, Wv и Wk. Аналогично значения их внутренних компонентов совершенно не важны. Нейронная сеть подтвердит их конкретные значения посредством обучения:
print("步骤 2,确认 Wq, Wv, Wk,由于要跟上面向量做乘法,因此他们的行数是 4,列数可以任意取值,注意 w_query 和 w_key 列数取值要相同")
w_query = np.array([
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
])
print(f"Wq is: {
w_query}")
w_key = np.array([
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
])
print(f"Wk is :{
w_key}")
w_value = np.array([
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
])
print(f"Wv is :{
w_value}")
Три добавленные матрицы преобразования показаны на рисунке ниже:
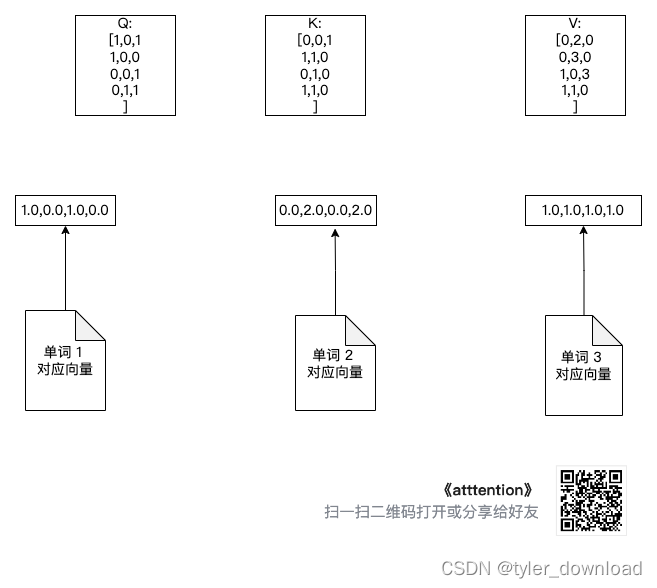
При обработке естественного языка каждое слово в предложении будет играть роль запроса, и каждое слово будет использоваться как ключ и значение. Поэтому нам нужно умножить каждое слово на w_q, чтобы вычислить «сумму» для следующего шага. Чтобы подготовиться для соотношения «жидкий буровой раствор» делаем следующее:
print("每个向量都会作为 query 使用,因此他们都要乘以 w_query 为下一步计算分配比率做准备")
Q = np.matmul(x, w_query)
print(f"query matrix is: {
Q}")
Поскольку каждое слово должно иметь ключ и значение, их также необходимо умножить на матрицы w_k, w_v соответственно. Код выглядит следующим образом:
print("每个向量都会作为 key 使用,因此他们也需要乘以 w_key")
K = np.matmul(x, w_key)
print(f"key matrix is : {
K}")
print("每个向量都会作为 value 使用,因此也需要乘以 w_value")
V = np.matmul(x, w_value)
print(f"value matrix is {
V}")
Вышеописанный процесс расчета показан на рисунке ниже:
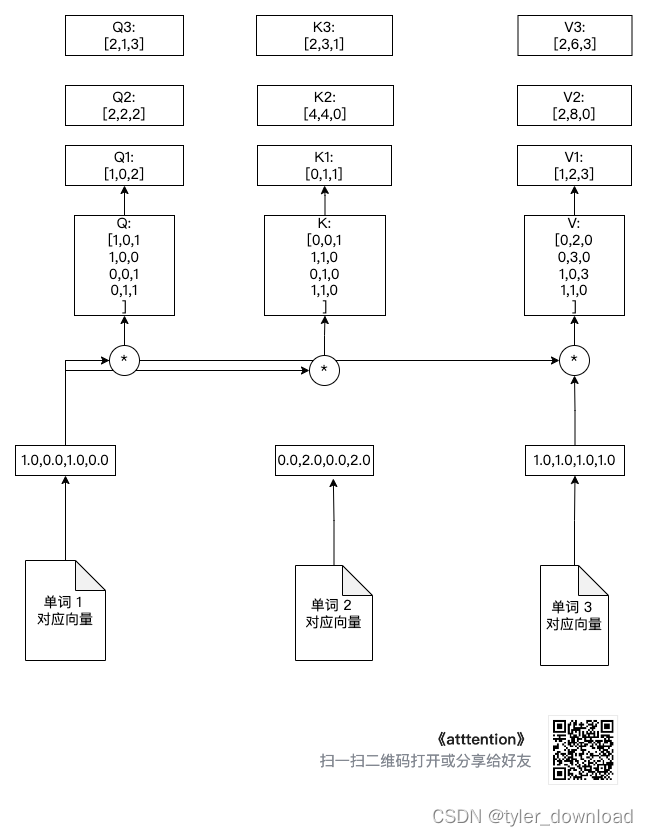
Как видно из рисунка выше, вектор слова 1 умножается на матрицы Q, K, V соответственно, чтобы получить Q1, K1, V1. Аналогично, вектор слова 2 умножается на Q, K, V, чтобы получить Q2, K2, V2. , слова Вектор 3 умножаются на Q, K, V, чтобы получить Q3, K3, V3. Чтобы строки не были слишком запутанными, я не соединял вектор слов 2 и вектор слов 3 с тремя символами операции умножения в на рисунке выше, но нам нужно знать Q2. Источником K2, V2, Q3, K3, V3 является результат одной и той же операции с вектором слова 2 и вектором 3.
Далее мы вычисляем «коэффициент распределения», который рассчитывается следующим образом:
s of t m a t ( Q ∗ K T / s q r t ( d k )) softmat(Q * K^T / sqrt( д_к )) такftmat (Вопрос∗КT/sqrt(dk))
Значение d_k соответствует количеству слов в предложении, поэтому значение равно 3, а его квадратный корень равен 1,75. Когда мы округляем его, оно равно 1, поэтому коэффициент распределения рассчитывается следующим образом:
from scipy.special import softmax
print(f"计算分配比率")
'''
k_d 对应 Q * K^t 后矩阵的维度,由于 Q的列数和 K^t 都是 3*3 矩阵,相乘后矩阵
每行的列数为 3,因此 k_d = sqrt(t) 就约等于 1
'''
k_d = 1
attention_scores = Q @ K.transpose() / k_d
print(attention_scores)
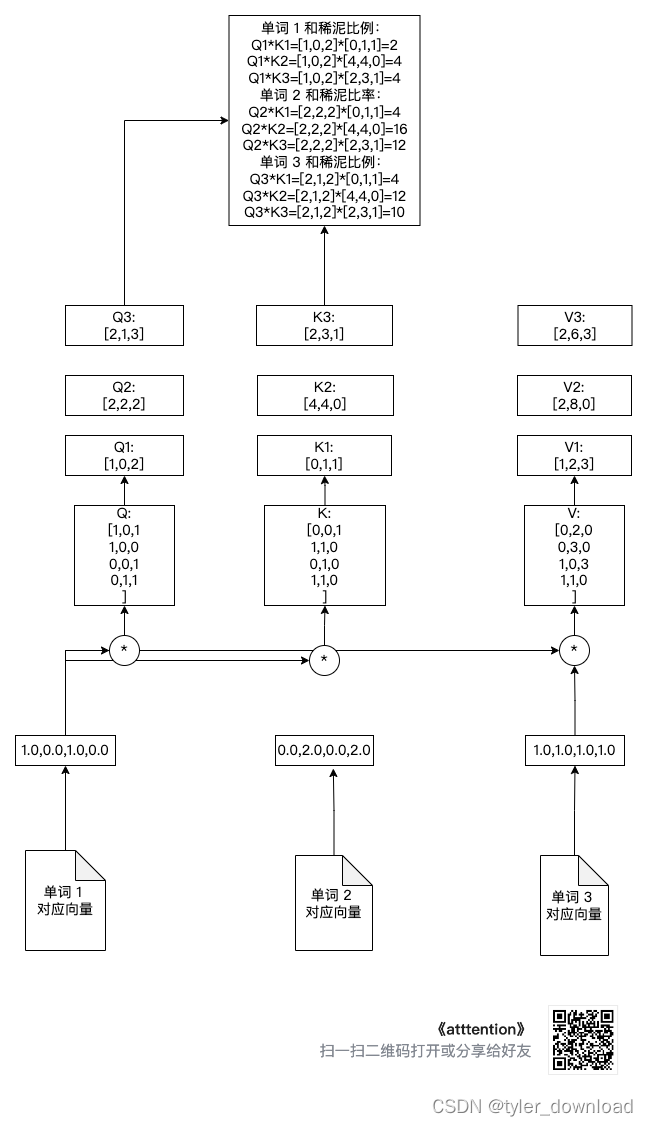
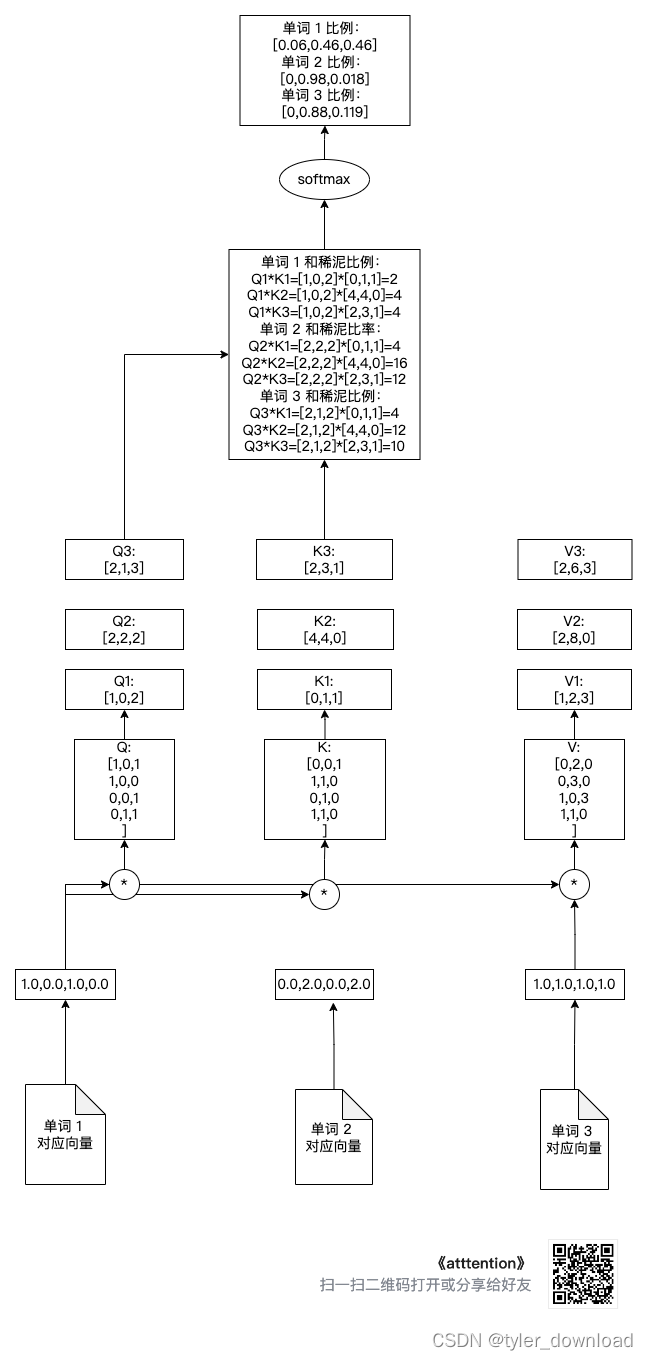
Обратите внимание на Q @ K.transpose() Здесь мы фактически умножаем Q1, Q2, Q3 на (K1, K2, K3) соответственно, чтобы получить сумму и коэффициент грязи для каждого вектора. Например, коэффициент суммы для первого вектора слова равен (Q1*K1^t, Q2*K2^2, Q3*K3^t), где K1^t — транспозиция вектора K1, то есть он изменяется из строки Преобразуйте вектор в вектор-столбец, чтобы два вектора можно было умножить.
Давайте посмотрим на сумму и коэффициент грязи, соответствующие каждому вектору после вышеуказанной операции, как показано на рисунке ниже:
Далее мы выполняем softmax для полученного коэффициента распределения при нормализации каждого слова, то есть приравнивании суммы пропорций к 1, соответствующий код выглядит следующим образом:
print("通过 softmax 将分配比率正规化,也就是使得各比率之和为 1")
attention_scores[0] = softmax(attention_scores[0])
attention_scores[1] = softmax(attention_scores[1])
attention_scores[2] = softmax(attention_scores[2])
#第一个单词对应的 value 分配比率
print(attention_scores[0])
#第二个单词对应的 value 分配比率
print(attention_scores[1])
#第三个单词对应的 value 分配比率
print(attention_scores[2])
Вышеуказанная операция соответствует следующему рисунку:
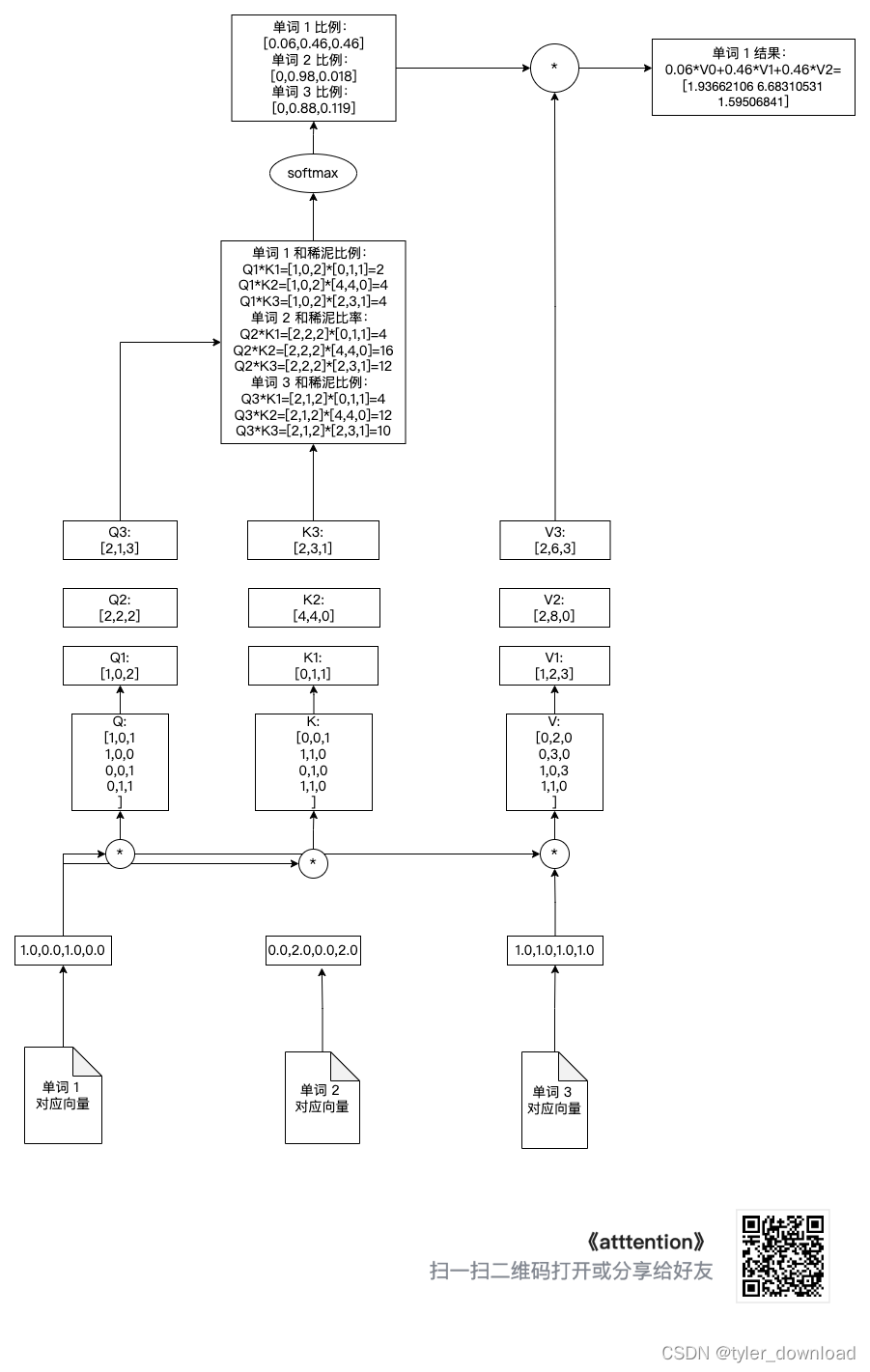
Наконец, мы умножаем коэффициент распределения на V[0], V[1], V[2], а затем складываем их Чтобы получить соответствующий вектору результата, мы проделаем соответствующую операцию со словом 1 ниже. Операция с другими словами точно такая же:
print("计算和稀泥结果")
print(V[0])
print(V[1])
print(V[2])
'''
计算第二,第三个单词分配比率时,只要把 attention_scores[0][i](i=1,2,3)换成
attention_scores[1][i], attention_scores[2][i]即可
'''
attention1 = attention_scores[0].reshape(-1, 1)
print(f"第一个单词的和稀泥分配比为:{
attention1}")
print("第一个向量和稀泥给第一个单词的数量为:")
attention1 = attention_scores[0][0] * V[0]
print(attention1)
print("第二个向量和稀泥给第一个单词的数量为:")
attention2 = attention_scores[0][1] * V[1]
print(attention2)
print("第三个向量和稀泥给第一个单词的数量为")
attention3 = attention_scores[0][2] * V[2]
print(attention3)
print("将上面 3 个 attention 加总就是针对第一个单词和稀泥的结果")
attention_input1 = attention1 + attention2 + attention3
print(f"第一个单词的和稀泥结果:{
attention_input1}")
Вышеуказанная операция соответствует следующему рисунку:
В описанном выше процессе операции матрицы Q, K, V являются параметрами, подлежащими обучению сетью. Вышеописанное является основным процессом механизма самовнимания. В модели, используемой ChatGPT, механизм внимания немного отличается от описанного выше: он называется multihead-attention, что означает, что описанный выше процесс разделен на 8 параллельных процессов и продвигается одновременно.
В нашей симуляции длина вектора слов составляет всего 4, тогда как в примененииchatGPT длина не менее 512. ПослеchatGPT3.5 длина определенно будет больше, но алгоритм алгоритма аналогичен. Предположим, что соответствующая длина вектора слов равна 512. Так называемая мультиголовка означает деление вектора слов длиной 512 на 8 субвекторов, каждый вектор имеет длину 64, а затем каждый субвектор выполняет операция, описанная выше, и эти 8 подвекторов могут выполняться одновременно.
Давайте также смоделируем процесс multihead.Предположим, что 8 подвекторов длиной 64 завершают описанные выше операции.Результаты следующие:
import numpy as np
print("模拟 8 个长度为 64 的子向量完成 attention 操作后的结果,这里我们设定 Q,K,V 对应的列都是 64,因此操作结果得到的就是长度为 64 的向量")
head1 = np.random.random((3, 64))
head2 = np.random.random((3, 64))
head3 = np.random.random((3, 64))
head4 = np.random.random((3, 64))
head5 = np.random.random((3, 64))
head6 = np.random.random((3, 64))
head7 = np.random.random((3, 64))
head8 = np.random.random((3, 64))
print("将 8 个 3*64 向量在水平方向拼接变成 3*512 向量")
output_attention = np.hstack((head1, head2, head3, head4, head5, head6, head7, head8))
print(output_attention)
Приведенный выше код моделирует результаты 8 подвекторов после прохождения описанного выше процесса, а затем горизонтально объединяет 8 364 результатов в 3512, согласно архитектуре преобразователя, которую мы описали ранее, следующим шагом будет нормализация этого результата:
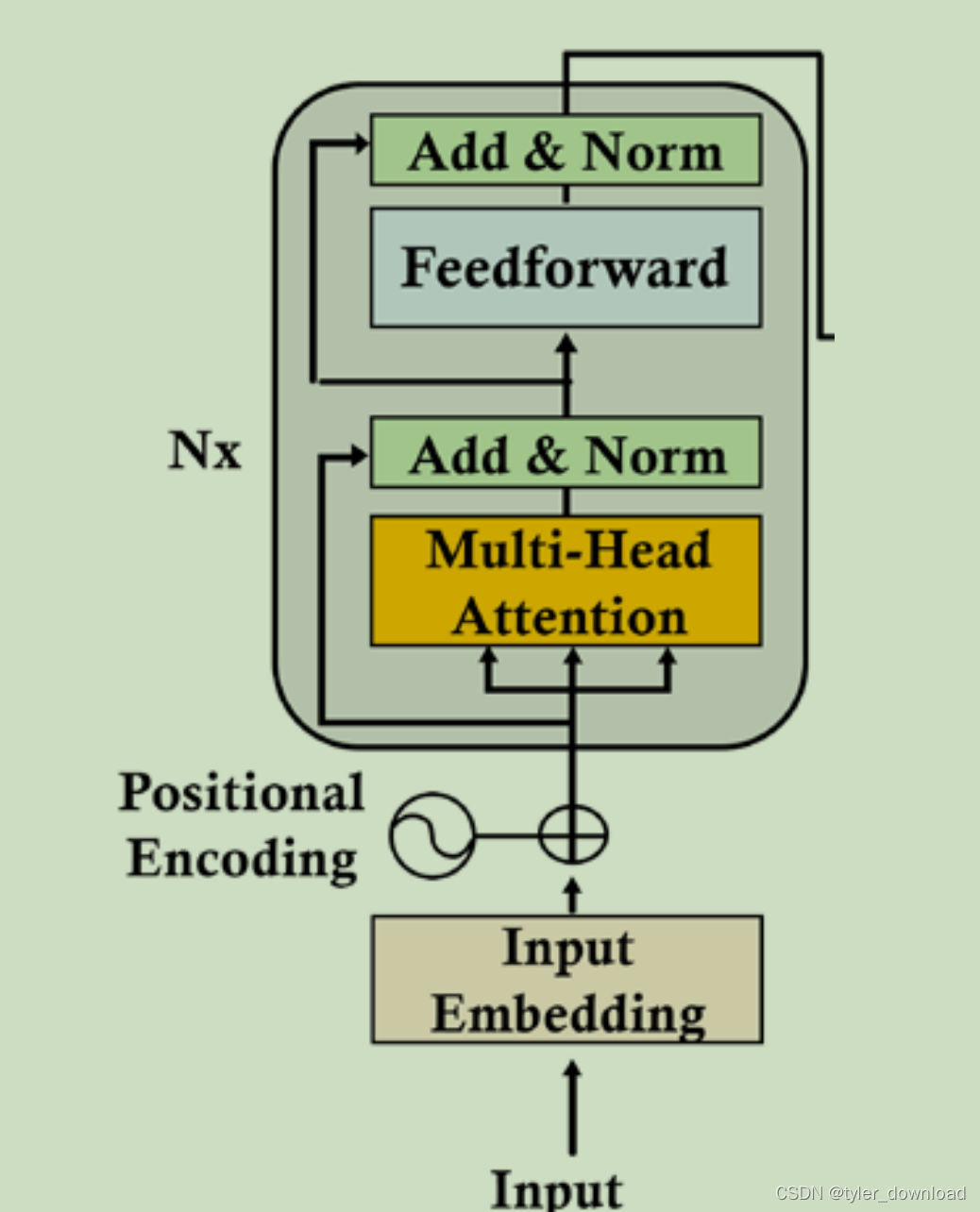
Множественное внимание на рисунке выше является результатом того, что мы описали ранее. Давайте посмотрим, что делает Add & Norm. Фактически он выполняет функцию LayerNormalization. Процесс расчета этой функции выглядит следующим образом:
LayerNormalization(v) = r * (v - u)/a + b
Здесь r, u, a, b — параметры, которые можно вычислить, здесь v — входные данные функции, которая соответствует вектору. Если длина вектора, соответствующего входному сигналу v, равна d, то есть v имеет d параметров v=(v1, v2, …vd), то u = (v1 + v2 +… + vd)/d, a — стандартный входного вектора v Variance a = sqrt((v1-u) ^ 2 + ...(vd-u)^2), и, наконец, b — вектор той же размерности, что и v. Этот b также является вектором параметров который может быть обучен сетью.
Следует отметить, что слой "Добавить и норма" получает два входных сигнала. Один — это входной вектор для слоя внимания с несколькими головами, который является результатом добавления вектора слова к вектору позиции. Другой — это мульти- Вывод результата по главному вниманию. Это связано с тем, что входной вектор слова предупреждает многоголовое внимание о том, что после этого слоя некоторая информация в векторе слов может быть потеряна, поэтому суммирование результатов многоголового внимания вектора слов может гарантировать Принцип заключается в том, что информация, содержащаяся в векторе слов, не теряется.Эта операция называется «Добавить» в «Добавление и норма».
Вверх идет уровень прямой связи (FFN), который на самом деле представляет собой простую двухуровневую прямую сеть. Первый уровень содержит 2048 узлов, а второй уровень – 512 узлов. Функция активации использует ReLU. Требуемый входной сигнал длина вектора равна 512, а выходной вектор также равен 512. Соответствующий расчет:
FFN(x) = max(O, x * W1 + b1) * W2 + b2
W1 является параметром соединения между первым уровнем и входным уровнем, а W2 является параметром соединения между первым уровнем и вторым уровнем.
Выше приведено наше краткое введение в модель трансформатора. Есть еще много важных деталей, которые трудно описать словами. Позже мы используем архитектуру преобразователя для создания двух языковых моделей перевода. Благодаря практическому бою, возможно, мы сможем лучше понять теорию. Для получения дополнительной информации, пожалуйста, выполните поиск на станции B-кодирование Дисней.