
Laf는 Sealos 템플릿 마켓에 성공적으로 상장되었으며 Laf 애플리케이션 템플릿을 통해 한 번의 클릭으로 배포할 수 있습니다!

이는 Laf 의 프라이빗 배포 확장성이 크게 향상되었음을 의미합니다 .
강력한 클라우드 운영 체제 인 Sealos는 MySQL, PostgreSQL, MongoDB, Redis 등 다양한 고가용성 데이터베이스를 단 몇 초 만에 생성할 수 있으며, GPU 클러스터가 종료된 후에도 한 번의 클릭으로 다양한 메시지 대기열과 마이크로서비스를 실행할 수 있습니다. 온라인으로 다양한 AI 대형 모델을 실행해 보세요.
한 번의 클릭으로 Laf를 Sealos에 배포 하면 Laf 에서 Sealos가 제공하는 모든 기능을 인트라넷을 통해 직접 호출 할 수 있습니다 . 사용자에게 어떤 종류의 백엔드 지원이 필요하든 Sealos에서 해당 서비스만 실행하면 됩니다 . 이 통합 모델은 리소스 활용 효율성을 향상시킬 뿐만 아니라 원활한 기술 통합을 제공하여 Laf를 더욱 강력하고 다재다능한 서버리스 플랫폼으로 만들어 백엔드 기능에서 기존 서버리스 플랫폼의 단점을 보완합니다.
Sealos의 강력한 템플릿 마켓은 풍부한 애플리케이션 생태계를 제공하며, 사용자는 원클릭으로 템플릿 마켓에 다양한 애플리케이션을 배포할 수 있습니다. 이 기사에서는 Elasticsearch를 예로 들어 Laf 의 Sealos 템플릿 시장에 배포된 Elasticsearch를 호출하여 벡터 데이터베이스를 구축하고 맞춤형 지식 기반 검색 기능을 제공하는 방법을 보여줍니다 .
배경 지식
대형 모델에 지식을 주입하려면 가장 먼저 생각할 수 있는 것은 대형 모델을 미세 조정하는 것입니다. 대형 모델은 위의 내용을 바탕으로 질문에 답하는 능력이 뛰어납니다.
"만칭 유스호스텔 밴드를 소개해 주세요."(모델이 완칭에 대한 관련 정보를 저장하지 않는다고 가정)라는 질문이 있다고 가정해 보겠습니다. 그런 다음 전 세계를 포함하는 100만 단어 문서가 있습니다. 모든 밴드가 켜져 있습니다. 모델이 무한히 긴 입력을 잘 이해하고 있다면 "다음은 세상의 모든 밴드에 대한 소개입니다. [100w 단어 밴드 소개 문서 삽입]"을 기반으로 저에게 소개해주세요. Above Evergreen은 밴드입니다.” 모델이 내 질문에 답하도록 하세요. 그러나 모델에서 지원하는 입력 길이는 매우 제한적이며, 예를 들어 ChatGPT는 32K 토큰 길이(약 50페이지의 텍스트) 입력만 지원합니다.
실제로 대규모 모델이 문서를 기반으로 한 질문에 대답하려면 입력에서 문서 콘텐츠의 길이를 줄여야 합니다. 한 가지 접근 방식은 문서를 여러 세그먼트로 자르고 문제와 관련된 소수의 문서 조각만 꺼내어 대규모 모델의 입력에 넣을 수 있다는 것입니다. 이 시점에서 "대형 모델 플러그인 데이터베이스"의 문제는 "텍스트 검색 문제"로 변환되었으며, 목표는 문제를 기반으로 문서의 가장 관련성이 높은 조각을 찾는 것입니다. 대형 모델 그 자체.
검색을 위해 벡터를 사용하는 것이 텍스트 검색에서 더 일반적으로 사용됩니다. 모든 문서 조각을 (bert 등과 같은 언어 모델을 통해) 벡터화한 다음 이를 벡터 데이터베이스(예: Annoy, FAISS, hnswlib 등)에 저장할 수 있습니다. .) 질문이 발생합니다.이후 질문문도 벡터화되고, 벡터 데이터베이스에서 질문 벡터와 가장 유사한 상위 k개의 문서 조각을 코사인 유사도나 내적 등의 지표를 사용하여 계산하여 입력하게 됩니다. 위와 같이 대형 모델로 들어갑니다.
벡터 데이터베이스는 모두 대략적인 검색 기능을 지원하므로 벡터 검색 정확도를 희생하면서 검색 속도를 향상시킵니다. 전체 흐름도는 다음과 같습니다.

이 아이디어에 따르면 우리가 해야 할 일은 두 가지입니다. 하나는 문서를 벡터화하는 것이고, 다른 하나는 벡터 데이터베이스를 구축하는 것입니다. 문서를 벡터화하는 가장 간단한 방법은 openai제공된 변환 인터페이스를 사용하여 문서를 벡터 배열로 변환하는 것입니다.또한 bert 모델을 사용할 수도 있습니다. OpenAI는 또한 벡터 데이터베이스 참조 옵션을 제공하여 코사인 유사성 공식을 사용하여 벡터 유사성을 찾을 것을 제안합니다.
$$\cos (\theta) = \frac {AB} {|A| |B|} = \frac {\sum {i=1}^{n} A_i B_i} {\sqrt {\sum {i=1}^{n} A_i^2} \sqrt {\sum_ {i=1 }^{n} B_i^2}}$$

Sealos에 벡터 데이터베이스를 빠르게 배포하는 방법은 무엇입니까? OpenAI의 추천을 통해 Elasticsearch 옵션이 있다는 것을 보고 이를 사용하게 되었습니다.
Laf 및 Elasticsearch 배포
먼저 Sealos 퍼블릭 클라우드 데스크탑( https://cloud.sealos.top )을 열어야 합니다.
Sealos는 완전한 오픈 소스이므로 Sealos를 통해 자체 프라이빗 클라우드를 구축할 수도 있습니다: https://sealos.run/self-hosting
그런 다음 "템플릿 마켓"에 들어가서 각각 Laf 템플릿과 Elasticsearch 템플릿을 통해 Laf와 Elasticsearch를 배포합니다 .
그런 다음 Laf 에서 새 애플리케이션을 만들고 종속성을 설치합니다 elastic/elasticsearch.
애플리케이션이 생성되면 클라우드 함수 코드를 사용하여 Elasticsearch에 연결할 수 있습니다. 이 예시에서는 테스트 데이터 10개를 직접 삽입했습니다(시연 과정을 단순화하기 위해 테스트 데이터를 직접 사용했으며 문서의 벡터 데이터 생성에 OpenAI 인터페이스를 사용하지 않았습니다).
import cloud from '@lafjs/cloud'
const { Client } = require('@elastic/elasticsearch')
const ca = `-----BEGIN CERTIFICATE-----
MIIDITCCAgmgAwIBAgIQQKs5V2terYVNUrHt9K0CzTANBgkqhkiG9w0BAQsFADAb
MRkwFwYDVQQDExBlbGFzdGljc2VhcmNoLWNhMB4XDTIzMTEyMjA3MDcxOFoXDTI0
MTEyMTA3MDcxOFowGzEZMBcGA1UEAxMQZWxhc3RpY3NlYXJjaC1jYTCCASIwDQYJ
KoZIhvcNAQEBBQADggEPADCCAQoCggEBAPYyHrFgyoD3Pkkc/ekXhHGKi+qKPBbp
afPuGImQfTtkGlzhaHJ7Iy3MZojP/iyt3FTY+LvxODsbkgIrQJWwiG2s26rw03Zd
lphf7RULRa9Z/TKt0jxHV9M419ge2zRij6Al3uUHCP2FxjVMgYjuFisKwNalQfUE
spCTq9lWNp4bKP32GieEBQKeNRD8ElNBJkInIA2aTyH2TIhyICK0f5GjH52rxKeV
wrE/BHq8zomHRVtTM67KHoXc9RJgYNICfooeDHvi/f9f+pWrX881rmbNWXGcxu2u
GQLqCAkqpIpUwn5HAoSvUYHmxwgaDC866fjsgxv/6DMDJuGPmfsBqQMCAwEAAaNh
MF8wDgYDVR0PAQH/BAQDAgKkMB0GA1UdJQQWMBQGCCsGAQUFBwMBBggrBgEFBQcD
AjAPBgNVHRMBAf8EBTADAQH/MB0GA1UdDgQWBBQaGk9O4hQFjJPU6ay8qqU8CNug
uzANBgkqhkiG9w0BAQsFAAOCAQEAfZUesinfp1jeSqfHBSPHOgZ1q/v8xoClEPRl
wzh8sbL14iuuSb190J8zQefvzxC7ip4kVCVTW52fBZNyoMpvj0cXKWRGFmz3yHIs
TNdwOy15mQRQGbOTDBkQ528SbrmrWF4W7kDMoWs0t02UIlSfBWDjJrVharRR9QuF
cGjoS59TCAFcHHUsPO3lcUT1TCq/W4xnds3zBxJiGeIdmDqE6DbS78YfwP9rhTx0
oxcQwpKaOj8vxQNQxNbJRmWgffx0PgUzFPni/N5FgFQQXDPG4i0gMciekHWz8VRM
pp2z1uD1lVdDa/83w/IZCQOqDU7cRjDosg+gaAefFGNMHVbPBw==
-----END CERTIFICATE-----
`
export default async function (ctx: FunctionContext) {
const client = new Client({
node: 'https://elasticsearch-master.ns-wz9g09tc.svc.cluster.local:9200',
auth: {
username: 'elastic',
password: 'zhtvadgdinhkyirozeznxlxd'
},
tls: {
ca: ca,
rejectUnauthorized: false
}
})
const health = await client.cluster.health()
console.log(health)
// 删除已存在的索引(如果有)
await client.indices.delete({
index: 'vectors',
ignore_unavailable: true
})
// 创建一个新的向量索引
await client.indices.create({
index: 'vectors',
body: {
mappings: {
properties: {
embedding: {
type: 'dense_vector',
// 向量列表的长度
dims: 3,
index:true,
// 字段索引,consin函数求相似度
similarity:'cosine'
},
text: {
type: 'text'
}
}
}
}
})
// 测试数据
const documents = [
{ embedding: [0.5, 10, 6], text: 'text1' },
{ embedding: [-0.5, 10, 10], text: 'text2' },
{ embedding: [1.0, 5, 8], text: 'text3' },
{ embedding: [-0.2, 8, 12], text: 'text4' },
{ embedding: [0.8, 12, 4], text: 'text5' },
{ embedding: [-0.7, 6, 14], text: 'text6' },
{ embedding: [0.3, 14, 2], text: 'text7' },
{ embedding: [-0.4, 16, 8], text: 'text8' },
{ embedding: [0.6, 8, 10], text: 'text9' },
{ embedding: [-0.6, 12, 6], text: 'text10' }
];
// 插入测试数据
for (const doc of documents) {
await client.index({
index: 'vectors',
document: doc,
refresh: true
});
}
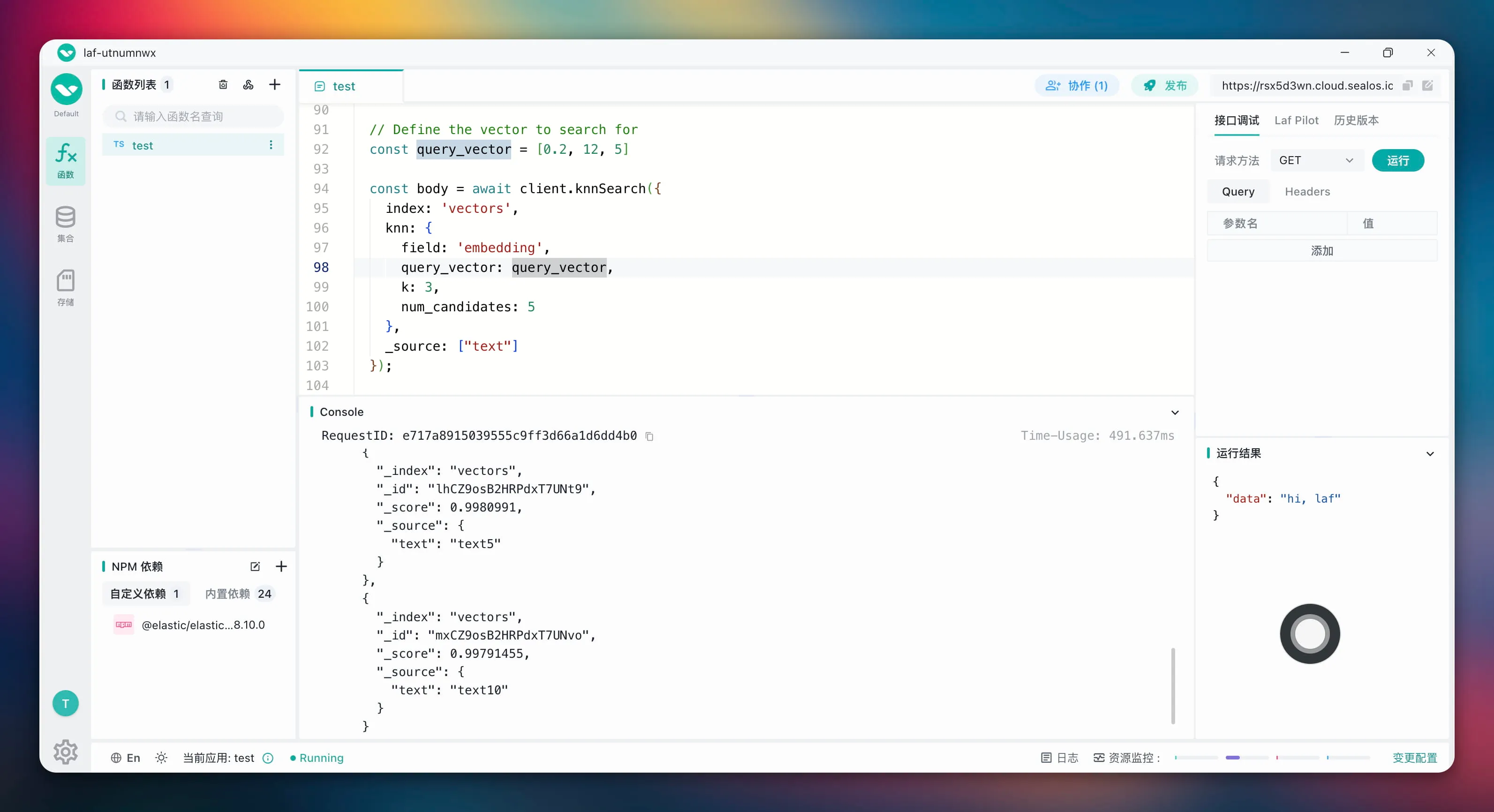
// Define the vector to search for
const query_vector = [0.2, 12, 5]
const body = await client.knnSearch({
index: 'vectors',
knn: {
field: 'embedding',
query_vector: query_vector,
k: 3,
num_candidates: 5
},
_source: ["text"]
});
// 输出搜索结果
console.log(JSON.stringify(body, null, 2))
return { data: 'hi, laf' }
}
[0.2, 12, 5]코사인 유사성 검색을 통해 벡터와 가장 유사한 벡터 데이터 3개를 찾았습니다 . 이 데이터의 텍스트는 text8, text5및 입니다 text10.
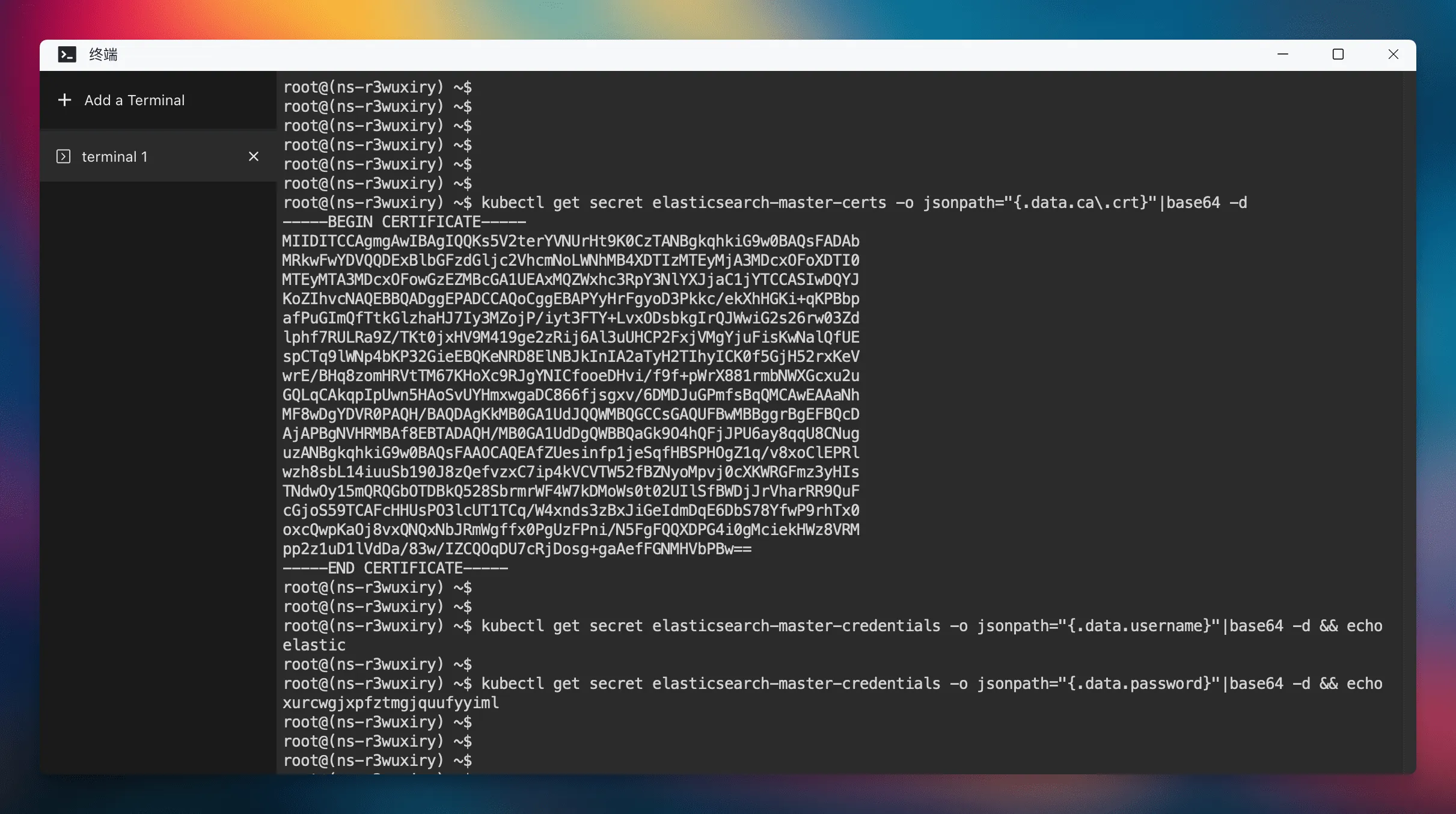
Elasticsearch 인트라넷 호출 주소는 다음과 같습니다.

ca 값은 Elasticsearch 인증서입니다. Elasticsearch 인증서는 명령줄을 통해 얻을 수 있습니다. 먼저 Sealos 데스크탑에서 "터미널" 앱을 연 후 다음 명령을 실행하여 인증서를 얻습니다.
kubectl get secret elasticsearch-master-certs -o jsonpath="{.data.ca\.crt}"|base64 -d
Elasticsearch의 사용자 이름과 비밀번호는 다음 명령을 통해 얻을 수 있습니다.
$ kubectl get secret elasticsearch-master-credentials -o jsonpath="{.data.username}"|base64 -d && echo
elastic
$ kubectl get secret elasticsearch-master-credentials -o jsonpath="{.data.password}"|base64 -d && echo
xurcwgjxpfztmgjquufyyiml
이제 간단한 데모가 완성되었으며, 다음으로 해야 할 일은 벡터 데이터베이스에 더 많은 문서의 벡터화된 데이터를 계속 추가하는 것입니다. 이를 통해 강력한 지식 기반을 구축할 수 있습니다. 사용자가 질문을 하면 먼저 사용자의 질문을 벡터 데이터로 변환한 후 벡터 데이터베이스에서 가장 유사한 문서를 찾아 위와 같이 해당 문서를 대형 모델에 입력하고 마지막으로 대형 모델에서 답변을 출력합니다. 우리의 스타 프로젝트 FastGPT가 이를 수행합니다. 게다가 빙챗(Bing Chat)도 유사하다고 보는 것은 어렵지 않습니다.
요약하다
Laf를 Sealos 클라우드 운영 체제 에 통합함으로써 클라우드 운영 체제 의 리소스를 보다 효율적으로 활용할 수 있습니다 . 사용자는 MySQL, PostgreSQL, MongoDB, Redis 등 Sealos가 Laf 에서 제공하는 다양한 데이터베이스와 서비스 는 물론 메시지 큐, 마이크로서비스를 직접 호출하여 리소스 활용도를 극대화할 수 있습니다 . 이 통합 방법을 통해 Laf는 더욱 포괄적인 서버리스 플랫폼이 됩니다. 특히 백엔드 기능 측면에서 이번 통합은 기존 서버리스 플랫폼의 단점을 보완하는 원활한 솔루션을 제공합니다.
OpenAI는 모든 사용자에게 ChatGPT Voice Vite 5를 무료로 공개합니다. 공식 출시됩니다. 운영자의 마법 작전: 백그라운드에서 네트워크 연결을 끊고, 광대역 계정을 비활성화하고, 사용자가 광 모뎀을 강제로 변경하도록 합니다. Microsoft 오픈 소스 터미널 채팅 프로그래머가 ETC 잔액을 조작하고 연간 260만 위안 이상 횡령 Redis의 아버지가 사용하는 Pure C 언어 코드는 Telegram Bot 프레임워크를 구현합니다. 오픈 소스 프로젝트 관리자라면 이런 답변을 어디까지 견딜 수 있습니까? Microsoft Copilot Web AI는 중국 OpenAI를 지원하는 12월 1일 공식 출시될 예정입니다 . 전 CEO이자 사장인 Sam Altman과 Greg Brockman이 Microsoft에 합류했습니다. Broadcom은 VMware의 성공적인 인수를 발표했습니다.