
Los principios subyacentes de las transacciones.
En términos del mecanismo de implementación de transacciones, MySQL utiliza WAL: registro de escritura anticipada, registro de escritura anticipada, mecanismo para implementarlo.
En un sistema que utiliza WAL, todos los cambios se escriben primero en el registro y luego se aplican al sistema. Generalmente contiene dos partes de información: rehacer y deshacer.
¿Por qué necesitamos usar WAL y luego incluir información de rehacer y deshacer? Por ejemplo, si un sistema aplica cambios directamente al estado del sistema, luego de apagar y reiniciar la máquina, el sistema necesita saber si la operación fue exitosa, solo parcialmente exitosa o falló. Si se utiliza WAL, el sistema puede decidir si continúa completando la operación o cancela la operación después de reiniciar comparando el registro y el estado del sistema.
El registro de rehacer se llama registro de rehacer. Siempre que hay una operación, la operación se escribe en el registro de rehacer antes de que cambien los datos, de modo que cuando ocurre un corte de energía o similar, el sistema pueda continuar funcionando después de reiniciar.
El registro de deshacer se llama registro de deshacer. Cuando algunos cambios no se pueden completar a la mitad de la ejecución, el registro de deshacer se puede utilizar para restaurar el estado entre cambios.
El registro de rehacer se usa en MySQL para reparar datos cuando el sistema falla y se reinicia, mientras que el registro de deshacer se usa para garantizar la atomicidad de las transacciones.
ID de transacción
Una transacción puede ser de solo lectura o de lectura y escritura: una transacción de solo lectura se puede iniciar con la instrucción START TRANSACTION READ SOLAMENTE.
En una transacción de solo lectura, las tablas ordinarias no se pueden agregar, eliminar ni modificar, pero sí se pueden agregar, eliminar o modificar tablas temporales de usuario.
Se puede iniciar una transacción de lectura y escritura mediante la instrucción START TRANSACTION READ WRITE, o una transacción iniciada mediante las instrucciones BEGIN e START TRANSACTION se considera una transacción de lectura y escritura de forma predeterminada.
En transacciones de lectura y escritura, puede realizar operaciones de agregar, eliminar, modificar y consultar en la tabla.
Si se agrega, elimina o modifica una tabla durante la ejecución de una transacción, el motor de almacenamiento InnoDB le asignará una ID de transacción única. El método de asignación para MySQL 5.7 es el siguiente:
- Para una transacción de solo lectura, se asignará un ID de transacción a la transacción solo cuando realice por primera vez una operación de agregar, eliminar o modificar en una tabla temporal creada por un usuario. De lo contrario, no se asignará ningún ID de transacción.
- Para las transacciones de lectura y escritura, se asignará un ID de transacción a la transacción solo cuando realice operaciones de agregar, eliminar o modificar en una tabla por primera vez. De lo contrario, no se asignará ningún ID de transacción.
- A veces, aunque se abre una transacción de lectura y escritura, la transacción contiene solo declaraciones de consulta y no se ejecutan declaraciones de agregar, eliminar o modificar, lo que significa que a la transacción no se le asignará un ID de transacción.
Este ID de transacción es esencialmente un número y su estrategia de asignación es aproximadamente la misma que la de la columna oculta row_id. La estrategia específica es la siguiente:
- El servidor mantendrá una variable global en la memoria. Siempre que sea necesario asignar una identificación de transacción a una transacción, el valor de la variable se asignará a la transacción como la identificación de la transacción y la variable se incrementará en 1.
- Siempre que el valor de esta variable sea múltiplo de 256, el valor de la variable se actualizará a un atributo llamado Max Trx ID en la página número 5 del espacio de tabla del sistema. Este atributo ocupa 8 bytes de espacio de almacenamiento.
- La próxima vez que el sistema se reinicie, el atributo Max Trx ID mencionado anteriormente se cargará en la memoria, el valor se agregará a 256 y luego se asignará a la variable global, porque el valor de la variable global puede ser mayor que Max Trx cuando se cerró la última vez Valor del atributo ID.
- Esto garantiza que el valor de ID de transacción asignado en todo el sistema sea un número creciente. La transacción cuyo ID se asigna primero obtiene el ID de transacción más pequeño y la transacción cuyo ID se asigna más tarde obtiene el ID de transacción más grande.
mvcc
El nombre completo es Control de concurrencia de múltiples versiones, que es un control de concurrencia de múltiples versiones, principalmente para mejorar el rendimiento de concurrencia de la base de datos.
Cuando se produce una solicitud de lectura o escritura para la misma fila de datos, se bloqueará y bloqueará. Pero MVCC utiliza una mejor manera de manejar las solicitudes de lectura y escritura, de modo que no es necesario bloquear cuando ocurre un conflicto entre las solicitudes de lectura y escritura.
Esta lectura se refiere a la lectura instantánea, no a la lectura actual. La lectura actual es una operación de bloqueo y es un bloqueo pesimista.
Principio MVCC
Los problemas encontrados en la ejecución concurrente de transacciones son los siguientes:
- Lectura sucia: si una transacción lee datos modificados por otra transacción no confirmada, significa que se ha producido una lectura sucia;
- Lectura no repetible: si una transacción solo puede leer los datos modificados por otra transacción que se ha enviado, y cada vez que otras transacciones modifican los datos y los envían, la transacción puede consultar y obtener el último valor, lo que significa que ocurre No -lectura repetible;
- Lectura fantasma: si una transacción primero consulta algunos registros según ciertas condiciones y luego otra transacción inserta registros que cumplen estas condiciones en la tabla, cuando la transacción original vuelve a consultar de acuerdo con las condiciones, los registros insertados por la otra transacción pueden ser Si también se lee en voz alta, lo que significa que se ha producido una lectura fantasma. El énfasis de la lectura fantasma es que cuando una transacción lee registros varias veces de acuerdo con una determinada misma condición, los registros que no se han leído antes se leen en la lectura posterior. La lectura fantasma solo enfatiza que se leyó un registro que no se obtuvo antes.
MySQL puede evitar problemas de lectura fantasma en gran medida bajo el nivel de aislamiento de LECTURA REPETIBLE.
cadena de versiones
Para las tablas que utilizan el motor de almacenamiento InnoDB, sus registros de índice agrupados contienen dos columnas ocultas necesarias:
- trx_id: cada vez que una transacción cambia un registro de índice agrupado, el ID de transacción de la transacción se asignará a la columna oculta trx_id;
- roll_pointer: cada vez que se modifica un registro de índice agrupado, la versión anterior se escribirá en el registro de deshacer, y luego esta columna oculta es equivalente a un puntero, a través del cual se modifica la información antes de que se pueda encontrar el registro;
Manifestación
-- 创建表
CREATE TABLE mvcc_test (
id INT,
name VARCHAR(100),
domain varchar(100),
PRIMARY KEY (id)
) Engine=InnoDB CHARSET=utf8;
-- 添加数据
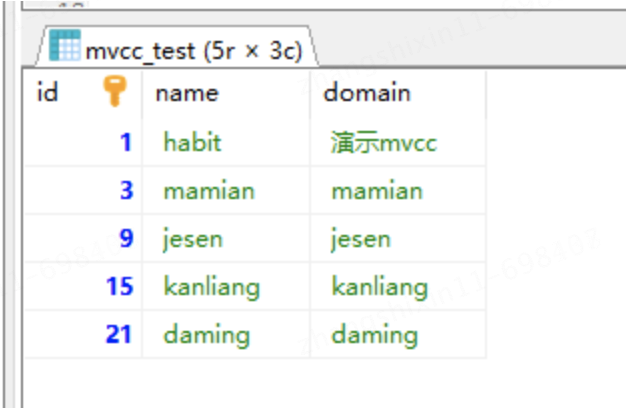
INSERT INTO mvcc_test VALUES(1, 'habit', '演示mvcc');Suponiendo que el ID de transacción para insertar el registro es 50, el registro se muestra como se muestra en la figura:
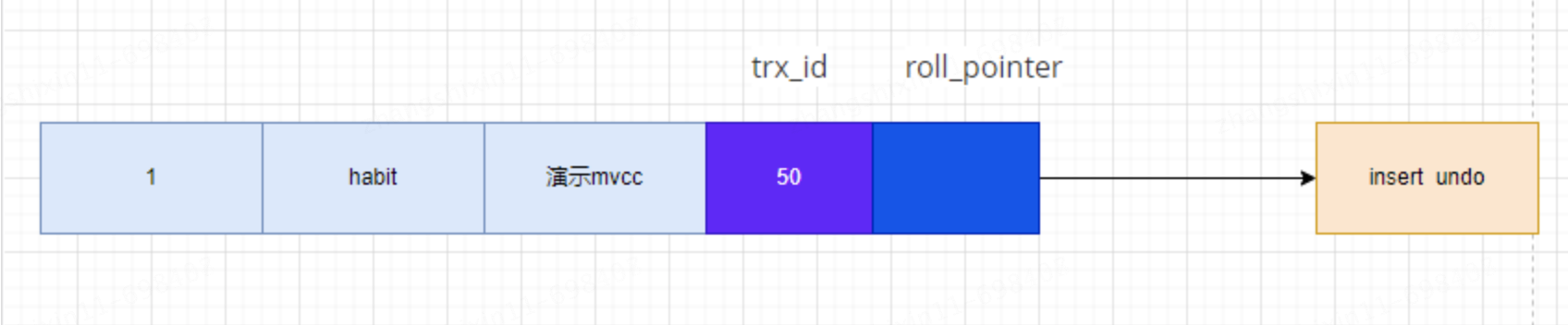
Supongamos que dos transacciones posteriores con ID de transacción de 70 y 90 realizan operaciones de ACTUALIZACIÓN en este registro.
| trx_id=70 | trx_id=90 |
|---|---|
| comenzar | |
| | comenzar |
| | |
| actualizar mvcc_test set name='habit_trx_id_70_01' donde id=1 | |
| actualizar mvcc_test set name='habit_trx_id_70_02' donde id=1 | |
| comprometerse | |
| | actualizar mvcc_test set name='habit_trx_id_90_01' donde id=1 |
| | actualizar mvcc_test set name='habit_trx_id_90_02' donde id=1 |
| | comprometerse |
Cada vez que se modifica un registro, se registrará un registro de deshacer. Cada registro de deshacer también tiene un atributo roll_pointer. Estos registros de deshacer se pueden conectar para formar una lista vinculada.
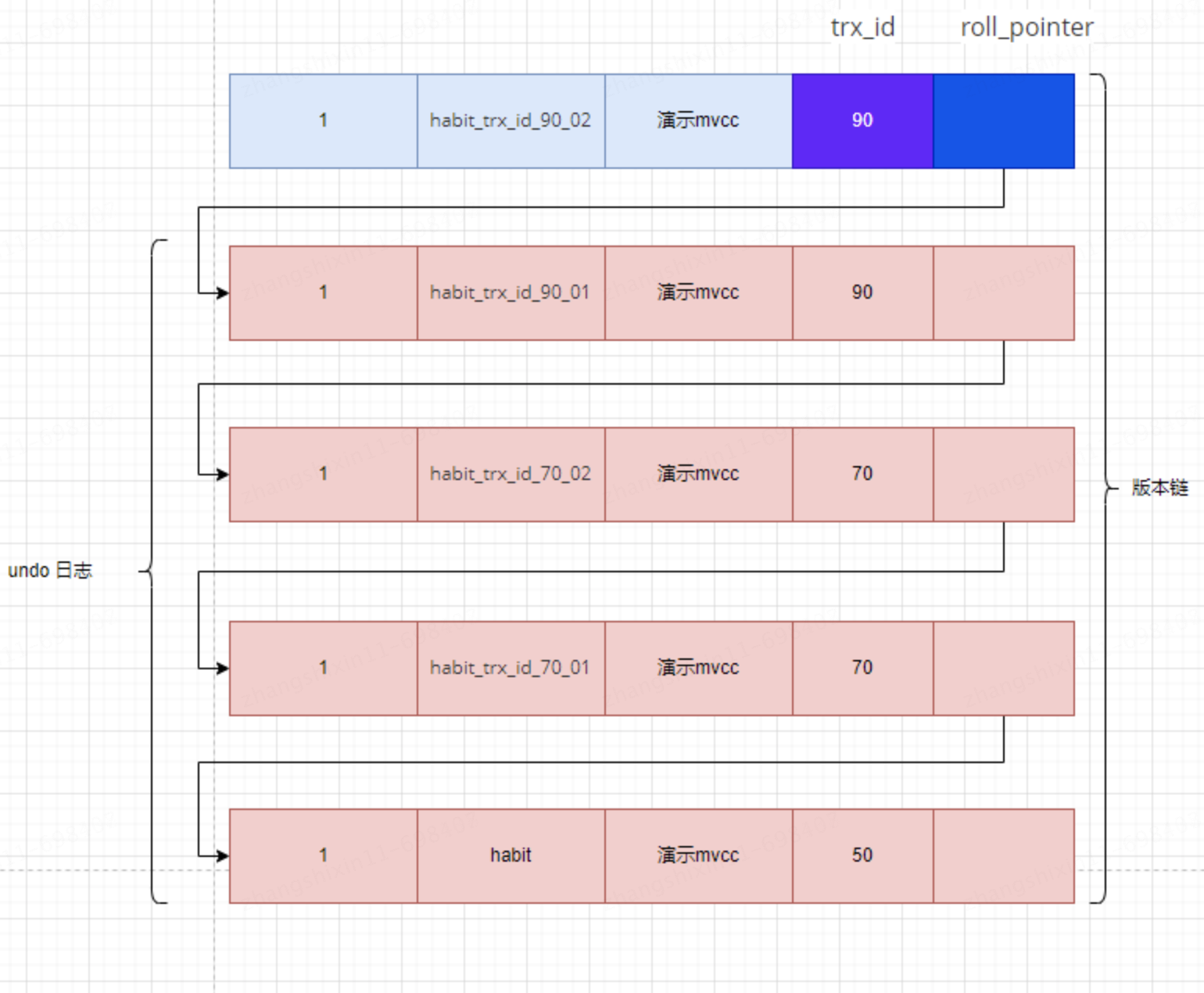
Después de cada actualización del registro, el valor anterior se colocará en un registro de deshacer. Incluso si es una versión anterior del registro, a medida que aumenta el número de actualizaciones, todas las versiones se conectarán en una lista vinculada mediante el atributo roll_pointer. Esta lista vinculada se llama cadena de versiones y el nodo principal de la cadena de versiones es el último valor del registro actual. Además, cada versión también contiene el ID de transacción correspondiente al momento en que se generó la versión. Por lo tanto, la cadena de versiones de este registro se puede utilizar para controlar el comportamiento de las transacciones simultáneas que acceden al mismo registro, este mecanismo se denomina control de concurrencia de versiones múltiples o MVCC.
LeerVer
Para las transacciones que utilizan el nivel de aislamiento READ UNCOMMITTED, dado que los registros modificados por transacciones no confirmadas se pueden leer, basta con leer directamente la última versión del registro.
Para transacciones que utilizan el nivel de aislamiento SERIALIZABLE, InnoDB utiliza bloqueo para acceder a los registros.
Para las transacciones que utilizan los niveles de aislamiento READ COMMITTED y REPEATABLE READ, es necesario asegurarse de que se lean los registros modificados por la transacción enviada, es decir, si otra transacción ha modificado el registro pero aún no lo ha enviado, no puede hacerlo directamente. Para la grabación de versiones más recientes, el problema central es: ¿de dónde proviene la diferencia entre los niveles de aislamiento de LECTURA COMPROMETIDA y LECTURA REPETIBLE en lectura no repetible y lectura fantasma? De hecho, combinado con el conocimiento previo, la clave para estos dos aislamientos niveles es para juzgar la cadena de versiones, qué versión es visible para la transacción actual.
Para ello, InnoDB propone el concepto de ReadView, que contiene principalmente cuatro contenidos importantes:
- m_ids: representa la lista de ID de transacción de transacciones de lectura y escritura activas en el sistema actual cuando se genera ReadView;
- min_trx_id: indica la identificación de transacción más pequeña entre las transacciones de lectura y escritura activas en el sistema actual cuando se genera ReadView, que es el valor más pequeño en m_ids;
- max_trx_id: indica el valor de identificación que se debe asignar a la siguiente transacción en el sistema al generar ReadView. Nota: max_trx_id no es el valor máximo en m_ids y la identificación de la transacción se asigna de forma incremental. Por ejemplo, hay tres transacciones con los ID 1, 2 y 3, y luego se confirma la transacción con el ID 3. Luego, cuando una nueva transacción de lectura genera ReadView, m_ids incluye 1 y 2, el valor de min_trx_id es 1 y el valor de max_trx_id es 4;
- Creator_trx_id: Indica el id de la transacción que generó el ReadView;
Con este ReadView, al acceder a un registro, solo necesita seguir los pasos a continuación para determinar si una determinada versión del registro es visible:
- Si el valor del atributo trx_id de la versión accedida es el mismo que el valor de Creator_trx_id en ReadView, significa que la transacción actual está accediendo a sus propios registros modificados, por lo que la transacción actual puede acceder a esta versión;
- Si el valor del atributo trx_id de la versión accedida es menor que el valor min_trx_id en ReadView, indica que la transacción que generó esta versión se confirmó antes de que la transacción actual genere ReadView, por lo que la transacción actual puede acceder a esta versión;
- Si el valor del atributo trx_id de la versión accedida es mayor o igual que el valor max_trx_id en ReadView, significa que la transacción que generó esta versión se abrió después de que la transacción actual generó ReadView, por lo que el actual no puede acceder a esta versión. transacción;
- Si el valor del atributo trx_id de la versión a la que se accede está entre min_trx_id y max_trx_id de ReadView, min_trx_id <trx_id <max_trx_id, entonces debe determinar si el valor del atributo trx_id está en la lista m_ids. Si es así, significa que la transacción de este La versión se generó cuando se creó ReadView. Activa, no se puede acceder a esta versión, si no, significa que la transacción que generó esta versión cuando se creó ReadView se ha confirmado y se puede acceder a esta versión;
- Si una determinada versión de los datos no es visible para la transacción actual, siga la cadena de versiones para encontrar la siguiente versión de los datos, continúe siguiendo los pasos anteriores para determinar la visibilidad, y así sucesivamente, hasta la última versión de la cadena de versiones. . Si la última versión no es visible, significa que el registro es completamente invisible para la transacción y el resultado de la consulta no incluye el registro;
En MySQL, una diferencia muy grande entre los niveles de aislamiento READ COMMITTED y REPEATABLE READ es el diferente momento en el que generan ReadView.
Tomemos la tabla mvcc_test como ejemplo. Supongamos que solo hay un registro insertado por la transacción con ID de transacción 50 en la tabla mvcc_test. A continuación, echemos un vistazo a la diferencia en el llamado tiempo de generación de ReadView entre LEER COMPROMETIDO y LECTURA REPETIBLE.
LECTURA COMPROMETIDA: Se genera un ReadView cada vez antes de leer los datos;
Por ejemplo, hay dos transacciones con los ID de transacción 70 y 90 actualmente ejecutándose en el sistema:
-- T 70
UPDATE mvcc_test SET name = 'habit_trx_id_70_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_70_02' WHERE id = 1;En este momento, la lista vinculada de versiones obtenida por el registro con id 1 en la tabla mvcc_test es la siguiente:

Supongamos que se inicia una transacción que utiliza el nivel de aislamiento READ COMMITTED:
-- 使用 READ COMMITTED 隔离级别的事务
BEGIN;
-- SELECE1:Transaction 70、90 未提交
SELECT * FROM mvcc_test WHERE id = 1;
-- 得到的列 name 的值为'habit'El proceso de ejecución de SELCE1 es el siguiente:
Al ejecutar la instrucción SELECT, primero se generará un ReadView. El contenido de la lista m_ids de ReadView es [70, 90], min_trx_id es 70, max_trx_id es 91 y Creator_trx_id es 0.
Luego seleccione los registros visibles de la cadena de versiones. Como se puede ver en la figura, el contenido del nombre de la columna de la última versión es habit_trx_id_70_02. El valor trx_id de esta versión es 70, que está en la lista m_ids, por lo que no cumplir con el requisito de visibilidad Artículo 4: saltar a la siguiente versión basada en roll_pointer.如果被访问版本的 trx_id 属性值在 ReadView 的 min_trx_id 和 max_trx_id之间 min_trx_id < trx_id < max_trx_id,那就需要判断一下trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
El contenido del nombre de la columna de la próxima versión es habitat_trx_id_70_01. El valor trx_id de esta versión también es 70 y también está en la lista m_ids, por lo que no cumple con los requisitos y continúa saltando a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es hábito. El valor trx_id de esta versión es 50, que es menor que el valor min_trx_id en ReadView, por lo que esta versión cumple con los requisitos. Artículo 2: Si el valor del atributo trx_id del objeto accedido La versión es menor que el valor min_trx_id en ReadView Value, lo que indica que la transacción que generó esta versión se confirmó antes de que la transacción actual genere ReadView, por lo que la transacción actual puede acceder a esta versión. La versión final devuelta es el registro cuyo nombre de columna es hábito.
Después de eso, envíe la transacción con el ID de transacción 70 y luego actualice el registro con el ID 1 en la tabla mvcc_test en la transacción con el ID de transacción 90:
-- T 90
UPDATE mvcc_test SET name = 'habit_trx_id_90_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_90_02' WHERE id = 1;En este momento, la cadena de versiones del registro con ID 1 en la tabla mvcc se ve así:
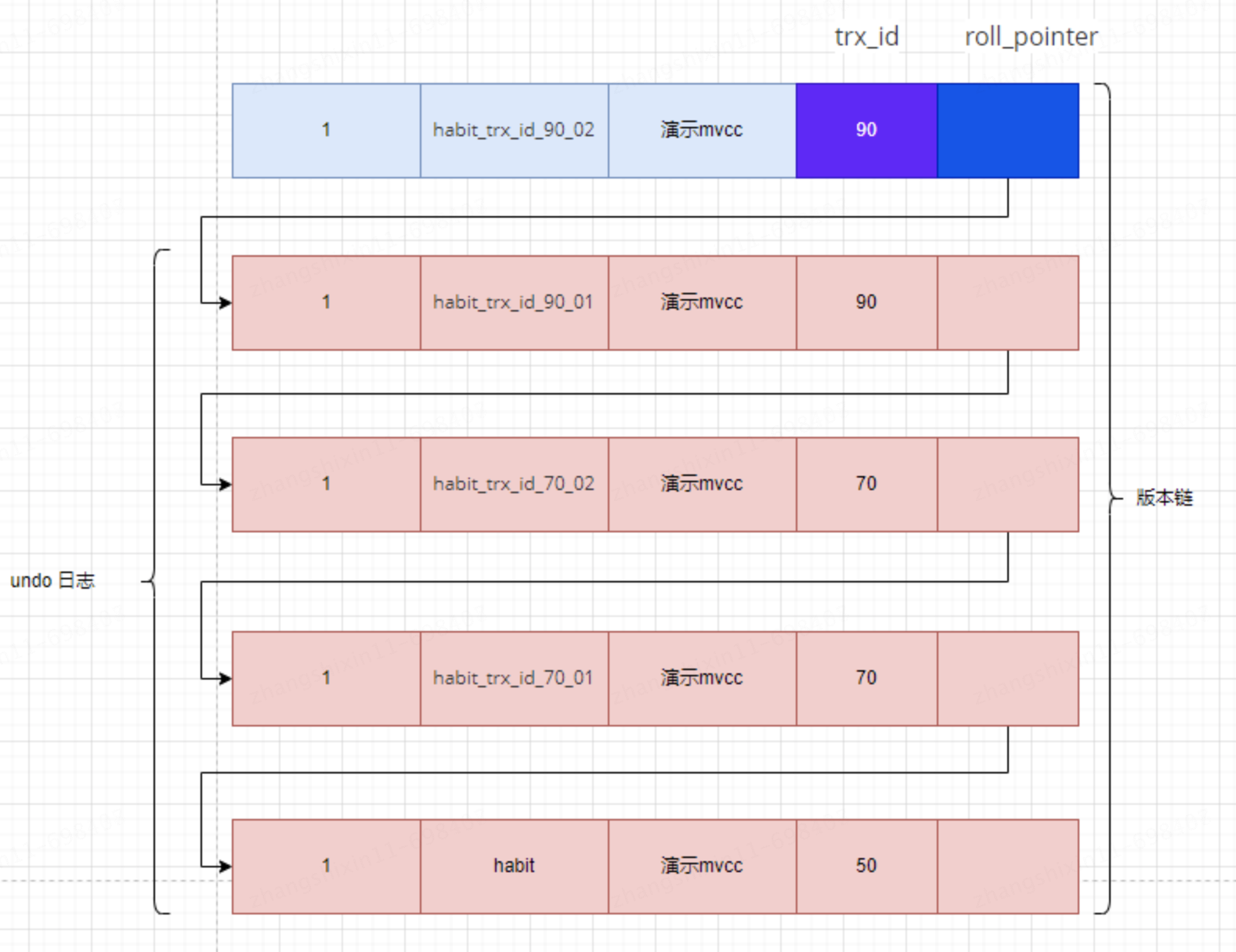
Luego continúe buscando el registro con ID 1 en la transacción que acaba de usar el nivel de aislamiento LEER COMMITIDO, de la siguiente manera:
-- 使用 READ COMMITTED 隔离级别的事务
BEGIN;
-- SELECE1:Transaction 70、90 均未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值为'habit'
-- SELECE2:Transaction 70 提交,Transaction 90 未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值为'habit_trx_id_70_02'El proceso de ejecución de SELCE2 es el siguiente:
Al ejecutar la instrucción SELECT, se generará un ReadView por separado. El contenido de la lista m_ids de ReadView es [90], min_trx_id es 90, max_trx_id es 91 y Creator_trx_id es 0.
Luego seleccione los registros visibles de la cadena de versiones. Como se puede ver en la figura, el contenido del nombre de la columna de la última versión es habit_trx_id_90_02. El valor trx_id de esta versión es 90, que está en la lista m_ids, por lo que no cumplir con los requisitos de visibilidad Saltar según roll_pointer a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es habitat_trx_id_90_01. El valor trx_id de esta versión es 90, que también está en la lista m_ids, por lo que no cumple con los requisitos y continúa saltando a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es habitat_trx_id_70_02. El valor trx_id de esta versión es 70, que es menor que el valor min_trx_id 90 en ReadView, por lo que esta versión cumple con los requisitos. Finalmente, el registro cuyo nombre de columna es habit_trx_id_70_02 en se devuelve esta versión.
Por analogía, si el registro con el ID de transacción 90 también se envía más tarde, cuando el registro con el valor de ID 1 en la tabla mvcc_test se consulta nuevamente en una transacción usando el nivel de aislamiento READ COMMITTED, el resultado obtenido es habit_trx_id_90_02.
Resumen: Las transacciones que utilizan el nivel de aislamiento READ COMMITTED generarán un ReadView independiente al comienzo de cada consulta.
LECTURA REPETIBLE: Genera un ReadView cuando lees datos por primera vez;
Para las transacciones que utilizan el nivel de aislamiento REPEATABLE READ, solo se generará un ReadView la primera vez que se ejecute una declaración de consulta y las consultas posteriores no se generarán repetidamente.
Por ejemplo, hay dos transacciones con los ID de transacción 70 y 90 actualmente ejecutándose en el sistema:
-- T 70
UPDATE mvcc_test SET name = 'habit_trx_id_70_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_70_02' WHERE id = 1;En este momento, la lista vinculada de versiones obtenida por el registro con id 1 en la tabla mvcc_test es la siguiente:
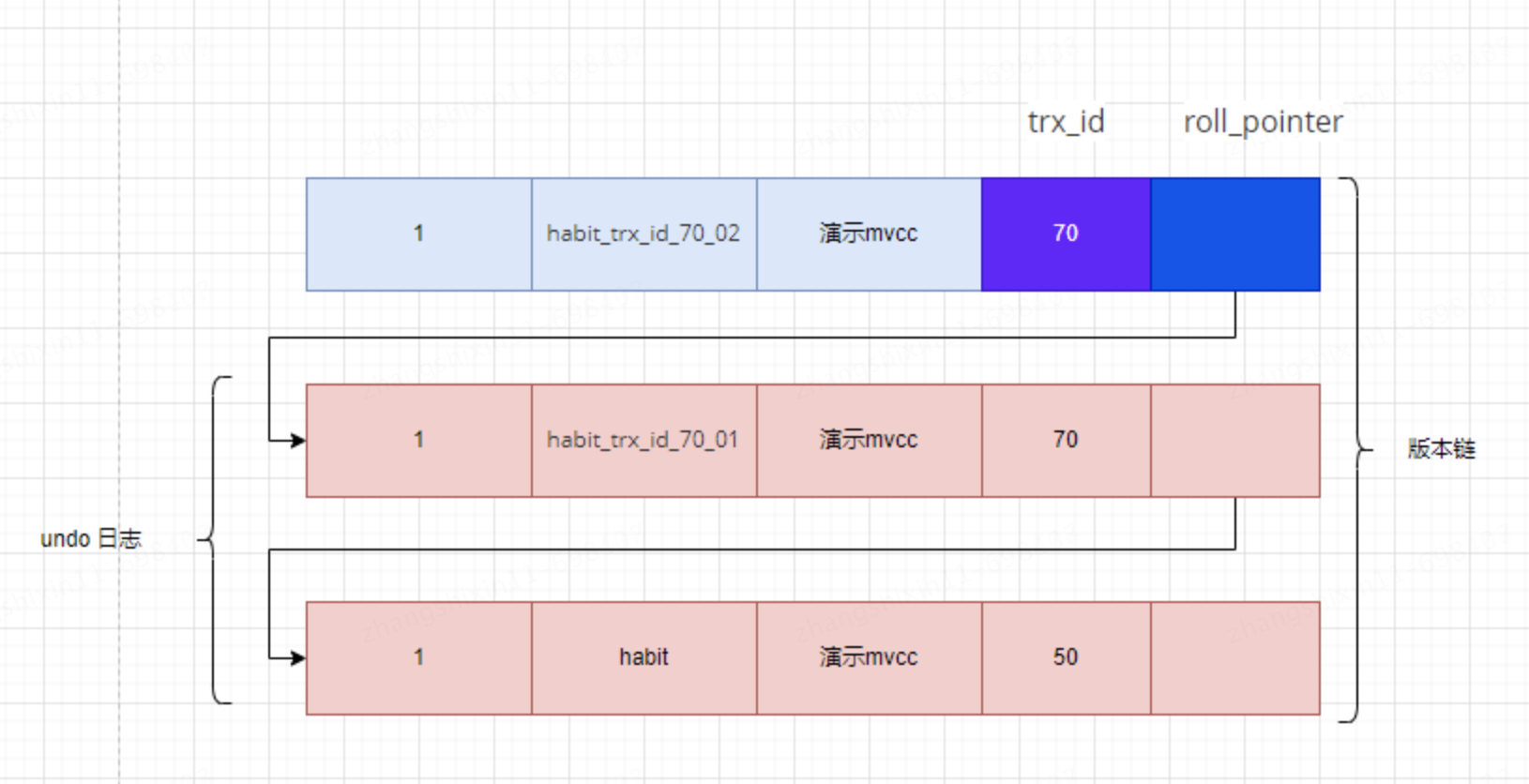
Supongamos que se inicia una transacción que utiliza el nivel de aislamiento REPEATABLE READ:
-- 使用 REPEATABLE READ 隔离级别的事务
BEGIN;
-- SELECE1:Transaction 70、90 未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列name 的值为'habit'El proceso de ejecución de SELCE1 es el siguiente:
Al ejecutar la instrucción SELECT, primero se generará un ReadView. El contenido de la lista m_ids de ReadView es [70, 90], min_trx_id es 70, max_trx_id es 91 y Creator_trx_id es 0.
Luego seleccione los registros visibles de la cadena de versiones. Como se puede ver en la figura, el contenido del nombre de la columna de la última versión es habit_trx_id_70_02. El valor trx_id de esta versión es 70, que está en la lista m_ids, por lo que no cumplir con los requisitos de visibilidad Saltar según roll_pointer a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es habitat_trx_id_70_01. El valor trx_id de esta versión también es 70 y también está en la lista m_ids, por lo que no cumple con los requisitos y continúa saltando a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es habitual. El valor trx_id de esta versión es 50, que es menor que el valor min_trx_id en ReadView, por lo que esta versión cumple con los requisitos. El último registro devuelto es el registro cuyo nombre de columna es hábito.
Después de eso, envíe la transacción con el ID de transacción 70 y luego actualice el registro con el ID 1 en la tabla mvcc_test en la transacción con el ID de transacción 90:
-- 使用 REPEATABLE READ 隔离级别的事务
BEGIN;
UPDATE mvcc_test SET name = 'habit_trx_id_90_01' WHERE id = 1;
UPDATE mvcc_test SET name = 'habit_trx_id_90_02' WHERE id = 1;En este momento, la cadena de versiones del registro con id 1 en la tabla mvcc_test se ve así:
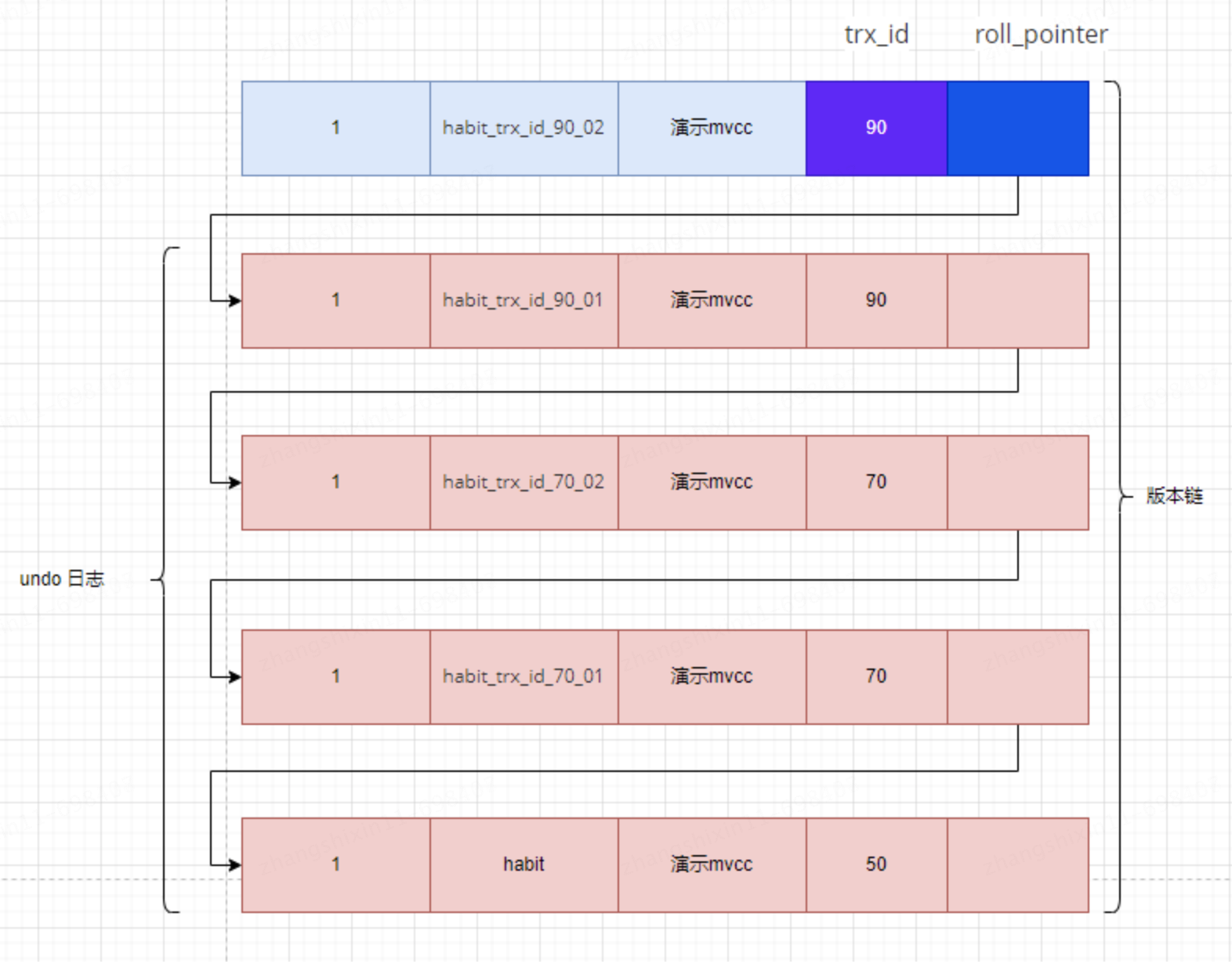
Luego continúe buscando el registro con ID 1 en la transacción que acaba de usar el nivel de aislamiento REPEATABLE READ, de la siguiente manera:
-- 使用 REPEATABLE READ 隔离级别的事务
BEGIN;
-- SELECE1:Transaction 70、90 均未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值为'habit'
-- SELECE2:Transaction 70 提交,Transaction 90 未提交
SELECT * FROM mvcc_test WHERE id = 1; -- 得到的列 name 的值为'habit'El proceso de ejecución de SELCE2 es el siguiente:
Debido a que el nivel de aislamiento de la transacción actual es READ REPETIBLE y se generó un ReadView antes de ejecutar SELCE1, el ReadView anterior se reutiliza directamente en este momento. El contenido de la lista m_ids del ReadView anterior es [70, 90], y min_trx_id es 70., max_trx_id es 91, Creator_trx_id es 0.
Luego seleccione los registros visibles de la cadena de versiones. Como se puede ver en la figura, el contenido del nombre de la columna de la última versión es habit_trx_id_90_02. El valor trx_id de esta versión es 90, que está en la lista m_ids, por lo que no cumplir con los requisitos de visibilidad Saltar según roll_pointer a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es habitat_trx_id_90_01. El valor trx_id de esta versión es 90, que también está en la lista m_ids, por lo que no cumple con los requisitos y continúa saltando a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es habit_trx_id_70_02. El valor trx_id de esta versión es 70 y la lista m_ids contiene el ID de transacción con un valor de 70, por lo que esta versión no cumple con los requisitos. De manera similar, el contenido de el nombre de la siguiente columna es La versión de habit_trx_id_70_01 tampoco cumple con los requisitos. Continúe saltando a la siguiente versión.
El contenido del nombre de la columna de la próxima versión es hábito. El valor trx_id de esta versión es 50, que es menor que el valor min_trx_id 70 en ReadView, por lo que esta versión cumple con los requisitos. La versión devuelta al usuario al final es el registro con el nombre de la columna de hábito. .
Es decir, los resultados obtenidos por las dos consultas SELECT se repiten y los valores de los nombres de las columnas registrados son todos hábitos, este es el significado de lectura repetible. Si envía el registro con el ID de transacción 90 más tarde y luego continúa buscando el registro con el ID 1 en la transacción que acaba de usar el nivel de aislamiento REPEATABLE READ, el resultado seguirá siendo habitual.
Solución de lectura fantasma y fenómeno de lectura fantasma bajo MVCC
MVCC puede resolver el problema de lectura no repetible bajo el nivel de aislamiento de LECTURA REPETIBLE, pero ¿qué pasa con las lecturas fantasma? ¿Cómo se resuelve MVCC? La lectura fantasma es cuando una transacción lee registros varias veces de acuerdo con las mismas condiciones, y la última lectura lee un registro que no se ha leído antes, y este registro proviene de un nuevo registro agregado por otra transacción.
Puede pensarlo: la transacción T1 bajo el nivel de aislamiento REPEATABLE READ primero lee varios registros según una determinada condición de búsqueda, luego la transacción T2 inserta un registro que cumple con la condición de búsqueda correspondiente y lo envía, y luego la transacción T1 ejecuta una consulta basada en la misma condición de búsqueda. . ¿Cuál será el resultado? De acuerdo con los artículos 3 y 4 de las reglas de comparación en ReadView, independientemente de si la transacción T2 se abre antes que la transacción T1, la transacción T1 no puede ver el envío de T2.
Sin embargo, MVCC en InnoDB bajo el nivel de aislamiento REPEATABLE READ puede evitar en gran medida la lectura fantasma, en lugar de prohibir por completo la lectura fantasma. ¿Qué está sucediendo? Considere la siguiente situación:
Primero ejecute en la transacción T1: en este momento, no se puede encontrar el registro con id = 30.select * from mvcc_test where id = 30;
En la transacción T2, ejecute la instrucción de inserción:insert into mvcc_test values(30,'luxi','luxi');
En este punto, regrese a la transacción T1 y ejecute:
update mvcc_test set domain='luxi_t1' where id=30;
select * from mvcc_test where id = 30;La transacción T1 obviamente tiene un fenómeno de lectura fantasma.
Bajo el nivel de aislamiento REPEATABLE READ, T1 genera un ReadView cuando ejecuta una instrucción SELECT ordinaria por primera vez, y luego T2 inserta un nuevo registro en la tabla mvcc_test y lo envía.
ReadView no puede evitar que T1 ejecute la instrucción UPDATE o DELETE para modificar el registro recién insertado. Dado que T2 ya lo envió, modificar el registro no provocará el bloqueo. Sin embargo, de esta manera, el valor de la columna oculta trx_id de este nuevo registro cambio Se convierte en la identificación de la transacción de T1. Después de eso, T1 puede ver este registro cuando usa una instrucción SELECT ordinaria para consultar este registro y puede devolver este registro al cliente. Debido a la existencia de este fenómeno especial, se puede considerar que MVCC no puede prohibir por completo la lectura fantasma.
resumen mvcc
Como se puede ver en la descripción anterior, el llamado MVCC (Control de concurrencia de múltiples versiones) se refiere al uso de dos transacciones de nivel de aislamiento, READ COMMITTD y REPEATABLE READ, para acceder a registros al realizar operaciones SELECT ordinarias. El proceso de cadena de versiones permite que las operaciones de lectura y escritura, escritura y lectura de diferentes transacciones se ejecuten simultáneamente, mejorando así el rendimiento del sistema.
Una gran diferencia entre los dos niveles de aislamiento de READ COMMITTD y REPEATABLE READ es que el momento de generar ReadView es diferente. READ COMMITTD genera un ReadView antes de cada operación SELECT ordinaria, mientras que REPEATABLE READ solo realiza la primera operación SELECT ordinaria. Simplemente genere un ReadView antes y reutilice este ReadView para operaciones de consulta posteriores, evitando así básicamente el fenómeno de la lectura fantasma.
Grupo de búfer de InnoDB
Para las tablas que utilizan InnoDB como motor de almacenamiento, ya sean índices utilizados para almacenar datos del usuario, incluidos índices agrupados e índices secundarios, o varios datos del sistema, todos se almacenan en el espacio de tablas en forma de páginas. El espacio de tabla es solo la abstracción de InnoDB de uno o varios archivos reales en el sistema de archivos, lo que significa que los datos todavía están almacenados en el disco.
Sin embargo, la velocidad del disco es lenta, por lo que cuando el motor de almacenamiento InnoDB necesita acceder a los datos de una determinada página al procesar la solicitud del cliente, cargará todos los datos de la página completa en la memoria, incluso si solo hay un registro. Es necesario acceder a una página, lo que también requiere cargar primero toda la página de datos en la memoria. Después de cargar toda la página en la memoria, puede realizar acceso de lectura y escritura. Después del acceso de lectura y escritura, no tiene prisa por liberar el espacio de memoria correspondiente a la página, sino almacenarlo en caché para que haya una solicitud. Para acceder a la página nuevamente en el futuro, puede ahorrar la sobrecarga de E/S del disco.
Grupo de almacenamiento intermedio
Para almacenar en caché las páginas en el disco, InnoDB solicita una memoria continua del sistema operativo cuando se inicia el servidor MySQL, esta memoria continua se llama: Buffer Pool, nombre chino: buffer pool.
De forma predeterminada, el grupo de búfer tiene un tamaño de solo 128 M.
Ver el valor:show variables like 'innodb_buffer_pool_size';
Puede configurar el valor del parámetro innodb_buffer_pool_size al iniciar el servidor, que indica el tamaño del Buffer Pool, la configuración es la siguiente:
[server]
innodb_buffer_pool_size = 268435456Entre ellos, la unidad de 268435456 es bytes, es decir, el tamaño del grupo de búfer especificado es 256 M. El grupo de búfer no puede ser demasiado pequeño. El valor mínimo es 5 M. Cuando sea menor que este valor, se configurará automáticamente. a 5M.
Al iniciar el servidor MySQL, debe completar el proceso de inicialización del Buffer Pool, que consiste en solicitar primero al sistema operativo el espacio de memoria del Buffer Pool y luego dividirlo en pares de bloques de control y páginas de caché. Sin embargo, en este momento no se almacenan en caché páginas de disco reales en el Buffer Pool. Más adelante, a medida que se ejecuta el programa, las páginas del disco seguirán almacenándose en caché en el Buffer Pool.
Se crearán varias páginas de caché en el grupo de búfer. El tamaño de página de caché predeterminado es el mismo que el tamaño de página predeterminado en el disco, ambos de 16 KB.
Entonces, ¿cómo saber si la página está en el Buffer Pool?
Al buscar datos, primero verifique si la clave está en la tabla hash a través de la tabla hash. Si prueba que la información de caché existe en el Buffer Pool, si no existe, prueba que la información de caché no existe y carga leer el disco.La información de la página se coloca en el Buffer Pool.La clave en la tabla hash se compone del número de espacio de tabla + número de página, y el valor es la página de caché del Buffer Pool.
gestión de listas enlazadas al ras
Si se modifican los datos de una página de caché en el grupo de búfer, serán inconsistentes con la página en el disco, dicha página de caché también se denomina página sucia . La forma más sencilla es sincronizar inmediatamente con la página correspondiente en el disco cada vez que se produce una modificación, pero la escritura frecuente de datos en el disco afectará seriamente el rendimiento del programa. Por lo tanto, cada vez que se modifica la página de caché, no hay prisa por sincronizar la modificación en el disco, sino en un momento determinado en el futuro. Pero si no se sincroniza con el disco inmediatamente, ¿cómo sabrá qué páginas del Buffer Pool están sucias y qué páginas nunca se han modificado al sincronizar más tarde? Es imposible sincronizar todas las páginas de caché con el disco. Si el grupo de búfer está configurado en un tamaño grande, la sincronización única será muy lenta.
Por lo tanto, debe crear otra lista vinculada para almacenar páginas sucias. Los bloques de control correspondientes a las páginas de caché modificadas se agregarán a una lista vinculada como un nodo, porque las páginas de caché correspondientes a los nodos en esta lista vinculada deben actualizarse al disco, por lo que también se le llama lista enlazada al ras.
Vaciar las páginas sucias al disco
Hay un hilo dedicado en segundo plano que es responsable de actualizar las páginas sucias en el disco de vez en cuando, de modo que no afecte el procesamiento de las solicitudes normales por parte del hilo del usuario.
Actualice algunas páginas de la lista de descarga al disco, y el hilo en segundo plano también actualizará periódicamente algunas páginas de la lista de descarga al disco. La frecuencia de actualización depende de si el sistema está muy ocupado en ese momento. Esta forma de actualizar la página se llama: BUF_FLUSH_LIST.
rehacer registro
El papel de los registros de rehacer
El motor de almacenamiento InnoDB administra el espacio de almacenamiento en unidades de páginas. Las operaciones de agregar, eliminar, modificar y consultar son esencialmente acceso a páginas, que incluyen: leer páginas, escribir páginas, crear nuevas páginas y otras operaciones. Antes de acceder realmente a la página, la página en el disco debe almacenarse en caché en el grupo de búfer de la memoria antes de poder acceder a ella. Sin embargo, al tratar con transacciones se enfatizó una característica llamada persistencia, es decir, para una transacción que se ha enviado, incluso si el sistema falla después de enviar la transacción, los cambios realizados por esta transacción en la base de datos no se pueden perder.
Si la página solo se modifica en el grupo de búfer de memoria, suponiendo que se produzca una falla repentina después de enviar la transacción, lo que provocará que todos los datos en la memoria dejen de ser válidos, entonces los cambios realizados en la base de datos por la transacción enviada también seguirán. Perdido, esto es intolerable. Entonces, ¿cómo garantizar esta durabilidad? Un enfoque muy simple es vaciar todas las páginas modificadas por la transacción en el disco antes de que se confirme la transacción. Sin embargo, este enfoque simple y tosco tiene algunos problemas:
- Actualizar una página de datos completa es un desperdicio; a veces solo se modifica un byte en una página, pero en InnoDB la E/S del disco se realiza en unidades de páginas, lo que significa que cuando se envía la transacción, la página completa se vacía de la memoria al disco. El tamaño predeterminado de una página es 16 KB. Obviamente es un desperdicio actualizar 16 KB de datos en el disco cuando solo se modifica un byte.
- El IO aleatorio es relativamente lento para vaciar; una transacción puede contener muchas declaraciones, e incluso una declaración puede modificar muchas páginas. Las páginas modificadas por la transacción pueden no ser adyacentes, lo que significa que en el grupo de búfer donde se modifica una determinada transacción, cuando Cuando la página se actualiza en el disco, se requieren muchas E/S aleatorias, que son más lentas que las E/S secuenciales, especialmente para los discos duros mecánicos tradicionales.
Solo quiero que las modificaciones realizadas por la transacción enviada a los datos de la base de datos surtan efecto de forma permanente. Incluso si el sistema falla más tarde, esta modificación se puede restaurar después de reiniciar. De hecho, no es necesario actualizar en el disco todas las páginas modificadas en la memoria por la transacción cada vez que se confirma una transacción. Solo necesita registrar lo que se ha modificado. Por ejemplo: una transacción cambia la primera página en el espacio de tabla del sistema. Para cambiar el valor del byte en el desplazamiento 5000 en la página No. 5 de 0 a 5, solo necesita registrar: Actualice el valor en el desplazamiento 5000 en la página No. 5 en el espacio de tabla No. 5 a: 5 .
De esta manera, cuando se confirma la transacción, el contenido anterior se vacía en el disco. Incluso si el sistema falla más tarde, siempre que la página de datos se actualice de acuerdo con los pasos registrados en el contenido anterior después del reinicio, las modificaciones realizadas en la base de datos mediante la transacción se puede restaurar. Salir significa cumplir con los requisitos de persistencia. Debido a que la página de datos debe volver a actualizarse de acuerdo con los pasos registrados anteriormente cuando el sistema falla y se reinicia, el contenido anterior también se llama: rehacer registro, es decir: rehacer registro . En comparación con vaciar todas las páginas modificadas en la memoria al disco cuando se confirma una transacción, los beneficios de vaciar solo el registro de rehacer generado durante la ejecución de la transacción al disco son los siguientes:
- El registro de rehacer ocupa muy poco espacio y el espacio de almacenamiento necesario para almacenar el ID del espacio de tabla, el número de página, el desplazamiento y el valor que debe actualizarse es muy pequeño;
- El registro de rehacer se escribe en el disco secuencialmente. Durante la ejecución de una transacción, cada vez que se ejecuta una declaración, se pueden generar varios registros de rehacer. Estos registros se escriben en el disco en el orden en que se generan, es decir, se utiliza IO secuencial;
El proceso de escritura del registro de rehacer.
Para recuperarse mejor de fallas del sistema, InnoDB coloca el registro de rehacer generado por una operación atómica en bloques de 512 bytes.
Buffer Pool se introdujo para resolver el problema de la baja velocidad del disco. De la misma manera, al escribir el registro de rehacer, no puede escribirlo directamente en el disco. De hecho, cuando se inicia el servidor, solicita al sistema operativo un gran espacio de memoria continuo llamado búfer de registro de rehacer, es decir, búfer de registro de rehacer. También puede ser Abreviatura: buffer de registro. Este espacio de memoria se divide en varios bloques de registro de rehacer consecutivos. El tamaño del búfer de registro se puede especificar a través del parámetro de inicio innodb_log_buffer_size. El valor predeterminado de este parámetro de inicio es: 16 MB.
El proceso de escribir el registro de rehacer en el búfer de registro es secuencial, es decir, escribir primero en el bloque anterior y luego escribir en el siguiente bloque cuando se agota el espacio libre del bloque.
rehacer el tiempo de vaciado del registro
¿Cuándo se escribirá el búfer de registro en el disco?
- Cuando el búfer de registro no tiene espacio suficiente, si continúa llenando registros en el búfer de registro de tamaño limitado, se llenará pronto. InnoDB cree que si la cantidad de registros de rehacer escritos actualmente en el búfer de registros ha ocupado aproximadamente la mitad de la capacidad total del búfer de registros, estos registros deben vaciarse en el disco.
- Cuando se confirma la transacción, el registro de rehacer correspondiente a las páginas modificadas debe vaciarse en el disco.
- Hay un hilo en segundo plano que actualiza el registro de rehacer en el búfer de registro en el disco aproximadamente cada segundo.
- Al cerrar el servidor correctamente, etc.
deshacer registro
Las transacciones deben ser atómicas, es decir, todas las operaciones de la transacción deben completarse o no se debe hacer nada. Pero a veces algo sucede a mitad de la ejecución de una transacción, como por ejemplo:
- Situación 1: Se pueden encontrar varios errores durante la ejecución de la transacción, como errores en el propio servidor, errores del sistema operativo o incluso errores causados por cortes de energía repentinos.
- Escenario 2: el programador puede ingresar manualmente la instrucción ROLLBACK durante la ejecución de la transacción para finalizar la ejecución de la transacción actual.
Ambas situaciones harán que la transacción finalice a mitad de la ejecución, pero es posible que se hayan modificado muchas cosas durante la ejecución de la transacción. Para garantizar la atomicidad de la transacción, es necesario cambiar las cosas a su apariencia original. El proceso se llama reversión, es decir, reversión, lo que puede hacer que parezca que esta transacción no ha hecho nada, por lo que cumple con los requisitos de atomicidad.
Siempre que desee realizar cambios en un registro, deberá anotar todo lo necesario para la reversión.
Por ejemplo:
- Al insertar un registro, debe escribir al menos el valor de la clave principal de este registro. Cuando retroceda más tarde, solo necesita eliminar el registro correspondiente a este valor de clave principal.
- Después de eliminar un registro, al menos escriba el contenido de este registro para que los registros compuestos por este contenido se puedan insertar en la tabla durante la reversión.
- Cuando se modifica un registro, se debe registrar al menos el valor anterior antes de modificar el registro, de modo que el registro pueda actualizarse al valor anterior cuando se revierta más tarde.
Estas cosas registradas para la reversión se denominan registros de deshacer, es decir: registros de deshacer. Una cosa a tener en cuenta aquí es que, dado que la operación de consulta no modifica ningún registro de usuario, no es necesario registrar el registro de deshacer correspondiente cuando se ejecuta la operación de consulta.
deshacer formato de registro
Para lograr la atomicidad de las transacciones, el motor de almacenamiento InnoDB primero debe registrar el registro de deshacer correspondiente cuando realmente agrega, elimina o modifica un registro. Generalmente, cada cambio realizado en un registro corresponde a un registro de deshacer, pero en algunas operaciones de actualización de registros, también puede corresponder a dos registros de deshacer.
Durante la ejecución de una transacción, se pueden agregar, eliminar o actualizar varios registros, lo que significa que es necesario registrar muchos registros de deshacer correspondientes. Estos registros de deshacer se numerarán a partir de 0, lo que significa que se llamarán respectivamente según el orden en que se generan: Deshacer registro No. 0, deshacer registro No. 1,..., deshacer registro No. n, etc.
Estos registros de deshacer se registran en páginas de tipo FIL_PAGE_UNDO_LOG. Estas páginas se pueden asignar desde el espacio de tabla del sistema o desde un espacio de tabla dedicado a almacenar registros de deshacer, que es el llamado espacio de tabla de deshacer.
Alibaba Cloud sufrió un fallo grave y todos los productos se vieron afectados (restaurados). Tumblr enfrió el sistema operativo ruso Aurora OS 5.0. Se presentó la nueva interfaz de usuario Delphi 12 y C++ Builder 12, RAD Studio 12. Muchas empresas de Internet contratan urgentemente programadores de Hongmeng. Tiempo UNIX está a punto de entrar en la era de los 1.700 millones (ya entró). Meituan recluta tropas y planea desarrollar la aplicación del sistema Hongmeng. Amazon desarrolla un sistema operativo basado en Linux para deshacerse de la dependencia de Android de .NET 8 en Linux. El tamaño independiente es reducido en un 50%. Se lanza FFmpeg 6.1 "Heaviside"Autor: JD Logística Zhang Shixin
Fuente: La comunidad de desarrolladores de JD Cloud justifica la tecnología Indique la fuente al reimprimir