
fondo
Recientemente, durante el período de Double Eleven, ocurrió un problema en línea en el grupo debido al punto muerto de Mysql. En ese momento, pudimos ver en el monitoreo que el número de conexiones de bases de datos activas se disparó, lo que provocó que el grupo de conexiones de bases de datos de la capa de aplicación se llenara. y todas las solicitudes posteriores se bloquearon debido a la imposibilidad de obtenerlas.
La lógica general de simplificación del código comercial es la siguiente:
@Transaction
public void service(Integer id) {
delete(id);
insert(id);
}
Monitoreo de instancias de bases de datos:
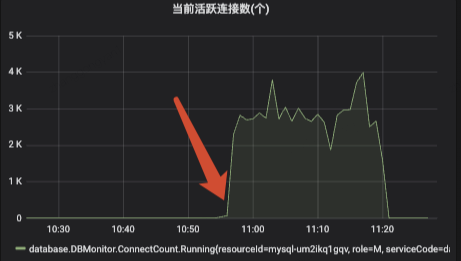
Después de analizar el problema ascendente y resolver el problema del límite de tráfico en ese momento, encontré tiempo para volver a analizar la causa raíz del problema. Ahora lo resumo de la siguiente manera: este artículo primero analizará los diversos bloqueos en MySQL, incluidos los bloqueos mutex. ., bloqueos de espacio y bloqueos de intención de inserción, permita que todos comprendan los escenarios de uso de varios bloqueos y luego analice este problema sobre esta base. Espero que todos puedan localizar rápidamente el problema cuando se encuentren con escenarios similares en el futuro.
Mecanismo de bloqueo de MySQL
Para resolver el problema de la escritura concurrente de la misma fila de registros en Mysql, se introduce un mecanismo de bloqueo de fila. Múltiples transacciones no pueden modificar una fila de datos al mismo tiempo. Cuando es necesario modificar una fila de datos en la base de datos , la fila de datos se juzgará primero. Ya sea para bloquear o no. Si no, entonces la transacción actual se bloquea exitosamente y se pueden realizar operaciones de modificación posteriores. Sin embargo, si los datos de la fila han sido bloqueados por otras transacciones, la transacción actual Solo se puede bloquear después de esperar a que la transacción bloqueada libere el bloqueo. Éxito, continúe con la operación de modificación.
Declaraciones de creación de tablas utilizadas en todos los experimentos de este artículo:
create table `test` (
`id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `num` (`num`)
) ENGINE = InnoDB;
insert into
test
values
(10, 10),
(20, 20),
(30, 30),
(40, 40),
(50, 50);
Cerraduras compartidas y exclusivas
El bloqueo compartido (S) representa un bloqueo compartido. Cuando una transacción mantiene el bloqueo S en una fila, puede leer los datos de la fila. Puede agregar un bloqueo compartido a través de la instrucción select... del bloqueo de prueba en modo compartido, ** Generalmente se usa menos, ** no da más detalles
El bloqueo exclusivo (X) representa un bloqueo de exclusión mutua. Cuando una transacción actualiza o elimina una fila de datos, primero debe adquirir el bloqueo X en el registro. Si otra transacción ha adquirido el bloqueo X en el registro, entonces la transacción actual bloquee y espere hasta que la transacción anterior libere el bloqueo X en el registro correspondiente.
Los bloqueos S no son mutuamente excluyentes. Varias transacciones pueden adquirir el bloqueo S en un registro al mismo tiempo. Los bloqueos X son mutuamente excluyentes. Varias transacciones no pueden adquirir el bloqueo X en el mismo registro al mismo tiempo. Los bloqueos S y los bloqueos X son mutuamente excluyentes. mutuamente excluyentes. Varias transacciones no pueden adquirir bloqueos S y bloqueos X en el mismo registro al mismo tiempo.
Cuando varias transacciones actualizan el mismo registro en el índice al mismo tiempo, todas deben obtener primero el bloqueo X en el registro. El llamado bloqueo significa que se genera una estructura de datos en la memoria para registrar la información de la transacción actual. tipo de bloqueo y si está esperando información . En la siguiente figura, T1 y T2 actualizan el registro de fila con id = 30 al mismo tiempo, y T1 obtiene con éxito el bloqueo. El campo is_wating en la información de la estructura del bloqueo generada en la memoria es falso y la lógica posterior de la transacción puede continuar ejecutándose, mientras que T2 falla la adquisición del bloqueo, el campo de información de estructura de bloqueo generado is_wating es verdadero y los bloques esperan que se libere el bloqueo en T1.
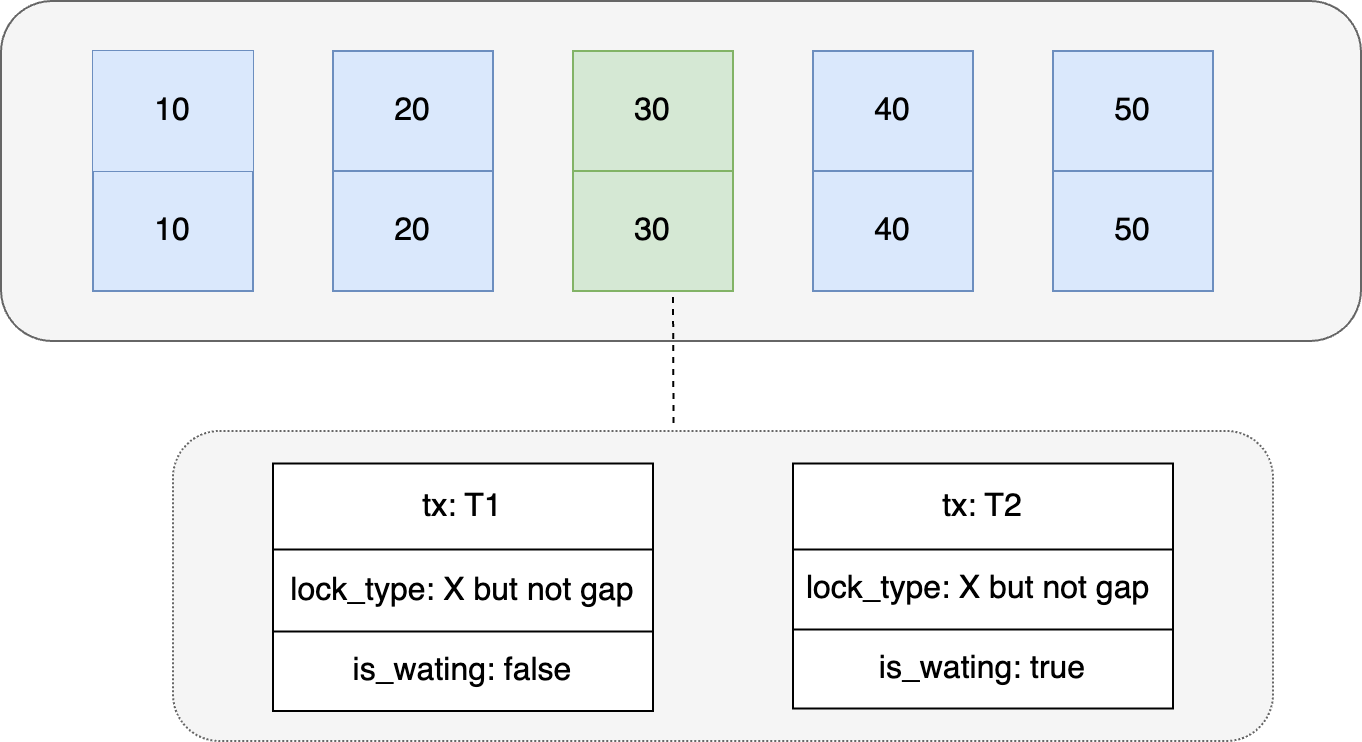
La información de bloqueo del bloqueo mutex en el registro de Mysql es: lock_mode X bloquea rec pero no gap
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t`
trx id 10078 lock_mode X locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 00000000274f; asc 'O;;
2: len 7; hex b60000019d0110; asc ;;
Cerraduras de espacio
Los bloqueos exclusivos se introdujeron en la sección anterior. Este bloqueo puede evitar que varias transacciones actualicen una fila de registros al mismo tiempo, pero no puede resolver el problema de la lectura fantasma . La llamada lectura fantasma significa que cuando una transacción consulta la misma rango dos veces antes y después. La última consulta encontró registros que no estaban disponibles en la consulta anterior.
| | sesión A | sesión B |
|---|---|---|
| T1 | seleccione num de la prueba donde num > 10 y num < 15 para actualizar; (0 filas) | |
| T2 | | insertar en los valores de prueba (12, 12); |
| T3 | seleccione num de la prueba donde num > 10 y num < 15 para actualizar; (1 filas) | |
En el escenario anterior, la sesión A realizó dos consultas de rango en T1 y T3, y la sesión B insertó un dato dentro del rango en T2. Si la sesión A pudo consultar los datos insertados por la sesión B en T3, esto significa que la lectura fantasma tiene ocurrió. En este momento, usar solo un bloqueo mutex no puede resolver la lectura fantasma, porque el registro con num = 12 aún no existe en la base de datos y no se le puede agregar un bloqueo mutex para evitar la inserción de la sesión B en el momento T2.
Por lo tanto, para resolver el problema de la lectura fantasma, solo se puede introducir un nuevo mecanismo de bloqueo, a saber, Gap Locks . Los bloqueos de espacio son diferentes de los bloqueos mutex: los bloqueos mutex son bloqueos de fila que solo bloquean una fila específica de registros, mientras que los bloqueos de espacio bloquean el espacio entre dos filas de registros para evitar que otras transacciones inserten nuevos registros en este espacio.
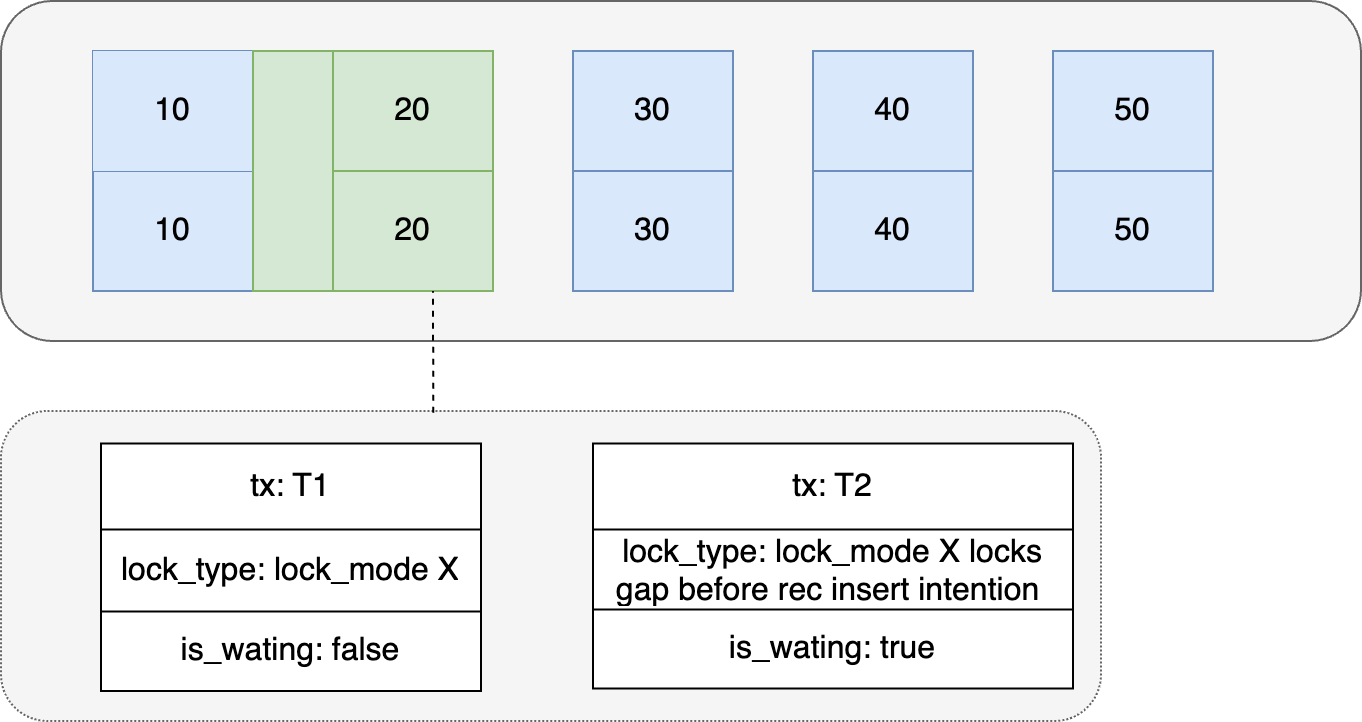
Después de introducir el bloqueo de espacios, la sesión A generará bloqueos de espacios para el registro con id = 20 en el momento T1. Luego, cuando la sesión B quiera insertar un registro en el momento T2, primero debe determinar si hay bloqueos de espacios en el siguiente registro que se insertará. Obviamente, los Gap Locks ya existen en el registro con id = 20 en este momento, por lo que la sesión B necesita generar un bloqueo de intención de inserción en el registro con id = 20 e ingresar la espera de bloqueo.

La información del registro de bloqueo del bloqueo de espacio en Mysql es la siguiente: lock_mode X bloquea el espacio antes de rec
RECORD LOCKS space id 133 page no 3 n bits 80 index PRIMARY of table `test`.`test` trx id 38849 lock_mode X locks gap before rec
Record lock, heap no 4 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 8000001e; asc 30 ;;
1: len 6; hex 00000000969c; asc ;;
2: len 7; hex a60000011a0128; asc (;;
3: len 4; hex 8000001e; asc ;;
Aunque los bloqueos de espacio resuelven el problema de lectura fantasma, bloquean un espacio cada vez, lo que reduce en gran medida la concurrencia general de la base de datos . Y debido a que los bloqueos de espacio y los bloqueos de espacio no son mutuamente excluyentes, diferentes transacciones pueden agregar bloqueos al mismo espacio al mismo tiempo. Bloqueos de brechas, que a menudo son la fuente de varios puntos muertos
Cerraduras de siguiente llave
Los bloqueos de siguiente clave son una combinación de (fragmento/bloqueos exclusivos + bloqueos de espacio). Cuando la sesión A agrega bloqueos de siguiente clave mutuamente excluyentes a una determinada fila del registro R, equivale a poseer el bloqueo X del registro R y el espacio. Cerraduras
En el ejemplo anterior de Gap Locks, la transacción 1 agrega Next-Key Locks, es decir, los bloqueos X y Gap se agregan al registro con id = 20 al mismo tiempo.
Bajo el nivel de aislamiento de lectura repetible, las operaciones de actualización y eliminación agregarán Next-Key Locks al registro de forma predeterminada . La información del registro de bloqueo de Next-Key Locks en Mysql es: lock_mode X
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t`
trx id 10080 lock_mode X
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 00000000274f; asc 'O;;
2: len 7; hex b60000019d0110; asc ;
Insertar cerraduras de intención
Los bloqueos de intención de inserción también son una especie de bloqueo de espacio, adquiridos mediante la operación INSERT antes de que se inserten los datos de la fila.
Antes de insertar un registro, primero debe ubicar la ubicación de almacenamiento del registro en el árbol B + y luego determinar si se agregarán bloqueos de espacio al siguiente registro en la ubicación que se insertará. Si hay bloqueos de espacio en el siguiente registro, luego la operación de inserción requiere Bloquear y esperar hasta que se confirme la transacción que posee Gap Locks. Al mismo tiempo, la transacción que espera la operación de inserción también generará una estructura de bloqueo en la memoria, lo que indica que una transacción desea insertar un nuevo registro en un cierta brecha, pero actualmente está en un estado bloqueado. La estructura de bloqueo generada es para insertar el bloqueo de intención
La simulación experimental es la siguiente:
| | Sesión 1 | sesión 2 | sesión 3 |
|---|---|---|---|
| T1 | comenzar; | | |
| T2 | seleccione * de la prueba donde id = 25 para actualizar; | | |
| T3 | | insertar en los valores de prueba (26, 26); (obstruido) | |
| T4 | | | insertar en los valores de prueba (26, 26); (obstruido) |
Para la declaración, seleccione * de la prueba donde id = 25 para actualizar, debido a que el registro no existe en la tabla actual, bajo el nivel de aislamiento de lectura repetible, para evitar lecturas fantasmas, se agregarán Gap Locks a (20, 30 ] brecha.
En el registro de bloqueo, podemos ver que la sesión 1 agregó un bloqueo de espacio al registro 30 ( lock_mode X bloquea el espacio antes de rec ).
RECORD LOCKS space id 133 page no 3 n bits 80 index PRIMARY of table `test`.`test` trx id 38849 lock_mode X locks gap before rec
Record lock, heap no 4 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 8000001e; asc 30 ;;
1: len 6; hex 00000000969c; asc ;;
2: len 7; hex a60000011a0128; asc (;;
3: len 4; hex 8000001e; asc ;;
Cuando la sesión 2 inserta el registro 26, primero ubicará la ubicación que se insertará en el árbol B + y luego determinará si hay bloqueos de espacio en el espacio en la ubicación de inserción, es decir, determinará si hay bloqueos de espacio en el siguiente registro. id = 30 en la ubicación a insertar. Si es necesario generar un bloqueo de intención de inserción, espere en este registro.
RECORD LOCKS space id 133 page no 3 n bits 80 index PRIMARY of table `test`.`test` trx id 38850 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 4; compact format; info bits 0
0: len 4; hex 8000001e; asc 30 ;;
1: len 6; hex 00000000969c; asc ;;
2: len 7; hex a60000011a0128; asc (;;
3: len 4; hex 8000001e; asc ;;
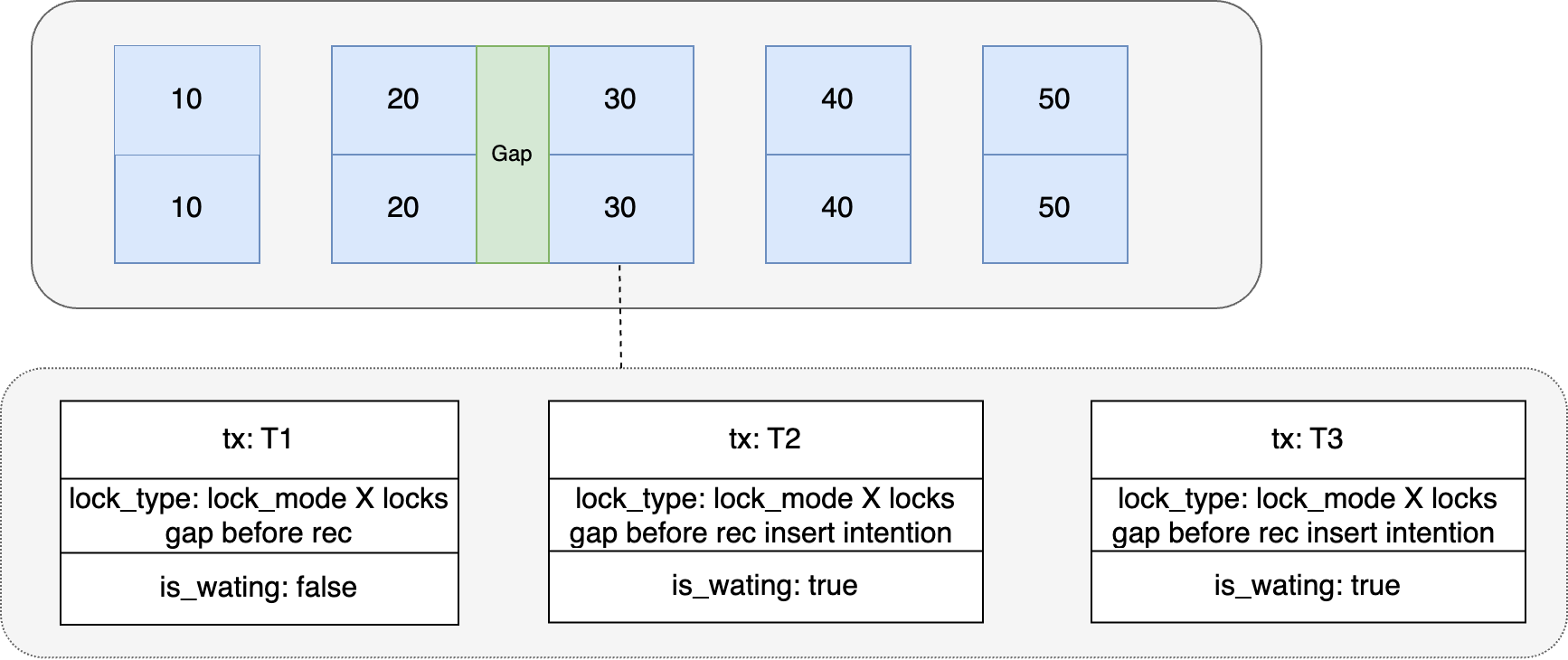
En este momento, tanto la sesión 2 como la sesión 3 agregaron bloqueos de intención de inserción al registro con id = 30 y esperaron a que se liberaran los bloqueos de brecha en la sesión 1. Los registros de bloqueo generados son los siguientes:
Análisis de problemas en línea
Después de tener una comprensión clara de las diversas estructuras de bloqueo en Mysql, volvamos y veamos las preguntas en línea anteriores.
@Transaction
public void service(Integer id) {
delete(id);
insert(id);
}
Pueden existir las dos situaciones siguientes para el código comercial anterior:
- El ID del parámetro pasado no existe en la base de datos original.
- El ID del parámetro pasado existe en la base de datos original.
Esta vez analizaremos principalmente si el registro de identificación no existe en la base de datos original.
| | Sesión 1 | sesión 2 | sesión 3 |
|---|---|---|---|
| T1 | eliminar de la prueba donde id = 15; | | |
| T2 | | eliminar de la prueba donde id = 15; | eliminar de la prueba donde id = 15; |
| T3 | insertar en los valores de prueba (15, 15); | | |
| T4 | | insertar en los valores de prueba (15, 15); | |
| T5 | | | insertar en los valores de prueba (15, 15); |
Debido a que id = 15 no existe en la base de datos, la sesión 1 agregará Gap Locks al siguiente registro en el espacio en el momento T1, y debido a que Gap Locks no son mutuamente excluyentes, la sesión 2 y la sesión 3 obtendrán la identificación al mismo tiempo. en el momento T2. = 20 Bloqueo de espacio
En la siguiente figura, tx: T1, T2 y T3 representan la sesión 1, la sesión 2 y la sesión 3 respectivamente.
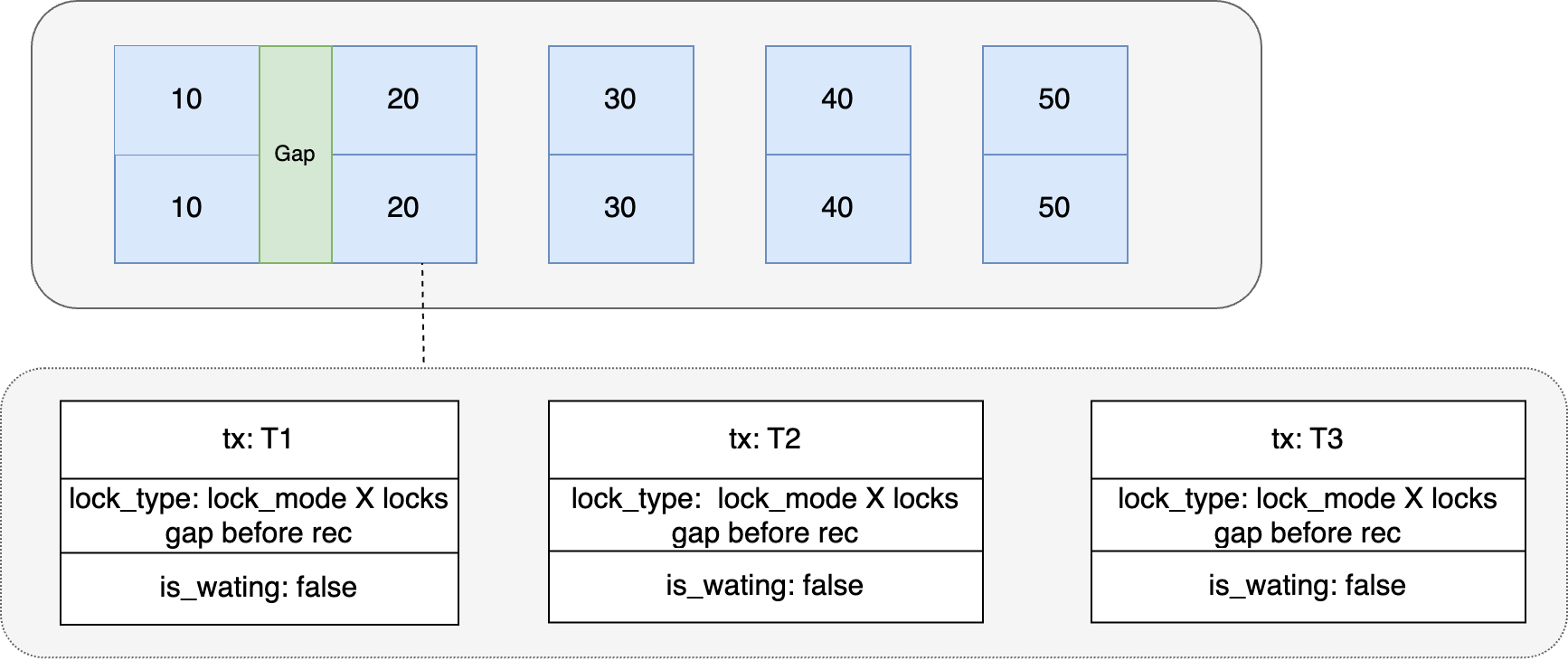
Cuando el registro con id = 15 se inserta en la sesión 1 en el momento T3, se juzgará si el registro después de la posición de inserción tiene bloqueos de espacio. Si existe, se deben generar bloqueos de intención de inserción en el registro y esperar la transacción. sosteniendo los bloqueos de espacio para liberarlos.
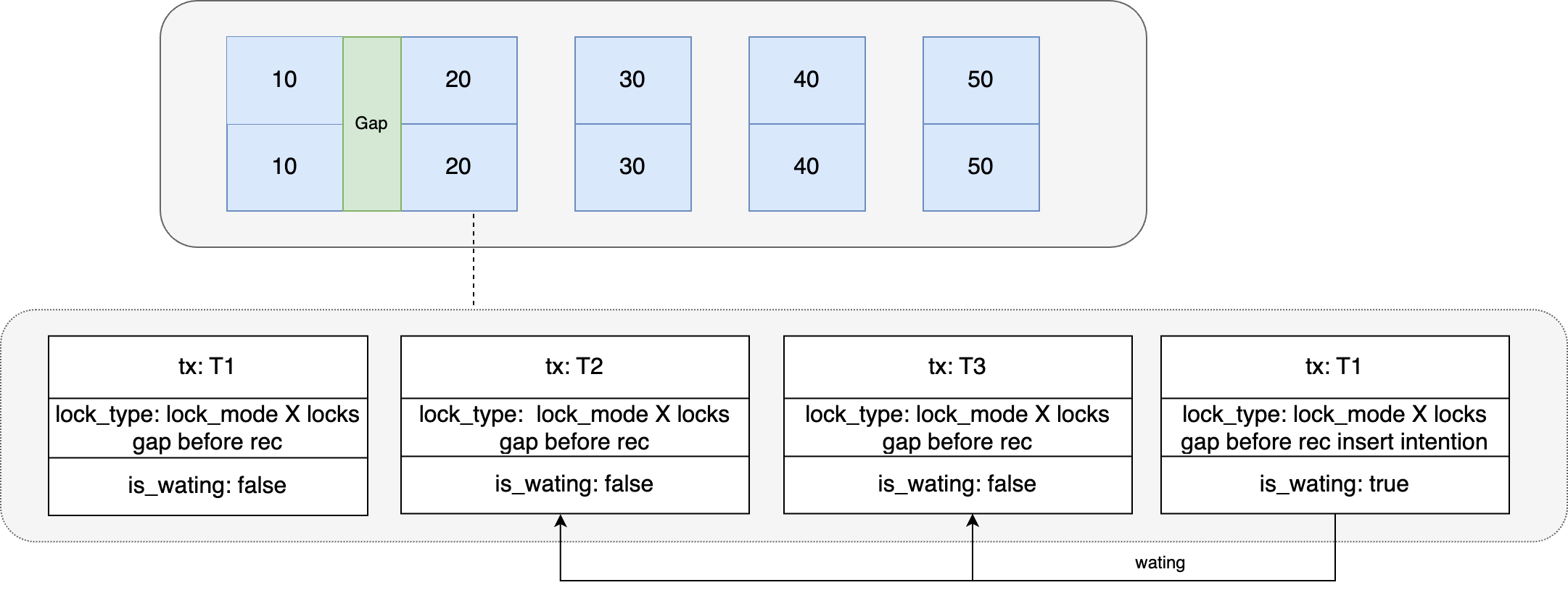
Cuando la instrucción de inserción se ejecuta en la sesión 2 en el momento T4, también será necesario generar la espera de bloqueos de intención de inserción porque hay bloqueos de espacio en el registro después de la posición de inserción. En este punto, es obvio que se ha formado un punto muerto. La sesión 1 genera un bloqueo de intención de inserción y espera a que se liberen los bloqueos de espacio en las sesiones 2 y 3, mientras que la sesión 2 también genera un bloqueo de intención de inserción y espera el espacio. se liberarán los bloqueos de las sesiones 1 y 3.
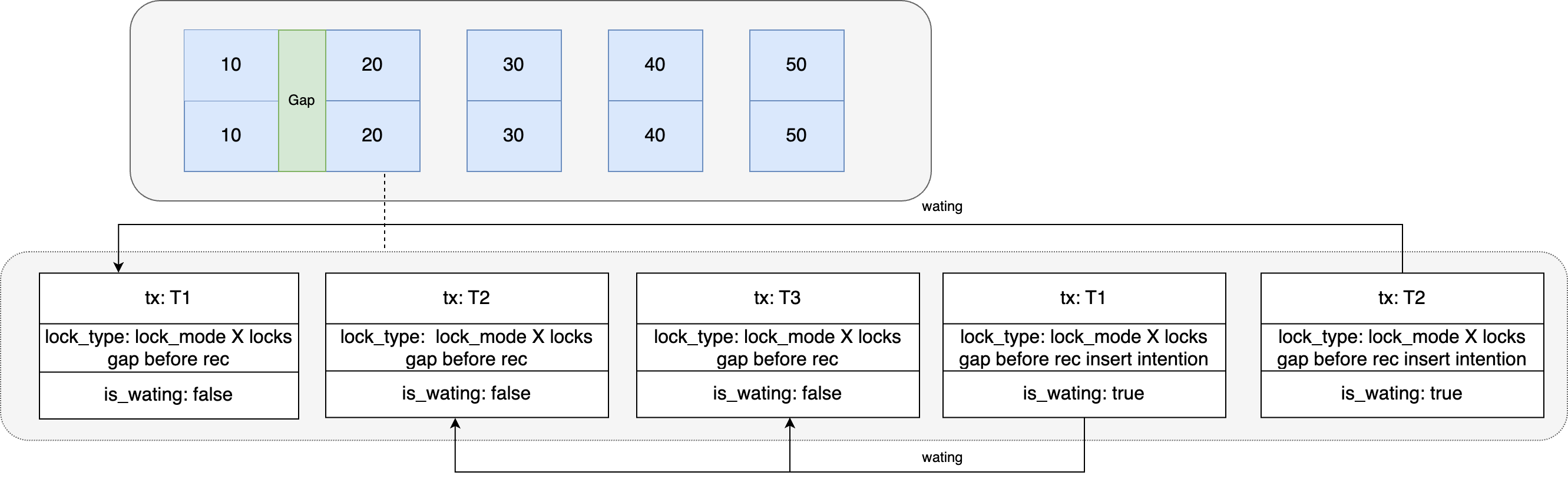
Después de que se detecta un punto muerto en T4, MySQL seleccionará una de las transacciones para revertir. Supongamos que la sesión 2 se revierte en este momento y todos los recursos de bloqueo que contiene se liberan. ¿Puede continuar ejecutándose la sesión 1? Obviamente no, la sesión 1 todavía está esperando que se libere el bloqueo de brecha en la sesión 3 y continúa bloqueando y esperando.
En el momento T5, la sesión 3 comienza a ejecutar la instrucción de inserción. En este momento, al mismo tiempo que T4, se forma un punto muerto. El bloqueo de intención de inserción generado por la sesión 1 está esperando que se liberen los Gap Locks en la sesión 3, y el bloqueo de intención de inserción generado en la sesión 3 está esperando la sesión 1. Se liberan los bloqueos de brecha. En este momento, la sesión 3 retrocede y libera todos los recursos de bloqueo, y la sesión 1 finalmente puede ejecutarse con éxito.
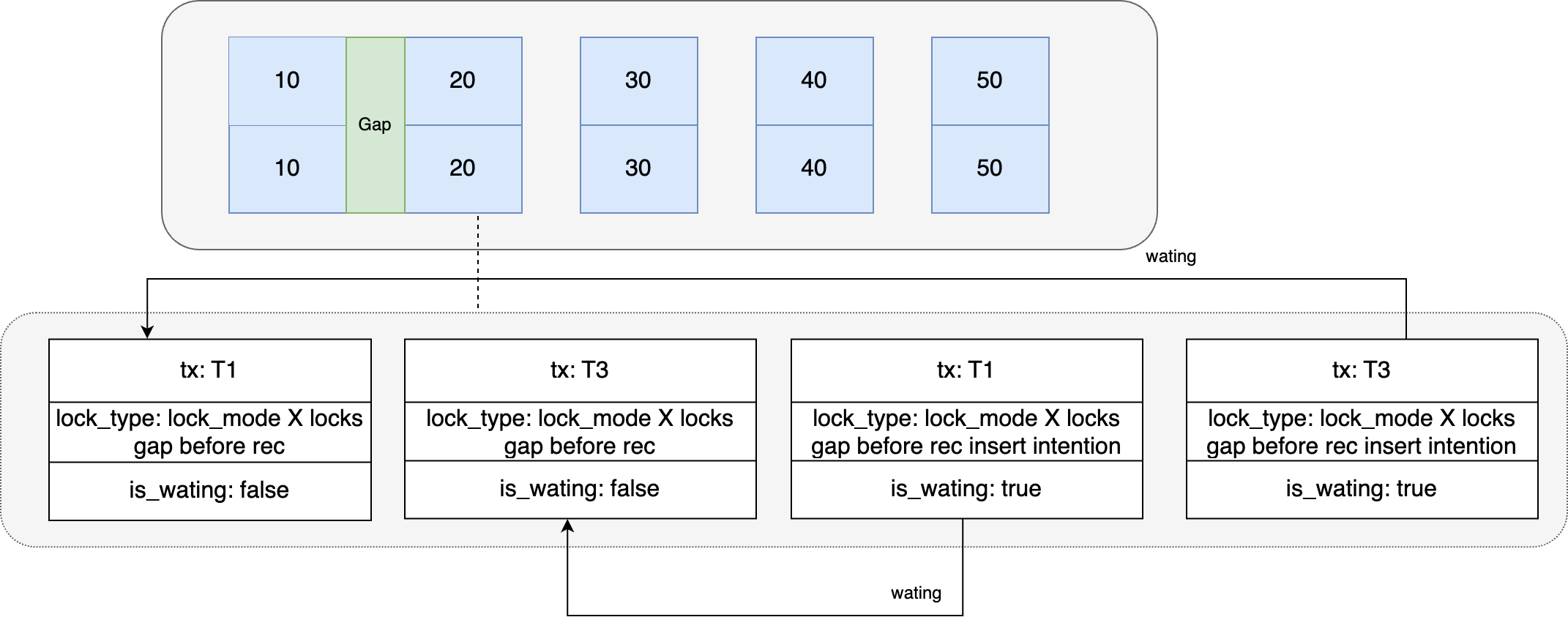
Después de completar el análisis de interbloqueo de tres subprocesos concurrentes, algunas personas pueden pensar que, aunque hay un interbloqueo, se puede detectar rápidamente mediante la detección de interbloqueo y el programa se puede ejecutar normalmente ¿Cuál es el problema con esto? De hecho, no hay problemas anteriores principalmente porque la cantidad de concurrencia es pequeña y la detección de interbloqueo se puede detectar rápidamente. Si la cantidad de concurrencia se expande 100 veces o incluso 1000 veces, ¿todavía no habrá problemas?
Observe la cantidad de llamadas a la interfaz cuando ocurrieron problemas en línea.
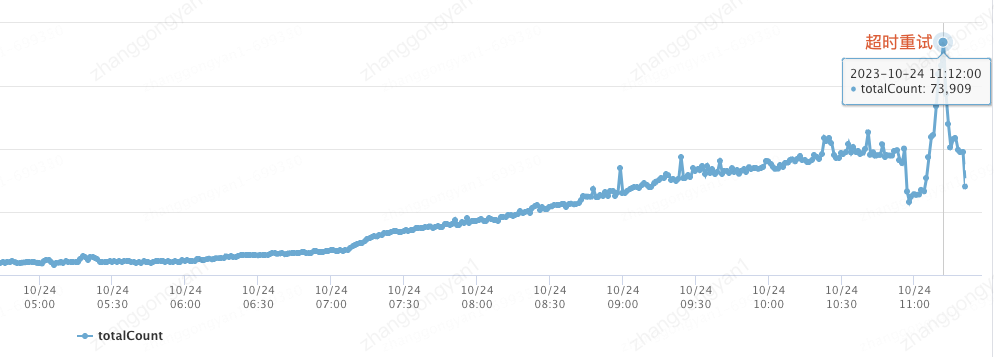
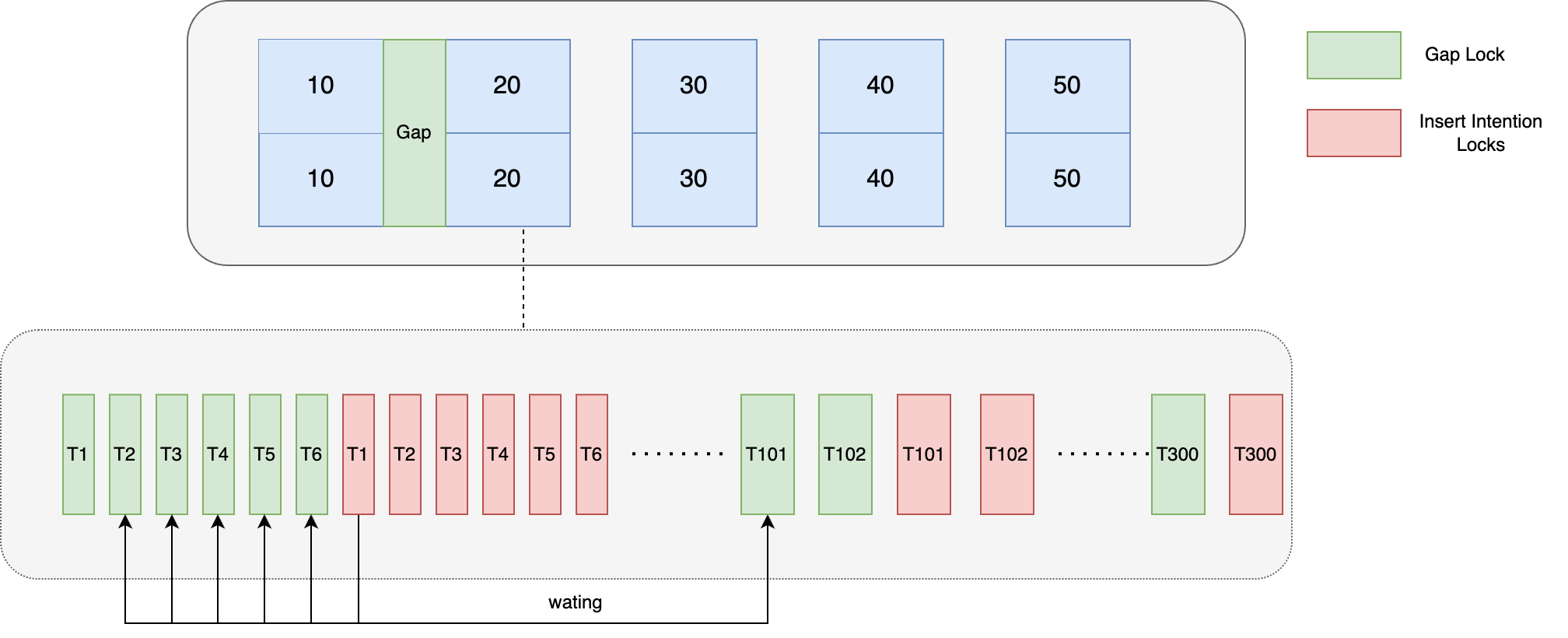
Simule aún más la ejecución concurrente de 300 subprocesos localmente. Debido a que sería muy complicado para el cerebro humano analizar la ejecución de todas las transacciones al mismo tiempo, esta vez solo usamos la transacción 1 como punto de análisis.
Como se puede ver en la figura, cuando T1 ejecuta la instrucción de inserción, debe esperar a que se liberen los Gap Locks retenidos en T2-T101. Después de eso, T2-T6 puede ejecutar la instrucción de inserción al mismo tiempo, y luego realice la detección de interbloqueo y la reversión de la transacción. Parece que siempre que una transacción posterior ejecute la instrucción de inserción, se realizará una reversión del interbloqueo y la operación será normal. Sin embargo, durante el proceso de detección de interbloqueo, nuevas transacciones (T101 - T 200) adquiere Gap Locks, lo que hace que el bloqueo espere transacciones en la cola. Cada vez más, **y la complejidad general del tiempo de detección de interbloqueos de Mysql es O(n^2),** cuando hay muchas transacciones en la cola de espera de bloqueos. , cada vez que hay una nueva transacción esperando el bloqueo, la detección de interbloqueo requiere atravesar las transacciones que esperan antes de ella en la cola de espera del bloqueo para determinar si se formará un bucle debido a su propia adición. En este momento, la detección consumirá un una gran cantidad de recursos de CPU, lo que hace que el rendimiento general de la base de datos disminuya, el tiempo de detección de interbloqueo aumente y la cantidad de conexiones activas de MySQL aumente significativamente. , y la conexión no se puede liberar debido a la espera de bloqueo, lo que finalmente provoca que la capa de aplicación piscina de conexiones por llenar.
Según el análisis anterior, la razón principal de este problema es que hay grandes solicitudes simultáneas para eliminar primero y luego insertar la misma fila de datos en un corto período de tiempo (lo mismo ocurre con la actualización primero y luego la inserción), lo que resulta en En el punto muerto de espera y la conexión de la capa de aplicación. El grupo estaba lleno y una gran cantidad de solicitudes ascendentes excedieron el tiempo de espera y se volvieron a intentar, lo que provocó aún más esperas de bloqueo y, en última instancia, afectó a todas las empresas que dependían de la base de datos.
Por lo tanto, cuando exista una lógica similar en el código comercial en el futuro, se debe evitar la duplicación para evitar operaciones simultáneas de actualización y luego inserción de la misma fila de datos en un corto período de tiempo. Al mismo tiempo, en la categoría de aislamiento de lectura repetible, se agregan bloqueos de siguiente tecla de forma predeterminada para las operaciones de actualización y eliminación. La introducción de bloqueos de espacio hace que se produzcan fácilmente problemas de interbloqueo en situaciones de concurrencia. Este también es un problema que debe tenerse en cuenta. en la implementación de la lógica de negocios.
Resumir
Este artículo utiliza un problema en línea como fondo para hacer un resumen detallado de los diversos mecanismos de bloqueo en Mysql y analiza el tiempo de bloqueo y los escenarios de uso específicos de cada bloqueo. Se debe prestar especial atención al uso de bloqueos de espacio, porque los bloqueos de espacio y brechas Los bloqueos no son mutuamente excluyentes y se pueden formar fácilmente interbloqueos cuando se ejecutan múltiples transacciones al mismo tiempo.
Alibaba Cloud sufrió un fallo grave y todos los productos se vieron afectados (restaurados). Tumblr enfrió el sistema operativo ruso Aurora OS 5.0. Se presentó la nueva interfaz de usuario Delphi 12 y C++ Builder 12, RAD Studio 12. Muchas empresas de Internet contratan urgentemente programadores de Hongmeng. Tiempo UNIX está a punto de entrar en la era de los 1.700 millones (ya entró). Meituan recluta tropas y planea desarrollar la aplicación del sistema Hongmeng. Amazon desarrolla un sistema operativo basado en Linux para deshacerse de la dependencia de Android de .NET 8 en Linux. El tamaño independiente es reducido en un 50%. Se lanza FFmpeg 6.1 "Heaviside"Autor: JD Logística Zhang Gongyan
Fuente: Comunidad de desarrolladores de JD Cloud Ziyuanqishuo Tech Indique la fuente al reimprimir