
요약
AI 서비스의 데이터, 훈련, 추론 등에는 많은 양의 컴퓨팅 리소스와 운영 및 유지 관리 비용이 필요합니다.Shuhe Technology의 금융 비즈니스 시나리오에서는 모델 스토리지가 자주 반복되고 모델의 여러 버전이 평가를 위해 온라인으로 동시에 배포됩니다. 온라인 모델의 실제 효과는 리소스 비용이 높습니다. 서비스 품질을 보장하면서 AI 서비스 운영 및 유지 관리 효율성을 향상하고 리소스 비용을 줄이는 방법은 어렵습니다.
Knative는 Kubernetes 기반의 오픈 소스 서버리스 애플리케이션 아키텍처로, 요청에 따라 자동 탄력성을 제공하고 0으로 확장하며 그레이스케일 릴리스를 제공합니다. Knative를 통해 서버리스 애플리케이션을 배포하면 애플리케이션 로직 개발에 집중하고 요청 시 리소스를 사용할 수 있습니다. 따라서 AI 서비스와 Knative 기술을 결합하면 효율성을 높이고 비용을 절감할 수 있습니다.
Shuhe Technology는 현재 Knative를 통해 500개 이상의 AI 모델 서비스를 배포하여 리소스 비용을 60% 절감하고 있으며, 평균 배포 주기가 이전 1일에서 0.5일로 단축되었습니다.
이번 공유에서는 Knative를 기반으로 AI 워크로드를 배포하는 방법을 보여드리겠습니다. 구체적인 내용은 다음과 같습니다.
- K네이티브 소개
- Shuhe는 Knative의 모범 사례를 기반으로 합니다.
- Knative에서 Stable Diffusion을 배포하는 방법
K네이티브 소개

우리 모두가 알고 있듯이 쿠버네티스는 2014년 오픈소스화 이후 많은 제조사와 개발자들의 주목을 받아왔습니다. 오픈소스 컨테이너 오케스트레이션 시스템으로서 사용자는 K8s를 이용하여 운영 및 유지관리 비용을 절감하고 운영 및 유지관리 효율성을 향상시킬 수 있으며, 표준화된 API를 제공한다는 의미는 클라우드 공급업체에 얽매이지 않고 K8을 핵심으로 하는 클라우드 네이티브 생태계를 형성한다는 의미입니다. CNCF 2021 설문조사에 따르면 기업의 96%가 Kubernetes를 사용하거나 평가하고 있습니다.
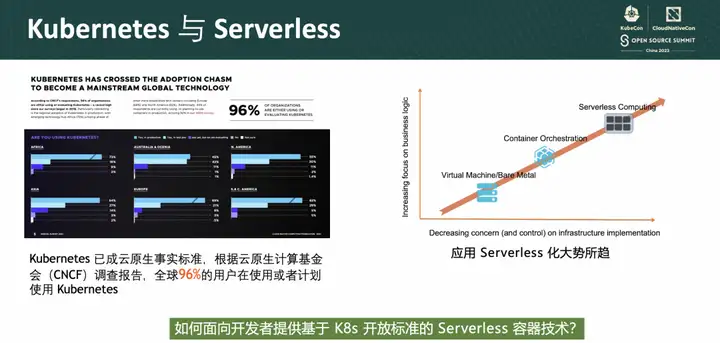
클라우드 네이티브 기술이 발전하면서 애플리케이션 중심으로 온디맨드 방식으로 리소스를 사용하는 서버리스 기술이 점차 주류로 자리 잡았습니다. Gartner는 2025년까지 글로벌 기업의 50% 이상이 서버리스를 배포할 것으로 예측합니다.
우리는 AWS Lambda로 대표되는 FaaS가 서버리스를 대중화했다는 것을 알고 있습니다. FaaS는 프로그래밍을 단순화하여 직접 실행하기 위해 코드 조각만 작성하면 되며 개발자는 기본 인프라에 신경 쓸 필요가 없습니다. 그러나 현재 FaaS에는 침해성이 높은 개발 모델, 기능 런타임 제한, 클라우드 간 플랫폼 지원 등 명백한 단점이 있습니다.
K8s로 대표되는 컨테이너 기술은 이러한 문제를 매우 잘 해결했습니다. 서버리스의 핵심 개념은 비즈니스 로직에 집중하고 인프라 문제를 줄이는 것입니다.
그렇다면 K8s 개방형 표준을 기반으로 하는 서버리스 컨테이너 기술을 개발자에게 어떻게 제공할 수 있을까요? 대답은 Knative입니다.
Knative 개발 궤적
Knative는 2018 Google Cloud Next 컨퍼런스에서 출시된 Kubernetes 기반의 오픈 소스 서버리스 컨테이너 조정 프레임워크입니다. 목표는 클라우드 네이티브, 크로스 플랫폼 서버리스 애플리케이션 조정 표준을 공식화하고 엔터프라이즈 수준의 서버리스 플랫폼을 만드는 것입니다. Alibaba Cloud Container Service는 이미 2019년 초에 Knative 제품화 기능을 제공했습니다. 2022년 3월 CNCF에 Knative가 추가되면서 이제 점점 더 많은 개발자가 Knative를 채택하고 있습니다.
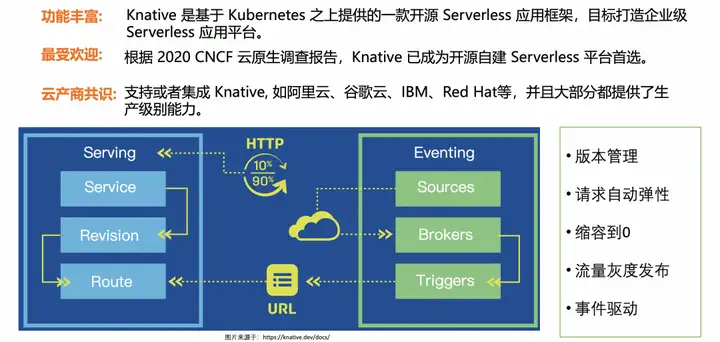
Knative 개요
Knative의 핵심 모듈에는 주로 워크로드 배포를 위한 Serving과 이벤트 중심 프레임워크인 Eventing이 포함됩니다.
Knative Serving의 핵심 기능은 간단하고 효율적인 애플리케이션 호스팅 서비스이며, 이는 서버리스 기능의 기반이기도 합니다. Knative는 애플리케이션의 요청 볼륨에 따라 피크 기간 동안 인스턴스 수를 자동으로 확장하고, 요청 볼륨이 감소할 때 인스턴스 수를 자동으로 줄여 비용을 자동으로 절감하는 데 도움이 됩니다.
Knative의 Eventing은 완전한 이벤트 모델을 제공합니다. 이벤트에 액세스한 후에는 CloudEvent 표준을 통해 내부적으로 흐르며 브로커/트리거 메커니즘과 결합되어 이벤트 처리를 위한 이상적인 방법을 제공합니다.
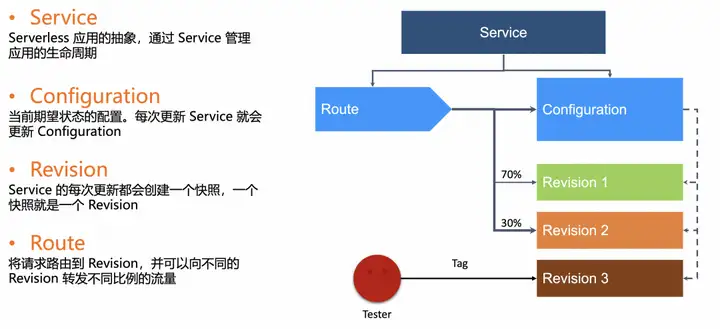
Knative 애플리케이션 모델
Knative 애플리케이션 모델은 Knative Service입니다.
- Knative Service에는 구성의 두 부분이 포함되어 있습니다. 한 부분은 구성이라는 워크로드를 구성하는 데 사용됩니다. 구성 콘텐츠가 업데이트될 때마다 새 개정판이 생성됩니다.
- Route의 다른 부분은 주로 Knative의 트래픽 관리를 담당합니다.
트래픽 기반 그레이스케일 게시로 무엇을 할 수 있는지 살펴보겠습니다.
처음에 Revison의 V1 버전을 생성했다고 가정하고, 이번에 새로운 버전 변경이 있는 경우 서비스에서 구성만 업데이트하면 V2 버전이 생성되며, 그러면 다른 트래픽 흐름을 설정할 수 있습니다. Route.Ratio를 통한 V1 및 V2의 경우, 여기서 v1은 70%이고 v2는 30%인 경우 트래픽은 7:3 비율로 이 두 버전에 분산됩니다. 새 V2 버전이 확인되고 문제가 없으면 새 버전 V2가 100%가 될 때까지 비율을 조정하여 계속해서 회색조를 사용할 수 있습니다. 이러한 Grayscale 업데이트 과정에서 새 버전에서 이상이 발견되면 비율을 조정하여 롤백 작업을 수행할 수 있습니다.
또한 Route to Traffic에서 Revison을 태그할 수 있으며, Revison을 태그한 후 Url을 통해 직접 별도의 버전 테스트를 수행할 수 있는데 이는 카나리아 검증으로 이해될 수 있습니다. 이 버전은 일반적인 디버깅 트래픽 액세스에는 영향을 미치지 않습니다.
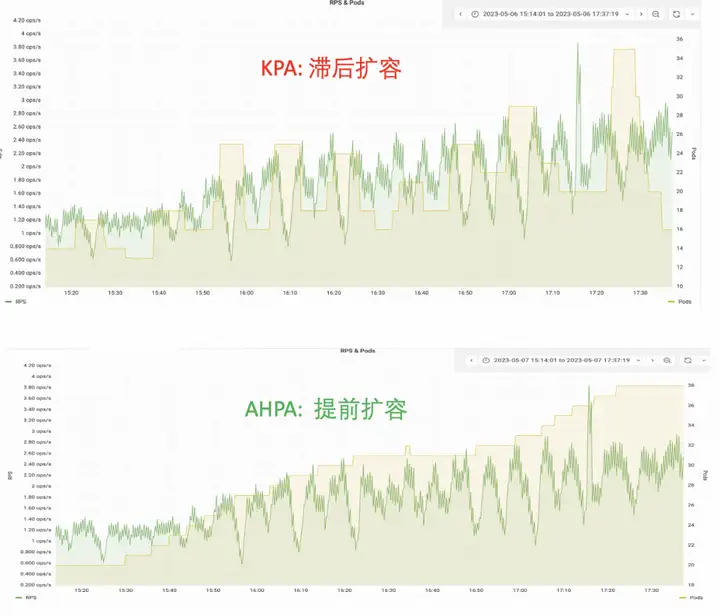
요청 기반 자동 복원력: KPA
요청에 따른 자동 탄력성이 필요한 이유는 무엇입니까?
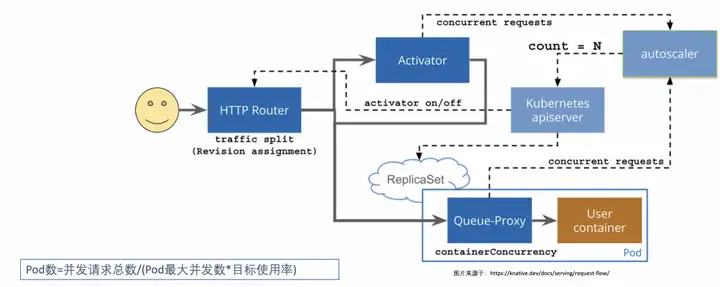
CPU나 메모리 기반의 탄력성은 비즈니스의 실제 사용량을 완전히 반영하지 못하는 경우도 있지만, 웹 서비스의 경우 동시성 수나 초당 처리되는 요청 수(QPS/RPS)를 기준으로 보다 직접적으로 반영할 수 있습니다. 서비스 성능 Knative는 요청 기반 자동 복원 기능을 제공합니다.
지표를 수집하는 방법은 무엇입니까?
현재 서비스 요청 수를 얻기 위해 Knative Serving은 사용자 컨테이너 동시성(동시성) 또는 요청 수(rps) 표시기 수집을 담당하는 각 Pod에 QUEUE 프록시 컨테이너(queue-proxy)를 삽입합니다. Autoscaler는 이러한 지표를 정기적으로 얻은 후 해당 알고리즘에 따라 배포의 Pod 수를 조정하여 요청에 따라 자동 확장 및 축소를 달성합니다.
탄력적 Pod 수를 계산하는 방법은 무엇입니까?
자동 확장 처리는 각 포드의 평균 요청 수(또는 동시성)를 기반으로 필요한 포드 수를 계산합니다. 기본적으로 Knative는 동시성 수를 기반으로 자동 탄력성을 사용하며 기본 최대 동시성 Pod 수는 100입니다. 또한 Knative는 Target Utilization이라고 불리는 target-utilization-percentage라는 개념도 제공합니다.
동시성을 기반으로 한 탄력성을 예로 들면 Pod 수는 다음과 같이 계산됩니다.
포드 수 = 총 동시 요청 수/(최대 동시 포드 수 * 목표 사용량)
0으로 축소하는 구현 메커니즘
KPA를 사용하는 경우 트래픽 요청이 없으면 Pod 수가 자동으로 0으로 줄어들고, 요청이 있으면 Pod 수가 0에서 확장됩니다. 그렇다면 Knative에서는 어떻게 이런 일이 발생할까요? 대답은 모드 전환을 통해서입니다.
Knative는 프록시와 서비스라는 두 가지 요청 액세스 모드를 정의합니다. 프록시 이름에서 알 수 있듯이 프록시 모드, 즉 요청은 활성기 구성 요소를 통해 프록시에 의해 전달됩니다. Serve 모드는 Activator Proxy를 통하지 않고 게이트웨이에서 Pod로 직접 요청하는 직접 요청 모드입니다. 아래 그림과 같이:
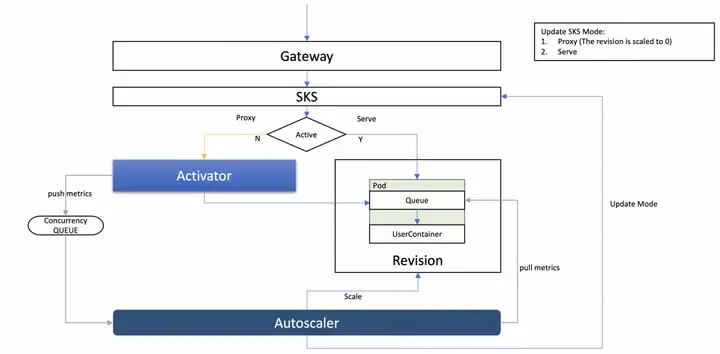
모드 전환은 Autoscaler 구성 요소에 의해 수행되며 요청이 0이면 Autoscaler는 요청 모드를 Proxy 모드로 전환합니다. 이때 요청은 게이트웨이를 통해 Activator 컴포넌트로 전송되며, 요청을 받은 Activator는 해당 요청을 대기열에 넣고 Autoscaler에 확장 알림을 표시하는 푸시 기능을 수행합니다. 확장을 위해 요청을 전달합니다.
버스트 트래픽에 대처
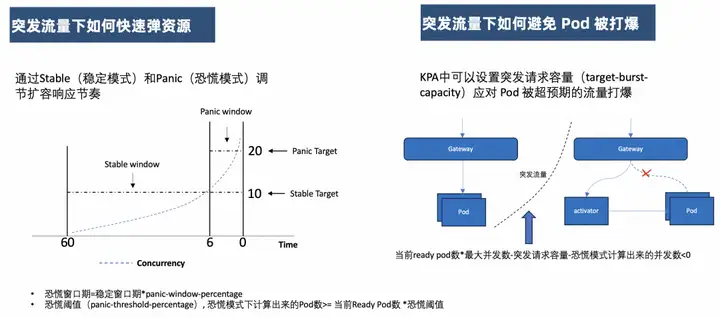
갑작스러운 트래픽 상황에서 리소스를 빠르게 반송하는 방법
여기서 KPA는 탄력성과 관련된 두 가지 개념인 Stable(안정 모드)과 Panic(패닉 모드)을 포함하며, 이 두 가지 모드를 기반으로 KPA가 어떻게 리소스를 신속하게 탄력화할 수 있는지 확인할 수 있습니다.
첫째, 안정 모드는 기본적으로 60초인 안정 창 기간을 기반으로 합니다. 즉, 평균 동시 Pod 수는 60초 이내에 계산됩니다.
패닉 모드는 안정성 창 기간과 패닉 창 백분율 매개변수를 통해 계산되는 패닉 창 기간을 기반으로 합니다. 패닉 창 기간 계산 방법은 패닉 창 기간 = 안정 창 기간 * 패닉 창 비율입니다. 기본값은 6초입니다. 6초 이내에 평균 동시 Pod 수를 계산합니다.
KPA는 안정 모드와 패닉 모드의 평균 동시 Pod 수를 기준으로 필요한 Pod 수를 계산합니다.
그렇다면 탄력성을 적용하기 위해 실제로 어떤 값이 사용됩니까? 이는 패닉 모드에서 계산된 포드 수가 패닉 임계값 PanicThreshold를 초과하는지 여부에 따라 판단됩니다. 기본적으로 패닉 모드에서 계산된 포드 수가 현재 준비된 포드 수의 2배 이상이면 패닉 모드의 포드 수가 탄력적 검증에 사용됩니다. 그렇지 않으면 안정 모드의 포드 수가 사용됩니다.
당연히 패닉 모드는 갑작스러운 교통 상황을 처리하도록 설계되었습니다. 탄성 감도는 위에서 언급한 구성 가능한 매개변수를 통해 조정할 수 있습니다.
갑작스러운 교통 상황에서 Pod가 폭발하는 것을 방지하는 방법
버스트 요청 용량(target-burst-capacity)은 예상치 못한 트래픽으로 인해 포드가 압도되는 것을 처리하기 위해 KPA에서 설정할 수 있습니다. 즉, 이 매개변수 값의 계산을 통해 요청이 프록시 모드로 전환되는지 여부를 조정할 수 있으므로 갑작스러운 트래픽이 발생할 때 Activator 구성 요소를 요청 버퍼로 사용하여 Pod가 폭발하는 것을 방지할 수 있습니다.
콜드 스타트를 줄이기 위한 몇 가지 팁
지연된 스케일링
시작 비용이 높은 포드의 경우 KPA를 사용하면 포드 지연 감소 시간과 포드 감소를 보존 기간 0으로 설정하여 포드 확장 및 축소 빈도를 줄일 수 있습니다.
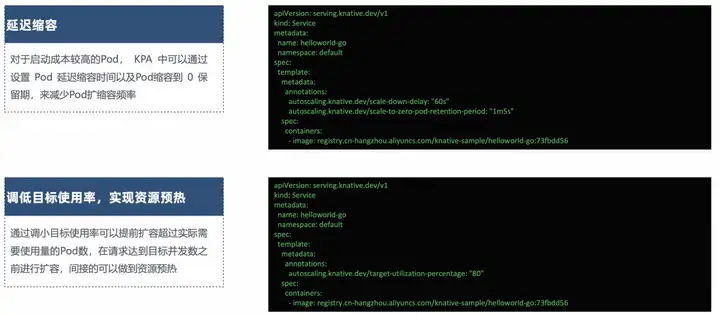
리소스를 준비하기 위해 목표 사용률을 낮춥니다.
대상 임계값 사용 구성은 Knative에서 제공됩니다. 이 값을 줄이면 실제 필요한 사용량을 초과하는 Pod 수를 미리 확장할 수 있고, 요청이 목표 동시 수에 도달하기 전에 용량을 확장할 수 있어 간접적으로 리소스를 워밍업할 수 있습니다.
유연한 정책 구성
위의 소개를 통해 Knative Pod Autoscaler의 작동 메커니즘을 더 잘 이해했으며 다음으로 KPA 구성 방법을 소개하겠습니다. Knative는 KPA를 구성하는 두 가지 방법인 전역 모드와 개정 모드를 제공합니다. 전역 모드는 ConfigMap: config-autoscaler를 통해 구성할 수 있으며 매개변수는 다음과 같습니다.
Alibaba Cloud 컨테이너 서비스 Knative
오픈 소스 제품은 일반적으로 제품에 직접 사용할 수 없습니다. Knative의 제품화에서 직면한 문제는 다음과 같습니다.
- 많은 관리 및 제어 구성 요소와 복잡한 운영 및 유지 관리가 있습니다.
- 컴퓨팅 성능의 다양성, 필요에 따라 다양한 리소스 사양에 맞게 예약하는 방법
- 클라우드 제품 수준 게이트웨이 기능
- 콜드 스타트 문제를 해결하는 방법
- 。。
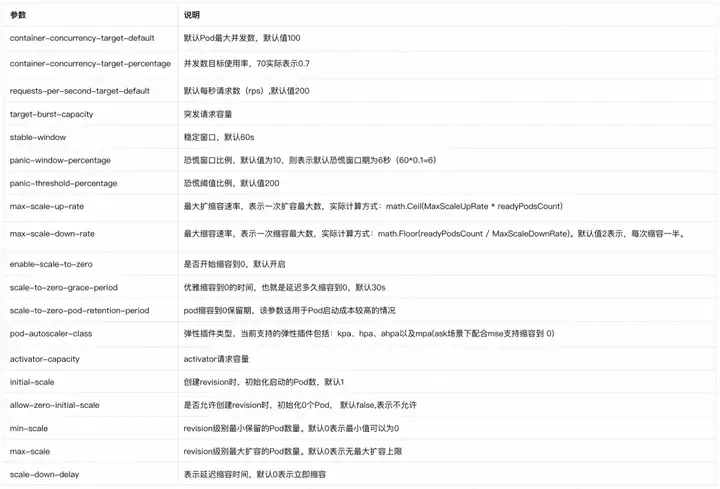
이러한 문제를 해결하기 위해 우리는 컨테이너 서비스 Knative 제품을 제공합니다. 커뮤니티 Knative와 완벽하게 호환되며 AI 추론 프레임워크 KServe를 지원합니다. 강화된 탄력성 기능, 예약된 리소스 풀 지원, 정확한 탄력성 및 탄력적 예측, 완전 관리형 ALB, MSE 및 ASM 게이트웨이 지원, 클라우드 제품 EventBridge와의 이벤트 기반 통합, 또한 ECI, Arm, 로그 서비스 등 포괄적인 통합이 이루어졌습니다.
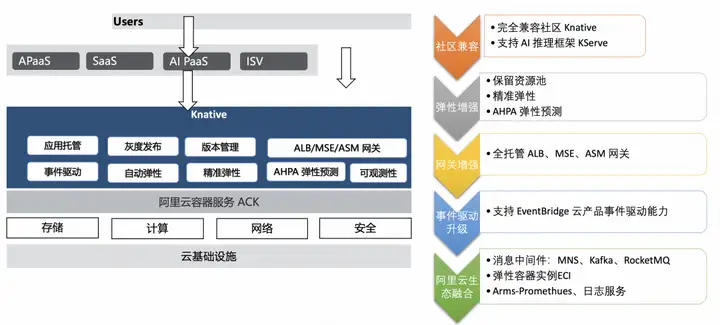
예약된 리소스 풀
기본 KPA 기능 외에도 리소스 풀을 예약하는 기능을 제공합니다. 이 기능은 다음 시나리오에 적용될 수 있습니다.

- ECS는 ECI와 혼합되어 있습니다. 일반적인 상황에서 ECS 리소스를 사용하고 버스트 트래픽에 ECI를 사용하려는 경우 리소스 풀을 예약하여 이를 달성할 수 있습니다. 정상적인 상황에서는 트래픽이 ECS 리소스를 통해 전달되며, 갑작스런 트래픽이 발생할 경우 새로 확장된 리소스는 ECI를 사용합니다.
- 자원 워밍업. ECI가 완전히 사용되는 시나리오의 경우 리소스 풀을 예약하여 리소스 예열을 달성할 수도 있습니다. 사업이 어려울 때 기본 컴퓨팅 인스턴스를 대체하기 위해 저사양 예약 인스턴스를 사용하는 경우, 첫 번째 요청이 들어올 때 예약 인스턴스를 사용하여 서비스를 제공하며, 이는 기본 사양 인스턴스의 확장도 트리거합니다. 기본 사양 인스턴스의 확장이 완료된 후 모든 새 요청은 기본 사양으로 전달된 다음 인스턴스를 유지하기 위해 인스턴스가 오프라인 상태가 됩니다. 이러한 원활한 교체 방법을 통해 비용과 효율성 간의 균형이 달성됩니다. 즉, 상당한 콜드 스타트 시간 없이 상주 인스턴스의 비용이 절감됩니다.
정확성과 유연성
단일 Pod가 요청을 처리하는 처리 속도에는 제한이 있으며, 동일한 Pod에 여러 요청이 전달되면 서버 측에 과부하 예외가 발생하므로 단일 Pod 요청의 동시 처리 수를 정확하게 제어할 필요가 있습니다. . 특히 일부 AIGC 시나리오에서는 단일 요청이 많은 GPU 리소스를 차지하므로 각 Pod에서 처리되는 동시 요청 수를 엄격하게 제한해야 합니다.
Knative는 MSE 클라우드 기본 게이트웨이와 결합되어 동시성에 기반한 정확한 탄력적 제어 구현인 mpa 탄력적 플러그인을 제공합니다.
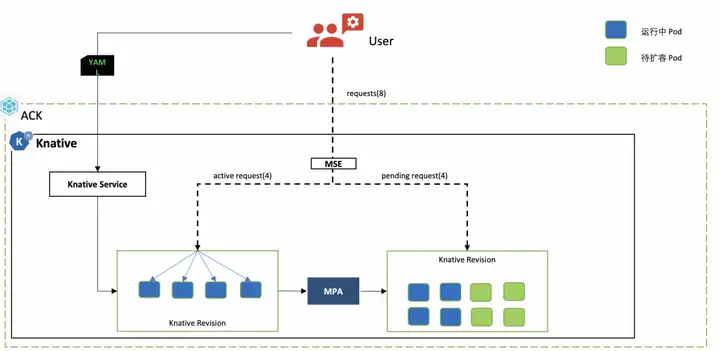
mpa는 MSE 게이트웨이에서 동시성 수를 가져와 확장 및 축소에 필요한 포드 수를 계산합니다. 포드가 준비되면 MSE 게이트웨이는 요청을 해당 포드로 전달합니다.
탄력적 예측
컨테이너 서비스 AHPA(Advanced Horizon Pod Autoscaler)는 탄력적 주기를 자동으로 식별하고 과거 비즈니스 지표를 기반으로 용량을 예측하여 탄력적 지연 문제를 해결할 수 있습니다.
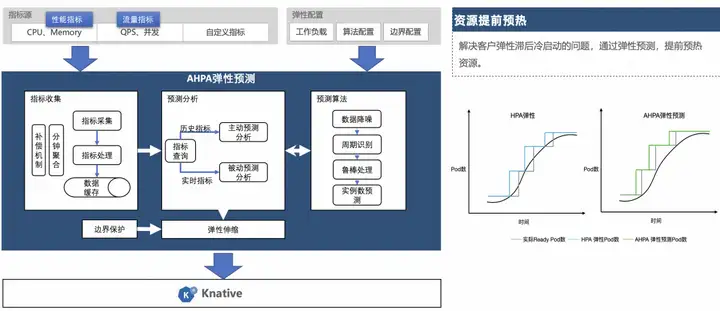
현재 Knative는 AHPA(Advanced Horizon Pod Autoscaler)의 탄력적 기능을 지원하고 있으며, 요청이 주기적일 경우 탄력적 예측을 통해 리소스를 예열할 수 있습니다. 자원 예열 임계값을 낮추는 것과 비교하여 AHPA는 자원 활용도를 극대화할 수 있습니다.
AHPA를 통해 다음을 수행할 수 있습니다.
- 사전 리소스 준비: 요청이 도착하기 전에 미리 용량을 확장합니다.
- 안정적이고 신뢰할 수 있음: 예상 RPS 처리량은 필요한 실제 요청 수를 처리하기에 충분합니다.
이벤트 중심
Knative는 Eventing을 통해 이벤트 중심 기능을 제공하고 Eventing은 이벤트 흐름 및 배포를 위해 Broker/Trigger를 사용합니다.
그러나 기본 Eventing을 직접 사용하는 경우에도 몇 가지 문제에 직면합니다.
- 충분한 이벤트 소스를 다루는 방법
- 전송 중에 이벤트가 손실되지 않도록 하는 방법

프로덕션 수준의 이벤트 중심 기능을 구축하는 방법은 무엇입니까? Alibaba Cloud EventBridge와 통합됩니다.
EventBridge는 Alibaba Cloud에서 제공하는 서버리스 이벤트 버스 서비스입니다. Alibaba Cloud Knative Eventing은 하위 계층에 EventBridge를 통합하여 Knative Eventing에 클라우드 제품 수준 이벤트 기반 기능을 제공합니다.
그렇다면 실제 비즈니스 시나리오에서 Knative를 어떻게 사용합니까? Knative를 통해 어떤 이점을 얻을 수 있나요? 다음으로 Shuhe Technology에서 Knative를 활용한 모범 사례를 소개하겠습니다.
Shuhe는 Knative의 모범 사례를 기반으로 합니다.

Shuhe Technology(전체 명칭 "Shanghai Shuhe Information Technology Co., Ltd.")는 2015년 8월에 설립되었습니다. Shuhe Technology는 빅 데이터와 기술을 기반으로 금융 기관에 효율적인 지능형 소매 금융 솔루션을 제공합니다. 사업 분야는 소비자 신용, 마케팅 고객 확보, 리스크 예방 및 통제, 운영 관리 등 중소기업 신용, 시나리오 할부 등 다양한 분야의 서비스를 제공합니다.

Shuhe Technology의 자회사인 Huanbei APP는 다양한 소비 시나리오를 기반으로 하는 할부 서비스 플랫폼으로, 2016년 2월에 공식 출시되었습니다. 인가받은 금융기관과 협력하여 국민에게 개인소비자 신용서비스를 제공하고, 소상공인에게 대출자금 지원을 제공합니다. 2023년 6월 현재 Huanbei는 1억 3천만 명의 활성화된 사용자를 보유하고 있으며 1,700만 명의 사용자에게 합리적인 신용 서비스를 제공하여 사용자가 '쉽게 빌리고 상환'할 수 있도록 지원합니다.

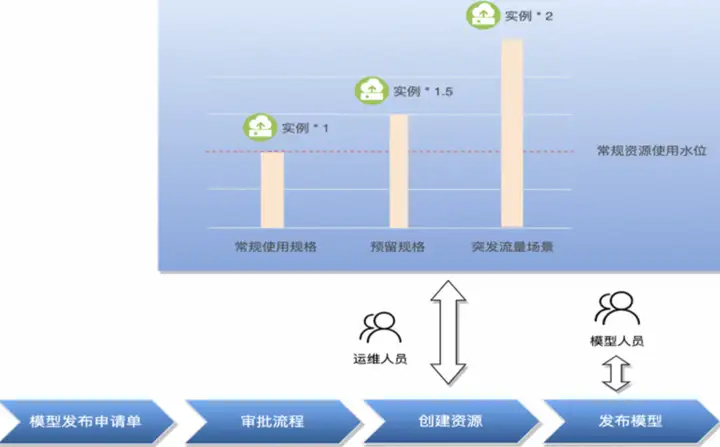
모델 출시의 문제점
모델 출시 단계에서 자원 낭비가 문제
- 당사 서비스의 안정성을 보장하기 위해 버퍼는 일반적으로 예약되며, 리소스는 일반적으로 실제 사용량을 초과하는 사양에 따라 예약됩니다.
- 생성된 리소스가 전체 시간 동안 완전히 사용되지 않습니다. 일부 온라인 응용 프로그램, 특히 일부 오프라인 작업 유형 응용 프로그램을 볼 수 있습니다. 대부분의 경우 전체 CPU 및 메모리 사용량이 매우 낮고 특정 기간의 리소스만 사용됩니다. 이용률이 높아지며, 조석 현상이 뚜렷하게 나타납니다.
- 리소스 사용에는 유연성이 부족하기 때문에 많은 양의 리소스 낭비가 발생하는 경우가 많습니다.
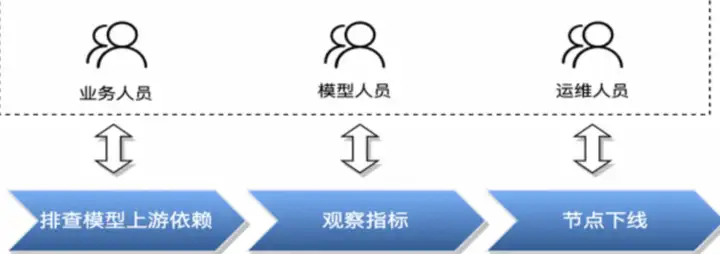
모델 오프라인 단계에서 자원 회수가 어려운 문제
- 온라인 모델에는 동시에 여러 버전이 있을 수 있습니다.
- 모델의 실제 온라인 효과를 평가하기 위해 다양한 버전이 사용되며, 특정 버전이 제대로 작동하지 않으면 해당 버전은 의사 결정 과정에서 제거됩니다. 이때 모델은 실제로 더 이상 서비스를 제공하지 않으며, 이때 리소스가 제때에 오프라인 상태가 되지 않으면 리소스 낭비가 발생합니다.
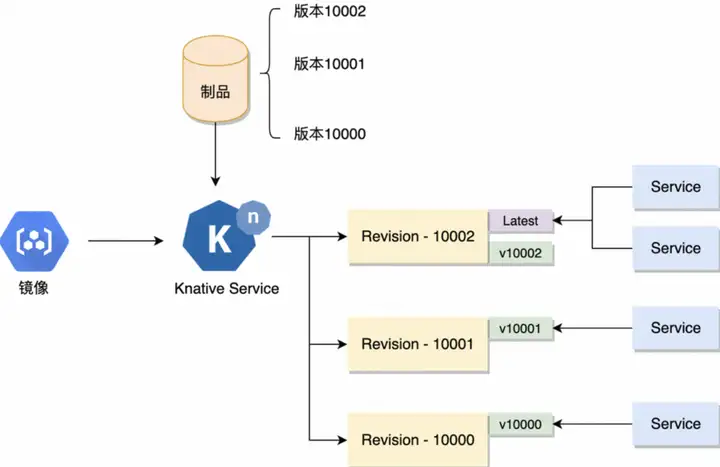
모델 지속적 전달 기술 아키텍처
모델 플랫폼 부분
모델 플랫폼은 모델 파일을 생성한 후 모델 파일을 BetterCDS에 등록합니다.
BetterCDS는 이 모델 파일에 해당하는 아티팩트를 생성합니다.
모델 출시 및 모델 버전 관리는 제품을 통해 완료 가능
Knative 관리 모듈
모델의 글로벌 Knative 확장 구성 구성
각 모델은 자체 knative 확장 구성으로 구성될 수 있습니다.
CI 파이프라인
CI 파이프라인의 주요 프로세스는 모델 파일을 가져오고 dockerfile을 통해 모델 이미지를 빌드하는 것입니다.
배포 프로세스
파이프라인은 Knative Service를 업데이트하고 라우팅 버전과 미러 주소를 설정하며 Knative의 탄력적 확장 구성을 업데이트합니다. Knative는 제품 버전에 해당하는 개정판을 생성합니다.
Knative 서비스 업데이트 프로세스
- Knative 서비스 업데이트로 개정 버전이 생성됩니다.
- 개정 버전은 배포 개체를 생성합니다.
- 파이프라인은 배포 상태를 관찰하며, 모든 포드가 준비되면 이 버전은 성공적으로 배포된 것으로 간주됩니다.
- 배포가 성공적으로 완료되면 개정에 태그를 지정하여 버전 경로를 생성합니다.

모델 다중 버전 출시
모델의 다중 버전 제품 릴리스는 Knative 구성을 통해 구현됩니다.
1. 제품의 여러 버전은 구성의 개정 버전과 일대일로 대응됩니다.
2. 제품에는 모델 버전 이미지가 포함되어 있으며, Knative Service의 이미지 버전을 업데이트하여 제품에 해당하는 Revision이 생성됩니다.
다중 버전 서비스 공존 기능 모델:
1. 태그를 통해 개정에 대한 버전 경로를 생성하고 경로에 따라 다른 버전 서비스를 호출합니다.
2. 여러 버전이 동시에 존재하기 때문에 의사결정 과정에서 서로 다른 모델 버전을 호출하여 모델 효과를 관찰할 수 있으며, 동시에 여러 라우팅 버전이 존재하므로 여러 트래픽 정책을 지원할 수 있습니다. .
또한 의사 결정 프로세스를 변경하지 않고도 최신 경로를 어떤 버전으로든 전환하여 온라인 트래픽 전환을 완료할 수 있는 일련의 최신 경로를 지원합니다.
요청 기반 팝업
모델이 요청 수에 따라 탄력적 확장 전략을 채택하는 이유는 다음과 같습니다.
1. 대부분의 모델이 컴퓨팅 집약적인 서비스로 모델의 CPU 사용량은 요청 수와 정비례하므로 요청이 급증하면 CPU가 가득 차서 결국 서비스 폭증으로 이어집니다.
2. 요청 기반 팝업 외에 CPU, 메모리 지표 기반 HPA 팝업도 있는데, HPA 팝업에도 다음과 같은 문제점이 있습니다.
a.지표의 탄력적 확장 링크가 길다: Prometheus가 서비스 노출 지표에서 지표를 수집하면 지표가 상승하며, HPA는 해당 지표를 기반으로 확장할 Pod 수를 계산한 후 Pod 확장을 시작합니다. 전체적인 탄성 확장 링크는 상대적으로 길다.
b. 부정확한 표시기: 예를 들어 Java의 gc는 메모리에 주기적인 변경을 발생시킵니다.
c. 표시기는 실제 서비스 상태를 반영할 수 없습니다. 표시기가 상승하면 응답 지연이 매우 높아집니다. 즉, 표시기가 임계값을 초과한 것으로 확인되면 지연되고 Pod는 종료됩니다. 확장되면 포드가 준비됩니다. 또한 연기되었습니다.
3. 따라서 모델 서비스가 정상적인 서비스 상태를 유지할 수 있도록 확장 시간을 앞당기고 요청 수를 사용하여 모델 확장을 트리거해야 합니다.
다음은 100%-0%의 개정 버전 요청 작업 프로세스입니다.

Knative 팝업 링크는 다음과 같습니다.
1. 서비스에서 포드로 트래픽이 요청됩니다.
2. PodAutoscaler는 Pod에 있는 queue-proxy의 트래픽 요청 지표를 실시간으로 수집하고, 현재 요청에 따라 확장할 Pod 수를 계산합니다.
3. PodAutoscaler는 배포를 제어하여 Pod를 확장하고, 확장된 Pod가 이 서비스에 추가되어 Pod 확장이 완료됩니다.
지표 탄력적 확장과 비교하여 요청 기반 탄력적 확장 전략은 더 빠른 응답과 더 높은 민감도를 갖습니다. 서비스 대응을 보장할 수 있습니다. 과거 오프라인 리소스의 문제점을 고려하여 0까지 축소가 가능하므로 개정의 최소 Pod 수를 0으로 조정할 수 있습니다. 요청이 없으면 자동으로 0으로 축소됩니다. 탄력적 노드와 결합하여 용량을 0으로 줄이면 더 이상 리소스를 차지하지 않으며 모델 서비스의 서버리스 기능도 실현됩니다.
BetterCDS 원스톱 모델 출시
모델은 파이프라인을 통해 배포되며, 다음은 BetterCDS 릴리스 파이프라인 단계 프로세스입니다.

- 버전 배포 단계: Knative 모델 배포를 트리거합니다.
- 새 경로: Knative 버전 경로를 추가합니다.
- 최신 경로 업데이트: 파이프라인의 매개변수로 최신 경로를 업데이트하며, 배포가 완료되면 최신 경로를 업데이트하도록 선택할 수 있습니다.
Knative 팝업 구성 관리 모듈을 통해 각 모델별로 글로벌 팝업 구성과 버전 팝업 구성이 가능합니다.
클러스터 탄력적 확장 아키텍처
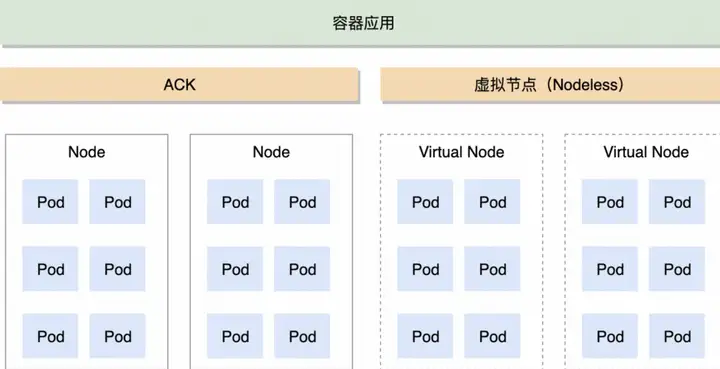
컨테이너 애플리케이션은 ACK 및 가상 노드 클러스터에서 실행되며 EC와 Elastic 노드가 혼합되어 있습니다. 일반 비즈니스는 연간 및 월간 ECS 노드로 수행되고 탄력적 비즈니스는 종량제 탄력 노드로 수행되어 높은 성과를 달성할 수 있습니다. 저렴한 비용으로 탄력성을 제공합니다. 가상 노드의 탄력성 기능을 기반으로 탄력성 요구 사항을 충족할 뿐만 아니라 리소스 낭비를 방지하고 사용 비용을 절감합니다.
1. ACK는 고정 노드 리소스 풀을 유지하고 상주 Pod 및 일반 비즈니스 볼륨을 기반으로 노드를 예약하며 연간 및 월별 비용은 더 저렴합니다.
2. 가상 노드는 탄력적인 인스턴스를 실행하여 탄력적인 기능을 제공합니다.노드에 신경 쓸 필요가 없기 때문에 필요에 따라 탄력적인 기능을 확장하여 갑작스러운 트래픽과 최고점과 최저점에 쉽게 대처할 수 있습니다.
3. 작업 및 오프라인 작업에 대한 실시간 요구 사항이 높지 않은 기업의 경우 주기성으로 인해 자원이 항상 점유되지 않으며 비용 이점이 높습니다.
4. 무료 운영 및 유지 관리: 탄력적 노드, 포드는 모두 사용되면 폐기됩니다.
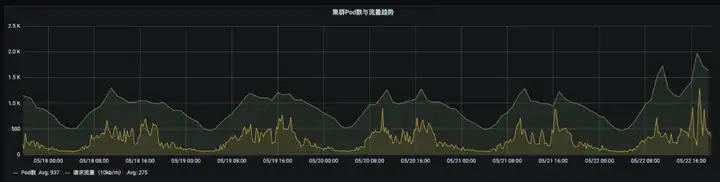
결과 및 이점
Knative의 탄력성은 리소스 사용량을 극대화합니다. 리소스 및 트래픽 요청의 곡선을 보면 리소스에 최고점과 최저점이 있으며 뚜렷한 주기성이 있음을 알 수 있습니다. 요청이 증가하면 Pod 사용량이 증가하고 요청이 감소하면 Pod가 사용량이 증가하고 볼륨이 감소합니다. 클러스터 내 최대 Pod 수는 2,000개에 가깝고, 비용은 과거 대비 약 60% 절감되었으며, 리소스 절감 효과도 상당합니다.
Knative의 다중 버전 게시 기능 덕분에 게시 효율성도 과거 몇 시간에서 지금은 몇 분으로 향상되었습니다. Shuhe의 Knative 모델 사례도 권위 있는 인증을 받았으며 정보통신기술원(Academy of Information and Communications Technology)의 클라우드 네이티브 산업 연합에서 "우수한 클라우드 네이티브 응용 사례"로 선정되었습니다.

Knative와 AIGC
AIGC 분야에서 잘 알려진 프로젝트인 Stable Diffusion은 사용자가 원하는 장면과 그림을 빠르고 정확하게 생성할 수 있도록 도와줍니다. 그러나 현재 K8s에서 Stable Diffusion을 직접 사용하면 다음과 같은 문제에 직면합니다.
- 단일 Pod가 요청을 처리하는 처리 속도에는 제한이 있으며, 동일한 Pod에 여러 요청이 전달되면 서버 측에 과부하 예외가 발생하므로 단일 Pod 요청의 동시 처리 수를 정확하게 제어할 필요가 있습니다. .
- GPU 자원은 소중합니다. 수요에 따라 자원을 사용하고, 경기가 좋지 않을 때 적시에 GPU 자원을 출시할 것으로 예상됩니다.
위의 두 가지 이슈를 바탕으로 Knative를 통해 동시성 기반의 정밀한 탄력성을 얻을 수 있으며, 리소스를 사용하지 않을 때는 용량이 0으로 줄어듭니다.
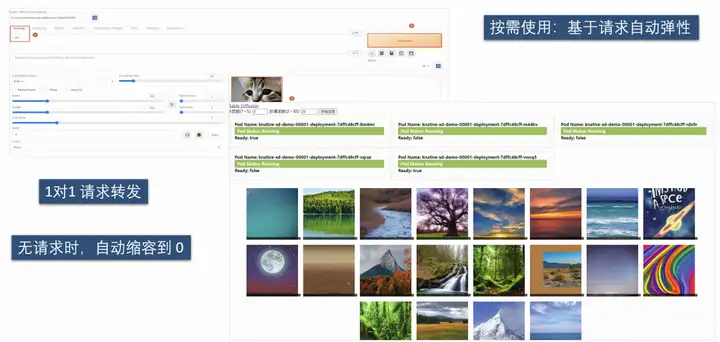
또한 Knative는 요청 수, 요청 성공률, Pod 확장 및 축소 추세, 요청 응답 지연 등을 볼 수 있는 즉시 사용 가능한 관찰 가능한 디스크를 제공합니다.
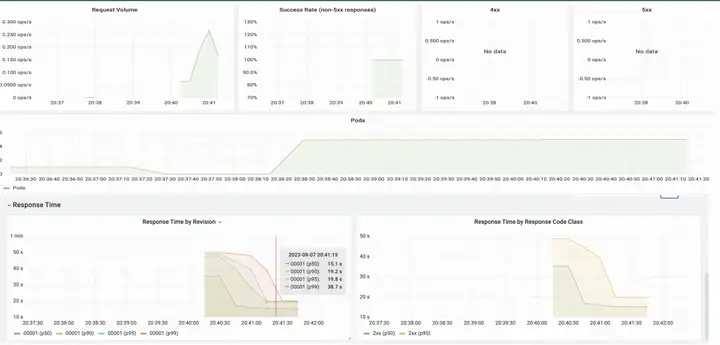
작성자: Li Peng(Alibaba Cloud), Wei Wenzhe(Shuhe Technology), 이 기사는 KubeCon China 2023 공유 및 편집을 기반으로 합니다.
이 기사는 Alibaba Cloud의 원본 콘텐츠이므로 허가 없이 복제할 수 없습니다.
Alibaba Cloud가 심각한 장애를 겪고 모든 제품이 영향을 받음(복원) Tumblr는 러시아 운영 체제 Aurora OS 5.0을 냉각시켰습니다 . 새로운 UI는 Delphi 12 & C++ Builder 12, RAD Studio 12를 공개했습니다 . 많은 인터넷 회사들이 Hongmeng 프로그래머를 긴급 채용합니다. UNIX 시간 17억 시대를 앞두고 있다.(이미 돌입했다.) 메이투안은 병력을 모집해 홍몽 시스템 앱을 개발할 계획이다. 아마존은 리눅스 기반의 운영체제인 .NET 8에 대한 안드로이드의 의존성을 없애기 위해 리눅스 기반 운영체제를 개발한다 . 독립 규모는 50% 감소 FFmpeg 6.1 "Heaviside" 출시