Presente algunos modelos de aprendizaje multitarea para comprender cómo manejar ramas multitarea.
ESSM, modelo multitarea para todo el espacio
El nombre completo de ESSM propuesto por Ali es Entire Space Multi-Task Model . Es un modelo multitarea en el espacio muestral completo que resuelve eficazmente dos problemas muy importantes en el modelado CVR (estimación de la tasa de conversión): sesgo de selección de muestra (SSB). , sesgo de selección de muestra) y escasez de datos.
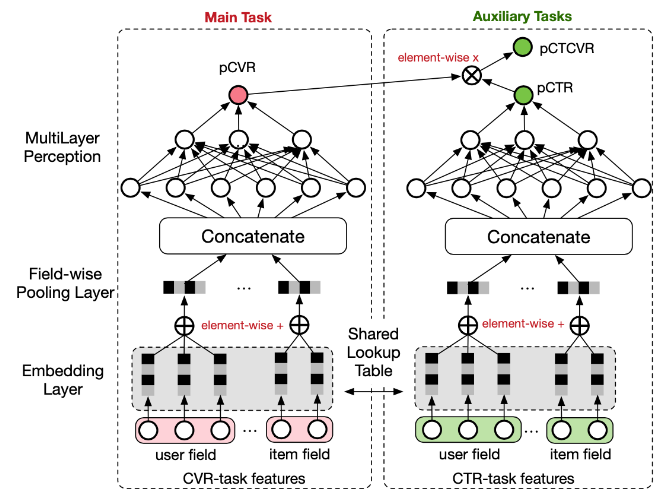
La estructura de red general de ESMM se muestra en la figura. Se pueden ver dos características de ESMM:
- Las dos torres, CTR y CVR, comparten la base de empotramiento. Por lo tanto, el número de muestras de CVR es demasiado pequeño, lo que significa que existe un problema de escasez de datos en los dos problemas mencionados al principio, por lo que es difícil entrenar completamente y aprender buenas expresiones de incrustación, pero hay muchas muestras de CTR, por lo que compartir la incrustación base es un poco de aprendizaje por transferencia. Taste ayuda a que los vectores de incrustación de CVR se entrenen de manera más completa y precisa.
- CVR es en realidad una variable intermedia . No tiene su propia función de pérdida, lo que significa que no hay una señal de supervisión clara durante el entrenamiento. Durante el entrenamiento de ESMM, las dos tareas de CTR y CTCVR se entrenan principalmente. Esto se puede ver en la pérdida. función de ESMM Esto también se puede ver en el diseño funcional.
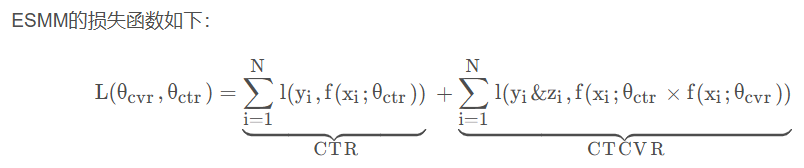
MMoE, mezcla de expertos multipuerta
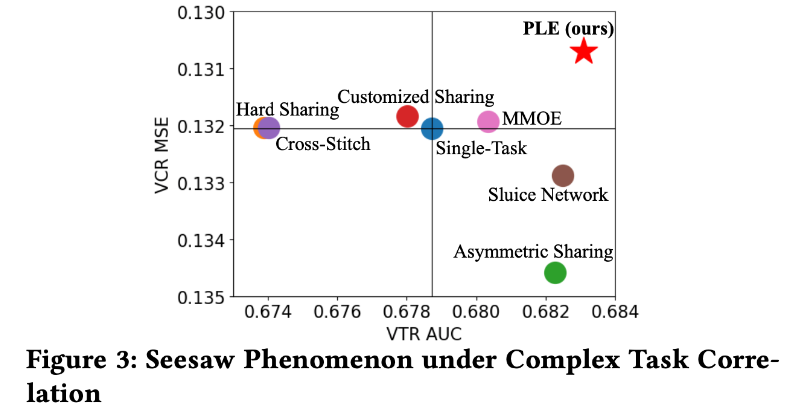
MMoE de Google, el nombre completo es Mezcla de expertos de puertas múltiples . En el modelo ESMM las dos torres tienen una clara dependencia y el rendimiento es destacable. Sin embargo, si la correlación entre estas torres es muy pequeña, el rendimiento será muy pobre e incluso se producirá un fenómeno de "balancín", es decir, la mejora del rendimiento de una tarea es a expensas del desempeño de otra tarea .
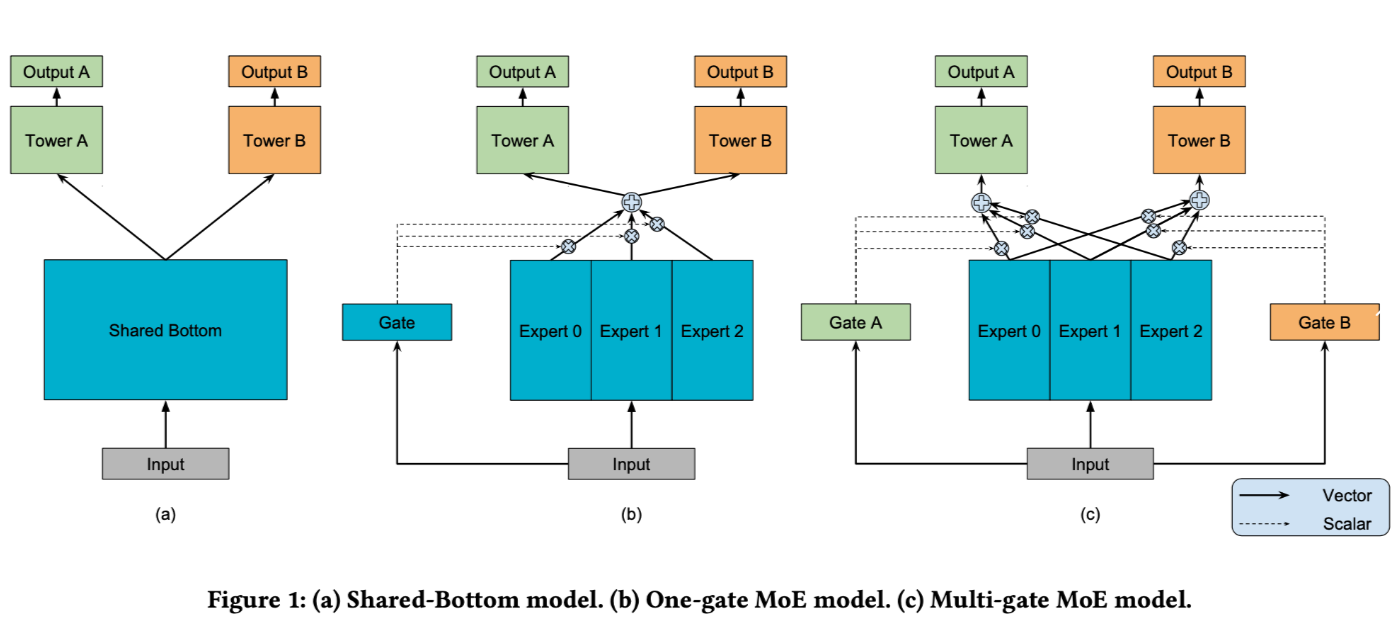
- (a) muestra la estructura del modelo MTL tradicional, es decir, múltiples tareas comparten la base (generalmente incorporando vectores),
- (b) es la estructura del modelo de mezcla de expertos de una puerta mencionada en el artículo,
- (c) es la estructura del modelo MMoE en el artículo.
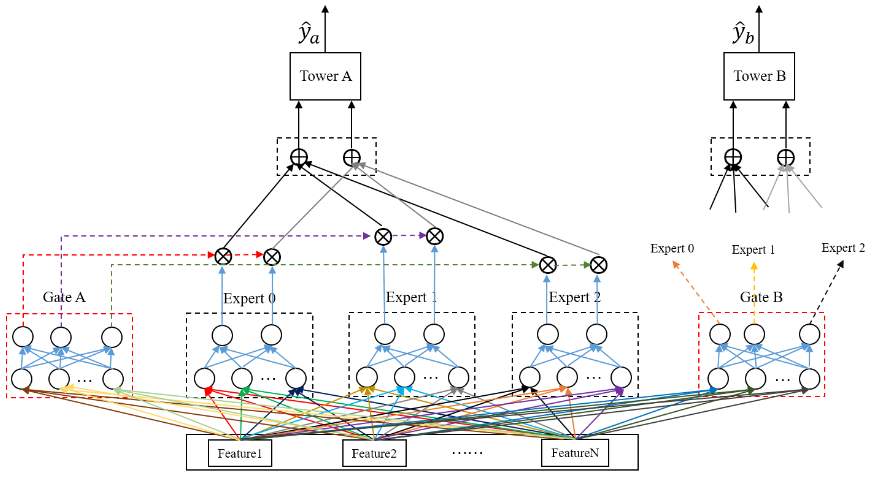

PLE, modelo de extracción progresiva en capas
Modelo PLE de Tencent, el nombre completo es Modelo de extracción en capas progresivas . Alivia dos problemas principales del aprendizaje multitarea: el fenómeno de transferencia negativa y el fenómeno de balancín.
- Transferencia negativa: MTL se propone para diferentes tareas, especialmente tareas con pequeñas cantidades de datos, que pueden usar el aprendizaje por transferencia (compartiendo la incrustación. Por supuesto, no solo puede compartir la incrustación, sino también la red completamente conectada de la capa base. Espere para estas operaciones tan comunes). Pero cuando la correlación entre dos tareas es débil o muy compleja, a menudo se produce una transferencia negativa, es decir, el efecto después de compartirlas es muy pobre.
- Fenómeno de balancín: cuando la correlación entre dos tareas es débil o compleja, un fenómeno común es que el desempeño de una tarea mejora al comprometer el desempeño de la otra.
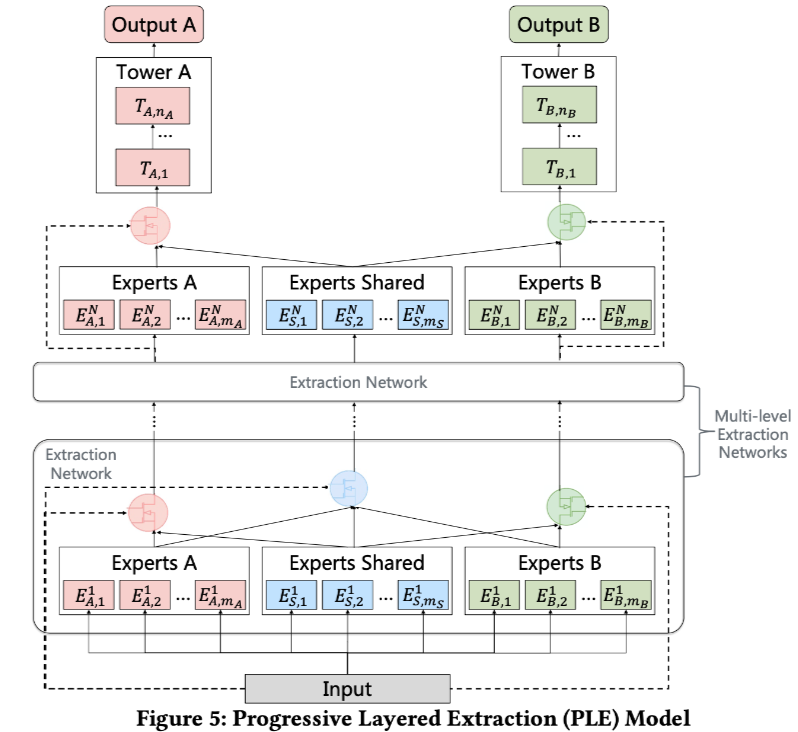
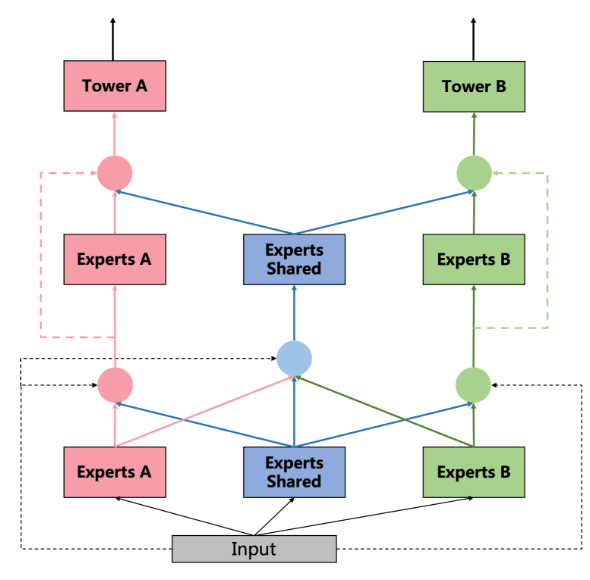
En comparación con MMoE, PLE ha realizado mayores innovaciones: MMoE permite que diferentes tareas compartan los mismos expertos a través de la red de puerta, mientras que PLE divide a los expertos en dos tipos: expertos compartidos (es decir, expertos compartidos en la figura anterior) y cada tarea específica. expertos. Por lo tanto, este diseño no solo conserva la capacidad de transferir el aprendizaje (al compartir experiencia), sino que también evita la interferencia de parámetros dañinos (evitando la transferencia negativa).

DSSM, modelos semánticos estructurados profundos
Modelo DSSM de Microsoft, el nombre completo es Deep Structured Semantic Models .

La estructura del modelo es muy simple y consta principalmente de dos partes: una torre en el lado del usuario y una torre en el lado del artículo. Las características del lado del usuario y las características del lado del elemento se pasan a través de sus propios DNN (generalmente, las dos estructuras DNN son las mismas) para obtener la incrustación del usuario y la incrustación del elemento. Es necesario asegurarse de que las dimensiones de salida sean las mismas, es decir , El número de unidades ocultas en la última capa completamente conectada. Si los números son los mismos, debe asegurarse de que las dimensiones de la incrustación del usuario y la incrustación del elemento sean las mismas , porque el siguiente paso es calcular la similitud (producto interno de uso común). o coseno). La parte de la función de pérdida es la pérdida de entropía cruzada binaria de uso común, y_true es la etiqueta real 0 o 1 e y_pred es el resultado de similitud.
Desventajas del modelo DSSM: las funciones cruzadas del elemento n.º de usuario no se pueden utilizar.
PuertaNet
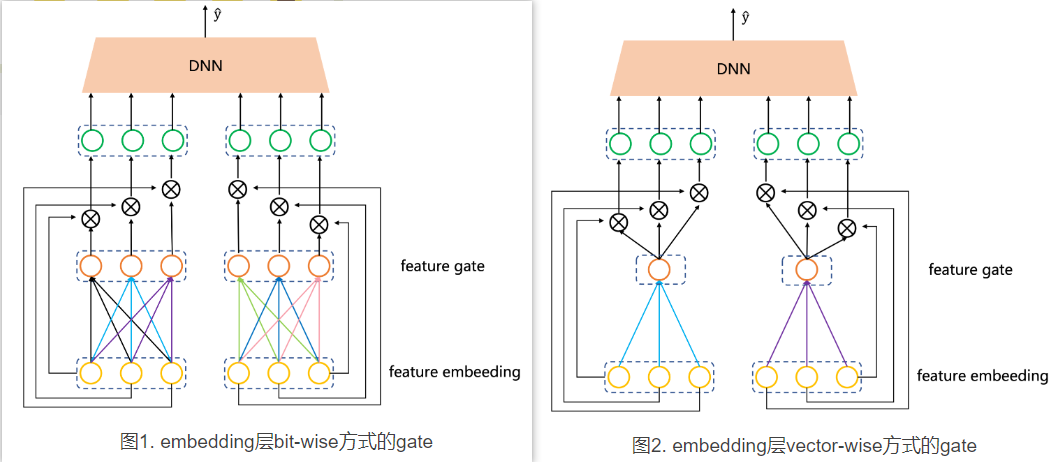
GateNet de Sina Weibo . Según las diferentes posiciones de aplicación de la red Gate, se divide en dos tipos: Puerta de capa de incrustación (Puerta de incrustación de características) y Puerta de capa oculta (Puerta oculta).
La capa de incrustación Gate aplica la red Gate a la capa de incrustación, y la capa oculta Gate aplica la red Gate a la capa oculta del MLP.
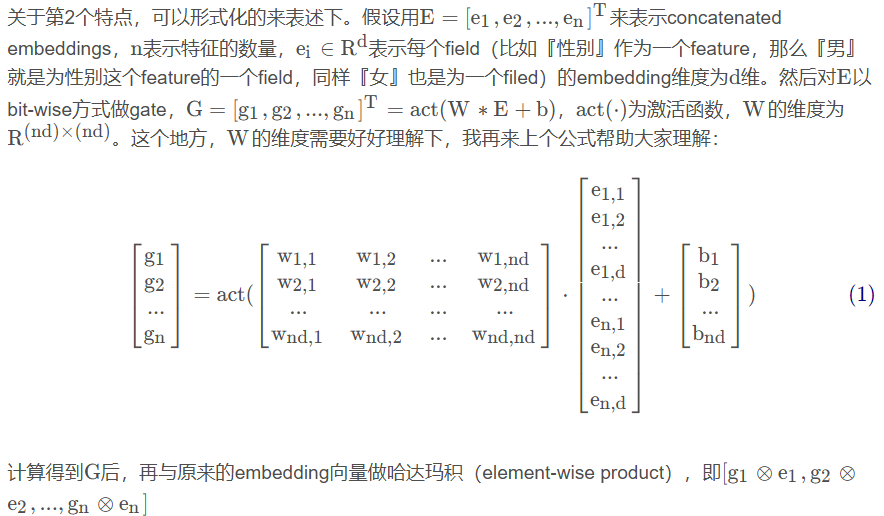
Ambas puertas se dividen específicamente en dos tipos: bit a bit y vectorial. Bit a bit significa que cada elemento (bit) del vector de incrustación de cada característica tendrá un parámetro Gate correspondiente, mientras que vectorial significa que un vector de incrustación tiene solo un parámetro Gate. Suponga que la muestra tiene dos características y que la dimensión de incrustación de cada característica es 3. Utilice la figura para comparar vívidamente la diferencia entre puertas bit a bit y vectoriales:
En el artículo, se proponen dos conceptos con respecto a si se comparten los parámetros de la red de puertas:
- Campo privado: cada característica tiene su propia puerta (lo que significa que el número de puertas es igual a la cantidad de características). Los parámetros no se comparten entre estas puertas y son todos independientes. El método de puerta en la Figura 1 y la Figura 2 es este.
- Compartir campo: a diferencia del campo privado, diferentes funciones comparten una puerta y solo se necesita una. La ventaja es que los parámetros se reducen considerablemente y la desventaja es que los parámetros se reducen considerablemente y el rendimiento no es tan bueno como el privado en el campo.
Los experimentos presentados en el artículo muestran que el efecto del modelo del método privado de campo es mejor que el método de uso compartido de campo.
- Pregunta 1: ¿Qué es mejor, el método privado del campo del parámetro de puerta o el método de compartir campo? Los resultados experimentales muestran que el efecto del modelo del método privado de campo es mejor que el del método compartido de campo.
- Pregunta 2: ¿Qué método de aplicación de puerta es mejor, bit a bit o vectorial? En el conjunto de datos de Criteo, el efecto bit a bit es mejor que el efecto vectorial, pero tal conclusión no se puede obtener en el conjunto de datos ICME.
- Pregunta 3: ¿Qué efecto es mejor cuando la puerta se aplica a la capa de incrustación o a la capa oculta? El artículo no da una conclusión, pero a partir de los datos proporcionados, se puede ver que el efecto en la capa oculta es mejor que en la capa incrustada. Además, si se utilizan ambos métodos, el efecto no mejorará mucho en comparación con usar solo uno.
- Pregunta 4: ¿Qué función de activación es mejor para la red de puerta? La capa de incrustación es lineal y la capa oculta es tanh.
GemNN, redes neuronales multitarea mejoradas con puertas
GemNN de Baidu, el nombre completo es Gating-Enhanced Multi-Task Neural Networks .
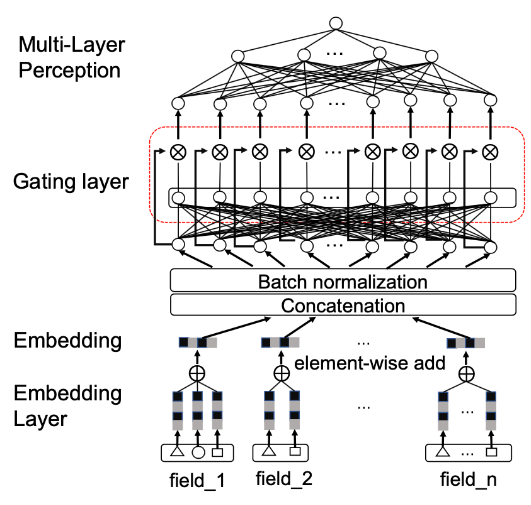
Con respecto a la puerta en GemNN, como se muestra en la figura, hay tres características notables:
- La posición de la puerta es entre la capa de incrustación y la capa MLP completamente conectada.
- En lugar de crear puertas separadas para cada característica, todas las características se concatenan (concatenación) antes de crear puertas.
- El método de puerta es bit a bit.
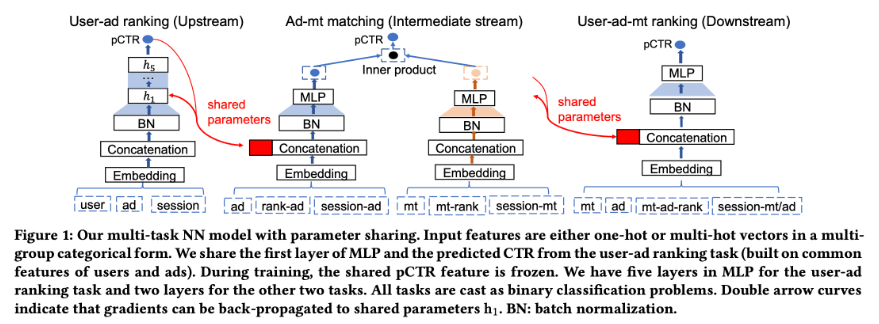
Se compartirán las mismas funciones incorporadas en el enlace. Compartido aquí no se comparte durante el entrenamiento, pero es similar al inicio en caliente previo al entrenamiento. En combinación con la figura, se compartirán algunas características comunes del modelo de clasificación de anuncios de usuario, el modelo de coincidencia de anuncios-mt y el modelo de usuario-ad-mt.
referencia
Sistema de recomendación (18) Red de puertas (1): Blog Sina Weibo GateNet-CSDN