Explicación: este es un proyecto práctico de aprendizaje automático (con datos + código + documentación + explicación en video ). Si necesita datos + código + documentación + explicación en video, puede ir directamente al final del artículo para obtenerlo.
1. Antecedentes del proyecto
Los sistemas de recomendación en línea son el trabajo de muchos sitios de comercio electrónico. El sistema de recomendación recomienda ampliamente productos a los clientes que son más adecuados para sus gustos y características. De acuerdo con los registros de interacción usuario-libro en el mundo real, utilizando tecnologías relacionadas con el aprendizaje profundo, se establece un sistema de recomendación de libros preciso y estable para predecir los libros. que los usuarios pueden leer.
Este proyecto aplica un modelo de integración de aprendizaje profundo para implementar un sistema de recomendación de libros.
2. Adquisición de datos
Los datos de modelado para este tiempo provienen de Internet (compilados por el autor de este proyecto), y las estadísticas de los elementos de datos son las siguientes:
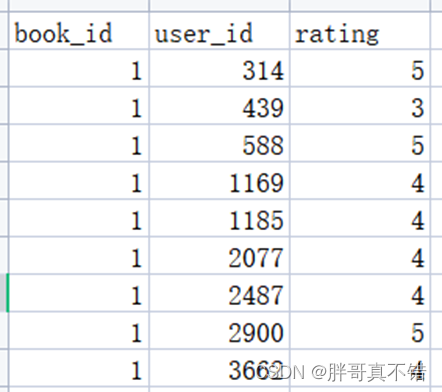
Los detalles de los datos son los siguientes (visualización parcial):
Algunos datos de visualización:
3. Preprocesamiento de datos
3.1 Ver datos con las herramientas de Pandas
Use el método head() de la herramienta Pandas para ver las primeras cinco filas de datos:
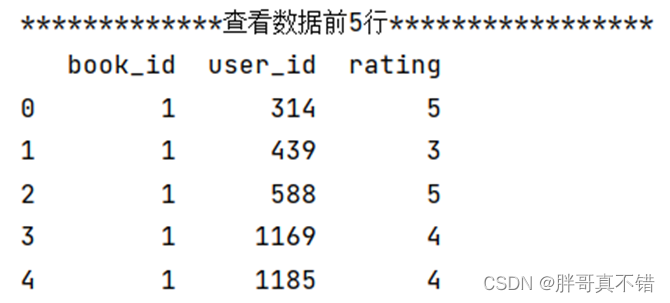
Como puede ver en la figura anterior, hay 3 campos en total.
clave:
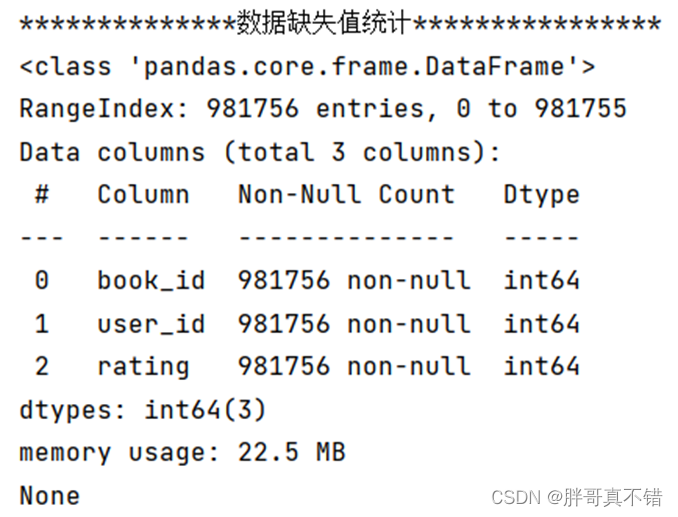
3.2 Estadísticas de valores perdidos
Usa el método info() de la herramienta Pandas para contar la ausencia de cada función:
Como se puede ver en la figura anterior, no faltan valores en los datos, y el volumen total de datos es 981,756.
clave:
3.3 Ver la forma del conjunto de datos
Utilice el atributo de forma de la herramienta Pandas para ver la forma del conjunto de datos:
El código clave es el siguiente:
Cuente el número de usuarios y el número de libros:
El código clave es el siguiente:
4. Análisis de datos exploratorios
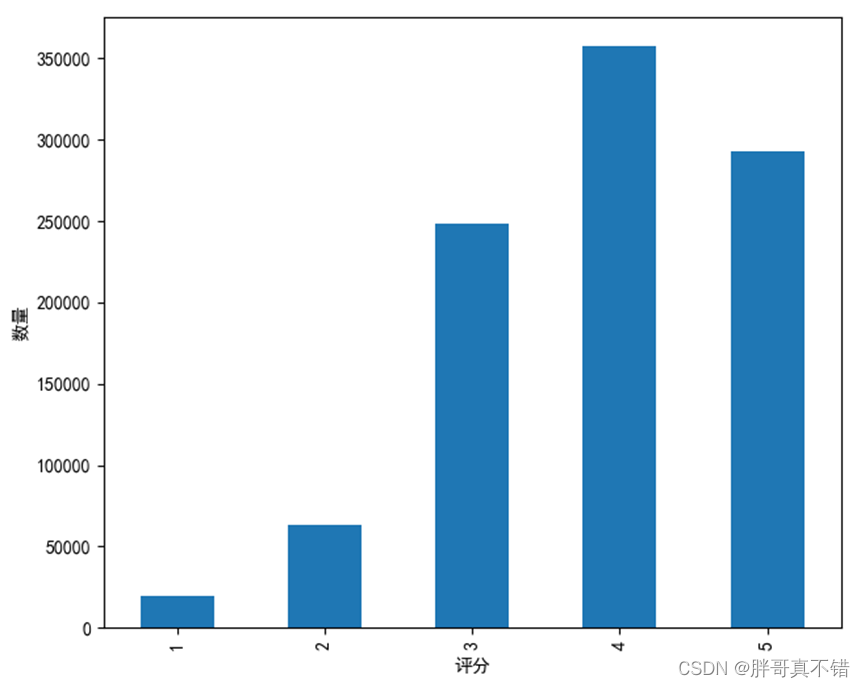
4.1 Visualización grupal
Estadísticas de grupos por puntuación, como se muestra en la siguiente figura:
5. Ingeniería de características
5.1 División de conjuntos de datos
El conjunto de datos se divide en conjunto de entrenamiento y conjunto de prueba, 80% conjunto de entrenamiento y 20% conjunto de prueba, el código clave es el siguiente:
6. Cree un modelo de recomendación de libros
Utiliza principalmente un algoritmo de modelo de incrustación de aprendizaje profundo para la recomendación de objetivos.
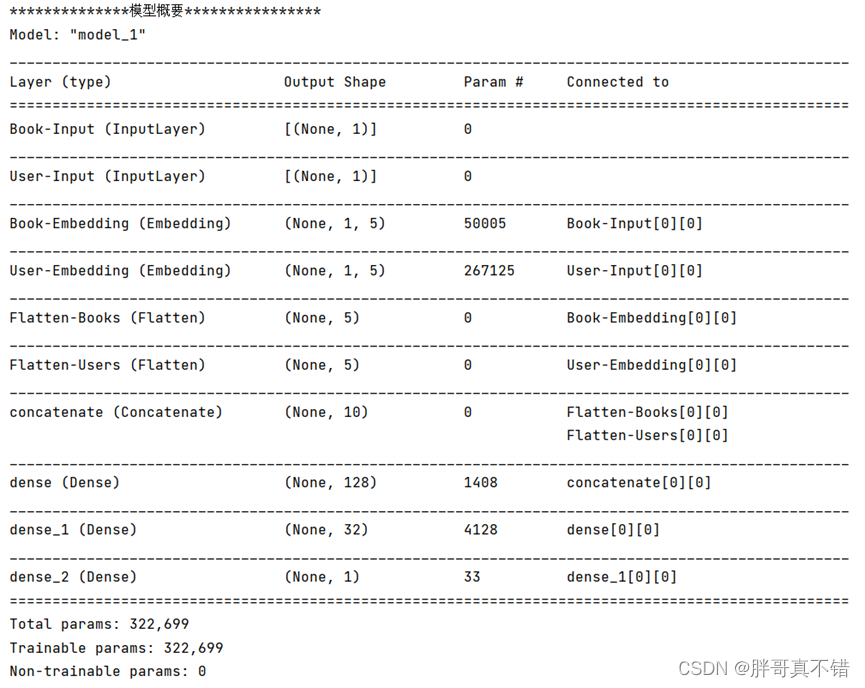
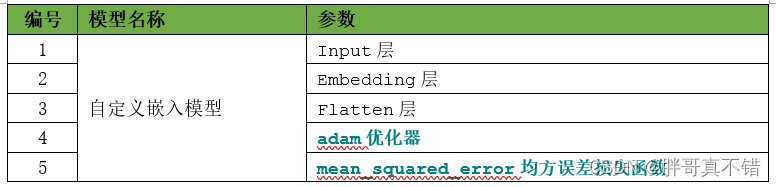
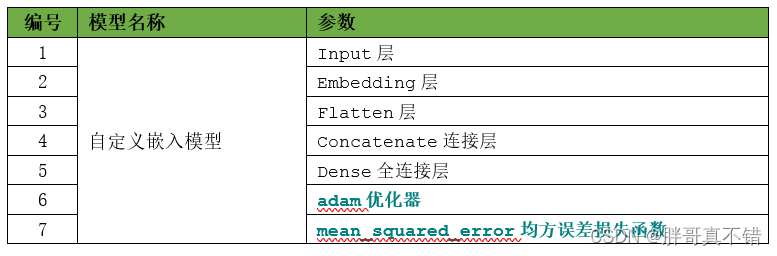
6.1 Construcción del modelo de incrustación inicial
Información resumida del modelo:
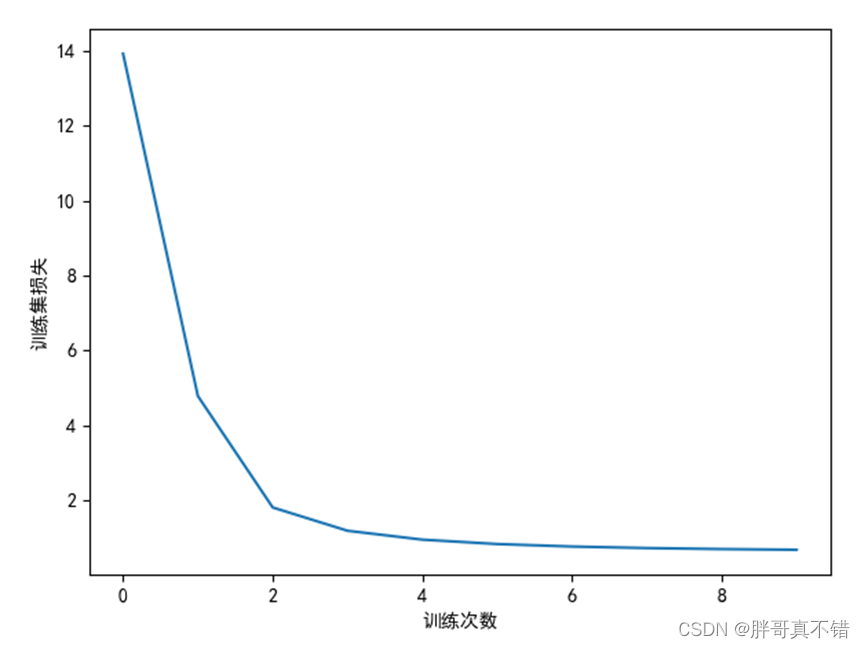
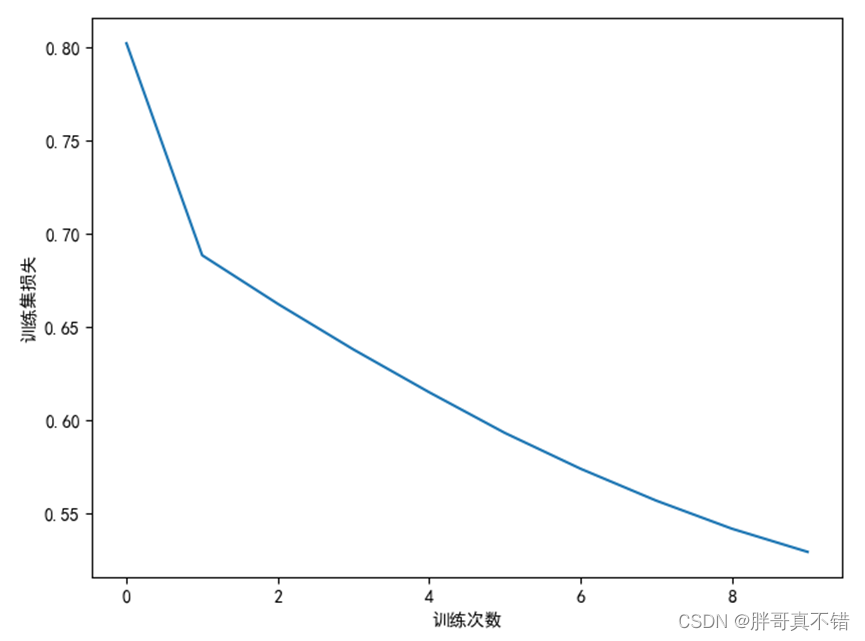
6.2 Gráfico de pérdida de conjuntos de entrenamiento
6.3 Evaluación del modelo
Como se puede ver en la figura anterior, la pérdida de este modelo es 0.9201.
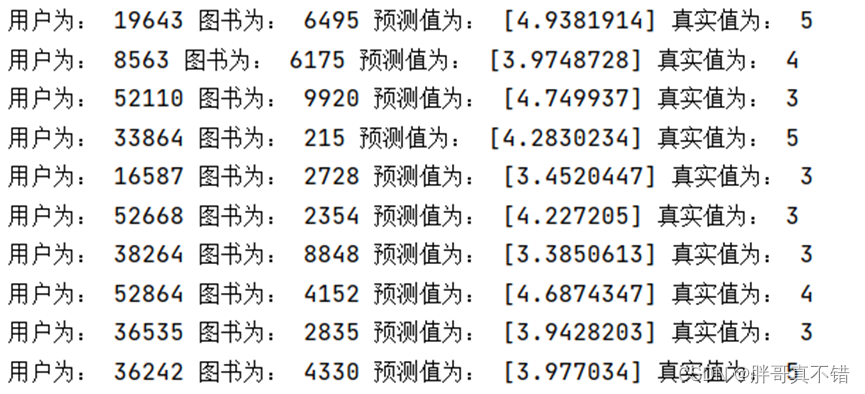
6.4 Predicción del modelo
6.5 Optimización del modelo
Información resumida del modelo:
7. Modelo de Evaluación y Predicción
7.1 Gráfico de pérdida de conjuntos de entrenamiento
7.2 Indicadores y resultados de la evaluación
Como se puede ver en la figura anterior, la pérdida del modelo optimizado es 0.7458, que es menor que el modelo de inicialización.
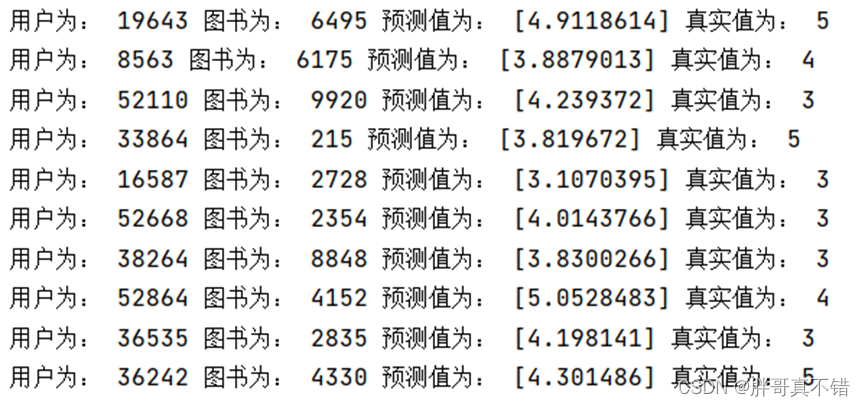
7.3 Predicción del modelo
Como se puede ver en la figura anterior, los libros se pueden recomendar a los usuarios en función de las calificaciones previstas. Por ejemplo, los usuarios se pueden ordenar por grupo y las calificaciones se ordenan de mayor a menor, y los libros con calificaciones altas se pueden recomendar a usuarios
8. Conclusión y perspectiva
En resumen, este proyecto utiliza algoritmos de aprendizaje profundo para construir un sistema de recomendación de libros y, finalmente, demuestra que nuestro modelo propuesto funciona bien y puede usarse para modelar y predecir en la vida diaria para mejorar el valor de la producción.










Los materiales y recursos del proyecto necesarios para el combate real de este proyecto de aprendizaje automático son los siguientes:
Descripción del proyecto:
Enlace: https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
Código de extracción: bcbp