
論文リンク:視覚認識のための深層高解像度表現学習
時期: 2019.08 TPAMI2019
著者チーム: Jingdong Wang、Ke Sun、Tianheng Cheng、Burui Jiang、Chaorui Deng、Yang Zhao、Dong Liu、Yadong Mu、Mingkui Tan、Xinggang Wang、Wenyu Liu、Bin Xiao
分類: コンピューター ビジョン – 人間のキー ポイント検出 – 2D トップダウン
目次:
1.HRNetv2の背景
2.HRNetv2 ジェスチャ認識
3.HRNetv2ネットワークアーキテクチャ図
4. 引用
1. 主に学習記録用です 違反がある場合はプライベートメッセージを送って修正してください
2. レベルに制限があります 不備があればご指摘いただきありがとうございます
1.HRNetv2の背景
コンピューター ビジョン タスクでは、深層学習に基づく特徴表現は通常、低解像度表現と高解像度表現の 2 つのカテゴリに分類されます。
高解像度の表現を取得するには、現在 2 つの主なアプローチがあります。
- ネットワークによって出力された低解像度表現または中間の中解像度表現から高解像度表現を復元し、ダウンサンプリング後に得られた特徴マップをアップサンプリングして高解像度表現を取得します (Hourglass、SegNet、DeconvNet など)。 、U-Net、エンコーダ - デコーダなど。
- 高解像度の畳み込みによって高解像度の表現を維持し、並列の低解像度の畳み込みによって表現を強化します。
高解像度コンボリューションでは高解像度の表現が維持されますが、高解像度と低解像度の融合を設計する必要があります。主なアイデアは次のとおりです:
(a) 対称構造、最初にダウンサンプリング、次にアップサンプリング、およびアップサンプリングとダウンサンプリングのプロセスは対称的、U-Net や Hourglass など。
(b) カスケード ピラミッド。リファインネットなどの高解像度と低解像度の融合中に畳み込み処理が行われます。
(c) シンプルなベースライン、転置畳み込みによるアップサンプリング。
(d) 拡張畳み込みは、受容野を増加させ、ダウンサンプリングの数を減らし、ディープラボなどの層接続をスキップすることなく直接アップサンプリングします。
HRNet V1 は (b) を改善し、大きな解像度の表現を維持します。ただし、HRNet V1 は姿勢推定の分野でのみ使用され、HRNet V2 は HRNetV2 に小さな改良を加えて、より広範囲の視覚タスクに適したものにしています。
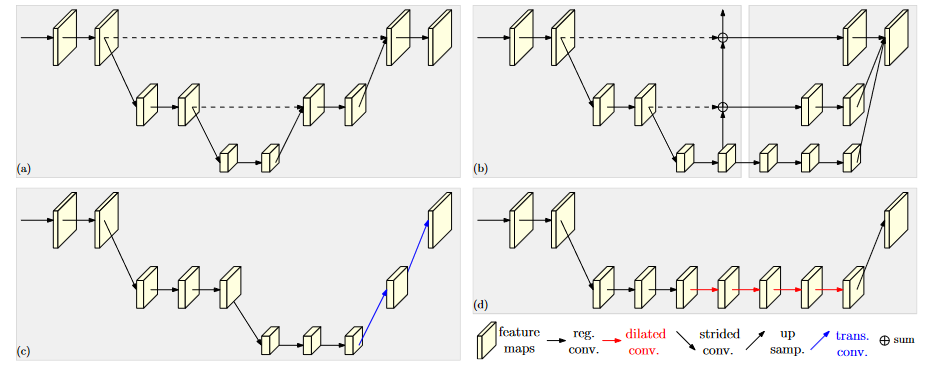
HRNetV1 では、高解像度のコンボリューションを並列に接続し、並列コンボリューション内でマルチスケール フュージョンを繰り返すことで高解像度の表現を維持します。HRNetV1 の概要については、こちらを参照してください: HRNetV1
本論文で提案する HRNetv2 は、HRNetV1 のモデル構造を変更するだけで、より強力な高解像度表現を実現します。異なる解像度の情報を並行して処理すると、結果として得られる特徴はセマンティクスが豊富になり、空間的にはより正確になります。
2.HRNetv2 ジェスチャ認識
-
ネットワーク構造部分では、
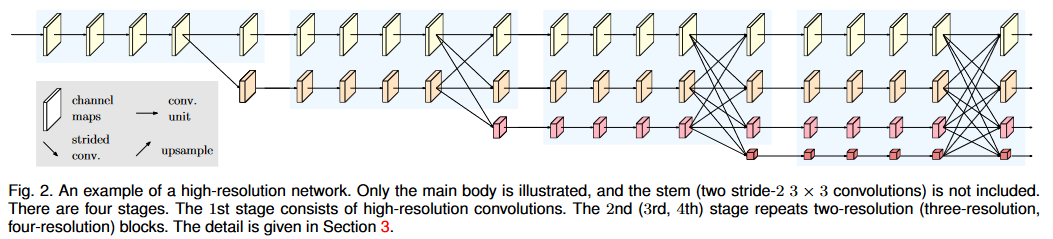
まず画像入力を特徴マップの 4 倍にダウンサンプリングします。水平 conv ブロックは残差単位を参照します。異なる解像度間のマルチクロスライン部分は多重解像度コンボリューションです。この時点では、HRNet V2 と HRNet V1 は基本的に同じです。
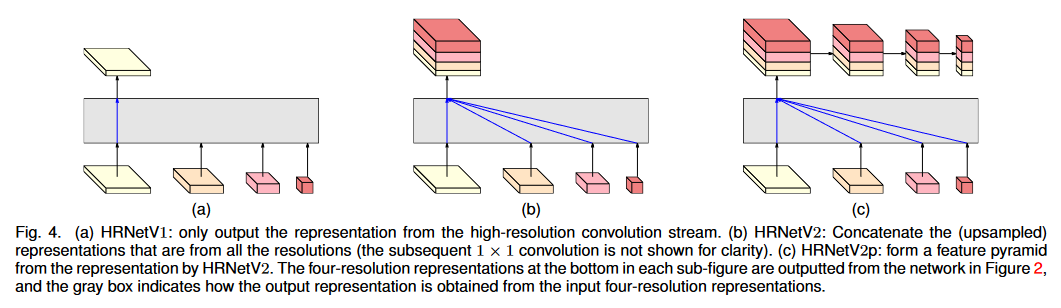
主な違いは、ネットワークに追加されるヘッドです:
(a) 高解像度の特徴マップのみを使用するのは HRNet V1 であり、高解像度ブランチの特徴マップのみを出力し、他の 3 つのブランチの特徴マップは無視されます。
(b) HRNet V2 は、セマンティック セグメンテーションの出力として concat を介して、異なる解像度ブランチの特徴マップを連結します。
(c) 物体検出のために複数のレベルにダウンサンプリングすることにより、HRNetV2 の高解像度表現に基づいてマルチレベルの特徴マップを構築します。
分類用のヘッド
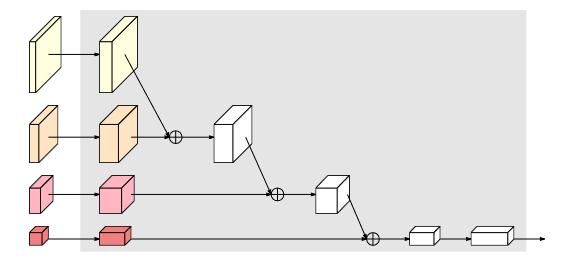
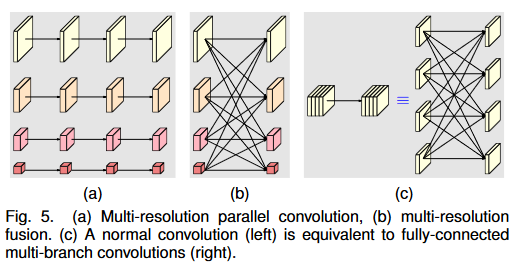
多重解像度並列コンボリューションおよび多重解像度融合モジュール
多重解像度並列コンボリューションは、グループ コンボリューション (a) に似ています。入力チャンネルをいくつかのチャンネルのサブセットに分割し、異なる空間解像度で各サブセットに対して個別に畳み込み演算を実行します。ただし、多重解像度並列畳み込みの異なるサブセット間の解像度は異なりますが、グループ畳み込みの異なるサブセットの解像度は同じです。
マルチ解像度フュージョン モジュールの入力チャンネルと出力チャンネルはいくつかのサブセットに分割されており、入力と出力のサブセットは全結合方式で接続されており、各接続は通常の畳み込みです。出力チャネルの各サブセットは、入力チャネルの各サブセットの畳み込み出力の合計であるため、HRNetv2 にはより多くの空間情報が組み込まれます。
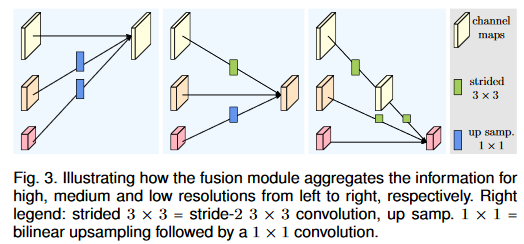
マルチ解像度フュージョンの場合、アップサンプリング、レベリング、ダウンサンプリングが含まれます。ダウンサンプリングには、1 つのレイヤーと複数のレイヤーにわたるダウンサンプリングが含まれます。アップサンプリングには補間が使用され、レベリングには畳み込みが使用されます。ブランチが 2 より大きい場合、ストライド > 1 の複数の畳み込みがダウンサンプリングに使用されます。
つまり、マルチ解像度コンボリューションでは、各チャネルの解像度が異なります。
次に、チャネル間の接続が解像度を下げる場合は 3x3 stride=2 畳み込みが使用され、接続が解像度を上げる場合は双線形最近傍補間アップサンプリングが使用されます。 -
結果の評価
人間の姿勢推定
HRNetV1 と HRNetV2 の結果は類似しており、計算の複雑さは HRNetV1 の方が低いため、この実験では HRNetV1 が選択モデルとして使用されました。トレーニング データセットとテスト データセットの両方で COCO データセットが使用されます。
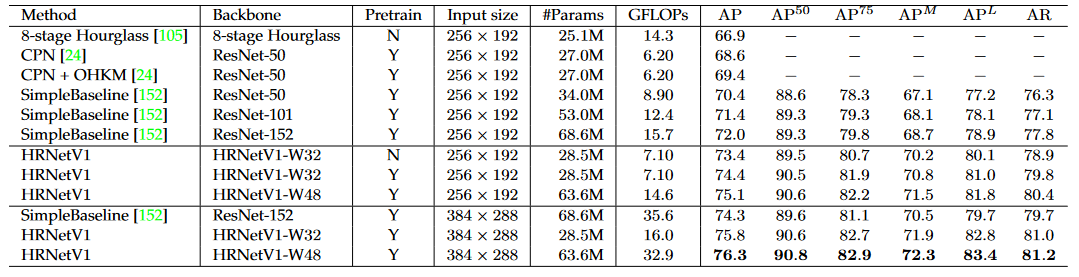
COCO テスト開発データ セットでは、HRNetV1 は既存の方法と比較して、精度、Params、GFLOP の大幅な向上を達成しました。
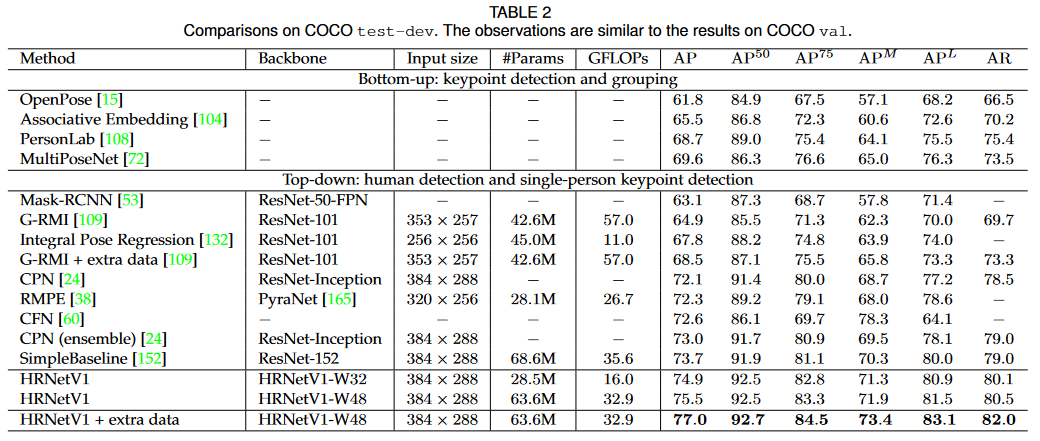
セマンティック セグメンテーションとオブジェクト検出の結果の評価については検討されていません。
アブレーション実験
1. 異なる解像度の特徴マップを使用して
2 つの HRNetV1 ネットワークをトレーニングします。HRNetV1-W32 は人間の姿勢推定に使用され、HRNetV2-W48 はセマンティック セグメンテーションに使用されます。ネットワークは、高解像度から低解像度まで 4 つのフィーチャ マップを出力します。最も低い解像度のフィーチャ マップのヒート マップの予測品質は低すぎるため、表示されません。結果には、他の 3 つのフィーチャ マップの AP スコアが表示されます。
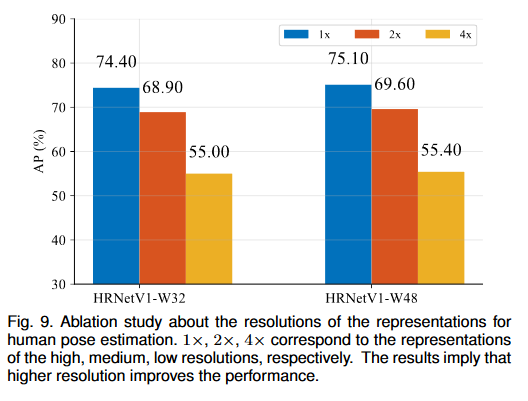
2. 多重解像度フュージョンを繰り返す
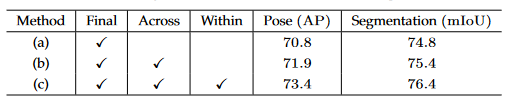
(a) 中間融合モジュールは存在せず、最終融合モジュールのみが存在します。
(b) クロスステージ融合ユニット。各ステージ内の同じ解像度を持つブランチ間の融合はありません。
(c) クロスステージステージおよび最終融合モジュール。
3. 最終的な低解像度特徴マップと高解像度特徴マップの融合に関する比較実験を実施し、HRNetV2 の低解像度並列畳み込みの集合表現により精度が向上することを示します。
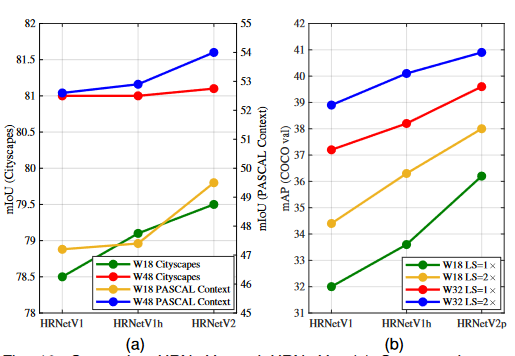
3.HRNetv2ネットワークアーキテクチャ図
