- Este artículo es un resumen de los apuntes sobre la capa de red en el microaula de redes informáticas de la Universidad de Ciencia y Tecnología de Lake , espero que sea de utilidad para todos.
Directorio de artículos
-
- 4.1 Descripción general de la capa de red
- 4.2 Dos servicios proporcionados por la capa de red:
- 4.3 IPv4
-
- 4.3.1 Descripción general de las direcciones IPv4
- 4.3.2 Método de direccionamiento: direcciones IPv4 con direccionamiento con clase
- 4.3.3 Método de direccionamiento: dirección IPv4 dividida en subredes
- 4.3.4 Métodos de direccionamiento: direcciones IPv4 sin direccionamiento con clase
- 4.3.5 Planificación de aplicaciones de direcciones IPv4
- 4.4 Proceso de envío y reenvío de datagrama IP
- 4.5 Configuración de enrutamiento estático y posibles problemas de bucle de enrutamiento
- 4.6 Protocolos de enrutamiento
-
- 4.6.1 Descripción general de los protocolos de enrutamiento
- 4.6.2 Principio de funcionamiento básico del protocolo de información de enrutamiento RIP
- 4.6.3 Principio de funcionamiento básico de Open Shortest Path First OSPF
- 4.6.4 El principio de funcionamiento básico del protocolo de puerta de enlace fronteriza BGP:
- 4.7 El formato de encabezado del datagrama IPv4
- 4.8 Protocolo de mensajes de control de Internet ICMP
- 4.9 VPN de red privada virtual y traducción de direcciones de red NAT
-
4.1 Descripción general de la capa de red
La tarea principal de la capa de red es realizar la interconexión de la red y luego realizar la transmisión de paquetes de datos entre redes.
Para realizar las tareas de la capa de red, es necesario resolver los siguientes problemas:
- Qué tipo de servicio proporciona la capa de red a la capa de transporte (transmisión confiable o transmisión no confiable).
- Problemas de direccionamiento de la capa de red
- problema de enrutamiento
Internet: Actualmente es la Internet con mayor número de usuarios en el mundo, y utiliza la pila de protocolos TCP/IP.
Dado que la capa de red en la pila de protocolos TCP/IP utiliza el protocolo de Internet IP, que es el protocolo central de toda la pila de protocolos, la capa de red en la pila de protocolos TCP/IP a menudo se denomina capa de Internet.

4.2 Dos servicios proporcionados por la capa de red:
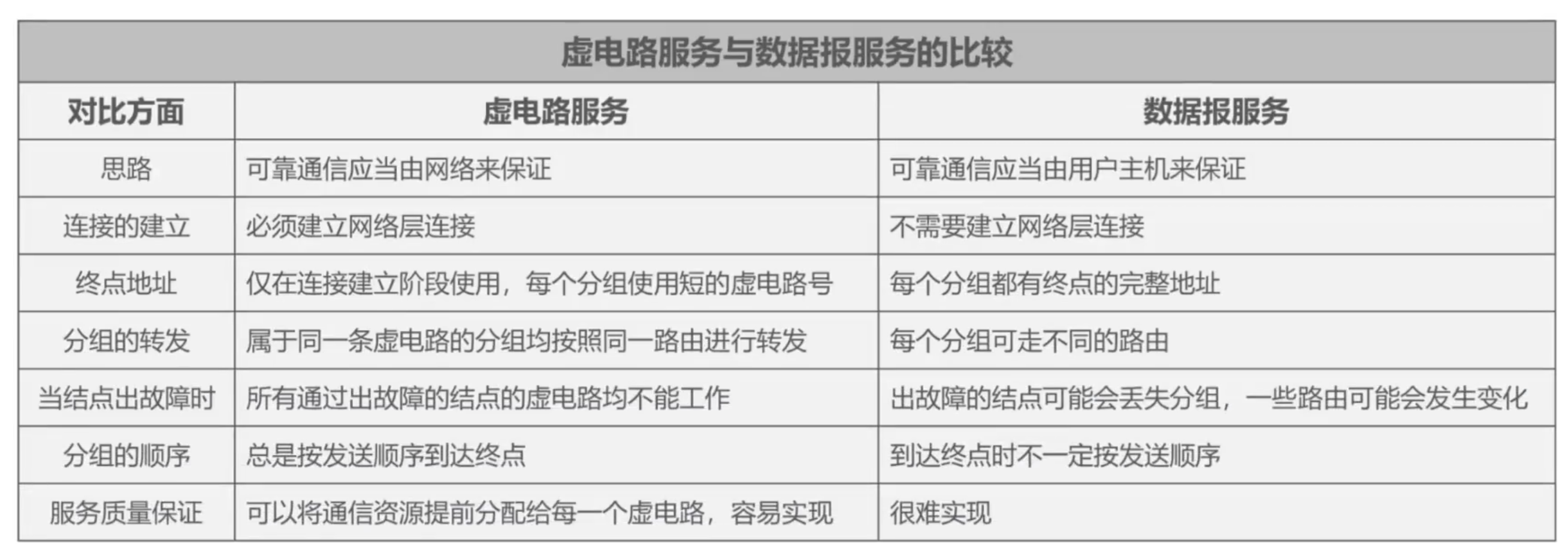
1. Servicio de circuito virtual orientado a conexión
Idea central: la red debe garantizar una comunicación confiable
Cuando dos computadoras se comunican, se debe establecer una conexión en la capa de red, es decir, se establece un circuito virtual y las dos partes envían paquetes a lo largo del circuito virtual.
Un circuito virtual representa una conexión lógica, no una conexión física, que es diferente del método de comunicación que utiliza la conmutación de circuitos.
El encabezado del paquete solo usa la dirección completa del host de destino en la etapa de establecimiento de la conexión, y luego el encabezado de cada paquete solo necesita llevar un número de circuito virtual.
Una vez finalizada la comunicación, es necesario liberar el circuito virtual establecido entre ellos.
Muchas redes de conmutación de paquetes de área amplia utilizan servicios de circuitos virtuales orientados a la conexión, como el anterior X.25 y el Frame Relay FR gradualmente obsoleto, el modo de transferencia asíncrono ATM, etc.
Sin embargo, los pioneros de Internet no adoptaron esta idea de diseño, sino que adoptaron un servicio de datagramas sin conexión.

2. Servicio de datagramas sin conexión
Idea central: el host del usuario debe garantizar una comunicación confiable.
Cuando dos computadoras se comunican, no hay necesidad de establecer una conexión de capa de red y cada paquete puede tomar una ruta diferente.
Cada paquete debe llevar la dirección del host de destino.
Los paquetes transmitidos de esta manera pueden ser incorrectos, perdidos, repetidos o fuera de secuencia.
Dado que la capa de red en sí misma no proporciona servicios de transmisión confiables de extremo a extremo, el enrutador puede ser relativamente simple y económico.
Internet adopta este concepto de diseño, colocando funciones de procesamiento de red complejas en el borde de la red (hosts de usuario y capas de transporte internas) y colocando funciones de entrega de paquetes simples en el centro de Internet. Los beneficios son: costo de red reducido y modo de operación flexible.

4.3 IPv4
4.3.1 Descripción general de las direcciones IPv4
1. Introducción básica
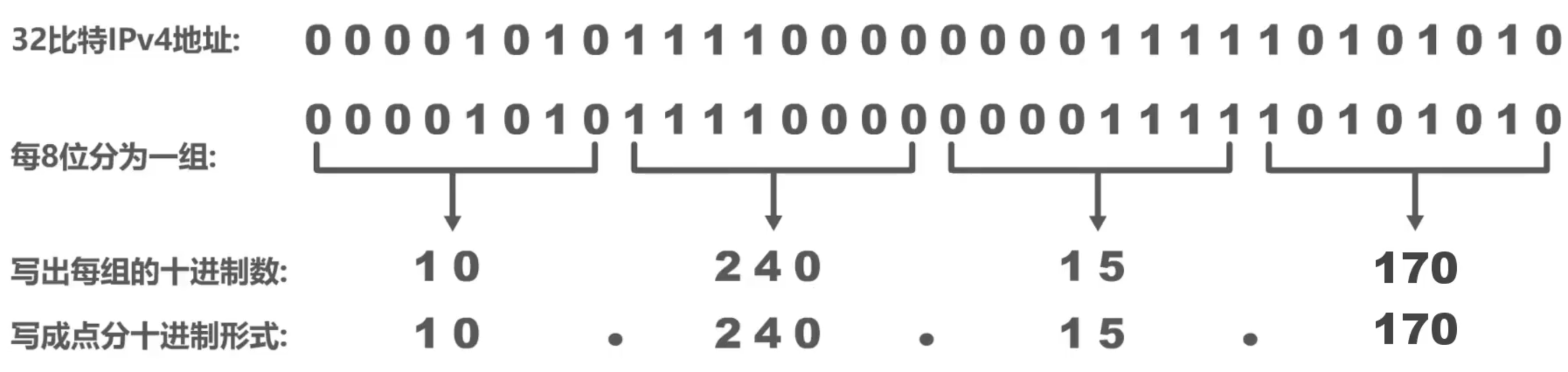
2. Método de representación
La dirección IPv4 de 32 bits es un inconveniente para leer y registrar, por lo que la dirección IPv4 adopta la notación decimal con puntos para comodidad de los usuarios.
Ejemplo:
4.3.2 Método de direccionamiento: direcciones IPv4 con direccionamiento con clase
En cuanto al direccionamiento clasificado, las direcciones IPv4 se dividen en Clase A, Clase B, Clase C, Clase D y Clase E.
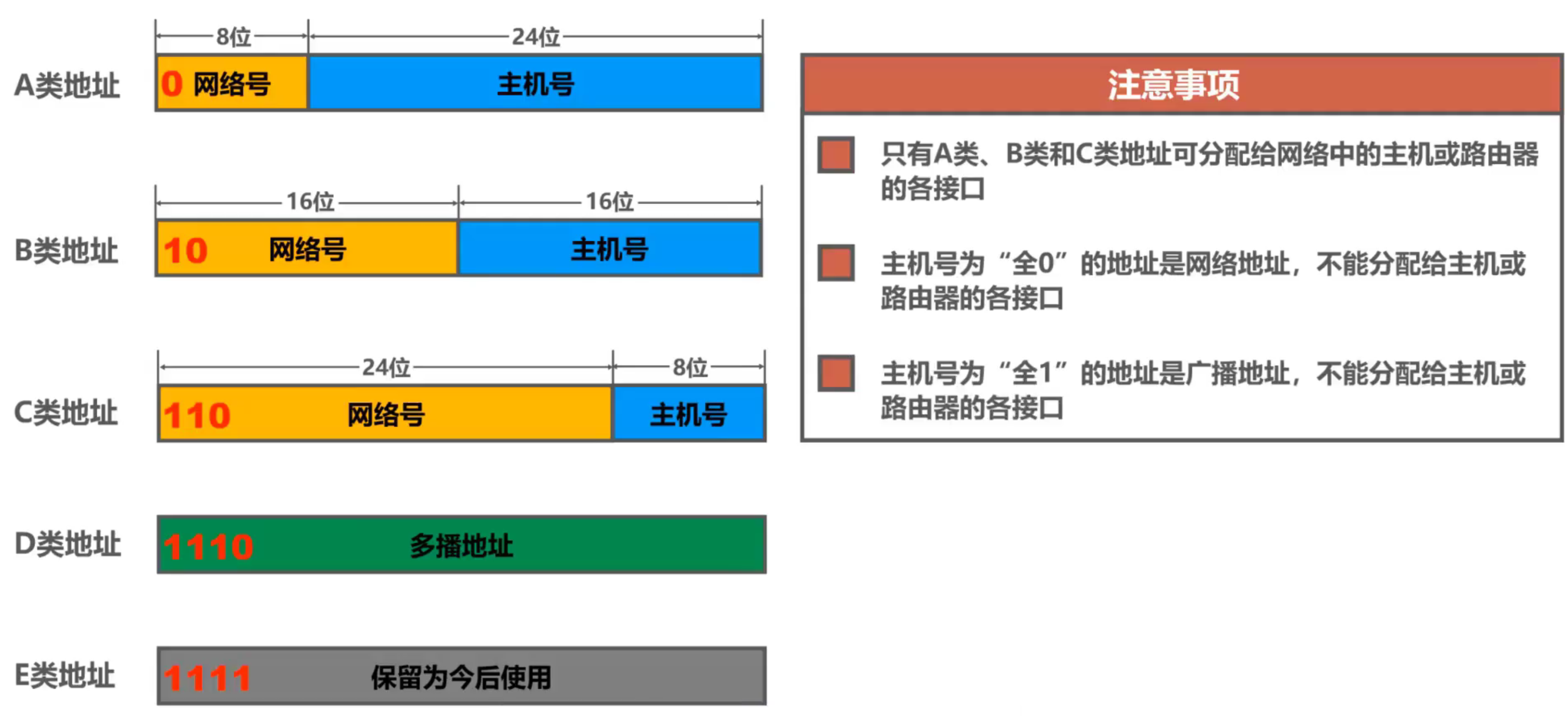
Dirección de clase A:
- El número de red es de 8 bits y el número de host es de 24 bits.
- El bit más alto del número de red se fija en 0 y hay 126 números de red asignables (2 7 -2), la dirección de red más pequeña es 1.0.0.0 y la dirección de red más grande es 126.0.0.0
- Restando todos los ceros, la dirección IP cuyo número de red es todo ceros es una dirección reservada, lo que significa que la red
- Reste la dirección con el número de red 127 para la prueba de bucle invertido de software local, la dirección de prueba de bucle invertido de software local mínima es 127.0.0.1 y la máxima es 127.255.255.254
- El número de hosts que se pueden asignar a cada red es 2 24 -2
- El número de host de todos los 0 indica la dirección de red a la que está conectado el host
- El número de host de todos 1 indica todos los hosts en la red, es decir, la dirección de transmisión
Dirección de clase B:
- El número de red es de 16 bits y el número de host es de 16 bits
- Los dos dígitos inferiores del número de red se fijan en 10, el número de red asignable es 2 14 , la dirección de red mínima es 128.0.0.0 y la dirección de red máxima es 191.255.0.0
- El número de hosts que se pueden asignar a cada red es 2 16 -2
- El número de host de todos los 0 indica la dirección de red a la que está conectado el host
- El número de host de todos 1 indica todos los hosts en la red, es decir, la dirección de transmisión
Dirección de clase C:
- La dirección de red es de 24 bits y el número de host es de 8 bits
- Los primeros 3 dígitos del número de red se fijan en 110, el número de red asignable es 2 21 , la dirección de red mínima es 192.0.0.0 y la dirección de red máxima es 223.255.255.0
- El número de hosts que se pueden asignar a cada red es 2 8 -2
- El número de host de todos los 0 indica la dirección de red a la que está conectado el host
- El número de host de todos 1 indica todos los hosts en la red, es decir, la dirección de transmisión
Ejercicio 1:
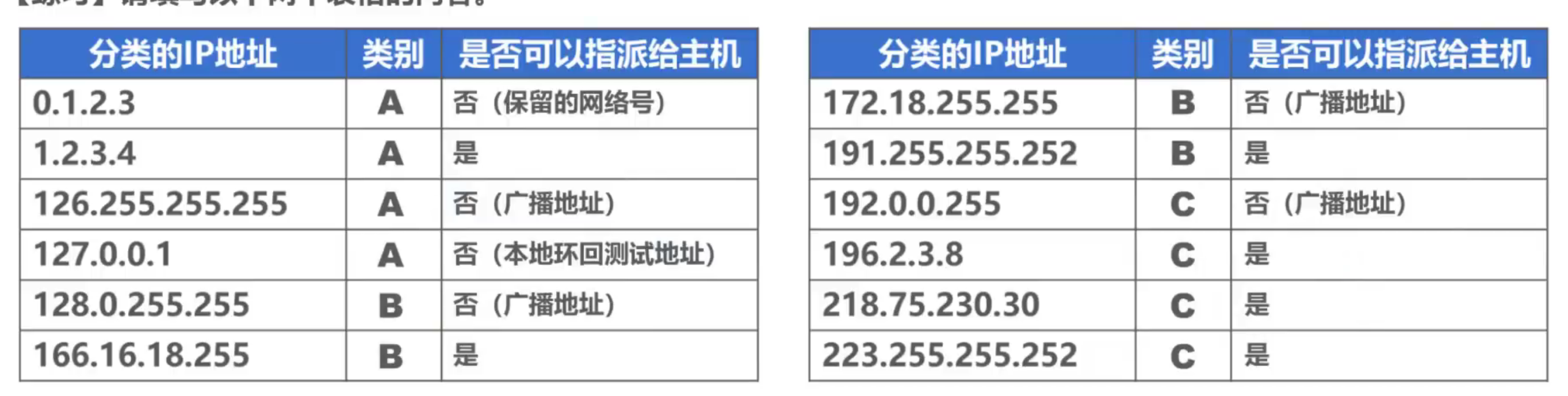
Las direcciones en las siguientes tres situaciones no se pueden asignar a interfaces de host o enrutador:
- Los números de red de Clase A son 0 y 127
- El número de host es todo 0
- El número de anfitrión es todo 1
Ejercicio 2:
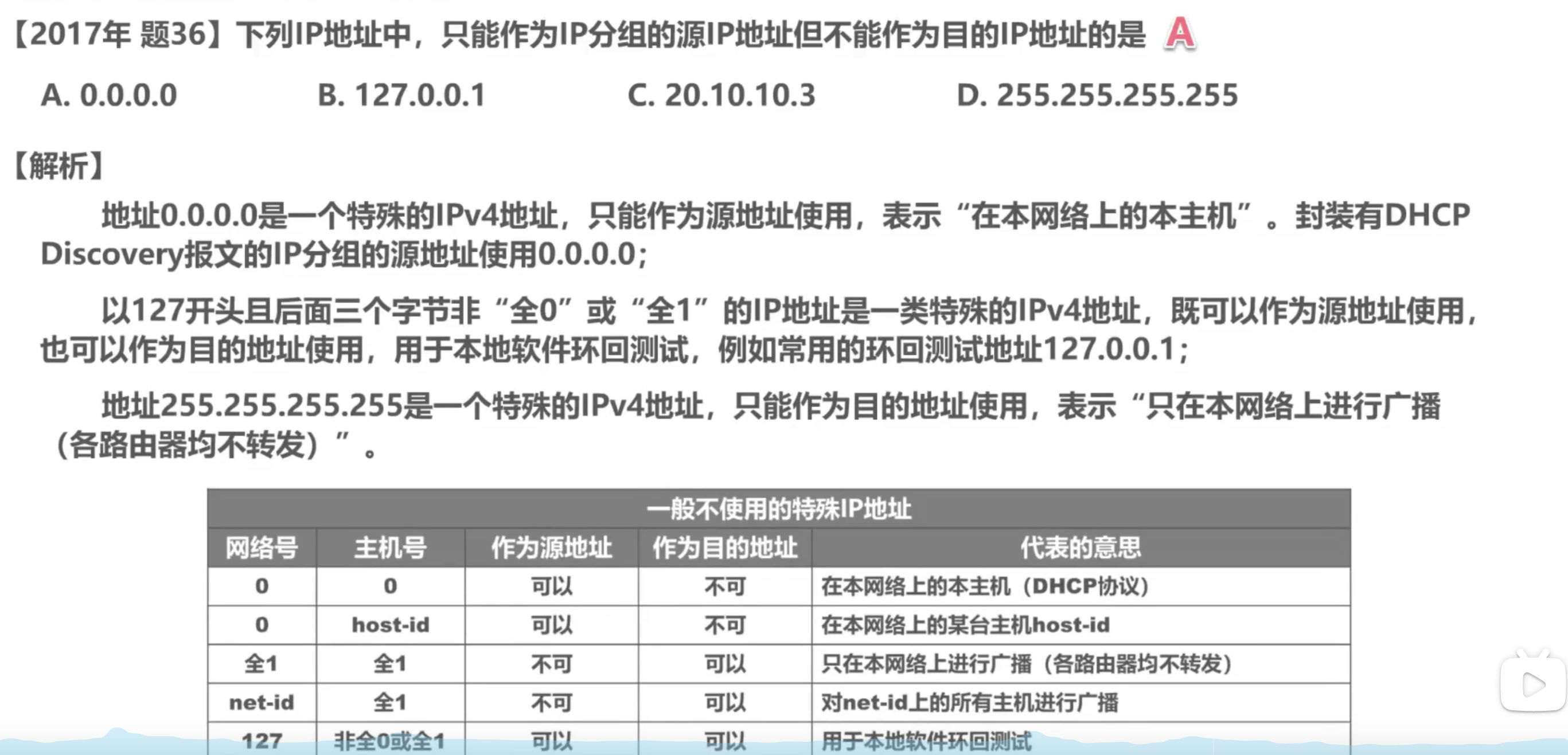
4.3.3 Método de direccionamiento: dirección IPv4 dividida en subredes
1. Razones para dividir en subredes:
- La tasa de utilización del espacio de direcciones IP a veces es muy baja, lo que es fácil de desperdiciar
- Asignar un número de red a cada red hará que la tabla de enrutamiento sea muy grande
- No disponible inmediatamente cuando se necesita una nueva red
2. Una herramienta para dividir en subredes: máscara de subred

Ejemplo uno:
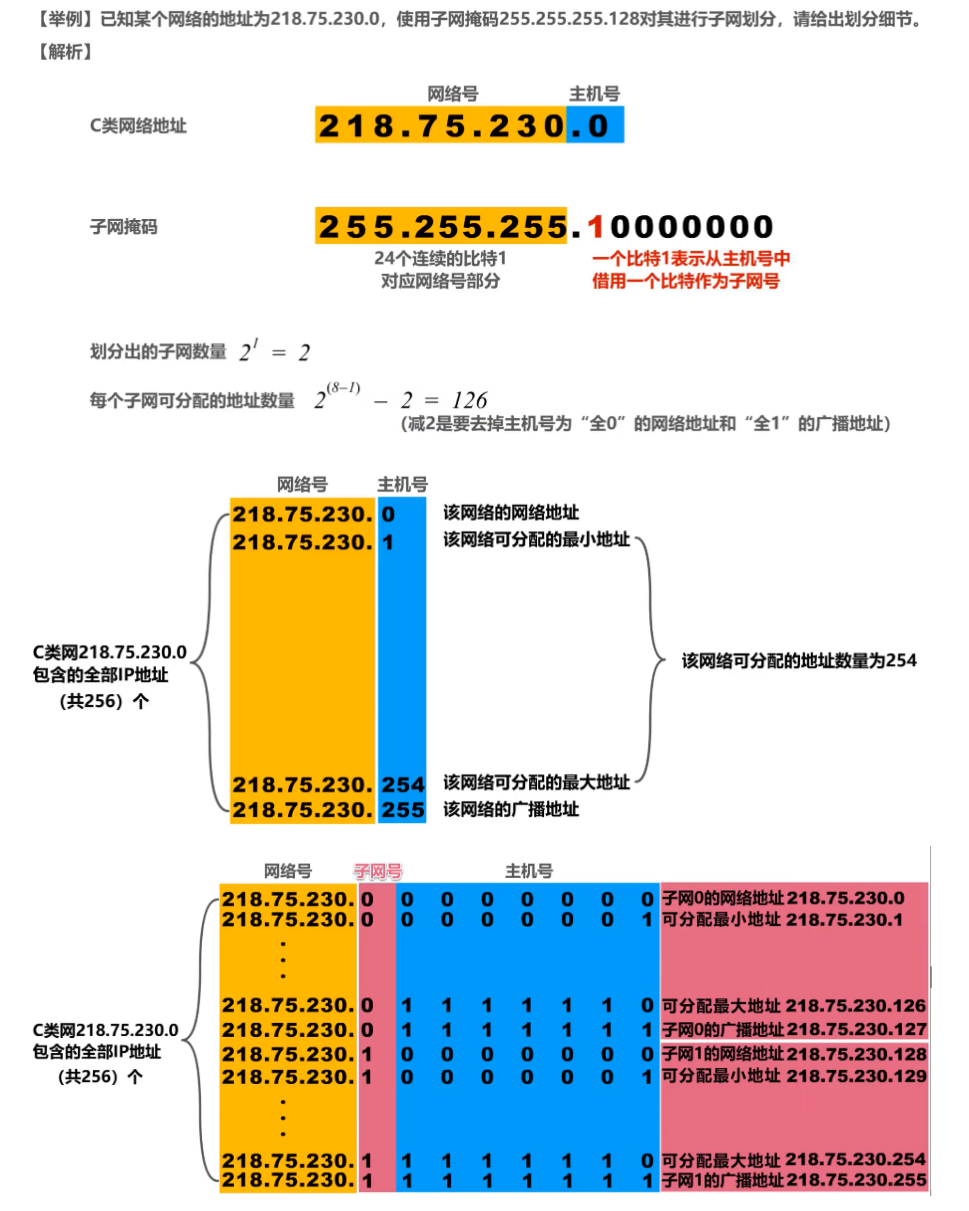
Ejemplo dos:
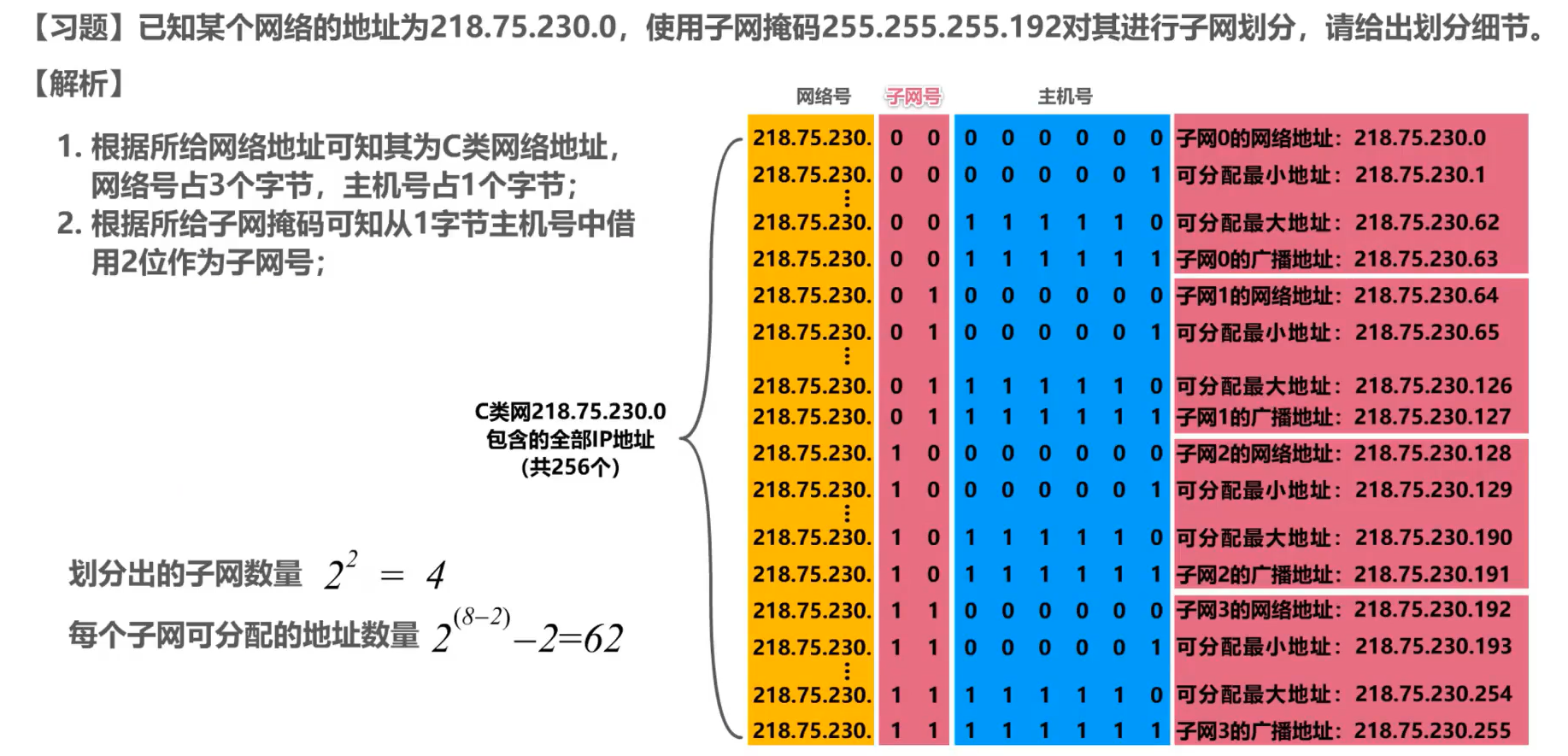
3. Máscara de subred predeterminada:

4.3.4 Métodos de direccionamiento: direcciones IPv4 sin direccionamiento con clase
-
La división de subredes alivia hasta cierto punto las dificultades en el desarrollo de Internet, pero la gran cantidad de redes de Clase C no se utilizan por completo porque su espacio de direcciones es demasiado pequeño . El consumo de direcciones IP en Internet sigue acelerándose, y todo el espacio de direcciones IPv4 enfrenta la amenaza de agotamiento.
-
IETF ha propuesto el método de utilizar direccionamiento no clasificado para resolver el problema de escasez de direcciones IP.
-
CIDR de enrutamiento entre dominios sin clases:
- Elimina las direcciones de clase A, clase B y clase C, y el concepto de división en subredes.
- El espacio de direcciones IPv4 se puede asignar de manera más efectiva.
1. Anotación de la dirección CIDR:

Ejemplo:

2. Agregación de rutas:

Ejercicio 1:

Ejercicio 2:

4.3.5 Planificación de aplicaciones de direcciones IPv4
-
Dado un bloque de direcciones IPv4, cómo dividirlo en varios bloques de direcciones más pequeños y asignar estos bloques de direcciones a diferentes redes en Internet, y luego asignar direcciones IPv4 a hosts e interfaces de enrutadores en cada red.
-
Hay dos formas de dividir la dirección:
- Use una máscara de subred de longitud fija
- Use una máscara de subred de longitud variable
1. Máscara de subred de longitud fija:

Anteriormente, la división en subredes de las direcciones IPv4 se obtenía mediante máscaras de subred de longitud fija.
Por ejemplo:
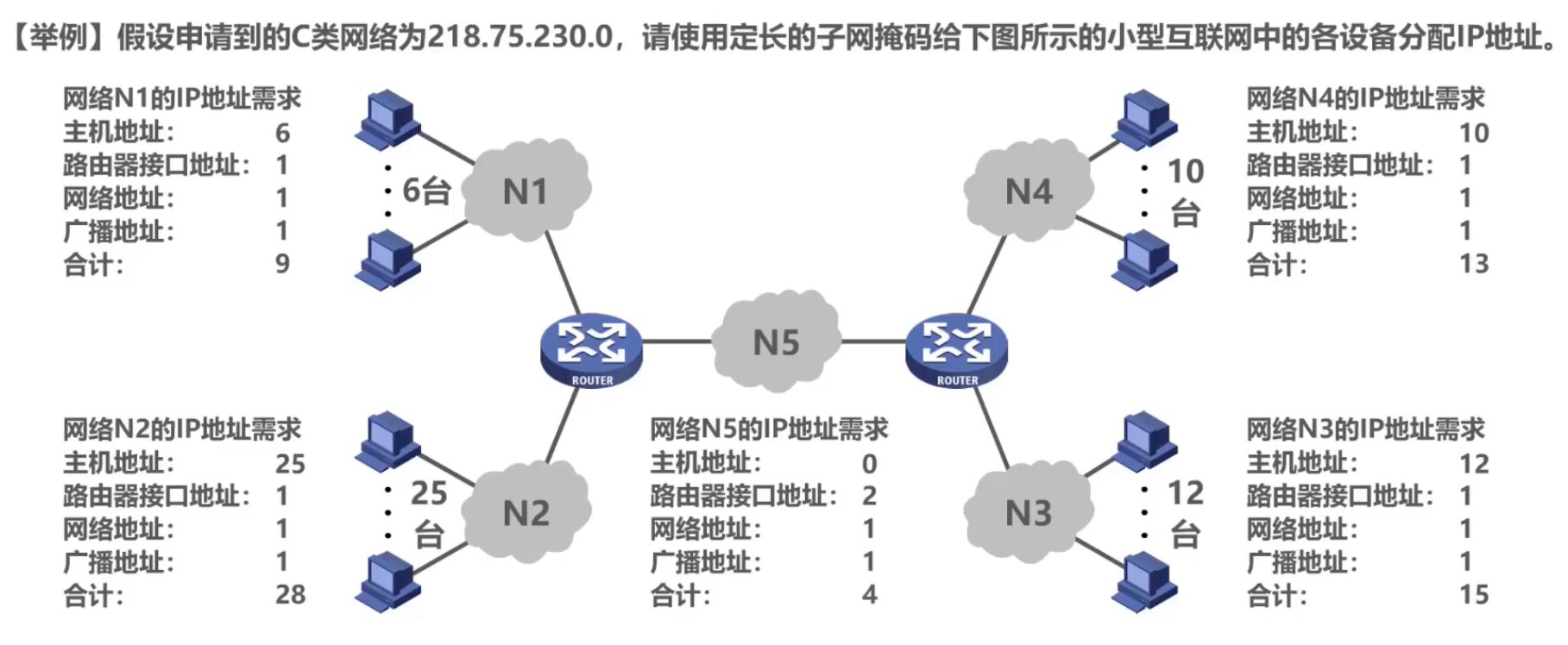
Hay 5 redes en la figura, por lo que se requieren los primeros 3 dígitos del 4.° byte de la red 218.75.230.0 como número de subred.
Aquí está el resultado de dividir los 3 bits en 8 subredes:
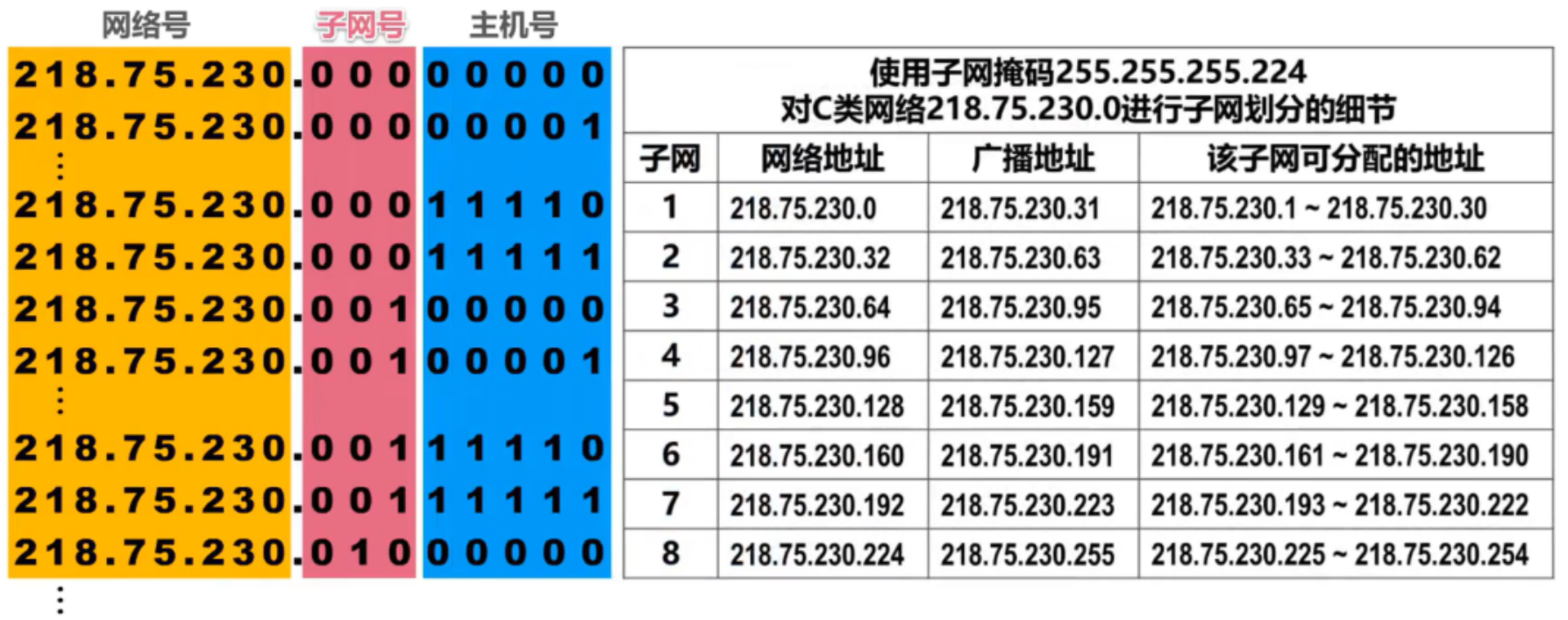
Cada subred dividida de esta manera tiene la misma cantidad de hosts, lo cual es un desperdicio para subredes que no necesitan tantos hosts.
2. Máscara de subred de longitud variable

El método de direccionamiento no clasificado se obtiene utilizando máscaras de subred de longitud variable.
Ejemplo:
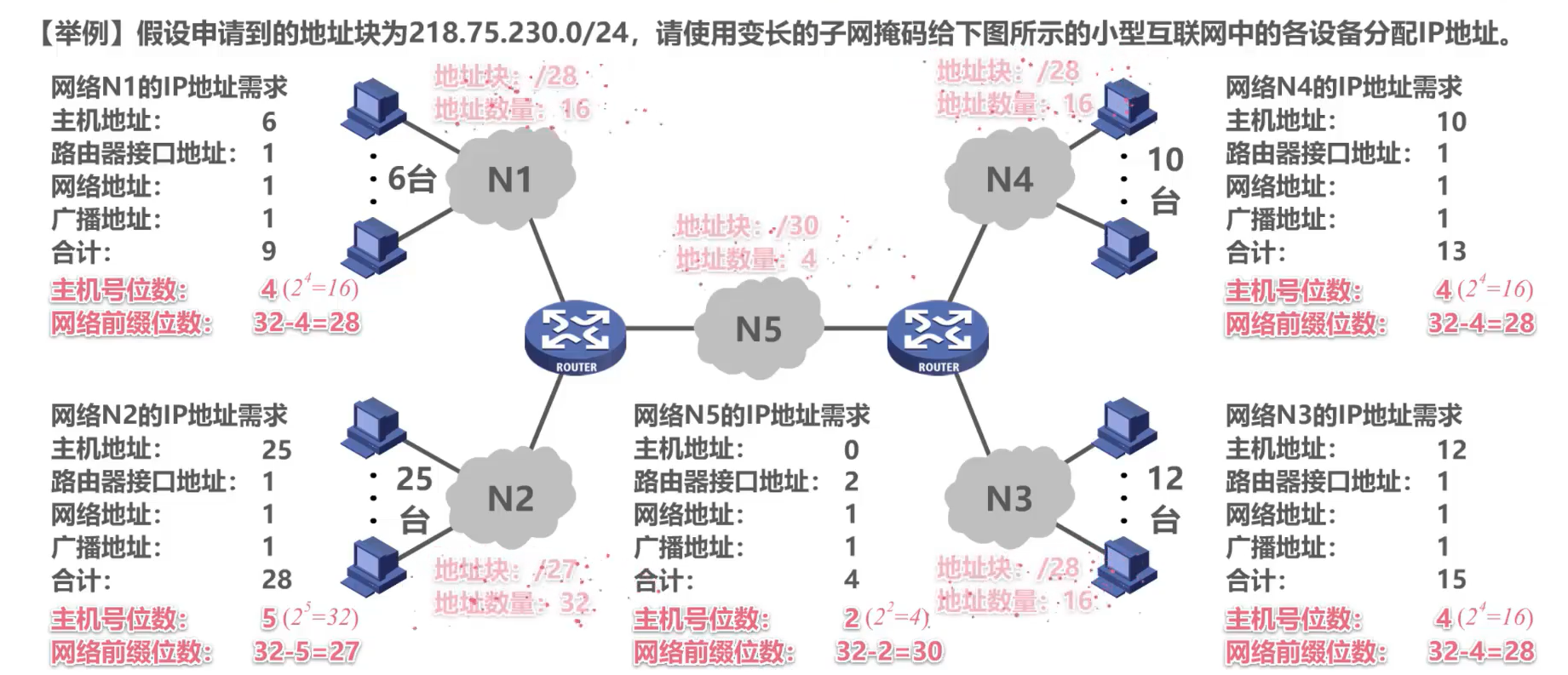
La distribución es la siguiente:
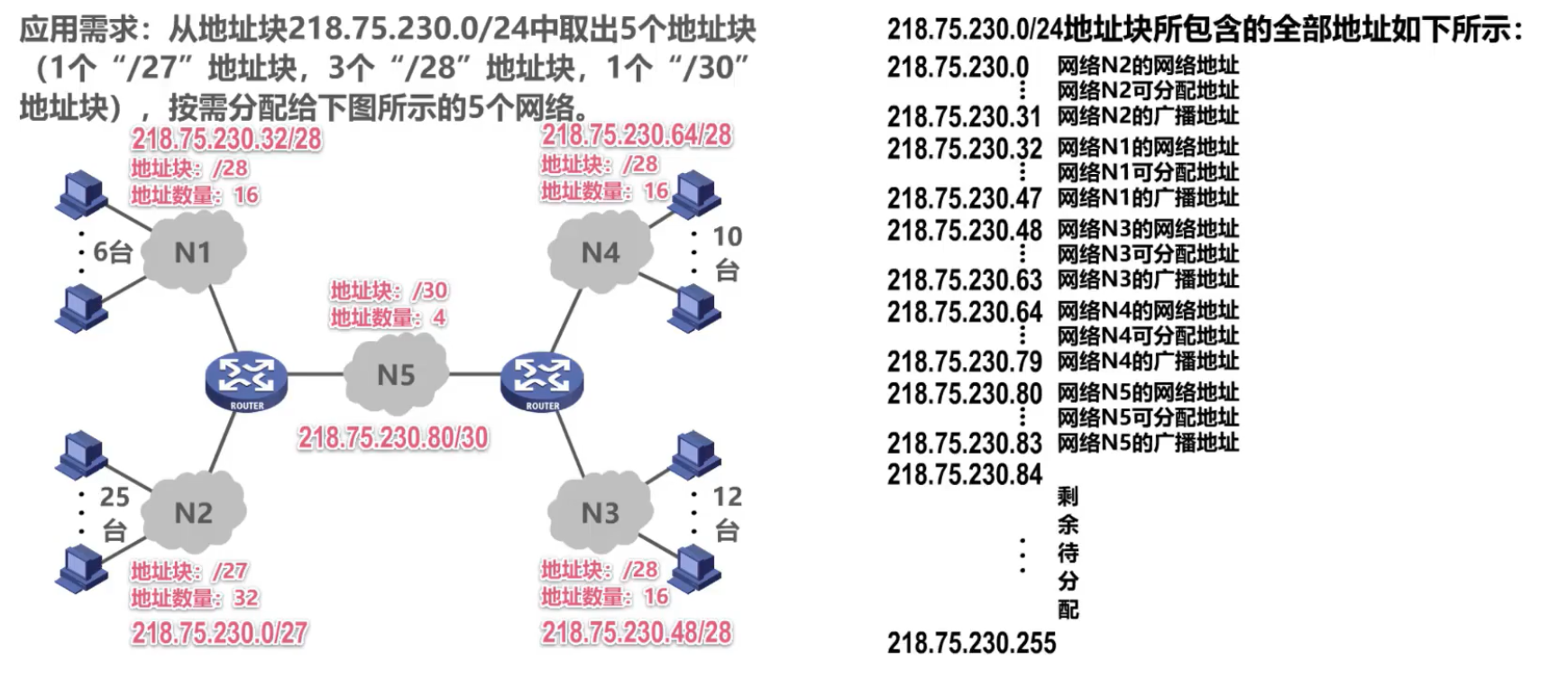
4.4 Proceso de envío y reenvío de datagrama IP
-
El proceso de envío y reenvío de un datagrama IP consta de las dos partes siguientes:
- Host envía datagrama IP
- El enrutador reenvía el datagrama IP

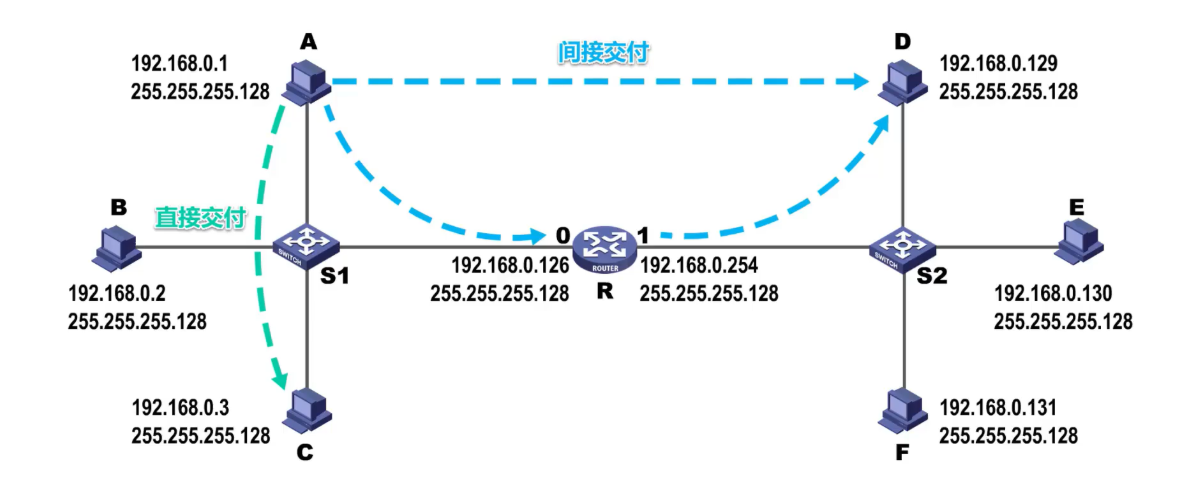
Entonces, ¿cómo sabe el host de origen si el host de destino está en la misma red que él?

Compare la dirección IP del host con la máscara de subred del host para obtener la dirección de red del host, compare la dirección IP de destino con la máscara de subred del host para obtener la dirección de red de destino y compare la dirección de red del host de origen con la dirección de red de destino:
- Si es igual, significa en la misma red, entrega directa
- Si no son iguales, significa que la red es diferente, que pertenece a la entrega indirecta, y el datagrama se reenvía a la puerta de enlace predeterminada, y el reenvío se reemplaza por la puerta de enlace predeterminada.
Entonces, ¿cómo sabe el host C a qué enrutador debe entregar?
Puerta de enlace predeterminada: el enrutador asignado a un host se denomina puerta de enlace predeterminada.

Cuando el host quiera comunicarse con hosts en otras redes, transmitirá el datagrama IP a la puerta de enlace predeterminada y la puerta de enlace predeterminada lo reenviará.
Después de comparar la dirección de destino con la máscara de subred y determinar que no es la misma red, el host reenviará el datagrama a la puerta de enlace predeterminada.Después de que el enrutador donde se encuentra la puerta de enlace predeterminada reciba el datagrama:
- Primero verifique si hay un error en el encabezado del datagrama IP
- Si ocurre un error, el datagrama se descarta y se notifica al host
- Si no hay error, adelante
- Luego busque una entrada coincidente en la tabla de enrutamiento según la dirección de destino del datagrama IP :
- Si lo encuentra, reenvía al siguiente salto indicado en la entrada
- Si no lo encuentra, deséchelo y notifíquelo al host de origen.
El proceso de búsqueda del enrutador es el siguiente:
- Primero extraiga el campo de dirección de origen y el campo de dirección de destino del encabezado del datagrama IP
- La dirección IP de destino se compara con la máscara de dirección para obtener la dirección de red de destino y luego se determina si es igual al campo de dirección de red de destino correspondiente en la tabla de enrutamiento.
Aquí hay unos ejemplos:
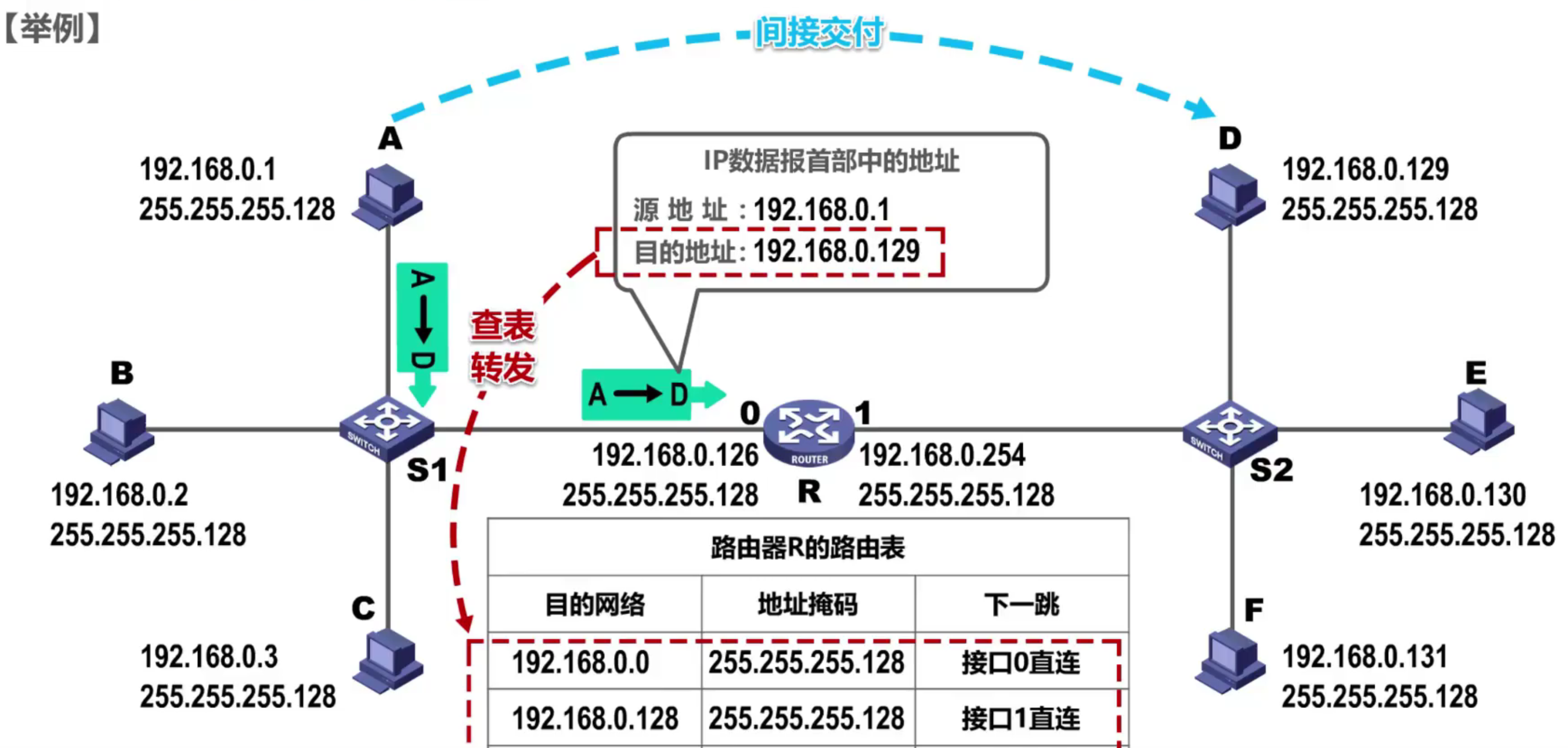
El primer registro: la dirección de red 192.168.0.129 se obtiene después de combinar la dirección de destino 192.168.0.129 con la máscara 255.255.255.128, que es diferente de la dirección de red de destino correspondiente en la tabla de enrutamiento.
El segundo registro: la dirección de destino 192.168.0.129 y la máscara 255.255.255.128 se combinan para obtener la dirección de red 192.168.0.129, que es la misma que la dirección de red de destino correspondiente en la tabla de enrutamiento, por lo que el enrutador sabe que debe reenviar a través de la interfaz 1.
La tabla de enrutamiento mencionada anteriormente solo tiene la configuración de la red conectada directamente y otros registros de red obtenidos dinámicamente por el enrutador, etc., que deben aprenderse más adelante.
La tabla de enrutamiento no reenvía datagramas IP de difusión.
4.5 Configuración de enrutamiento estático y posibles problemas de bucle de enrutamiento
- La configuración de enrutamiento estático significa que los usuarios o los administradores de red usan comandos relacionados con el enrutador para configurar manualmente las tablas de enrutamiento para los enrutadores.
- Este método de configuración manual es simple y tiene una sobrecarga baja, pero no puede adaptarse a los cambios en el estado de la red (tráfico, topología, etc.) en el tiempo, y generalmente solo se usa en redes de pequeña escala.
El uso de la configuración de enrutamiento estático puede causar errores de bucle de enrutamiento:
- Error de configuración
- redes agregadas que no existían
- falla de red
1. Configuración de enrutamiento estático
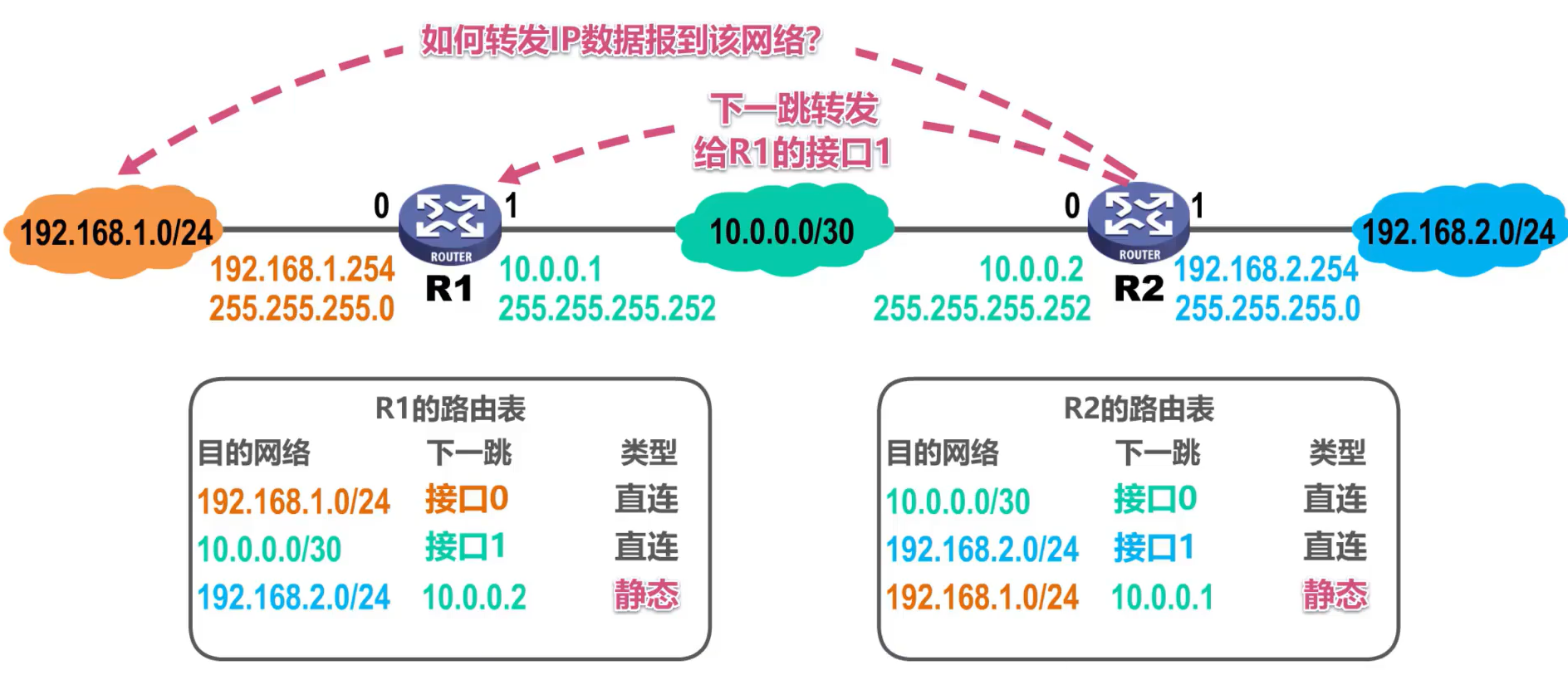
(1) Ruta por defecto
Si un enrutador quiere reenviar datagramas a otras redes en Internet, esto requiere que la tabla de enrutamiento del enrutador tenga entradas para las redes correspondientes. Si agregamos entradas manualmente para estas redes, requerirá una gran cantidad de trabajo y hará que la tabla de enrutamiento sea muy grande. En este momento, para enrutar entradas de diferentes redes de destino con el mismo siguiente salto, se puede usar una ruta predeterminada en su lugar.
La dirección de red de destino de la ruta predeterminada es 0.0.0.0 y su formato CIDR es 0.0.0.0/0.
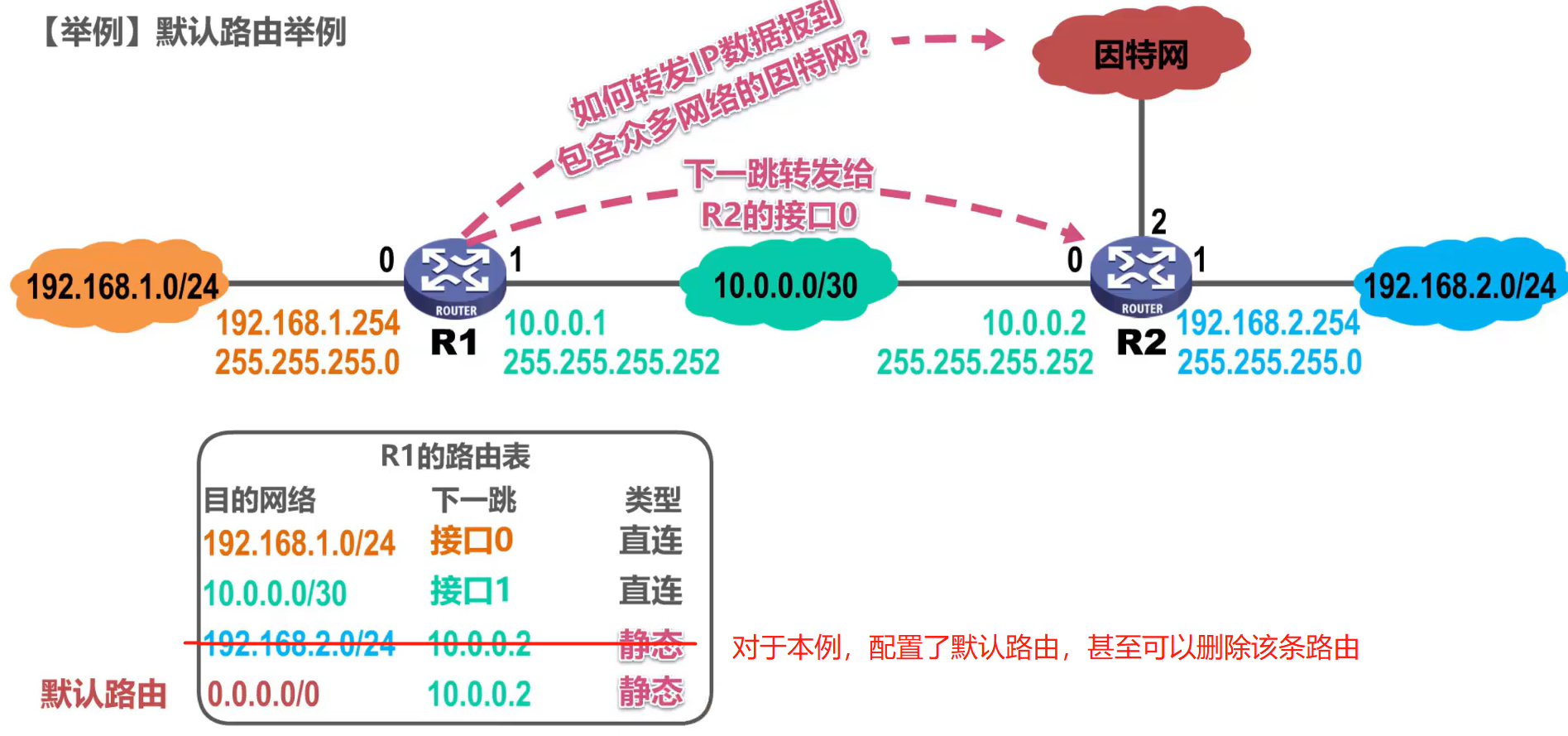
(2) Enrutamiento de host específico
A veces, podemos agregar una entrada de enrutamiento específica del host para un host al enrutador, que generalmente usan los administradores de red para administrar y probar la red.
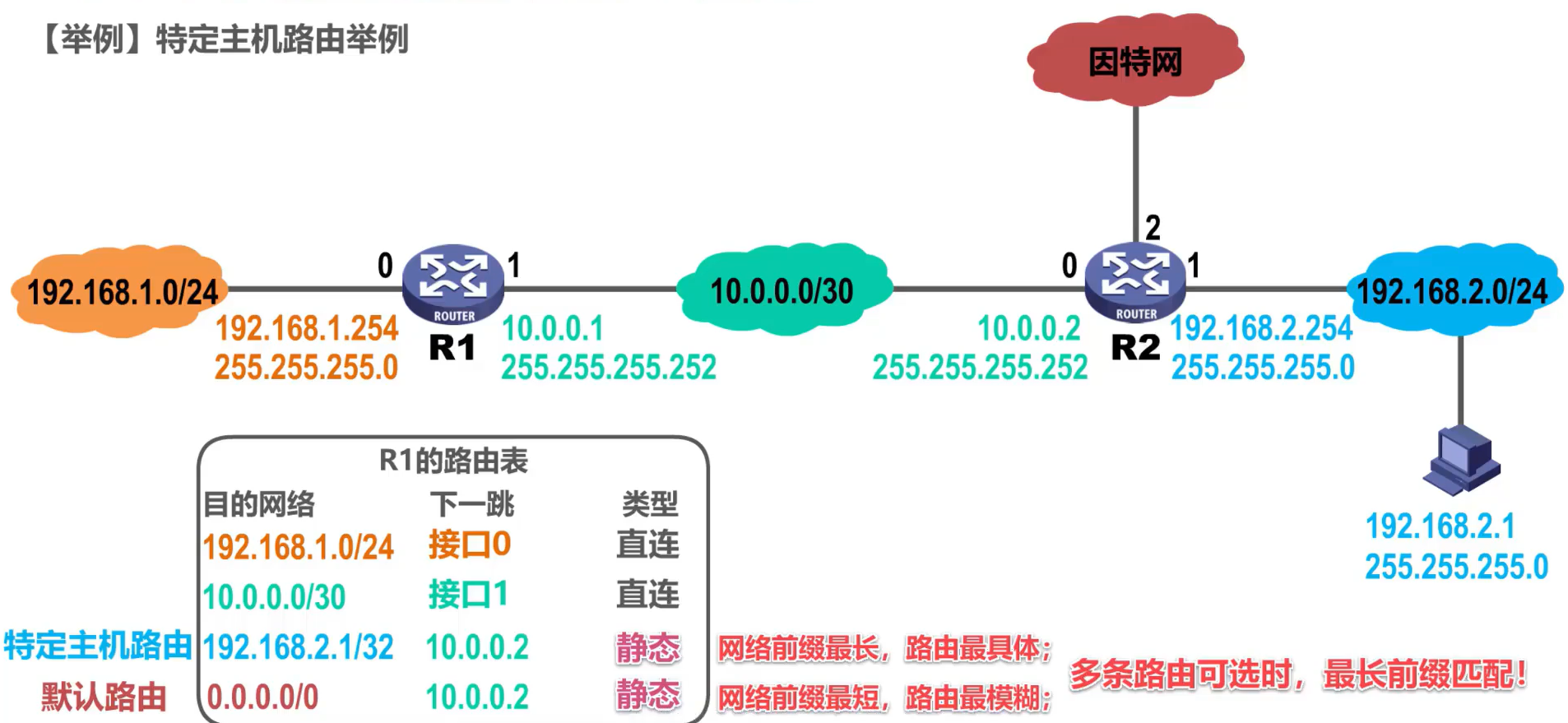
Cabe señalar que el número de red de una ruta de host específica es 32
2. Problema de bucle de enrutamiento causado por enrutamiento estático
Caso 1: error de configuración
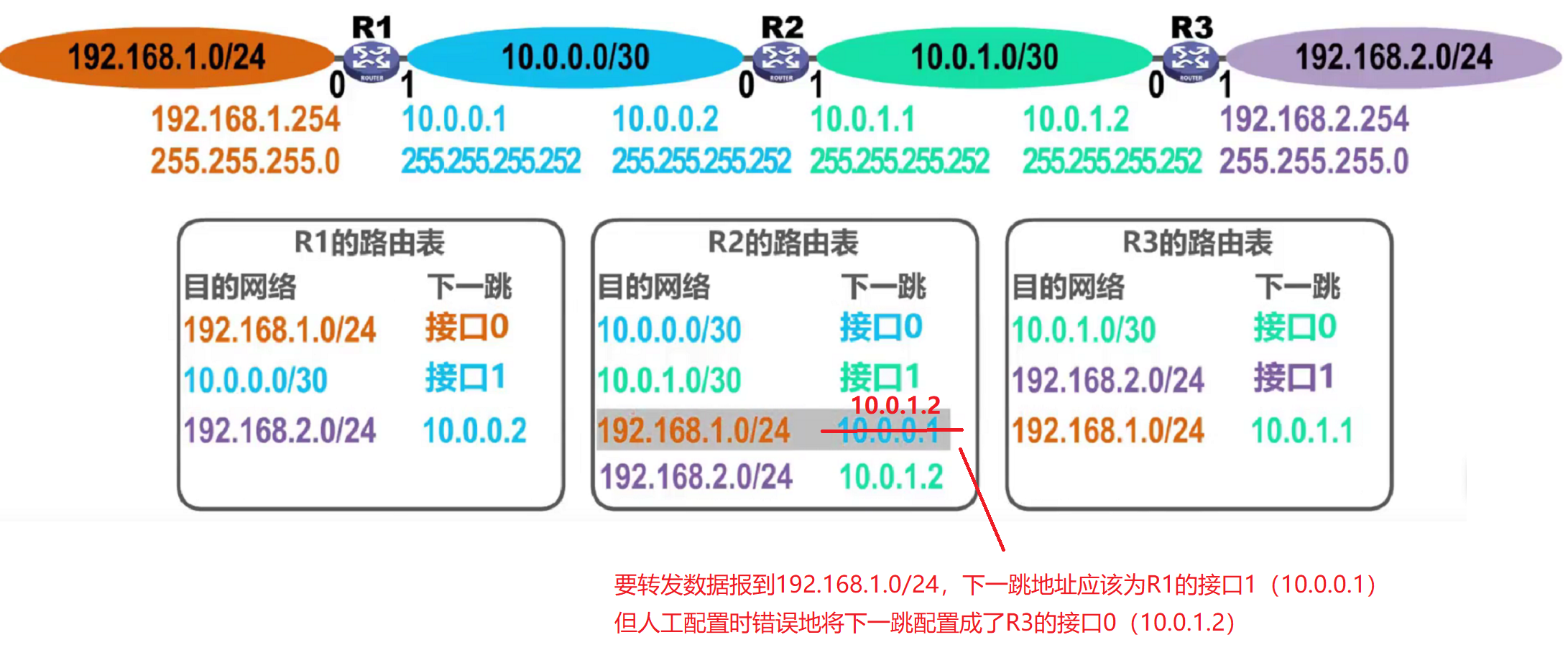
Cuando R2 recibe el datagrama cuya red de destino es 192.168.1.0, lo reenvía a la interfaz 0 de R3 de acuerdo a la tabla de enrutamiento, luego de recibir el datagrama, R3 reenvía el datagrama a la interfaz 1 de R2 de acuerdo a la tabla de enrutamiento, de esta manera el datagrama es reenviado circularmente entre R2 y R3, es decir se genera un loop de enrutamiento .
Para evitar que el datagrama IP circule permanentemente en el bucle de enrutamiento, se establece un campo TTL de tiempo de vida en el encabezado del datagrama IP . Después de que el datagrama IP ingresa al enrutador, el valor TTL se reduce en 1. Si el TTL no es igual a 0, el enrutador lo reenviará, de lo contrario, se descartará.
Caso 2: Agregación de redes inexistentes
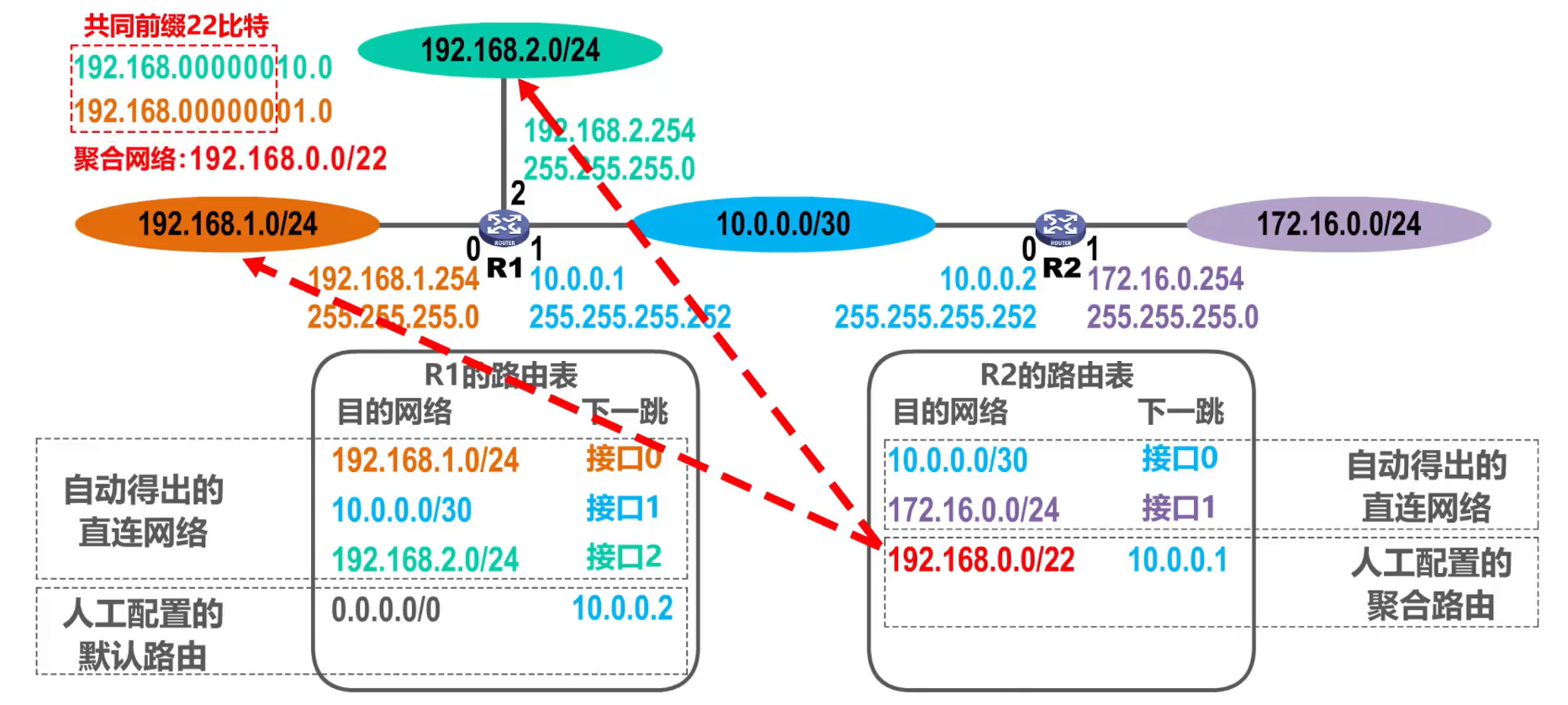
De hecho, la red 192.168.0.0/22 contiene cuatro redes:
- 192.168.0.0/24
- 192.168.1.0/24
- 192.168.2.0/24
- 192.168.3.0/24
Cuando la red de destino del datagrama reenviado por R2 es 192.168.3.0 (que no existe en la topología de red anterior), R2 compara el tercer elemento en la tabla de enrutamiento y reenvía el datagrama a la interfaz 1 de R1. Después de recibir el datagrama, R1 selecciona la ruta predeterminada para reenviar después de verificar la tabla de enrutamiento y reenvía el datagrama a R2. De esta manera, el datagrama se reenvía circularmente entre R1 y R2, lo que genera un problema de bucle de enrutamiento.
Solución:
En la tabla de enrutamiento de R2, agregue una ruta de agujero negro para la red agregada no existente El siguiente salto de la ruta de agujero negro es null0 , que es una interfaz virtual dentro del enrutador, lo que equivale a que el enrutador descarte el datagrama IP de la dirección de red.

En este momento, si R2 recibe un datagrama cuya red de destino es 192.168.3.0, puede hacer coincidir dos registros en la tabla de enrutamiento: las entradas tercera y cuarta, pero de acuerdo con el principio de coincidencia de prefijo más largo, el enrutador seleccionará la cuarta entrada para el reenvío.
Caso 3: falla de la red
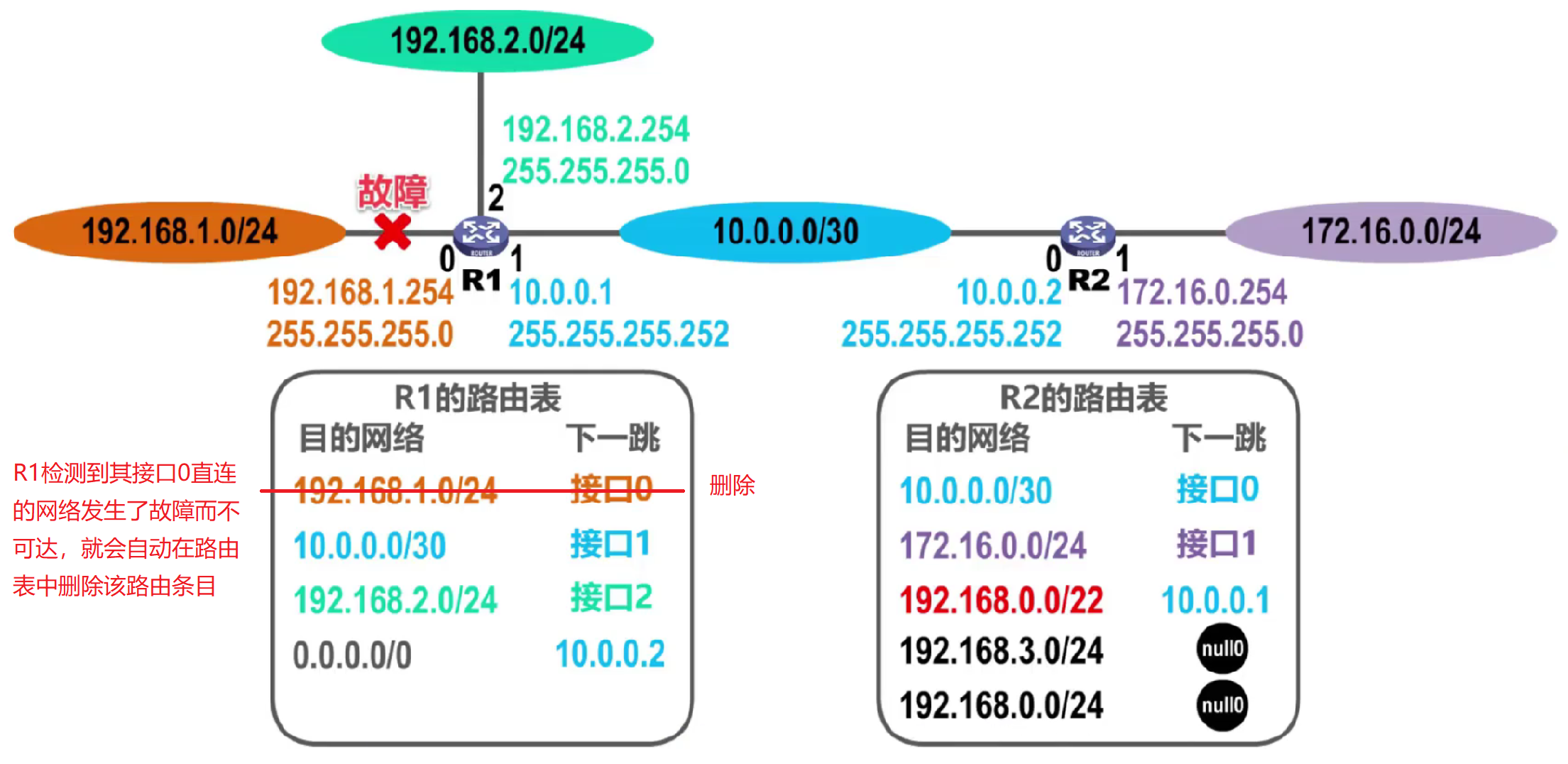
Si R2 quiere reenviar el datagrama cuya red de destino es 192.168.1.0/24, reenviará el datagrama a la interfaz 1 de R1. Después de recibir el datagrama, R1 consulta la tabla de enrutamiento, selecciona la ruta predeterminada y reenvía el datagrama a la interfaz 0 de R2. De esta manera, el datagrama se reenvía circularmente entre R1 y R2, lo que genera un problema de bucle de enrutamiento.
Solución:
En la tabla de enrutamiento de R1, agregue una ruta de agujero negro para la red conectada directamente , de modo que R1 no reenvíe el datagrama cuya red de destino es esta red.
Si desaparece la falla anterior , R1 obtiene automáticamente la entrada de enrutamiento de la red conectada directamente de su interfaz 0 y establece la entrada de enrutamiento del agujero negro cultivado artificialmente en un estado no válido.
4.6 Protocolos de enrutamiento
4.6.1 Descripción general de los protocolos de enrutamiento
(1) El enrutamiento se puede dividir en enrutamiento estático y enrutamiento dinámico:
- Enrutamiento estatico:
- Hace referencia a rutas de red específicas configuradas manualmente, rutas predeterminadas, rutas de host específicas, rutas de agujero negro, etc. Para obtener más información, consulte la sección 4.5 anterior
- El método de configuración manual es simple y la sobrecarga es pequeña. No se puede adaptar a los cambios de estado de la red a tiempo
- Generalmente solo se usa en redes de pequeña escala
- Enrutamiento dinámico:
- Se refiere a la adquisición automática de información de enrutamiento a través de protocolos de enrutamiento.
- Es más complicado, tiene una gran sobrecarga y puede adaptarse mejor a los cambios de la red.
- Adecuado para redes a gran escala
(2) El protocolo de enrutamiento adoptado por Internet tiene las siguientes tres características:
- Adaptativo : significa que Internet adopta un enrutamiento dinámico, que puede adaptarse mejor a los cambios en el estado de la red.
- Distribuido : se refiere al intercambio de información de enrutamiento entre enrutadores.
- Jerarquía : Dividir todo Internet en muchos sistemas autónomos más pequeños AS (Sistema Autónomo), por ejemplo, un gran proveedor de servicios de Internet se puede dividir en un sistema autónomo.
(3) Internet adopta un protocolo de enrutamiento jerárquico:
El enrutamiento entre sistemas autónomos se denomina enrutamiento entre dominios y se selecciona el protocolo de enrutamiento de la categoría Protocolo de puerta de enlace exterior (EGP) .
El enrutamiento dentro del sistema autónomo se denomina enrutamiento intradominio , y se selecciona el protocolo de enrutamiento de la categoría IGP del protocolo de puerta de enlace interior .
Hoy en día, el Protocolo de puerta de enlace exterior EGP también se conoce como Protocolo de enrutamiento exterior ERP, y el Protocolo de puerta de enlace interior IGP también se conoce como Protocolo de enrutamiento interior IRP.
Los protocolos de puerta de enlace interior seleccionados por los dos sistemas autónomos no necesitan ser consistentes.
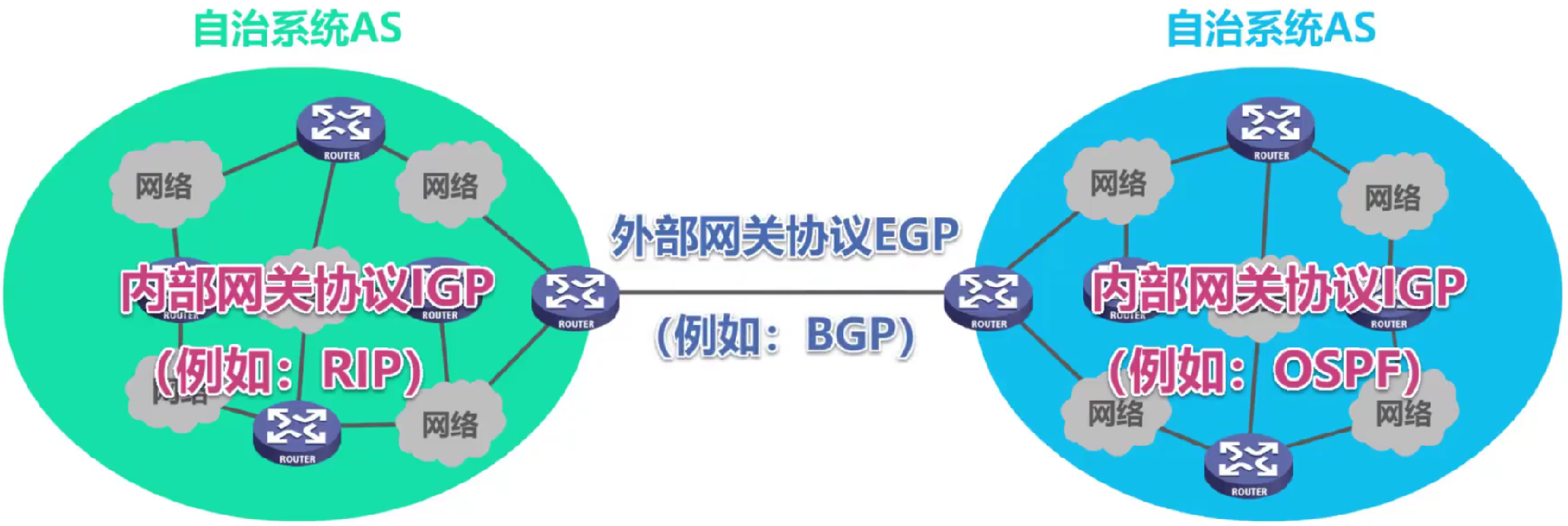
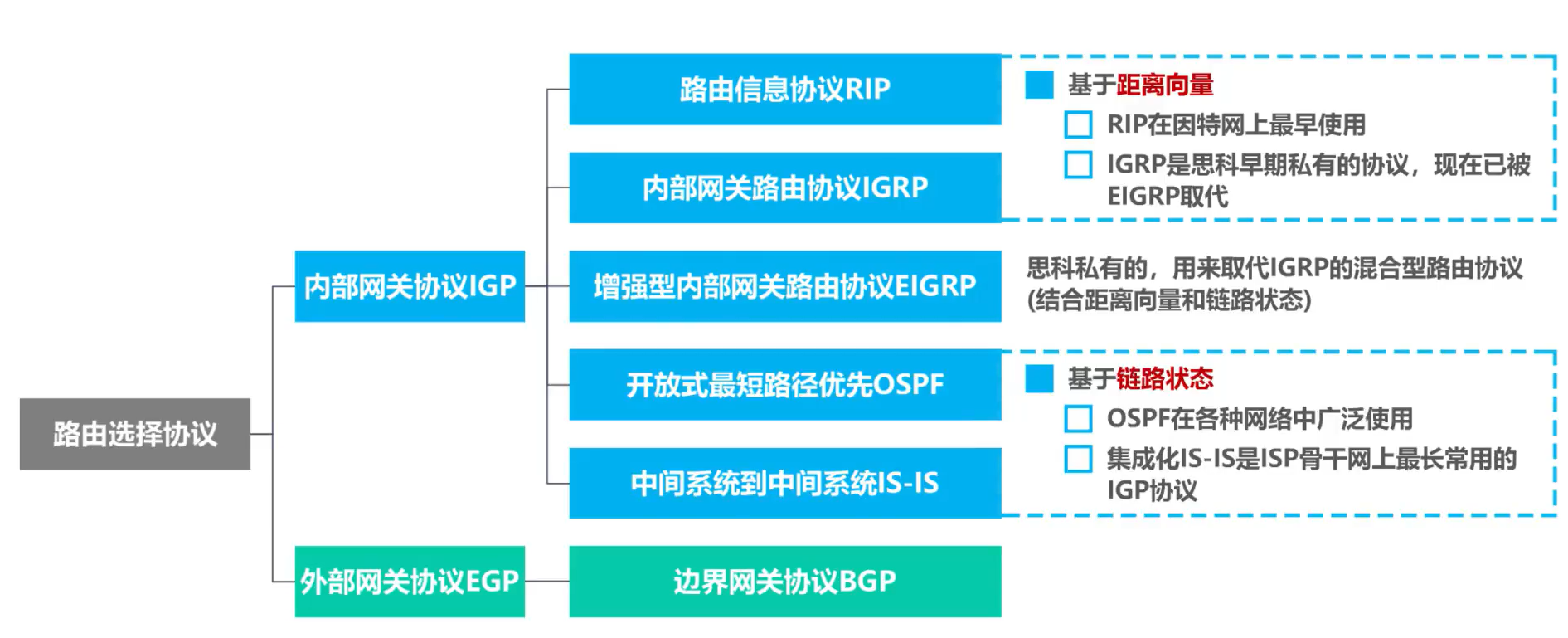
(4) Protocolos de enrutamiento comunes:
(5) La estructura básica del enrutador:
Un enrutador es una computadora especializada con múltiples puertos de entrada y salida cuya tarea es reenviar paquetes.
Toda la estructura del enrutador se puede dividir en dos partes :
- Parte de selección de enrutamiento : el componente central es el procesador de selección de enrutamiento , y su tarea es intercambiar periódicamente información de enrutamiento con otros enrutadores para actualizar la tabla de enrutamiento de acuerdo con el protocolo de selección de enrutamiento utilizado.
- Parte de conmutación de paquetes : consta de tres partes:
- cambiar de tela
- un conjunto de puertos de entrada
- un conjunto de puertos de salida
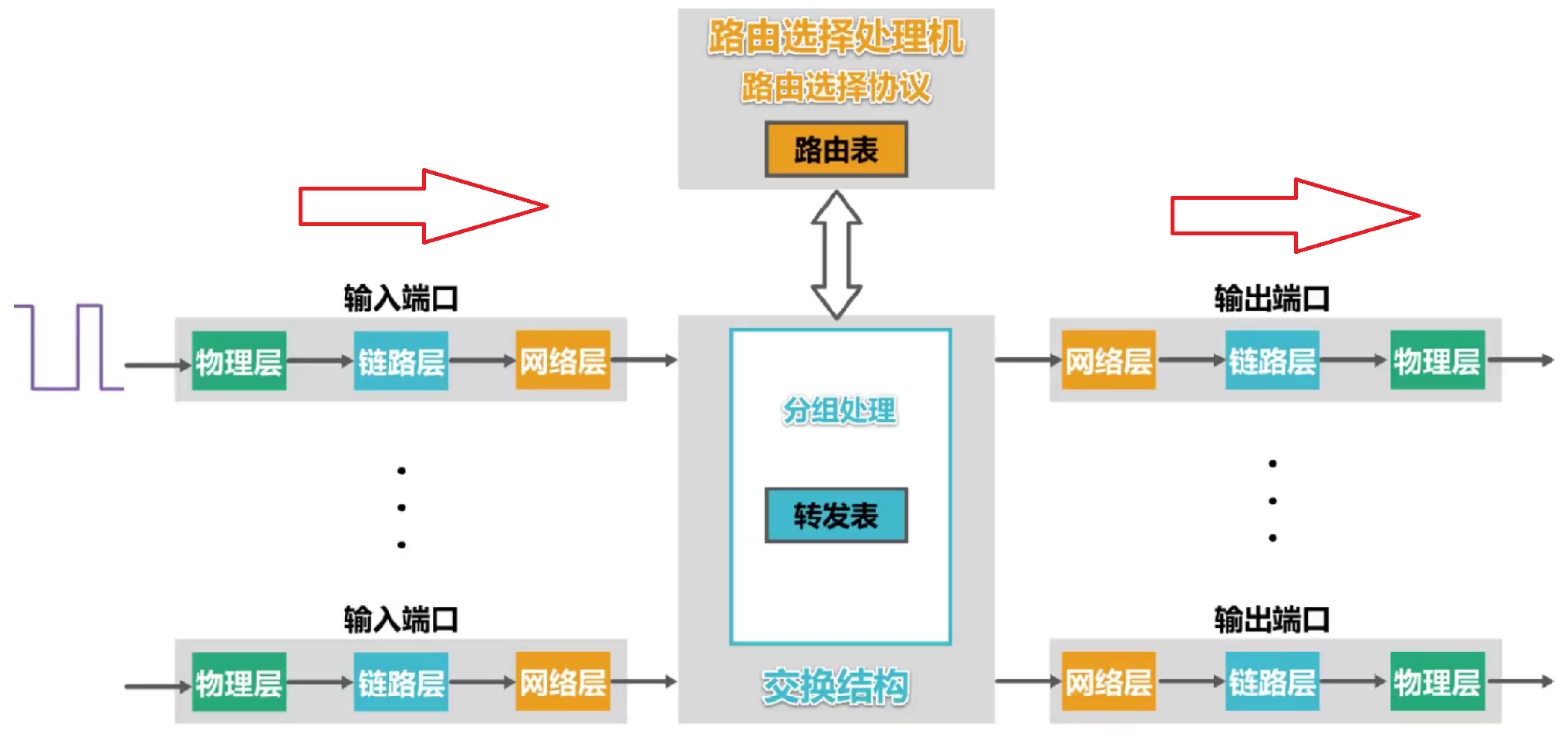
Hay dos tipos de paquetes recibidos por el enrutador:
- Si es un paquete ordinario , buscará en la tabla y lo reenviará de acuerdo con la dirección de destino en el paquete , si no lo encuentra, se descartará, de lo contrario, se reenviará de acuerdo con el puerto indicado.
- Si es un mensaje de enrutamiento para intercambiar información entre enrutadores , el paquete se envía al procesador de enrutamiento y el procesador de enrutamiento actualiza su propia tabla de enrutamiento de acuerdo con el contenido del paquete.
Cada puerto del enrutador también debe tener un búfer de entrada y un búfer de salida:
- El búfer de entrada se utiliza para almacenar temporalmente paquetes que se ingresan recientemente en el enrutador pero que aún no se han procesado.
- El búfer de salida se utiliza para almacenar temporalmente paquetes que se han procesado pero aún no se han enviado.
4.6.2 Principio de funcionamiento básico del protocolo de información de enrutamiento RIP
El Protocolo de información de enrutamiento, RIP, fue uno de los primeros protocolos de puerta de enlace interior en obtener un uso generalizado.
RIP requiere que cada enrutador en un AS en un sistema autónomo mantenga un registro de la distancia de sí mismo a cualquier otra red en el AS.
RIP usa el conteo de saltos como una métrica para medir la distancia a una red de destino.
- La distancia desde el enrutador a la red conectada directamente es 1
- La distancia desde el enrutador a la red no conectada directamente es el número de enrutadores pasados + 1
- Una ruta solo puede contener hasta 15 enrutadores , y una distancia de 16 equivale a ser inalcanzable , por lo que RIP solo es adecuado para Internet pequeños.
Nota: Los enrutadores de algunos fabricantes no implementan RIP estrictamente de acuerdo con las regulaciones.Por ejemplo, el RIP de los enrutadores Cisco define la distancia a la red directamente conectada como 0.
RIP considera que la ruta con la distancia más corta es una buena ruta , es decir, la ruta con la menor cantidad de enrutadores pasados.
Cuando hay varias , se puede realizar un equilibrio de carga de igual costo , es decir, el tráfico se distribuye uniformemente a varias rutas de igual costo.
Los enrutadores adyacentes intercambian sus propias tablas de enrutamiento periódicamente , por ejemplo, enviando paquetes de actualización RIP cada 30 segundos.
1. El proceso de trabajo básico de RIP:
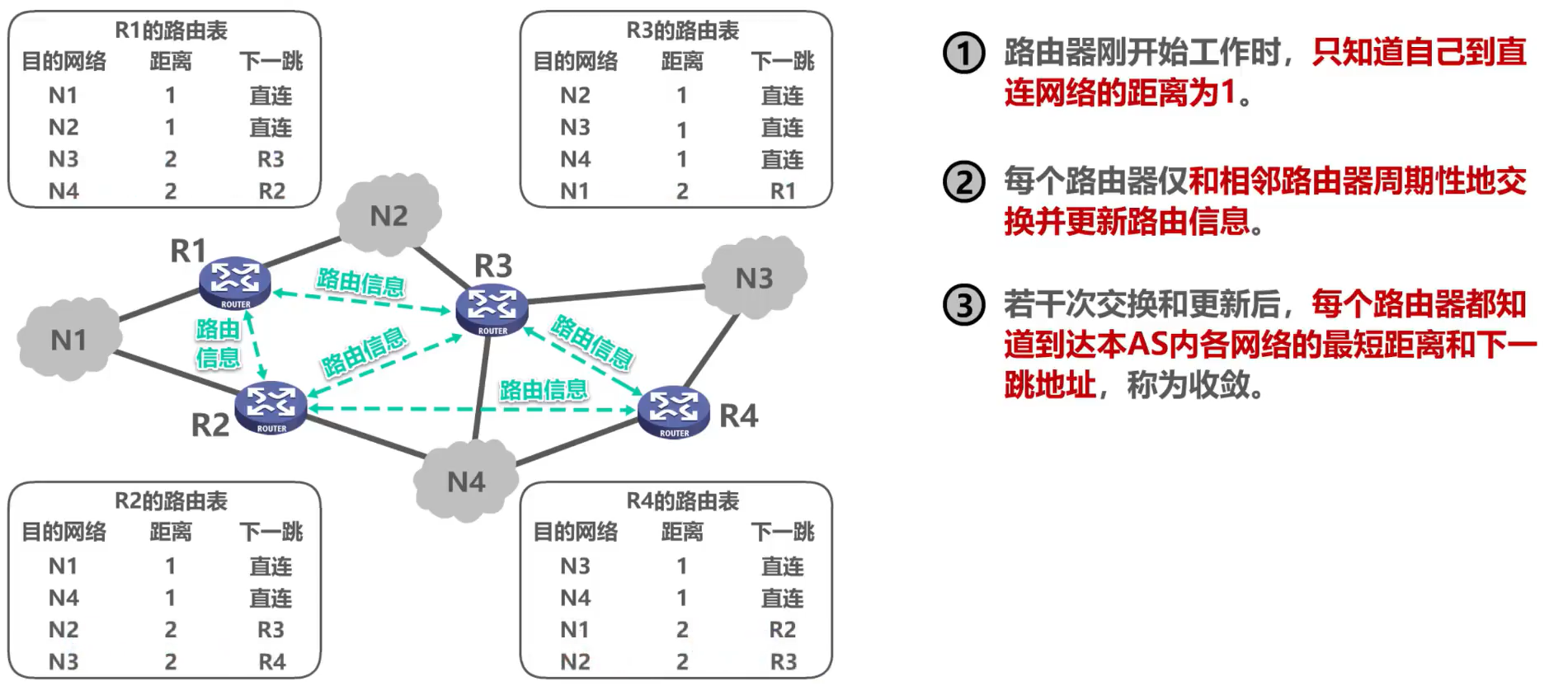
2. Reglas de actualización de entrada de enrutamiento RIP
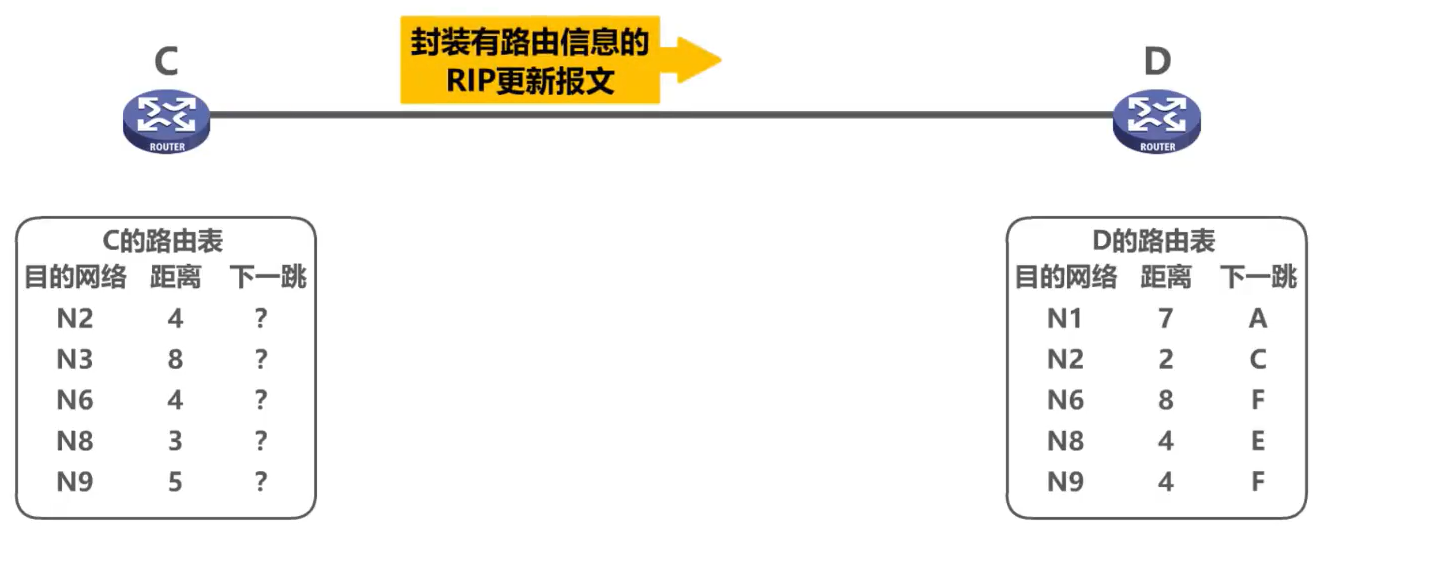
La tabla del enrutador C muestra que la siguiente entrada a cada red de destino se registra como un signo de interrogación, lo que puede entenderse como que el enrutador D no necesita preocuparse por estos contenidos del enrutador C.
Suponiendo que el período para enviar el mensaje de actualización de RIP del enrutador C ha terminado, el enrutador C encapsula la información de enrutamiento relevante en su propia tabla de enrutamiento en el mensaje de actualización de RIP y lo envía al enrutador D.
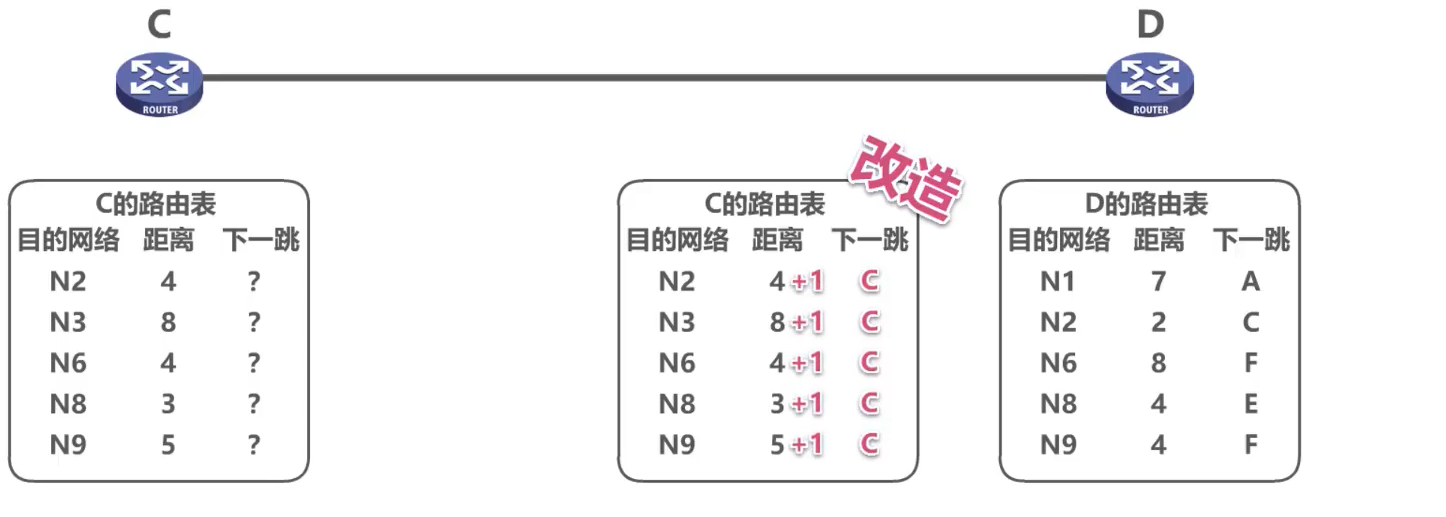
Después de que el enrutador D recibe el paquete de actualización RIP del enrutador C, actualiza su tabla de enrutamiento de acuerdo con las reglas.
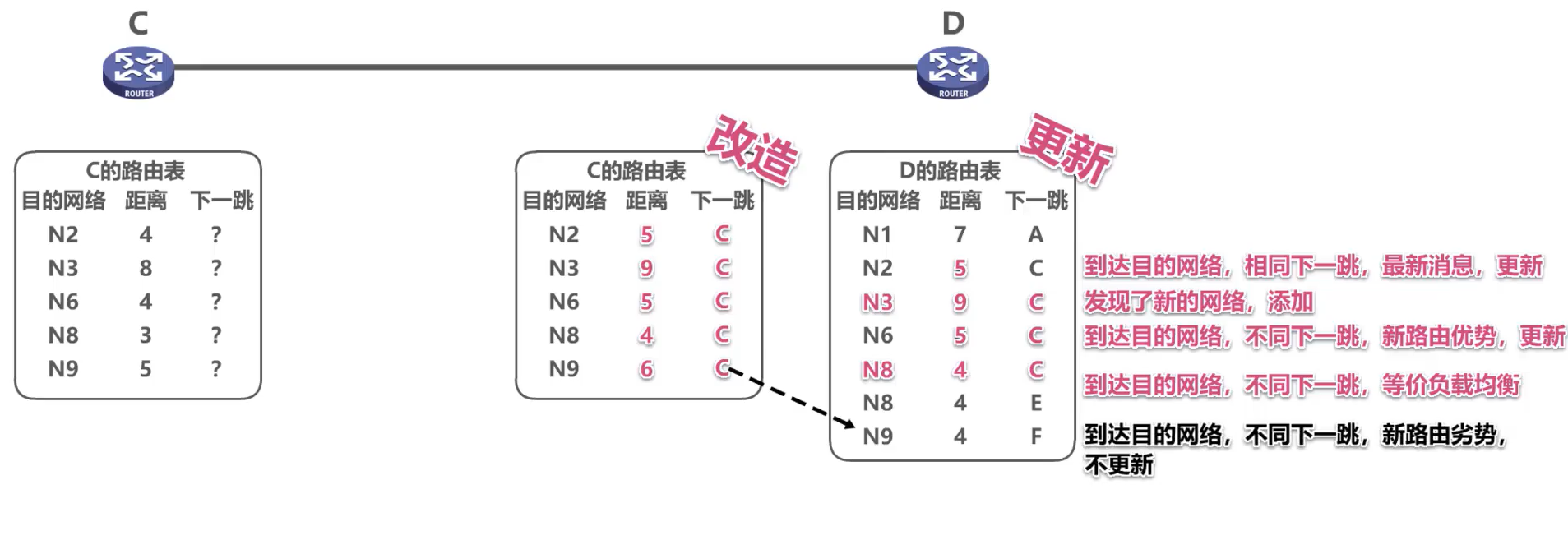
3. El protocolo RIP tiene el problema de la "transmisión lenta de malas noticias"



Solución:
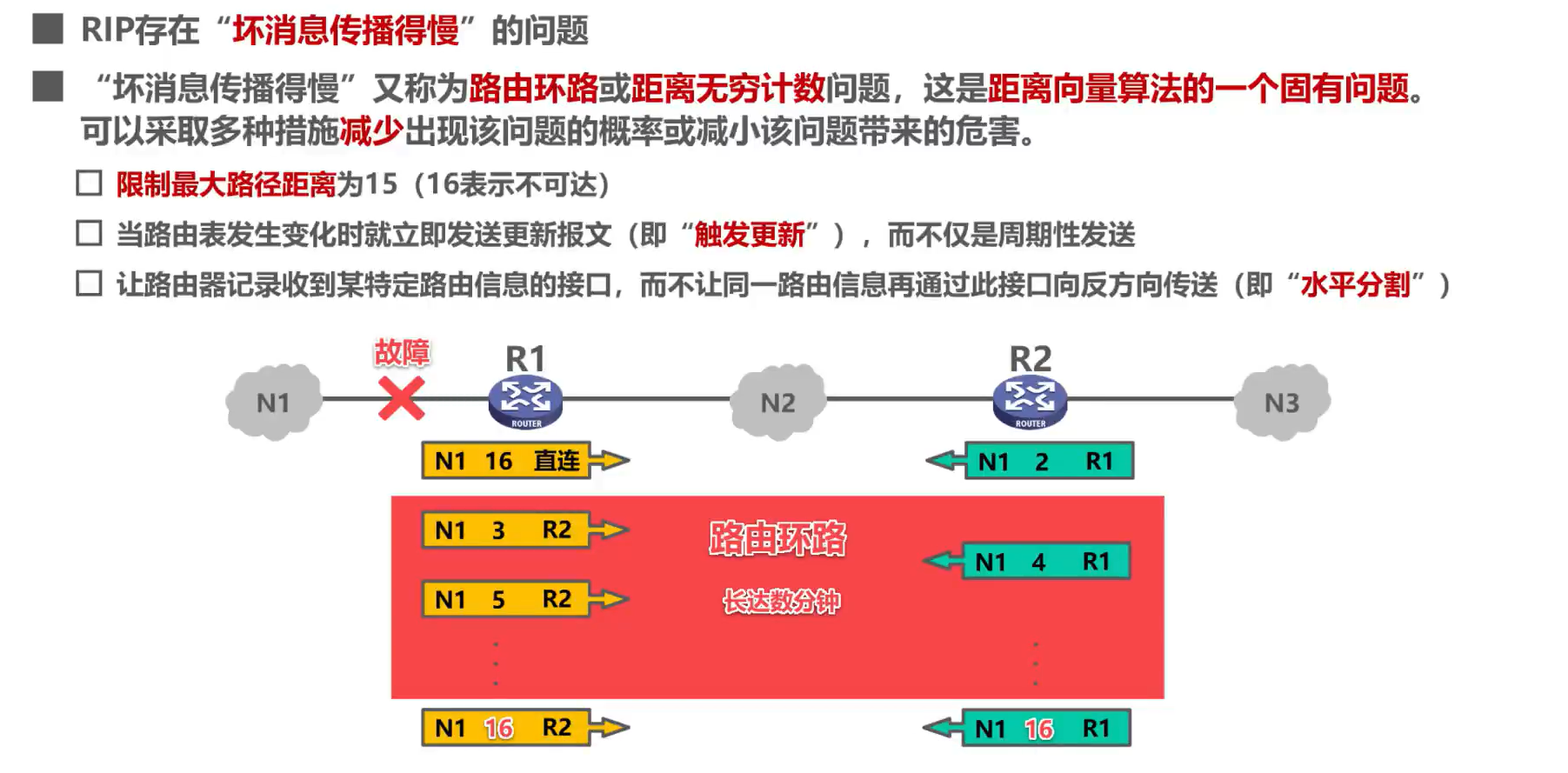
Sin embargo, estos métodos no pueden resolver por completo el problema de "las malas noticias viajan lentamente", que es la naturaleza del vector distancia.
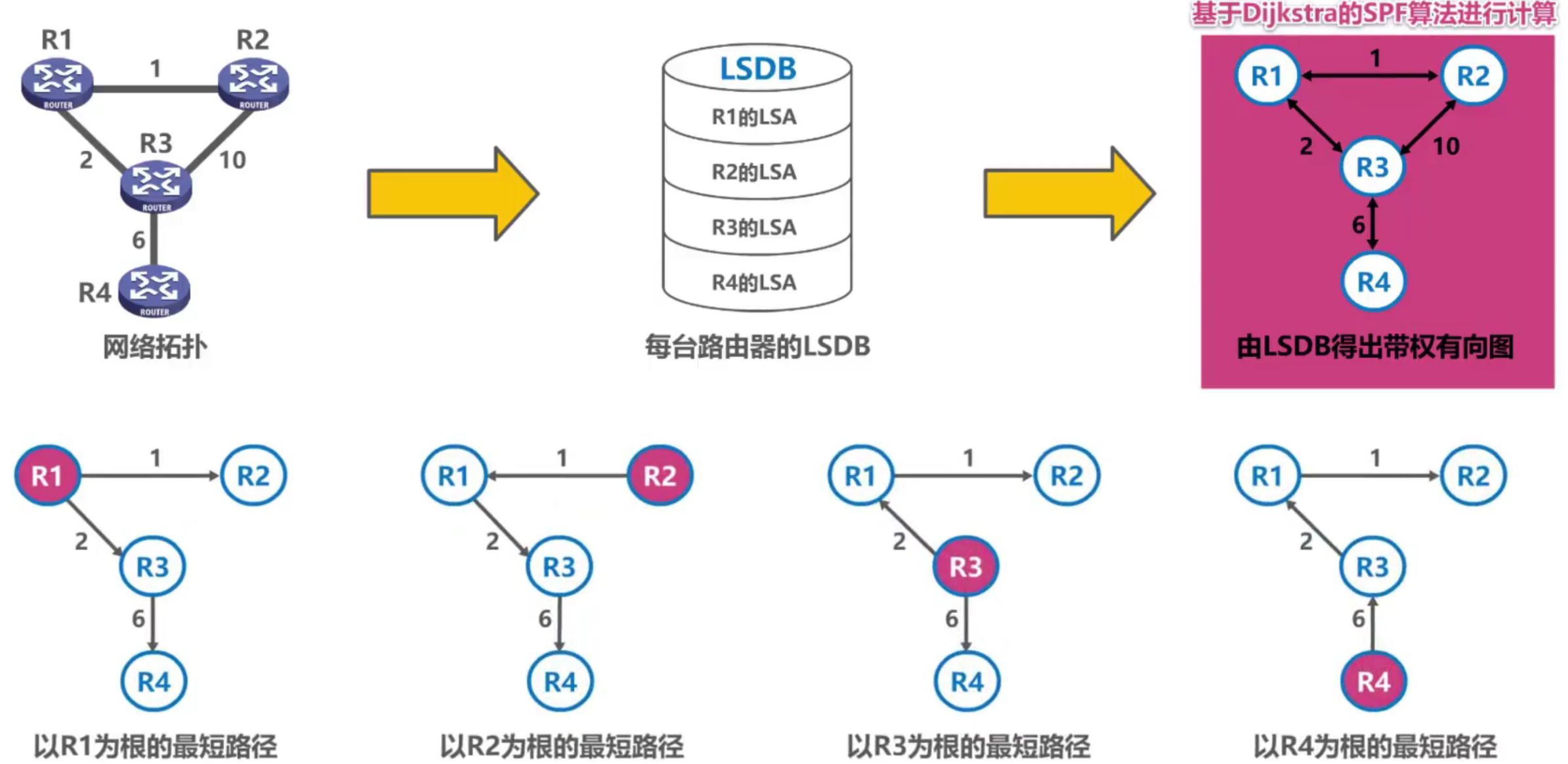
4.6.3 Principio de funcionamiento básico de Open Shortest Path First OSPF
1. Conceptos básicos
Open Shortest Path First OSPF (Open Shortes Path First) se desarrolló en 1989 para superar las deficiencias de RIP.
- "Abierto" indica que OSPF no está controlado por un determinado proveedor, sino que se publica públicamente.
- "La ruta más corta primero" se debe a que se utiliza el algoritmo de ruta más corta propuesto por Dijkstra.
OSPF se basa en el estado del enlace , no en el vector de distancia como RIP.
OSPF utiliza el algoritmo de ruta más corta para calcular las rutas, lo que garantiza que no se produzcan bucles de enrutamiento.
OSPF no limita la escala de la red y tiene una alta eficiencia de actualización y una rápida velocidad de convergencia.

2. Grupo de saludo
Los enrutadores OSPF vecinos establecen y mantienen relaciones vecinas mediante el intercambio de paquetes Hello (Hola) .

El paquete de saludo debe encapsularse en un datagrama IP y enviarse a la dirección de multidifusión 224.0.0.5 . El valor del campo de número de protocolo en el encabezado del datagrama IP debe ser 89 para indicar que la carga útil de datos del datagrama IP es un paquete OSPF.

El ciclo de envío del paquete de saludo es de 10 segundos.Si el paquete de saludo del enrutador vecino no se recibe dentro de los 40 segundos, el enrutador vecino se considera inalcanzable.
Cada enrutador creará una tabla de vecinos para registrar la información relevante de los enrutadores adyacentes, como la identificación del vecino, la interfaz y la cuenta regresiva de muerte.
Si no se recibe el paquete de saludo cuando la cuenta regresiva de muerte es 0, se determina que el enrutador vecino es inalcanzable.

3. Paquete de actualización de estado de enlace
Cada enrutador que usa OSPF generará un anuncio de estado de enlace LSA (anuncio de estado de enlace), LSA contiene los siguientes dos contenidos:
- Información de estado de enlace para redes conectadas directamente
- Información de estado de enlace de enrutadores vecinos
LSA se encapsula en el paquete de actualización de estado de enlace LSU y se envía mediante el método de inundación .
Un enrutador que recibe un paquete de actualización de estado de enlace reenviará el paquete a través de todas sus otras interfaces , es decir, realizará un reenvío de inundación .
De esta forma, cada enrutador del sistema autónomo envía un paquete de actualización de estado de enlace encapsulado con un anuncio de estado de enlace, que se entregará a todos los demás enrutadores del sistema.
Cada enrutador que usa OSPF tiene una base de datos de estado de enlace LSDB , que se usa para almacenar anuncios de estado de enlace.
Al enviar el LSU encapsulado con su propio LSA por cada enrutador, los LSDB de cada enrutador eventualmente llegarán al mismo.
Cada enrutador que usa OSPF realiza el cálculo de la ruta más corta en función de LSDB y crea su propia ruta más corta a otros enrutadores, es decir, crea su propia tabla de enrutamiento.
Cinco tipos de paquetes de OSPF:

4. El proceso de trabajo básico de OSPF

- Los enrutadores vecinos envían periódicamente paquetes de saludo para establecer y mantener relaciones vecinas.
- Una vez que se establece la relación, el paquete de descripción de la base de datos se envía al enrutador vecino (tenga en cuenta que esta es solo la información de resumen del estado del enlace).
- Después de recibir el paquete de descripción de la base de datos, R1 descubre que le falta información sobre el estado del enlace, por lo que envía un paquete de solicitud de estado del enlace a R2 .
- Después de recibirlo, R2 encapsula la información detallada del elemento de estado de enlace que le falta a R1 en un paquete de actualización de estado de enlace y lo envía a R1.
- Después de recibirlo, R1 agrega la información detallada de estos elementos de estado de enlace a su propia base de datos de estado de enlace y envía un paquete de confirmación de estado de enlace a R2 .
De manera similar, R2 también puede solicitar información de estado de enlace que le falta a R1, de modo que R1 y R2 puedan lograr la sincronización de la base de datos de estado de enlace .
Cada 30 minutos o cuando cambie el estado del enlace, el enrutador enviará un paquete de actualización del estado del enlace, y otros enrutadores que reciban el paquete realizarán un reenvío de inundación y enviarán un paquete de confirmación del estado del enlace al enrutador.

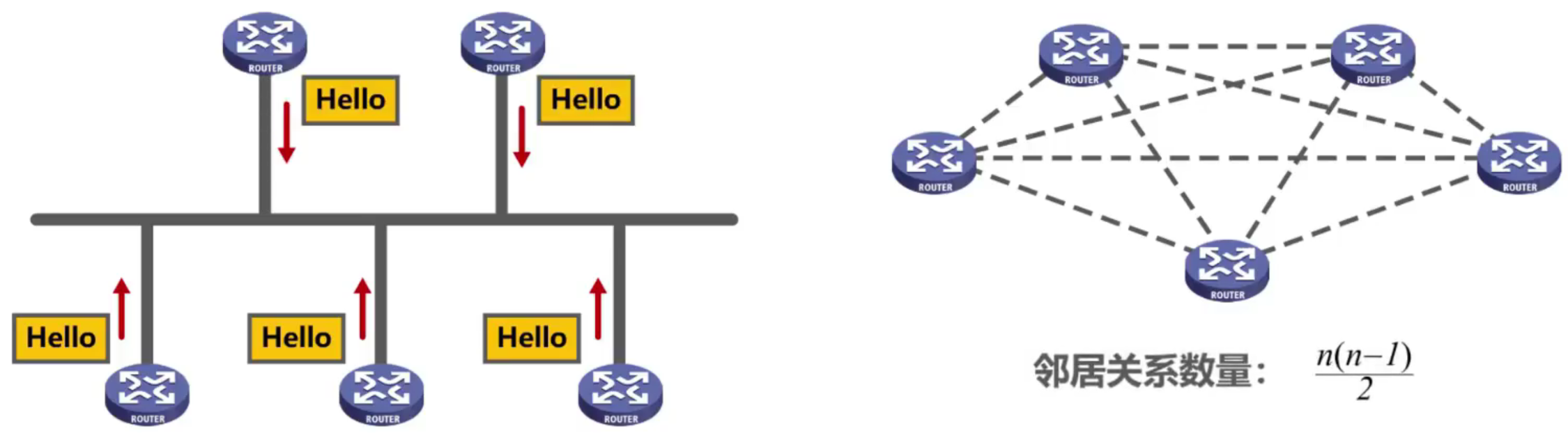
5. OSPF en red de acceso multipunto
Cuando un enrutador OSPF establece una relación de vecino en una red de acceso multipunto, si no se adoptan otros mecanismos, se generará una gran cantidad de grupos de multidifusión.
Por ejemplo: los enrutadores de la siguiente figura son vecinos y cada enrutador envía un paquete de saludo y un paquete de actualización de estado de enlace a otros enrutadores n-1.
Para reducir la cantidad de paquetes enviados, OSPF adopta el método de elegir el enrutador designado DR y el enrutador designado de respaldo BDR .
Todos los enrutadores que no son DR ni BDR solo establecen una relación de vecino con DR y BDR , y los que no son DR/BDR solo pueden intercambiar información a través de DR/BDR.
Si hay un problema con el DR, el BDR reemplazará al DR.
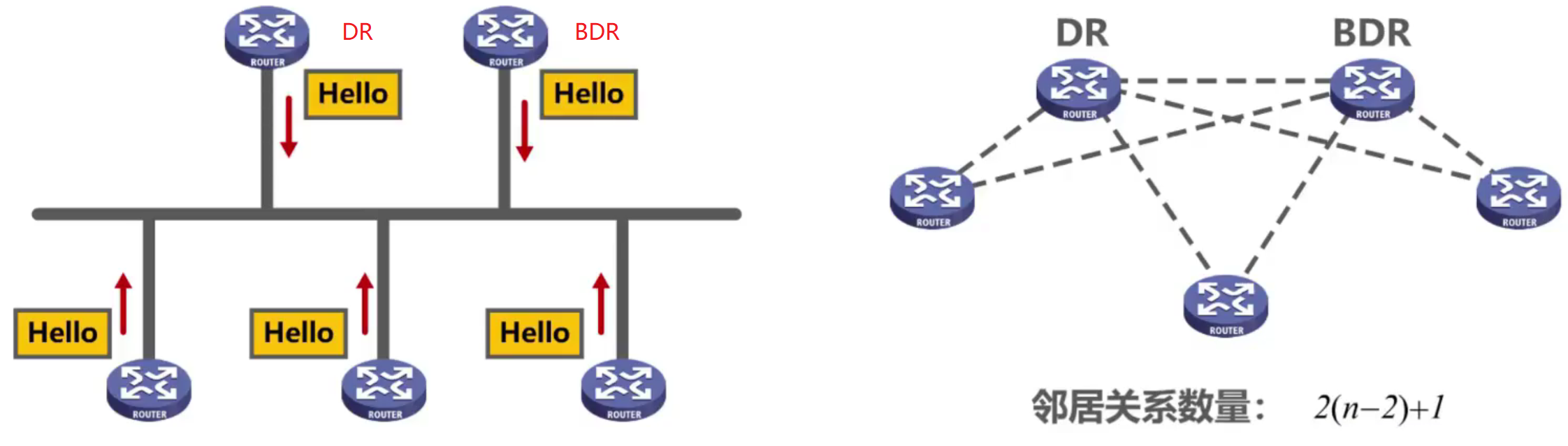
No es complicado implementar DR y BDR, simplemente intercambie algunos parámetros de elección entre los enrutadores, como la prioridad del enrutador, la ID del enrutador, la dirección IP de la interfaz, etc., y luego seleccione DR y BDR de acuerdo con las reglas de elección.
6. Área
En una red a gran escala, los paquetes enviados por cada enrutador serán reenviados por todos los enrutadores del sistema, lo que provocará demasiado tráfico en toda la red.
Por lo tanto, OSPF divide un sistema autónomo en varias áreas más pequeñas llamadas áreas .
Cada área tiene un identificador de área de 32 bits , que se puede expresar en notación decimal con puntos. El identificador del área de backbone debe ser 0, y los identificadores de otras áreas son diferentes.
El tamaño de cada área no debe ser demasiado grande y, por lo general, no debe contener más de 200 enrutadores .
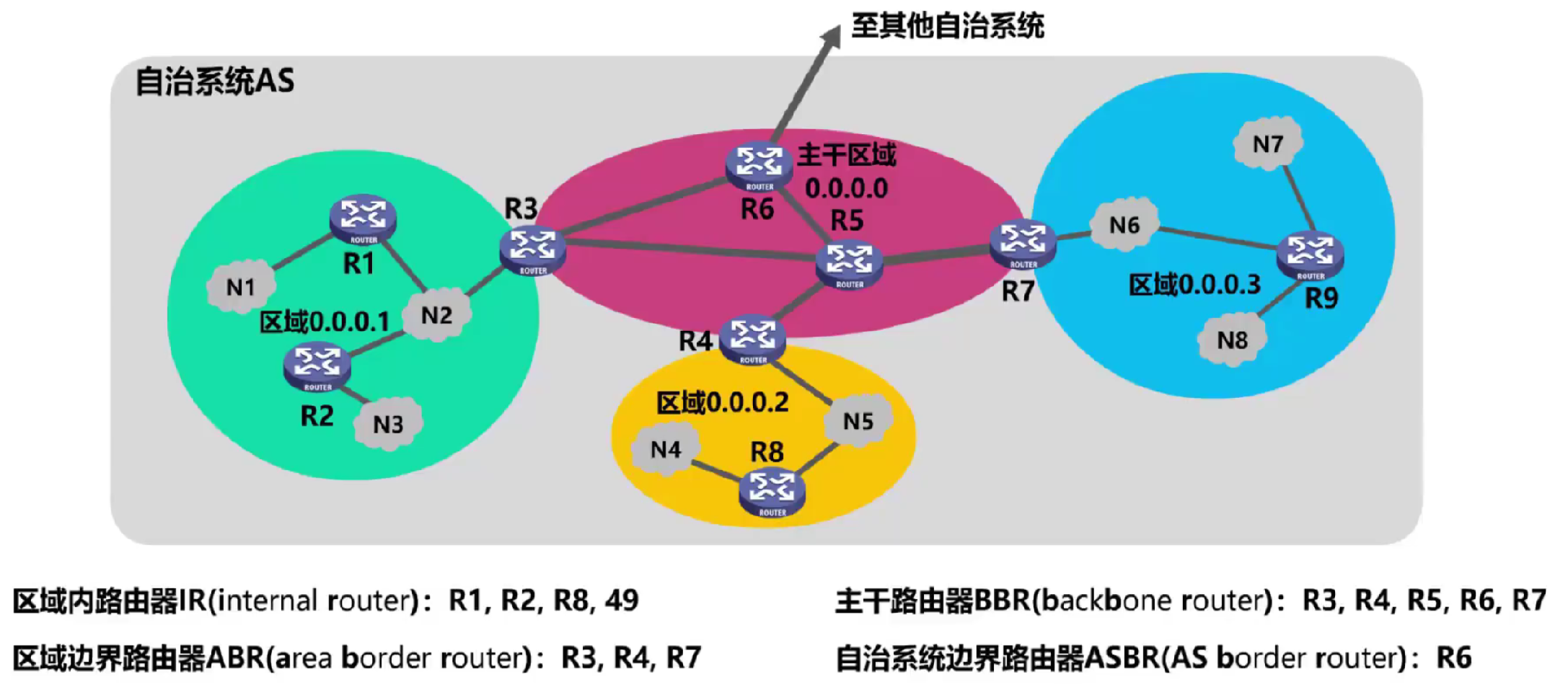
Enrutador intraárea : todas las interfaces del enrutador están en la misma área.
Enrutador de área fronteriza : conecta diferentes áreas, una interfaz se usa para conectar su propia área y la otra interfaz se usa para conectar el área de red troncal.
Enrutador de red troncal : un enrutador en un área de red troncal y un enrutador de borde de área también pueden considerarse como un enrutador de red troncal.
Enrutador de borde del sistema autónomo : uno de los enrutadores de la red troncal, que se utiliza para intercambiar información de enrutamiento con otros sistemas autónomos.
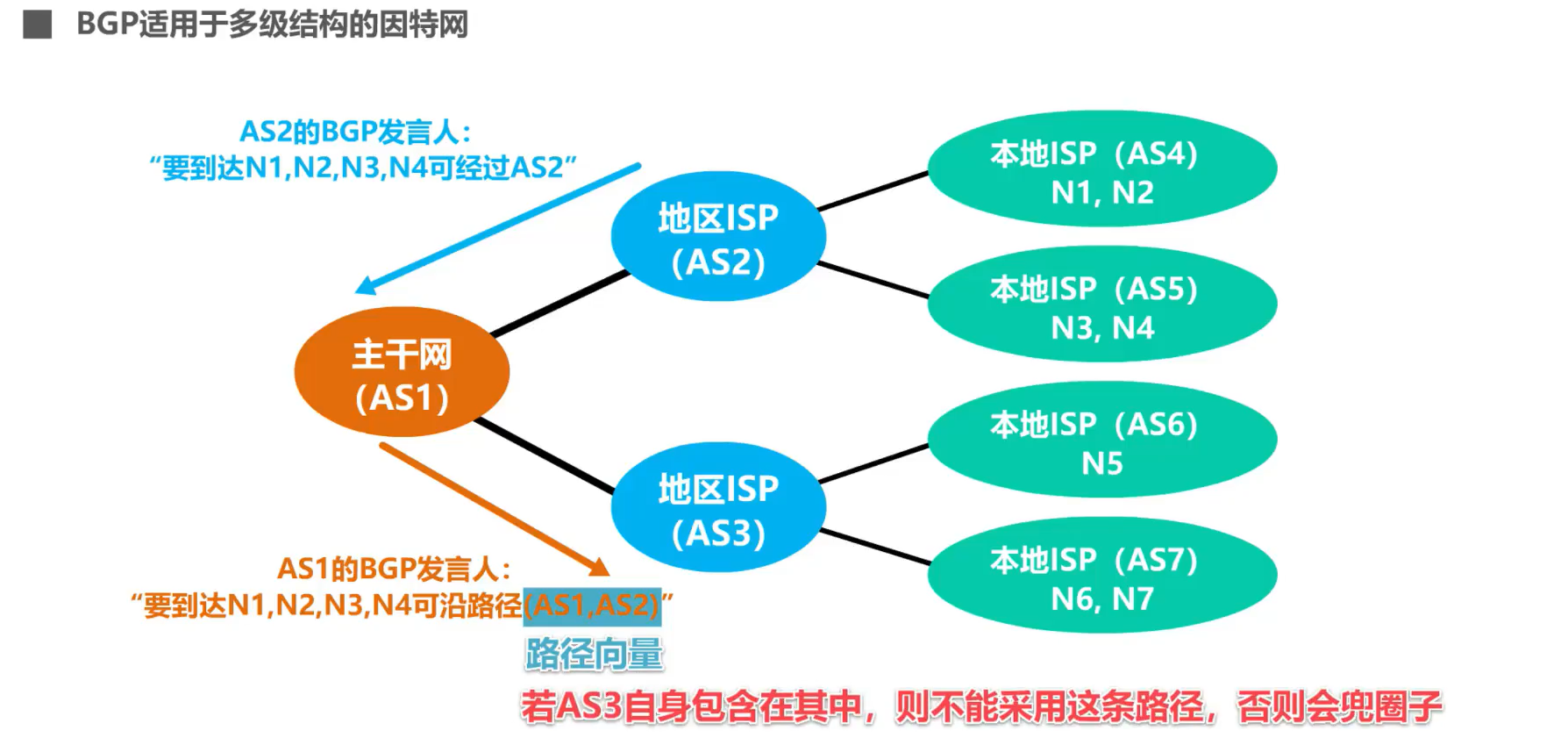
4.6.4 El principio de funcionamiento básico del protocolo de puerta de enlace fronteriza BGP:
El protocolo RIP y el protocolo OSPF anteriores pertenecen al protocolo de puerta de enlace interior, y el protocolo de puerta de enlace de borde presentado en este resumen pertenece al protocolo de puerta de enlace exterior.
En diferentes sistemas autónomos, el costo de medir el enrutamiento (distancia, ancho de banda, costo, etc.) puede ser diferente Por lo tanto, para la selección de enrutamiento entre diferentes sistemas autónomos, no es factible usar el costo para medir la mejor ruta.
La selección de enrutamiento entre sistemas autónomos también debe considerar las políticas relacionadas (políticas, económicas, de seguridad, etc. ), como no pasar por algunos países con amenazas de seguridad, y algunos sistemas autónomos deben cobrar, etc.
BGP solo puede encontrar una ruta mejor que pueda llegar a la red de destino, en lugar de buscar una ruta óptima.

Al configurar BGP, el administrador de cada sistema autónomo debe seleccionar al menos un enrutador como "portavoz de BGP" del sistema autónomo .
Para intercambiar información de enrutamiento entre altavoces BGP de diferentes sistemas autónomos, primero se debe establecer una conexión TCP y el número de puerto es 179 .
-
Los paquetes BGP se intercambian en esta conexión TCP para establecer una sesión BGP .
-
Use sesiones BGP para intercambiar información de enrutamiento (por ejemplo, agregar nuevas rutas, retirar rutas obsoletas e informar errores, etc.)
-
Dos altavoces BGP que intercambian información de enrutamiento mediante una conexión TCP se denominan vecinos o pares entre sí .
Después de que los altavoces BGP intercambien la información de accesibilidad de la red entre sí, cada altavoz BGP encuentra una mejor ruta a cada sistema autónomo a partir de la información de enrutamiento recibida de acuerdo con la estrategia adoptada .

Preguntas de práctica:

4.7 El formato de encabezado del datagrama IPv4
Parte fija : 20 bytes, que deben incluirse en cada datagrama IP.
Parte variable : ocupa de 0 a 40 bytes.
El encabezado de un datagrama IP a menudo se describe en unidades de bits 32. Cada fila en la figura consta de bits 32 (4 bytes), y cada cuadrícula pequeña se denomina campo o dominio .

Versión : 4 bits, que indican la versión del protocolo IP. Las versiones del protocolo IP utilizadas por ambas partes de la comunicación deben ser las mismas. Actualmente, el número de versión del protocolo IP ampliamente utilizado es 4 (a saber, IPv4).
Longitud del encabezado : 4 bits, que indica la longitud del encabezado del datagrama IP, y el valor de este campo está en unidades de 4 bytes .
- El valor decimal mínimo es 5, lo que significa que la cabecera del datagrama IP sólo tiene una parte fija de 20 bytes.
- El valor decimal máximo es 15, lo que indica que la cabecera del datagrama IP contiene una parte fija de 20 bytes y una parte variable de hasta 40 bytes.
DiffServ : se utilizan 8 bits para obtener mejores servicios. Normalmente este campo no se utiliza.
Longitud total : 16 bits, que indican la longitud total del datagrama IP (cabecera + carga útil de datos), el valor máximo es 65535 en decimal, en bytes, y en la práctica rara vez se transmiten datagramas IP tan largos.
Tiempo de vida : 8 bits
- Inicialmente, la unidad es segundos y la vida útil máxima es de 255. Cuando un enrutador reenvía un datagrama IP, resta el valor de este campo en el encabezado del datagrama IP del tiempo que el enrutador pasó en el datagrama IP. Si no es 0, se reenvía; de lo contrario, se descarta.
- Ahora tome el número de saltos como la unidad, cuando el enrutador reenvía el datagrama IP, el valor de este campo en el encabezado del datagrama IP se decrementa en 1, si no es 0, se reenvía, de lo contrario se descarta.
- Función: evita que los datagramas IP circulen en la red (consulte el problema del bucle de enrutamiento 4.5.2)
Protocolo : 8 bits, utilizados para indicar qué tipo de unidad de datos de protocolo es la parte de datos del datagrama IPv4.

Checksum de cabecera : ocupa 16 bits y se utiliza para detectar si hay algún error en la cabecera durante la transmisión. Más simple que la codificación CRC, conocida como suma de comprobación de Internet.
- Cada vez que un datagrama IP pasa a través de un enrutador, el enrutador debe volver a calcular la suma de verificación del encabezado, porque algunos campos (tiempo de vida, bandera, compensación de segmento, etc.) pueden cambiar.
- Dado que la capa IP en sí misma no proporciona servicios de transmisión confiables, y calcular la suma de verificación del encabezado es una operación que consume mucho tiempo, los enrutadores ya no calculan la suma de verificación del encabezado en IPv6, por lo que reenvían los datagramas IP más rápido.
Dirección IP de origen y dirección IP de destino : 32 bits cada una, que se utilizan para completar la dirección IP del host de origen que envía el datagrama IP y la dirección IP del host de destino que recibe el datagrama IP.
Campo opcional : la longitud puede variar de 1 byte a 40 bytes. Se utiliza para apoyar la resolución de problemas, la medición y las medidas de seguridad. Los campos opcionales agregan funcionalidad al datagrama IP, pero también agregan sobrecarga. En la práctica, rara vez se utilizan campos opcionales.
Campo de relleno : asegúrese de que la longitud del encabezado sea un múltiplo entero de 4 bytes. Pad con todos los 0s.
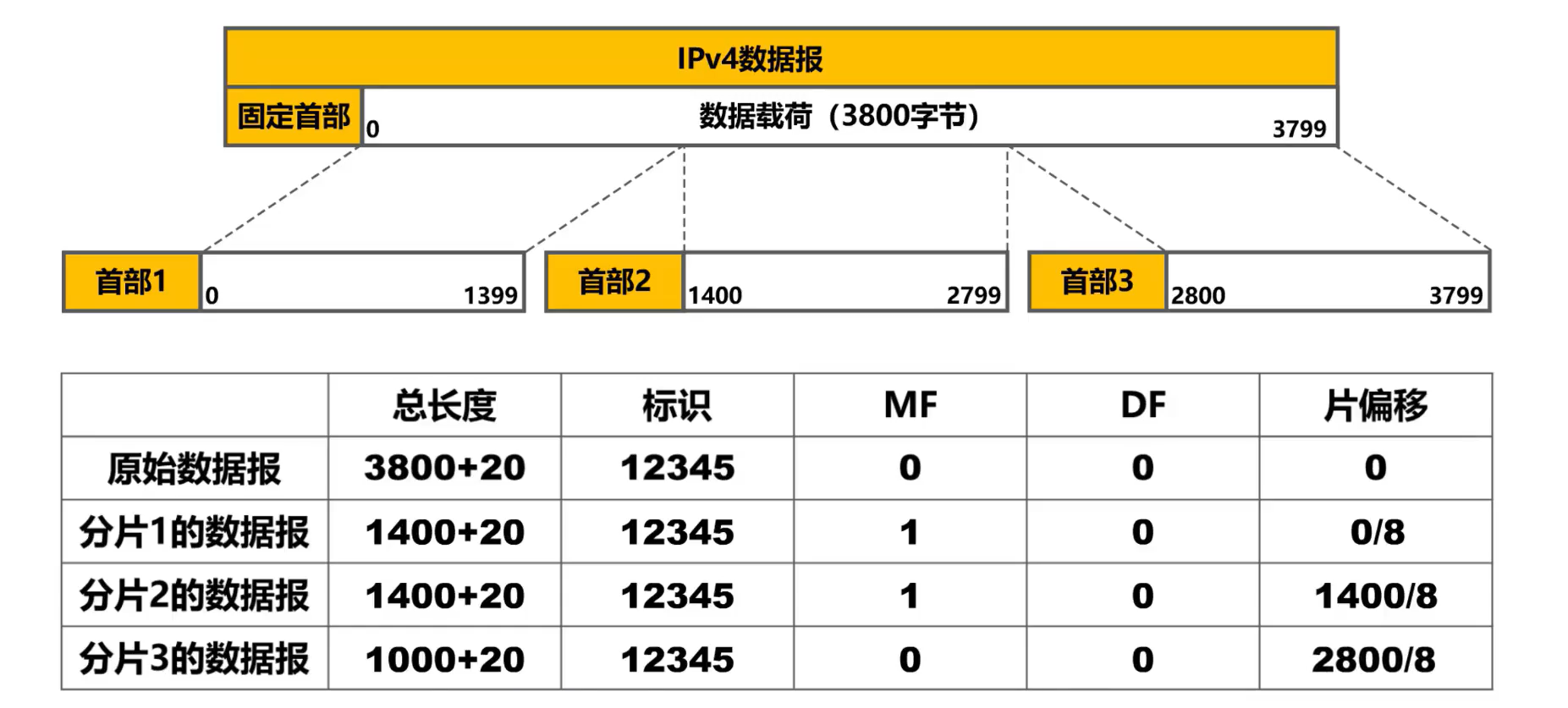
El campo de identificación, el campo de bandera y el campo de desplazamiento de segmento se utilizan juntos para la fragmentación de datagramas IP.
El protocolo de la capa de enlace de datos estipula la longitud máxima de la carga útil de datos de la trama , que se denomina unidad máxima de transmisión MTU . Si la longitud de un datagrama IP supera la MTU, no se puede encapsular en una trama y el datagrama IP original debe fragmentarse en datagramas IP más pequeños.

Identificación : ocupando 16 bits, cada fragmento perteneciente a un mismo datagrama tiene la misma identificación. El software IP mantiene un contador, incrementa el valor del contador en uno cada vez que se genera un datagrama y asigna este valor al campo de identificación.
Bandera : ocupa 3 bits, el significado de cada bit es el siguiente:
- Bit DF: indica si se permite la fragmentación, 1 significa que no se permite la fragmentación y 0 significa que se permite la fragmentación.
- Bit MF: Indica si hay fragmentos detrás de este fragmento. 1 significa que todavía hay fragmentos, 0 significa que este es el último fragmento.
- Bits reservados: DEBEN establecerse en 0.
Desplazamiento de fragmentos : 13 bits, que indican la posición de cada datagrama fragmentado en el datagrama original. en unidades de 8 bytes.
Ejemplo de fragmentación:
4.8 Protocolo de mensajes de control de Internet ICMP
Para reenviar datagramas IP de manera más eficiente y mejorar la posibilidad de una entrega exitosa, se utiliza el Protocolo de mensajes de control de Internet (ICMP) en la capa de Internet.
Los hosts o enrutadores usan ICMP para enviar mensajes de informe de errores y mensajes de consulta .
Los mensajes ICMP se encapsulan y envían en datagramas IP.
1. Mensaje de informe de error ICMP
Hay cinco tipos de mensajes de error ICMP:
- punto final inalcanzable
- supresión de fuente
- tiempo excedido
- problema de parámetros
- cambiar ruta (redireccionar)
(1) El punto final es inalcanzable
Cuando un enrutador o host no puede entregar un datagrama, envía un mensaje de destino inalcanzable a la fuente.
Específicamente, según el campo de código ICMP, se puede subdividir en 13 tipos de errores, como red de destino inalcanzable, host de destino inalcanzable, protocolo de destino inalcanzable, puerto de destino inalcanzable y red de destino desconocida.
Ejemplo: H1 quiere enviar un datagrama de IP a H2, que R1 debe reenviar, pero no hay una entrada relevante sobre H2 en la tabla de enrutamiento de R1, el datagrama se descartará y se enviará un mensaje de destino inalcanzable a H1.

(2) Supresión de fuente
Cuando un enrutador o host descarta un datagrama debido a la congestión, envía un mensaje de supresión de fuente a la fuente para informarle que la velocidad de envío debe reducirse.
Ejemplo:

(3) El tiempo excede
Cuando el router recibe un datagrama IP cuya dirección de destino no es la suya, disminuirá su TTL en 1. Si el resultado no es 0, reenviará el datagrama, si el resultado es 0, descartará el datagrama y enviará el mensaje de tiempo excedido a la fuente.
Además, cuando el terminal no puede recibir todos los fragmentos de datagrama de un datagrama dentro del tiempo predeterminado, descarta todos los fragmentos de datagrama recibidos y envía un mensaje de tiempo excedido al punto de origen.
Por ejemplo:

(4) Problema de parámetros
Cuando un enrutador o un host recibe un datagrama IP, descubre que se produce un error de bit en el encabezado de acuerdo con el campo de suma de verificación del encabezado, descarta el datagrama y envía un mensaje de problema de parámetro a la fuente.
Ejemplo:

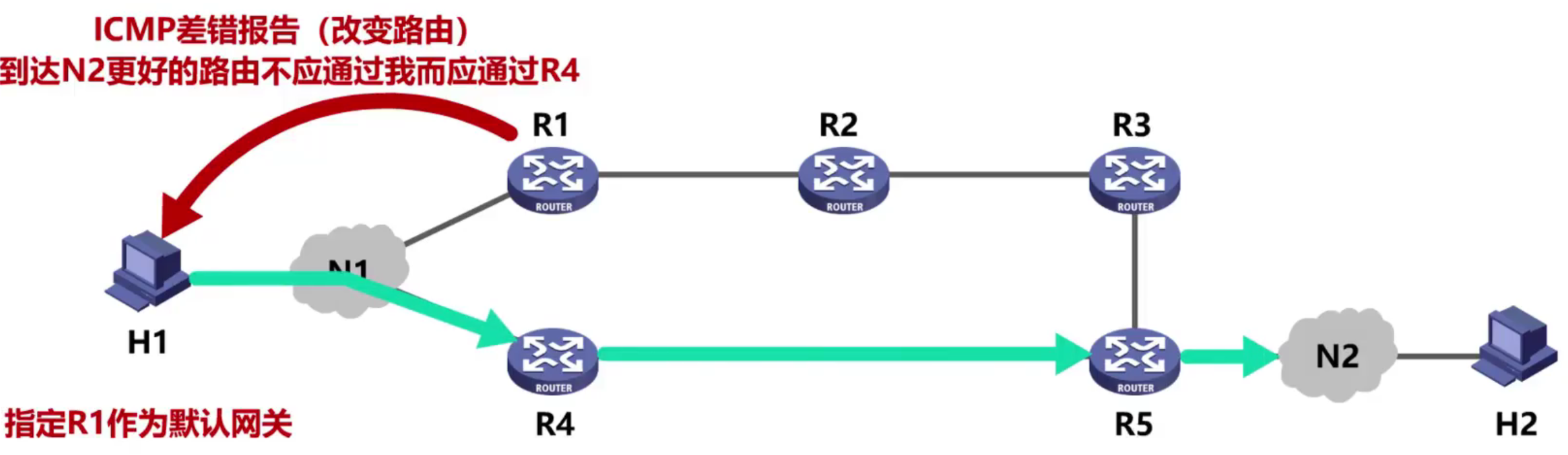
(5) Cambiar la ruta
El enrutador envía el mensaje de cambio de ruta al host, haciéndole saber que el datagrama debe enviarse a otro enrutador (mejor ruta) la próxima vez.
Ejemplo:
Los mensajes de informe de errores de ICMP no deben enviarse en las siguientes situaciones:

2. Mensaje de consulta ICMP
(1) Solicitud y respuesta de eco
El mensaje de solicitud de eco ICMP es una consulta enviada por un host o enrutador a un host de destino específico .
El host que recibe el mensaje debe enviar un mensaje de respuesta de eco ICMP al host o enrutador de origen .
Este mensaje de consulta se utiliza para probar si la estación de destino es accesible y conocer su estado relacionado .
(2) Solicitud y respuesta de marca de tiempo
El mensaje de solicitud de marca de tiempo ICMP es para solicitar a un host o enrutador que responda la fecha y hora actuales .
Hay un campo de 32 bits en el mensaje de respuesta de marca de tiempo ICMP , y el número entero escrito en él indica cuántos segundos hay desde el 1 de enero de 1900 hasta el momento actual.
Este mensaje de consulta se utiliza para la sincronización del reloj y la medición del tiempo.
3. Ejemplos de aplicaciones ICMP
(1) PING de detección de paquetes entre redes
- Usado para probar la conectividad entre hosts o enrutadores, el comando ping se usa en la ventana.
- La capa de aplicación usa directamente ICMP en la capa de Internet , sin TCP o UDP en la capa de transporte.
- Utilice ICMP para repetir mensajes de solicitud y respuesta.

(2) rastrear ruta rastrear ruta

El principio de implementación de traceroute:


