Implementación del clúster Elasticsearch
- 1. Arquitectura del clúster Elasticsearch
- 2. Implementación del clúster Elasticsearch
-
- 2.1 Modificación de la configuración del sistema
- 2.2 Descargue la base de datos es y cárguela en el servidor
- 2.3 Modificar el archivo de configuración del clúster
- 2.4 Crear usuarios y grupos de Elasticsearch
- 2.5 Establecer permisos de directorio
- 2.6 Iniciar el servicio Elasticsearch
- 2.7 Abrir puertos de firewall
- 2.8 Ver el estado de inicio de es
1. Arquitectura del clúster Elasticsearch
El clúster de Elasticsearch es un potente motor de búsqueda y análisis que consta de varios nodos, cada nodo es una instancia independiente de Elasticsearch. Estos nodos trabajan juntos para construir un motor de búsqueda escalable y de alta disponibilidad. Este artículo profundizará en la arquitectura y la implementación de los clústeres de Elasticsearch, incluidos los nodos maestros, los nodos de datos, los nodos de cliente, los fragmentos y los métodos de comunicación entre nodos.
nodo maestro
En un clúster de Elasticsearch, hay un nodo designado como nodo maestro. La tarea principal del nodo maestro es la gestión y coordinación del clúster. Estas son algunas de las responsabilidades clave del masternode:
-
Mantener el estado del clúster: el nodo maestro es responsable de mantener el estado de todo el clúster, incluidos
节点列表、索引元数据和分片状态etc. -
Responsable del reequilibrio del clúster: cuando se unen nuevos nodos o los nodos antiguos salen del clúster, el nodo maestro será responsable
重新平衡集群,确保分片被适当地重新分配给节点,以保持负载均衡. -
Realizar operaciones a nivel de clúster: el nodo maestro puede realizar operaciones a nivel de clúster, como crear o eliminar índices, establecer configuraciones a nivel de índice, etc.
-
Monitorear el estado del nodo: el nodo maestro monitorea el estado de cada nodo en el clúster y detecta si el nodo está funcionando correctamente de manera oportuna.
En un clúster sólo puede haber un nodo maestro. Si el nodo maestro falla, Elasticsearch creará 自动选举un nuevo nodo maestro para hacerse cargo del trabajo y garantizar el funcionamiento estable del clúster.
nodo de datos
La principal responsabilidad del nodo de datos es 存储和处理数据. Cuando un cliente inicia una solicitud de búsqueda en el clúster, el nodo de datos consulta los datos locales de acuerdo con la solicitud y devuelve los resultados. Cada nodo de datos es responsable de almacenar una parte de los datos en el clúster. Cuando se indexan nuevos datos, los nodos de datos asignan los datos a los fragmentos correspondientes y los almacenan en discos locales. Si un nodo de datos falla, otros nodos del clúster se harán cargo del trabajo del nodo, garantizando la disponibilidad de los datos y una copia de seguridad redundante.
nodo cliente
Los nodos de cliente no almacenan datos; su función principal es proporcionar datos al cliente 集群发送查询请求,并将查询结果返回给客户端应用程序.
Los nodos cliente tienen las dos funciones clave siguientes:
-
Equilibrio de carga: los nodos cliente pueden asignar solicitudes de consulta a diferentes nodos de datos para lograr el equilibrio de carga y mejorar el rendimiento de las consultas.
-
Conmutación por error: si un nodo de datos falla, el nodo cliente puede cambiar automáticamente las solicitudes de consulta a otros nodos en buen estado para garantizar la disponibilidad del servicio.
Fragmentación
En un clúster de Elasticsearch, los datos se dividen en varios fragmentos para su almacenamiento y administración. Cada fragmento es un índice de Lucene independiente que contiene 一部分数据和索引信息. La fragmentación se puede distribuir y replicar en diferentes nodos del clúster para lograrlo 高可用性和数据冗余.
Cada índice se puede dividir en varios fragmentos primarios y varios fragmentos de réplica. El fragmento primario es la unidad básica del índice y contiene parte de los datos y la información del índice. Cada fragmento principal es un índice de Lucene independiente que se puede almacenar en cualquier nodo del clúster. Los fragmentos de réplica son copias de fragmentos primarios y se utilizan para mejorar la eficiencia y la disponibilidad de las consultas.
El número de fragmentos se especifica cuando se crea el índice y no se puede cambiar una vez creado. Normalmente, 主分片的数量应该与集群中的数据节点数量相匹配para garantizar que cada nodo pueda almacenar una determinada cantidad de fragmentos.
Comunicación entre nodos
En un clúster de Elasticsearch, los nodos se comunican entre sí a través de la red. Cada nodo tiene un nombre de nodo único, que Elasticsearch genera automáticamente. Los nombres de los nodos suelen tener el siguiente formato:
<host>-<uuid>
Entre ellos, host es el nombre de host donde se encuentra el nodo y uuid es un identificador único que se utiliza para garantizar la unicidad del nombre del nodo.
La comunicación entre nodos puede ocurrir de dos maneras: protocolo HTTP y protocolo de transporte. El protocolo HTTP es el protocolo predeterminado de Elasticsearch y se utiliza para manejar solicitudes de API RESTful. El protocolo de transporte es un protocolo utilizado internamente por el clúster de Elasticsearch para la comunicación directa entre nodos.
Estado del clúster
El estado del clúster de Elasticsearch se puede dividir en los siguientes tres tipos:
-
Verde: el clúster es normal y todos los fragmentos primarios y réplicas están disponibles.
-
Amarillo: el clúster está parcialmente disponible, todos los fragmentos principales están disponibles, pero algunos fragmentos de réplica no están disponibles.
-
Rojo: el clúster no está disponible y al menos un fragmento principal no está disponible.
Cuando falla un nodo en un clúster de Elasticsearch, el nodo maestro elimina automáticamente el nodo fallido del clúster y redistribuye los fragmentos asignados al nodo a otros nodos. Una vez que el nodo fallido vuelve a la normalidad
, se volverá a unir al clúster y redistribuirá los fragmentos para garantizar la integridad y disponibilidad de los datos.
La arquitectura de clúster de Elasticsearch proporciona alta escalabilidad y disponibilidad para búsqueda y almacenamiento de datos a gran escala, lo que la hace ideal para manejar necesidades complejas de búsqueda y análisis. Al comprender los diferentes componentes y funciones de la arquitectura del clúster, podrá planificar y gestionar mejor su clúster de Elasticsearch para satisfacer las necesidades empresariales.
2. Implementación del clúster Elasticsearch
2.1 Modificación de la configuración del sistema
2.1.1 Modificar el número de identificadores de archivos y subprocesos
Para evitar errores causados por permisos bajos en descriptores de archivos creables propiedad del usuario de Elasticsearch, debe modificar la cantidad de identificadores de archivos y subprocesos. Edite /etc/security/limits.confel archivo y agregue el siguiente contenido:
# 文件句柄
es soft nofile 65536
es hard nofile 65536
# 线程
es soft nproc 4096
es hard nproc 4096
保存退出后,需要重新启动系统
La configuración anterior es para resolver:
Informe de error: el número máximo de descriptores de archivos [4096] para el proceso de elasticsearch es demasiado bajo, aumente al menos a [65535]
Descripción del problema: el usuario de elasticsearch tiene permisos demasiado bajos para crear descripciones de archivos, se requiere al menos 65536;
2.1.2 Modificar la memoria virtual
Edite /etc/sysctl.confel archivo y agregue el siguiente contenido:
vm.max_map_count=262144
Después de guardar y salir, actualice el archivo de configuración:
sysctl -p
Verifique si la modificación fue exitosa:
sysctl vm.max_map_count
La configuración anterior es para resolver
el problema de error: las áreas máximas de memoria virtual vm.max_map_count [65530] son demasiado bajas, aumente al menos a [262144]
2.1.3 Cerrar espacio de intercambio (Swap)
Recomendación oficial: dé la mitad de la memoria a Lucene + y no exceda los 32G + apague el intercambio.
ES recomienda apagar el espacio de intercambio de la memoria de intercambio y deshabilitar el intercambio. Porque cuando la memoria se intercambia en el disco, una operación de 100 microsegundos puede convertirse en 10 milisegundos, y luego se suma el retraso de la operación de 100 microsegundos. Se puede ver que el intercambio tiene un impacto fatal en el rendimiento.
vim /etc/fstab
El comentario contiene la línea de intercambio.
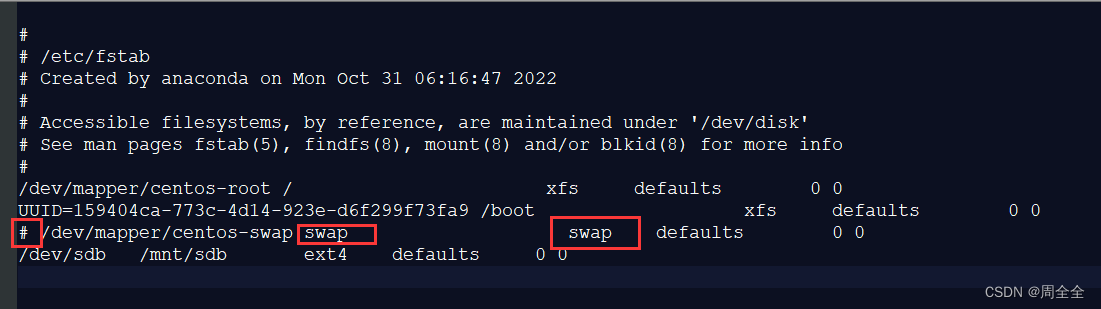
Antes del comentario:

保存退出后需要系统重启!
Después del comentario:

2.2 Descargue la base de datos es y cárguela en el servidor
Descargue Elasticsearch 7.17.11 , cárguelo en el servidor y use el siguiente comando para descomprimir Elasticsearch:
cd /mnt/data/es-cluster
tar -zxvf elasticsearch-7.17.11-linux-x86_64.tar.gz
Haz 3 copias y nómbralas de la siguiente manera:

2.3 Modificar el archivo de configuración del clúster
2.3.1 descripción del elemento de configuración elasticsearch.yml
| Elementos de configuración | Instrucciones de configuración | Ejemplo de configuración |
|---|---|---|
| nombre.clúster | Nombre del clúster | es-cluster |
| nombre del nodo | Nombre del nodo | nodo1 |
| ruta.datos | directorio de datos | /home/es/ruta/nodo/datos |
| ruta.logs | Directorio de registro | /home/es/ruta/nodo/logs |
| nombre del nodo | Nombre del nodo | nodo1 |
| red.host | Vincular dirección IP | 127.0.0.1 |
| http.puerto | Especificar el puerto de acceso al servicio | 9201 |
| transporte.tcp.puerto | Especificar el puerto de llamada del cliente API | 9301 |
| descubrimiento.seed_hosts | Dirección de comunicación del clúster | [“127.0.0.1:9301”, “127.0.0.1:9301:9302”, “127.0.0.1:9301:9303”] |
| cluster.initial_master_nodes | Información del nodo que se puede seleccionar para la inicialización del clúster | [“127.0.0.1:9301”, “127.0.0.1:9301:9302”, “127.0.0.1:9301:9303”] |
| http.cors.enabled | Habilitar el soporte de acceso entre dominios | verdadero |
| http.cors.allow-origin | Nombres de dominio permitidos para acceso entre dominios | “*” |
Las asignaciones de puertos son las siguientes:
| Anfitrión | Nombre del nodo | puerto HTTP | Puerto de transporte |
|---|---|---|---|
| 192.168.0.119 | nodo1 | 9201 | 9301 |
| 192.168.0.119 | nodo2 | 9202 | 9302 |
| 192.168.0.119 | nodo3 | 9203 | 9303 |
2.3.2 Modificar la información de configuración del nodo nodo1
vim /mnt/data/es-cluster/elasticsearch-7.17.11-node1/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node1
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node1/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node1/logs
# 指定服务访问端口
http.port: 9201
# 指定API端户端调用端口
transport.tcp.port: 9301
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.3.2 Modificar la información de configuración del nodo nodo2
vim /mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node2
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node2/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node2/logs
# 指定服务访问端口
http.port: 9202
# 指定API端户端调用端口
transport.tcp.port: 9302
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.3.3 Modificar la información de configuración del nodo nodo3
vim /mnt/sdb/es-cluster/elasticsearch-7.17.11-node3/config/elasticsearch.yml
elasticsearch.yml
# 集群名称
cluster.name: es-cluster
#节点名称
node.name: node3
# 绑定IP地址
network.host: 192.168.0.119
# 数据目录
path.data: /mnt/data/es-cluster/elasticsearch-7.17.11-node3/data
# 日志目录
path.logs: /mnt/data/es-cluster/elasticsearch-7.17.11-node3/logs
# 指定服务访问端口
http.port: 9203
# 指定API端户端调用端口
transport.tcp.port: 9303
#集群通讯地址
discovery.seed_hosts: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#集群初始化能够参选的节点信息
cluster.initial_master_nodes: ["192.168.0.119:9301", "192.168.0.119:9302","192.168.0.119:9303"]
#开启跨域访问支持,默认为false
http.cors.enabled: true
##跨域访问允许的域名, 允许所有域名
http.cors.allow-origin: "*"
# 单机启动es实例的个数
node.max_local_storage_nodes: 3
2.4 Crear usuarios y grupos de Elasticsearch
Cree un usuario llamado "es" y un grupo llamado "es" y agregue el usuario al grupo:
# 新建群组es
groupadd es
# 新建用户es并指定群组为es
useradd -g es es
# 设置用户密码
passwd es
# usermod 将用户添加到某个组group
usermod -aG root es
2.5 Establecer permisos de directorio
Establezca el usuario y grupo al que pertenece el directorio del clúster de Elasticsearch:
chown -R es:es /mnt/data/es-cluster
2.6 Iniciar el servicio Elasticsearch
2.6.1 Configurar la memoria de inicio (opcional)
Si el tamaño de la memoria de una sola máquina es limitado, puede configurar el tamaño de la memoria de inicio de es. Ingrese al directorio /config de los tres nodos respectivamente, ejecute vim jvm.optionsy modifique la configuración.
-Xms512m
-Xmx512m
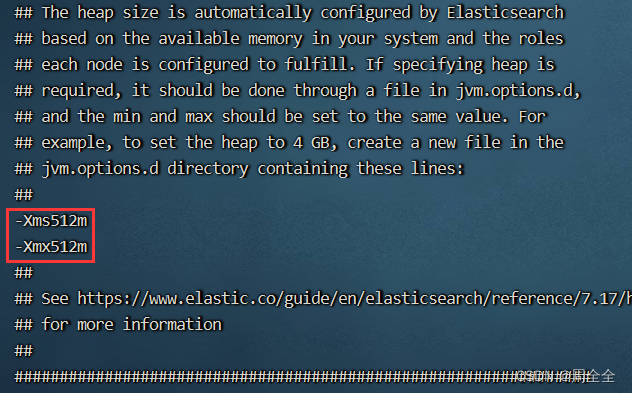
2.6.2 Crear scripts para iniciar y detener servicios
Cree 三个es节点un script para iniciar y detener el servicio Elasticsearch
( 注意当前目录是在 ../elasticsearch-7.17.11-node1)
-
comienza-single.sh
#!/bin/bash cd "$(dirname "$0")" # -d:后台(daemon)方式运行 Elasticsearch ./bin/elasticsearch -d -p pid -
stopes-single.sh
#!/bin/bash cd "$(dirname "$0")" if [ -f "pid" ]; then pkill -F pid fi -
Conceder permisos de ejecución:
chmod 755 startes-single.sh stopes-single.sh chown es:es startes-single.sh stopes-single.sh -
Inicie el servicio Elasticsearch como usuario de Elasticsearch:
su es cd /mnt/sdb/es-cluster/elasticsearch-7.17.11-node1 ./startes-single.sh
Posibles errores:
- no se pudieron obtener los bloqueos de nodo, intenté [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] con ID de bloqueo [0]; tal vez estas ubicaciones no se puedan escribir o se iniciaron varios nodos sin aumentar
][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [node2] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:173) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:160) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112) ~[elasticsearch-cli-7.17.11.jar:7.17.11]
at org.elasticsearch.cli.Command.main(Command.java:77) ~[elasticsearch-cli-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:125) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80) ~[elasticsearch-7.17.11.jar:7.17.11]
Caused by: java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:328) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.node.Node.<init>(Node.java:429) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.node.Node.<init>(Node.java:309) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434) ~[elasticsearch-7.17.11.jar:7.17.11]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:169) ~[elasticsearch-7.17.11.jar:7.17.11]
... 6 more
uncaught exception in thread [main]
java.lang.IllegalStateException: failed to obtain node locks, tried [[/mnt/sdb/es-cluster/elasticsearch-7.17.11-node2/data]] with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing [node.max_local_storage_nodes] (was [1])?
at org.elasticsearch.env.NodeEnvironment.<init>(NodeEnvironment.java:328)
at org.elasticsearch.node.Node.<init>(Node.java:429)
at org.elasticsearch.node.Node.<init>(Node.java:309)
at org.elasticsearch.bootstrap.Bootstrap$5.<init>(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:234)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:434)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:169)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:160)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:77)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:112)
at org.elasticsearch.cli.Command.main(Command.java:77)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:125)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:80)
Solución: agregue: node.max_local_storage_nodes: 3 al archivo de configuración.
Esta configuración limita la cantidad de instancias de almacenamiento ES que se pueden abrir en un solo nodo. Si necesita iniciar varias instancias en una sola máquina, debe escribir esta configuración en el archivo de configuración y asignar un valor de 2 o superior a esta configuración.
2.7 Abrir puertos de firewall
CentOS
# 查看防火墙状态
systemctl status firewalld
# 查看开放的端口
firewall-cmd --query-port=9200/tcp
# 添加端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent
# 重载防火墙
firewall-cmd --reload
# 再次查看端口是否已经开放
firewall-cmd --query-port=9200/tcp
ubuntu
# 查看防火墙状态
sudo ufw status
# 开放端口 9200
sudo ufw allow 9200/tcp
# 查看已添加的规则
sudo ufw status numbered
# 查看防火墙状态
sudo ufw status
2.8 Ver el estado de inicio de es
- Acceda a los puertos http de tres nodos respectivamente
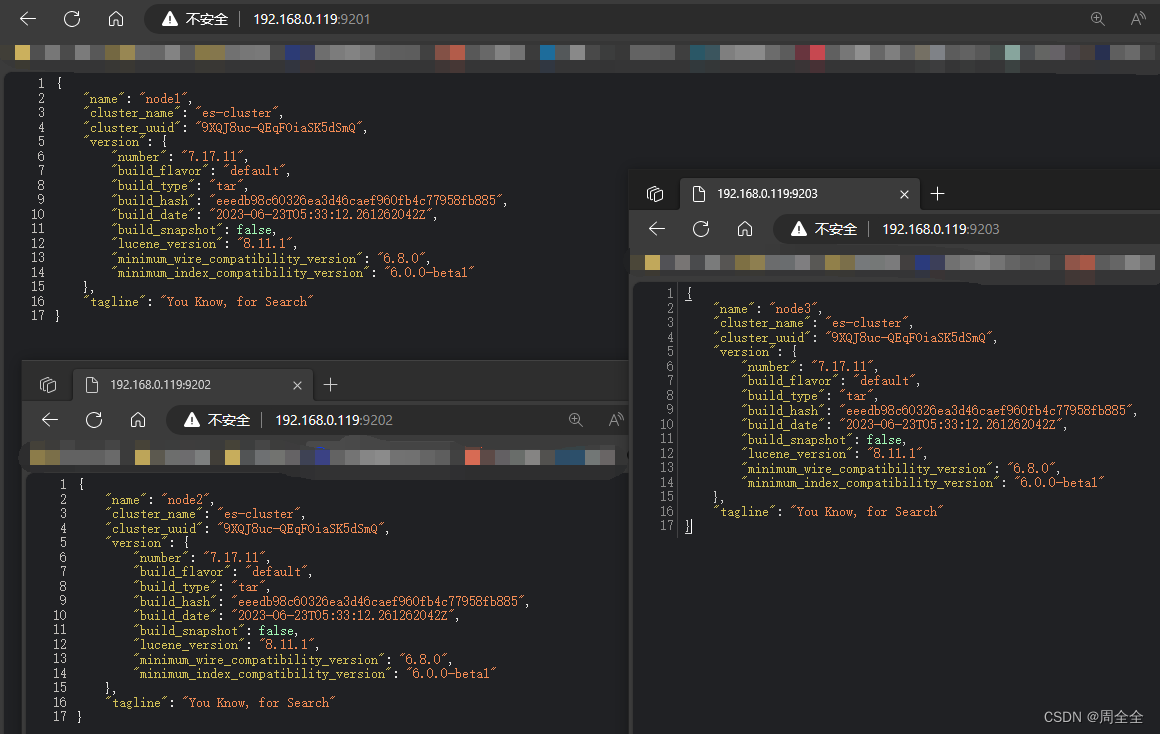
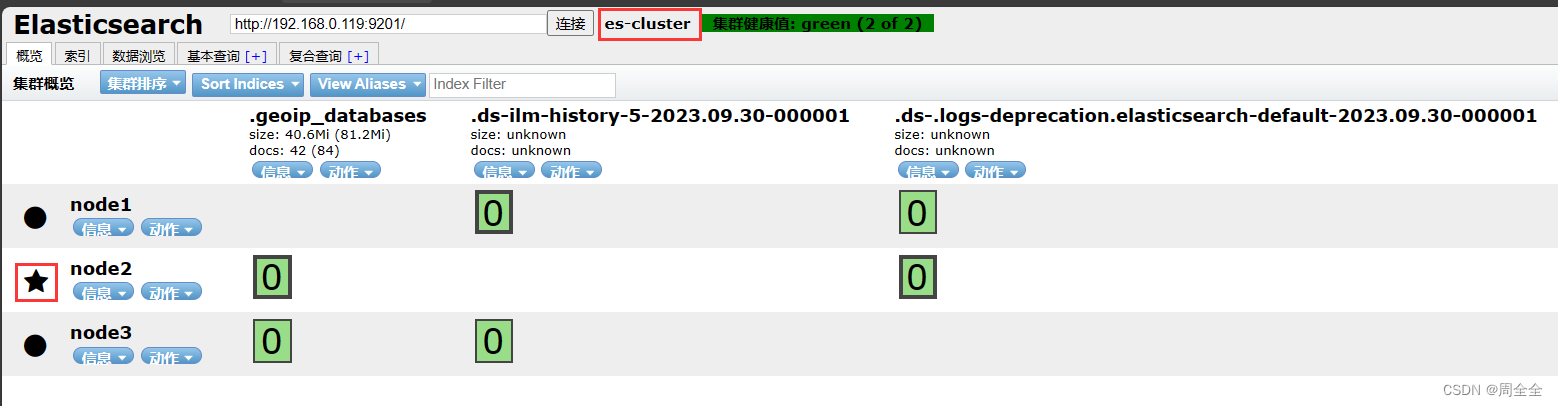
- Ver el estado del nodo
http://192.168.0.119:9201/_cat/nodes?pretty
Puede ver la información de tres nodos, y los tres nodos elegirán el nodo maestro por sí solos (ES es una implementación mejorada basada en el algoritmo de elección Bully)
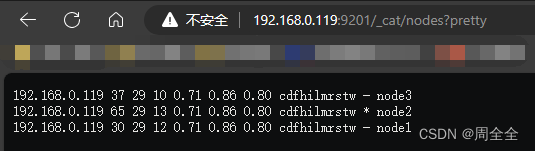
- Ver el estado de salud del clúster
http://192.168.0.119:9201/_cluster/health?pretty
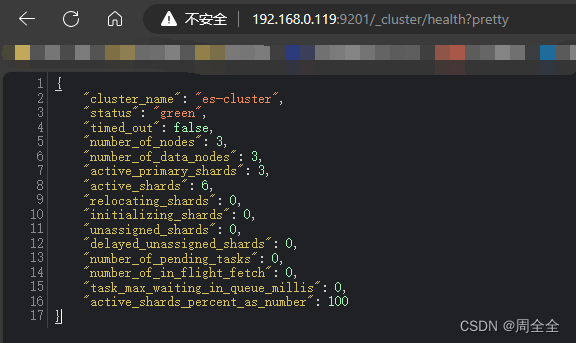
4.Vista del encabezado de Elasticsearch