Principios y conceptos básicos de HAProxy
1. Introducción básica
https://www.haproxy.org/ (sitio web oficial)
https://www.haproxy.org/download/1.8/src/haproxy-1.8.14.tar.gz (enlace de descarga)
http://cbonte.github.io/haproxy-dconv/1.8/configuration.html (documento documento Haproxy 1.8)
HAProxy proporciona alta disponibilidad, balanceo de carga y proxy basado en aplicaciones TCP y HTTP, y soporta hosts virtuales, es una solución gratuita, rápida y confiable. HAProxy es especialmente adecuado para sitios web con cargas pesadas, que generalmente requieren retención de sesión o procesamiento de siete capas. HAProxy se ejecuta en hardware actual y puede admitir por completo decenas de miles de conexiones simultáneas. Y su modo de funcionamiento hace que sea fácil y seguro integrarse en su arquitectura actual, mientras protege su servidor web de estar expuesto a la red.
HAProxy implementa un modelo de proceso único impulsado por eventos que admite una gran cantidad de conexiones simultáneas. Los modelos multiproceso o multiproceso están limitados por limitaciones de memoria, limitaciones del programador del sistema y limitaciones de bloqueo ubicuas, y rara vez pueden manejar miles de conexiones simultáneas. El modelo impulsado por eventos realiza todo esto en el User-Space con una mejor gestión de recursos y tiempo.
Dos, el tipo de equilibrio de carga
(1) Sin equilibrio de carga: un entorno de aplicación web simple sin equilibrio de carga puede tener el siguiente aspecto

En este ejemplo, el usuario se conecta directamente a su servidor web, en sudominio.com, y no hay equilibrio de carga. Si su único servidor web falla, los usuarios ya no podrán acceder a su servidor web. Además, si muchos usuarios intentan acceder a su servidor al mismo tiempo y no pueden manejar la carga, es posible que experimenten una experiencia lenta o que no puedan conectarse en absoluto.
(2) Equilibrio de carga de 4 capas:
La forma más sencilla de equilibrar la carga del tráfico de red a varios servidores es utilizar el equilibrio de carga de la capa 4 (capa de transporte). El equilibrio de carga de esta manera reenviará el tráfico del usuario según el rango de IP y el puerto (es decir, si la solicitud va a http://yourdomain.com/anything , el tráfico se reenviará al backend que maneja todas las solicitudes para yourdomain.com . El puerto 80 ).
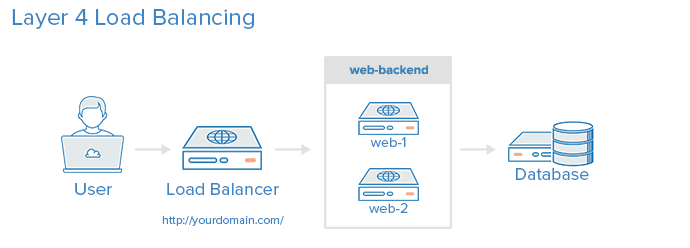
El usuario accede al equilibrador de carga y el equilibrador de carga reenvía la petición del usuario a la secundaria de web grupo del servidor de backend . Independientemente del servidor back-end que se seleccione, responderá directamente a la solicitud del usuario. Por lo general, todos los servidores del backend web deben proporcionar el mismo contenido; de lo contrario, los usuarios pueden recibir contenido incoherente.
(3) Equilibrio de carga de capa 7:
El equilibrio de carga de la capa 7 es un método más complejo para equilibrar la carga del tráfico de red y es utilizar el equilibrio de carga de la capa 7 (capa de aplicación). El uso de la capa 7 permite que el equilibrador de carga reenvíe solicitudes a diferentes servidores back-end en función de lo que solicite el usuario. Este modo de equilibrio de carga le permite ejecutar varios servidores de aplicaciones web bajo el mismo dominio y puerto.
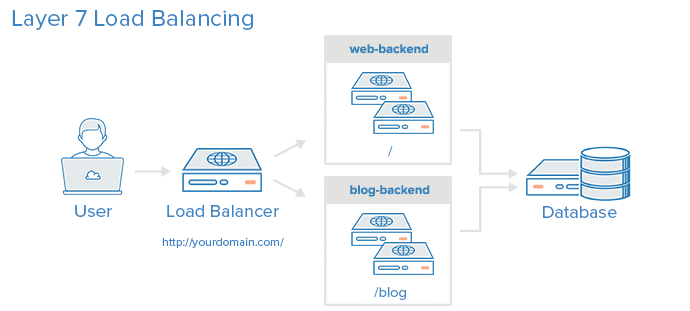
En el ejemplo, si un usuario solicita yourdomain.com/blog , se reenviará al backend del blog , que es un conjunto de servidores que ejecutan aplicaciones de blog. Otras solicitudes se reenvían al backend web y es posible que el backend esté ejecutando otra aplicación.
3. Explicación detallada del archivo de configuración básica de HAProxy:
La configuración de haproxy se divide en cinco partes, como sigue:
- global: Establece los parámetros de configuración global, que pertenecen a la configuración del proceso, generalmente relacionados con el sistema operativo.
- valores predeterminados: configure los parámetros predeterminados, estos parámetros se pueden usar en componentes frontend, backend y Listen;
- frontend: El nodo virtual de front-end que recibe la solicitud. Frontend puede especificar directamente el backend que usa el backend más reglas;
- backend: la configuración del clúster de servicios de backend es un servidor real, y un backend corresponde a uno o más servidores físicos;
- Escuche: una combinación de frontend y backend.
Archivo de configuración detallado de HAProxy:
global # 全局参数的设置
log 127.0.0.1 local0 info
# log语法:log <address_1>[max_level_1] # 全局的日志配置,使用log关键字,指定使用127.0.0.1上的syslog服务中的local0日志设备,记录日志等级为info的日志
user haproxy
group haproxy
# 设置运行haproxy的用户和组,也可使用uid,gid关键字替代之
daemon
# 以守护进程的方式运行
nbproc 16
# 设置haproxy启动时的进程数,根据官方文档的解释,我将其理解为:该值的设置应该和服务器的CPU核心数一致,即常见的2颗8核心CPU的服务器,即共有16核心,则可以将其值设置为:<=16 ,创建多个进程数,可以减少每个进程的任务队列,但是过多的进程数也可能会导致进程的崩溃。这里我设置为16
maxconn 4096
# 定义每个haproxy进程的最大连接数 ,由于每个连接包括一个客户端和一个服务器端,所以单个进程的TCP会话最大数目将是该值的两倍。
#ulimit -n 65536
# 设置最大打开的文件描述符数,在1.4的官方文档中提示,该值会自动计算,所以不建议进行设置
pidfile /var/run/haproxy.pid
# 定义haproxy的pid
defaults # 默认部分的定义
mode http
# mode语法:mode {http|tcp|health} 。http是七层模式,tcp是四层模式,health是健康检测,返回OK
log 127.0.0.1 local3 err
# 使用127.0.0.1上的syslog服务的local3设备记录错误信息
retries 3
# 定义连接后端服务器的失败重连次数,连接失败次数超过此值后将会将对应后端服务器标记为不可用
option httplog
# 启用日志记录HTTP请求,默认haproxy日志记录是不记录HTTP请求的,只记录“时间[Jan 5 13:23:46] 日志服务器[127.0.0.1] 实例名已经pid[haproxy[25218]] 信息[Proxy http_80_in stopped.]”,日志格式很简单。
option redispatch
# 当使用了cookie时,haproxy将会将其请求的后端服务器的serverID插入到cookie中,以保证会话的SESSION持久性;而此时,如果后端的服务器宕掉了,但是客户端的cookie是不会刷新的,如果设置此参数,将会将客户的请求强制定向到另外一个后端server上,以保证服务的正常。
option abortonclose
# 当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
option dontlognull
# 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器或者监控系统为了探测该服务是否存活可用时,需要定期的连接或者获取某一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接;官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来
option httpclose
# 这个参数我是这样理解的:使用该参数,每处理完一个request时,haproxy都会去检查http头中的Connection的值,如果该值不是close,haproxy将会将其删除,如果该值为空将会添加为:Connection: close。使每个客户端和服务器端在完成一次传输后都会主动关闭TCP连接。与该参数类似的另外一个参数是“option forceclose”,该参数的作用是强制关闭对外的服务通道,因为有的服务器端收到Connection: close时,也不会自动关闭TCP连接,如果客户端也不关闭,连接就会一直处于打开,直到超时。
contimeout 5000
# 设置成功连接到一台服务器的最长等待时间,默认单位是毫秒,新版本的haproxy使用timeout connect替代,该参数向后兼容
clitimeout 3000
# 设置连接客户端发送数据时的成功连接最长等待时间,默认单位是毫秒,新版本haproxy使用timeout client替代。该参数向后兼容
srvtimeout 3000
# 设置服务器端回应客户度数据发送的最长等待时间,默认单位是毫秒,新版本haproxy使用timeout server替代。该参数向后兼容
listen status # 定义一个名为status的部分
bind 0.0.0.0:1080
# 定义监听的套接字
mode http
# 定义为HTTP模式
log global
# 继承global中log的定义
stats refresh 30s
# stats是haproxy的一个统计页面的套接字,该参数设置统计页面的刷新间隔为30s
stats uri /admin?stats
# 设置统计页面的uri为/admin?stats
stats realm Private lands
# 设置统计页面认证时的提示内容
stats auth admin:password
# 设置统计页面认证的用户和密码,如果要设置多个,另起一行写入即可
stats hide-version
# 隐藏统计页面上的haproxy版本信息
frontend http_80_in # 定义一个名为http_80_in的前端部分
bind 0.0.0.0:80
# http_80_in定义前端部分监听的套接字
mode http
# 定义为HTTP模式
log global
# 继承global中log的定义
option forwardfor
# 启用X-Forwarded-For,在requests头部插入客户端IP发送给后端的server,使后端server获取到客户端的真实IP
acl static_down nbsrv(static_server) lt 1
# 定义一个名叫static_down的acl,当backend static_sever中存活机器数小于1时会被匹配到
acl php_web url_reg /*.php$
#acl php_web path_end .php
# 定义一个名叫php_web的acl,当请求的url末尾是以.php结尾的,将会被匹配到,上面两种写法任选其一
acl static_web url_reg /*.(css|jpg|png|jpeg|js|gif)$
#acl static_web path_end .gif .png .jpg .css .js .jpeg
# 定义一个名叫static_web的acl,当请求的url末尾是以.css、.jpg、.png、.jpeg、.js、.gif结尾的,将会被匹配到,上面两种写法任选其一
use_backend php_server if static_down
# 如果满足策略static_down时,就将请求交予backend php_server
use_backend php_server if php_web
# 如果满足策略php_web时,就将请求交予backend php_server
use_backend static_server if static_web
# 如果满足策略static_web时,就将请求交予backend static_server
backend php_server #定义一个名为php_server的后端部分
mode http
# 设置为http模式
balance source
# 设置haproxy的调度算法为源地址hash
cookie SERVERID
# 允许向cookie插入SERVERID,每台服务器的SERVERID可在下面使用cookie关键字定义
option httpchk GET /test/index.php
# 开启对后端服务器的健康检测,通过GET /test/index.php来判断后端服务器的健康情况
server php_server_1 10.12.25.68:80 cookie 1 check inter 2000 rise 3 fall 3 weight 2
server php_server_2 10.12.25.72:80 cookie 2 check inter 2000 rise 3 fall 3 weight 1
server php_server_bak 10.12.25.79:80 cookie 3 check inter 1500 rise 3 fall 3 backup
# server语法:server [:port] [param*] # 使用server关键字来设置后端服务器;为后端服务器所设置的内部名称[php_server_1],该名称将会呈现在日志或警报中、后端服务器的IP地址,支持端口映射[10.12.25.68:80]、指定该服务器的SERVERID为1[cookie 1]、接受健康监测[check]、监测的间隔时长,单位毫秒[inter 2000]、监测正常多少次后被认为后端服务器是可用的[rise 3]、监测失败多少次后被认为后端服务器是不可用的[fall 3]、分发的权重[weight 2]、最后为备份用的后端服务器,当正常的服务器全部都宕机后,才会启用备份服务器[backup]
backend static_server
mode http
option httpchk GET /test/index.html
server static_server_1 10.12.25.83:80 cookie 3 check inter 2000 rise 3 fall 3
--------------------- Reimpreso: principios y conceptos básicos de HAProxy