Al recopilar contenido en PHP, utilicé el componente de colección querylist, pero cuando este complemento recopila contenido de la página, debe escribir un selector de colección. Esto es más problemático: cada página de artículo debe especificar una regla de recopilación. Empecé a buscar un complemento que pudiera identificar y recopilar automáticamente el contenido de texto de la URL de cualquier artículo. Encontré un complemento que recopila etiquetas de contenido, divide cada etiqueta y puntúa para analizar el contenido de texto. A continuación se muestra la implementación. proceso y código.
Primero eche un vistazo a la captura de pantalla:
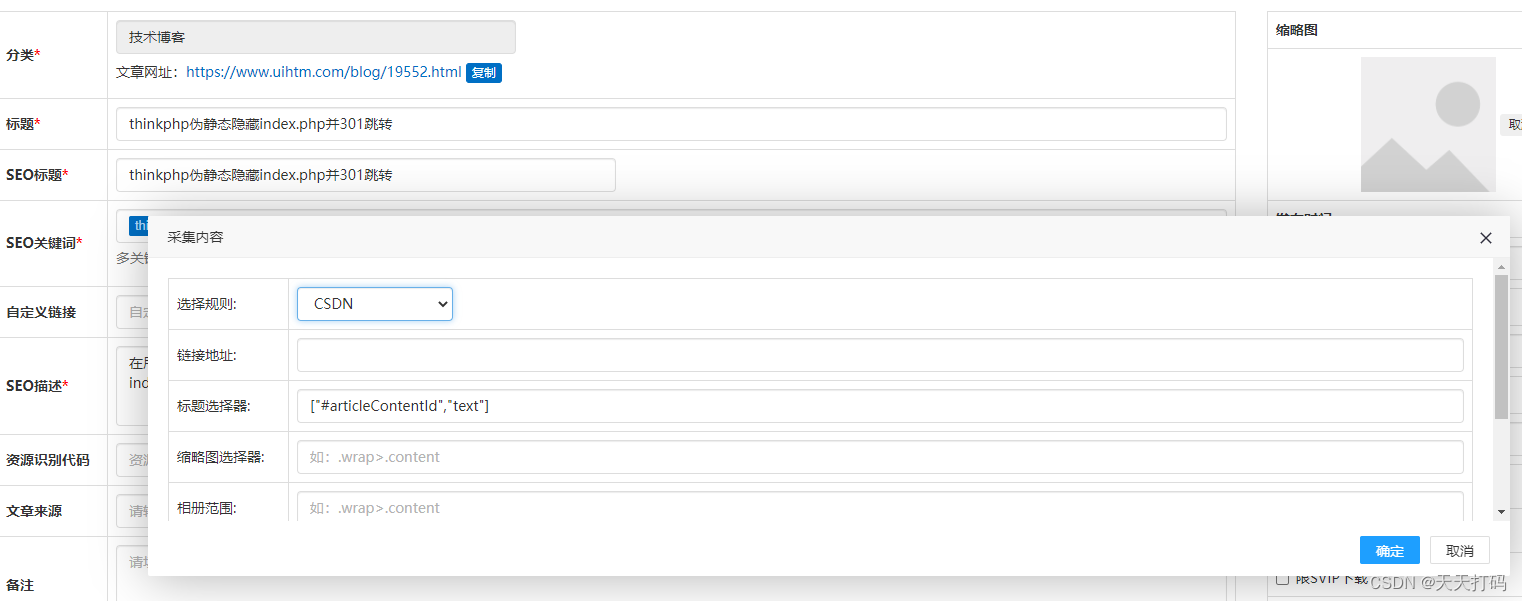
código de colección:
try{
$ql = QueryList::get($url);
}catch(RequestException $e){
//print_r($e->getRequest());
return json(['status'=>false,'msg'=>'Http Error:服务器错误,url不存在']);die;
}
//queryData 方法等同于 query()->getData()->all()
//$query = $ql->rules($rules)->queryData();
$title_rule = json_decode(htmlspecialchars_decode($title_rule),true);
$content_rule = json_decode(htmlspecialchars_decode($content_rule),true);
if($thumb_rule)
$thumb_rule = json_decode(htmlspecialchars_decode($thumb_rule),true);
$photos_range = htmlspecialchars_decode($photos_range);
if(is_array($content_rule)&&is_array($title_rule))
{
$rules = [
'title' => $title_rule,
'seo_title' => ['title','text'],
'keywords' => ['meta[name=keywords]','content'],
'description' => ['meta[name=description]','content'],
'content' => $content_rule,
'thumb' => $thumb_rule
];
if(empty($thumb_rule))
unset($rules['thumb']);
}
else
{
$rules = [
'title' => ['h1','text'],
'seo_title' => ['title','text'],
'keywords' => ['meta[name=keywords]','content'],
'description' => ['meta[name=description]','content'],
'content' => [$content_rule,'html','-a -ul -li -.group-post-list'],
'thumb' => [$thumb_rule,'src']
];
}
$query = $ql->rules($rules)->queryData();
Estas reglas de escritura deben establecerse para cada página. Es problemático. ¿Existe un componente que pueda identificar y recopilar automáticamente el contenido de texto de cualquier URL? Veamos primero el efecto. Solo necesita ingresar al sitio web de un
artículo y complemento que se utiliza principalmente para
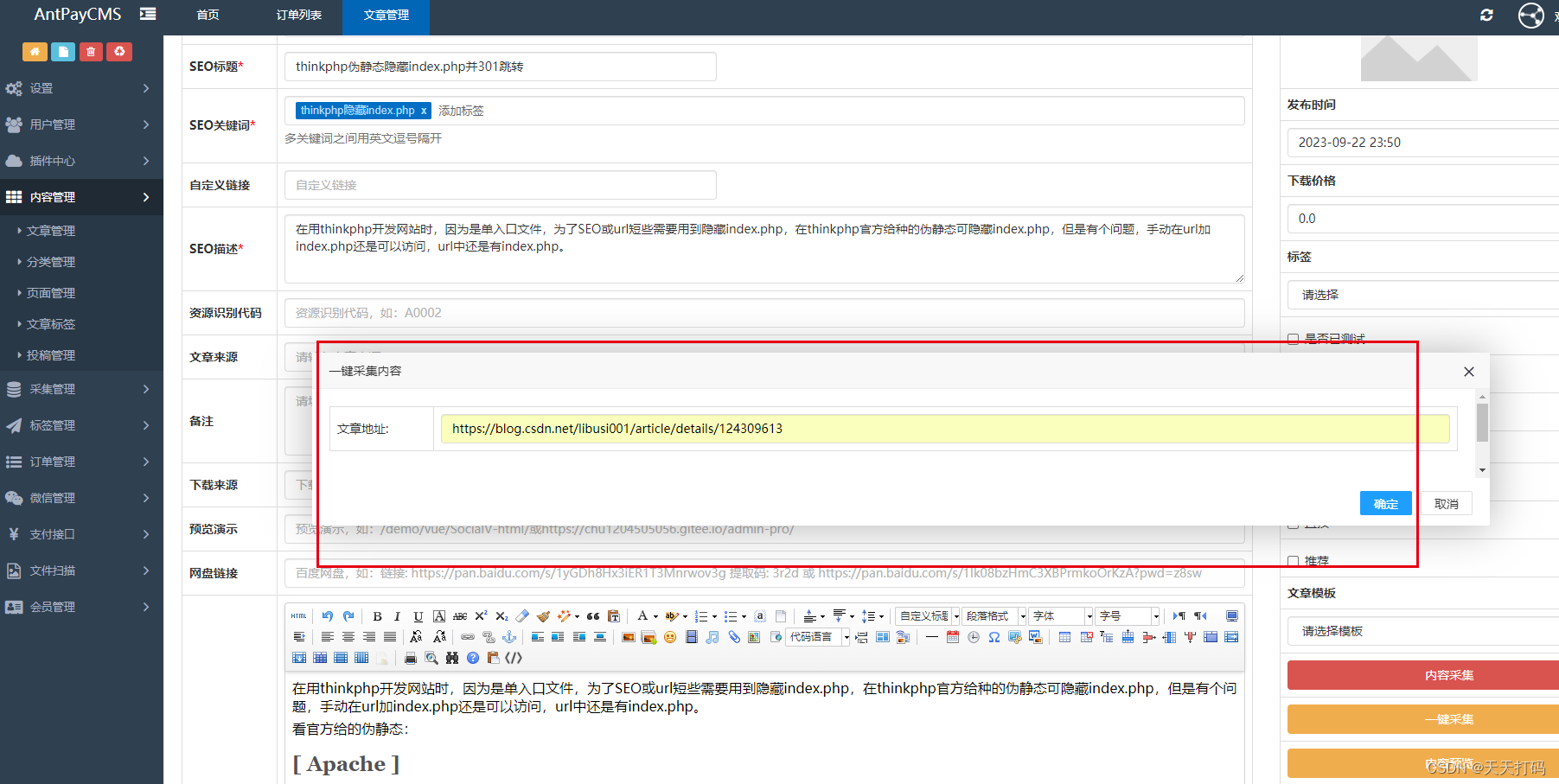
identificar automáticamente el contenido del texto y recopilar código:
$html = file_get_contents($url);
$readability = new Readability(new Configuration());
$readability->parse($html);
$data['title'] = $readability->getTitle();
$data['seo_title'] = $readability->getTitle();