1.java
(1) Colección
1.list: Lista enlazada, Lista de matrices y Vector
- Clase de implementación de interfaz LinkedList, lista vinculada, inserción y eliminación, sin sincronización, subprocesos inseguros
- Clase de implementación de interfaz ArrayList, matriz, acceso aleatorio, sin sincronización, subprocesos inseguros
- La interfaz vectorial implementa una matriz, sincronizada y segura para subprocesos.
2.conjunto: HashSet y TreeSet
- HashSet usa una tabla hash para almacenar elementos y los elementos pueden ser nulos
- LinkedHashSet mantiene el orden de inserción de elementos en una lista vinculada
- La implementación subyacente de TreeSet es un árbol rojo-negro, los elementos están ordenados y los elementos no pueden ser nulos.
3.map: HashMap, TreeMap y HashTable
- Seguridad del hilo
- HshaMap no es seguro
- TreeMap no es seguro para
- Seguridad de subprocesos de HashTable
- valor nulo
- HashMap tiene una clave nula y múltiples valores nulos
- TreeMap no puede tener una clave nula ni varios valores nulos.
- HashTable no puede contener nulo
- Herencia e interfaces
- HashMap hereda AbstractMap e implementa la interfaz Map
- TreeMap hereda AbstractMap e implementa la interfaz NavigableMap (un tipo de SortMap)
- HashTable hereda el Diccionario e implementa la interfaz Mapa
- orden
- Las claves en HashMap están desordenadas
- TreeMap está ordenado
- HashTable está desordenada
- Constructor
- HashMap ha ajustado la capacidad inicial y el factor de carga
- TreeMap no
- HashTable有
- estructura de datos
- HashMap es lista vinculada + matriz + árbol rojo-negro
- TreeMap es un árbol rojo-negro
- HashTable es una lista vinculada + matriz
4.La diferencia entre lista, conjunto y mapa.
- lista: los elementos se guardan en orden según el orden de entrada, repetible
- conjunto: no repetible y ordenado internamente
- mapa: representa un conjunto con una relación de mapeo, todas sus claves son una colección de Conjunto, es decir, las claves están desordenadas y no se pueden repetir.
5.Mecanismo de expansión HashMap
- La capacidad inicial de la matriz es 16 y la capacidad se expande a la potencia de 2. Una es usar una matriz lo suficientemente grande para mejorar el rendimiento y la otra es usar operaciones de bits en lugar de presupuesto de módulo (se dice que es mejorado de 5 a 8 veces).
- La necesidad de expandir la matriz está determinada por el factor de carga. Si el número actual de elementos es 0,75 de la capacidad de la matriz, la matriz se expandirá. Este 0,75 es el factor de carga predeterminado y el constructor puede pasarlo. También podemos establecer un factor de carga mayor que 1 para que la matriz no se expanda, sacrificando rendimiento y ahorrando memoria.
- Para resolver colisiones, los elementos de la matriz son del tipo lista enlazada unidireccional. Cuando la longitud de la lista vinculada alcanza un umbral (7 u 8), la lista vinculada se convertirá en un árbol rojo-negro para mejorar el rendimiento. Cuando la longitud de la lista vinculada se reduce a otro umbral (6), el árbol rojo-negro se convertirá nuevamente en una lista vinculada unidireccional para mejorar el rendimiento.
- Como complemento al tercer punto, antes de verificar la longitud de la lista vinculada y convertirla en un árbol rojo-negro, también verificará primero si la matriz actual alcanza un umbral (64), si no alcanza esta capacidad, se abandonará la conversión y la matriz se expandirá primero. Por eso también se dijo anteriormente que el umbral de longitud de la lista vinculada es 7 u 8, porque habrá una operación para abandonar la conversión.
6. ¿Cómo se genera la lista circular enlazada en HashMap (jdk1.7)?
¿Cómo se forma una lista circular enlazada en HashMap?
- Dado que el método de inserción de encabezado se usa en jdk1.7, en subprocesos múltiples, hay situaciones en las que dos subprocesos expanden la lista vinculada al mismo tiempo. La ejecución de la función de transferencia (transferencia de datos de la lista vinculada) hará que los datos de la lista vinculada sean invertido Cuando dos subprocesos hacen esto al mismo tiempo, provocará un bucle infinito en la lista enlazada.
7. La diferencia entre el árbol B y el árbol B+
- El árbol B evoluciona a partir del árbol de clasificación binaria; el árbol B+ evoluciona a partir de la búsqueda de bloques.
- Los nodos hoja B+ contienen todos los datos, los nodos que no son hoja solo sirven como índices; los nodos terminales del árbol B y superiores contienen datos y no se repiten (los nodos hoja son solo un concepto y no existen)
- Los nodos de hoja B+ contienen todas las palabras clave
- El árbol B+ admite búsqueda secuencial y búsqueda multidireccional, el árbol B solo admite búsqueda multidireccional
8. ¿Por qué HashMap usa árboles rojo-negro en lugar de árboles AVL o árboles B+?
- Los árboles AVL están más estrictamente equilibrados y, por tanto, proporcionan búsquedas más rápidas. Por lo tanto, no hay nada de malo en utilizar árboles AVL para tareas de búsqueda intensiva. Pero para tareas intensivas en inserción, los árboles rojo-negro son mejores.
- Los nodos del árbol B / B + pueden almacenar múltiples datos. Cuando la cantidad de datos no es lo suficientemente grande, los datos se "amontonarán" en un nodo y la eficiencia de la consulta se degradará a una lista vinculada.
9.Principio de CopyOnWriteArrayList
Uso de CopyOnWriteArrayList y análisis de principios
- No hay restricción de bloqueo cuando los subprocesos acceden simultáneamente para operaciones de lectura.
- Durante una operación de escritura, primero haga una copia del contenedor y luego realice la operación de escritura en la nueva copia. En este momento, la operación de escritura está bloqueada. Después de terminar, apunte la referencia del contenedor original al nuevo contenedor. Tenga en cuenta que durante el proceso de bloquear y realizar una operación de escritura, si se requiere una operación de lectura, se aplicará al contenedor original. Por lo tanto, las operaciones de escritura bloqueadas no afectarán las operaciones de lectura a las que se accede simultáneamente.
10. ¿Cuáles son los métodos en BlockingQueue?
- Un total de cuatro grupos de API de adición y eliminación
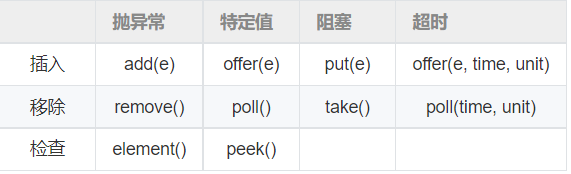
- Lanzar una excepción: si la operación no se puede ejecutar inmediatamente, se lanza una excepción;
- Valor específico: si la operación no se puede ejecutar inmediatamente, se devuelve un valor específico (normalmente verdadero/falso).
- Bloqueo: si la operación no se puede ejecutar inmediatamente, la llamada al método se bloqueará hasta que se pueda ejecutar;
- Tiempo de espera: si la operación no se puede realizar inmediatamente, la llamada al método se bloqueará hasta que se pueda realizar. Pero no esperará más que el valor dado y devuelve un valor específico para indicar si la operación fue exitosa (normalmente verdadero/falso).
(2) subprocesos múltiples
1. Estructuras de datos básicas de seguridad de subprocesos en Java
- cadena
- Tabla de picadillo
- Mapa de hash concurrente
- Copiar en escritura Lista de matrices
- Copiar en escrituraArraySet
- Vector
- cadenaBuffer
2. ¿Cuáles son las formas de crear un hilo?
- Herede la clase Thread, reescriba el método de ejecución y llame a start: new MyThread().start();
- Implemente la interfaz Runnable y reescriba el método de ejecución, new Thread(new MyRunnable()).start();
- Implemente la interfaz invocable y anule el método de llamada (con valor de retorno)
- Grupo de subprocesos
- Siete parámetros
- Número de hilos centrales
- Número máximo de hilos
- Tiempo de supervivencia del hilo inactivo
- unidad de tiempo
- cola de tareas
- fabrica de hilos
- Denegar política
- rechazar y lanzar excepción
- Negarse a ignorar tareas
- Abandonar la tarea del encabezado de la cola
- Regresar al hilo de llamada para su ejecución.
- Siete parámetros
3. Ciclo de vida del hilo
¿Cuál es el ciclo de vida de un hilo?
- Hay cinco estados de subprocesos: nuevo (nuevo), listo (inicio()), en ejecución (asignado a la CPU), bloqueado y muerto.
- La CPU cambia entre varios subprocesos, por lo que el estado del subproceso cambiará entre en ejecución y listo varias veces.
- Se produce un bloqueo
- El hilo llama al método sleep() para ceder activamente los recursos ocupados del procesador.
- El hilo llama a un método IO de bloqueo y se bloquea hasta que el método regresa.
- El subproceso intentó adquirir un monitor de sincronización, pero otro subproceso retenía el monitor de sincronización.
- El hilo está esperando una notificación (notificar)
- El programa llama al método suspender() del hilo para suspender el hilo. Sin embargo, este método puede conducir fácilmente a un punto muerto, por lo que debe evitarse en la medida de lo posible.
- Desbloquear y volver a entrar en el estado listo
- El hilo que llama al método sleep() ha transcurrido el tiempo especificado
- El método IO de bloqueo llamado por el hilo ha regresado.
- El subproceso adquirió con éxito el monitor de sincronización que intentó adquirir.
- Mientras un hilo espera una notificación, otro hilo emite una notificación.
- El hilo en estado suspendido tiene llamado al método de recuperación resume().
- La muerte ocurre
- Se ejecuta el método run() o call() y el hilo finaliza normalmente.
- El hilo arrojó una excepción o error no detectado.
- Llame directamente al método stop () del hilo para finalizar el hilo. Este método puede conducir fácilmente a un punto muerto y generalmente no se recomienda.
4. Cómo lograr la sincronización de subprocesos
- Método sincronizado (sincronizado)
- bloque de código sincronizado
- Bloqueo reentrante
- volátil
5.Métodos de comunicación entre subprocesos múltiples de Java
- esperar(), notificar(), notificar a todos(). Utilice sincronizado para garantizar la seguridad del hilo
- espera(), señal(), señalTodo(). Utilice un candado para garantizar la seguridad del hilo.
- Cola de bloqueo. Cuando el subproceso productor intenta colocar elementos en BlockingQueue, si la cola está llena, el subproceso se bloquea; cuando el subproceso consumidor intenta eliminar elementos de BlockingQueue, si la cola está vacía, el subproceso se bloquea.
6.La diferencia entre dormir() y esperar()
- dormir () es un método estático en la clase Thread y esperar () es un método miembro en la clase Objeto;
- sleep() se puede usar en cualquier lugar, mientras que wait() solo se puede usar dentro de un método sincronizado o bloque de código sincronizado.
- sleep() no liberará el bloqueo, pero wait() liberará el bloqueo y deberá volver a adquirirlo a través de notify()/notifyAll().
7.La diferencia entre sincronizado y Lock
- sincronizado es una palabra clave de Java que implementa el bloqueo y desbloqueo a nivel de JVM; Lock es una interfaz que implementa el bloqueo y desbloqueo a nivel de código
- sincronizado se puede usar en bloques y métodos de código; Lock solo se puede escribir en código.
- sincronizado libera automáticamente el bloqueo cuando se ejecuta el código o se produce una excepción; Lock no liberará automáticamente el bloqueo y el bloqueo debe liberarse finalmente.
- sincronizado hará que el hilo espere hasta que no pueda obtener el bloqueo; Lock puede establecer el tiempo de espera en caso de que no se pueda obtener el bloqueo.
- sincronizado no puede saber si la adquisición del bloqueo fue exitosa; Lock puede saber si el bloqueo fue exitoso a través de tryLock.
- los bloqueos sincronizados pueden ser reentrantes, ininterrumpibles e injustos; los bloqueos de bloqueo pueden ser reentrantes, interrumpibles, justos/injustos y pueden subdividir los bloqueos de lectura y escritura para mejorar la eficiencia.
8. La diferencia entre bloqueo optimista y bloqueo pesimista
9. Bloqueo justo y bloqueo injusto
- Bloqueo injusto: cuando un hilo compite por un bloqueo, primero hará un intento CAS para adquirir el bloqueo. Si falla, ingresará a la función adquirir(1) y realizará un tryAcquire para intentar adquirir el bloqueo nuevamente. Si falla nuevamente, usará addWaiter para agregar el bloqueo actual. El hilo se encapsula en un nodo y se agrega a la cola de sincronización. En este momento, el hilo solo puede esperar a que el hilo anterior termine de ejecutarse antes de que sea su turno.
- Bloqueo justo: cuando un subproceso adquiere un bloqueo, primero determinará si hay subprocesos esperando adquirir recursos en la cola de sincronización. De lo contrario, intente adquirir el bloqueo. Si es así, encapsule el hilo actual en un nodo a través de addWaiter y agréguelo a la cola de sincronización.
10.volátil
- Visibilidad garantizada, atomicidad no garantizada
- Deshabilitar la reorganización de comandos
(3) Otros
1. Tres características principales de la orientación a objetos
- Encapsulación: (agrupar datos y código para evitar interferencias externas) encapsular cosas objetivas en clases abstractas, y las clases solo pueden permitir que sus propios datos y métodos sean operados por clases u objetos confiables, y ocultar información de los que no son confiables.
- Herencia: (un método para permitir que un objeto de un tipo posea las propiedades de un objeto de otro tipo) para usar todas las funciones de una clase existente y ampliar estas funciones sin tener que reescribir la clase original.
- Polimorfismo: (es decir, una cosa tiene la capacidad de tener diferentes formas) La referencia de la clase principal apunta al objeto de la clase secundaria, por lo que tiene múltiples formas.
2. Métodos comunes de la clase Objeto.
- es igual()
- código hash()
- Encadenar()
- obtenerClase()
- esperar()
- notificar()
- notificar a todos()
- clon()
- finalizar()
3.string, stringBuffer y stringBuilder
- La cadena es inmutable y segura para subprocesos.
- stringBuffer es variable, ineficiente y seguro para subprocesos
- stringBuilder es variable, eficiente y no seguro
4. La diferencia entre clases abstractas e interfaces.
- Las clases abstractas pertenecen a la herencia y solo pueden heredar una; las interfaces pueden implementar múltiples
- Las clases abstractas tienen constructores; las interfaces no tienen constructores.
- Las variables miembro de clases abstractas pueden ser variables o constantes; las variables miembro de interfaces solo pueden ser constantes y el modificador predeterminado es public static final.
- Los métodos miembro de las clases abstractas pueden ser abstractos o implementarse concretamente; las interfaces solo pueden ser métodos miembros abstractos en jdk1.7, pero después de jdk1.8 pueden tener implementaciones concretas y deben modificarse de forma predeterminada. Y las interfaces también pueden tener métodos estáticos y modificaciones estáticas.
- Elección de clases e interfaces abstractas: si se centra en la esencia de una transacción, utilice clases abstractas; si se centra en una operación, utilice interfaces. Por ejemplo, si te enfocas en una persona, un hombre o una mujer, en lo que te enfocas en este momento es la esencia, así que usa clases abstractas. Preste atención a las diferentes acciones de comer y dormir de cada tipo de persona, por lo que necesita usar una interfaz, definir una plantilla e implementarlas por separado.
5. Tipos de datos básicos de Java
- byte: 1 byte (8 bits), el rango de datos es -2^7 ~ 2^7-1.
- corto: 2 bytes (16 bits), el rango de datos es -2^15 ~ 2^15-1.
- int: 4 bytes (32 bits), el rango de datos es -2^31 ~ 2^31-1.
- de largo: 8 bytes (64 bits), el rango de datos es -2^63 ~ 2^63-1.
- flotante: 4 bytes (32 bits), el rango de datos es aproximadamente -3,4 10^38 ~ 3,4 10^38.
- doble: 8 bytes (64 bits), el rango de datos es aproximadamente -1,8 10^308 ~ 1,8 10^308.
- char: 2 bytes (16 bits), el rango de datos es \u0000 ~ \uffff.
- booleano: no existe una disposición clara en la especificación de Java y diferentes JVM tienen diferentes mecanismos de implementación.
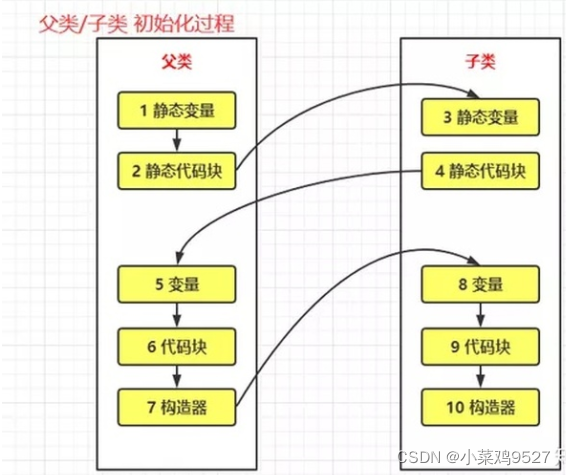
Seis.orden de ejecución del bloque de código java
- Bloque de código estático de clase principal
- Bloque de código estático de subclase
- Bloque de código de construcción de clase principal
- Constructor de clase padre
- Bloque de código de construcción de subclase
- constructor de subclases
- bloque de código normal
7.palabra clave estática
- Variables miembro modificadas: esta variable estática tiene solo una copia en la memoria. Siempre que esté cargada la clase en la que se encuentra la variable estática, a esta variable estática se le asignará espacio.
- Método miembro modificado: para llamar a este método, solo se necesitan el nombre de la clase y el nombre del método; se puede acceder a los métodos estáticos sin depender de ningún objeto, por lo que para los métodos estáticos, no existe esto. No se puede acceder a las variables miembro no estáticas y a los métodos miembros no estáticos de la clase en métodos estáticos, porque los métodos/variables miembros no estáticos deben depender de objetos específicos para ser llamados.
- Bloque de código modificado: cuando la clase se carga por primera vez, cada bloque estático se ejecutará en secuencia en el orden de los bloques estáticos y solo se ejecutará una vez.
- Modificar clases internas: las clases internas estáticas no pueden acceder directamente a miembros no estáticos de clases externas, pero se puede acceder a ellos a través de nuevos miembros de clase externa ().
8. La diferencia entre sobrescribir (reescribir) y sobrecargar
- La reescritura es generalmente una subclase que anula un método de clase principal (uno a uno), una relación vertical; la sobrecarga es generalmente una sobrecarga de múltiples métodos (entre múltiples) en una clase, una relación horizontal
- Los parámetros entre métodos anulados son los mismos; los parámetros entre métodos sobrecargados son diferentes
- La anulación no puede modificar el tipo de valor de retorno; la sobrecarga puede modificar el tipo de valor de retorno.
9.java cuatro modificadores de acceso
- privado: en esta clase
- predeterminado: en este paquete
- protegido: subclases de diferentes paquetes
- público: todos
10. La diferencia entre variables globales y variables locales.
-
Variables miembro:
-
Las variables miembro son variables definidas en el ámbito de la clase;
-
Las variables miembro tienen valores iniciales predeterminados;
-
Las variables miembro que no se modifican estáticamente también se denominan variables de instancia, se almacenan en la memoria del montón donde se encuentra el objeto y su ciclo de vida es el mismo que el del objeto;
-
Las variables miembro modificadas por estática también se denominan variables de clase, se almacenan en el área de métodos y tienen el mismo ciclo de vida que la clase actual.
-
-
Variables locales:
-
Las variables locales son variables definidas en métodos;
-
Las variables locales no tienen un valor inicial predeterminado;
-
Las variables locales se almacenan en la memoria de la pila y cuando finaliza el alcance del efecto, el espacio de la variable se liberará automáticamente.
-
11.La relación entre hashCode() y equals()
- hashCode busca el código hash del objeto (generalmente la dirección de almacenamiento del objeto) y es igual a comparar si los objetos son iguales según la dirección.
- Si dos objetos son iguales, deben tener el mismo código hash.
- Si dos objetos tienen el mismo código hash, no son necesariamente iguales
12. ¿Por qué deberíamos reescribir hashCode() y equals()?
- El método igual () proporcionado por la clase Objeto usa == para comparar de forma predeterminada, lo que significa que solo se pueden devolver resultados iguales cuando los dos objetos son el mismo objeto. En los negocios reales, nuestro requisito habitual es que si el contenido de dos objetos diferentes es el mismo, se consideran iguales.
13. Reflexión
- El mecanismo de reflexión de JAVA es que en el estado de ejecución, para cualquier clase, puede conocer todas las propiedades y métodos de esta clase; para cualquier objeto, puede llamar a cualquiera de sus métodos y propiedades; esta información obtenida dinámicamente y llamadas dinámicas La función del método del objeto se llama mecanismo de reflexión del lenguaje Java.
14.La diferencia entre cookie y sesión.
- Las ubicaciones de almacenamiento son diferentes: las cookies se almacenan en el lado del cliente; las sesiones se almacenan en el lado del servidor.
- La política de privacidad es diferente: las cookies son visibles para el cliente, y personas con motivos ocultos pueden analizar las cookies almacenadas localmente y realizar suplantación de cookies, por lo que no es seguro almacena en el servidor, es transparente para el cliente, y hay sin sensibilidad Riesgo de fuga de información.
- El ciclo de vida es diferente: establezca los atributos de la cookie para lograr el efecto de validez a largo plazo de la cookie; mientras la ventana esté cerrada, la sesión dejará de ser válida, por lo que la sesión no podrá ser válida durante mucho tiempo.
- Las cookies tienen un límite de almacenamiento de aproximadamente 3k; las sesiones no.
15.La diferencia entre solicitudes de obtención y publicación
- Visibilidad de la URL: obtener, la URL del parámetro es visible; publicar, el parámetro de la URL no es visible
- Transmisión de datos: obtener, transmitir parámetros empalmando la URL; publicar, transmitir parámetros a través del cuerpo
- Capacidad de almacenamiento en caché: las solicitudes de obtención se pueden almacenar en caché; las solicitudes de publicación no se pueden almacenar en caché
- Respuesta a la página que regresa: cuando la página de solicitud de obtención regresa, no tendrá ningún impacto; cuando la página de solicitud de publicación regresa, la solicitud se volverá a enviar.
- Seguridad : Esto también es lo más difícil de analizar. En principio, publicar es definitivamente más seguro que obtener . Después de todo, la URL no es visible al transmitir parámetros.
- El tamaño de los datos transmitidos por get generalmente no excede 2k-4k; el tamaño de los datos transmitidos por post request se establece de acuerdo con el archivo de configuración php.ini y también puede ser infinito.
16. Interacción de datos de front-end y back-end
-
formulario de formulario
-
Solicitud HttpServlet/Respuesta HttpServlet
-
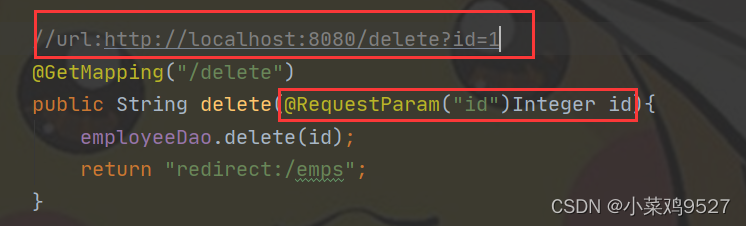
@RequestParam
- Los datos están en la ruta?id=1 después de la URL.
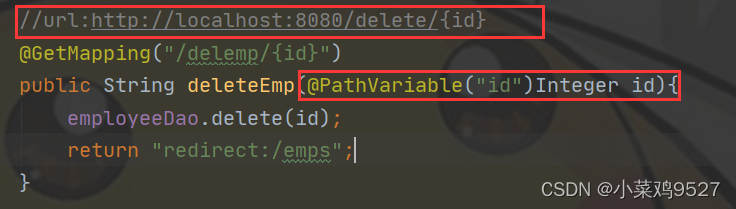
- @PathVariable
- Los datos son ruta/{id} después de la URL.
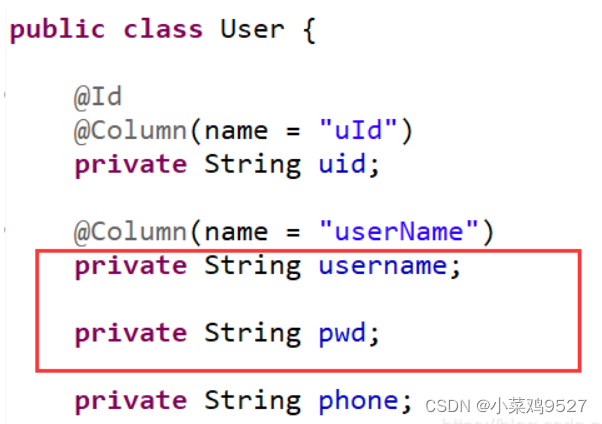
- @RequestBody
- Tomando datos json como ejemplo, primero hay una clase
- Luego el front-end pasa los datos.
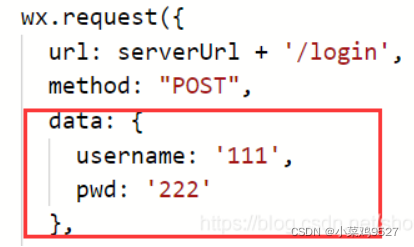
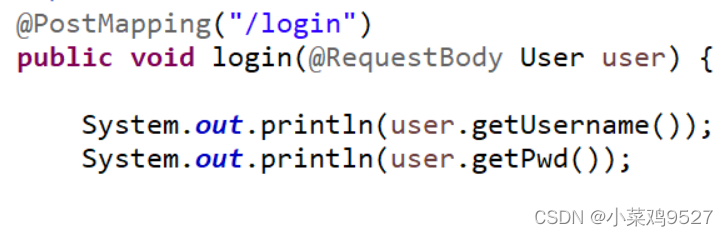
- Recepción de backend
- Tomando datos json como ejemplo, primero hay una clase
- Los datos están en la ruta?id=1 después de la URL.
- ModelAndView (solo transmite datos al front-end)
- Configurar el solucionador de vistas 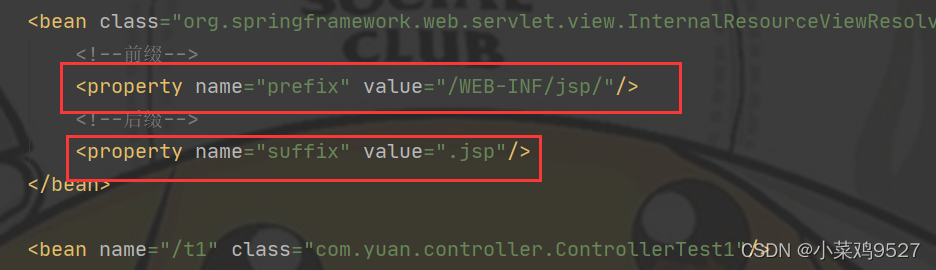
- Crear un objeto ModelAndView, agregar los datos devueltos y la dirección 
- modelo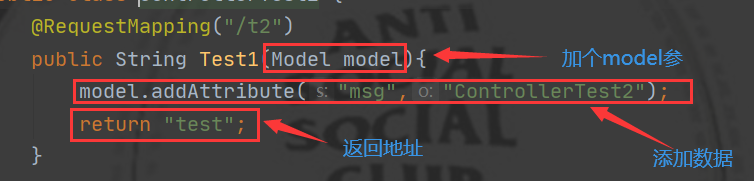
- ajax implementado por jquery
- Interfaz

- p.ej:
-
Clase de portador de transmisión de datos
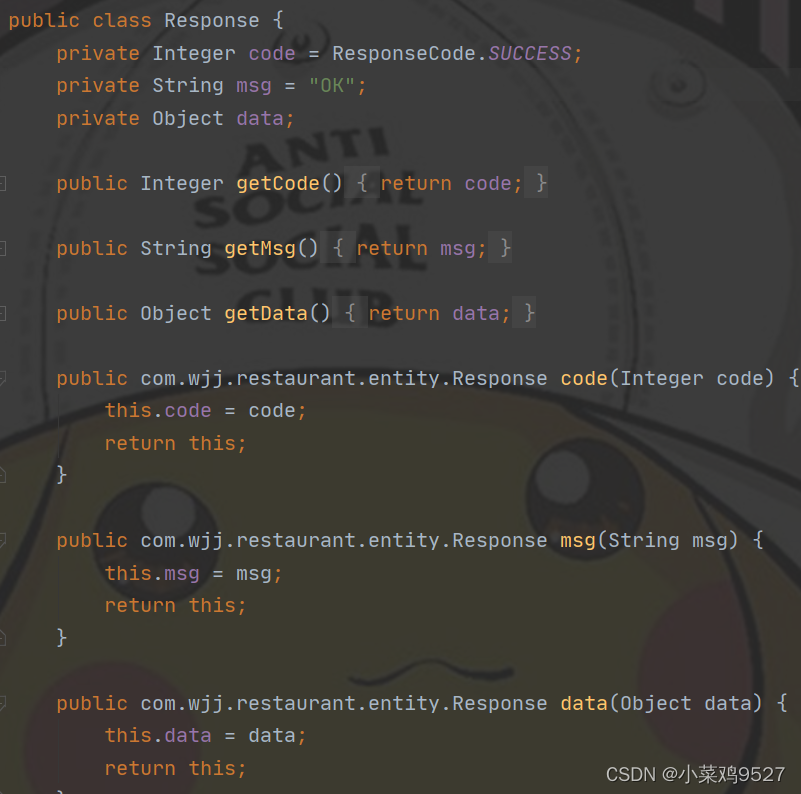
-
parte frontal
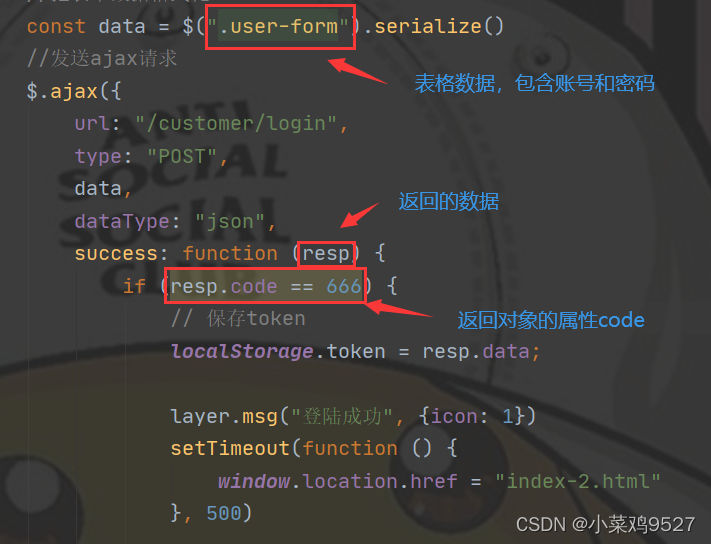
-
Parte trasera
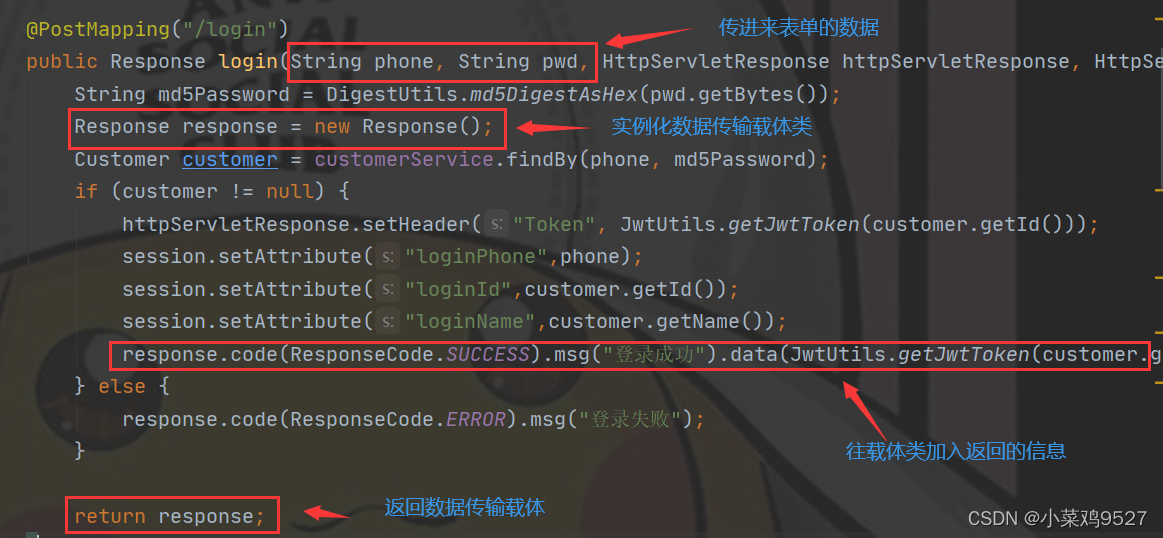
-
- Interfaz
17. Clasificación IO
- Según la dirección del flujo: flujo de entrada, flujo de salida
- Según unidades de datos: flujo de bytes, flujo de caracteres
- Dividido por función: flujo de nodo, flujo de procesamiento
18. Métodos para lidiar con colisiones de hash
- Método de direccionamiento abierto (método repetido)
- Sondeo lineal y luego hash
- Segunda detección y luego hash
- Sondeo pseudoaleatorio y luego hash
- refrito
- método de cremallera
19.La diferencia entre tirar y tirar
- Los lanzamientos siguen a la declaración del método, seguidos del nombre de la clase de excepción; los lanzamientos están dentro del método, seguidos de la instancia de la clase de excepción.
- Los lanzamientos pueden ir seguidos de múltiples clases de excepción; los lanzamientos solo pueden lanzar un objeto de excepción.
- throws lanza una excepción, que es manejada por la persona que llama; throw es manejada por la declaración en el cuerpo del método
20.23 Patrones de diseño
- Tipo de creación (5): patrón de método de fábrica, patrón de fábrica abstracto, patrón singleton, patrón de constructor, patrón de prototipo.
- Tipo estructural (7): modo adaptador, modo decorador, modo proxy, modo apariencia, modo puente, modo combinación, modo peso mosca.
- Comportamiento (11): patrón de estrategia, patrón de método de plantilla, patrón de observador, subpatrón iterativo, patrón de cadena de responsabilidad, patrón de comando, patrón de memorando, patrón de estado, patrón de visitante, patrón de mediador, patrón de intérprete.
21. Varios principios de patrones de diseño.
- principio de responsabilidad única
- Principio de aislamiento de interfaz
- Principio de sustitución de Richter
- principio de apertura y cierre
- Principio de limitación
- principio de inversión de dependencia
- Principio de reutilización sintética
22. Patrones de diseño involucrados en la primavera.
- Patrón de fábrica: BeanFactory y ApplicationContext para crear objetos
- Modo singleton: Bean utiliza de forma predeterminada el modo singleton
- Modo proxy: proxy dinámico AOP
- Métodos de plantilla: jdbcTemplete, restTemplete (herramienta de solicitud http)
- Patrón de adaptador: adaptación del procesador en mvc
- Patrón de observador: impulsado por la primavera
Contenido recomendado
2. JVM
1. ¿Qué partes incluye JVM?
- cargador de clases
- Área de datos en tiempo de ejecución (montón, pila, área de método, pila de método local y contador de programa)
- Área de métodos: variables estáticas, constantes, información de clase y grupo de constantes de tiempo de ejecución
- Contador de programa: cada hilo tiene un contador de programa, que es como un puntero que apunta al código de bytes del método en el método (por ejemplo, dándole +1 cada vez que se lee la siguiente instrucción).
- Pila de métodos nativos: registre métodos nativos y cargue bibliotecas locales al ejecutar el motor
- Pila: ciclo de vida y sincronización de subprocesos; sin problemas de recolección de basura; métodos para almacenar ocho tipos básicos, nombres de variables de referencia de objetos e instancias
- Montón: instancias de clases, grupo constante de cadenas
- Nueva área: Área del Edén, Área de supervivencia 0, Área de supervivencia 1
- zona de retiro
- Área permanente (la implementación específica del área de método, se cambió al metaespacio después de jdk1.8. Algunas personas piensan que no debería dividirse en el montón, y otras piensan que debería dividirse en el montón)
- motor de ejecución
- interfaz de biblioteca nativa

2. Mecanismo de delegación parental
- El cargador de clases recibe una solicitud de carga de clases.
- Delegue esta solicitud al cargador de clases principal para que la complete y continúe delegando hacia arriba hasta que se inicie el cargador de clases.
- El cargador de clases de inicio finalizará cuando se pueda ejecutar; de lo contrario, se generará una excepción y se notificará a las subclases que se carguen a su vez.
- ventaja:
- La carga comienza desde la capa más interna y la clase maliciosa externa con el mismo nombre no se puede cargar ni utilizar.
- Los dominios de acceso se distinguen estrictamente a través del paquete y las clases externas maliciosas no pueden acceder a las clases internas a través del código integrado.
3. Crear análisis de memoria de objetos.
(El caso está tomado del video del curso de java de Encontrando al Dios Loco)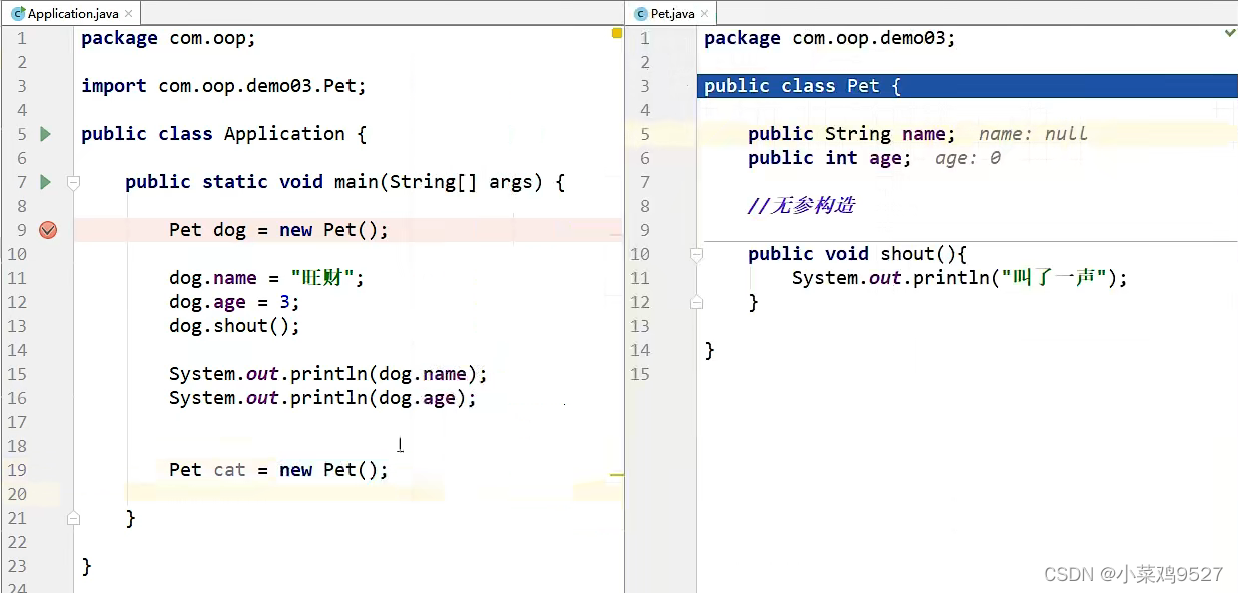
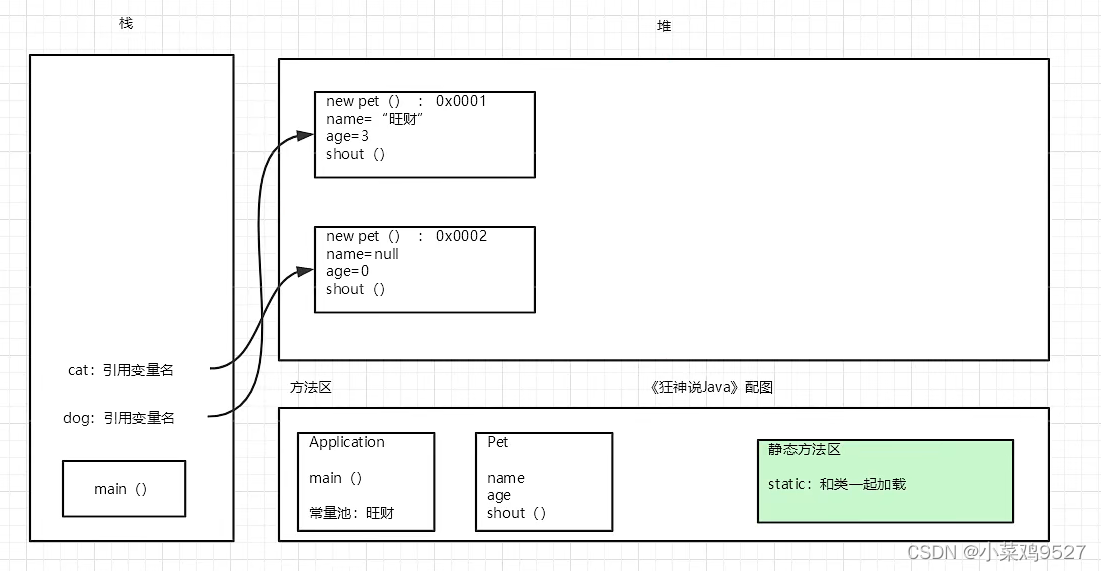
4.Proceso de creación de instancias de objetos JAVA
- Inicialización de carga de clases
- Cargando: carga el objeto de clase, que no necesariamente se obtiene del archivo de clase, puede ser un paquete jar o una clase generada dinámicamente.
- conectar
- Verificación: verifique si el flujo de bytes de clase se ajusta a la especificación JVM actual
- Preparación: asigne memoria para las variables de clase y establezca el valor inicial de la variable (valor predeterminado). Si es un objeto modificado final, el valor se asigna y declara.
- Análisis: reemplace la referencia del símbolo del grupo constante con una referencia directa
- inicialización
- usar
- desinstalar
- Inicialización de objetos
5. ¿Qué se debe reciclar durante la GC?
- Algoritmo de conteo de referencias
- Algoritmo de análisis de accesibilidad
6. Tres algoritmos básicos de GC
- Algoritmo de marca-borrado
Los objetos en la memoria forman un árbol. Cuando se agota la memoria efectiva, el programa se detendrá y hará dos cosas. La primera es marcar los objetos accesibles desde la raíz del árbol. La segunda es: Borrar inalcanzables. objetos. El programa dejará de ejecutarse cuando se borre la marca.
Desventajas: baja eficiencia recursiva y bajo rendimiento, la liberación discontinua de espacio puede conducir fácilmente a la fragmentación de la memoria, todo el programa dejará de ejecutarse; - El algoritmo de copia
divide la memoria en dos áreas: el área libre y el área activa. El primer paso es marcar. Después de marcar, los objetos alcanzables se copian al área libre, convirtiendo el área libre en un área activa. Al mismo tiempo Al mismo tiempo, los objetos en el área activa anterior se borran y se convierten en área libre.
Desventajas: Rápido pero ocupa espacio - El algoritmo de barrido de marcas
no limpia directamente los objetos reciclables después del algoritmo de barrido de marcas, sino que mueve todos los objetos supervivientes a un extremo y luego limpia la memoria fuera del límite final. - Algoritmo de recopilación generacional, a saber, nueva generación, antigua generación y generación permanente.
- Eficiencia de la memoria: algoritmo de copia> algoritmo de marca y barrido> algoritmo de compresión de marcas (complejidad del tiempo)
- Orden de la memoria: algoritmo de copia = algoritmo de compresión de marcas> algoritmo de borrado de marcas
- Utilización de la memoria: algoritmo de copia <algoritmo de barrido de marcas = algoritmo de compresión de marcas
7.jdk, jre y jvm
- jdk: kit de desarrollo java. Incluyendo el entorno de ejecución de Java (jre), herramientas de Java y bibliotecas de clases básicas de Java.
- jre: entorno de ejecución de Java. Incluyendo la implementación estándar de JVM y la biblioteca de clases principales de Java.
- jvm: máquina virtual java, una computadora abstracta
3. mysql
1. Tres paradigmas principales de bases de datos
- Primera forma normal: enfatiza la atomicidad de las columnas, es decir, las columnas no se pueden dividir en otras columnas.
- Segunda forma normal: según la primera forma normal, debe haber una clave principal y otros campos deben depender completamente de la clave principal, no solo una parte de la clave principal.
- Tercera forma normal: según las dos primeras formas normales, las columnas de clave no principal deben depender directamente de la clave principal y no puede haber dependencias transitivas.
2. Prevenir la inyección de SQL
- La mejor solución para prevenir ataques de inyección SQL en la capa de código es la precompilación de SQL (clase de declaración preparada)
- Especificar la longitud de los datos puede evitar la inyección SQL hasta cierto punto
- Restringir estrictamente los permisos de la base de datos puede minimizar el daño de la inyección SQL
3.Índice
- El índice es una estructura de datos que ayuda a MySQL a obtener datos de manera eficiente. En términos generales, el índice es como el índice de un libro, lo que acelera la consulta de la base de datos .
- Clasificación
- Lógicamente dividido por función
- Índice de clave principal: acelerar la consulta + valor de columna único (no puede tener nulo) + solo uno en la tabla
- Índice único: acelerar la consulta + valor de columna único (puede tener nulo)
- Índice normal: solo acelera las consultas
- Índice combinado: los valores de varias columnas forman un índice, que se utiliza específicamente para búsquedas combinadas, y su eficiencia es mayor que la combinación de índices.
- Indexación de texto completo: segmentación de palabras del contenido del texto y búsqueda
- Según estructura física
- índice agrupado
- índice no agrupado
- Lógicamente dividido por función
4.ÁCIDO
- Atomicidad: O pasa todo o no pasa nada.
- Coherencia: la integridad de los datos antes y después de una transacción debe ser consistente.
- Aislamiento: una transacción no puede verse interferida por los datos operativos de otras transacciones, y varias transacciones simultáneas deben aislarse entre sí.
- Durabilidad: una vez confirmada una transacción, los datos no se pueden restaurar
5. Tres problemas causados por la concurrencia de transacciones
- Lectura sucia: una transacción lee datos no confirmados de otra transacción
- Lectura fantasma: en la misma transacción se utiliza la misma operación para leer dos veces y el número de registros obtenidos es diferente (número de datos)
- Lectura no repetible: En una misma transacción se leen dos veces los mismos datos y el contenido obtenido es diferente (contenido de datos)
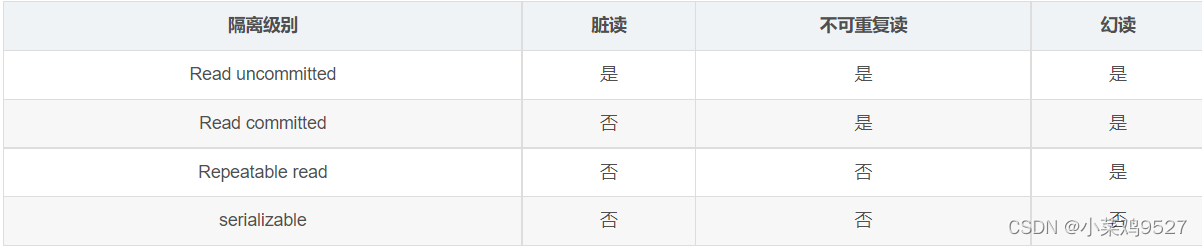
6.nivel de aislamiento de transacciones mysql
- Lectura no confirmada: cuando una transacción no se ha confirmado, otras transacciones pueden ver los cambios que realiza.
- Lectura confirmada: una vez confirmada una transacción, otras transacciones verán los cambios que realice.
- Lectura repetible: los datos vistos durante la ejecución de una transacción siempre son consistentes con los datos vistos cuando se inicia la transacción. Los cambios no confirmados también son invisibles para otras transacciones.
- Serializable: para la misma fila de registros, la escritura agregará un "bloqueo de escritura" y la lectura agregará un "bloqueo de lectura". Cuando ocurre un conflicto de bloqueo, la transacción a la que se accede más tarde debe esperar a que se complete la transacción anterior antes de poder continuar ejecutando.
7. Bloqueo de base de datos
- Según granularidad:
- bloqueo de fila
- bloqueo de página
- cerradura de mesa
- bloqueo global
- Nivel de bloqueo
- Bloqueo(s) compartido(s)
- Bloqueo exclusivo (escritura) (X)
- Bloqueo compartido de intención
- bloqueo exclusivo de intención
8.Clasificación de transacciones Mysql
- transacción plana
- Transacciones planas con puntos de guardado
- transacción en cadena
- Transacciones anidadas
- Transacciones distribuidas
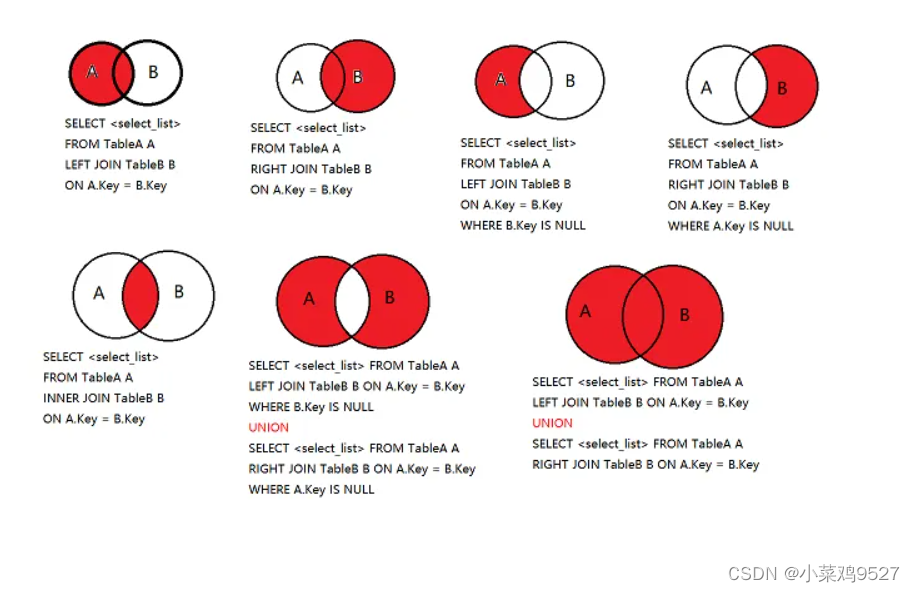
9.Consulta de tabla conjunta
10.La diferencia entre innodb y myisam
- innodb admite transacciones; myisam no admite transacciones
- innodb admite claves externas; myisam no admite claves externas
- Innodb es un índice agrupado y los datos y el índice están agrupados; myisam es un índice no agrupado y los datos y el índice están separados, lo que también da como resultado que sus estructuras de árbol B+ subyacentes sean diferentes.
- Hay dos archivos debajo de cada tabla en innodb: el archivo .frm almacena la estructura de la tabla y el archivo .ibd almacena los datos y los métodos de índice.
- Hay tres archivos debajo de cada tabla Myisam: un archivo se usa para guardar la estructura de la tabla, un archivo se usa para guardar los datos y un archivo se usa para guardar el índice.
11.ajuste de mysql
- ajuste de mysql
- Ajuste a nivel de hardware: el ajuste relacionado con el hardware generalmente lo realizan ingenieros de operación y mantenimiento.
- Ajuste de declaraciones SQL basadas en el propio MySQL : deje que las declaraciones SQL estén "indexadas" tanto como sea posible para mejorar el efecto.
- Optimización del diseño de tablas, siguiendo tres paradigmas principales.
- Configurar índice
- En términos de consulta, intente utilizar el índice en lugar de seleccionar *
- Fallo del índice
- como la consulta comienza con %
- El índice compuesto no satisface la coincidencia más a la izquierda
- La palabra clave o debe ir precedida y seguida de columnas de índice.
- La columna de índice donde se utiliza una función.
- Fallo del índice
- Cuando la cantidad de datos sea demasiado grande, realice la fragmentación de la base de datos y la fragmentación de la tabla: fragmentación horizontal y fragmentación vertical.
4. Red informática
1.Modelo OSI de siete capas
- (Cosas) Capa física: proporciona una ruta de transmisión para el flujo de bits original para dispositivos finales de datos
- (Conectado) Capa de enlace de datos: establecimiento de conexiones de enlace de datos entre entidades comunicantes
- (Red) Capa de red : crea enlaces lógicos para la transmisión de datos entre nodos y reenvía datos en grupos (IP, IPX)
- (Shu) Capa de transporte: proporciona comunicación lógica entre procesos de aplicaciones (TCP, UDP)
- (Beneficio) Capa de sesión: establece conexiones finales y proporciona verificación de acceso y gestión de sesiones
- (Prueba) Capa de presentación: proporciona servicios de conversión de formatos de datos
- (Uso) Capa de aplicación: interfaz para acceder a servicios de red (DNS, HTTP, FTP)

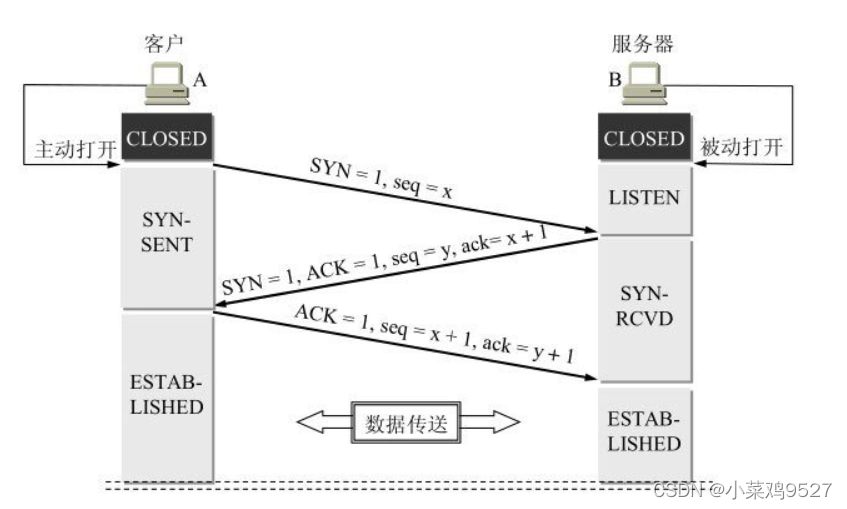
2.Tres apretones de manos
- A establece el indicador SYN en 1, genera aleatoriamente un valor seq = x y envía el paquete de datos a B. A ingresa al estado SYN_SENT y espera la confirmación de B.
- Después de que B recibe el paquete de datos, sabe que A solicita establecer una conexión desde el bit de bandera SYN = 1. B establece los bits de bandera SYN y ACK en 1, ack = x + 1, genera aleatoriamente un valor seq = y y envía el paquete de datos. Para confirmar la solicitud de conexión a A, B ingresa al estado SYN_RCVD.
- Después de que A recibe la confirmación, verifica si el reconocimiento es x+1 y si el ACK es 1. Si es correcto, establece el indicador ACK en 1, reconocimiento = y+1, y envía el paquete de datos a B. B verifica si el ACK es y + 1, si el ACK es 1, si es correcto, la conexión se establece exitosamente, A y B ingresan al estado ESTABLECIDO y completan el protocolo de enlace de tres vías
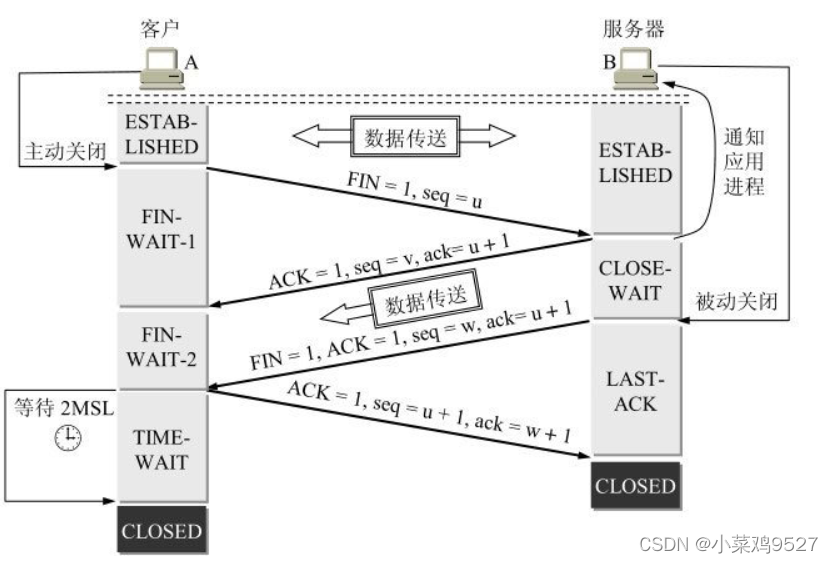
3. Saluda cuatro veces
- La primera ola: A envía un FIN para cerrar la transferencia de datos de A a B, y A ingresa al estado FIN_WAIT_1.
- La segunda ola: después de que B recibe el FIN, envía un ACK a A. El número de secuencia de confirmación es el número de secuencia recibido + 1 (igual que SYN, un FIN ocupa un número de secuencia) y B ingresa al estado CLOSE_WAIT. En este momento, el enlace TCP está en un estado semicerrado, es decir, el cliente no tiene datos para enviar, pero si el servidor envía datos, el cliente aún necesita recibirlos.
- La tercera ola: B envía un FIN para cerrar la transferencia de datos de B a A, y B ingresa al estado LAST_ACK.
- La cuarta ola: después de que A recibe B, A ingresa al estado TIME_WAIT y luego envía un ACK a B. El número de secuencia de confirmación es el número de secuencia recibido + 1. B ingresa al estado CERRADO y completa cuatro ondas.
4.La diferencia entre http y Htpps
- El protocolo https requiere solicitar un certificado.
- http es el Protocolo de transferencia de hipertexto, la información está en texto sin formato; https se transmite después del cifrado SSL
- Los puertos son diferentes, http es 80; https es 443
- La conexión http es simple y sin estado; https es SSL + http, que puede cifrar y confirmar la identidad, haciéndola más segura.
5.La diferencia entre Tcp y Udp
- TCP está orientado a la conexión; UDP no tiene conexión
- TCP es una transmisión confiable, sin pérdidas ni errores; UDP es una transmisión no confiable, entrega con el mejor esfuerzo
- TCP solo puede ser uno a uno; UDP admite uno a uno y uno a muchos
- tcp está orientado al flujo de bytes, udp está orientado a mensajes
6. Ingrese la URL de todo el proceso de visualización de la página.
- Introducir URL
- Compruebe si el nombre de dominio existe en la memoria caché . Si existe, recupere directamente la dirección IP. De lo contrario, realice la resolución DNS para obtener el nombre del protocolo, el número de host y el número de puerto.
- El protocolo de enlace de tres vías TCP permite al cliente y al servidor establecer una conexión
- El cliente envía una solicitud http para obtener recursos.
- El mensaje de respuesta http del servidor, el cliente obtiene el recurso.
- tcp cierra la conexión agitando cuatro veces
- Interfaz de representación de recursos de análisis del navegador
7.Proceso DNS
- La computadora del usuario realiza una solicitud de resolución de nombre de dominio y la envía al servidor de nombres de dominio local.
- Si existe en el caché local, se devolverá directamente.
- De lo contrario, el servidor de nombres de dominio local enviará directamente la solicitud al servidor de nombres de dominio raíz , y el servidor de nombres de dominio raíz devolverá al servidor de nombres de dominio local la dirección del servidor de nombres de dominio principal del dominio consultado (subdominio del raíz).
- Luego, el servidor local envía una solicitud al servidor de nombres de dominio devuelto en el paso anterior , y luego el servidor que acepta la solicitud consulta su propio caché. Si no existe tal registro, la dirección del servidor de nombres de dominio de nivel inferior relevante es regresó;
- Repita el cuarto paso hasta encontrar el registro correcto. El servidor de nombres de dominio local guarda el resultado devuelto en el caché y luego devuelve el resultado de la consulta;
8. Procesos e Hilos
- Proceso: la unidad más pequeña de asignación de recursos del sistema operativo
- Tema: La unidad más pequeña de programación de operaciones del sistema operativo
- la diferencia:
- La relación de afiliación es diferente: el proceso contiene subprocesos y los subprocesos pertenecen al proceso.
- La sobrecarga es diferente: la sobrecarga de crear, destruir y cambiar procesos es mucho mayor que la de los subprocesos.
- Tener recursos es diferente: cada proceso tiene su propia memoria y recursos, y los subprocesos de un proceso comparten esta memoria y recursos.
- Las capacidades de control e influencia son diferentes: el proceso hijo no puede afectar al proceso padre, pero el hilo hijo puede afectar al hilo padre. Si ocurre una excepción en el hilo principal, afectará su proceso y sus subprocesos.
- La utilización de la CPU es diferente: la utilización de la CPU del proceso es baja porque la sobrecarga del cambio de contexto es grande, mientras que la utilización de la CPU del subproceso es alta y el cambio de contexto es rápido.
- Los operadores son diferentes: el operador del proceso suele ser el sistema operativo y el operador del hilo suele ser el programador.
Cinco, marco java
(1) arranque de primavera
1.Las ventajas de springboot sobre spring
- Incorpora Tomcat, Jetty Undertow y no necesita implementarlos.
- Pompones "iniciales" proporcionados para simplificar la configuración de Maven
- Al iniciar dependencias, puede verificar las dependencias requeridas al crear el proyecto.
- Todo usando anotaciones, sin configuraciones xml engorrosas
(2) primavera
1.COI
- La inversión de control es una idea de diseño. El control de los objetos creados originalmente manualmente en el programa se entrega al contenedor del marco Spring para su administración, y se necesita una descripción para que el contenedor conozca la relación entre los objetos que se crearán. Es decir, los contenedores IOC gestionan objetos y sus dependencias.
2. Cómo implementar la inyección de dependencia
La inyección de dependencia (DI) es una forma de implementar IOC
- inyección constructora
- establecer método de inyección
- Otros métodos (inyección de interfaz, inyección de anotaciones)
Nota: No se recomienda la inyección de propiedades a partir de Spring 4.0 (es decir, aparecen líneas onduladas en @Autowride)
Razones: 1. No se permite declarar campos inmutables. La inyección de dependencia basada en campos no funciona en campos declarados finales/inmutables porque se deben crear instancias de estos campos cuando se crea una instancia de la clase. La única forma de declarar dependencias inmutables es utilizar la inyección de dependencias basada en constructores. 2. Estrechamente acoplado con el contenedor de inyección de dependencia. Una clase de este tipo no se puede reutilizar fuera del contenedor DI porque no hay otra forma de proporcionarle las dependencias necesarias además de la reflexión. 3. Violar el principio de responsabilidad única. Agregar nuevas dependencias es muy fácil. Cuando se agregan demasiados, es difícil encontrarlo, pero si se usa un constructor, habrá demasiados parámetros del constructor y el problema se puede encontrar claramente. Demasiadas dependencias normalmente significan que la clase tiene demasiadas responsabilidades. Esto puede violar el principio de responsabilidad única. 4. Ocultar dependencias. No se pueden especificar dependencias de manera efectiva
3.AOP
- La programación orientada a aspectos es una tecnología que logra el mantenimiento unificado de las funciones del programa mediante agentes dinámicos de precompilación y tiempo de ejecución. Basado en proxy dinámico, oop (programación orientada a objetos), reflexión
4.Terminología AOP
- Aspecto: el aspecto generalmente se refiere a la lógica entre negocios. Por ejemplo, el procesamiento de transacciones declarativas y el procesamiento de registros pueden entenderse como aspectos
- Notificación: Es la función que quieres, es decir el método en el aspecto
- Punto de conexión: Donde se pueden utilizar las notificaciones. Como antes y después de cada método.
- Punto de entrada: el lugar donde el aspecto realmente interviene.
- Objetivo: el objeto a notificar
5.Implementación de AOP
- Utilice la interfaz nativa de Spring API (implemente interfaces de notificación previa, notificación posterior, notificación envolvente, etc.)
- Clase personalizada
- Implementación de anotaciones (@Aspect)
6.Contenedor del COI
- BeanFactory: proporciona la función de contenedor más simple y solo proporciona las funciones de crear instancias de objetos y obtener objetos;
- ApplacationContext: hereda la interfaz BeanFactory, que es un contenedor más avanzado de Spring y proporciona funciones más útiles.
- globalización
- Acceda a recursos como URL y archivos
- Entrega de eventos: implementando la interfaz ApplicationContextAware
7. Método para crear ApplacationContext
- FileSystemXmlApplicationContext: creado a partir del archivo de configuración xml especificado por el sistema de archivos o la URL, el parámetro es el nombre del archivo de configuración o la matriz de nombres de archivo
- ClassPathXmlApplicationContext: creado a partir del archivo de configuración xml de classpath, el archivo de configuración se puede leer desde el paquete jar
- WebApplicationContextUtils: lea el archivo de configuración desde el directorio raíz de la aplicación web. Primero debe configurarse en web.xml. Puede configurar un oyente o servlet para lograr esto.
8. Alcance del frijol
- singleton: solo hay una instancia en el contenedor Spring, es decir, el Bean existe en forma de singleton.
- prototipo: proporcione una instancia para cada solicitud de bean.
- Solicitud: se crea un nuevo Bean con cada solicitud HTTP.
- sesión: la misma sesión HTTP comparte un Bean y diferentes sesiones HTTP utilizan diferentes Beans.
- globalSession: La misma sesión global comparte un Bean, generalmente utilizado en entornos Portlet.
9.Ciclo de vida del frijol
- Creación de instancias (a través del constructor o método de fábrica)
- Asignación de propiedad (inyección de dependencia)
- inicialización
- destruir
10.Ensamblaje automático de frijoles
- @Autowried: implementado a través de byType y requiere que este objeto exista
- @Resouce: De forma predeterminada, se implementa a través de byName, si no se puede encontrar el nombre, se implementa a través de byType.
(3)PrimaveraMVC
1.Concepto SpringMVC
- MVC es un patrón de diseño en el que el software se divide en tres capas: Modelo, Vista y Controlador.
2. Proceso de ejecución de Spring MVC
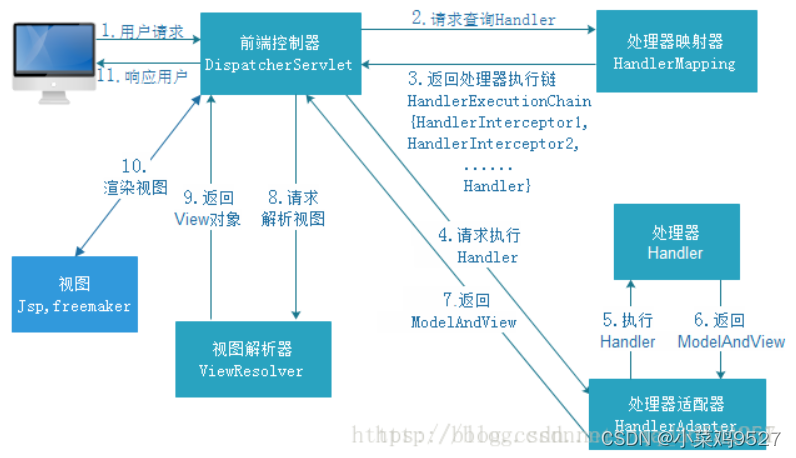
-
El usuario envía una solicitud al controlador front-end DispatcherServlet
-
DispatcherServlet recibe la solicitud y llama al asignador del controlador HandlerMapping
-
El asignador de procesamiento encuentra el procesador específico de acuerdo con la URL de solicitud, genera la cadena de ejecución del procesador HandlerExecutionChain (incluido el objeto del procesador y el interceptor del procesador) y lo devuelve a DispatcherServlet.
-
DispatcherServlet obtiene el adaptador correspondiente según el controlador del procesador
-
HandlerAdapter llama al procesador Handler
-
Handler (Controlador) regresa a ModelAndView después de completar la ejecución
-
HandlerAdapter devuelve ModelAndView
-
DispatcherServlet envía uniformemente el ModelAndView devuelto a ViewResolve (resolución de vistas) para su análisis
-
Ver resultados del analizador Ver después del análisis
-
Renderizar la vista
-
Responder al usuario
3. La diferencia entre interceptores y filtros.
- Los principios de implementación son diferentes: el principio de implementación del interceptor es un mecanismo de reflexión y el filtro es una devolución de llamada de función.
- El alcance de uso es diferente: el filtro se define en el serverlet, depende de contenedores como tomcat y solo se puede usar en programas web; el interceptor es un componente de Spring, que se puede usar solo y también se puede usar en programas web y otros programas.
6. Redis
1. La diferencia entre RDB persistente y AOF
- La persistencia de RDB se refiere a escribir una instantánea del conjunto de datos en la memoria en el disco dentro de un intervalo de tiempo específico. El proceso de operación real es bifurcar un proceso secundario, primero escribir el conjunto de datos en un archivo temporal y luego reemplazar el archivo anterior después del La escritura es exitosa. , almacenado .
- ventaja:
- Maximice el rendimiento. Para el proceso de servicio de Redis, cuando comienza la persistencia, lo único que debe hacer es bifurcar el proceso hijo, y luego el proceso hijo completará el trabajo de persistencia, lo que puede evitar en gran medida que el proceso de servicio realice operaciones de IO.
- En comparación con el mecanismo AOF, si el conjunto de datos es grande, la eficiencia de inicio de RDB será mayor
- Para la recuperación ante desastres, RDB es una muy buena opción. Porque podemos comprimir fácilmente un único archivo y luego transferirlo a otros medios de almacenamiento
- defecto:
- Una vez que el sistema falla antes de la persistencia programada, se perderán todos los datos que no hayan tenido tiempo de escribirse en el disco.
- ventaja:
- La persistencia de AOF registra cada operación de escritura y eliminación procesada por el servidor en forma de registro. Las operaciones de consulta no se registran, sino que se registran en texto. Puede abrir el archivo para ver registros de operaciones detallados.
- ventaja:
- Puede aportar mayor seguridad de los datos , es decir, persistencia de los datos. Redis proporciona tres estrategias de sincronización, a saber, sincronización cada segundo, sincronización con cada modificación y sin sincronización.
- Incluso si hay un tiempo de inactividad, el contenido existente en el archivo de registro no se destruirá. Si solo escribimos la mitad de los datos en esta operación y se produce una falla del sistema, use la herramienta redis-check-aof para resolver el problema de coherencia de los datos antes de que Redis se inicie la próxima vez.
- defecto:
- Para la misma cantidad de conjuntos de datos, los archivos AOF suelen ser más grandes que los archivos RDB. RDB es más rápido que AOF al restaurar grandes conjuntos de datos
- Dependiendo de la estrategia de sincronización, AOF suele ser más lento que RDB en términos de eficiencia operativa.
- ventaja:
2.tipo de datos redis
- Cinco tipos de datos principales: Cadena, Lista, Conjunto, Hash, Zset (campo de puntuación agregado para ordenar)
- Tres tipos de datos especiales: Geoespacial (ubicación geográfica), Hyperloglog (estadísticas de cardinalidad, aplicadas a las visitas al sitio web), BitMaps (mapas de bits, aplicados a las estadísticas de check-in y estado)
3.redis alta disponibilidad
- Modos centinela y enjambre
4. Penetración de caché, avería de caché, avalancha de caché
- Penetración de caché: el cliente consulta datos que no existen en absoluto, lo que hace que la solicitud vaya directamente a la capa de almacenamiento , lo que genera una carga excesiva o incluso un tiempo de inactividad. El motivo de esta situación puede ser que la capa empresarial eliminó por error los datos en el caché y la biblioteca, o puede ser que alguien atacó maliciosamente y accedió específicamente a datos que no existen en la biblioteca.
- Solución: Caché de objetos vacíos; filtro Bloom
- Desglose de la caché: un dato importante que tiene una gran cantidad de visitas. En el momento en que su caché caduca, una gran cantidad de solicitudes van directamente a la capa de almacenamiento, provocando que el servicio falle.
- Solución: los datos del hotspot nunca caducan; agregue un bloqueo mutex
- avalancha de caché
- Solución: al configurar el tiempo de vencimiento, agregue un número aleatorio para evitar que los datos caduquen al mismo tiempo;
7. Comandos comunes de Linux
1. Cambio de directorio
- cd/: cambia al directorio raíz
- cd .../: cambia al directorio de nivel superior
- cd ~: cambiar al directorio de inicio
2. Vista de directorio
- ls: ver todos los directorios y archivos en el directorio actual
- ls -a: ver todos los directorios y archivos en el directorio actual (incluidos los archivos ocultos)
- ls -l: Lista para ver todos los directorios y archivos en el directorio actual (vista de lista, muestra más información)
3. Operaciones de directorio
- crear
- nombre del directorio mkdir
- Eliminar
rm -f: eliminación forzada sin preguntar
rm -r nombre del directorio: eliminar el directorio de forma recursiva - Revisar
- mv directorio actual nuevo directorio
- Encontrar
- buscar el nombre del archivo de parámetros del directorio
- Ejemplo: buscar /usr/tem -name 'a*' Encuentra todos los directorios o archivos que comienzan con a en el directorio /usr/tmp
4. Operaciones de archivos
- crear
- toque el nombre del archivo
- borrar
- rm-rf
- Revisar
- vi o vim, dividido en tres modos
- modo de línea de comando
- modo de edición
- Modo de fila inferior
- vi o vim, dividido en tres modos
- Controlar
- gato: mira la última pantalla
- más: Visualización de porcentaje
- menos: visualización de paso de página
- tail: especifica el número de líneas o visualiza dinámicamente
5.Operación de permiso
chmod (ugoa) (+ - =) (rwx) (nombre de archivo)
- u: el propietario del archivo
- g: En el mismo grupo que el propietario
- o: otros usuarios
- a: Los tres anteriores
- +: aumentar permisos
- -: revocar permiso
- =: Establecer permisos
- r: permiso de lectura
- w: permiso de escritura
- x: ejecutable (si no, significa que no puedes acceder a este directorio)
6. Embalaje y compresión
- Archivo de empaquetado: tar -cvf archivo de empaquetado.tar archivo/ruta empaquetados...
- Desempaquete el archivo: tar -xvf paquete file.tar
- Descripción de parámetros
- c: generar archivos de almacenamiento y crear archivos de empaquetado
- x: desbloquear el archivo comprimido
- v: proceso de visualización
- f: Especifique el nombre del archivo comprimido
- Archivo comprimido: tar -zcvf archivo empaquetado.tar.gz archivo comprimido/ruta...
- Descomprima el archivo: tar -zxvf paquete file.tar.gz
7. Encuentra instrucciones
- grep: coincidencia de cadenas (coincide con una cadena del contenido de un archivo)
- Ejemplo: ps -ef | grep sshd -c para encontrar el número de ssh en el proceso especificado
- -c: genera solo el recuento de líneas coincidentes.
- -i: no distingue entre mayúsculas y minúsculas.
- -h: no muestra los nombres de los archivos al consultar varios archivos.
- -l: al consultar varios archivos, solo se generan los nombres de archivos que contienen caracteres coincidentes.
- -n: muestra líneas coincidentes y números de línea.
- -s: no muestra mensajes de error que no existen o que no tienen texto coincidente.
- -v: muestra todas las líneas que no contienen texto coincidente.
- buscar: busca archivos o directorios en el directorio especificado.
- Uso: buscar el nombre del archivo del parámetro de ruta
- Ejemplo: buscar /home/ygt -name test.txt Busque el archivo llamado test.txt en su cuenta
- Buscar por nombre de archivo: buscar nombre-directorio "nombre de archivo o nombre de directorio"
- Buscar por tipo de archivo: busque el tipo de directorio d (archivo de directorio)/f (archivo normal)
- Buscar por tamaño de archivo: buscar directorio -size +nk (más que nk)/-n (menos que nk)
- Buscar por minuto: buscar directorio -amin/-bmin/-mmin +n (fuera de n minutos)/-n (dentro de n minutos)
- Buscar por día: buscar directorio -atime/-ctime/-mtime +n (fuera de n días)/-n (dentro de n días)
- localizar: localiza archivos más rápido. (Se actualiza automáticamente una vez al día de forma predeterminada. Si desea consultar archivos modificados recientemente, primero debe actualizar la base de datos de búsqueda con actualizadob )
- Ejemplo: localizar /etc/sh busca todos los archivos que comienzan con sh en el directorio etc
- localizar pwd encuentra todos los archivos relacionados con pwd
8. Cambio de usuario
- son
- sudo (diseñado para todos los usuarios normales que quieran utilizar privilegios de root)
9. Ver el directorio actual
- persona con discapacidad
10. Ver el proceso
- ps-ef
11. Finaliza el proceso
- matar
8. Distribuido
1.Principio de la PAC
- Consistencia (C): si todas las copias de seguridad de datos en un sistema distribuido tienen el mismo valor al mismo tiempo.
- Disponibilidad (A): después de que falla una parte de los nodos del clúster, si todo el clúster aún puede responder a las solicitudes de lectura y escritura del cliente.
- Tolerancia de partición (P): La pérdida o falla de cualquier información en el sistema no afectará el funcionamiento continuo del sistema.
2. ¿Por qué no puedes tener los dos?
3.RPC
- llamada a procedimiento remoto
- Dos núcleos: comunicación y serialización.