Implemente la interacción de voz ROS utilizando el SDK del módulo de síntesis de voz iFlytek
El contenido de este artículo es el mismo que el artículo original del blogger de CSDN "AI Chen", puede consultar directamente el artículo original: https://blog.csdn.net/qq_39400324/article/details/125351722 Enlace rápido
El propósito El objetivo de este artículo es registrar el proceso de aprendizaje en forma de notas.
Este artículo está marcado para reimpresión.
Tabla de contenido
- Implemente la interacción de voz ROS utilizando el SDK del módulo de síntesis de voz iFlytek
Referencias y citas
Artículo original del blogger de CSDN "AI Chen"
La mayor parte del contenido de este artículo se basa en las notas registradas en el artículo original del blogger de CSDN "AI Chen" (siguiendo el acuerdo de derechos de autor CC 4.0 BY-SA).
Enlace original: https://blog.csdn.net/qq_39400324/article/details/125351722Enlace rápido
—————————————————————————————————————————————
1. Descarga del SDK
Plataforma abierta iFlytek: https://www.xfyun.cn/Enlace rápido Consola
- Crear nueva aplicación - DescargarLinux MSC
Después de descargarlo, descomprímelo y muévelo a Ubuntu. Le puse el nombreLinux_aisound
2. Conversión mutua entre voz y texto
1. Voz a texto
Ⅰ Compile el SDK descargado
Vaya a home/安装Ubuntu的用户名/所下载的SDK包/samples/iat_online_record_samplela ruta y use el siguiente comando para compilar
source 64bit_make.sh
ⅡSi ocurre un error de compilación
Si ocurre un error de compilación, use este comando para instalar y compilar nuevamente. Para más detalles, consulte aquí
sudo apt-get install libasound2-dev
ⅢEjecutar el proceso de conversión de voz a texto
Una vez completada la compilación en el paso Ⅰ, se generará home/安装Ubuntu的用户名/所下载的SDK包/bin/en la ruta iat_online_record_sample. home/安装Ubuntu的用户名/所下载的SDK包/bin/Abra la terminal en la ruta y ejecute el siguiente comando:
./iat_online_record_sample
Se produce el siguiente error:
./iat_online_record_sample: error while loading shared libraries: libmsc.so: cannot open shared object file: No such file or directory
Solución:
copie los archivos home/安装Ubuntu的用户名/所下载的SDK包/bin/libs/x64/en la ruta a. Puede consultar el método proporcionado por el autor original.libmsc.sousr/lib/
sudo cp libs/x64/libmsc.so /usr/lib/
sudo ldconfig
Después de probarlo aquí, descubrí que se informaría un error, por lo que después de cambiar la ruta ( vm123era mi nombre de usuario), la copia se realizó correctamente. Las instrucciones son las siguientes:
sudo cp /home/vm123/Linux_aisound/libs/x64/libmsc.so /usr/lib
Una vez completada la copia, vuelva a ejecutar:
./iat_online_record_sample
Y configure:
①Si desea cargar la biblioteca de personajes del usuario, seleccioneNo
②¿De dónde viene la voz?SeleccioneFrom microphone
Finalmente, hable por el micrófono y será reconocido y convertido en texto.
2. Texto a voz
Ⅰ Compile el SDK descargado
Vaya a home/安装Ubuntu的用户名/所下载的SDK包/samples/tts_online_samplela ruta y use el siguiente comando para compilar
source 64bit_make.sh
Ⅱ Ejecutar el proceso de conversión de texto a voz
Una vez completada la compilación en el paso Ⅰ, se generará home/安装Ubuntu的用户名/所下载的SDK包/bin/en la ruta tts_online_sample. home/安装Ubuntu的用户名/所下载的SDK包/bin/Abra la terminal en la ruta y ejecute el siguiente comando:
./tts_online_sample
Después de ejecutar, cierre la terminal y home/安装Ubuntu的用户名/所下载的SDK包/bin/la voz que acaba de probar se generará en la ruta.
ⅢLograr reproducción automática según lo anterior
home/安装Ubuntu的用户名/所下载的SDK包/samples/tts_online_sample/Modifique el archivo bajo la ruta tts_online_sample.c.
Después de la línea 174 printf("合成完毕\n");, agregue el siguiente código para reproducir automáticamente el archivo sintetizado después de la síntesis.
popen("play tts_sample.wav","r");
Una vez completada la adición, debe volver a compilar como se indica arriba.
3. Conversión de voz y texto ROS
1. Convertir la entrada de voz en texto
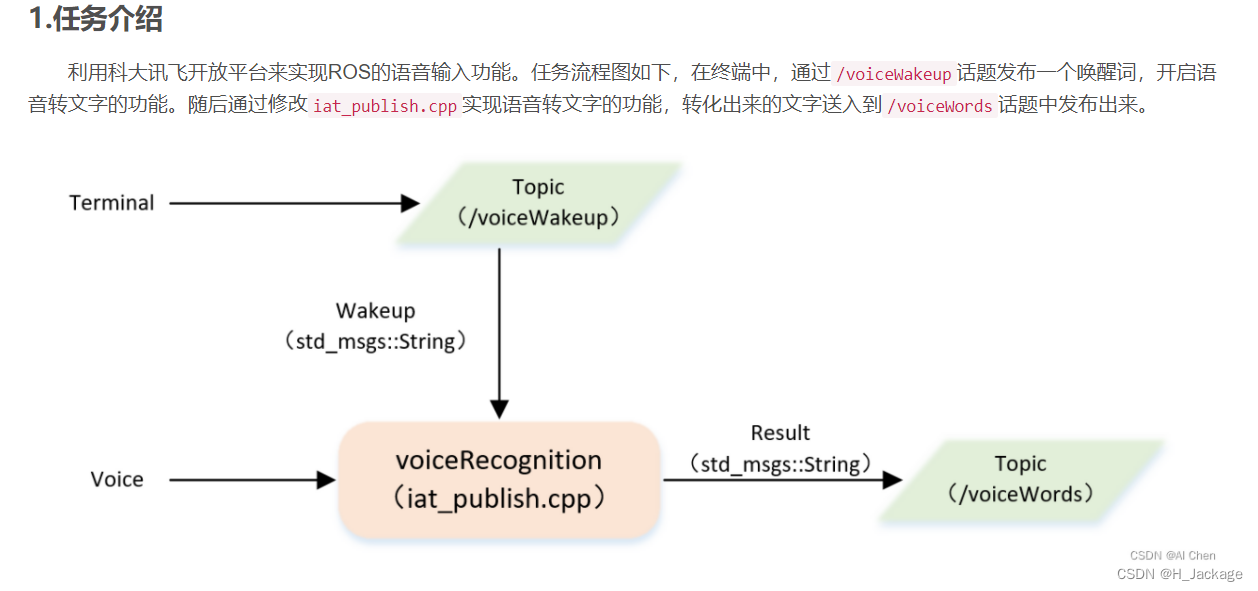
ⅠCrear espacio de trabajo
Cree un espacio de trabajo, asígnele un nombre catkin_ws_voice_control, cree un paquete de funciones en el espacio de trabajo, asígnele un nombre robot_voicey cree la dependencia del paquete de funciones roscpp std_msgs.
Copie 所下载的语音SDK包/include/los archivos 7 .h en la ruta a home/安装Ubuntu的用户名/catkin_ws_voice_control/robot_voice/include/robot_voice/la ruta.
Copie 所下载的语音SDK包/samples/iat_online_record_sample/los archivos 3 .h en la ruta a home/安装Ubuntu的用户名/catkin_ws_voice_control/robot_voice/include/robot_voice/la ruta.
Copie 所下载的语音SDK包/samples/iat_online_record_sample/los archivos 3 .c en la ruta a home/安装Ubuntu的用户名/catkin_ws_voice_control/src/robot_voice/src/la ruta. Y iat_online_record_sample.ccámbielo a iat_publish.cpp(tenga en cuenta el cambio de sufijo).
ⅡModificar archivos de código
Primero, modifique iat_publish.cpp:
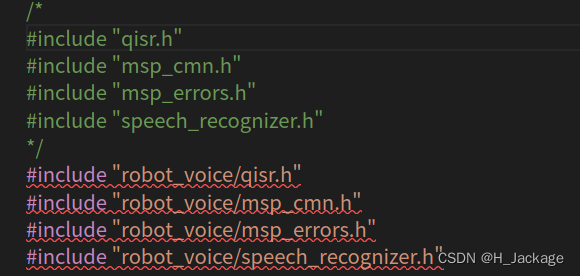
①El archivo de
encabezado
#include "qisr.h"
#include "msp_cmn.h"
#include "msp_errors.h"
#include "speech_recognizer.h"
Cambiar a
#include "robot_voice/qisr.h"
#include "robot_voice/msp_cmn.h"
#include "robot_voice/msp_errors.h"
#include "robot_voice/speech_recognizer.h"
Como se muestra en la figura:
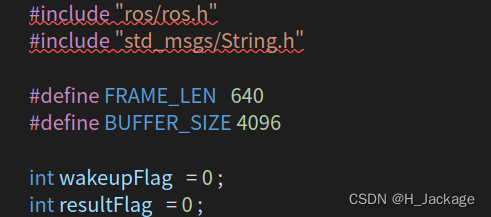
②

#include "ros/ros.h"
#include "std_msgs/String.h"
int wakeupFlag = 0 ;
int resultFlag = 0 ;
Como se muestra en la figura después de agregar:
③

resultFlag=1;
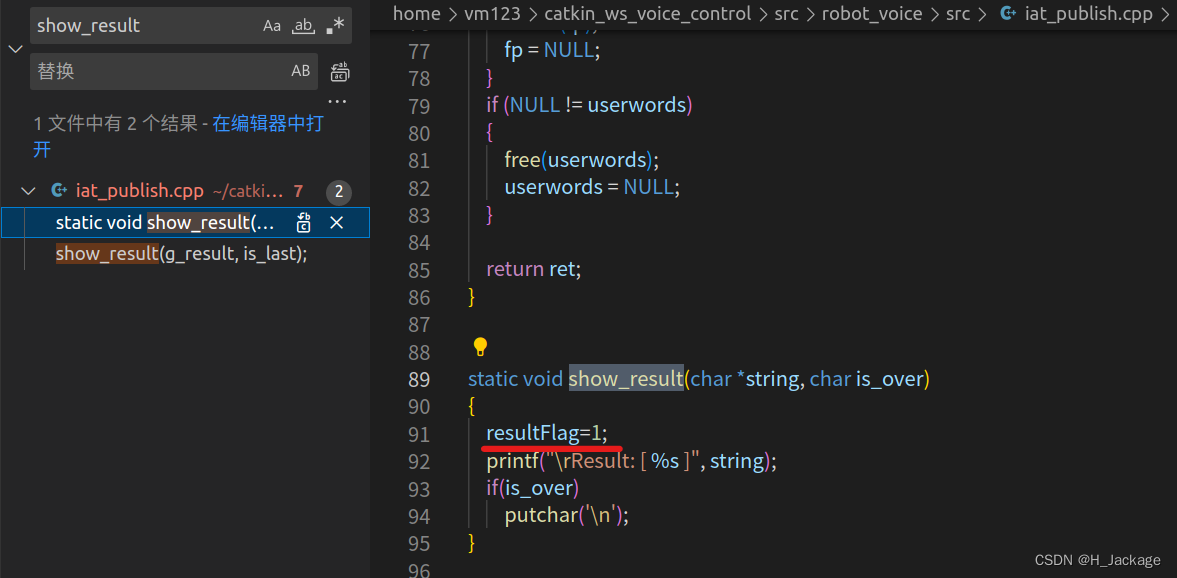
④

// 初始化ROS
ros::init(argc, argv, "voiceRecognition");
ros::NodeHandle n;
ros::Rate loop_rate(10);
// 声明Publisher和Subscriber
// 订阅唤醒语音识别的信号
ros::Subscriber wakeUpSub = n.subscribe("voiceWakeup", 1000, WakeUp);
// 订阅唤醒语音识别的信号
ros::Publisher voiceWordsPub = n.advertise<std_msgs::String>("voiceWords", 1000);
ROS_INFO("Sleeping...");
int count=0;
⑤

while(ros::ok())
{
// 语音识别唤醒
if(wakeupFlag)
{
printf("Demo recognizing the speech from microphone\n");
printf("Speak in 8 seconds\n");
demo_mic(session_begin_params);
printf("8 sec passed\n");
wakeupFlag=0;
}
// 语音识别完成
if(resultFlag){
resultFlag=0;
std_msgs::String msg;
msg.data = g_result;
voiceWordsPub.publish(msg);
}
ros::spinOnce();
loop_rate.sleep();
count++;
}
⑥

void WakeUp(const std_msgs::String::ConstPtr& msg)
{
printf("waking up\r\n");
usleep(700*1000);
wakeupFlag=1;
}
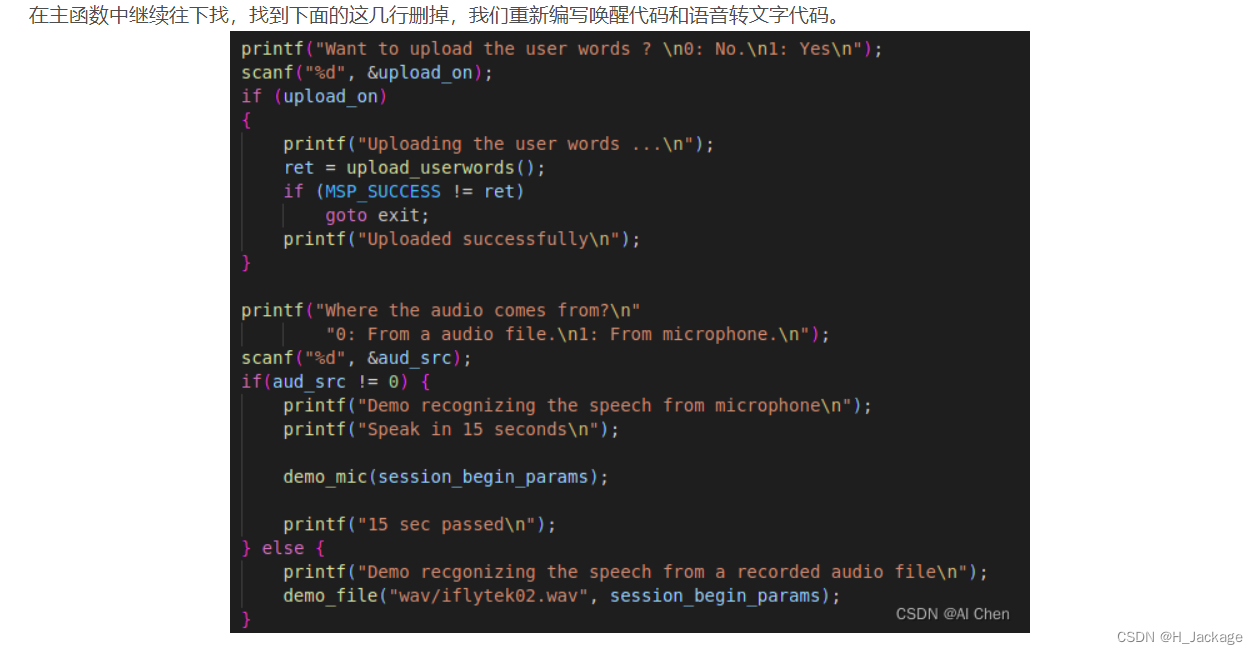
⑦ Si necesita cambiar la conversión de voz a texto de 15 segundos a voz a texto en otros momentos, entonces

printf("Demo recognizing the speech from microphone\n");
printf("Speak in 8 seconds\n");
printf("Speak in 8 seconds\n");
printf("8 sec passed\n");

/* demo 8 seconds recording */
while(i++ < 8)
sleep(1);
En segundo lugar, modifique linuxrec.cy speech_recognizer.c:
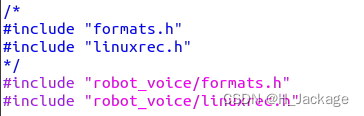
#include "robot_voice/formats.h"
#include "robot_voice/linuxrec.h"
y

#include "robot_voice/speech_recognizer.h"
#include "robot_voice/qisr.h"
#include "robot_voice/msp_cmn.h"
#include "robot_voice/msp_errors.h"
#include "robot_voice/linuxrec.h"
ⅢArchivo de compilación de configuración
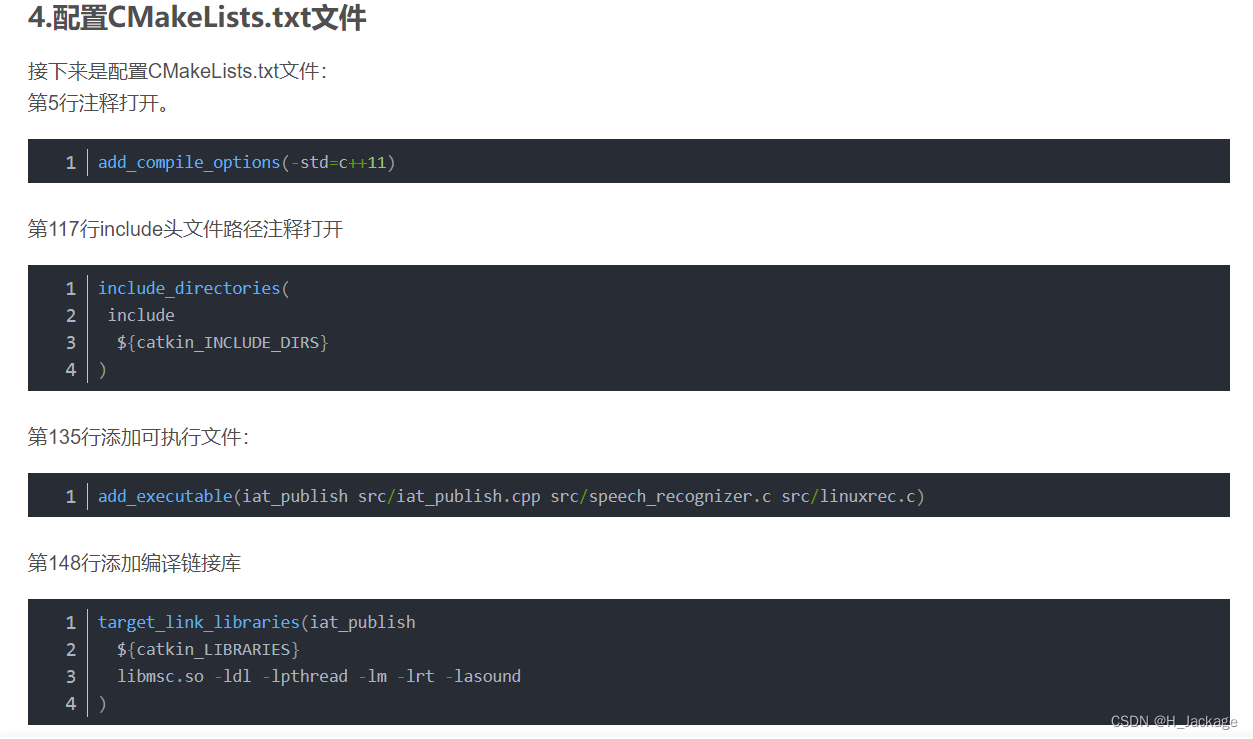
Agregar archivo ejecutable:
add_executable(iat_publish src/iat_publish.cpp src/speech_recognizer.c src/linuxrec.c)
Agregue la biblioteca de enlaces de compilación:
target_link_libraries(iat_publish
${
catkin_LIBRARIES}
libmsc.so -ldl -lpthread -lm -lrt -lasound
)
ⅣEjecute el programa de código
Compilar paquete de funciones
(variable de entorno)
(ejecutar roscore)
ejecutar programa de código
rosrun robot_voice iat_publish
Publicar un tema
rostopic pub /voiceWakeup std_msgs/String "data: 'input any words'"
2. Convertir la entrada de texto a voz
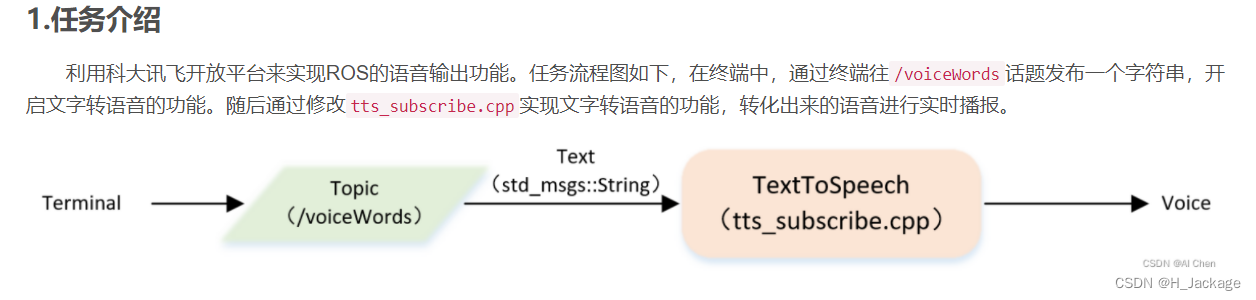
ⅠCrear espacio de trabajo
Copie los archivos 所下载的语音SDK包/samples/tts_online_sample/debajo de la ruta a la ruta. Y cámbielo a (tenga en cuenta el cambio de sufijo).tts_online_sample.chome/安装Ubuntu的用户名/catkin_ws_voice_control/src/robot_voice/src/tts_online_sample.ctts_subscribe.cpp
ⅡModificar archivos de código
Modifique tts_subscribe.cpp
① archivo de encabezado
para
#include "qtts.h"
#include "msp_cmn.h"
#include "msp_errors.h"
Cambiar a
#include "robot_voice/qtts.h"
#include "robot_voice/msp_cmn.h"
#include "robot_voice/msp_errors.h"
como muestra la imagen:
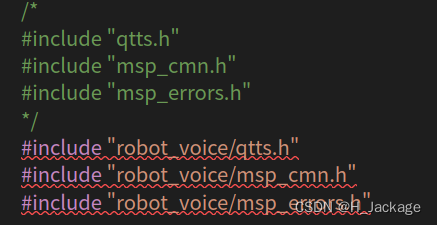
②Agregar archivo de encabezado ROS
#include "ros/ros.h"
#include "std_msgs/String.h"
③ Modifique el contenido del código
y elimine el contenido como se muestra en la imagen (en la función principal)

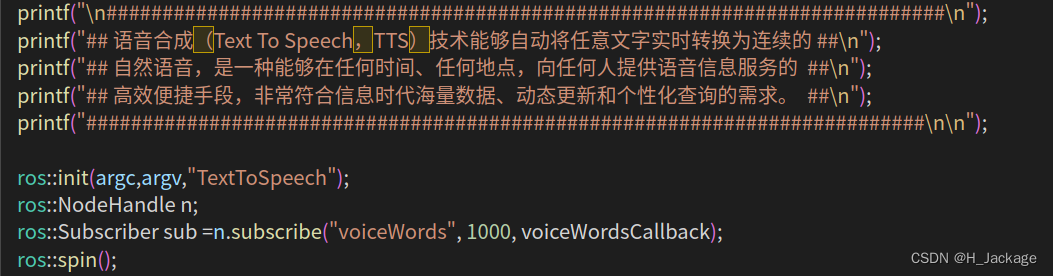
④Inserte el identificador de ros en la función principal
ros::init(argc,argv,"TextToSpeech");
ros::NodeHandle n;
ros::Subscriber sub =n.subscribe("voiceWords", 1000, voiceWordsCallback);
ros::spin();
⑤Inserte la función de devolución de llamada de texto a voz antes de la función principal
void voiceWordsCallback(const std_msgs::String::ConstPtr& msg)
{
char cmd[2000];
const char* text;
int ret = MSP_SUCCESS;
const char* session_begin_params = "voice_name = xiaoyan, text_encoding = utf8, sample_rate = 16000, speed = 50, volume = 50, pitch = 50, rdn = 2";
const char* filename = "tts_sample.wav"; //合成的语音文件名称
std::cout<<"I heard :"<<msg->data.c_str()<<std::endl;
text = msg->data.c_str();
/* 文本合成 */
printf("开始合成 ...\n");
ret = text_to_speech(text, filename, session_begin_params);
if (MSP_SUCCESS != ret)
{
printf("text_to_speech failed, error code: %d.\n", ret);
}
printf("合成完毕\n");
popen("play tts_sample.wav","r");
sleep(1);
}
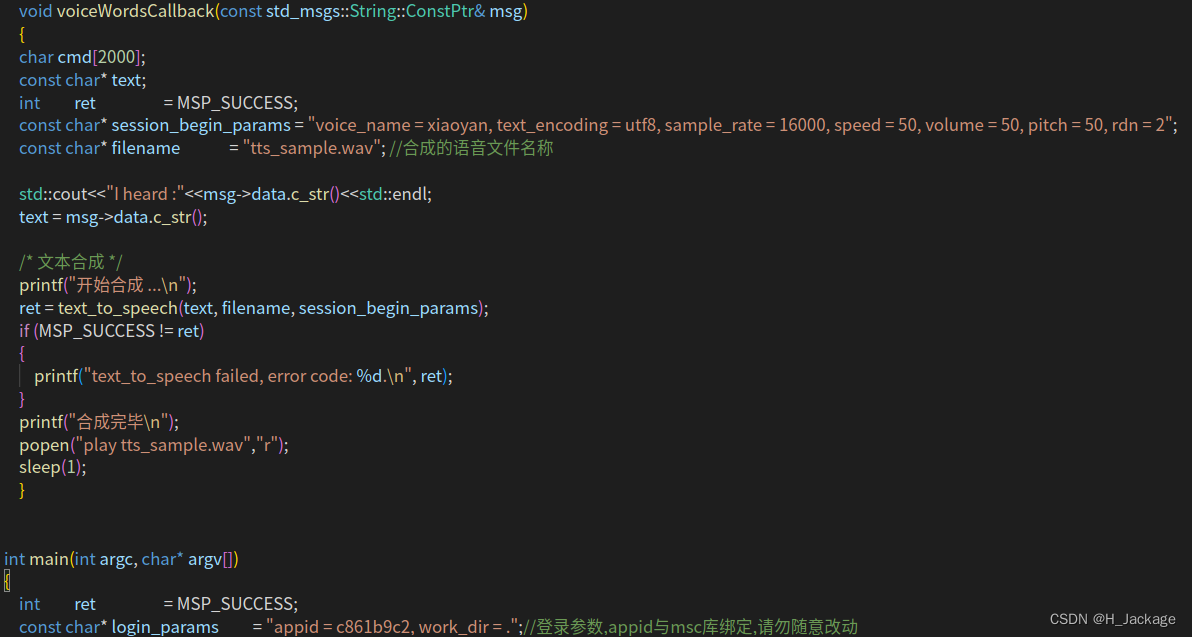
⑥Comenta parte de ello.

⑦ Corregir un error

void toExit()
{
printf("按任意键退出 ...\n");
getchar();
MSPLogout(); //退出登录
}
ⅢArchivo de compilación de configuración
Agregue lo siguiente al CMakeLists.txtarchivo
add_executable(tts_subscribe src/tts_subscribe.cpp)
target_link_libraries(tts_subscribe
${
catkin_LIBRARIES}
libmsc.so -ldl -pthread
)
ⅣEjecute el programa de código
Compilar paquete de funciones
(variable de entorno)
(ejecutar roscore)
ejecutar programa de código
rosrun robot_voice tts_subscribe
Luego abre otra terminal y ejecuta
rostopic pub /voiceWords std_msgs/String "data: ' 这是一个测试案例'"
Si se informa un error, puede encontrar el motivo usted mismo o utilizar mi código exitoso https://blog.csdn.net/m0_64730542/article/details/128792625
3. Utilice el archivo de inicio para convertir voz y texto entre sí.
ⅠIntroducción
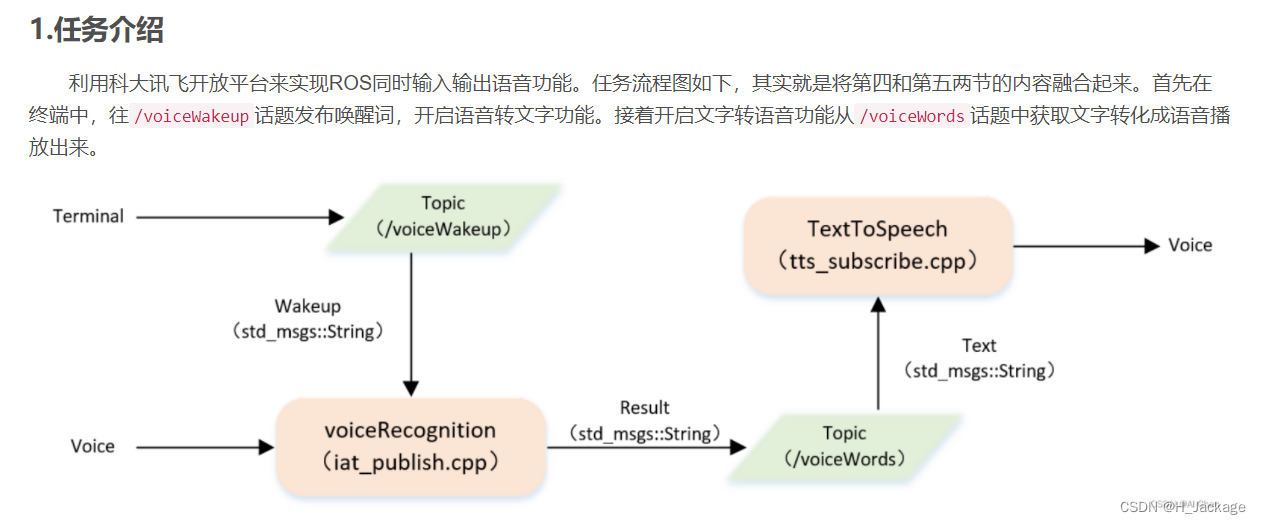
ⅡCrear archivo de inicio
①Cree un archivo home/安装Ubuntu的用户名/catkin_ws_voice_control/src/robot_voice/con el nombre debajo de la ruta launch.
②Cree un nuevo texto y asígnele el nombre con repeat_voice.launch
el contenido como
<launch>
<node name="iat_publish" pkg="robot_voice" type="iat_publish" output="screen"/>
<node name="tts_subscribe" pkg="robot_voice" type="tts_subscribe" output="screen"/>
</launch>
roslaunch robot_voice repeat_voice.launch
ⅢEjecute el programa de código
4. Implementar la interacción por voz
1. Introducción
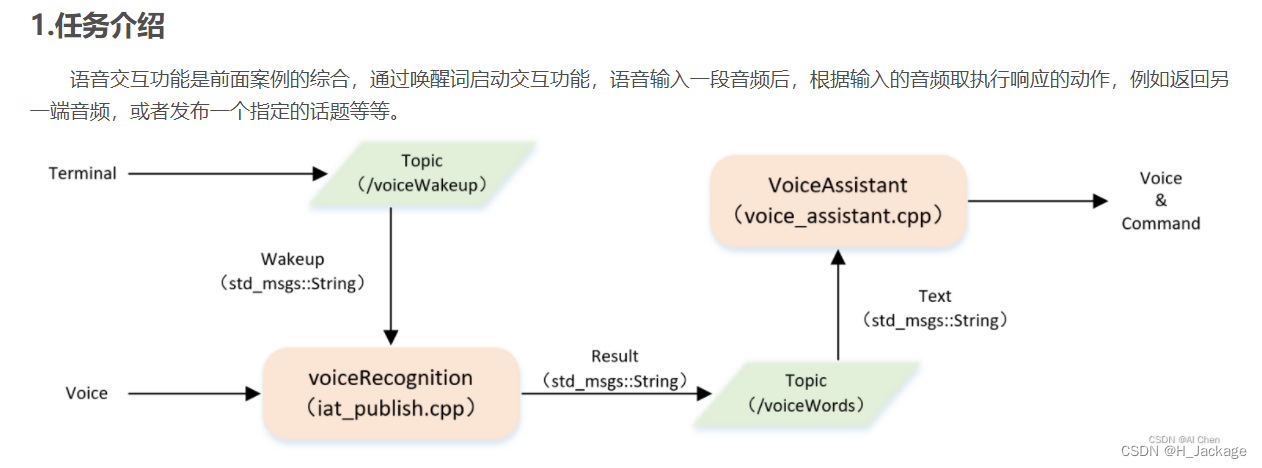
2. Modifique el archivo cpp

①Agregar to_string( )función
std::string to_string(int val)
{
char buf[20];
sprintf(buf, "%d", val);
return std::string(buf);
}
②Modificar voiceWordsCallback( )función
void voiceWordsCallback(const std_msgs::String::ConstPtr& msg)
{
char cmd[2000];
const char* text;
int ret = MSP_SUCCESS;
const char* session_begin_params = "voice_name = xiaoyan, text_encoding = utf8, sample_rate = 16000, speed = 50, volume = 50, pitch = 50, rdn = 2";
const char* filename = "tts_sample.wav"; //合成的语音文件名称
std::cout<<"I heard :"<<msg->data.c_str()<<std::endl;
std::string dataString = msg->data;
if(dataString.find("你是谁") != std::string::npos
|| dataString.find("名字") != std::string::npos)
{
char nameString[100] = "我是你的语音小助手,你可以叫我小R";
text = nameString;
std::cout<<text<<std::endl;
}
else if(dataString.find("你几岁了") != std::string::npos
|| dataString.find("年龄") != std::string::npos)
{
char eageString[100] = "我已经四岁了,不再是两三岁的小孩子了";
text = eageString;
std::cout<<text<<std::endl;
}
else if(dataString.find("你可以做什么") != std::string::npos
|| dataString.find("干什么") != std::string::npos)
{
char helpString[100] = "你可以问我现在时间";
text = helpString;
std::cout<<text<<std::endl;
}
else if(dataString.find("时间") != std::string::npos)
{
//获取当前时间
struct tm *ptm;
long ts;
ts = time(NULL);
ptm = localtime(&ts);
std::string string = "现在时间" + to_string(ptm-> tm_hour) + "点" + to_string(ptm-> tm_min) + "分";
char timeString[40] = {
0};
string.copy(timeString, sizeof(string), 0);
text = timeString;
std::cout<<text<<std::endl;
}
else
{
text = msg->data.c_str();
}
/* 文本合成 */
printf("开始合成 ...\n");
ret = text_to_speech(text, filename, session_begin_params);
if (MSP_SUCCESS != ret)
{
printf("text_to_speech failed, error code: %d.\n", ret);
}
printf("合成完毕\n");
popen("play tts_sample.wav","r");
sleep(1);
}
3. Configurar archivos de compilación
Añadiendo CMakeLists.txt_
add_executable(voice_assistant src/voice_assistant.cpp)
target_link_libraries(
voice_assistant
${
catkin_LIBRARIES}
libmsc.so -ldl -pthread
)
4. Crear archivo de inicio
Crea voice_assistant.launchun archivo nombrado con el contenido.
<launch>
<node name="iat_publish" pkg="robot_voice" type="iat_publish" output="screen"/>
<node name="voice_assistant" pkg="robot_voice" type="voice_assistant" output="screen"/>
</launch>
5. Ejecute el programa de código.
correr
roslaunch robot_voice voice_assistant.launch
luego publicar
rostopic pub /voiceWakeup std_msgs/String "data: 'any words'"
Listo para continuar