Instancia informática en tiempo real de Spark Streaming
1. Contenido experimental
: escriba una aplicación Spark Steaming para implementar estadísticas de frecuencia de palabras en tiempo real.
2. Pasos experimentales
1. Ejecute nc para simular la fuente de datos. nc -lk 9999 inicia el servidor y escucha el servicio Socket.
Orden:
nc -lk 9999
2. Cree un proyecto Maven y agregue la dependencia de Spark Streaming en el archivo pom.xml.
Código de dependencia:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hw</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<scala.version>2.12.15</scala.version>
<hadoop.version>2.7.4</hadoop.version>
<spark.version>3.1.2</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${
scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testOutputDirectory>src/test/scala</testOutputDirectory>
</build>
</project>
Las dependencias deben configurarse de acuerdo con los requisitos de la versión de su propia idea y los complementos instalados en su computadora. Una vez completada la configuración, la descarga comenzará automáticamente. Si no hay descarga, simplemente haga clic en el lado derecho de la idea para Mida maevn y se descargará automáticamente.
3.Escriba un programa y utilice el método updateStateByKey() para realizar estadísticas de frecuencia de palabras en tiempo real sobre el contenido ingresado continuamente por el cliente nc.
Operación de computadora
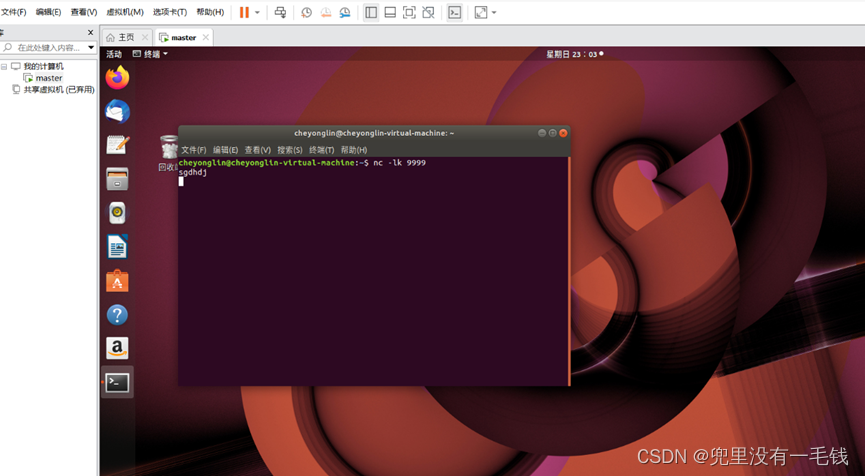
1. nc cliente
1. Comando para iniciar el cliente nc en la máquina virtual Linux:
nc -lk 9999
ingresar:
sgdhdj
Escriba cualquier letra aquí.
2. Captura de pantalla del cliente NC (datos requeridos)
2. Cliente de estadísticas de frecuencia de palabras en tiempo real
- Programa (el código debe estar comentado)
package cn.itcast.dstream
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
object UpdateSateByKeyTest {
//newValues 表示当前批次汇总成的(word,1)中相同单词的所有的1
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount =runningCount.getOrElse(0)+newValues.sum
Some(newCount)
}
def main(args: Array[String]): Unit = {
//创建sparkConf参数
val sparkConf: SparkConf = new SparkConf().setAppName("UpdateSateByKeyTest").setMaster("local[2]")
//构建sparkContext对象,它是所有对象的源头
val sc: SparkContext = new SparkContext(sparkConf)
//设置日志的级别
sc.setLogLevel("WARN")
//构建StreamingContext对象,需要两个参数,每个批处理的时间间隔
val scc: StreamingContext = new StreamingContext(sc, Seconds(5))
//设置checkpoint路径,当前项目下有一个cy目录
scc.checkpoint("./cy")
//注册一个监听的IP地址和端口 用来收集数据
val lines: ReceiverInputDStream[String] = scc.socketTextStream("192.168.118.128", 9999)
//切分每一行记录
val word: DStream[String] = lines.flatMap(_.split(" "))
//每个单词记为1
val wordAndOne: DStream[(String, Int)] = word.map((_, 1))
//累计统计单词出现的次数
val result: DStream[(String, Int)] = wordAndOne.updateStateByKey(updateFunction)
result.print()
//打印输出结果
scc.start()
//开启流式计算
scc.awaitTermination()
//保持程序运行,除非被打断
}
}
2. Captura de pantalla del cliente (debe tener resultados de cálculo en tiempo real)
