Transferencia de estilo arbitrario en tiempo real con normalización de instancia adaptable
Cuenta oficial: EDPJ
Tabla de contenido
0. Resumen
3.1 Normalización por lotes (Batch Normalization, BN)
3.2 Normalización de instancias (IN)
3.3 Normalización de instancia condicional (CIN)
4. Explicar la normalización de instancias
5. Normalización de instancia adaptable (AdaIN)
7.1 Comparación con otros métodos
4. El efecto de usar AdaIN en diferentes capas
S.3 Estructura y efecto de usar AdaIN en diferentes capas
0. Resumen
Gatys y otros [16] introdujeron recientemente un algoritmo neuronal que convierte el contenido de una imagen en el estilo de otra imagen, lo que permite la llamada transferencia de estilo. Sin embargo, su marco requiere un proceso de optimización iterativo lento, lo que limita su aplicación práctica. Se han propuesto aproximaciones rápidas que utilizan redes neuronales de alimentación hacia adelante para acelerar la transferencia de estilos neuronales. Desafortunadamente, esta mayor velocidad tiene un precio: las redes generalmente están vinculadas a un conjunto fijo de estilos y no pueden adaptarse a nuevos estilos arbitrarios. En este documento, proponemos un método simple pero efectivo que permite la transferencia de estilos arbitrarios en tiempo real por primera vez. En el corazón de nuestro enfoque se encuentra una nueva capa de Normalización de Instancia Adaptable (AdaIN) que alinea la media y la varianza de las características de contenido con las de las características de estilo. Nuestro método alcanza una velocidad comparable a los métodos existentes más rápidos y no está limitado por el conjunto de estilos predefinidos. Además, nuestro enfoque permite un control de usuario flexible, por ejemplo, compensaciones de contenido/estilo, interpolación de estilo, color y control espacial, todo utilizando una única red neuronal de avance.
1. Introducción
En este trabajo, proponemos el primer algoritmo de transferencia de estilo neuronal que aborda este dilema fundamental de flexibilidad/velocidad. Nuestro método puede transferir nuevos estilos arbitrarios en tiempo real, combinando la flexibilidad de un marco basado en optimización [16] con una velocidad similar a la de los métodos de avance más rápidos. Nuestro enfoque está inspirado en las capas de normalización de instancias (IN), que son sorprendentemente efectivas en la transferencia de estilo feed-forward. Para explicar el éxito de la normalización de instancias, proponemos una nueva explicación de que la normalización de instancias realiza la normalización de estilo al normalizar estadísticas de características, que se ha encontrado que contienen información de estilo de imágenes. Inspirándonos en nuestra explicación, presentamos una extensión simple de IN, la normalización de instancia adaptable (AdaIN). Dado el contenido y el estilo, AdaIN simplemente ajusta la media y la varianza de la imagen del contenido para que coincida con la media y la varianza de la imagen del estilo. A través de experimentos, encontramos que AdaIN combina efectivamente el contenido del primero y el estilo del segundo mediante la transferencia de estadísticas de funciones. Luego, la red del decodificador aprende a generar la imagen final invirtiendo la salida de AdaIN de nuevo en el espacio de la imagen. Nuestro método es casi tres órdenes de magnitud más rápido que [16] sin sacrificar la flexibilidad para transferir la entrada a nuevos estilos arbitrarios. Además, nuestro método proporciona un rico control de usuario en tiempo de ejecución sin modificaciones en el proceso de entrenamiento.
2. Trabajo relacionado
Transferencia de estilo . El problema de transferencia de estilo se origina en el renderizado no fotorrealista y está estrechamente relacionado con la síntesis y transferencia de texturas. Algunos de los primeros métodos incluían la comparación de histogramas de respuestas de filtros lineales y el muestreo no paramétrico. Estos métodos a menudo se basan en estadísticas de bajo nivel y, a menudo, no logran capturar la estructura semántica. Por primera vez, Gatys y otros [16] demostraron impresionantes resultados de transferencia de estilo al hacer coincidir estadísticas de características en las capas convolucionales de una DNN. Recientemente, se han propuesto varias mejoras sobre [16].
- Li y Wand introdujeron un marco basado en campos aleatorios de Markov (MRF) para aplicar patrones locales en espacios de características profundas.
- Gatys y otros propusieron métodos para controlar la escala de conservación del color, la ubicación espacial y la transferencia de estilo.
- Ruder y otros mejoraron la calidad de la transferencia de estilo de video al imponer restricciones temporales.
El marco de trabajo de Gatys [16] y otros se basa en un proceso de optimización lento que actualiza iterativamente las imágenes para minimizar la pérdida de contenido y la pérdida de estilo calculada por una red de pérdida. Incluso con las GPU modernas, la convergencia puede tardar varios minutos. Como resultado, el procesamiento en el dispositivo en aplicaciones móviles es demasiado lento para ser práctico.
- Una solución común es reemplazar el proceso de optimización con una red neuronal de avance entrenada para minimizar el mismo objetivo. Estos métodos de migración feed-forward son aproximadamente tres órdenes de magnitud más rápidos que las alternativas basadas en la optimización, lo que abre la puerta a las aplicaciones en tiempo real.
- La granularidad de la transferencia de avance se mejora mediante una arquitectura de resolución múltiple en Wang et al.
- Ulyanov y otros proponen métodos para mejorar la calidad y diversidad de las muestras generadas.
- Sin embargo, los métodos feed-forward antes mencionados están sujetos a un estilo fijo en cada red.
- Para abordar este problema, Dumoulin y otros introdujeron una red capaz de codificar 32 estilos y su interpolación.
- Al mismo tiempo que nuestro trabajo, Li y otros propusieron una arquitectura de avance que puede sintetizar hasta 300 texturas y transferir 16 estilos.
- Aún así, los dos métodos anteriores aún no pueden adaptarse a estilos arbitrarios que no se observan durante el entrenamiento.
Recientemente, Chen y Schmidt introdujeron un enfoque de avance que transfiere estilos arbitrarios a través de una capa de intercambio de estilos. Dadas las activaciones de funciones del contenido y las imágenes de estilo, la capa de intercambio de estilo reemplaza las funciones de contenido con las funciones de estilo que mejor coinciden parche por parche. Sin embargo, su capa de intercambio de estilo crea un nuevo cuello de botella computacional: más del 95 % del cálculo se gasta en el intercambio de estilo para imágenes de entrada de 512 × 512. Nuestro método también permite la transferencia de estilo arbitrario mientras es 1-2 órdenes de magnitud más rápido que Chen y Schmidt.
Otro tema central en la transferencia de estilo es qué función de pérdida de estilo usar. El marco original de Gatys y otros [16] combina estilos al comparar estadísticas de segundo orden entre activaciones de características, capturadas por la matriz de Gram. Se han propuesto otras funciones de pérdida efectiva, como pérdida MRF, pérdida adversaria, pérdida de histograma, pérdida CORAL, pérdida MMD y distancia entre medias y varianzas de canal. Tenga en cuenta que todas las funciones de pérdida anteriores tienen como objetivo hacer coincidir algunas estadísticas de características entre la imagen con estilo y la imagen sintetizada.
Modelado profundo de imágenes generativas . Existen varios marcos alternativos para la generación de imágenes, incluidos los codificadores automáticos variacionales, los modelos autorregresivos y las redes antagónicas generativas (GAN). En particular, las GAN han logrado la calidad visual más impresionante. Se han propuesto varias mejoras al marco GAN, como la generación condicional, el procesamiento en varias etapas y mejores objetivos de capacitación. Las GAN también se han aplicado a la transferencia de estilo y la generación de imágenes entre dominios.
3. Antecedentes
3.1 Normalización por lotes (Batch Normalization, BN)
El trabajo seminal de Ioffe y Szegedy introdujo capas de normalización por lotes (BN), que simplifica significativamente el entrenamiento de las redes de avance al normalizar las estadísticas de características. Las capas BN se diseñaron originalmente para acelerar el entrenamiento de redes discriminativas, pero también se ha demostrado que son eficaces en el modelado generativo de imágenes. Dado un lote de entrada x ∈ R^(N×C×H×W), BN normaliza la media y la desviación estándar de cada canal de función individual:
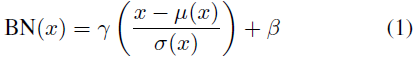
donde γ, β ∈ R^C son los parámetros afines aprendidos de los datos; μ(x), σ(x) ∈ R^C son la media y la desviación estándar, y el tamaño del lote y la dimensión espacial se calculan de forma independiente para cada característica canal:
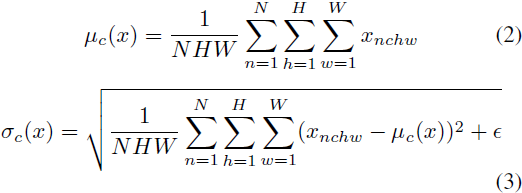
BN utiliza estadísticas de mini lotes en el momento del entrenamiento y las reemplaza con estadísticas de población en el momento de la inferencia, introduciendo así una diferencia entre el entrenamiento y la inferencia.
- La renormalización por lotes se propuso recientemente para abordar este problema mediante el uso gradual de las estadísticas de la población durante el entrenamiento.
- Como otra aplicación interesante de BN, Li y otros descubrieron que BN puede mitigar el cambio de dominio al volver a calcular las estadísticas de población en el dominio de destino.
- Recientemente, se han propuesto varios esquemas de normalización alternativos para extender la efectividad de los BN a arquitecturas recurrentes.
3.2 Normalización de instancias (IN)
En el método de estilización feed-forward original, la red de transferencia de estilo consta de una capa BN después de cada capa convolucional. Sorprendentemente, Ulyanov y otros encontraron mejoras significativas simplemente reemplazando las capas BN con capas IN:

A diferencia de las capas BN, aquí μ(x) y σ(x) se calculan de forma independiente en dimensión espacial para cada canal y cada muestra:
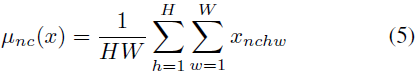
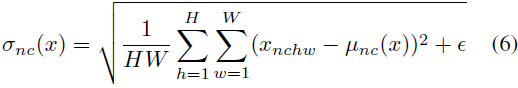
Otra diferencia es que las capas IN no varían en el momento de la prueba, mientras que las capas BN generalmente reemplazan las estadísticas de mini lotes con estadísticas de población.
3.3 Normalización de instancia condicional (CIN)
En lugar de aprender un conjunto de parámetros afines γ y β, Dumoulin y otros proponen una capa de normalización de instancia condicional (CIN) que aprende un conjunto diferente de parámetros γ^s y β^s para cada estilo s:
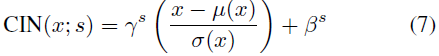
Durante el entrenamiento, las imágenes de estilo y sus índices s se seleccionan aleatoriamente de un conjunto de estilos fijos s ∈ {1, 2, ..., S} (S = 32 en sus experimentos). Luego, el contenido es procesado por la red de transferencia de estilo, donde los γ^s y β^s correspondientes se utilizan para la capa CIN. Sorprendentemente, la red puede generar estilos de imágenes completamente diferentes usando los mismos parámetros convolucionales pero diferentes parámetros afines en la capa IN.
En comparación con las redes sin capas de normalización, las redes con capas CIN requieren parámetros adicionales de 2FS, donde F es el número total de mapas de características en la red. Dado que la cantidad de parámetros adicionales se escala linealmente con la cantidad de estilos, es un desafío escalar su método para modelar una gran cantidad de estilos (por ejemplo, decenas de miles). Además, su método no puede adaptarse a nuevos estilos arbitrarios sin volver a entrenar la red.
4. Explicar la normalización de instancias
A pesar del gran éxito de las normalizaciones de instancias (condicionales), las razones por las que son particularmente efectivas en la transferencia de estilo siguen siendo esquivas. Ulyanov y otros atribuyen el éxito de IN a su invariancia al contraste del contenido de la imagen. Sin embargo, IN ocurre en el espacio de características, por lo que debería tener un impacto más profundo que la simple normalización del contraste en el espacio de píxeles. Quizás lo más sorprendente es que el parámetro afín en IN puede cambiar completamente el estilo de la imagen de salida.
Es bien sabido que las estadísticas de características convolucionales de las DNN pueden capturar el estilo de las imágenes. Si bien Gatys y otros [16] utilizaron estadísticas de segundo orden como objetivo de optimización, Li y otros demostraron recientemente que igualar muchas otras estadísticas, incluidas las medias y las varianzas del canal, también es eficaz para la transferencia de estilo. Inspirándonos en estas observaciones, consideramos que la normalización de instancias realiza una forma de normalización de estilo al normalizar las estadísticas de características (es decir, la media y la varianza). Aunque los DNN se usan como descriptores de imágenes en [16], argumentamos que las estadísticas de características de la red del generador también pueden controlar el estilo de las imágenes generadas.
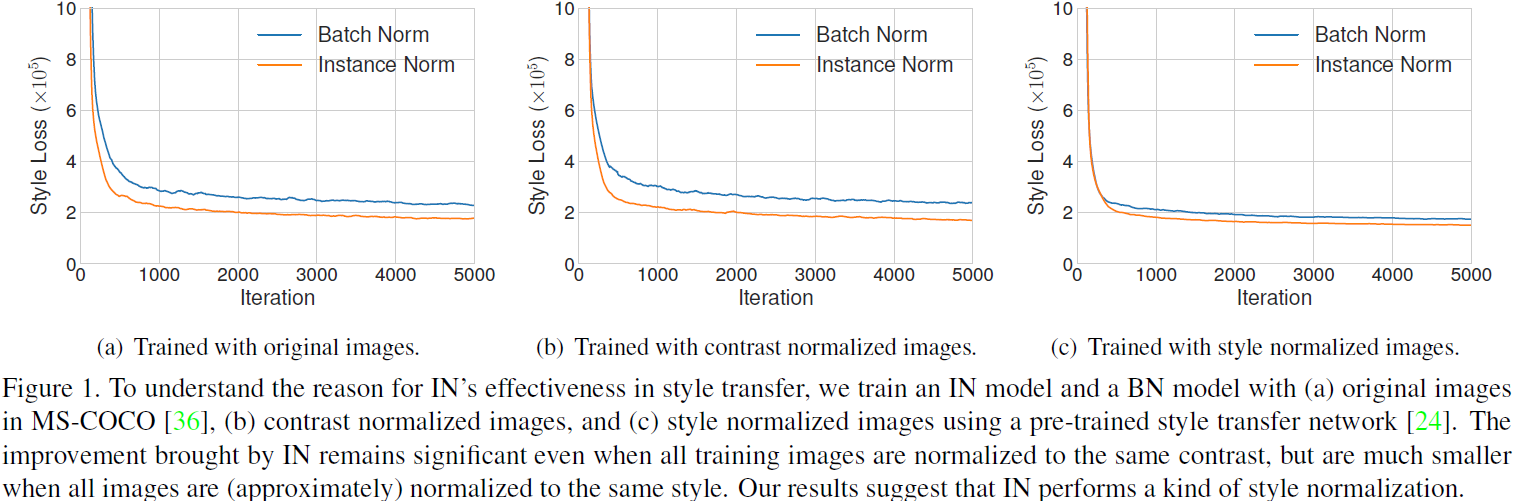
Ejecutamos el código para una red de textura modificada para realizar una transferencia de estilo único, con capas IN o BN. Como era de esperar, el modelo con IN converge más rápido que el modelo BN (Fig. 1(a)). Para probar la interpretación en la red de textura mejorada, luego normalizamos todas las imágenes de entrenamiento al mismo contraste al realizar la ecualización del histograma en el canal de luminancia. Como se muestra en la Figura 1(b), IN todavía funciona, lo que indica que la interpretación en la red de textura mejorada es incompleta. Para probar nuestra hipótesis, normalizamos todas las imágenes de entrenamiento al mismo estilo (diferente del estilo de destino) usando una red de transferencia de estilo previamente entrenada. De acuerdo con la Fig. 1(c), cuando la imagen ha sido normalizada por estilo, la mejora aportada por IN se vuelve muy pequeña. La brecha restante puede explicarse por la normalización imperfecta del estilo. Además, los modelos entrenados con BN en imágenes con estilo normalizado pueden converger tan rápido como los modelos entrenados con IN en imágenes originales. Nuestros resultados muestran que IN realiza una normalización de estilo.
Muchas muestras en lugar de una sola muestra pueden entenderse intuitivamente como la normalización de un lote de muestras para centrarse en un solo estilo. Sin embargo, cada muestra aún puede tener un estilo diferente. Esto no es deseable cuando queremos transferir todas las imágenes al mismo estilo, como es el caso del algoritmo de transferencia de estilo feed-forward original. Aunque las capas convolucionales pueden aprender a compensar las diferencias de estilo dentro del lote, presenta desafíos adicionales para el entrenamiento. Por otro lado, IN puede normalizar el estilo de cada muestra individual al estilo de destino. La capacitación es conveniente porque el resto de la red puede enfocarse en la manipulación de contenido y descartar información de estilo sin procesar. La razón detrás del éxito de CIN también queda clara: diferentes parámetros afines pueden normalizar las estadísticas de características a diferentes valores y, por lo tanto, normalizar la imagen de salida a diferentes estilos.
5. Normalización de instancia adaptable (AdaIN)
Si IN normaliza la entrada a un solo estilo especificado por el parámetro Affine, ¿se puede adaptar a cualquier estilo dado mediante una transformación afín adaptativa? Aquí, proponemos una extensión simple para IN, que llamamos Normalización de Instancia Adaptativa (AdaIN). AdaIN toma el contenido x y el estilo y, y simplemente alinea la media del canal y la varianza de x e y. A diferencia de BN, IN o CIN, AdaIN no tiene parámetros afines que se puedan aprender. En su lugar, calcula los parámetros afines de forma adaptativa en función de la entrada de estilo:
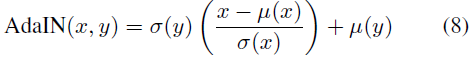
donde simplemente escalamos el contenido normalizado por σ(y) y lo compensamos por μ(y). Al igual que IN, estas estadísticas se calculan en ubicaciones espaciales.
Intuitivamente, consideremos un canal de características que detecta trazos específicos del estilo. Las imágenes estilizadas con tales trazos generarán activaciones promedio altas para esta función. La salida de AdaIN tendrá la misma activación promedio alta para esta característica mientras conserva la estructura espacial de la imagen del contenido. Las características del trazo se pueden invertir en el espacio de la imagen utilizando un decodificador de avance. La variación de este canal de funciones puede codificar información de estilo más sutil, que también se pasa a la salida de AdaIN y a la imagen de salida final.
En resumen, AdaIN realiza la transferencia de estilo en el espacio de características mediante la transferencia de estadísticas de características, especialmente las medias y variaciones del canal. Nuestra capa AdaIN juega un papel similar a la capa de intercambio de estilo propuesta en [6]. Aunque la operación de intercambio de estilos requiere mucho tiempo y memoria, nuestra capa AdaIN es tan simple como la capa IN con un costo computacional adicional mínimo.
6. Configuración experimental
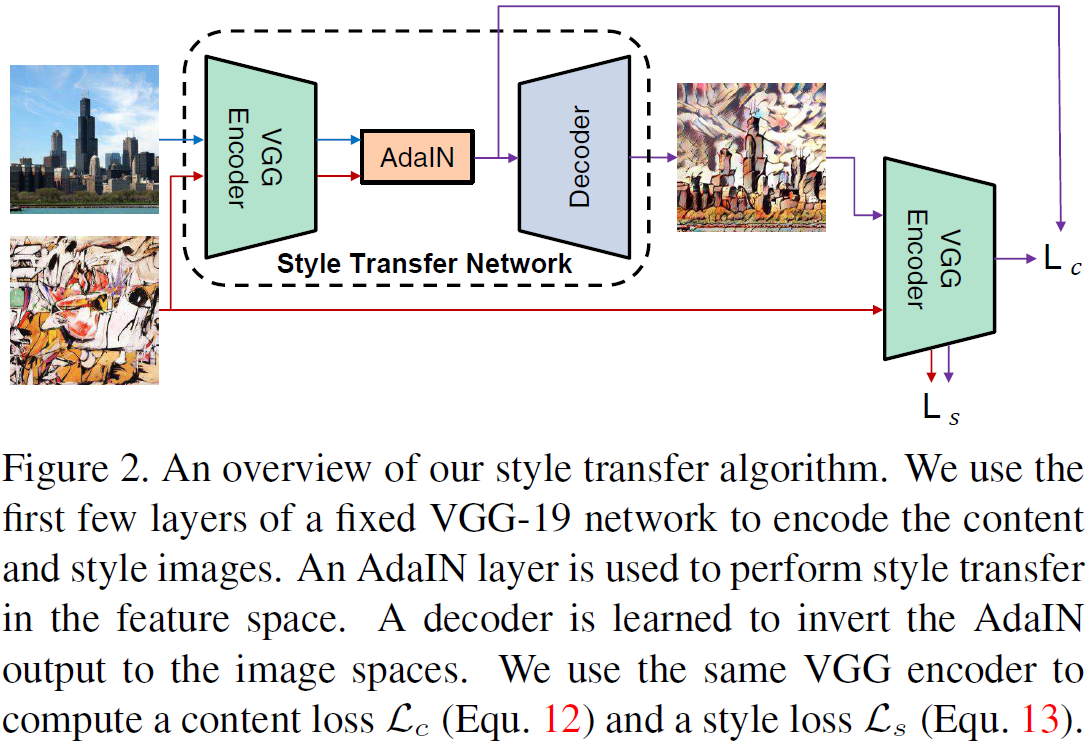
6.1 Estructura
Nuestra red de transferencia de estilo T toma como entrada una imagen de contenido c y una imagen de estilo arbitraria s, y sintetiza una imagen de salida que recombina el contenido de la primera y el estilo de la segunda. Adoptamos una arquitectura de codificador-decodificador simple donde el codificador f se fija a las primeras capas de VGG-19 preentrenado (hasta relu4_1). Después de codificar las imágenes de contenido y estilo en el espacio de características, alimentamos ambos mapas de características a la capa AdaIN, que alinea la media y la varianza de los mapas de características de contenido y estilo, lo que da como resultado el mapa de características de destino t:
![]()
Entrene un decodificador g inicializado aleatoriamente para mapear t nuevamente en el espacio de la imagen, produciendo imágenes estilizadas T (c, s):
![]()
El decodificador es principalmente una imagen especular del codificador, y todas las capas de agrupación se reemplazan por un muestreo ascendente reciente para reducir los efectos de tablero de ajedrez. Usamos relleno de reflexión tanto en f como en g para evitar artefactos de contorno. Otra elección arquitectónica importante es si el decodificador debe usar IN, BN o ninguna normalización. Como se discutió en la Sección 2, IN normaliza cada muestra a un solo estilo, mientras que BN normaliza un lote de muestras para centrarse en un solo estilo. Tampoco es deseable cuando queremos que el decodificador genere imágenes en estilos drásticamente diferentes. Por lo tanto, no usamos una capa de normalización en el decodificador. En la Sección 7.1 mostramos que las capas IN/BN en el decodificador afectan el rendimiento.
6.2 Formación
Siguiendo la configuración de [6], entrenamos nuestra red utilizando MS-COCO como imágenes de contenido y un conjunto de datos de pinturas recopiladas principalmente de WikiArt como imágenes de estilo. Cada conjunto de datos contiene alrededor de 80 000 ejemplos de entrenamiento. Usamos el optimizador Adam y 1 lote consta de 8 pares de imágenes de estilo de contenido. Durante el entrenamiento, primero cambiamos el tamaño mínimo de las dos imágenes a 512 mientras mantenemos la relación de aspecto y luego recortamos aleatoriamente regiones de tamaño 256 × 256. Dado que nuestra red es totalmente convolucional, se puede aplicar a imágenes de cualquier tamaño durante la prueba.
Usamos el VGG-19 preentrenado para calcular la función de pérdida para entrenar el decodificador:
![]()
Esta es una combinación ponderada de pérdida de contenido L_c y pérdida de estilo L_s con peso de pérdida de estilo λ. La pérdida de contenido es la distancia euclidiana entre las características de destino y las características de la imagen de salida. Usamos la salida t de AdaIN como objetivo de contenido en lugar de las respuestas de funciones habituales para las imágenes de contenido. Encontramos que esto conduce a una convergencia ligeramente más rápida y también cumple con nuestro objetivo de invertir la salida t de AdaIN.
![]()
Dado que nuestra capa AdaIN solo transfiere la media y la desviación estándar de las características de estilo, nuestra pérdida de estilo solo coincide con estas estadísticas. Si bien encontramos que la pérdida de matriz de Gram comúnmente utilizada puede producir resultados similares, igualamos la estadística IN porque es conceptualmente más clara. Esta pérdida de estilo también fue explorada por Li et al.

donde cada φ_i representa la capa en VGG-19 utilizada para calcular la pérdida de estilo. En nuestros experimentos, usamos capas relu1_1, relu2_1, relu3_1, relu4_1 con los mismos pesos.
7. Resultados
En esta subsección, comparamos nuestro método con tres métodos de transferencia de estilo:
- Métodos flexibles pero lentos basados en la optimización, Gatys [16],
- métodos de avance rápido limitados a un solo estilo, Ulyanov [52],
- Un método flexible de velocidad media basado en parches, Chen y M. Schmidt [6].
Si no se indica lo contrario, los resultados de los métodos comparados se obtuvieron ejecutando su código con la configuración predeterminada. Para [6], usamos la red inversa preentrenada proporcionada por los autores. Todas las imágenes de prueba tienen un tamaño de 512×512.
7.1 Comparación con otros métodos

resultados cualitativos . En la Fig. 4, mostramos resultados de transferencia de estilo de ejemplo generados por el método de comparación.
- Tenga en cuenta que todas las imágenes de estilo de prueba nunca se observan durante el entrenamiento de nuestro modelo, mientras que los resultados de Ulyanov se obtienen ajustando una red a cada estilo de prueba.
- Aun así, para muchas imágenes (p. ej., filas 1, 2, 3), la calidad de nuestras imágenes estilizadas es bastante competitiva con la de Ulyanov y Gatys.
- En algunos otros casos (por ejemplo, la fila 5), nuestro método está ligeramente por detrás de la calidad de Ulyanov y Gatys. Esto no es sorprendente, ya que creemos que existen tres ventajas y desventajas entre velocidad, flexibilidad y calidad.
- En comparación con Chen y M. Schmidt, nuestro método parece transferir estilos de manera más fiel para la mayoría de las imágenes de comparación.
- El último ejemplo ilustra claramente una importante limitación del intento de Chen y M. Schmidt de hacer coincidir cada parche de contenido con el mejor parche de estilo. Sin embargo, la transferencia de estilo falla si la mayoría de los parches de contenido coinciden con unos pocos parches de estilo que no representan el estilo de destino.
- Por lo tanto, consideramos que la coincidencia de estadísticas de características globales es una solución más general, aunque en algunos casos (p. ej., fila 3), el método de Chen y M. Schmidt también puede producir resultados atractivos.
Evaluación cuantitativa . ¿Nuestro algoritmo sacrifica algo de calidad por una mayor velocidad y flexibilidad, y si es así, cuánto? Para responder cuantitativamente a esta pregunta, comparamos nuestro método con métodos basados en optimización (Gatys) y métodos rápidos de transferencia de estilo único (Ulyanov) en términos de pérdida de contenido y estilo. Debido a que nuestro método usa una pérdida de estilo basada en estadísticas IN, también modificamos las funciones de pérdida en (Gatys) y (Ulyanov) en consecuencia para una comparación justa (sus resultados en la Fig. 4 aún se obtienen usando la pérdida de matriz de Gram predeterminada). La pérdida de contenido que se muestra aquí es la misma que en (Ulyanov, Gatys). Los números informados son el promedio de 10 imágenes de estilo seleccionadas al azar y 50 imágenes de contenido del conjunto de datos de WikiArt y el conjunto de prueba de MS-COCO.
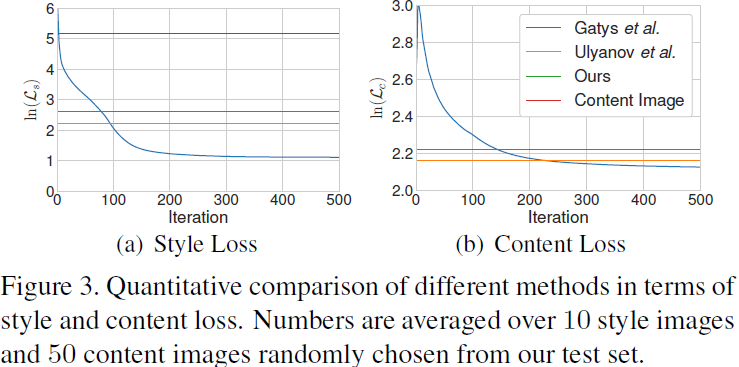
Como se muestra en la Figura 3, la pérdida promedio de contenido y estilo de nuestras imágenes sintéticas es ligeramente mayor, pero comparable con el método de transferencia de estilo único de Ulyanov et al. En particular, nuestro método y Ulyanov logran una pérdida de estilo similar a la de Gatys entre 50 y 100 iteraciones de optimización. Esto demuestra la gran capacidad de generalización de nuestro método, considerando que nuestra red nunca ve el patrón de prueba durante el entrenamiento, mientras que cada red en Gatys se entrena exclusivamente en el patrón de prueba. También tenga en cuenta que nuestra pérdida de estilo es mucho menor que la de la imagen de contenido original.
análisis de velocidad . La mayor parte de nuestro cálculo se gasta en la codificación de contenido, la codificación de estilo y la decodificación, cada una de las cuales requiere aproximadamente un tercio del tiempo. En algunos escenarios de aplicación, como el procesamiento de video, la imagen de estilo solo necesita codificarse una vez, y AdaIN puede usar las estadísticas de estilo almacenadas para procesar todas las imágenes posteriores. En algunos otros casos (por ejemplo, transformar el mismo contenido en diferentes estilos), el cálculo gastado en la codificación del contenido se puede compartir.

En la Tabla 1, comparamos la velocidad de nuestro método con métodos anteriores. Excluyendo el tiempo de codificación del estilo, nuestro algoritmo se ejecuta a 56 y 15 FPS para imágenes de 256 × 256 y 512 × 512, respectivamente, lo que permite procesar estilos arbitrarios subidos por el usuario en tiempo real. Entre los algoritmos aplicables a estilos arbitrarios, nuestro método es casi 3 órdenes de magnitud más rápido que (Gatys) y 1 o 2 órdenes de magnitud más rápido que (Chen y Schmidt). La mejora de la velocidad con respecto a (Chen y Schmidt) es especialmente importante para las imágenes de mayor resolución, ya que la capa de intercambio de estilo en (Chen y Schmidt) no se adapta bien a las imágenes de estilo de alta resolución. Además, nuestro método alcanza una velocidad comparable a los métodos feed-forward limitados a unos pocos estilos (Ulyanov, Dumoulin). El tiempo de procesamiento ligeramente más largo de nuestro método se debe principalmente a nuestra red basada en VGG más grande que a limitaciones metodológicas. Con una arquitectura más eficiente, nuestra velocidad se puede mejorar aún más.
7.2 Experimentos adicionales
En esta subsección, llevamos a cabo experimentos para justificar nuestras importantes elecciones arquitectónicas. Denotamos el método descrito en la Sección 6 como Enc-AdaIN-Dec. Experimentamos con un modelo llamado Enc-Concat-Dec, reemplazando AdaIN con concatenación, una estrategia de referencia natural para combinar información de imágenes de contenido y estilo. Además, ejecutamos el modelo con capas BN/IN en el decodificador, denominadas Enc-AdaIN-BNDec y Enc-AdaIN-INDec respectivamente. Otros ajustes de entrenamiento permanecen sin cambios.

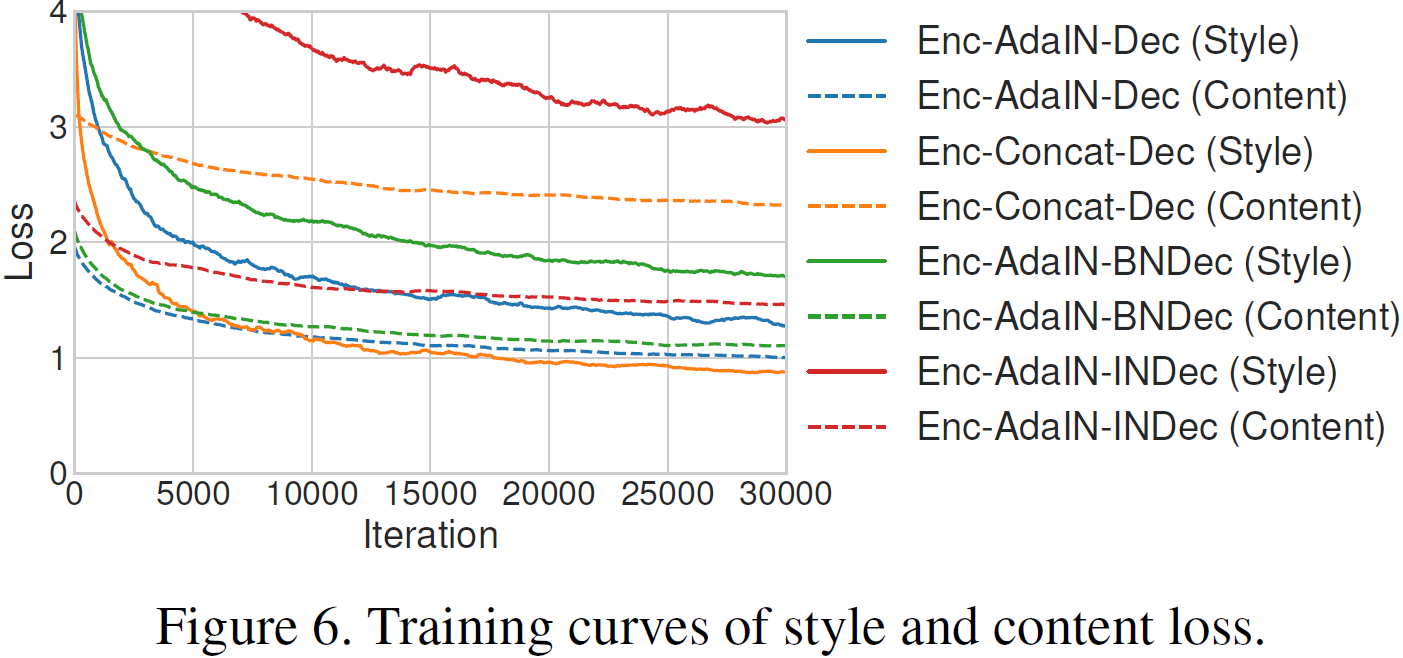
En las Figuras 5 y 6 mostramos ejemplos y curvas de entrenamiento para diferentes métodos. En las imágenes generadas por la línea de base Enc-Concat-Dec (Fig. 5(d)), los contornos del objeto de la imagen de estilo se pueden observar claramente, lo que indica que la red no pudo separar la información de estilo del contenido de la imagen de estilo. Esto también es consistente con la Fig. 6 Consistente, donde Enc-Concat-Dec puede lograr una baja pérdida de estilo pero no puede reducir la pérdida de contenido. Los modelos con capas BN/IN también obtienen resultados de peor calidad y pérdidas consistentemente mayores. Los resultados para la capa IN son particularmente malos. Esto nuevamente valida nuestra afirmación de que las capas IN tienden a normalizar la salida a un solo estilo y, por lo tanto, deben evitarse cuando queremos generar imágenes de diferentes estilos.
7.3 Control en tiempo real
Para resaltar aún más la flexibilidad de nuestro método, mostramos que nuestra red de transferencia de estilo permite a los usuarios controlar el grado de estilización, interpolar entre diferentes estilos, transferir estilos conservando el color y usar diferentes estilos en diferentes regiones espaciales. Tenga en cuenta que todos estos controles usan la misma aplicación web solo en tiempo de ejecución, sin modificaciones en el proceso de capacitación.
Compensaciones de estilo de contenido . El grado de transferencia del estilo se puede controlar durante el entrenamiento ajustando el peso del estilo λ en la Ecuación 11. Además, nuestro método permite compensaciones de estilo de contenido en el momento de la prueba al interpolar entre los mapas de características proporcionados al decodificador. Tenga en cuenta que esto es equivalente a interpolar entre los parámetros afines de AdaIN.
![]()
Cuando α = 0, la red intenta reconstruir fielmente la imagen del contenido, y cuando α = 1 sintetiza la imagen más estilizada.

Como se muestra en la Figura 7, se puede observar una transición suave entre la similitud de contenido y la similitud de estilo al variar α (de 0 a 1).

Interpolación de estilo . Para interpolar entre un conjunto de imágenes de estilo K s1, s2, ..., sK, los pesos correspondientes w1, w2, ..., wK tal que
![]()
De manera similar, interpolamos entre mapas de características (los resultados se muestran en la Figura 8):
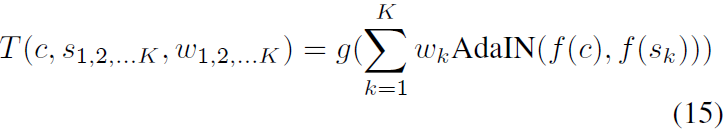
Control de espacio y color . Gatys y otros introdujeron recientemente el control del usuario sobre la ubicación espacial de la información de color y la transferencia de estilo, que se puede incorporar fácilmente a nuestro marco. Para conservar el color de la imagen de contenido, primero hacemos coincidir la distribución de color de la imagen de estilo con la de la imagen de contenido y, a continuación, realizamos una transferencia de estilo normal utilizando la imagen de estilo alineada con el color como entrada de estilo. Los resultados de ejemplo se muestran en la Figura 9. .

En la Figura 10, demostramos que nuestro método puede transformar diferentes regiones de imágenes de contenido en diferentes estilos. Esto se logra ejecutando AdaIN por separado en diferentes regiones en el mapa de características de contenido utilizando estadísticas de diferentes entradas de estilo, similar pero de manera totalmente anticipada. Aunque nuestro decodificador solo está entrenado en entradas con estilo homogéneo, se generaliza naturalmente a entradas con diferentes estilos en diferentes regiones.
8. Discusión y conclusión
En este documento, proponemos una capa simple de normalización de instancia adaptable (AdaIN), que por primera vez permite la transferencia de estilo arbitrario en tiempo real. Además de aplicaciones fascinantes, creemos que este trabajo arroja luz sobre nuestra comprensión de las representaciones generales de imágenes de profundidad.
Es interesante considerar las diferencias conceptuales entre nuestro método y los métodos de transferencia de estilo neuronal anteriores basados en estadísticas de características. Gatys et al emplean un proceso de optimización para manipular los valores de píxeles para que coincidan con las estadísticas de características. En algunos artículos, el proceso de optimización se reemplaza por redes neuronales de avance. Aún así, la red está entrenada para modificar los valores de píxeles para que coincidan indirectamente con las estadísticas de características. Tomamos un enfoque muy diferente al alinear directamente las estadísticas en el espacio de características de una sola vez y luego invertir las características de nuevo al espacio de píxeles.
Dada la simplicidad de nuestro método, creemos que todavía hay mucho margen de mejora. En trabajos futuros, planeamos explorar arquitecturas de red más avanzadas, como arquitecturas residuales o arquitecturas con conexiones de salto adicionales desde el codificador. También planeamos investigar esquemas de entrenamiento más complejos como el entrenamiento incremental. Además, nuestra capa AdaIN alinea solo las estadísticas de características más básicas (media y varianza). Reemplazar AdaIN con alineación de correlación o coincidencia de histogramas puede mejorar aún más la calidad mediante la transferencia de estadísticas de orden superior. Otra dirección interesante es aplicar AdaIN a la síntesis de texturas.
apéndice
4. El efecto de usar AdaIN en diferentes capas

La Figura 2 muestra el efecto de implementar AdaIN con diferentes capas. El uso de relu4_1 logra mejores resultados de percepción que las capas anteriores.
referencia
[16] LA Gatys, AS Ecker y M. Bethge. Transferencia de estilo de imagen utilizando redes neuronales convolucionales. En CVPR, 2016.
[52] D. Ulyanov, A. Vedaldi y V. Lempitsky. Redes de texturas mejoradas: maximización de la calidad y la diversidad en la estilización anticipada y la síntesis de texturas. En CVPR, 2017.
[6] TQ Chen y M. Schmidt. Transferencia de estilo rápida basada en parches de estilo arbitrario. preimpresión de arXiv arXiv:1612.04337, 2016.
Huang X, Belongie S. Transferencia de estilo arbitrario en tiempo real con normalización de instancia adaptativa[C]//Actas de la conferencia internacional IEEE sobre visión artificial. 2017: 1501-1510.
S. Resumen
S.1 Idea principal
Para explicar el éxito de la normalización de instancias, los autores proponen una nueva explicación de que la normalización de instancias realiza la normalización de estilo al normalizar las estadísticas de características, que contienen información de estilo de las imágenes. En base a esto, el autor propone la Normalización de Instancia Adaptativa (AdaIN). Dado el contenido y el estilo, AdaIN solo necesita ajustar la media y la varianza de la imagen de contenido para que coincida con la media y la varianza de la imagen de estilo, de modo que la imagen generada tenga el contenido de la primera y el estilo de la segunda.
S.2 ADAIN
AdaIN se muestra en la Ecuación 8:
donde x e y denotan la imagen de contenido y la imagen de estilo, respectivamente. μ(x) y σ(x) denotan la media y la desviación estándar de las imágenes de contenido, y μ(y) y σ(y) denotan la media y la desviación estándar de las imágenes de estilo. Dado que las estadísticas de características de la imagen llevan la información de estilo de la imagen, después de eliminar la información de estilo de la imagen de contenido a través de la normalización y luego usar las estadísticas de características (información de estilo) de la imagen de estilo para realizar una transformación afín, la transferencia de estilo puede ser realizado.
S.3 Estructura y efecto de usar AdaIN en diferentes capas


La estructura de red utilizada en este documento y el efecto de usar AdaIN en diferentes capas se muestran en las dos figuras anteriores.
Dado que AdaIN opera en función de las estadísticas de las características de la imagen (espacio de características), las últimas capas de la red pueden extraer características más precisas. En función de los valores estadísticos de estas características precisas, el estilo de la imagen del contenido se puede eliminar por completo durante la normalización de la instancia, logrando así una transferencia de estilo de mayor calidad.