Tabla de contenido
1 pregunta
Al usar Codeblock hoy, descubrí que la salida china del terminal de Codeblock estaba confusa durante la compilación.
Cuando ve el mensaje "Para evitar la pérdida de datos, este archivo se guardó como UTF-8" en la esquina inferior derecha del bloque de código, aparecen caracteres confusos.
2. Analiza los motivos
Hay mucha información en Internet que dice:
La razón del código confuso es que los métodos de decodificación de la codificación local del sistema y el compilador de bloques de código son diferentes. Es un conflicto entre el método de codificación GBK y el método de codificación UTF-8. .
Al principio no lo entendí del todo, pero luego lo analicé detenidamente.
Hay dos tipos de galimatías:
- El archivo está confuso cuando se abre.
- Caracteres confusos en la salida del terminal
El archivo está confuso cuando se abre.
como sigue:
cout<<"±à¼Æ÷£ºÉèÖÃΪÁËĬ"<<endl;
cout<<"±àÒëÆ÷£ºÄ¬ÈÏ"<<endl;
cout << "Hello world!" << endl;
Esto está relacionado con el método de codificación del editor.
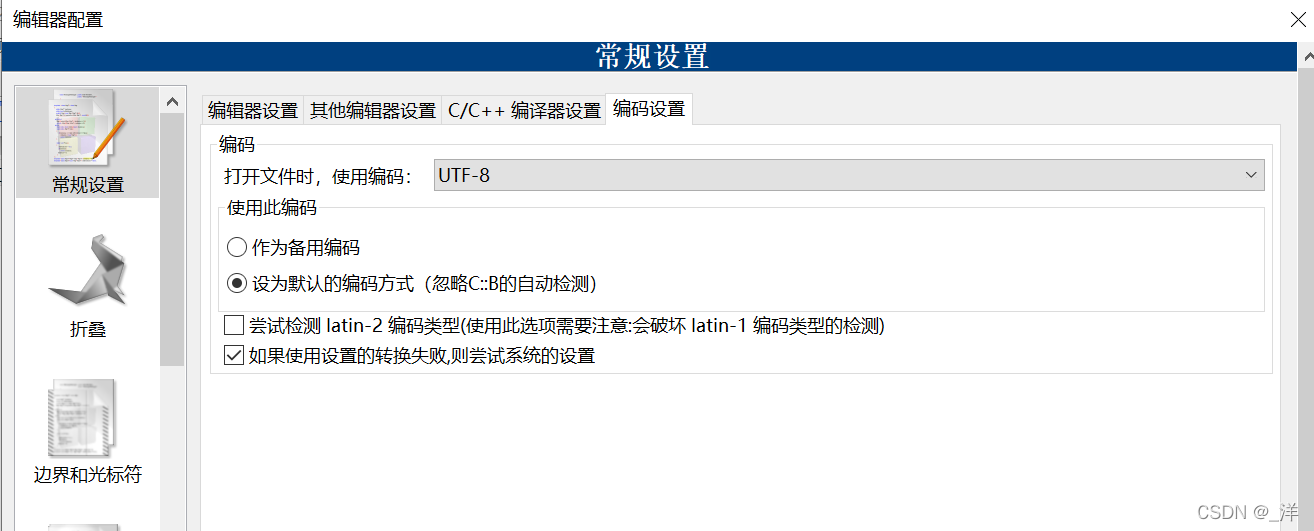
Configuración->Editor->Configuración de codificación
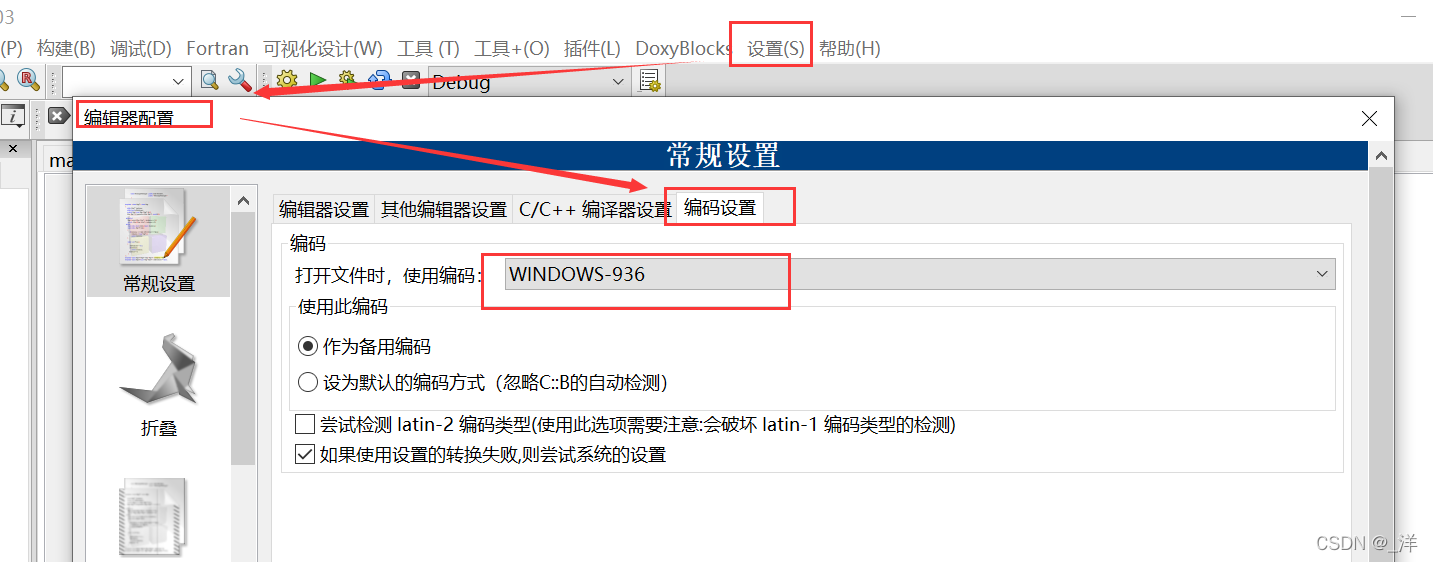
Encontramos uno aquí 打开文件时,使用编码, que es el formato de codificación que usamos al guardar y abrir archivos:
Hay dos métodos de codificación que usamos comúnmente: UTF-8 y GBK
WINDOWS-936 representa el formato de codificación GBK, GBK es el formato de codificación utilizado por Windows;
UTF-8 es el formato de codificación predeterminado de codeblock y UTF-8 es el formato de codificación de Linux.
Digresión:
es precisamente debido al conflicto entre estos dos formatos que mingGW proporciona un entorno de desarrollo de programas basado en GCC en Windows, que simula el entorno de desarrollo de GCC en Linux en la plataforma Windows.
Volviendo al tema, todavía usamos el formato de codificación WINDOWS-936 más comúnmente en el sistema Windows, pero debe tenerse en cuenta que debe seleccionarse.En “使用此编码”este “设为默认的编码方式”caso, el formato de codificación de los archivos que guarde y abra será el mismo. y no habrá caracteres confusos al abrir el archivo. Por supuesto, también es posible elegir UTF-8, pero también es necesario ajustar el método de codificación de la compilación posterior.
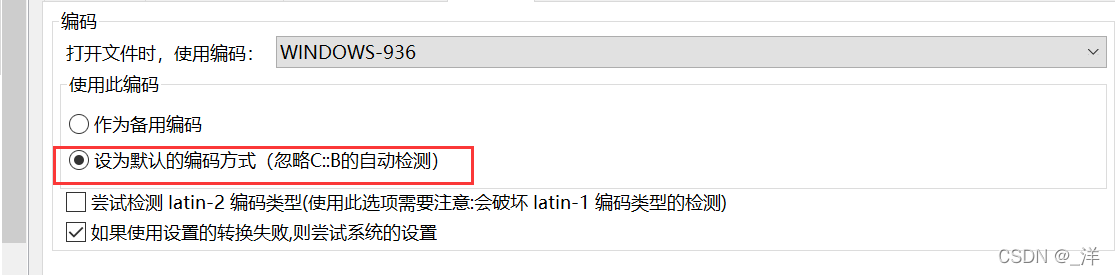
Lo que elegí antes fue que “作为备用编码”esto simplemente haría que codeblock detectara primero el formato de codificación y luego usara el formato de codificación que definimos si no se detecta. Es lógico que no haya ningún problema, pero no sé por qué mi bloque de código debería reconocer automáticamente el archivo como codificación UTF-8, incluso si el archivo es GBK. Por supuesto, si se abre un archivo GBK utilizando el análisis UTF-8, aparecerán los caracteres confusos anteriores.
Nota : El formato de codificación del archivo es el mismo que el formato establecido por el editor de bloques de código cuando se guarda, y el formato de codificación no se puede modificar después de guardarlo.
Caracteres confusos en la salida del terminal
Los caracteres confusos de salida del terminal están relacionados con el compilador:
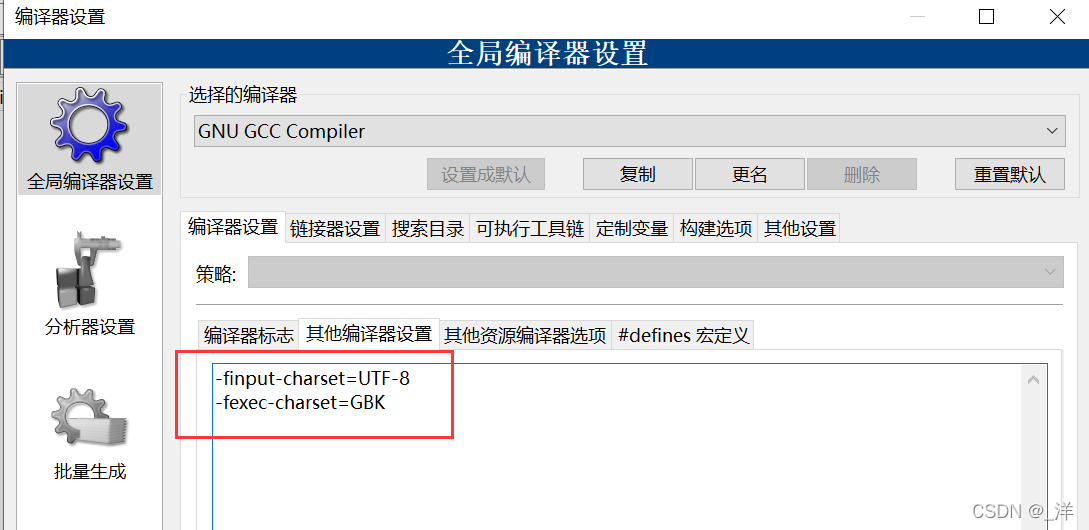
Configuración->Compilador
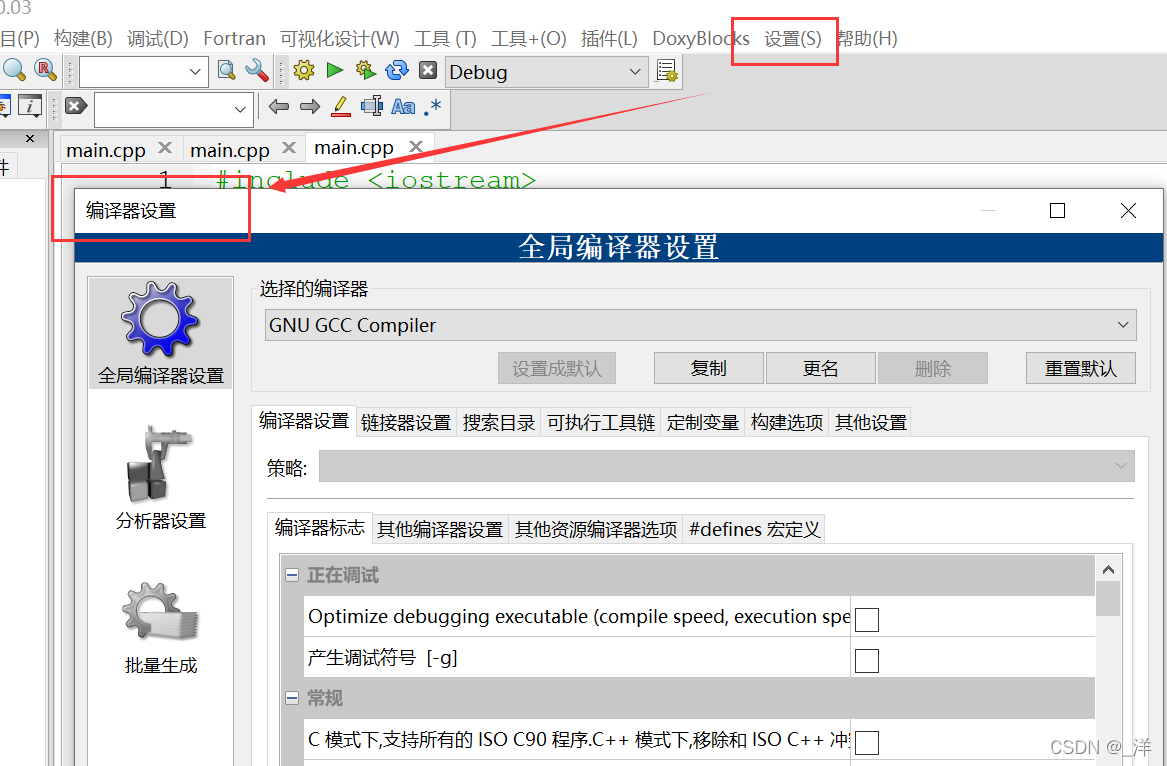
Aquí se necesitan dos comandos:
-finput-charset=charset
-fexec-charset=charset
significado:
-finput-charset=charset especifica qué codificación usa el compilador para interpretar el archivo fuente de entrada, requiereEl mismo formato de codificación que el archivo fuente., la compilación es posible sólo si los formatos son los mismos;
si los formatos son diferentes, se informará el siguiente error:

no se puede compilar en absoluto.
-finput-charset=El valor predeterminado del juego de caracteres es UTF-8;
-fexec-charset=charset es el formato de codificación utilizado para enviar al terminal durante la compilación.
-fexec-charset=charset es UTF-8 de forma predeterminada, pero Windows no puede reconocerlo, por lo que debe cambiarse a GBK para que los caracteres confusos no aparecerá.
3. Resumen
En resumen, el bloque de código tiene dos formatos para configurar la codificación:
(1)GBK-GBK-GBK
Configuración->Editor->Usar codificación WINDOWS-936

Configuración->Compilador->Otras configuraciones del compilador Ingrese
la siguiente declaración:
-finput-charset=GBK
-fexec-charset=GBK
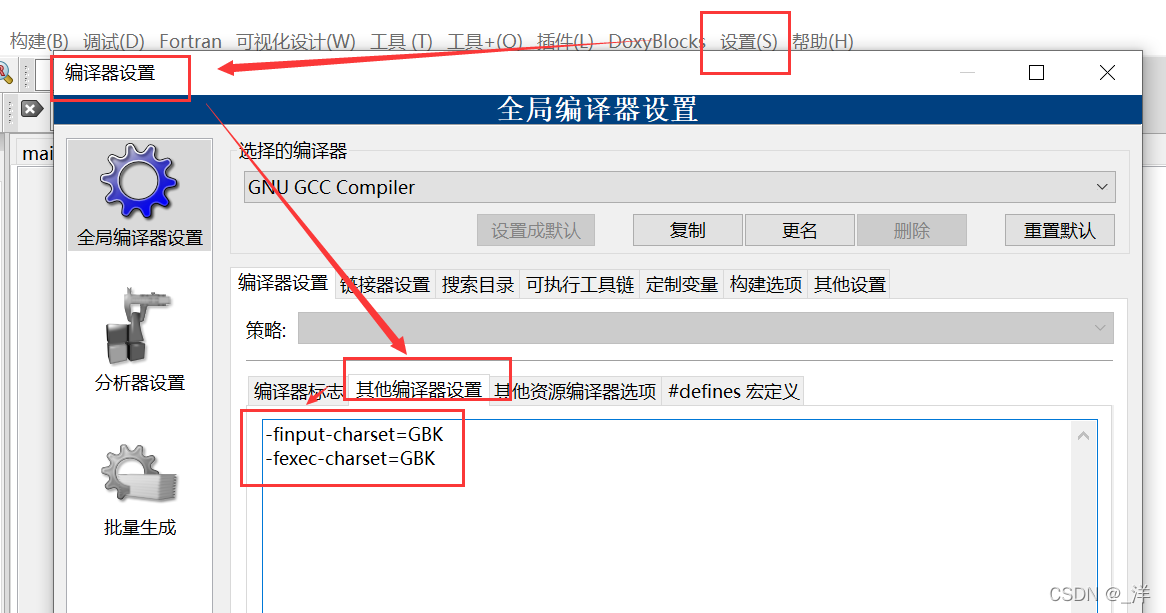
(2)UTF-8-UTF-8-GBK
Configuración->Editor->Usar codificación UTF-8
Configuración->Compilador->Otras configuraciones del compilador Ingrese
la siguiente declaración:
-finput-charset=UTF-8
-fexec-charset=GBK
4.Atención
Lo mejor es abrir archivos en ambos formatos con el formato de codificación correspondiente:
es decir, los archivos creados con UTF-8 - UTF-8 - GBK también deben abrirse con la configuración UTF-8 - UTF-8 - GBK, y los
archivos creados con GBK-GBK-GBK Simplemente use la configuración GBK-GBK-GBK para abrirlo.
De lo contrario, pueden ocurrir problemas como que no se encuentren archivos y que desaparezcan códigos.
(Descubrí que mi bloque de código:
UTF-8 - UTF-8 - La configuración GBK abre archivos GBK-GBK-GBK sin problemas y puede mostrar el contenido del código; la configuración
GBK-GBK-GBK abre archivos UTF-8 - UTF-8 - GBK está bien, no aparecerá, me asustó en ese momento
)