Tabla de contenido
3. Deducción de índices en InnoDB
4. Conceptos comunes de índice
4.2 Índice secundario (índice auxiliar, índice no agrupado)
¿Por qué necesitas volver a la mesa?
5. Precauciones para el índice de árbol B+ de InnoDB
5.1 La ubicación de la página raíz permanecerá sin cambios durante miles de años
5.2 Unicidad de registros de entrada de directorio en nodos internos
5.3 Una página almacena al menos 2 registros
1. Por qué usar índices
El índice es una estructura de datos utilizada por el motor de almacenamiento para encontrar rápidamente registros de datos, al igual que la parte del catálogo de un libro de texto.Al encontrar el número de página del artículo correspondiente en el catálogo, puede ubicar rápidamente el artículo requerido. Lo mismo es cierto en MySQL. Al buscar datos, primero verifique si la condición de consulta alcanza un índice. Si coincide, use el índice para encontrar los datos relevantes. De lo contrario, debe escanear toda la tabla , es decir, debe buscar registros uno por uno hasta que encuentre los registros de datos correspondientes que cumplan con la condición.

El propósito de la indexación: para reducir la cantidad de E/S de disco y acelerar la tasa de consulta .
2. Resumen del índice
La definición oficial de índice de MySQL es: Índice (Índice) es una estructura de datos que ayuda a MySQL a obtener datos de manera eficiente .
La naturaleza del índice: el índice es una estructura de datos. Puede entenderse como una "estructura de datos de búsqueda rápida ordenada" que satisface un algoritmo de búsqueda específico. Estas estructuras de datos apuntan a los datos de alguna manera para que se puedan implementar algoritmos de búsqueda avanzados sobre estas estructuras de datos.
Los índices se implementan en motores de almacenamiento , por lo que los índices de cada motor de almacenamiento no son necesariamente idénticos y cada motor de almacenamiento no admite necesariamente todos los tipos de índice. Al mismo tiempo, el motor de almacenamiento puede definir el número máximo de índices y la longitud máxima del índice para cada tabla . Todos los motores de almacenamiento admiten al menos 16 índices por tabla y la longitud total del índice es de al menos 256 bytes. Algunos motores de almacenamiento admiten más índices y longitudes de índice más grandes.
ventaja
- Similar a la construcción de un índice bibliográfico en una biblioteca universitaria, mejora la eficiencia de la recuperación de datos y reduce el costo de IO de la base de datos Esta es también la razón principal para crear un índice.
- Al crear un índice único, se puede garantizar la unicidad de cada fila de datos en la base de datos .
- En términos de lograr la integridad referencial de los datos, puede acelerar las uniones entre tablas . En otras palabras, la velocidad de consulta se puede mejorar cuando la tabla secundaria dependiente y la tabla principal se consultan conjuntamente.
- Cuando se utilizan cláusulas de agrupación y clasificación para la consulta de datos, puede reducir significativamente el tiempo de agrupación y clasificación en la consulta y reducir el consumo de CPU.
defecto
Agregar índices también tiene muchas desventajas, principalmente las siguientes:
- Crear y mantener índices lleva tiempo y, a medida que aumenta la cantidad de datos, aumenta el tiempo consumido.
- Los índices necesitan ocupar espacio en disco. Además del espacio de datos ocupado por las tablas de datos, cada índice también ocupa una cierta cantidad de espacio físico y se almacena en el disco. Si hay una gran cantidad de índices, el archivo de índice puede ser más grande que el archivo de datos y alcanzar el tamaño máximo de archivo. .
- Aunque el índice mejora considerablemente la velocidad de consulta, reducirá la velocidad de actualización de la tabla. Al agregar, eliminar y modificar los datos de la tabla, el índice también debe mantenerse de forma dinámica, lo que reduce la velocidad del mantenimiento de datos.
Por lo tanto, al elegir usar un índice, las ventajas y desventajas del índice deben considerarse de manera integral.
3. Deducción de índices en InnoDB
3.1 Página de datos
- La página es la unidad básica de intercambio de disco y memoria en mysql, y también la unidad básica del espacio de almacenamiento de administración de mysql.
- Todos los espacios de tabla de la misma instancia de base de datos tienen el mismo tamaño de página; de forma predeterminada, el tamaño de página en el espacio de tabla es de 16 KB, por supuesto, el tamaño predeterminado también se puede modificar cambiando la opción innodb_page_size, y es importante tener en cuenta que diferentes tamaños de página Eventualmente también resultará en una diferencia en el tamaño de la zona.
- Al menos 16 KB de contenido se leen del disco a la memoria a la vez, y al menos 16 KB de contenido en la memoria se descargan al disco a la vez. Por supuesto, el costo de leer una sola página es bastante alto, y la prelectura es generalmente realizado
3.2 Buscar en una página
Suponiendo que hay relativamente pocos registros en la tabla actual, todos los registros se pueden almacenar en una página. Al buscar registros, se puede dividir en dos situaciones según las diferentes condiciones de búsqueda:
- Usar la clave principal como condición de búsqueda
Puede utilizar el método de dicotomía en el directorio de páginas para ubicar rápidamente el espacio correspondiente y luego recorrer los registros en el grupo correspondiente al espacio para encontrar rápidamente el registro especificado.
- Usar otras columnas como criterio de búsqueda
Debido a que no existe el llamado directorio de páginas para columnas de clave no principal en la página de datos, no podemos ubicar rápidamente la ranura correspondiente a través del método de dicotomía. En este caso, solo podemos recorrer cada registro en la lista enlazada de forma secuencial comenzando desde el registro más pequeño y luego comparar si cada registro cumple con las condiciones de búsqueda. Obviamente, la eficiencia de esta búsqueda es muy baja.
3.2 Buscar en muchas páginas
En la mayoría de los casos, hay muchos registros almacenados en nuestras tablas y se necesitan muchas páginas de datos para almacenar estos registros. La búsqueda de registros en muchas páginas se puede dividir en dos pasos:
- Navegue a la página donde se encuentra el registro.
- Busque el registro correspondiente en la página donde se encuentra.
En ausencia de un índice, ya sea buscando en base a los valores de la columna de clave principal u otras columnas, dado que no podemos ubicar rápidamente la página donde se encuentra el registro, solo podemos buscar hacia abajo en la lista doblemente enlazada desde la primera página . En cada página, busque el registro especificado de acuerdo con nuestro método de búsqueda anterior. Debido a que es necesario recorrer todas las páginas de datos, este método obviamente consume mucho tiempo . ¿Qué pasa si una tabla tiene 100 millones de registros? En este punto nació el índice .
3.3 Diseñar un índice
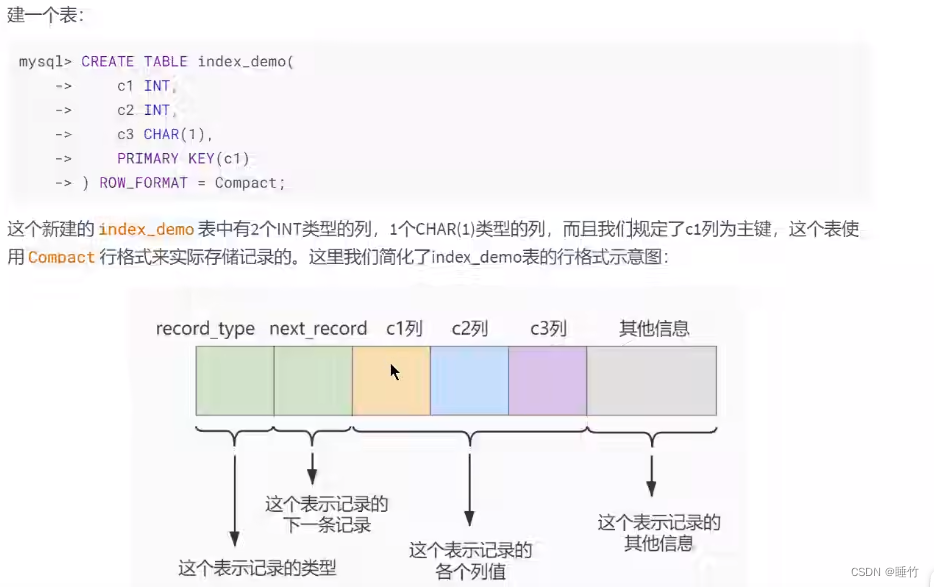







Pregunta: Cuando hay más y más páginas de datos, significa que hay más y más elementos de directorio. Si se insertan nuevos datos entre páginas de datos, entonces los elementos de directorio también deben insertarse en un nuevo directorio correspondiente. Si el anterior (El valor almacenado en la entrada del directorio es continuo), es imposible de realizar (igual que la página de datos, de hecho, la entrada del directorio es la página de datos). Por lo tanto, podemos procesar los elementos del directorio como páginas de datos, capa por capa: record_type en el formato de fila principal


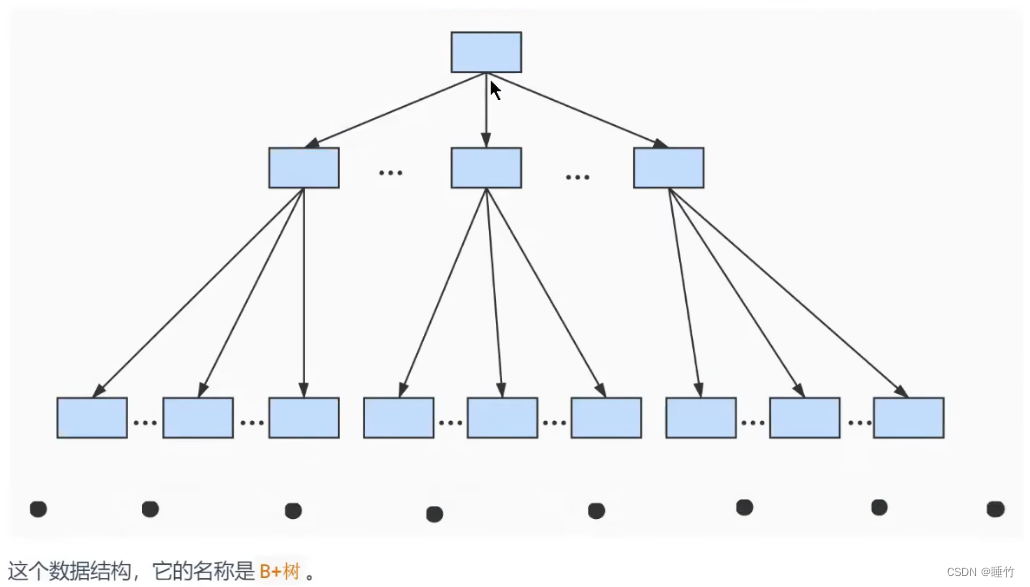
- Cada cuadro azul es una página de datos,
- El último nodo se llama nodo hoja, que almacena datos reales
- Los datos en los nodos hoja se almacenan en forma de una lista enlazada unidireccional, y los nodos hoja se almacenan en una lista doblemente enlazada (lógicamente continua)
- Los nodos que no son hojas se denominan páginas de directorio.

Aviso:
- Cuantos más niveles del árbol, más veces IO
4. Conceptos comunes de índice
Los índices se pueden dividir en dos tipos según su implementación física: índice agrupado (clustered) e índice no agrupado.También llamamos índice no agrupado índice secundario o índice auxiliar.
4.1, índice agrupado
El índice agrupado no es un tipo de índice separado, sino un método de almacenamiento de datos (todos los registros de usuario se almacenan en nodos hoja), es decir, el llamado índice son datos y los datos son índices
- El término "agrupación" significa que las filas de datos se almacenan juntas en grupos de valores clave adyacentes
características
1. Use el tamaño del valor de la clave principal del registro para ordenar registros y páginas, lo que incluye tres aspectos
- Los registros en la página ( es decir, los nodos en el árbol ) se organizan en una lista vinculada de un solo elemento en el orden del tamaño de la clave principal
- Una lista doblemente enlazada se organiza entre las hojas y las hojas de acuerdo con el orden del valor de la clave principal
- Las páginas que almacenan registros de entrada de directorio (no nodos hoja, no almacenan datos reales) se dividen en diferentes niveles, y las páginas en el mismo nivel también se organizan en una lista doblemente enlazada según el orden del tamaño de la clave principal del directorio. registros de entrada en la página
2. Los nodos hoja del árbol B+ almacenan registros de usuario completos (datos)
- El llamado registro de usuario completo significa que los valores de todas las columnas (incluidas las columnas ocultas) se almacenan en este registro
Llamamos al árbol B+ con estas dos características un índice agrupado, y todos los registros de usuario completos se almacenan en los nodos hoja de este índice agrupado. Este índice agrupado no requiere que usemos explícitamente la declaración INDEX en la declaración de MySQL para crear, el motor de almacenamiento InnoDB creará automáticamente un índice agrupado para nosotros.
ventaja
- El acceso a los datos es más rápido porque el índice agrupado almacena el índice y los datos en el mismo árbol B+, por lo que obtener datos del índice agrupado es más rápido que el índice no agrupado.
- La búsqueda de clasificación y la búsqueda de rango de la clave principal por el índice agrupado son más rápidas (porque está ordenada, como buscar datos con una identificación mayor que 12, solo obtenga todos los datos después de 12 directamente)
- De acuerdo con el orden de clasificación del índice agrupado, cuando la consulta muestra un cierto rango de datos, debido a que los datos están estrechamente conectados, la base de datos no necesita extraer datos de múltiples bloques de datos y el índice ahorra muchas operaciones IO ( la ventaja de construir un índice)
defecto
- La velocidad de inserción depende en gran medida del orden de inserción , y la inserción en el orden de la clave principal es la más rápida; de lo contrario, se producirán divisiones de página, lo que afectará gravemente al rendimiento. Por lo tanto, para las tablas de InnoDB, generalmente definimos una columna de ID de incremento automático como clave principal
- El costo de actualizar la clave principal es mayor , porque hará que la fila actualizada se mueva. Por lo tanto, para las tablas de InnoDB, generalmente la clave principal como no actualizable.
- El acceso al índice secundario requiere dos búsquedas de índice , la primera para encontrar el valor de la clave principal y la segunda para encontrar datos de fila basados en el valor de la clave principal.
límite
- Para la base de datos MySQL, solo la base de datos InnoDB actualmente admite el índice agrupado, mientras que MyISAM no admite el índice agrupado
- Dado que solo existe un método de clasificación para el almacenamiento físico de datos, cada tabla mysql solo puede tener un índice agrupado , que generalmente es la clave principal de la tabla.
- Si no se define una clave principal, InnoDB elegirá un índice único no vacío en su lugar Si no existe tal índice, InnoDB definirá implícitamente una clave principal como un índice agrupado.
- Para hacer un uso completo de las características de agrupamiento del índice agrupado, la columna de clave principal de la tabla InnoDB indexada debe usar una identificación de secuencia ordenada tanto como sea posible, y no se recomienda usar una identificación desordenada, como UUID, MD5, HASH y cadena como clave principal, y no se puede garantizar el orden de crecimiento de los datos.
4.2 Índice secundario (índice auxiliar, índice no agrupado)
El índice agrupado mencionado anteriormente solo puede ser efectivo para la búsqueda de clave principal (los datos en el árbol B+ se ordenan de acuerdo con la clave principal), ¿qué pasa si queremos usar otras columnas como condición de búsqueda? (ciertamente no desde cero)
Respuesta:
- Cree algunos árboles B+ más. Los datos en diferentes árboles B+ adoptan diferentes reglas de clasificación. Por ejemplo, usamos el tamaño de la columna c2 como página de datos y luego construimos otro árbol B+ de acuerdo con las reglas de clasificación registradas en la página.
- Este árbol contiene la clave principal y el valor de la columna c2 , excluyendo otras columnas
- Cuando seleccione * de xxx donde c2 = 4, los datos de c2=4 se encontrarán a través de este árbol B+
- Luego, de acuerdo con los datos de c2 = 4, obtenga el valor de clave principal correspondiente y luego busque la clave principal (índice agrupado) a través de la operación de regresar a la tabla , y finalmente obtenga los datos correspondientes (índice agrupado obtiene todos los datos)
- Se necesita buscar un total de 2 árboles B+
formulario de devolución
Solo podemos determinar el valor de la clave principal que se buscará en función del árbol B+ ordenado por el tamaño de la columna c2 Si encontramos el registro de usuario completo en función del valor de la columna c2, aún debemos verificarlo nuevamente en el índice agrupado Este proceso se llama back table.
¿Por qué necesitas volver a la mesa?
- Si coloca todos los datos completos en los nodos hoja, no necesita volver a la tabla, pero ocupa demasiado espacio.Es equivalente a copiar todos los datos cada vez que construye un árbol B+, que es un desperdicio de espacio de almacenamiento.
Debido a que este tipo de árbol B+ construido de acuerdo con la clave no principal necesita una operación de retorno de tabla para obtener el registro de usuario completo, todo este tipo de árbol B+ también se denomina índice secundario (nombre en inglés índice secundario) o índice auxiliar. Dado que usamos el tamaño de la columna c2 como la regla de clasificación del árbol B+, también llamamos a este árbol B+ el índice creado para la columna c2.

Resumir
- Los nodos de hoja del índice agrupado almacenan nuestros registros de datos, y los nodos de hoja del índice no agrupado almacenan la ubicación de los datos (la ubicación de los datos aquí se refiere a dónde está la clave principal de los datos, es decir, quién es la clave principal ). Los índices no agrupados no afectan el orden de almacenamiento físico de las tablas de datos.
- Una tabla solo puede tener un índice agrupado, porque solo puede haber una forma de ordenar y almacenar, pero puede haber varios índices no agrupados, es decir, varios directorios de índices proporcionan recuperación de datos.
- Cuando se utiliza un índice agrupado, la eficiencia de la consulta de datos es alta, pero si los datos se insertan, eliminan, actualizan, etc., la eficiencia será menor que la del índice no agrupado. (Razón: según el caso anterior, el índice agrupado almacena todos los datos y hay tres columnas en c1/c2/c3, mientras que el índice no agrupado de c2 solo tiene c1/c2. Cuando se actualizan los datos, el el costo de cambio de índice es bajo)
4.3 Índice conjunto
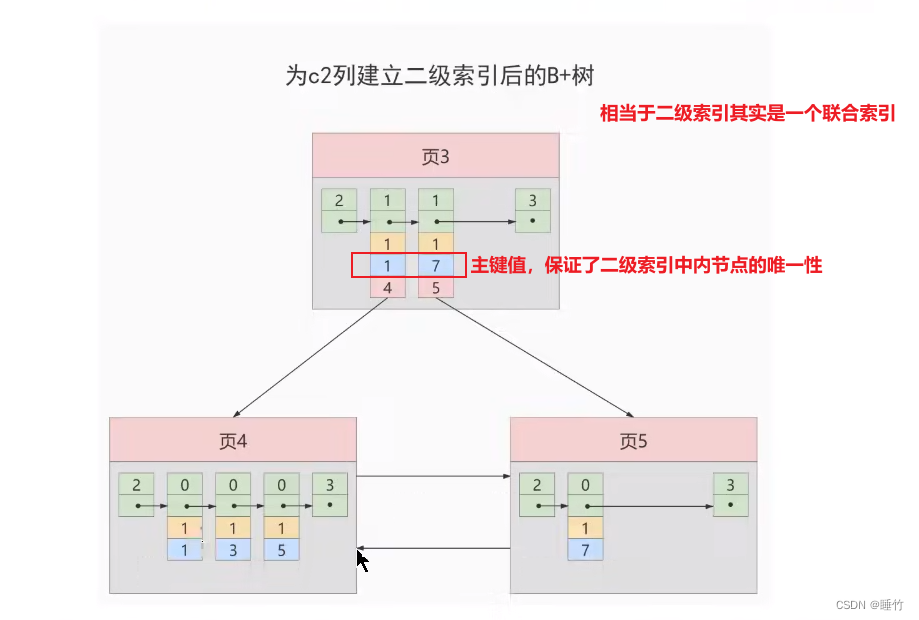
También podemos usar el tamaño de varias columnas como regla de ordenación al mismo tiempo, es decir, crear índices para varias columnas al mismo tiempo. Por ejemplo, queremos que el árbol B+ se ordene según el tamaño de c2 y c3 columnas Esto contiene dos significados:
- Primero ordene cada registro y página según la columna c2.
- En el caso de que la columna c2 del registro sea la misma, se utiliza la columna c3 para ordenar.
El diagrama esquemático del índice establecido para las columnas c2 y c3 es el siguiente:
 Esto implica el principio de coincidencia más a la izquierda
Esto implica el principio de coincidencia más a la izquierda
- Esencialmente un índice secundario
5. Precauciones para el índice de árbol B+ de InnoDB
5.1 La ubicación de la página raíz permanecerá sin cambios durante miles de años

5.2 Unicidad de registros de entrada de directorio en nodos internos
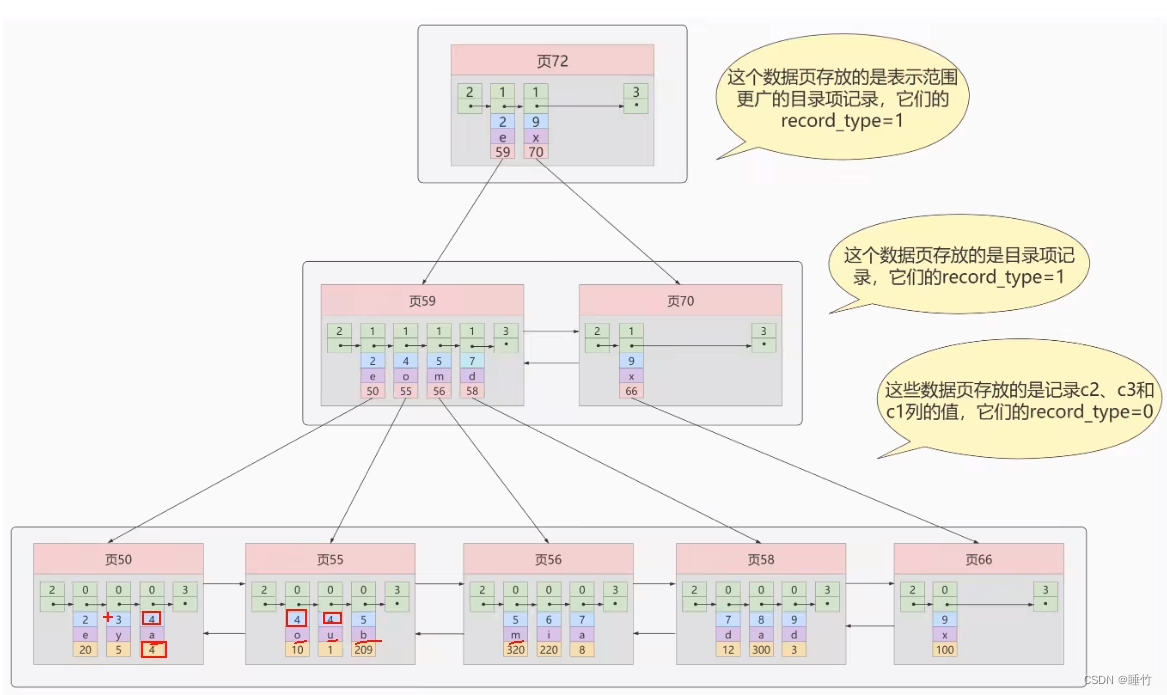
Sabemos que el contenido del registro de entrada de directorio en el nodo interno del índice de árbol B+ es la combinación de elemento de índice + número de página, pero esta combinación no es rigurosa para el índice secundario.
Supongamos que los datos de la tabla son los siguientes:
 Si el contenido del registro de entrada de directorio en el índice secundario es solo la combinación de columna de índice + número de página, entonces el árbol B+ después de indexar c2 debería ser:
Si el contenido del registro de entrada de directorio en el índice secundario es solo la combinación de columna de índice + número de página, entonces el árbol B+ después de indexar c2 debería ser:


5.3 Una página almacena al menos 2 registros
Bifurcación de árbol, la página aquí se refiere a un nodo que no es hoja, si no hay al menos 2 registros, entonces no es un árbol, sin sentido