Directorio de artículos
Evolución de los métodos de implementación de aplicaciones.
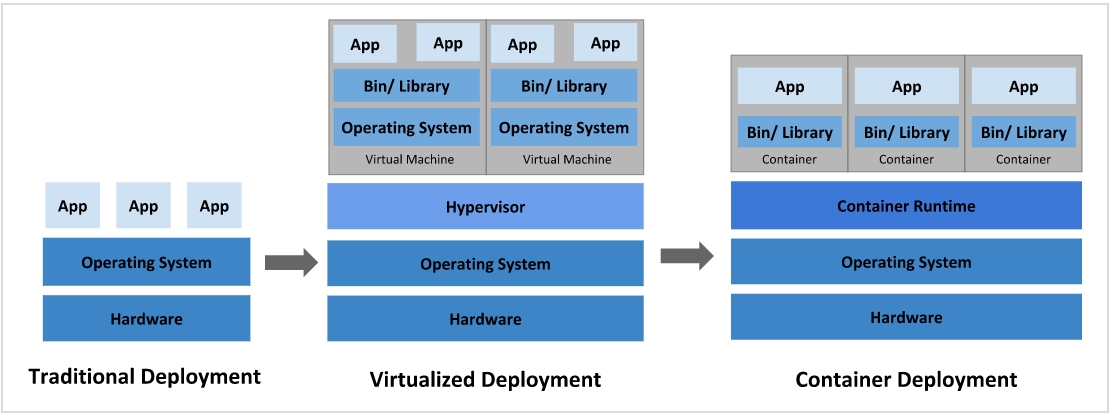
En términos de la forma de implementar aplicaciones, ha pasado principalmente por tres eras: implementación tradicional -> implementación de virtualización -> implementación de contenedores
-
Implementación tradicional: en los primeros días de Internet, las aplicaciones se implementaban directamente en máquinas físicas.
Ventajas: Simple, no se requiere otra tecnología
Desventajas: los límites de uso de recursos no se pueden definir para las aplicaciones, es difícil asignar recursos informáticos de manera razonable y es fácil influir entre programas.
-
Implementación de virtualización: se pueden ejecutar varias máquinas virtuales en una máquina física y cada máquina virtual es un entorno independiente.
Ventajas: los entornos del programa no se afectan entre sí, lo que proporciona un cierto grado de seguridad.
Desventajas: agregar un sistema operativo y desperdiciar algunos recursos
-
Implementación en contenedores: similar a la virtualización, pero con un sistema operativo compartido
ventaja:
Puede garantizar que cada contenedor tenga su propio sistema de archivos, CPU, memoria, espacio de proceso, etc.
Los recursos necesarios para ejecutar la aplicación están empaquetados en contenedores y desacoplados de la infraestructura subyacente.
Las aplicaciones en contenedores se pueden implementar entre proveedores de servicios en la nube y distribuciones de sistemas operativos Linux.
Problemas de orquestación de contenedores
Si un contenedor falla y se detiene, ¿cómo puedo iniciar otro contenedor inmediatamente para reemplazar el contenedor detenido?
Cuando aumenta el número de visitas simultáneas, ¿cómo ampliar horizontalmente el número de contenedores?
- Swarm: la herramienta de orquestación de contenedores propia de Docker, adecuada para proyectos pequeños y medianos
- Mesos: herramienta de Apache para la gestión y control unificado de recursos. Debe usarse junto con Marathon. Es anterior a Docker y admite el control de más de 50.000 nodos.
- Kubernetes: la herramienta de orquestación de contenedores de código abierto de Google
Introducción a los k8

Kubernetes es una nueva solución líder para arquitectura distribuida basada en tecnología de contenedores. Es el arma secreta de Google que se ha mantenido estrictamente confidencial durante más de diez años: una versión de código abierto del sistema Borg. La primera versión se lanzó en septiembre de 2014 y en 2015 La primera versión oficial se lanzó en julio.
La esencia de Kubernetes es un conjunto de clústeres de servidores, que pueden ejecutar programas específicos en cada nodo del clúster para administrar los contenedores en los nodos. El propósito es realizar la automatización de la gestión de recursos y proporciona principalmente las siguientes funciones principales:
- Autorreparación : una vez que un contenedor falla, se puede iniciar rápidamente un nuevo contenedor en aproximadamente 1 segundo
- Escalado automático : la cantidad de contenedores en ejecución en el clúster se puede ajustar automáticamente según sea necesario.
- Descubrimiento de servicios : un servicio puede encontrar los servicios de los que depende mediante el descubrimiento automático.
- Equilibrio de carga : si un servicio inicia varios contenedores, el equilibrio de carga de las solicitudes se puede realizar automáticamente
- Reversión de la versión : si encuentra un problema con la versión recién lanzada del programa, puede volver inmediatamente a la versión original.
- Orquestación del almacenamiento : los volúmenes de almacenamiento se pueden crear automáticamente según las necesidades del propio contenedor.
componentes k8s
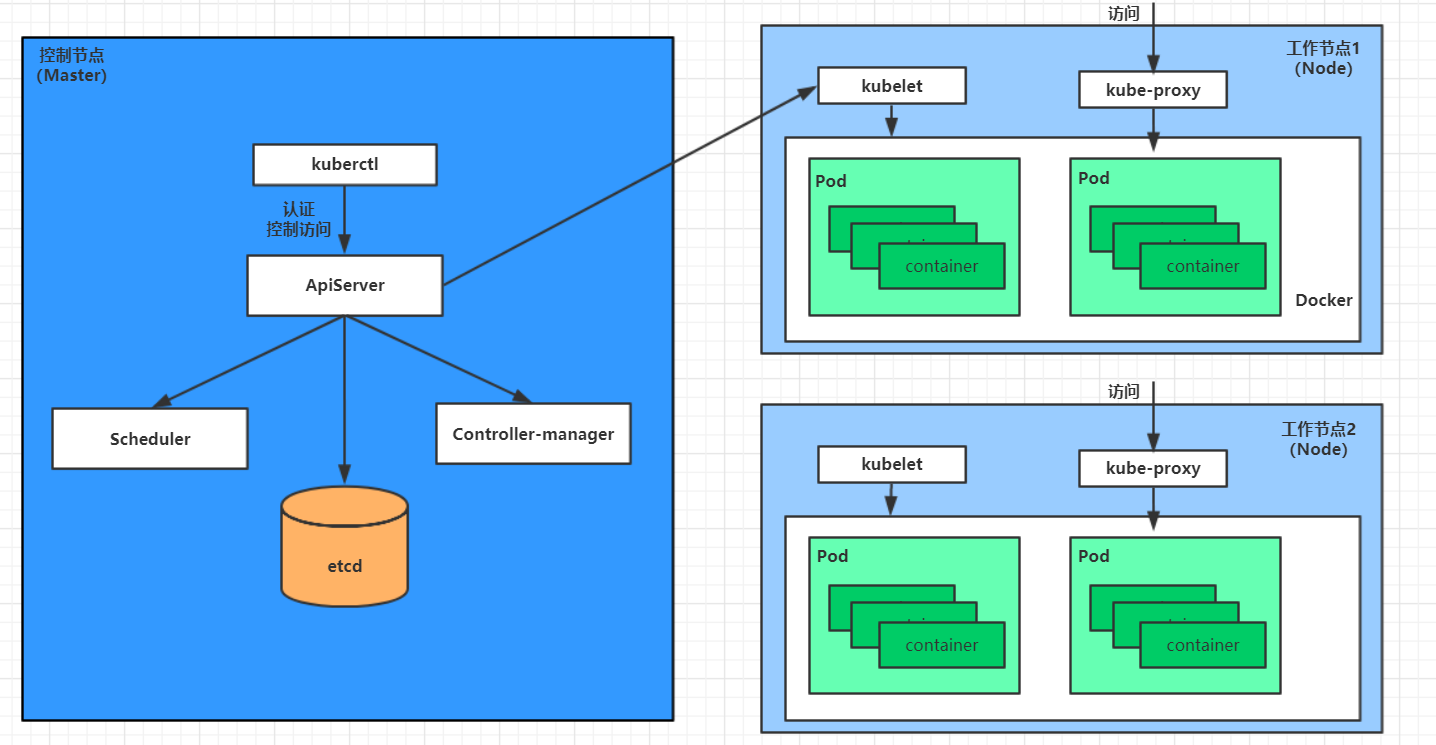
nodo maestro
El plano de control del clúster es responsable de la toma de decisiones (gestión) del clúster.
- ApiServer : la única entrada para operaciones de recursos, recibe comandos ingresados por los usuarios y proporciona mecanismos como autenticación, autorización, registro de API y descubrimiento.
- Programador : Responsable de la programación de recursos del clúster y la programación de Pods a los nodos correspondientes de acuerdo con la política de programación predeterminada.
- ControllerManager : Responsable de mantener el estado del clúster, como arreglos de implementación de programas, detección de fallas, expansión automática, actualizaciones continuas, etc.
- Etcd : Responsable de almacenar información sobre varios objetos de recursos en el clúster.
nodonodo
El plano de datos del clúster es responsable de proporcionar el entorno operativo (trabajo) para el contenedor.
- Kubelet : Responsable de mantener el ciclo de vida del contenedor, es decir, crear, actualizar y destruir el contenedor mediante el control de Docker.
- KubeProxy : responsable de proporcionar descubrimiento de servicios y equilibrio de carga dentro del clúster.
- Docker : Responsable de diversas operaciones de contenedores en nodos.
complementos
- kube-dns: Responsable de proporcionar servicios DNS para todo el clúster
- Controlador de ingreso: proporciona entrada a la red externa para servicios
- Prometheus: proporciona monitoreo de recursos
- Panel de control: proporciona GUI
- Federación: proporciona clústeres en zonas de disponibilidad
- Fluentd-elasticsearch: proporciona recopilación, almacenamiento y consulta de registros de clúster
flujo de llamadas entre componentes
Tome la implementación de un nginx como ejemplo para ilustrar
-
En primer lugar, deje claro: una vez que se inicia k8s, tanto el maestro como el nodo almacenarán sus propios datos en la base de datos etcd.
-
Primero se enviará una solicitud de instalación para un servicio nginx al componente apiserver del nodo maestro.
-
El componente apiserver llama al componente del programador para determinar en qué nodo se instalará el servicio.
En este momento, leerá la información del nodo de etcd, luego seleccionará de acuerdo con un determinado algoritmo y notificará al servidor api sobre el resultado)
-
apiserver llama al controlador-administrador para programar nodos de nodo para instalar servicios nginx
-
Después de que kubelet reciba la instrucción, notificará a Docker y luego Docker iniciará el pod nginx.
pod: la unidad operativa más pequeña de k8s, el contenedor debe ejecutarse en el pod
-
En este punto, un servicio nginx se ha ejecutado correctamente.
Diagrama de arquitectura
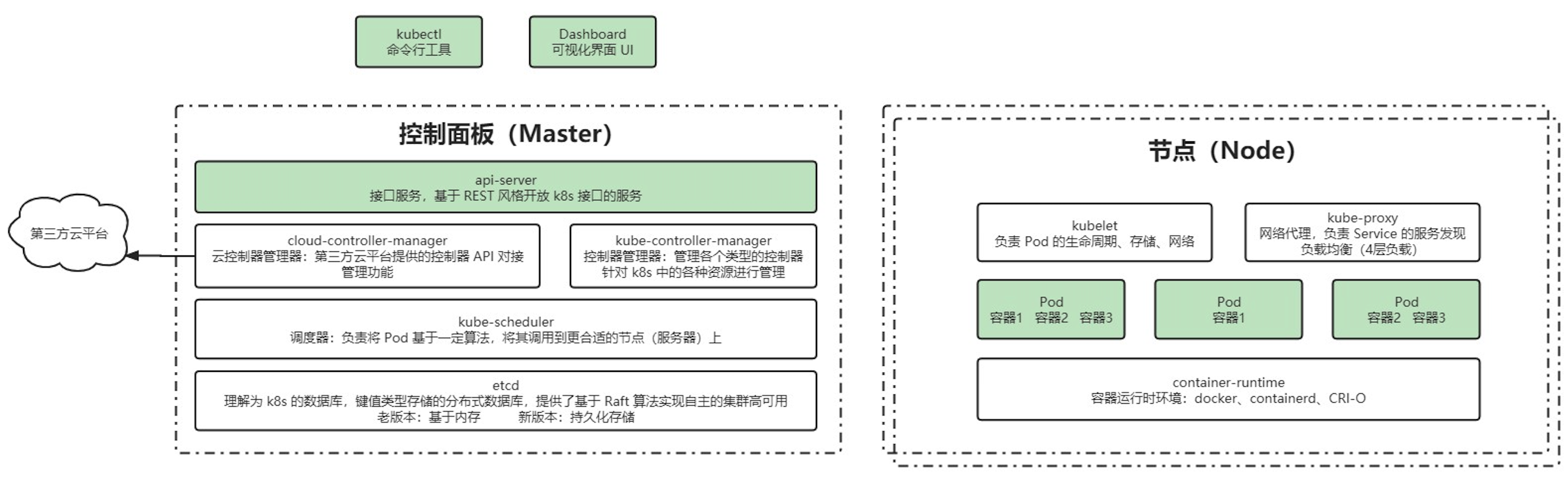
Idea principal
Clasificación de servicios (sin estado y con estado)
-
Sin estado -> no depende del entorno del servidor local
-
Servicios representativos: nginx, Apache
-
Ventajas: transparente para el cliente, sin dependencias y puede lograr expansión y migración de manera eficiente
-
Desventajas: no puede almacenar datos, requiere soporte de servicio de datos adicional

-
-
Con estado -> depende del entorno del servidor local y requiere migración de datos
- Servicios representativos: MySQL, Redis
- Ventajas: los datos se pueden almacenar de forma independiente para lograr la gestión de datos.
- Desventajas: en un entorno de clúster, es complicado implementar maestro-esclavo, sincronización de datos, copia de seguridad y expansión horizontal.

Terminología
-
Recursos y objetos : los recursos se configuran a través de listas de recursos; los recursos son aproximadamente iguales a las clases.
-
Especificación y estado del objeto : El propio k8s mantiene el atributo de estado, k8s administrará el objeto correspondiente a través de una serie de controladores para que el estado real del objeto coincida con el estado esperado (especificación) tanto como sea posible.
-
Clasificación de recursos : recursos a nivel de clúster -> recursos a nivel de espacio de nombres -> recursos a nivel de metadatos

-
Tipos de metadatos: escalador automático de pod horizontal (HPA), PodTemplate, LimitRange
Escalador automático de pods horizontal (HPA): Expansión automática de pods: los pods se pueden expandir/reducir automáticamente según el uso de la CPU o métricas personalizadas.
Pod Template es la definición de Pod, pero está incluida en otros objetos de Kubernetes (como Deployment, StatefulSet, DaemonSet y otros controladores). El controlador crea Pods a través de la información de la Plantilla de Pod.
LimitRange: puede establecer un límite unificado global en la configuración de Solicitud y Límites en el clúster, lo que equivale a establecer límites de uso de recursos para Pods dentro de un determinado rango (un determinado espacio de nombres) en lotes.
-
Nivel de clúster: espacio de nombres de espacio de nombres, recursos de nodo de nodo, grupo de autoridad de declaración de ClusterRoles, enlace de ClusterRoleBinding al nivel de clúster
-
Espacios de nombres:
-
Módulo de carga de trabajo
Pod (grupo de contenedores) es la unidad implementable más pequeña en Kubernetes. Un Pod (grupo de contenedores) contiene un contenedor de aplicaciones (o varios contenedores en algunos casos), recursos de almacenamiento, una dirección IP de red única y algunas opciones que determinan cómo debe ejecutarse el contenedor. Un grupo de contenedores Pod representa una instancia de ejecución de aplicación independiente en Kubernetes, que puede constar de un solo contenedor o de varios contenedores estrechamente acoplados.
Solo se ejecuta un contenedor en un Pod. "un contenedor por pod" es el uso más común en Kubernetes. En este punto, puede pensar en el grupo de contenedores Pod como el contenedor del contenedor, y Kubernetes administra el contenedor a través del Pod en lugar de administrarlo directamente.


-
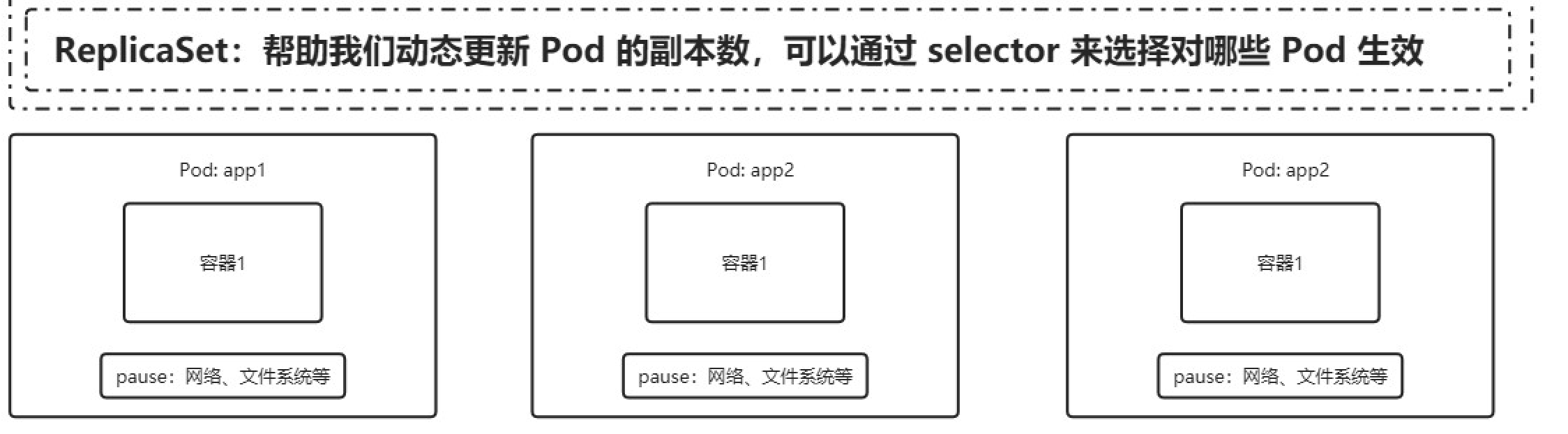
réplicas
Primero introduzca el concepto de "copia": un Pod se puede copiar en varias copias y cada copia se puede llamar "copia". Estas "copias" excepto cierta información descriptiva (nombre del pod, uid, etc.) excepto la misma El resto de la información es la misma, como los contenedores dentro del Pod, la cantidad de contenedores, las aplicaciones que se ejecutan en los contenedores, etc., y estas copias proporcionan las mismas funciones.
El "controlador" de un Pod normalmente contiene una propiedad llamada "réplicas". El atributo "réplicas" especifica el número de réplicas de un Pod específico. Cuando el número de Pods en el clúster actual no coincide con el valor especificado por este atributo, k8s adoptará algunas estrategias para que el estado actual cumpla con los requisitos de configuración.
-
controlador
Cuando se crea un Pod, se programará para que se ejecute en un nodo del clúster y permanecerá ejecutándose en ese nodo hasta que finalice el proceso, se elimine el objeto Pod, se desaloje el Pod debido a recursos insuficientes del nodo o el nodo falla. . Los pods no se curan solos. Cuando falla un nodo o la operación de programación de pods falla, los pods deben eliminarse. De esta manera, simplemente usar Pod para implementar aplicaciones es inestable e inseguro.
Kubernetes utiliza un "controlador" de objetos de recursos más avanzado para administrar Pods. El controlador puede crear y administrar varios Pods por usted, administrar réplicas y en línea, y proporcionar capacidades de autorreparación dentro del clúster. Por ejemplo, si un nodo falla, el controlador puede programar el mismo sustituto en un nodo diferente para reemplazar automáticamente el Pod.
-
Se aplica a servicios sin estado.
-
Controlador de replicación (RC)
RC puede garantizar la cantidad de copias de un Pod ejecutándose en cualquier momento y garantizar que el Pod esté siempre disponible. Si el número real de Pods es mayor que el número especificado, los que sobran se cancelarán. Si el número real es menor que el número especificado, se iniciarán algunos Pods nuevos. Cuando un Pod falla, se elimina o se cuelga, RC creará automáticamente un nuevo Pod para garantizar una cantidad de copias, por lo que incluso si solo hay un Pod, debemos usar RC para administrar nuestros Pods. Se puede decir que a través de ReplicationController, Kubernetes logra una alta disponibilidad de Pods.
Ha sido reemplazado por RS~~

-
ReplicaSet (RS): solo admite expansión y reducción
Etiqueta (etiqueta) es un par clave-valor adjunto a objetos de Kubernetes (como Pods) y se utiliza para distinguir objetos (como Pod, Servicio). La etiqueta está destinada a especificar propiedades de identificación de objetos que son significativos y relevantes para el usuario, pero que no tienen un significado semántico directo para el sistema central. Las etiquetas se pueden utilizar para organizar y seleccionar subconjuntos de objetos. Las etiquetas se pueden adjuntar a los objetos en el momento de la creación y se pueden agregar y modificar en cualquier momento. Al igual que el espacio de nombres, puedes usar la etiqueta para obtener ciertos tipos de objetos, pero la etiqueta se puede usar junto con el selector para limitar las condiciones con expresiones para lograr una búsqueda de recursos más precisa y flexible.
La etiqueta y el selector se pueden utilizar para lograr la "asociación" de objetos. El "Controlador de Pod" está asociado con el Pod; el "Controlador de Pod" depende del Pod. Puede establecer una etiqueta para el Pod y luego configurar el selector de "Controlador" correspondiente. que realiza la asociación de objetos.
-
Implementación : encapsula aún más RS
El controlador de implementación lo ayudará a cambiar el estado real del conjunto de réplicas y pods a su estado objetivo. Puede definir una implementación completamente nueva o crear una nueva para reemplazar la implementación anterior.
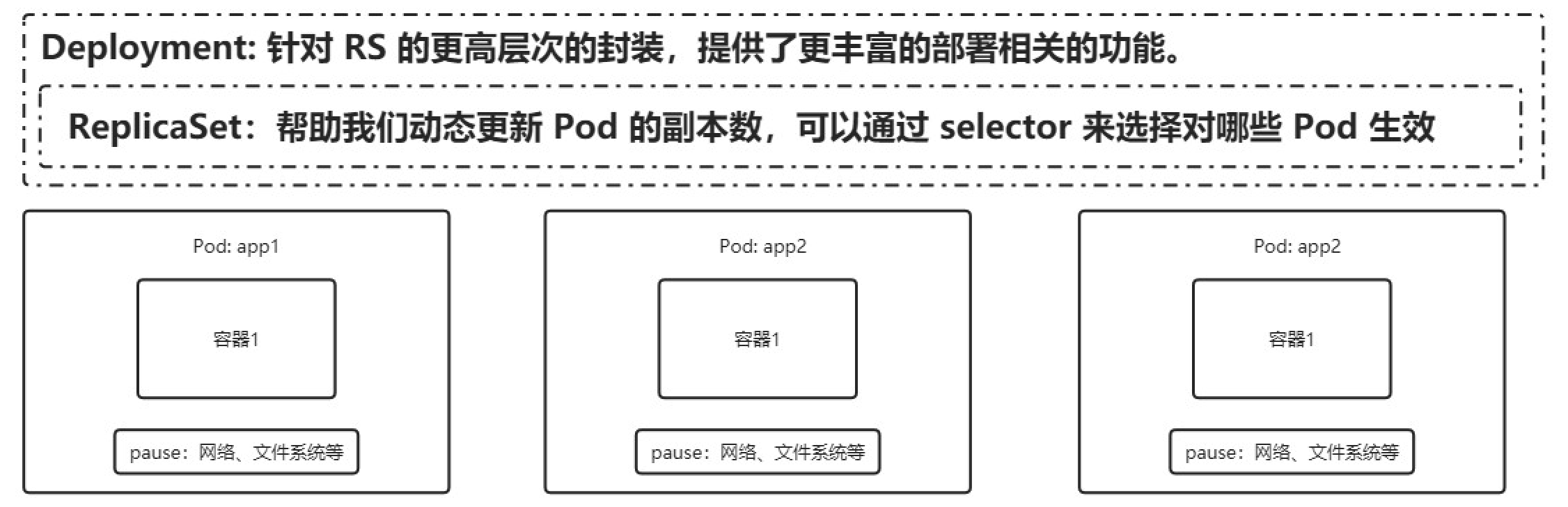
-
Crear conjunto/pod de réplicas
-
Actualización/reversión progresiva -> El RS1 actualizado se conservará para la reversión
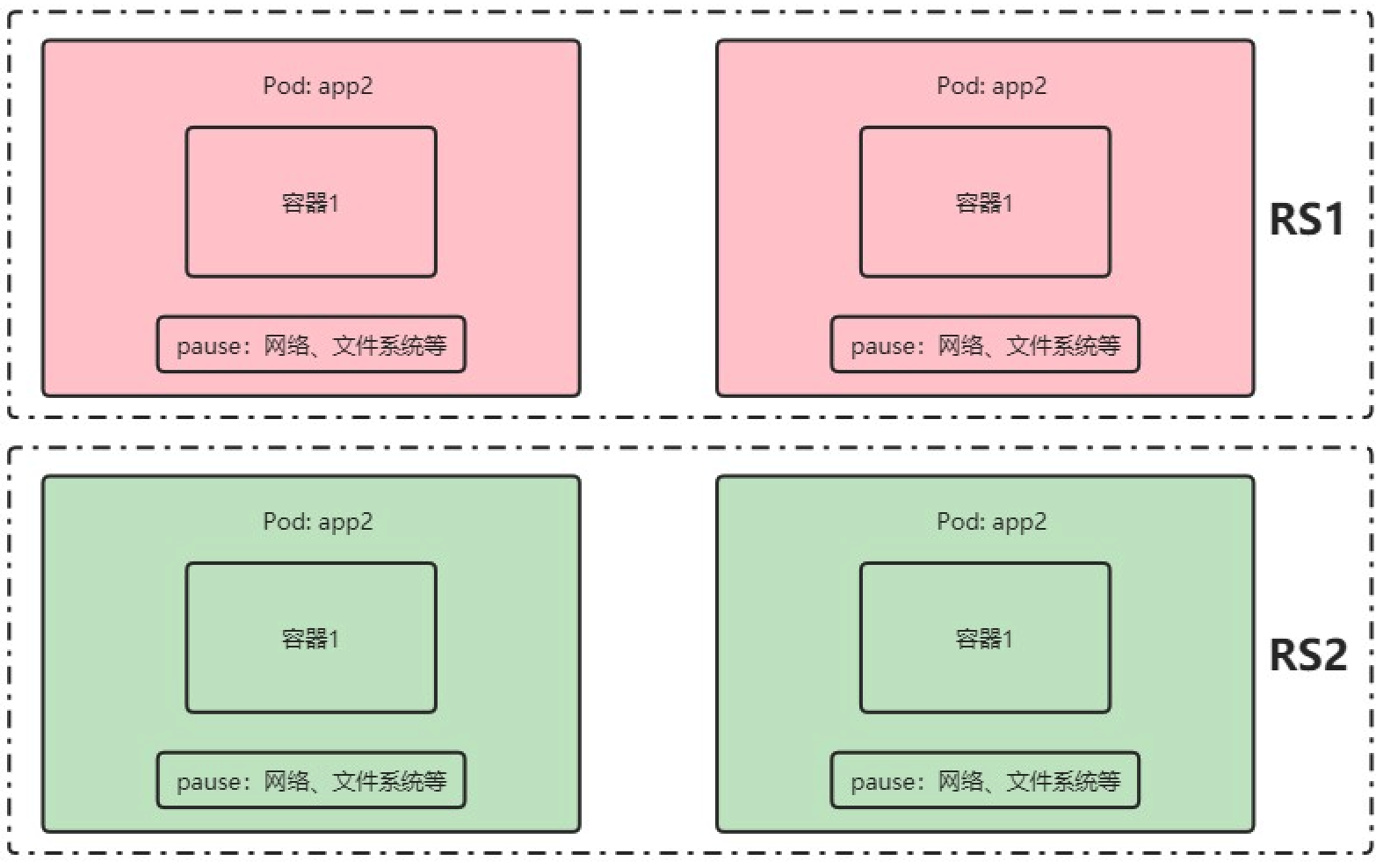
-
Suave expansión y contracción.
-
Pausar y reanudar la implementación
La reversión de la actualización es automática -> se puede pausar y reanudar
-
-
-
StatefulSet : adecuado para servicios con estado
El formato DNS de cada Pod en StatefulSet es statefulSetName-{0…N-1}.serviceName.namespace.svc.cluster.local
- serviceName es el nombre del servicio sin cabeza
- 0…N-1 es el número de secuencia del Pod, comenzando de 0 a N-1
- statefulSetName es el nombre de StatefulSet
- El espacio de nombres es el espacio de nombres donde se encuentra el servicio. Headless Service y StatefulSet deben estar en el mismo espacio de nombres.
- .cluster.local 为 Dominio de clúster

-
Características
- Almacenamiento persistente estable
- señal de red estable
- Despliegue ordenado y expansión ordenada
- Reducción ordenada, eliminación ordenada
-
composición
-
Servicio sin cabeza
Se utiliza para definir indicadores de red (dominio DNS)
Servidor de nombres de dominio: servicio de nombres de dominio, relación de mapeo vinculante entre el nombre de dominio y la IP
Nombre del servicio => Ruta de acceso (nombre de dominio) => ip
-
plantilla de reclamación de volumen
Se utiliza para crear volúmenes persistentes.
-
-
Proceso del demonio DaemonSet
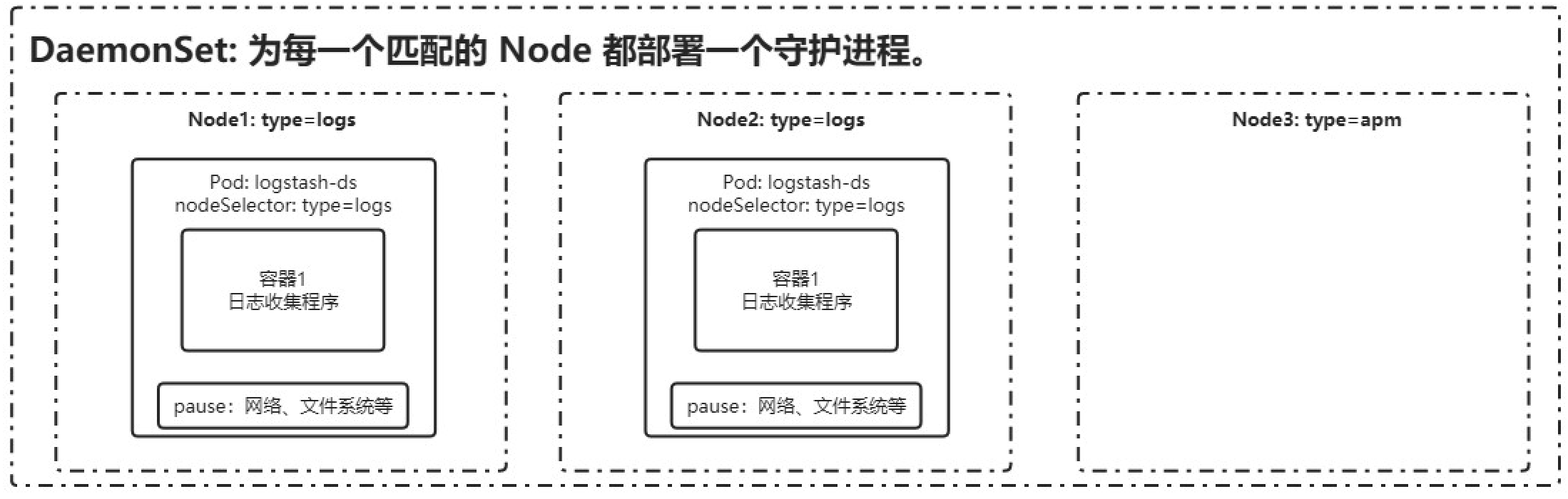
DaemonSet garantiza que se ejecute una copia del contenedor en cada nodo y, a menudo, se utiliza para implementar algunas aplicaciones de registro, monitoreo u otras aplicaciones de administración del sistema. Las aplicaciones típicas incluyen:
- Recopilación de registros, como fluentd, logstash, etc.
- Monitoreo del sistema, como Prometheus Node Exporter, Collectd, New Relic Agent, Ganglia Gmond, etc.
- Programas del sistema, como kube-proxy, kube-dns, glusterd, ceph, etc.
-
Tarea/tarea programada
-
TRABAJO
Una tarea única, el Pod se destruye una vez completada la operación y el nuevo contenedor no se reiniciará.
-
CronJob
CronJob agrega una función de sincronización basada en Job.
-
-
-
-
descubrimiento de servicios
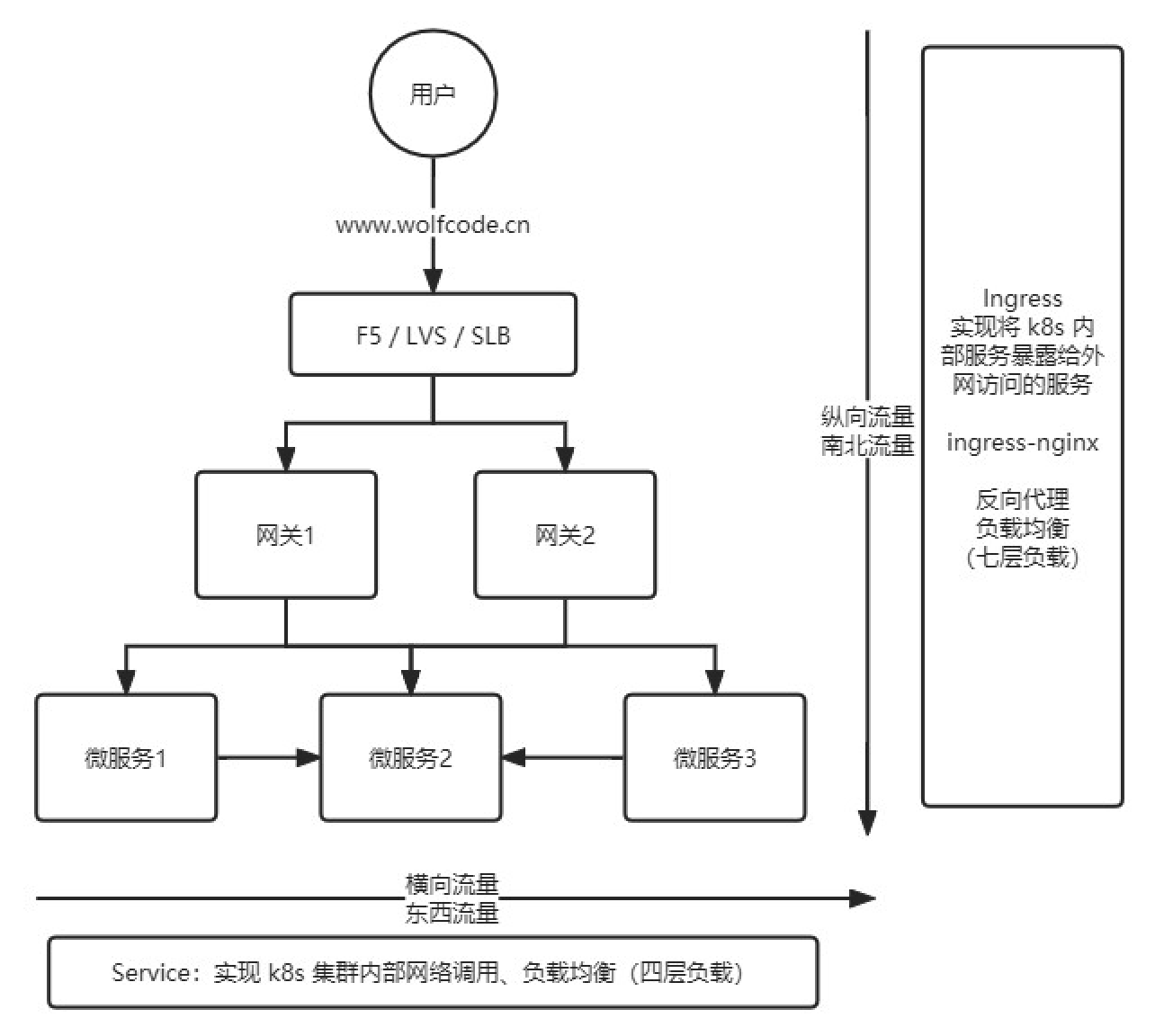
-
Servicio (comunicación interna del cluster, tráfico lateral (tráfico este-oeste))
"Servicio" se abrevia como "svc". El pod no se puede proporcionar directamente para el acceso a la red externa, pero debe utilizar el servicio. El servicio consiste en exponer Pod para que proporcione servicios. El servicio es el verdadero "servicio" y su nombre chino es "servicio".
Se puede decir que el Servicio es una abstracción de un servicio de aplicación, que define una colección lógica de Pods y una estrategia para acceder a esta colección de Pods. La colección de pods de proxy de servicio aparece como un portal de acceso al mundo exterior. Las solicitudes para acceder a este portal se reenviarán a los contenedores en el pod de backend a través del equilibrio de carga.
-
Ingreso (tráfico vertical (tráfico norte-sur))
Ingress puede brindar la posibilidad de acceder al Servicio desde la red externa. Una determinada dirección de solicitud se puede asignar y enrutar a un servicio específico.
Ingress debe usarse junto con el controlador de ingreso para funcionar. Ingress es solo una colección de reglas de enrutamiento. Es el controlador de ingreso el que realmente implementa la función de enrutamiento. El controlador de ingreso, al igual que otros componentes de k8s, también se ejecuta en el Pod.

-
-
almacenamiento
-
Volumen
Los volúmenes de datos comparten datos utilizados por contenedores en Pods. Se utiliza para almacenar datos persistentes, como datos de bases de datos.
-
CSI
La interfaz de almacenamiento de contenedores es una especificación de interfaz estándar de la industria desarrollada conjuntamente por miembros de la comunidad de Kubernetes, Mesos, Docker y otras comunidades, con el objetivo de exponer cualquier sistema de almacenamiento a aplicaciones en contenedores.
La especificación CSI define un conjunto mínimo de operaciones y recomendaciones de implementación para que los proveedores de almacenamiento implementen un complemento de volumen compatible con CSI. El objetivo principal de la especificación CSI es declarar las interfaces que debe implementar el complemento de volumen.
-
-
Configuración de tipo especial
-
Mapa de configuración
Se utiliza para almacenar configuraciones y es similar a Secret, excepto que ConfigMap almacena datos de texto sin formato, mientras que Secret almacena texto cifrado.
-
Secreto
Secret resuelve el problema de configuración de datos confidenciales como contraseñas, tokens y claves sin exponer estos datos confidenciales a imágenes o especificaciones de Pod. El secreto se puede utilizar como variable de volumen o de entorno.
Hay tres tipos de Secretos:
- Cuenta de servicio: se utiliza para acceder a la API de Kubernetes, creada automáticamente por Kubernetes y montada automáticamente en el directorio /run/secrets/kubernetes.io/serviceaccount del Pod;
- Opaco: secreto en formato de codificación base64, utilizado para almacenar contraseñas, claves, etc.;
- kubernetes.io/dockerconfigjson: se utiliza para almacenar información de autenticación para el registro privado de Docker.
-
DownwardAPI (compartir información del pod dentro del contenedor)
La diferencia entre downAPI y otros modos es que no se utiliza para almacenar datos del contenedor o intercambiar datos entre el contenedor y el host, sino que permite que el contenedor en el pod obtenga directamente información sobre el objeto del pod.
downAPI proporciona dos formas de inyectar información del pod en el contenedor:
Variables de entorno: utilizadas para una sola variable, que puede inyectar directamente información del pod y del contenedor en el contenedor.
Montaje de volumen: genere información del pod en un archivo y móntelo directamente en el contenedor.
-
-
Permisos
-
Role
El rol es un conjunto de permisos. Por ejemplo, el rol puede incluir una lista de permisos de Pod y una lista de permisos de implementación. El rol se utiliza para autenticar recursos en un espacio de nombres.
-
Vinculación de roles
RoleBinding: vincula el sujeto al rol. RoleBinding hace que las reglas sean efectivas dentro del espacio de nombres.
-
-
-