Tabla de contenido
1. Conócete a ti mismo y al enemigo
2.1 Comparación de la longitud de almacenamiento y la longitud de la cuerda
3.1 método de búsqueda de tabla ascii
Prefacio:
Con la continua profundización de la construcción digital, las empresas prestan cada vez más atención a la gobernanza de datos empresariales y ayudan a la toma de decisiones a través del consumo de datos. Como proveedor de servicios integrales en la industria global de nuevas energías. Nuestra empresa también encuentra muchos negocios especiales. Por supuesto, todas las empresas se enfrentarán a la digitalización empresarial y siempre dejarán algún margen para abordar algún "negocio ingrato". Es decir, el volumen de negocio es muy pequeño y no merece la pena un control estandarizado. Por supuesto, estos negocios también estarán totalmente integrados online: aunque el gorrión es pequeño, tiene todos los órganos internos. Esto dio lugar al descubrimiento durante un análisis empresarial exhaustivo de algunos "datos anormales" muy molestos, como lotes que contienen caracteres chinos. Hoy me gustaría compartir con ustedes cómo lidiar con estos "lotes extranjeros" de chino + inglés. Resumir el procesamiento del idioma chino aplicable a cualquier empresa.

1. Conócete a ti mismo y al enemigo
¿Por qué existe el chino?
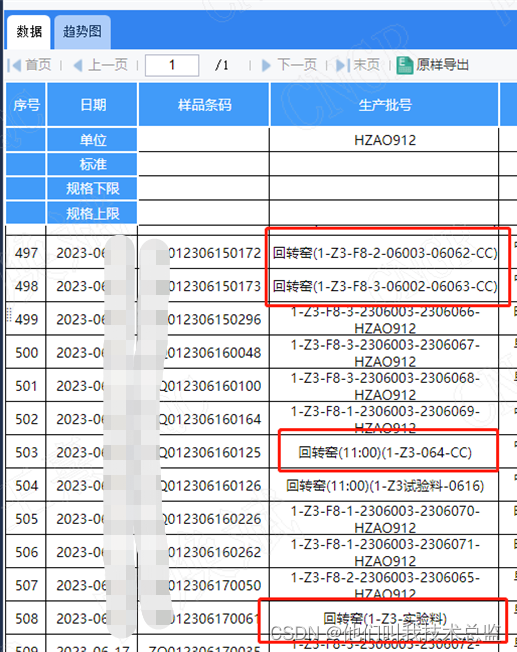
1.1 Escenario empresarial
Como se muestra en la figura anterior, el sistema no genera automáticamente los números de lote de algunos lotes comerciales personalizados, sino que se ingresan manualmente en el sistema. Aunque existen ciertas restricciones del sistema, para facilitar la visualización de los significados correspondientes, los caracteres chinos se añaden inevitablemente. He revisado muchos SQ sobre el filtrado de chino en Internet. Para ser honesto, casi no tienen sentido y básicamente no pueden satisfacer las necesidades. Por lo tanto, quiero organizarlos sistemáticamente para evitar hacer perder el tiempo a todos. También puedes consultarlos en cualquier momento en el que los necesitas~
1.2 Casos de error
Ejemplo de error
select *
from table_name
where regexp_like(text_field, '[\u4E00-\u9FA5]');mala interpretación
El código anterior utiliza la función regexp_like para implementar la función de filtrar caracteres chinos especificando el rango de valores Unicode de caracteres. El valor Unicode se establece de acuerdo con el rango de caracteres chinos. \u4E00 – \u9FA5 es el rango de caracteres más utilizado en el Tabla de codificación Unicode de caracteres chinos, que en circunstancias normales puede satisfacer las necesidades.
Ejemplo de efecto de error
Como se muestra en la figura siguiente, el lote final es el mismo que sin filtrar.

Análisis de causa
Por el motivo específico, puede consultar el artículo que escribí antes: En Oracle, no podemos filtrar chino según el rango Unicode.

2. Organizar ideas
2.1 Comparación de la longitud de almacenamiento y la longitud de la cuerda
Cuando se almacenan caracteres chinos en la base de datos de Oracle, un carácter chino ocupará más de dos caracteres. Depende de la codificación del juego de caracteres de la base de datos. Generalmente, el NLS_CHARACTERSET de la base de datos es AL32UTF8 o UTF8 , es decir, un carácter chino ocupa de tres a cuatro bytes . Si NLS_CHARACTERSET es ZHS16GBK , un carácter chino ocupa dos bytes .

Como se muestra en la figura anterior, un carácter chino ocupa 2 bytes.
¡Entonces podemos usar el primer método, que es a través de lengthb('Chinese')! =length('Chinese') para encontrar el número de lote que contiene chino. El caso de ejemplo correcto se muestra a continuación.
Código:
--查询带中文的数据
select 生产批次号 from BI.QZ_zB_GCPJCSJ zb
where 1=1
and flag='已清洗'
and LENGTH(生产批次号)!= LENGTHB(生产批次号);--查询中文批次
--查询非中文的数据
select 生产批次号 from BI.QZ_zB_GCPJCSJ zb
where 1=1
and flag='已清洗'
and LENGTH(生产批次号)= LENGTHB(生产批次号);--查询非中文批次Efecto:
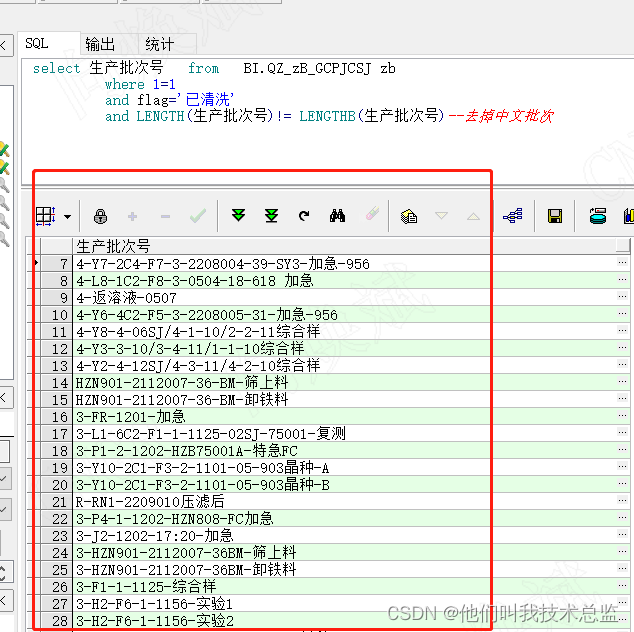
Interpretación:
Como se muestra en la imagen de arriba, los lotes que contienen caracteres chinos se pueden encontrar a través de LENGTH (número de lote de producción) = LENGTHB (número de lote de producción) . Por lo tanto, si solo queremos ver lotes no chinos , podemos lograr el objetivo usando LENGTH (número de lote de producción) = LENGTHB (número de lote de producción) ¿No es muy simple?
3. ¿Hay alguna otra idea?
Arriba utilizamos las reglas de almacenamiento chinas para filtrar datos chinos. De hecho, también podemos usar las reglas de las tablas ASCII para consultar datos chinos.
3.1 método de búsqueda de tabla ascii
Las reglas por lotes generalmente incluyen números, letras, símbolos especiales y caracteres chinos. Si elimina los caracteres que no están en la tabla ascii, serán chinos. Para obtener más información, consulte la tabla ascii correspondiente.
Específicamente, reemplazamos el chino con una cadena compleja que no aparecerá, como "Me llaman director técnico". Si determinamos si la cadena reemplazada contiene los caracteres "me llaman director técnico", podemos hacerlo. Vea el caso a continuación para más detalles.
3.2 Casos formales
Código:
select 生产批次号
from BI.QZ_ZB_GCPJCSJ
where instr(regexp_replace(生产批次号,
'[' || chr(128) || '-' || chr(255) || ']',
'他们叫我技术总监'),
'他们叫我技术总监',
1,
1) > 0
--将中文替换为一个不可能出现的字符,然后判断替换的字符串是否包含对应的字符Efecto:
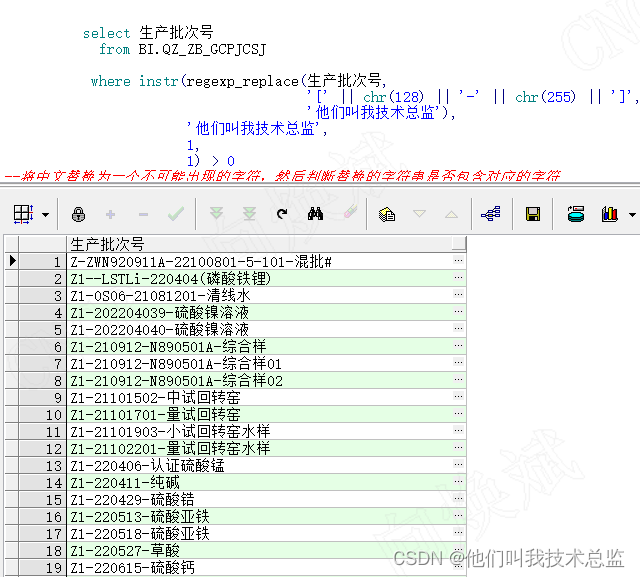
Interpretación:
Reemplazamos el chino con una cadena compleja que no aparecerá y luego determinamos si la cadena reemplazada contiene los caracteres reemplazados. La cadena reemplazada correspondiente puede ser china .
4. Resumen
En este artículo, se incluyen todas las soluciones de procesamiento de chino utilizadas comúnmente, como buscar datos que contengan chino, buscar datos que no sean chinos, reemplazar el chino con otros caracteres, etc. Por supuesto, a veces también necesitamos obtener números, fechas, etc. de un montón de cadenas que contienen caracteres chinos. Por ejemplo, "2,2 yuanes/jin", obtenga 2,2 como precio unitario. Por ejemplo, "2023-06-22 Estamos juntos" obtiene la fecha 2023-06-22 para su análisis. He escrito un artículo que explica los métodos de procesamiento correspondientes en el pasado. Espero que sea útil para todos. Ya no perderé el tiempo buscando tutoriales incorrectos en Internet ~