Como personal de I+D, además del desarrollo empresarial, la mejora de la eficiencia de la I+D es un tema eterno, y Nuwa llevó a cabo un análisis y una práctica exhaustivos sobre este tema.
Autor: Zhang Quanhong (iluminación tonta)
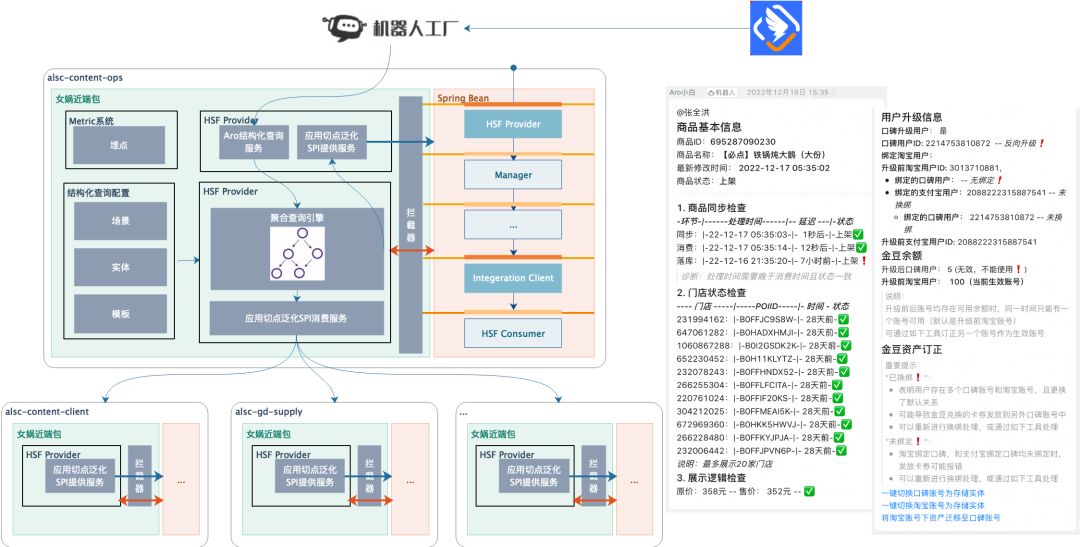
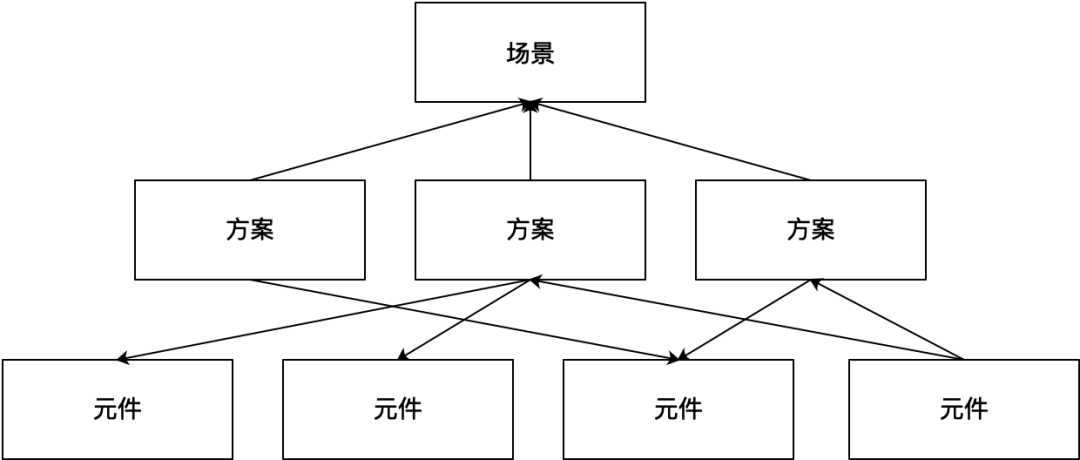
1. ¿Qué es Nuwa?
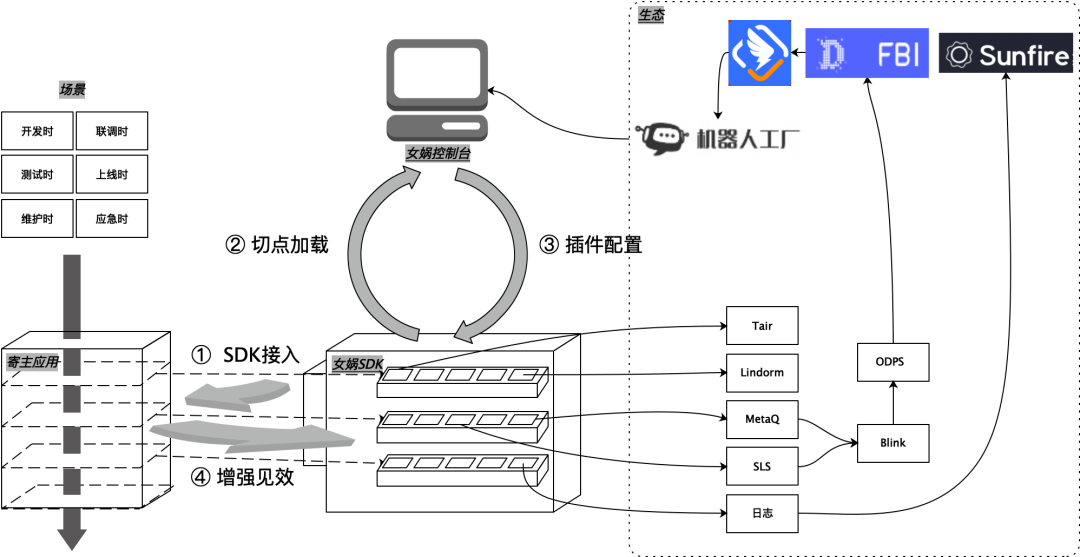
Nuwa es un compañero de clase de I + D empresarial (desarrollo, prueba, operación y mantenimiento). En cada etapa de la iteración del software (desarrollo, depuración conjunta, prueba, en línea, operación y mantenimiento), Nuwa interviene dinámicamente en el código (mejora, unboxing, derivación). a través de la consola Nuwa. ) es una plataforma integral que inyecta capacidades técnicas adicionales (caché, resultado final, simulacro, escala de grises, etc.) en el programa cuando se ejecuta, con el objetivo de mejorar la eficiencia del trabajo relacionado con la investigación y el desarrollo.

Nuwa se compone de "un SDK, una consola, varios complementos y una ecología", que se pueden utilizar en varios escenarios para formar varios escenarios de aplicación para soluciones tecnológicas NoCode/LowCode.
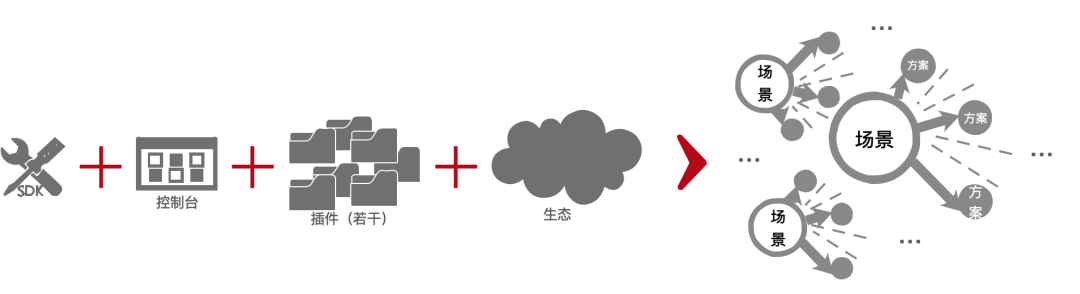
Diagrama esquemático del trabajo de Nuwa:
2. La historia del desarrollo de Wa
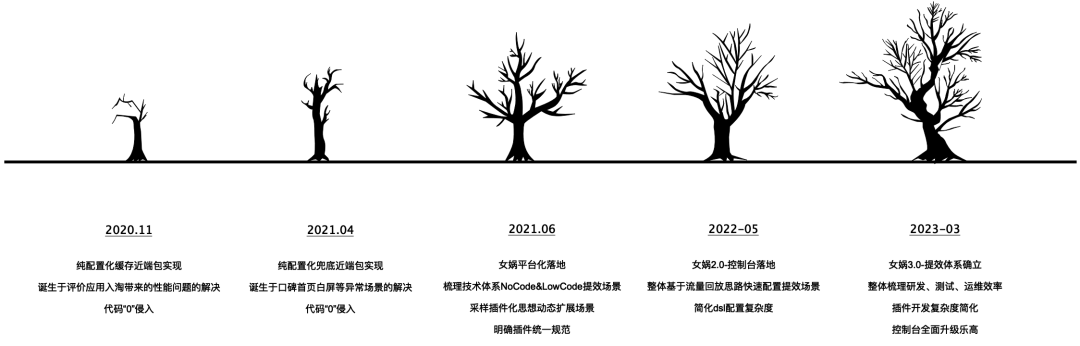
Nuwa 1.0
La implicación es "No reparamos el cielo, sólo reparamos la olla". El objetivo inicial es garantizar el rendimiento y la estabilidad en línea, así como las emergencias. Esperamos adoptar un modelo de procesamiento común para refinar lo no funcional puramente técnico. requisitos del negocio y forman complementos de mejora de tecnología intercambiables en caliente. El desarrollo empresarial se centra en la realización de los requisitos funcionales del negocio, mientras que los requisitos no funcionales se realizan mediante el ensamblaje y la configuración dinámica de la plataforma Nuwa. Nuwa está conectado al "código cero" para lograr la separación del negocio y la tecnología y mejorar la eficiencia de la investigación y el desarrollo. Los principales escenarios de mejora de la eficiencia son la depuración, el almacenamiento en caché y el control de flujo.
Nuwa 2.0
Conecte la configuración de Nuwa para reducir la complejidad del uso de Nuwa.
Nuwa 3.0
Con la actualización de Nuwa de 1.0, 2.0 y 3.0, la misión de Nuwa no es solo centrarse en las garantías de servicio en línea, sino también actualizarse integralmente a una caja de herramientas para que los técnicos ayuden en el trabajo integral en el proceso de investigación y desarrollo y logren un Espacio 360° Mejorar la eficiencia.
Los escenarios de mejora de la eficiencia incluyen, entre otros:
-
Mejora de la eficiencia del escenario de desarrollo: caché, cobertura, escala de grises, verificación, puntos enterrados, ABT, registro dinámico;
-
Mejora de la eficiencia del escenario de prueba: pruebas unilaterales, simuladas, de estrés y automatizadas;
-
Mejora de la eficiencia en escenarios de operación y mantenimiento: seguimiento de enlaces de tráfico, análisis estadístico de llamadas de enlaces, control de tráfico, grabación y reproducción de tráfico y servicios de orquestación de robots.
3. Los antecedentes del nacimiento de Nuwa
3.1 Primera comprensión de varios aspectos de la mejora de la eficiencia
No importa cómo mejore su capacidad y sus medios para resolver problemas, el objetivo principal final es mejorar la eficiencia y la calidad de las cosas. Aquí hay principalmente tres aspectos:
En términos de mejorar la eficiencia de la I+D : adoptar una arquitectura técnica, marcos, herramientas y plataformas razonables para simplificar, hacer que el proceso de I+D sea más fácil de usar y más inteligente. El trabajo que antes tomaba una semana ahora solo toma un día.
En términos de mejora de la eficiencia operativa: la adopción de arquitectura empresarial razonable, plataforma, sistematización, configuración, componenteización, procesamiento y plantillas puede respaldar de manera flexible nuevos negocios. Originalmente, los nuevos escenarios operativos solo podían desarrollarse, probarse y probarse en un caso por caso. Caso clínico: El proceso en línea se ha convertido en un proceso automatizado y sistemático de rápida configuración, implementación e inspección, permitiendo en cierta medida que las operaciones tengan más espacio y mejorando la eficiencia operativa general.
En términos de eficiencia monetaria : utilice modelos de algoritmos razonables para realizar entregas precisas a través de retratos masivos, sistemas de etiquetas y sistemas jerárquicos para mejorar la eficiencia del gasto, extender los ciclos de vida del usuario, obtener el máximo retorno de la inversión y perfeccionar el modelo único original. Entrega detallada para mejorar la eficiencia del dinero.
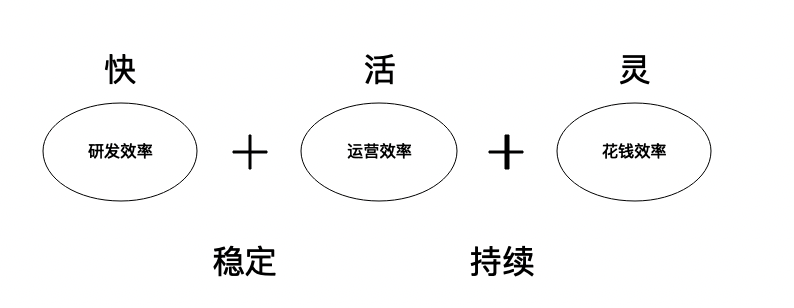
Independientemente del tipo de mejora de la eficiencia que se requiera, la "durabilidad" y la "estabilidad" son indispensables. Sobre esta base, cada aspecto de la mejora de la eficiencia tiene un enfoque: la investigación y el desarrollo deben ser "rápidos", las operaciones deben ser "flexibles" y el gasto debe ser "flexible".
Este artículo se centra en mejorar la eficiencia de la I + D. La eficiencia de la I + D incluye principalmente dos aspectos principales:
Uno es la calidad de ejecución del software , que también se puede decir que es la eficiencia de ejecución, como el tiempo de respuesta del programa, el rendimiento/concurrencia del procesamiento, la confiabilidad de la operación y la seguridad.
El otro es la eficiencia del mantenimiento del software: aquí el mantenimiento se refiere al mantenimiento de todo el ciclo de vida del software. La eficiencia del mantenimiento incluye la eficiencia del desarrollo, la eficiencia de las pruebas, la eficiencia del lanzamiento y la eficiencia de la operación y el mantenimiento; donde la eficiencia del desarrollo se mide en la legibilidad y facilidad del código. de uso, versatilidad Sobre la base de la flexibilidad, escalabilidad y capacidad de prueba, también se basa en la amabilidad e integridad de las herramientas y la ecología.
3.2 Matriz de demanda para la mejora de la eficiencia en I+D
Ahora entremos en las "cosas" específicas para mejorar la eficiencia. En el ciclo de vida del desarrollo de software, satisfacer las necesidades del negocio es un aspecto. Pero para garantizar la buena implementación de las necesidades del negocio, tendremos que cumplir con muchos requisitos no funcionales para garantizar la estabilidad de la operación del programa. Al mismo tiempo, ayudaremos con una gran cantidad de pruebas y aceptación para verificar si los requisitos se implementan correctamente. Además, también haremos una gran cantidad de requisitos derivados para verificar el análisis del efecto de la implementación de requisitos funcionales.
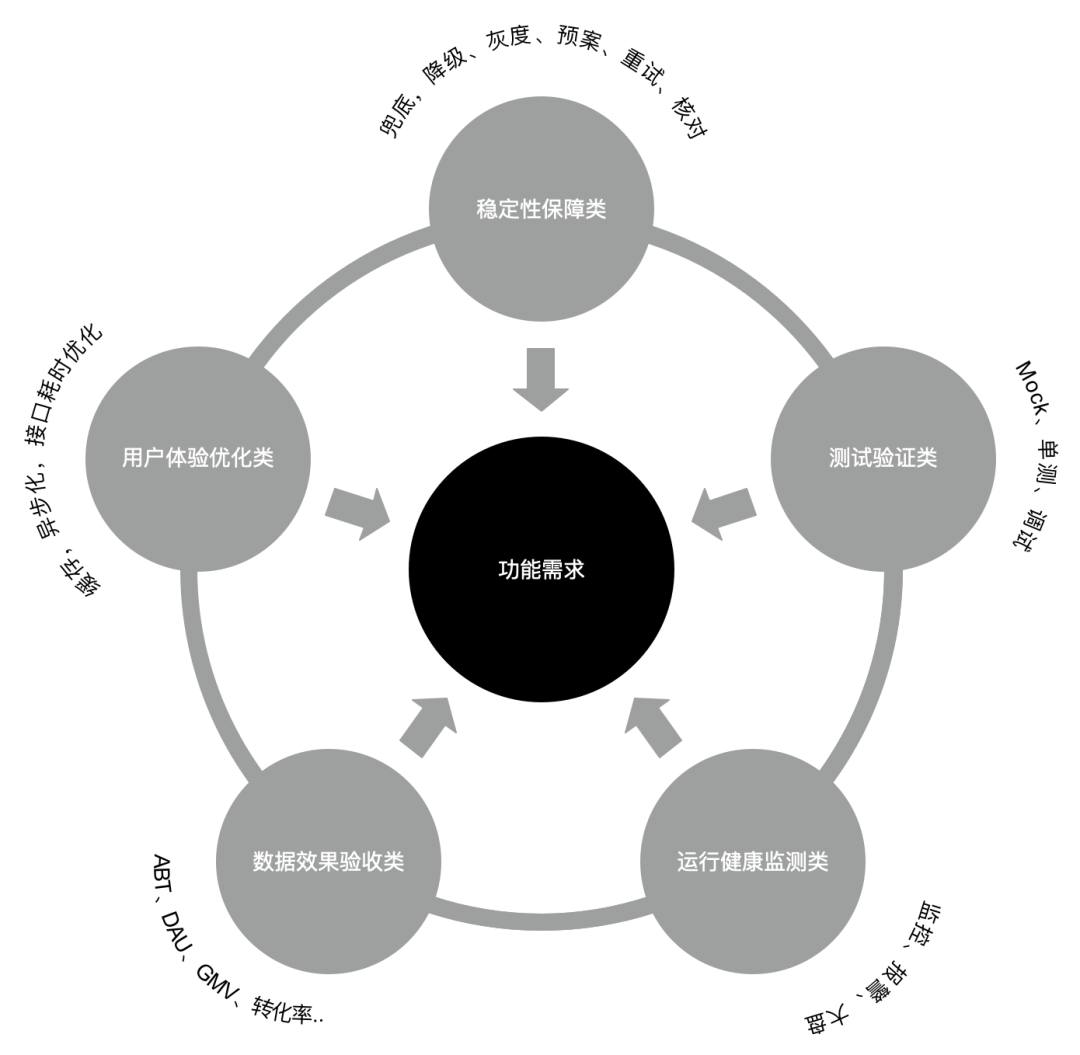
A continuación, lo perfeccionaremos aún más y abordaremos cada parte del trabajo de desarrollo de software.
Por ejemplo:
-
Etapa de demanda: en la etapa inicial de la demanda del producto, coopere con el plan de investigación técnica y aclare los vínculos existentes.
-
Etapa de desarrollo: además del desarrollo de requisitos funcionales, el desarrollo de requisitos no funcionales incluye:
-
-
Manejo de excepciones: manejo de varias posibles excepciones de programas, manejo de excepciones comerciales, procesamiento de control de flujo, procesamiento de seguridad de datos, procesamiento en escala de grises, procesamiento de reversión de excepciones, etc.
-
Categoría de experiencia de usuario: optimización del tiempo de respuesta, procesamiento de cola larga.
-
Categoría de verificación de efectos: se utiliza para monitoreo de operación y mantenimiento, alarmas y estadísticas de efectos comerciales, y se usa para verificación y procesamiento de datos, ya sea que los datos sean normales o no.
-
Categorías de procesamiento temporal: depuración conjunta simulada, pruebas unitarias, etc.
-
-
Fase de prueba:
-
Pruebas de interfaz y pruebas funcionales.
-
Pruebas de estrés y pruebas automatizadas.
-
Solución de problemas
-
-
Fase de lanzamiento: verificación de lista blanca, lanzamiento en escala de grises, reversión, degradación y otras operaciones hacia adelante y hacia atrás.
-
Etapa de operación y mantenimiento: registros de movimiento de usuarios, parentesco de datos, análisis de causa raíz anormal, monitoreo, alarmas, mercado y robots inteligentes.
-
Recuperación de efectos: enfoque empresarial, tasa de conversión, DUA, panel empresarial, informe diario empresarial.
-
Gestión de proyectos: organice el trabajo de entrega de software eficiente y de alta calidad en cada nodo técnico a través de modelos de desarrollo de proyectos como el desarrollo ágil y el desarrollo iterativo.

Al resumir el trabajo anterior, extrayendo capacidades generales, herramientas y plataformas, podemos formar nuestras "herramientas" para mejorar la eficiencia del trabajo correspondiente. Es innegable que todo el mundo hace esto también, hay muchas herramientas y métodos que se pueden utilizar en cada etapa, muchos equipos e individuos tienen cierta experiencia para mejorar la eficiencia del trabajo correspondiente y la mayoría de ellos funcionan bien.
3.3 Dos cuestiones importantes para mejorar la eficiencia de la I+D
Aunque existe una plataforma de herramientas madura para mejorar la eficiencia, todavía hay dos problemas principales, que también son problemas que Nuwa Core resuelve y repara.
La baja integración genera altos costos de aprendizaje y una gran cantidad de código adhesivo
La mayoría de ellos existen en forma de varios middleware maduros y, cuando es necesario, los enlaces de datos y los enlaces del sistema se abren mediante el "código adhesivo" correspondiente.
Por ejemplo, si necesitamos pruebas de estrés, primero debemos acceder a un paquete local para conectarnos en línea y registrar el tráfico; necesitamos estadísticas sobre el efecto de los datos, y cuando se activa la alarma de monitoreo del estado del sistema, primero debemos imprimir los registros; cuando se necesita almacenamiento en caché, Es necesario introducir el SDK de almacenamiento y la inyección de beans.
Cuando se utilizan estas herramientas, marcos y plataformas modulares independientes, están destinados a requerir una gran cantidad de "código adhesivo" para conectarlos en serie, cada uno centrado en sí mismo, lo que también conlleva muchos costos de aprendizaje y carga de trabajo.
La unidad más pequeña de granularidad de la interfaz rpc limita una gran cantidad de trabajo de I+D a realizar
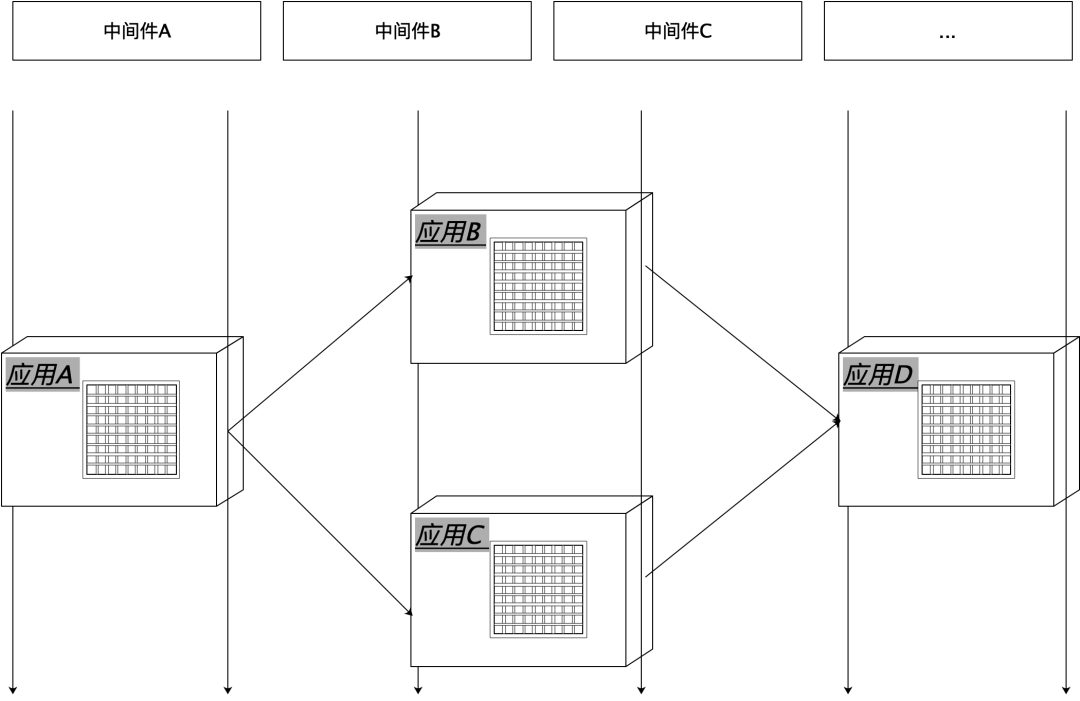
Bajo la arquitectura de microservicio, el método de servicio que exponemos es la unidad de negocio más pequeña, un método de interfaz corresponde a un comportamiento completo del usuario y la interfaz es la unidad externa más pequeña del programa.
Sin embargo, desde la perspectiva del programa, el método de interfaz es solo una entrada: se compone de unidades de procesamiento técnico más básicas conectadas en serie, como procesamiento anticorrosión posterior, procesamiento de agregación de datos, procesamiento lógico, operaciones de almacenamiento, etc. e incluso la lectura y escritura de cada unidad de datos comerciales, todas son una unidad de procesamiento. La mayoría de las herramientas, plataformas y middleware de mejora de la eficiencia solo se dirigen a la capa de llamadas de red, pero desde la perspectiva de la unidad de procesamiento interna del programa.
La mayoría de nuestros programas están orientados a objetos. La lógica de negocios de una interfaz se compone de varias unidades de procesamiento internas relativamente independientes conectadas en serie. Cuando a menudo necesitamos procesar, monitorear, intervenir y recopilar estadísticas sobre las unidades de procesamiento de lógica interna durante la investigación. y desarrollo, todos los cambios de herramientas ya preparados ya no son prácticos.
Por ejemplo, si queremos contar qué método de salida de una determinada interfaz descendente se llama en nuestra aplicación, nos resulta difícil encontrar herramientas para el análisis de correlación de dos componentes internos, además, muchas veces para un propósito especial, como para pruebas unitarias, corrección de datos, puerta trasera de emergencia e interfaz de consulta para robots inteligentes, necesitamos exponer una unidad de procesamiento interna a una interfaz separada.
La causa principal de esto es que la granularidad de procesamiento mínima de todas las herramientas y plataformas es la interfaz RPC, y Nuwa se centra en los componentes comerciales a nivel de código.
3.4 El desencadenante causado por Nuwa: caché universal
El análisis de arriba hacia abajo anterior nos hace darnos cuenta de que la mayoría de las herramientas tradicionales de I+D se quedan en el nivel de la interfaz y, a menudo, no pueden satisfacer directamente nuestros requisitos. ¿Podemos pensar por qué se produce este resultado? ¿Podemos también cambiar el ángulo? ¿Existe alguna posibilidad? ¿Una forma más eficiente de hacer estos enlaces?
De empresa a empresa, la introducción para convertirse en Nuwa es actualizar la arquitectura de evaluación de reputación y migrar el sistema del lado Ant a Tao. Sin embargo, la mayoría de los servicios dependientes todavía están en Ant y necesitamos agregar caché a un conjunto de interfaces entre dominios. Por lo general, codificaremos de manera estricta escenario por escenario; para mejorar aún más la eficiencia, escribiremos clases de herramientas de caché, encapsularemos parte de la lógica de lectura y escritura de caché y las llamaremos de la manera menos intrusiva. posible cuando sea necesario; además, haremos declaraciones de caché a través de anotaciones declarativas. La implementación, la lógica de negocios es casi no intrusiva, como la anotación Spring @Cacheable o la implementación personalizada de un conjunto de anotaciones.
Aunque los tres formularios anteriores son más eficientes paso a paso, solo acortan el nivel del código de 100 líneas a 50 líneas y reducen las 50 líneas a 20. La facilidad de uso y la reutilización del código se han mejorado hasta cierto punto. , pero se ha realizado cierta optimización: no hay una diferencia fundamental, es imposible responder rápidamente a los riesgos y esencialmente no puede resolver el problema.
Resumido de la siguiente manera:
-
Falta de capacidades sistemáticas: además de leer y escribir, el almacenamiento en caché suele ir acompañado de precalentamiento, actualización, procesamiento multinivel, etc. En la arquitectura de microservicios, estas acciones se pueden dividir en varios sistemas. Cada vez que se agrega un nuevo negocio Para el almacenamiento en caché En algunos casos, debe considerar qué almacenamiento usar, qué tipo de KV definir, dónde leer, dónde limpiar y actualizar, cuánto tiempo almacenar en caché, si precargar, cómo realizar la precarga, monitoreo de la tasa de aciertos de la caché y alerta temprana. fusionar datos de aciertos parciales, ya sea que haya fallas de caché, penetración, avalanchas y otros mecanismos de procesamiento, y luego agregar el código correspondiente cuando sea necesario, lo cual obviamente está disperso y requiere poco mantenimiento, pero el costo es muy alto; al mismo tiempo, hay una falta de análisis inmediato del efecto de los datos. Por lo general, el middleware solo proporciona paneles de perspectiva de recursos, mientras que la tasa de aciertos de la caché, la tasa de actualización, la duración promedio de la actualización, la tasa de aciertos parciales, la precisión de la caché, etc. en escenarios comerciales requieren paneles de efectos personalizados. Podemos ver que detrás de esto hay todo un conjunto de contenidos involucrados que, si no se consideran de manera integral, pueden causar problemas y retocarlos o asumir la culpa;
-
Falta de capacidad de intervención de ajuste dinámico (flexibilidad): cuando agregamos caché a través del código, algunos parámetros a menudo están codificados, como la lógica de procesamiento fallido y el valor de ttl. Sin embargo, durante la operación real, se descubre que ttl puede ser largo o corto. Sí, cuando se necesitan ajustes, es necesario volver a pasar por el proceso de liberación iterativa de requisitos. Nunca se sabe qué situaciones especiales y emergencias pueden surgir. Es posible que necesitemos hacer algunos trucos con los parámetros operativos almacenados en caché;
-
Falta de capacidades de replicación rápida: los requisitos no funcionales, como el almacenamiento en caché, se iteran en una interfaz caso por caso. El negocio suele ser complejo y nos resulta difícil predecir de antemano las interfaces con cuellos de botella en el rendimiento. no está a la altura del estándar después de conectarse, es el desarrollo Parches de emergencia, volver a probar la implementación y en línea; conectarse primero y reprogramar la optimización para la próxima vez; o posponer las reparaciones y luego conectarse. No importa qué tipo de desarrollo sea, es muy pasivo;
-
Facilidad de uso: la escritura en la computadora a través de código se ha optimizado hasta cierto punto, pero combinar la tecnología y los negocios a menudo aumenta la complejidad del sistema y dificulta su uso.
Además del almacenamiento en caché, otros requisitos no funcionales que no tienen nada que ver con el negocio durante el proceso de investigación y desarrollo, como respaldo, control de flujo, enterramiento dinámico, burla, unilateralidad, etc., tienen el mismo problema. . Ahora mismo:
-
Cada vez que hay un desarrollo, es necesario desarrollar un montón de capacidades de configuración.
-
Cada vez que hay un ajuste, es necesario cambiar el código.
Como resultado, carece de integridad, no es lo suficientemente flexible, tiene una gran complejidad y problemas de chimenea que dificultan su replicación rápida y requieren una gran carga de trabajo.
4. Construcción de Nuwa
Objetivo 4.1: Incrementar varias veces más la eficiencia de la I+D
Ante una gran cantidad de cargas de trabajo repetitivas, riesgos desconocidos en tiempo de ejecución, capacidades de control débiles y ciertos problemas de eficiencia causados por el modelo de desarrollo tradicional, se pueden utilizar ciertos métodos de mejora de la eficiencia para hacer: idealmente, la carga de trabajo que solía estar codificada de 2 horas a 1 día se puede reducir de 1 a 30 minutos para completar y la eficiencia aumenta al menos n veces.
4.2 Dificultad: Complejidad y diversidad de escenarios de mejora de la eficiencia
-
Frente a diferentes grupos de personas, diferentes contenidos de trabajo y diferentes formas de escenarios de mejora de la eficiencia, cómo expresarlos y realizarlos de manera uniforme en Nuwa para formar una mente unificada y una composición sistemática sin estar demasiado fragmentados;
-
¿Qué arquitectura y modelo de procesamiento se deberían adoptar para mejorar eficazmente la eficiencia de la investigación y el desarrollo de Nuwa y la eficiencia de la expansión de nuevos escenarios?
-
Hay muchos escenarios, cómo planificar módulos, definir módulos, definir estándares de implementación y extensión de módulos, y cómo unificar la terminología para formar una solución sistemática.
4.3 Idea central: Siete formas de Huigong Dafa
Entonces, ¿qué tipo de medidas de eficiencia deberían utilizarse? Desmantelamos los indicadores de viabilidad: integridad, aplicabilidad, flexibilidad, facilidad de uso, aislamiento y replicabilidad, y finalmente formamos un sistema sistemático, universal, dinámico, inteligente, transparente, a gran escala y Soluciones basadas en protocolos.
✪ 4.3.1 Solución sistemática para completar
A través de soluciones sistemáticas, se forma la integridad de los objetivos de mejora de la eficiencia y se proporcionan capacidades sistemáticas para garantizar completamente el circuito cerrado de los requisitos técnicos. Por ejemplo, el precalentamiento de caché y la visualización de efectos se convierten en capacidades generales y los enlaces se abren directamente, menos el pegamento de la especialización empresarial código para garantizar la integridad .
Por ejemplo, el almacenamiento en caché forma un ciclo cerrado completo de operaciones de almacenamiento en caché:
-
Primero, resumiremos las capacidades de almacenamiento en caché en sí, incluidas, entre otras, capacidades de lectura, capacidades de escritura, capacidades de almacenamiento, capacidades de precalentamiento, capacidades de procesamiento multinivel, capacidades estadísticas, así como capacidades de degradación y capacidades de escala de grises necesarias para el lanzamiento y la operación y mantenimiento.
-
En segundo lugar, elija diferentes operadores y métodos de extensión para conectar estas capacidades, como el procesamiento de lectura y escritura de proxy dinámico AOP para un determinado punto de contacto del código, capacidades de precalentamiento y depuración para SPI general, módulo de estadísticas métricas y panel de datos de soporte para estadísticas, como así como módulos para la gestión de fuentes de datos de almacenamiento en caché, compresión de caché, etc.
✪ 4.3.2 Solución generalizada de aplicabilidad
Dado que el objetivo de Nuwa es desarrollar I + D y mejorar la eficiencia, el alcance es relativamente amplio. Eventualmente se utilizará el tipo de arquitectura técnica que se utiliza en varios escenarios de mejora de la eficiencia, por lo que depende de las capacidades de la solución general para mejorar la practicidad de Nuwa para mejorar la eficiencia en todos. aspectos.
Por ejemplo, como se menciona a continuación:
-
Tres unificaciones: concepto, modelo, proceso
-
Dos sistemas: complementos y páginas.
-
Un ecosistema: el sistema tecnológico Alibaba
Principio: hacer que la lógica sea universal, flexible en expansión/configuración y evitar el método "copiar/pegar" (esquema: modularización + componenteización + solución de configuración)
✪ 4.3.3 Solución dinámica para mayor flexibilidad
Mejore la flexibilidad de la mejora de la eficiencia a través de soluciones dinámicas y mejore las capacidades de intervención en tiempo de ejecución, como medios más flexibles para crear y modificar la implementación de caché empresarial, mejorar la flexibilidad y completar el trabajo relacionado sin la necesidad de publicar código.
Por ejemplo, caché: el complemento de caché está controlado por la entrega de comandos, y la entrega de comandos lleva diferentes parámetros operativos según las diferencias en las instancias en ejecución. Desde nuestra perspectiva, estos parámetros operativos son configuraciones. Es una elección común dentro del grupo para elegir Diamond como centro de configuración.
✪ 4.3.4 Solución inteligente para facilitar su uso
Reduzca la complejidad y mejore la facilidad de uso a través de medios inteligentes, proporcione formas inteligentes de reducir la complejidad de la implementación técnica , reduzca los pasos de implementación lógica de varios parámetros manuales y cree instancias, cambie de imperativo a declarativo, sin prestar atención a los detalles técnicos, solo es necesario centrarse en objetivos técnicos.
Por ejemplo, si desea que el almacenamiento en caché sea más inteligente, debe encapsularlo mediante tecnología de almacenamiento en caché profunda, abstracción razonable y modelos de procesamiento maduros para formar una herramienta de almacenamiento en caché, un marco de almacenamiento en caché o incluso una plataforma. una tecnología.complemento .
La comprensión personal y la facilidad de uso tienen cuatro ámbitos:
-
El primer nivel, de código duro, es para programar en lenguajes de programación imperativos, y el desarrollo requiere la correspondiente comprensión empresarial y habilidades de programación;
-
El segundo nivel es el lenguaje DSL, que encapsula y expresa la lógica basada en lenguajes de dominio específicos, como el lenguaje de scripting Groovy, el lenguaje de expresión/función y otros DSL. Realiza un desarrollo declarativo hasta cierto punto y luego lo ejecuta y lo depura. tener ciertas habilidades comerciales Experiencia + habilidades de operación de sintaxis DSL;
-
El tercer nivel es la interfaz de configuración. El sistema interactúa con la encapsulación DSL, expresa el lenguaje técnico a través del lenguaje comercial y realiza expresiones y series lógicas a través de formularios + arreglos + bloques de construcción. Los usuarios solo necesitan tener experiencia comercial profesional a través de la configuración y pueden lograr;
-
El cuarto nivel es la inteligencia artificial. Muchas de las herramientas marco con las que entramos en contacto son muy versátiles porque están dirigidas a una amplia gama de grupos de usuarios. Si no son universales, inevitablemente serán inaplicables en ciertos escenarios, lo que generará comentarios negativos. Por tanto, la universalidad es la primera capacidad que deben soportar, sin embargo, cuanto más general es, más abierta y flexible es, pero la facilidad de uso disminuye. En un campo específico, General Internals en realidad cumple con la regla 80/20 y puede hacer que 8 sea más fácil de usar y universal. Por ejemplo, la configuración de caché puede programarse para calcular el 80% de las opciones posibles del usuario, y el usuario solo necesita para confirmar o elegir uno, sin embargo, en este momento el usuario solo necesita tener muy poca experiencia comercial y poder completarlo.
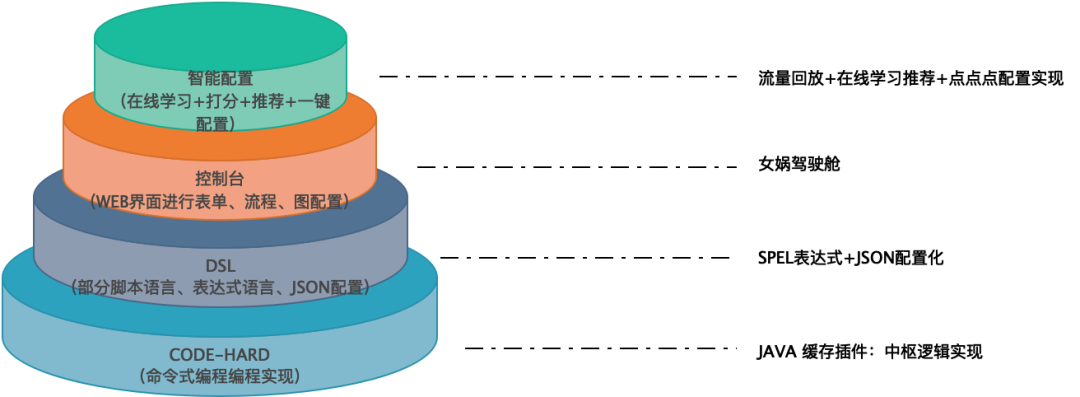
Estos cuatro ámbitos no son relaciones mutuamente excluyentes, sino que incluyen relaciones de dependencia, como nuestra solución de almacenamiento en caché:
-
Encapsule la lógica del centro central mediante complementos ;
-
Ampliar la definición lógica como diferenciación empresarial a través de lenguajes de expresión como SPEL ;
-
A través del formulario en línea de la consola Nuwa , puede configurar directamente la instancia de la aplicación de caché a través del paquete SPEL;
-
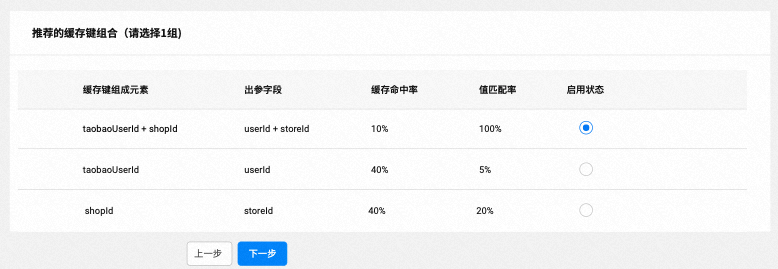
A través de la reproducción del tráfico + aprendizaje en línea, las combinaciones de teclas de caché se pueden utilizar para hacer recomendaciones inteligentes y los usuarios solo necesitan "hacer clic".
Principio: primero sin código, segundo con código bajo, tercero con cable duro.
✪ 4.3.5 Solución de transparencia para aislamiento
El entorno operativo de Nuwa es un entorno de caja de arena, mientras que el entorno operativo empresarial es un entorno real. El aislamiento ambiental se realiza bien, es transparente para el uso empresarial y no tiene ningún impacto en los resultados o la puntualidad. Esto se refleja principalmente en los siguientes tres puntos:
-
Separe el negocio y la tecnología tanto como sea posible para reducir la intrusión en las aplicaciones host (esquema: SDK + agente dinámico + consola)
-
Las excepciones de Nuwa están aisladas de las excepciones comerciales para evitar fallas comerciales (esquema: encapsular objetos de excepción separados)
-
El rendimiento debe optimizarse tanto como sea posible para evitar agregar una carga de rendimiento adicional al procesamiento original (esquema: precarga + esquema de orquestación bajo demanda)
✪ 4.3.6 Solución de escala para replicabilidad
Mejore la eficiencia y la replicación rápida mediante escala, proporcione acceso liviano y cree una solución fácil de usar, fácil de replicar y escalable . Para facilitar que la solución de almacenamiento en caché se copie rápidamente a otros escenarios de aplicaciones, todo el procesamiento La lógica central es Todo está empaquetado en Nuwa SDK , y la parte de diferenciación empresarial se configura a través de la consola Nuwa. Solo es necesario acceder a la aplicación una vez y usarla varias veces. Simplemente introdúzcalo como si fuera una biblioteca de terceros.
✪ 4.3.7 Solución de protocolo para apertura
Al abrir las definiciones de interfaz adecuadas, los estudiantes de negocios pueden implementarlas de acuerdo con sus propios requisitos, incluso complementos, abrir capacidades al mundo exterior e incluso la ecología y el uso compartido de complementos.
5. Diseño de puntos clave 1: tres unidades
Tres unidades, dos sistemas y una ecología:
-
Tres unificaciones: concepto unificado + modelo unificado + proceso unificado;
-
Dos sistemas: varios complementos + páginas coincidentes;
-
Una ecología: una ecología rica.
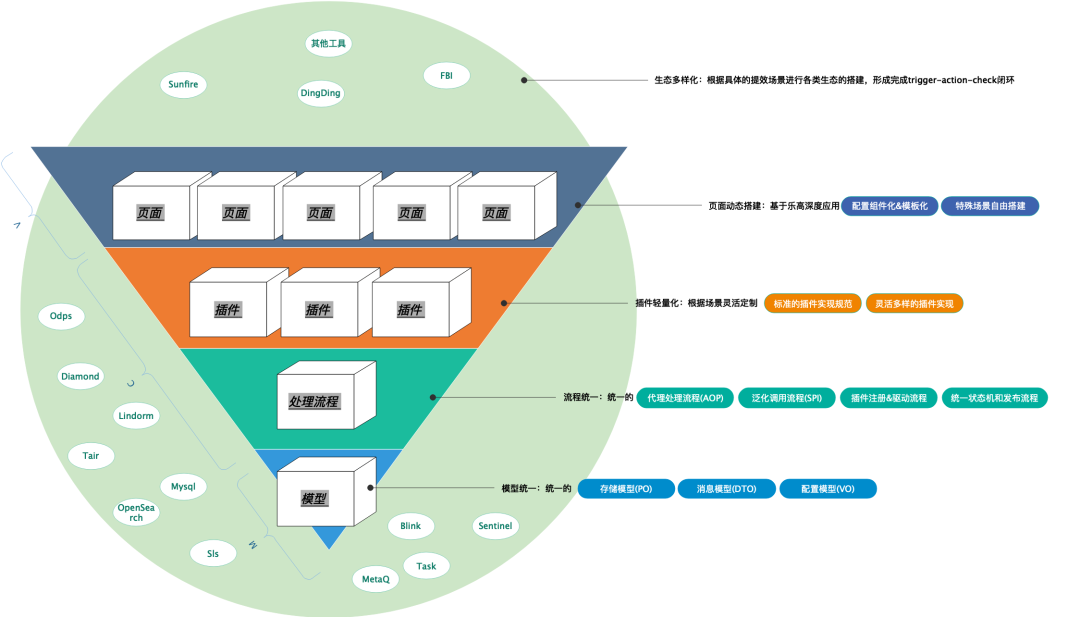
tres unidades
Unificación de conceptos, modelos y procesos.
-
Concepto unificado: definición unificada del problema;
-
Modelo unificado: modelo de almacenamiento, modelo de mensaje, modelo de configuración;
-
Procesos unificados: proceso de registro, proceso de agente, máquina de estado de procesamiento.
5.1 Unificación de conceptos
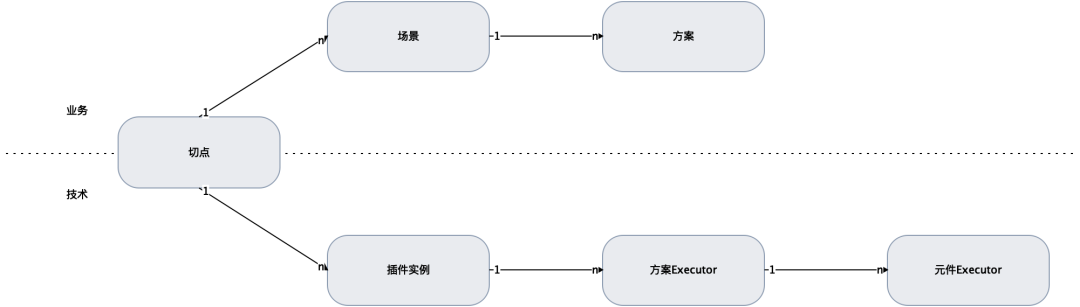
✪ 5.1.1 Complementos y componentes
Complemento: concepto técnico. Un complemento es un componente tecnológico de implementación preestablecido en el paquete cercano. Es esencialmente un fragmento de código que completa un objetivo técnico independiente. No se ejecuta de forma predeterminada. Está impulsado por instrucciones separadas. y configuraciones para ejecutar el complemento y pasar el tiempo de ejecución. Nuwa proporciona múltiples complementos para los parámetros dependientes y también proporciona una API simple de registro e implementación de complementos.
-
Ejemplos: complemento de caché, complemento de bolsillo, complemento simulado, complemento de escala de grises, complemento oculto, complemento de estadísticas, complemento de control de flujo, complemento de una sola cara
-
Módulo de atribución y código correspondiente: Nuwa SDK - NvWaPlugin.java
Componente: un concepto técnico, que es la capacidad atómica que puede utilizar un complemento. Si lo anterior es el producto de un diseño de arriba hacia abajo, entonces el componente es un producto de un diseño de abajo hacia arriba.
-
Ejemplos: componentes de ensamblaje de contenido, componentes en escala de grises, componentes limitantes de corriente, componentes de estadísticas de metadatos...
-
Módulo/código atribuible: Nuwa SDK - xxExecutor.java.
✪ 5.1.2 Puntos tangentes y planos tangentes
Punto de corte: se puede llamar "punto de contacto". El concepto técnico, como sugiere el nombre, es el punto de entrada, el punto que desencadena la lógica de expansión. El complemento es una Acción y el punto de corte es el Objetivo. ejecutado por el complemento. Los puntos de corte de puntos se dividen en dos categorías:
-
Punto de corte preciso: un punto de corte corresponde a un método de una clase en el código, es decir, diferentes objetos de Método son diferentes puntos de corte precisos, y el complemento actúa sobre un método de la clase;
-
Punto de corte difuso: generalmente el punto de corte preciso en el sistema varía de cientos a miles. Cuando queremos aplicar el mismo complemento a varios puntos de corte relacionados con el sistema, podemos definir un punto de corte difuso y expresarlo mediante una expresión formal. , los puntos de corte precisos que coinciden con el bloqueo de expresión regular comparten la instancia del complemento de la aplicación, en lugar de configurar e instanciar repetidamente cada punto de corte preciso.
Ejemplo:
-
Punto de corte exacto: com.alsc.comment.kbt.integration.rateplatform.impl.RateQueryServiceClientImpl#queryRates
-
Punto de corte difuso: com.alsc.comment.kbt.integration.rateplatform.impl.RateQueryServiceClientImpl#.*
-
Módulo/código perteneciente: aplicación host: todos los métodos públicos de clases en el contenedor IOC.
Aspectos: los aspectos de Spring son una tecnología para definir preocupaciones transversales en una aplicación.
✪ 5.1.3 Escenarios y escenarios
Escenario: Concepto de negocio, que representa una aplicación de capacidad técnica completa, que también corresponde a una aplicación empresarial completa. Un complemento actúa sobre un punto de corte para formar un escenario.
Es decir: 1 complemento + 1 punto de corte -> 1 escena. La escena es un Trigger que combina Acción + Objetivo.
-
Por ejemplo: escenario [Consultar la lista de buenas tiendas cercanas] [Verificar el resultado final], escenario [Consultar información de la tienda] [Caché], escenario [Capa anticorrosión] [Monitoreo de llamadas de servicio].
-
Módulo/código perteneciente: Consola: una colección de configuraciones para cada punto de acceso en cada menú de funciones.
Esquema: concepto de negocio. Un esquema es un conjunto de definiciones de cómo debe funcionar un complemento en un escenario. Un escenario puede tener uno o más esquemas (es decir, múltiples conjuntos de definiciones). Un esquema contiene varios parámetros que el complemento -in depende de cuándo se ejecuta. Múltiples esquemas pueden coincidir con uno de los planes (exclusivo) o múltiples planes para ejecución colaborativa (compartida). El plan es la forma en que funciona la Acción. Un plan corresponde a un Ejecutor. Un escenario con n planes tiene n+1 Ejecutores, uno de los cuales es múltiple El Ejecutor coordinado por el esquema Ejecutor.
-
Por ejemplo: [Consultar la lista de buenas tiendas cercanas] Escenario [Empujar hacia abajo], la solución en la mitad superior de la página, [Consultar la lista de buenas tiendas cercanas] [Empujar hacia abajo] escenario, el escenario más allá de la primera pantalla.
-
Módulo/código atribuible: Nuwa SDK - xxExecutor.java.
5.2 Unificación de modelos
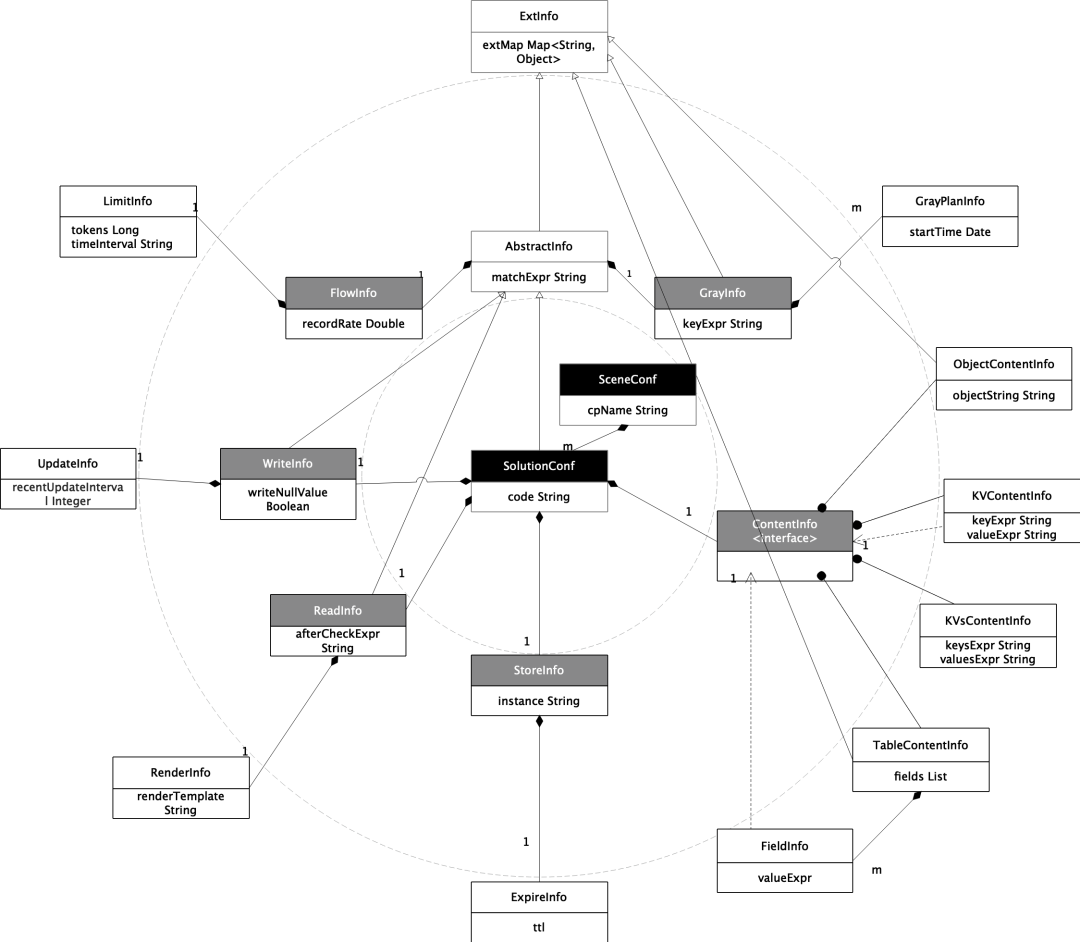
Modelo de mensaje: también es un modelo de dominio. Es un modelo de metadatos que impulsa el plan de trabajo del complemento. Establecerá un puente entre el modelo de almacenamiento y el complemento. Se deriva del modelo de configuración. Al mismo tiempo Al mismo tiempo, es necesario considerar las expresiones comunes y diferenciadas de varios complementos en el modelo de dominio, correspondientes al Objeto Modelo.
Modelo de configuración: También es un modelo de visualización, que se refiere al modelo de configuración estructurado cuando la consola realiza la configuración de escena. Este modelo está diseñado desde la perspectiva del personal de configuración, teniendo como prioridad la experiencia del personal de configuración. También puede ser fácilmente convertido en un modelo de almacenamiento, correspondiente a Ver Objeto.
Modelo de almacenamiento: el modelo de almacenamiento para la persistencia final de todas las configuraciones de front-end. Este modelo es fácil de convertir en un modelo de configuración y un modelo de mensaje de dominio, correspondiente al Objeto Persistente.
No importa qué tipo de modelo sea, todo está configurado para un escenario de aplicación de complemento en un punto de corte, es decir, las entidades del modelo son escenas Nuwa y objetos de solución.
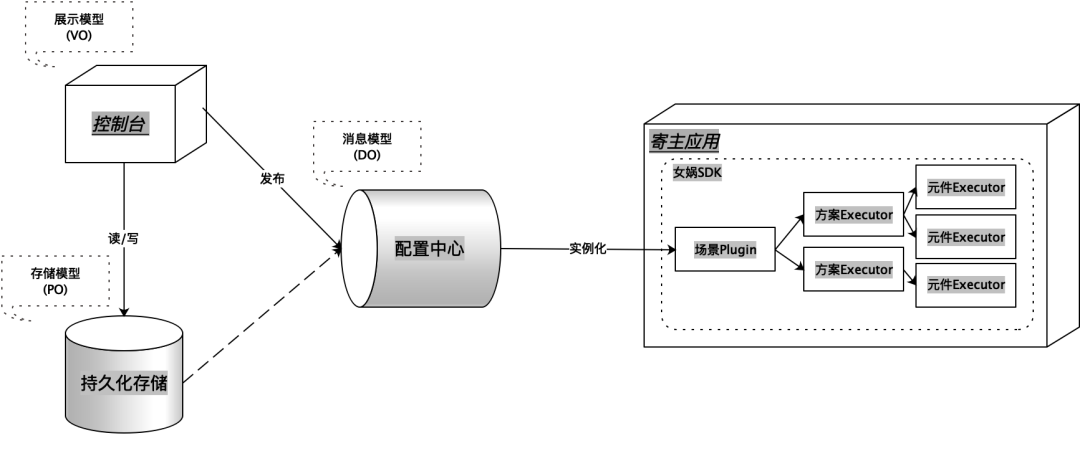
✪ 5.2.1 Modelo de mensaje (DO, normalizado)
desafío
Debido a que los complementos son demasiado diversos, en aras de la flexibilidad, es necesario admitir diferentes parámetros dinámicos cuando se ejecuta el complemento, como por ejemplo:
-
Los parámetros de los que depende el complemento de caché son: motor de caché, expresión de clave de caché, expresión dividida inteligente del resultado de caché por lotes, control de caché o no, estrategia de carga asincrónica (frecuencia de muestreo, aprendizaje inteligente, último intervalo de carga y otras configuraciones), precalentamiento plantilla, caché de expresiones condicionales, ttl, etc.;
-
Los parámetros de los que depende el complemento de respaldo son: motor de almacenamiento de instantáneas de respaldo, lista de matrices de expresiones clave de índice de instantáneas de respaldo (por prioridad), expresión de condición de acierto de respaldo, condición de actualización de datos de respaldo, respaldo -up snapshot ttl, estrategia de actualización de instantáneas de respaldo (estrategia de actualización forzada, estrategia de actualización débil, condiciones de verificación de actualización, etc.;
-
Los parámetros de los que depende la grabación de tráfico incluyen: número total de grabaciones, hora planificada de inicio y finalización de la grabación, control de velocidad de grabación, frecuencia de muestreo de grabación, configuración del contenido de grabación, etc.
Ideas
Opción 1: cuando no existe un modelo de mensaje unificado
Todos los complementos definen sus propios mensajes modelo y los complementos realizan el procesamiento correspondiente de acuerdo con sus respectivos modelos de mensajes, es decir, definen: modelo de mensajes de caché, modelo de mensajes de encubrimiento y modelo de mensajes de registro de tráfico.
ventaja
-
Cada complemento corresponde a un modelo de mensaje, que es flexible, semánticamente claro y directo.
defecto:
Cada vez que se agrega un nuevo complemento
-
Nivel de modelo: todos deben personalizar el modelo de mensaje correspondiente, carga de trabajo + 1;
-
Nivel de implementación del complemento: todos deben monitorear, consumir y analizar el modelo de mensaje correspondiente para responder, carga de trabajo + 1;
-
Nivel de consola: al crear la página de configuración correspondiente, es necesario admitir los campos correspondientes al nuevo modelo de mensaje y la carga de trabajo + 1.
De hecho, encontramos que muchos campos tienen significados similares o la misma función, por ejemplo: useCacheExpr y useSnapshotExpr representan la verificación previa cuando se ejecuta el complemento, y cacheEngine y snapshotEngine representan el objeto de instancia de almacenamiento de destino.
¿Existe una solución más adecuada? Aquí resumimos y unificamos varios escenarios.
Solución 2: modelo de mensaje unificado (modelo de mensaje de agregación de componentes)
Para lograr sus objetivos técnicos inherentes, un complemento generalmente requiere una serie de combinaciones de acciones, es decir, se puede descomponer internamente en varias operaciones atómicas. Por ejemplo, desmontamos el complemento de caché internamente en caché de lectura, escritura caché, juicio de condición independiente, cálculo de KV de caché, estadísticas, etc. Operaciones atómicas. Las operaciones atómicas de diferentes complementos pueden ser similares o personalizadas. Las operaciones atómicas de todos nuestros complementos están agrupadas. Las capacidades atómicas son básicamente del mismo tipo. tienen el mismo efecto y los mismos parámetros operativos dependientes. Consideramos las operaciones atómicas generales como "componentes" del sistema , que se pueden resumir aproximadamente en las siguientes categorías, como:
-
Leer componente
-
Escribir componente
-
componente en escala de grises
-
Elemento limitante de corriente
-
elemento de almacenamiento
-
....
Estos componentes tienen sus propios parámetros de configuración de tiempo de ejecución. Por ejemplo, los componentes en escala de grises incluyen: expresión de clave de depósito, grupo de prueba de lista blanca, relación de escala de grises, tipo de escala de grises (manual, automático), plan de escala de grises y otros parámetros de configuración de tiempo de ejecución. Los componentes tienen su propia configuración de componentes.
Diferentes complementos reutilizan el mismo modelo de mensaje
ventaja
Hay un modelo de configuración unificado y un mecanismo de extensión. Al agregar nuevos complementos:
-
Nivel de modelo: reutilización directa, si la reutilización no es posible, agregue campos de extensión a la configuración del componente correspondiente (carga de trabajo <carga de trabajo del esquema 1 * 0.2)
-
Nivel de implementación del complemento: monitoreo, consumo y análisis unificados. Además, solo los campos extendidos deben analizarse por separado (carga de trabajo <carga de trabajo del plan 1 * 0.2)
-
Nivel de consola: al crear la página de configuración correspondiente, utilice un modelo unificado y la mayoría de las configuraciones se pueden reutilizar directamente. Los campos extendidos deben representarse dinámicamente (carga de trabajo <esquema 1 carga de trabajo * 0.2)
-
Nivel de comprensión: un modelo unificado no requiere que cada configuración de escena se comprenda de forma independiente, y la mayoría de las configuraciones de escena se reutilizan
defecto:
-
Debido a la reutilización de modelos unificados, la semántica no es tan directa, como el modelo unificado checkExpr, y el modelo no unificado es canUseCacheExr. Este último tiene un propósito claro y el primero es solo una capacidad.
-
Debido a la reutilización de un modelo unificado, la semántica no es tan directa, existen definiciones estructurales y definiciones jerárquicas, y los mensajes son más complejos.
Opción 1 frente a Opción 2
Pensándolo desde otro ángulo, el modelo de mensaje es para uso de programas. La claridad de la semántica y la simplicidad de los mensajes no son tan importantes en comparación con la carga de trabajo real y la reutilización.
Por tanto, nuestro modelo de mensaje sin duda elige la opción dos .
✪ 5.2.2 Modelo de configuración (VO, recorte, aplanamiento, mapeo, agrupación, clasificación)
El modelo de mensaje está orientado al programa y enfatiza la versatilidad, la reutilización y la escalabilidad; mientras que el modelo de configuración está orientado al usuario y enfatiza la simplicidad, la franqueza y la claridad; el modelo de visualización se transforma en última instancia en un modelo de mensaje, por lo que el modelo de configuración se basa en el modelo de mensaje Diseño, si lo usamos directamente sin procesar, habrá algunos problemas.
desafío
Falta de semántica de escena (semántica clara)
El modelo de mensaje unificado está diseñado en función de capacidades técnicas, está orientado a complementos y adopta conceptos técnicos relativamente generales. No es un concepto comercial en escenarios comerciales de usuarios, carece de la semántica comercial de escenarios correspondiente y no puede cumplir con requisitos simples y claros. del modelo de configuración. Está más verificado y afecta la experiencia del usuario. Es similar al concepto de operación técnica de la base de datos de agregar, eliminar, modificar y consultar, en lugar de los conceptos comerciales de front-end como crear, editar, guardar y enviar (comportamientos de usuario correspondientes).
Por ejemplo, en nuestro escenario simulado, necesitamos devolver un mensaje simulado fijo para un escenario especial. Si se muestra directamente de acuerdo con el modelo de mensaje, será información de contenido (contenido de tipo cadena), ingrese un valor de cadena específico, como :

La visualización real para los usuarios debería ser así. No solo pueden saber claramente para qué completar la información, sino que también pueden crear estilos especiales y lógica de verificación para este campo en este escenario. Por ejemplo, el que aparece aquí se representará usando un editor json:
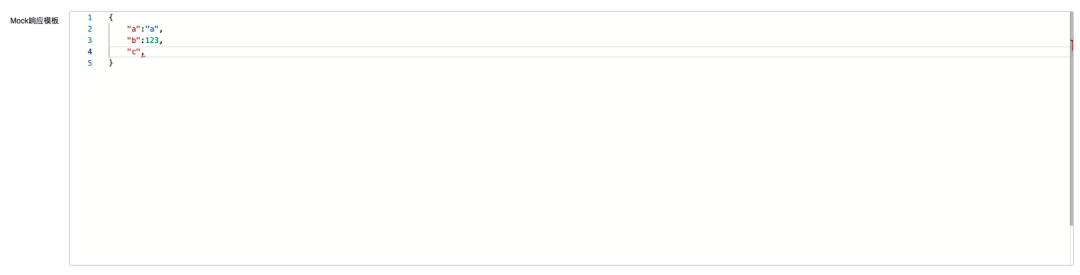
Cuanto más profunda es la jerarquía, más compleja es la expresión (el proceso es más fluido)
El modelo de mensaje unificado es un modelo grande y completo. Dado que transporta más información, tendrá más módulos y niveles más profundos. El front-end generalmente usa bloques de componentes como formularios, listas, etc. para transportar información. Para representación jerárquica y de módulo generalmente se anida a través de subpáginas, ventanas emergentes, pasos y pestañas. Si hay demasiados componentes de bloque frontales en una página, especialmente las diferentes formas de componentes de bloque, y especialmente los componentes de bloque anidados, no son propicios para la expresión. Las personas pueden comprender fácilmente el flujo de información, como la información en forma de I y L que a menudo entendemos, mientras que las estructuras de información en forma de S y caleidoscopio son más difíciles de entender.
Por ejemplo, cuando escribimos, nuestra expresión jerárquica es la siguiente:
Si hay empate en función de un escenario concreto, podemos expresarlo así:
Obviamente lo siguiente será más conciso y claro, por supuesto el ejemplo sólo muestra la punta del iceberg.
Falta de capacidades de personalización (orientadas a programas u orientadas al usuario)
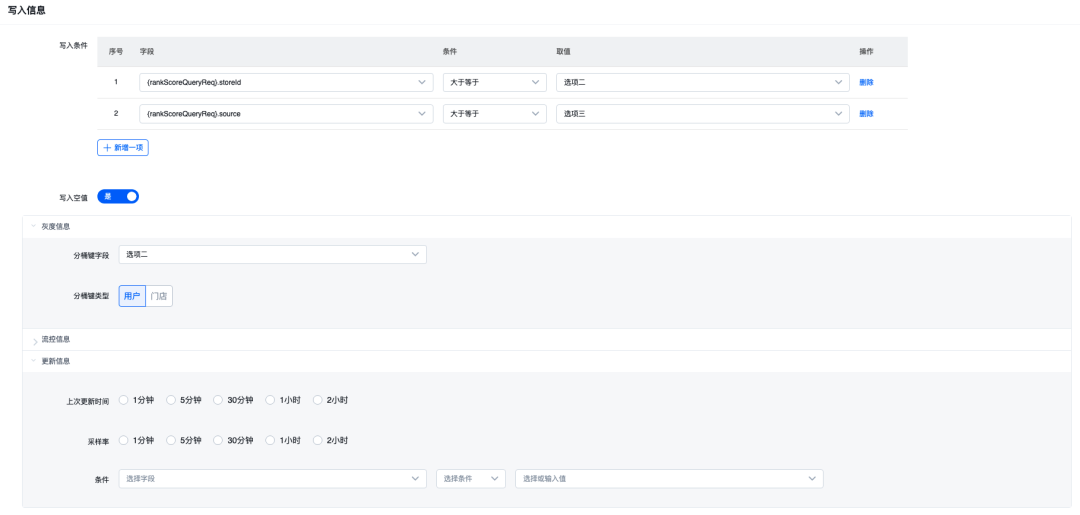
Como mencionamos anteriormente que el modelo de mensaje es grande y universal, los escenarios específicos no requieren todos los atributos, por lo que deben adaptarse durante la edición del escenario real. Además, para mejorar la eficiencia de la configuración, debemos mejorar la configuración. de algunos campos y agregar algunas capacidades de procesamiento adicionales, como cuando necesitamos agregar capacidades de aprendizaje automático en línea a los pares clave-valor almacenados en caché; y cuando la configuración es demasiado compleja, debemos permitir que los usuarios los guíen paso a paso para configurar.
Por ejemplo, cuando la configuración de la caché está orientada al modelo de mensaje, los componentes clave de la caché se ingresan como:

La expresión estructurada de la capa de presentación aquí es: dividimos la configuración de la caché en configuraciones básicas de la caché -> grabación de tráfico -> configuración de la clave de la caché -> configuración de la condición de la caché -> configuración de carga asincrónica -> análisis del efecto de reproducción y otros pasos, y en el Al mismo tiempo, al configurar las claves de caché, hemos agregado la opción de seleccionar muestras de grabación para analizar y generar opciones recomendadas, similares a las siguientes:

Ideas
El modelo de mensaje agrega capacidades de representación personalizadas al front-end en diferentes escenarios, es decir, plantillas de representación de escenas, que tienen principalmente las siguientes capacidades:
-
Recortar (simplificar expresión)
El modelo de mensaje es un modelo general y grande, y cuando se especializa en un escenario específico, a menudo no se requieren todas las configuraciones, por lo que se adapta en consecuencia para formar un subconjunto bajo demanda.
-
Nivelación (degradación, simplificación de expresión)
Aplane los datos estructurados json del modelo de mensaje y utilícelos como el nombre del campo del formulario para formar una estructura de datos que sea fácil de representar en el formulario de front-end sin utilizar la expresión jerárquica del multicomponente de front-end.
Mapeo (expresión mejorada)
Cada campo del modelo de mensaje tiene un nombre para mostrar concreto y una descripción de visualización en el escenario, así como capacidades de visualización adicionales, lo que facilita la representación frontal según la configuración en diferentes escenarios.
Como arriba, el contenido de String se asigna a:
Agrupación y clasificación (expresión modular y estructurada)
Después de nivelar y mapear modelos de mensajes para diferentes escenarios, se pueden agrupar y ordenar para una expresión modular y estructurada.
Como en el ejemplo anterior, varios módulos del modelo de mensaje se convierten en varios módulos del modelo de presentación.
Finalmente se dividió en múltiples formularios y múltiples módulos.
en conclusión
Agregar plantilla de renderizado
Agregue una plantilla de configuración de escenario para configurar cómo procesar el modelo de mensaje en el escenario para formar una plantilla de configuración de front-end separada, que sirve como definición de escenario para configurar el modelo, es decir, completar el corte, aplanamiento, mapeo, agrupación y clasificación. , etc.
Construcción dinámica de páginas: componente front-end y renderizado dinámico
Cree un componente independiente de front-end para cada elemento de configuración de cada componente y realice la representación en bucle de acuerdo con la plantilla de representación
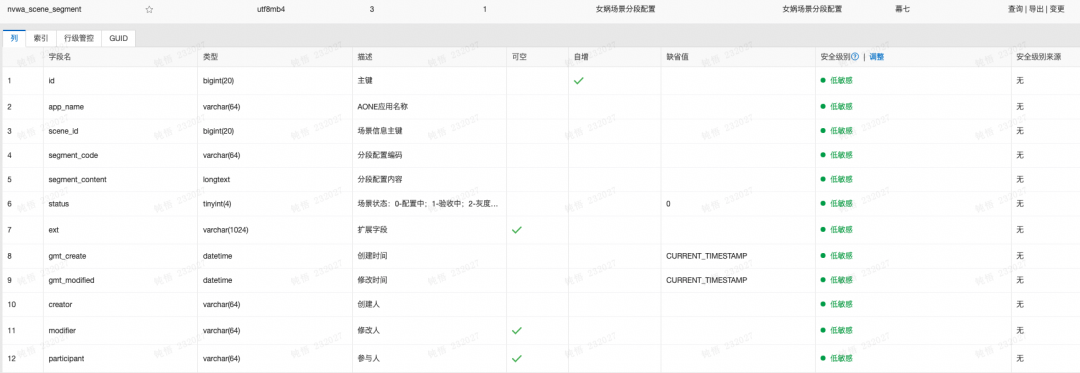
✪ 5.2.3 Modelo de almacenamiento (PO, combinación de mesas horizontales y verticales)
Como se mencionó anteriormente, el objetivo principal del modelo de almacenamiento de plataforma de herramientas es conservar la configuración y, al mismo tiempo, facilitar la conversión a un modelo de configuración de visualización y un modelo de mensaje de dominio. En principio, no está orientado al usuario ni es un complemento. orientado hacia dentro.
desafío
La esencia del almacenamiento es almacenar las configuraciones de la solución en diferentes escenarios de aplicaciones del complemento Nuwa, por lo que la clave principal de la configuración es el escenario y la configuración bajo el escenario es la solución. Diferentes escenarios requieren elementos de configuración muy diferentes.
Parados en el modelo de visualización, podemos configurarlo en pasos, por lo que el plan se puede dividir en varios pasos y luego la información del campo del formulario debajo de ese paso.

En cuanto al modelo de mensaje, nuestro modelo de mensaje para la misma solución consta de varios componentes, y cada componente tiene varias informaciones de campos de formulario.

¿Se almacena para mensajes o para visualización? ¿Cómo almacenar los cuatro tipos de información anteriores? ¿Hay cuatro tablas para los cuatro tipos de información? Al parecer las cosas no fueron tan difíciles.
Ideas
Almacenamiento para configuración
La relación más cercana entre el almacenamiento es la adición, eliminación, modificación y consulta, especialmente en los sistemas de configuración. El almacenamiento es el portador de la configuración y el modelo de almacenamiento a mensaje es solo una transacción única. Por lo tanto, según el grado de acoplamiento, el almacenamiento debe basarse en la configuración.
Configurar para escenarios
Como se mencionó anteriormente, 1 complemento + 1 punto de corte = 1 escena. La escena es un desencadenador de acción + objetivo. La escena en sí contiene menos información. Es solo la combinación de aplicación del punto de corte y el complemento, y Se le adjuntan varias soluciones. El plan existe. La descripción específica y el tiempo efectivo son el contenido, por lo que el cuerpo principal del modelo de almacenamiento puede elegir una solución, y una escena es solo una agregación de puntos de corte y soluciones complementarias.

La tabla vertical almacena información de pasos diferenciada para cada escenario.
Un plan tiene una configuración de múltiples pasos, los cuales pueden ser guardados en secciones o en su totalidad para el usuario, cada operación del usuario está asociada al almacenamiento de datos uno por uno, por lo que el contenido de cada paso se almacena en el campo JSON de la tabla vertical y los pasos. El código único y la identificación del esquema se componen de la clave única conjunta de la tabla vertical.
en conclusión
La unificación del modelo es una base importante para la estabilidad del sistema y la reducción de la carga de trabajo.
5.3 Unificación de procesos
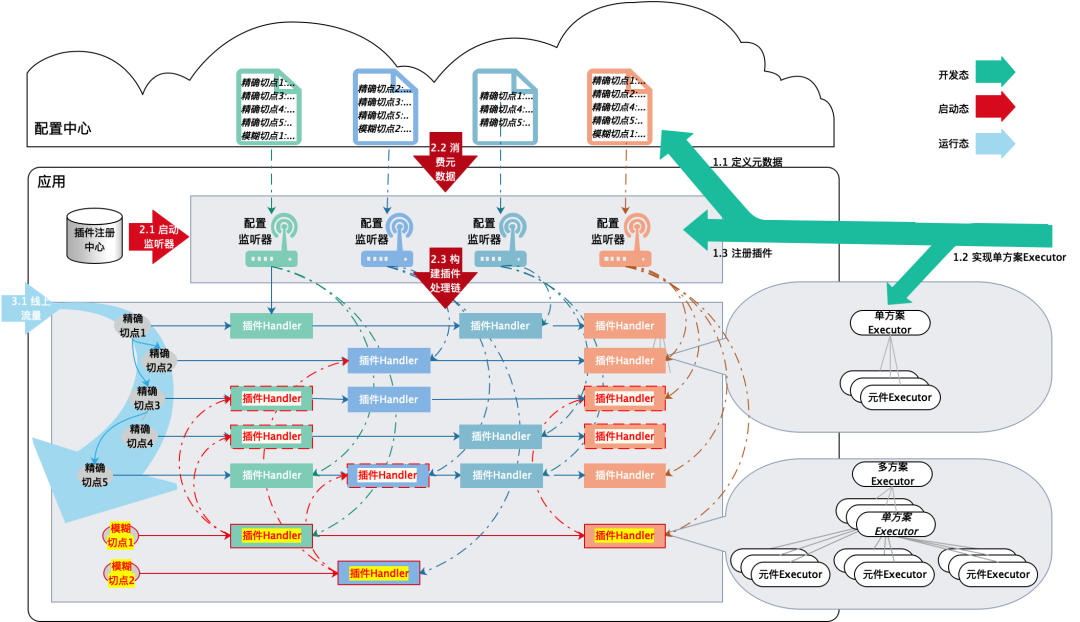
✪ 5.3.1 Desarrollo y registro de complementos (proceso de desarrollo)
Desarrollar un único ejecutor de complemento, definir la información del archivo de configuración del complemento y registrar el complemento en el centro de complementos.
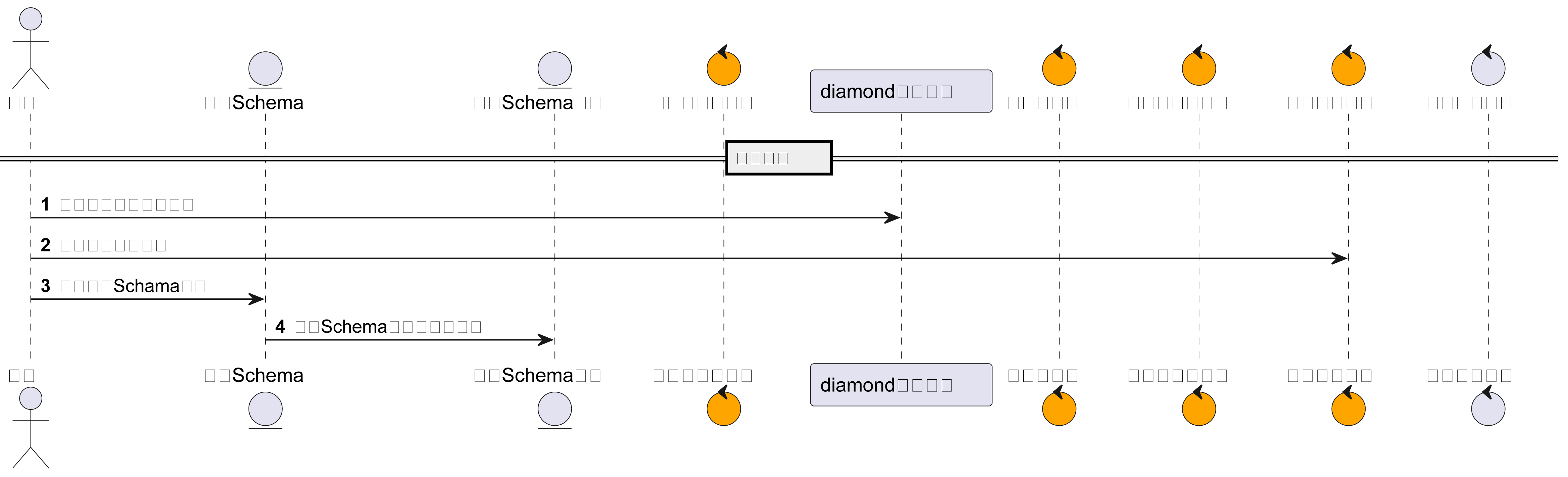
1. Defina la información del archivo de configuración del complemento (las convenciones son mayores que las especificaciones):
En última instancia, el mensaje debe almacenarse en el diamante, y el diamante está diseñado de la siguiente manera:
-
grupo de datos: alsc-nvwa
-
ID de datos:nvwa.{pluginCode}.conf.{appName}
-
Aplicación de atribución: Aplicación de atribución correspondiente al punto de corte de la escena
-
Contenido: un complemento para una aplicación corresponde a una configuración de diamante, con el punto de corte como clave del contenido del diamante y la lista de definición de solución como valor.
2. Implementación del ejecutor de la solución de complemento
Defina una interfaz Ejecutor unificada y los métodos a implementar son los siguientes:
-
preHandle: preprocesamiento, este método se llamará antes de que el complemento procese el siguiente nodo.
-
afterHandle: posprocesamiento, este método se llamará después de que el complemento procese el siguiente nodo.
-
alrededor: procesamiento envolvente, procesamiento manual, procesamiento previo y posterior al llamar al siguiente nodo según sus propias necesidades
3. Definir el esquema del complemento y el registro del complemento (una línea de código)
Simplemente agregue una instancia de esquema de complemento en com.alsc.content.sdk.nvwa3.schema.PluginSchemas#allPluginSchema. Los parámetros del constructor de PluginSchema se definen de la siguiente manera:
-
Codificación de complemento
-
Nombre del complemento
-
Clase de procesamiento de complemento
-
Ejecutor de plan único
-
Ejecutor del plan por lotes
✪ 5.3.2 Precarga y orquestación de complementos (proceso de inicio y carga en caliente)
Precarga y orquestación de complementos

Los cambios en varias soluciones en varios escenarios de configuración serán monitoreados y procesados por el módulo de configuración de Nuwa.
-
Cree un oyente de configuración: lógica general, no se requiere código adicional, Diamond escucha de manera uniforme y genera un ConfigHolder;
-
Construcción del controlador del complemento: lógica universal, no se requiere código adicional, MethodAspectHandlerRegistry.modifyHandler inserta el controlador del complemento en la posición correspondiente de la lista vinculada, lo que implica puntos de corte precisos y puntos de corte difusos;
-
Construcción de Scheme Executor: lógica común, no se requiere código adicional.
✪ 5.3.3 Solicitar proxy dinámico (ejecutar proceso de procesamiento)
Proceso de procesamiento del agente (AOP)
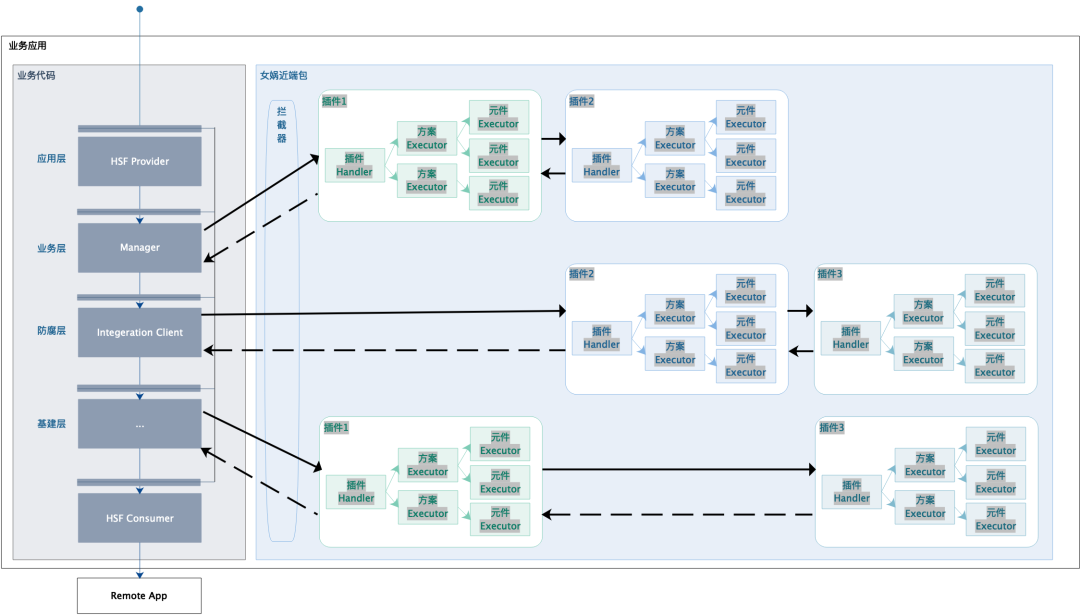
-
Entrada de tráfico: inicialización de ConfigurationAspect (Spring Aspect)
Nuwa proporciona de manera uniforme ConfigurationAspect para la interceptación del tráfico y se realiza el registro manual cuando se introduce Nuwa;
-
Ejecución del agente: llamada ConfigurationAspect
Llame a la cadena de procesamiento del complemento para ejecutar el plan de negocios, es decir, llame a MethodAspectHandlerRegistry.getHandler (methodReference), busque la cadena de procesamiento del complemento;
-
Ejecución del complemento: NvWaPlugin;
-
Ejecución del Plan Ejecutor: como GraySolutionExecutor;
-
Ejecución del Ejecutor de componentes: como LimitAndRateExecutor.
✪ 5.3.4 Proceso de llamada generalizado (proceso SPI)
Servicio SPI para uso de consola: la configuración solo es necesaria cuando se inicializa la aplicación de consola (com.alsc.content.sdk.nvwa.service.NvWaOpsSpiService)
Llamada generalizada orientada al corte de puntos al servicio SPI: a través de llamadas generalizadas, cualquier método interno de corte se puede descomprimir para llamadas externas: ( com.alsc.content.sdk.outer.user.service.**) Implementación específica ligeramente
✪ 5.3.5 Máquina de estados y proceso de liberación (proceso de configuración)
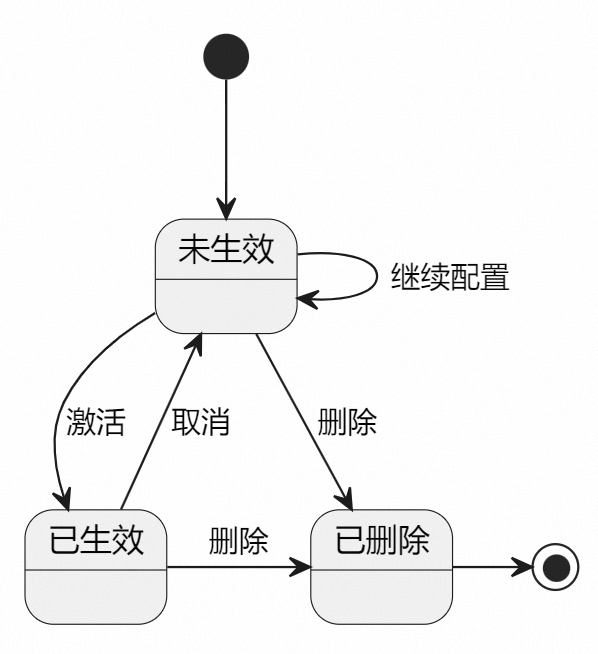
máquina estatal
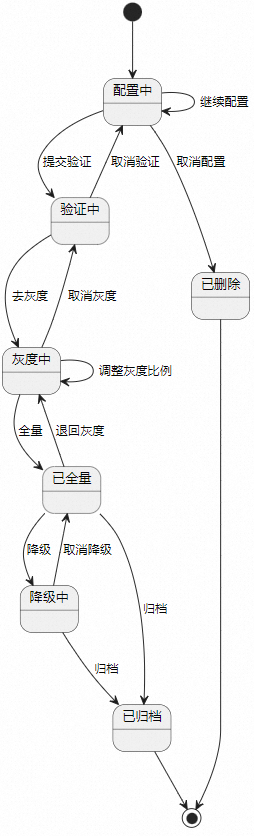
control de versiones

La misma configuración de solución se distingue en diferentes entornos por etiquetas de versión y entorno.
-
Los estándares ambientales del plan son: DIARIO/PROD/PRE
-
En cuanto a la versión de la solución, solo se mantiene una versión diaria y previa al lanzamiento. Mantener múltiples versiones coexistiendo en línea.
-
El prelanzamiento es en línea, si hay diferencias con respecto a la última vez, se generará una nueva versión en línea.
-
Puede elegir directamente cualquier versión en línea para sincronizarla con la versión actual prelanzada.
Proceso de liberación
Solo se puede sincronizar el estado completo de las versiones preliminares y diarias con otros entornos, y no se permiten modificaciones directas de la configuración en línea.
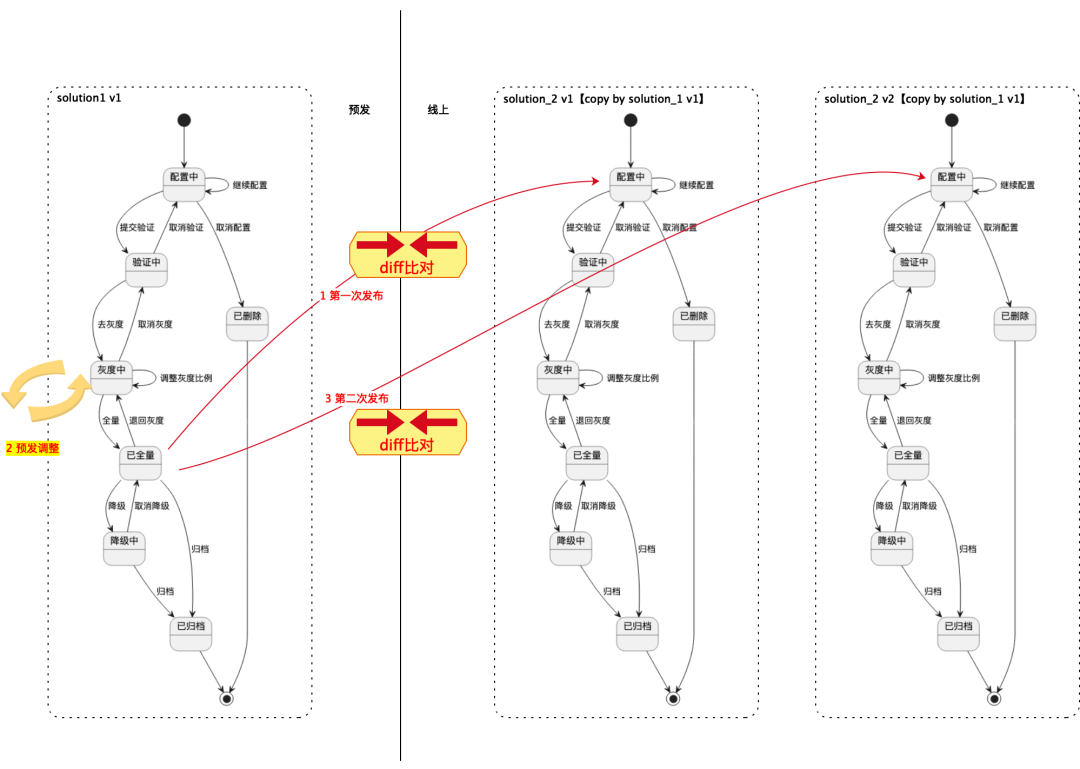
✪ 5.3.6 Proceso de configuración unificada de página (proceso de configuración)
Todos los escenarios cumplen con el siguiente proceso de configuración y los componentes básicamente se reutilizan de varias maneras.
-
Localización de aplicaciones y entornos
A través del banner superior de la aplicación Nuwa, seleccione la aplicación y el entorno que deben operarse esta vez.
![]()
-
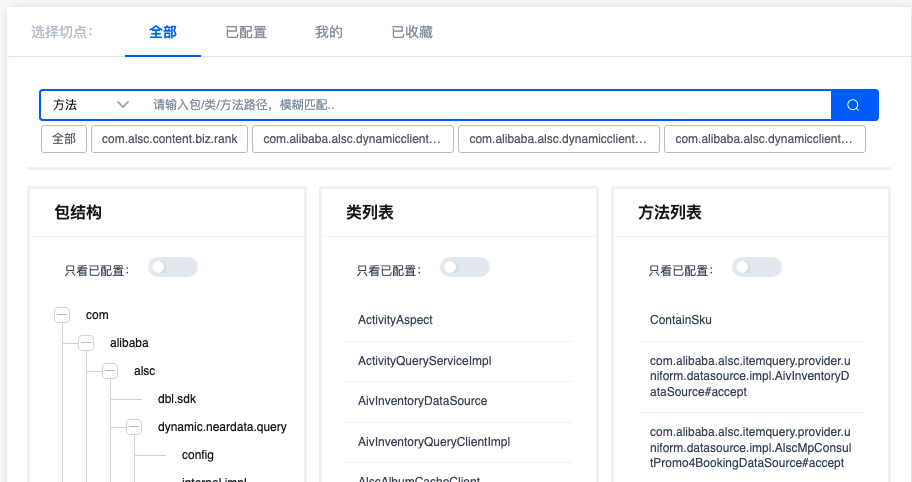
Seleccionar punto de corte
Método 1: estructura del paquete -> lista de clases -> lista de métodos Selección de tres niveles
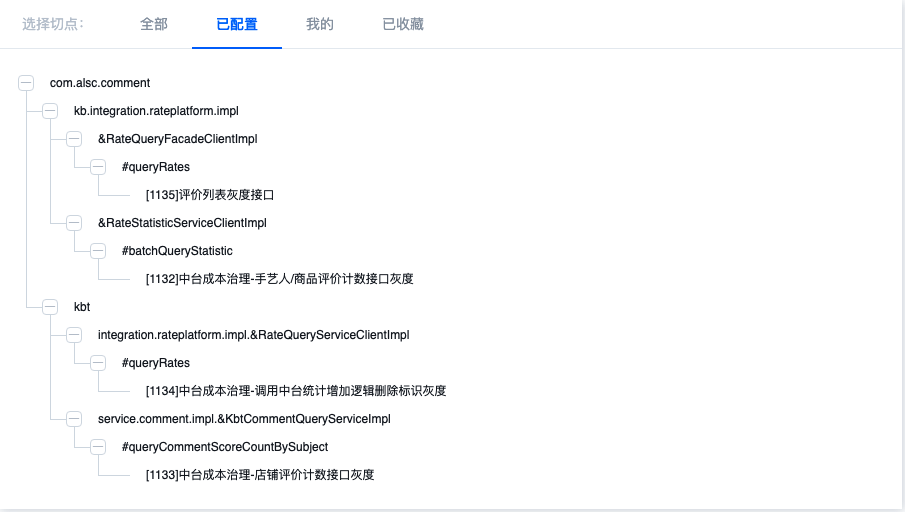
Método 2: selección de todos los árboles configurados
Método 3: otros
-
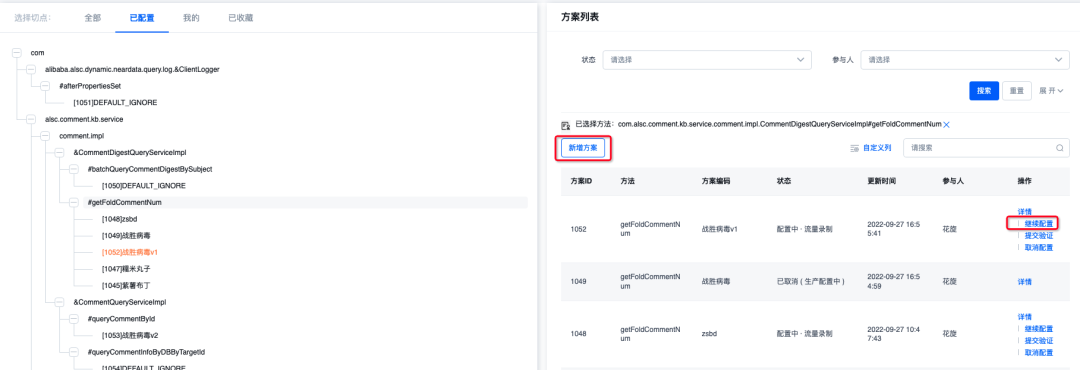
Cree un plan y elija modificarlo
-
Página de configuración y página de detalles
Vaya a la página de configuración y a la página de detalles. La página de configuración y la página de detalles renderizan, muestran, envían y guardan dinámicamente en función de las diferencias de escena (plantilla de renderizado de escena).
-
Barra de acción de publicación y estado unificada
Las operaciones de estado de todos los planos de escena se pueden controlar a través de la barra de operación de la columna del plan para operaciones rápidas.
6. Diseño de puntos clave 2: dos sistemas
-
Diversos complementos: complementos para diversos escenarios de mejora del rendimiento
-
Páginas de soporte: páginas de soporte para varios escenarios de mejora de la eficiencia
6.1 Sistema enchufable Nuwa
El complemento Nuwa utiliza pointcut como organización y perspectiva de llamada, es decir: pointcut -> cadena de complementos -> complemento -> ejecutor de soluciones -> ejecutor de componentes, donde el pointcut corresponde a un método de SpringBean; complemento cadena: pointcut requiere que los agentes dinámicos ejecuten cadenas de procesamiento.
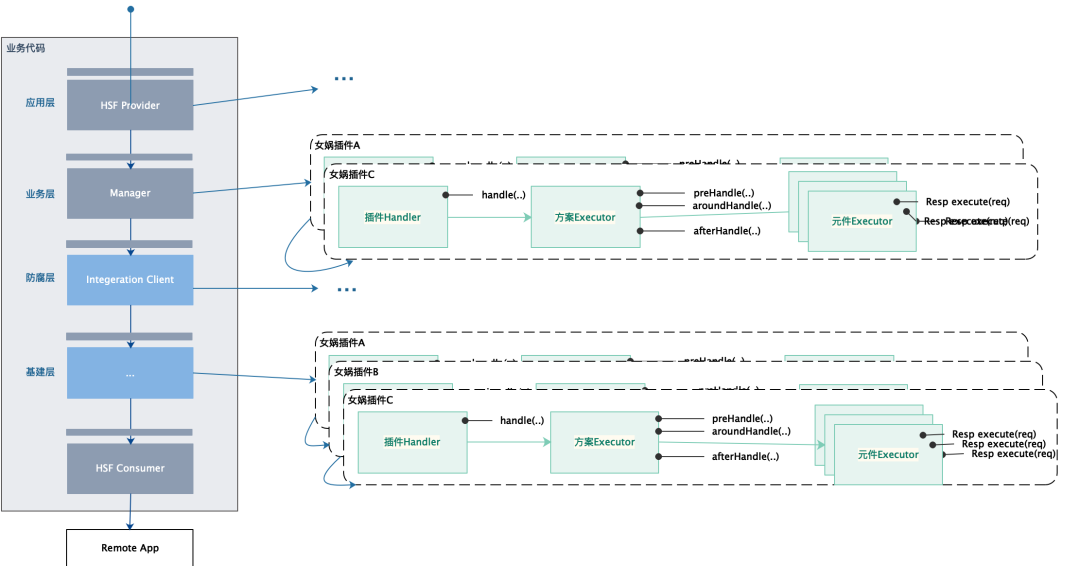
✪ 6.1.1 Controlador de complementos
Un componente de capacidad técnica independiente, la API principal es la siguiente:
-
El identificador de objeto público (contexto MethodHandleContext) lanza Throwable
El sistema proporciona una implementación de complemento general, com.alsc.content.sdk.nvwa3.plugins.NvWaPlugin. Puede utilizar este complemento de forma predeterminada. En casos especiales, también puede consultar la modificación del complemento para implementar un nuevo complemento.
✪ 6.1.2 Ejecutor del esquema
El plan es la lógica real al ejecutar cada plan de complemento y proporciona principalmente las siguientes tres API:
-
PreHandleResult preHandle (contexto MethodHandleContext, complemento NvWaPlugin) lanza Throwable;
-
AfterHandleResult afterHandle (contexto MethodHandleContext, complemento NvWaPlugin, PreHandleResult preHandleResult) lanza Throwable;
-
El objeto predeterminado aroundHandle (contexto MethodHandleContext, complemento NvWaPlugin) lanza Throwable。
La solución de complemento puede heredar e implementar la API correspondiente según su propio escenario. Por lo general, no es necesario implementar las tres API, como solo aroundHandle, preHandle + afterHandler o una de preHandle y afterHandler.
✪ 6.1.3 Ejecutor de componentes
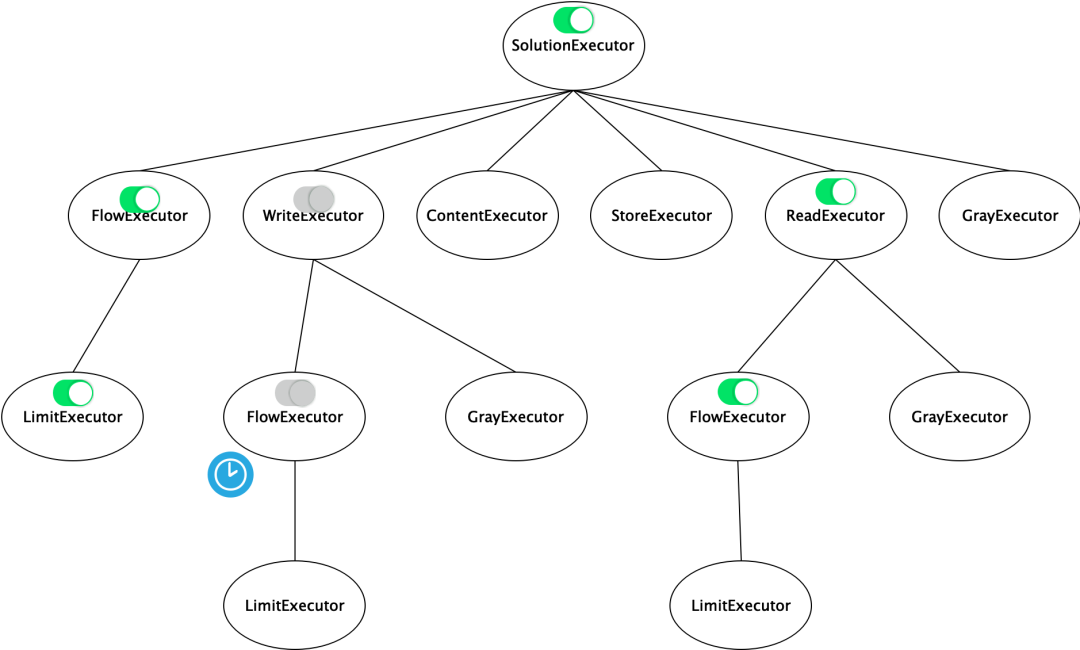
relación de estructura de árbol
El componente es un árbol que contiene relaciones.
Además, los componentes se dividen en componentes del ciclo de vida y componentes que no pertenecen al ciclo de vida. La figura anterior contiene


Los componentes son componentes del ciclo de vida, mientras que lo contrario son componentes del ciclo de vida, donde
Indica que el componente actual no es válido,
Indica que el componente actual es válido,

Representa los componentes del ciclo de vida de fallas y activación de tareas programadas.
Sin componentes del ciclo de vida
No hay ningún componente del ciclo de vida, que está en estado activo por defecto. La interfaz se define de la siguiente manera, con una entrada y una salida.
Hay componentes del ciclo de vida.
Un componente con un ciclo de vida se refiere a un componente con un estado, y el estado tiene su propio ciclo de vida. El estado determina si el componente es efectivo. Al mismo tiempo, la efectividad del componente notificará si el componente anterior es efectivo. a través del "modo observador".
Entre ellas, habrá tareas programadas para activar y desactivar el estado según la configuración de sus propios componentes, como cuando el componente de control de flujo establece la hora de inicio y finalización.
✪ 6.1.4 Contexto Nuwa (comunicación entre complementos)
Dado que el procesamiento de escenarios existentes se vinculará a otros escenarios de puntos de corte, por ejemplo, si nuestro punto de corte A llega a la escena de monitoreo de enlace interno, indica que todos los puntos de corte en la solicitud actual deben imprimir la pila de llamadas, es decir, otros puntos de corte. También es necesario seguir las instrucciones del complemento y se requiere el procesamiento predeterminado. En cuanto a cómo vincularlo, lo conectamos a través del objeto de contexto Nuwa.
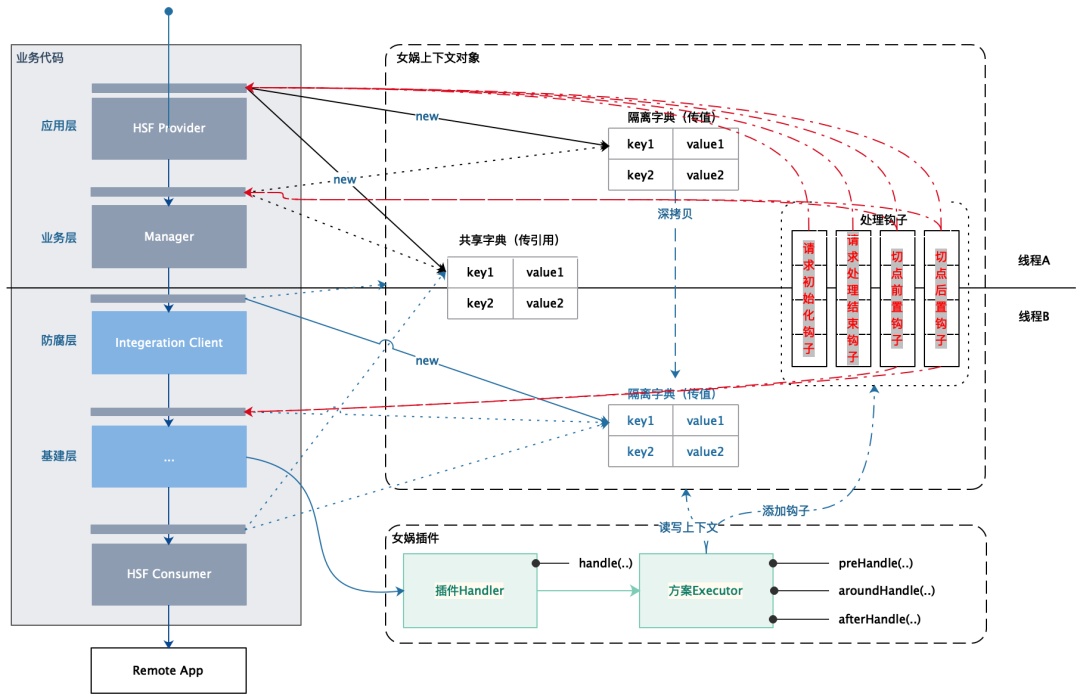
1.Objeto de contexto
El objeto de contexto Nuwa es un objeto contenedor de datos que contiene tres partes: diccionario compartido, diccionario de aislamiento y enlace de procesamiento, y se define de la siguiente manera:
public class NvWaContext {
/**
* 线程上下文
*/
private static ThreadLocal<NvWaContext> contextTL = new ThreadLocal<>();
/**
* 上下文传值数据对象(隔离字典)
*/
private static ThreadLocal<Map<String, Object>> cloneableDataTL = new ThreadLocal<>();
/**
* 上下文数据字典(共享字典)
*/
private Map<String, Object> data;
/**
* 上下文初始化时预加载对象(处理钩子)
*/
private static List<Consumer<NvWaContext>> initializedHooks = new ArrayList<>();
/**
* 上下文初始化时预加载对象(处理钩子)
*/
private static List<AopBeforeConsumer> aopBeforeHooks = new ArrayList<>();
/**
* 上下文初始化时预加载对象(处理钩子)
*/
private static List<AopAfterConsumer> aopHandleAfterHooks = new ArrayList<>();
..
}2. Diccionario compartido y diccionario aislado (intercambio de datos)
El objeto de contexto es esencialmente un objeto contenedor de datos mantenido a través de una variable de subproceso. Cuando sea necesario, se puede obtener y utilizar directamente a través de la variable de subproceso sin pasar explícitamente el objeto a través de los parámetros de la pila de llamadas.
Al mismo tiempo, los objetos de contexto generalmente almacenan algunos datos comunes que varios subprocesos deben compartir antes, por lo que los objetos de contexto deben transferirse entre subprocesos, y la transferencia se divide en dos nuevos tipos.
pasar por referencia
Cuando ejecutamos una nueva tarea de subproceso, asignamos el objeto de subproceso principal al objeto de subproceso del nuevo subproceso. Cuando el contexto Nuwa se pasa en el subproceso, se pasa por referencia de forma predeterminada, lo que reduce aún más la sobrecarga del objeto. .
Todos los datos del [Diccionario compartido] en Nuwa se pasan por referencia de forma predeterminada.
Pasar por valor
Sin embargo, en algunos escenarios, como la supervisión de enlaces internos, existen problemas de seguridad de subprocesos si se pasan por referencia.
Por ejemplo, cuando necesitamos calcular incrementalmente el spanId en un enlace, si varios subprocesos comparten el contador global SpanId, el SpanId eventualmente se confundirá. En este momento, se necesita un contador SpanId aislado entre subprocesos. El contador SpanId se hereda de el contador SpanId del hilo principal. , pero solo accesible dentro del hilo.
Todos los datos del [Diccionario de aislamiento] en Nuwa se pasan por valor de forma predeterminada.
Si se debe usar un diccionario aislado o un diccionario compartido depende de si los datos que se almacenarán son un valor o una variable. Si es una variable y hay problemas de seguridad de subprocesos, use la transferencia de valor; de lo contrario, use la transferencia de referencia.
Ya sea la transferencia de referencia de un diccionario compartido o la transferencia de valor de un diccionario aislado, los tres métodos estáticos de NvWaContext se empaquetan, extraen, transfieren y limpian respectivamente.
3. Ganchos de contexto (intervención entre complementos)
Cuando la ejecución del complemento de Nuwa requiere comunicación entre los puntos de corte, o cuando se realizan todos los puntos de corte y el procesamiento predeterminado global, Nuwa abre los siguientes dos niveles de enlaces para que el complemento implemente la implementación del enlace:
[Nivel de solicitud] Gancho
Los enlaces de procesamiento al ingresar a la aplicación, incluidos los enlaces de inicialización y finalización del procesamiento, como List<Consumer<NvWaContext>>inicializedHooks, se ejecutarán una vez cuando se inicialice el contexto de Nuwa. Si se activa el complemento de monitoreo de enlaces internos, debe agregar un objeto de contexto de monitoreo de enlaces e inicializarlo al ingresar, similar a lo siguiente:
NvWaContext.addInitializedHook(nvWaContext -> {
NvWaContext.currentContext().addCloneableInstance(TraceSpanId.NV_WA_CONTEXT_TRACE_SPAN_ID, new TraceSpanId());
TraceSolutionExecutor.initRecordingTraceInfoIfNecessary(
nvWaContext.getEntryMethodReference(), nvWaContext.getEntryStartTime());
});【Nivel de corte de punto】Gancho
Los enlaces durante cada procesamiento de punto de corte, a saber, List<AopBeforeConsumer> aopBeforeHooks y List<AopAfterConsumer> aopHandleAfterHooks, se procesarán una vez en los enlaces previos y posteriores a ConfigurationAspect respectivamente. Por ejemplo, en el complemento de monitoreo de enlaces internos, será procesado al final del procesamiento de corte de punta. Continúe enterrando la punta.
NvWaContext.addAopHandleBeforeHooks((methodReference, startMills, isInitialed) -> {
TraceSpanId spanId = NvWaTraceContext.getSpanId();
if(!isInitialed) {
spanId.enter();
}
});
NvWaContext.addAopHandleAfterHooks((methodReference, method, args, result, e, startMills, isInitialed, context) -> {
try {
TraceSolutionExecutor.recordingTraceInfoIfNecessary(methodReference, method, args, result, e, startMills, context);
} finally {
NvWaTraceContext.getSpanId().exit();
}
});6.2 Sistema de páginas
Cuando desarrollamos un complemento, normalmente necesitamos hacer lo siguiente:
-
Desarrollar código relacionado con complementos;
-
Cree una página de configuración de escena de complemento;
-
Cree una página de herramientas para admitir escenarios de complemento (como un escenario de monitoreo de enlaces internos, necesitamos una página de análisis de enlaces internos: puede ingresar un seguimiento para ver la información de llamada del enlace);
-
Cree un complemento para ejecutar la página de detección de estado (monitoreo y alarmas);
-
Cree un informe de datos de recuperación de efectos comerciales para la operación del complemento.
Por ejemplo:
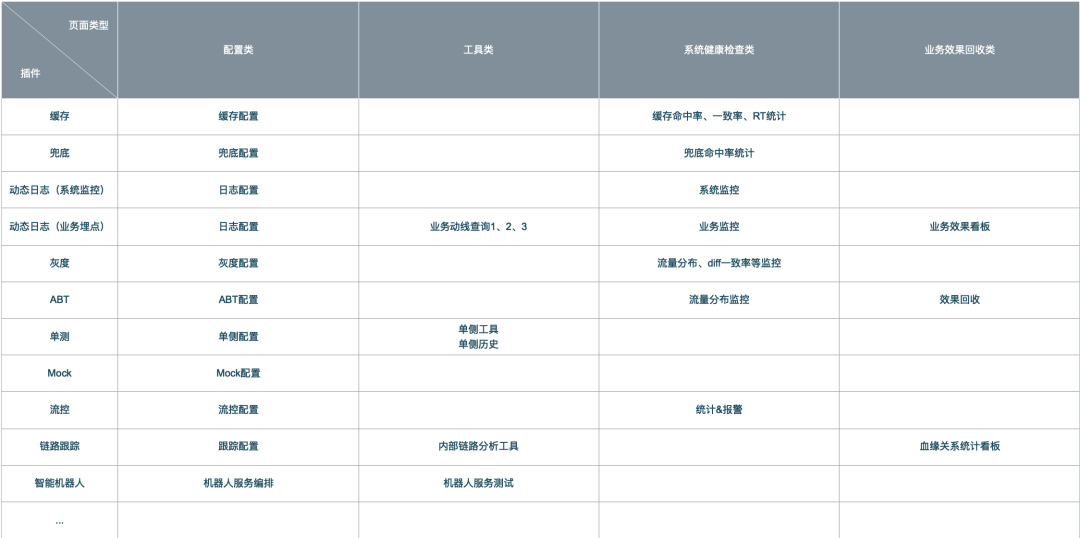
Anteriormente, resolvimos el problema de la chimenea de la implementación de back-end mediante "unificación de modelos" + "unificación de procesos" + "sistema de complementos", pero ¿cómo se puede admitir de manera eficiente la página de inicio?
Para las cuatro categorías principales de páginas, clasifique "cambiar" y "sin cambios" e intente reutilizar las plataformas existentes o los componentes existentes de la plataforma, incluidos:
-
Utilice Lego 3.0 para la página de configuración y el desarrollo de la página de herramientas de soporte
-
El efecto de verificación de estado del complemento es compatible con la configuración de Sunfire y eventualmente se integra en Nuwa
-
Los datos del efecto de los datos comerciales son configurados y desarrollados de forma independiente por el FBI y finalmente se integran en Nuwa.
✪ 6.2.1 Acceso a aplicaciones detalladas de Lego 3.0
LEGO 3.0 es una plataforma de desarrollo de código bajo dentro del grupo.
1. Implementación independiente de Lego
Teniendo en cuenta que las aplicaciones de Lego se implementan centralmente en la plataforma Lego y que la interfaz http/mtop del servidor pertenece a un nombre de dominio diferente y no se puede llamar directamente, la forma más efectiva o menos intrusiva de llamar a Lego es implementarlo integrado con Spring Web. solicitud.
2. Representación personalizada de la barra de navegación.
Como configuración global, incluye la selección de aplicaciones y la selección de entorno. Después de la selección, el siguiente salto hereda la selección, lo que facilita la continuidad de las operaciones de varios pasos. El rango de selección de aplicaciones es la aplicación para la que tiene permisos AONE. El acceso a Nuwa es opcional Si no estás conectado, Nuwa puso las cenizas.

3. Página de lista de configuración unificada
Todas las páginas deben intentar tener un estilo unificado, un proceso unificado e incluso reutilizarse. Para obtener más detalles, consulte la introducción de "Plantilla de configuración unificada de página (proceso de configuración)", especialmente la página de configuración. Debido a la unificación del modelo, la reutilización de la página de configuración es posible.
Hay un menú de configuración para cada complemento y la página de lista de administración de configuración del complemento correspondiente al menú. Todos los complementos reutilizan la página de lista de administración de configuración.
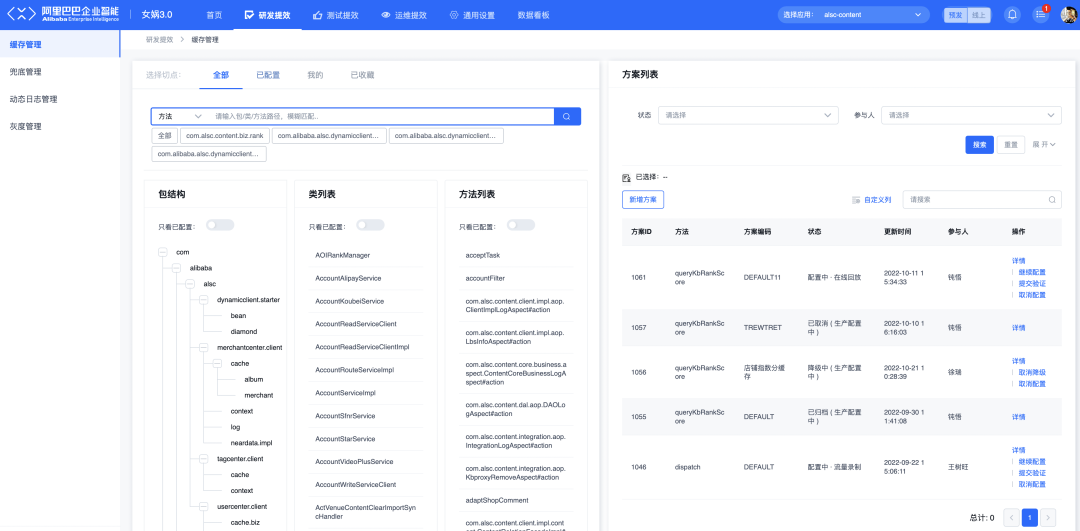
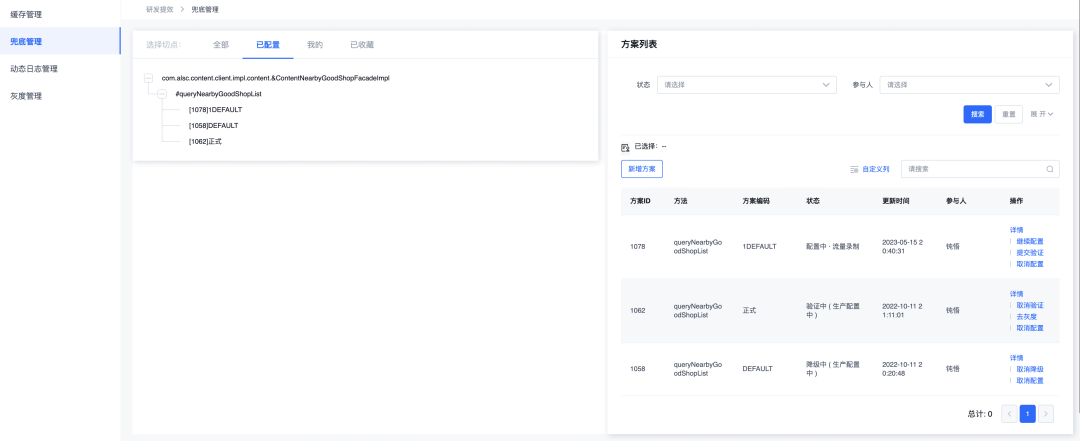
Los componentes, eventos y estilos de la página cuentan con todos los servicios. Los diferentes complementos solo tienen las siguientes diferencias de configuración en la página:
Los enlaces de las páginas son diferentes.
Los enlaces URL de esta página son diferentes, pero todos llevan el nombre de "{plugin code}_list"
Los elementos de configuración global de la página son diferentes.
-
El tipo de negocio del servidor de llamadas del complemento es diferente: {código de complemento}
-
El complemento salta a la página de configuración y los enlaces a la página de detalles son diferentes. Por ejemplo, el salto a la página de configuración se llama "{código de complemento}_cfg".
-
¿Es posible configurar diferentes configuraciones para puntos de corte difusos?
Los metadatos de configuración son los siguientes:
{
"businessType":"cache",
"cpLikeMatch": false,
"solutionSlug":"mock_cfg"
}Los botones de operación son diferentes.
Las opciones de operación de los elementos de configuración de la lista son diferentes. Las máquinas de estado correspondientes a diferentes elementos de configuración del complemento están controladas por la plantilla de representación del lado del servidor. Por ejemplo, el diagrama de estado de Mock es el siguiente:
-
El alias "Configurando" de la máquina de estados se ajusta a: no efectivo
-
El alias "completo" de la máquina de estados se ha ajustado a: efectivo
-
La máquina de estados ha sido podada.
4. Página de configuración renderizada dinámicamente
Según la plantilla de configuración de escena mencionada anteriormente, se realiza la representación de formularios dinámicos, es decir, utilizando el controlador del modelo de configuración.
Mantener la biblioteca de componentes de elementos de configuración de elementos
En referencia al diseño de componentes del modelo de mensaje, hay más de 10 componentes en el sistema de la siguiente manera. Cada componente tiene sus propios elementos de configuración. El sistema tiene un total de aproximadamente 100 elementos de configuración con el número de componentes * el número de elementos de configuración de componentes. La visualización frontal se realiza en última instancia a través de la representación de la escena: la plantilla "corta" + "aplana" + "mapea" + "agrupa y clasifica" el modelo de mensaje para formar un modelo de configuración especializado para cada escenario.
Entre ellos, los elementos de configuración de cada componente son independientes, relativamente claros y sin cambios; mientras que los elementos de configuración y alias en diferentes escenarios son dinámicos y cambiantes, en LEGO 3.0, cada elemento de configuración del componente se convertirá en una interfaz. componente.
El mismo componente de elemento de configuración de elemento en diferentes escenarios:
Mismo punto:
-
estilo unificado
-
evento unificado
diferencia:
-
Diferentes alias y descripciones.
-
Diferentes módulos de edición y secuencias de edición.
La extracción es la siguiente:
Corresponden a las siguientes piezas de la caja roja:
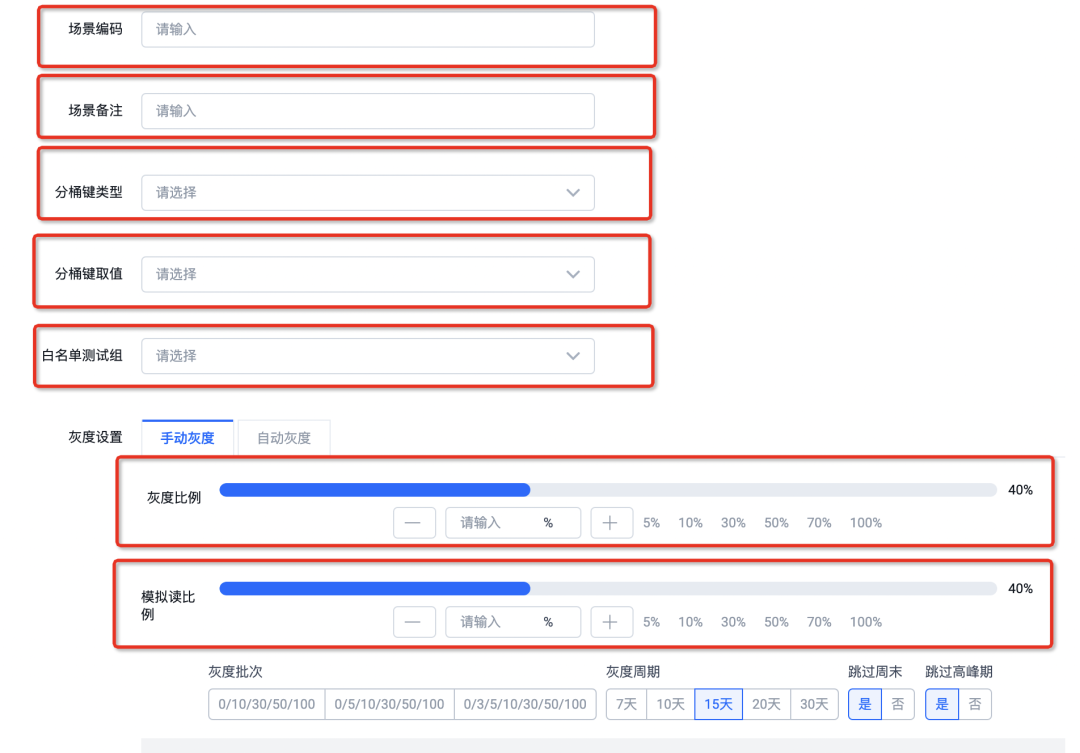
Utilice la representación en bucle para la representación dinámica de formularios
Lego 3.0 no es muy amigable para el soporte de renderizado dinámico. Aquí, cada componente del elemento de configuración del componente solo se puede colocar en un contenedor de bucle (x1, x2, x3 ...), y luego todos los contenedores de bucle del componente del elemento de configuración del componente se pueden colocar en mosaico. en uno En el contenedor de bucle más grande y, el servidor procesa la plantilla de renderizado en la siguiente estructura:
{
"code": [{
"title":"场景编码",
"desc":"同一个场景同一个方案编码唯一"
}],
"remark": [{
"title":"场景备注",
"desc":"场景备注仅为便于识别作用,无逻辑依赖处理"
}],
"matchExpr_items": [{
"title":"场景条件",
"desc":"无条件或者命中条件时配置才生效"
}],
...
}Luego recorra los elementos de configuración de la plantilla de representación de escena, suponiendo que hay n elementos, y renderice el contenedor de bucle yn veces; cada vez que se renderice el contenedor de bucle y, solo el contenedor de bucle x correspondiente al elemento de configuración con el mismo nombre de La plantilla de representación se representa una vez y otros contenedores de bucle x no se representan.
5. Página de herramientas personalizada
Dado que las diferentes herramientas de soporte de complementos tienen diferentes características y funciones, las plantillas y componentes no se pueden extraer de manera uniforme. Aquí, se utilizan directamente las capacidades de creación de páginas de Lego 3 y el servidor proporciona las interfaces relevantes según sea necesario.
Por ejemplo, la página de análisis de enlaces internos es diferente de otras páginas:
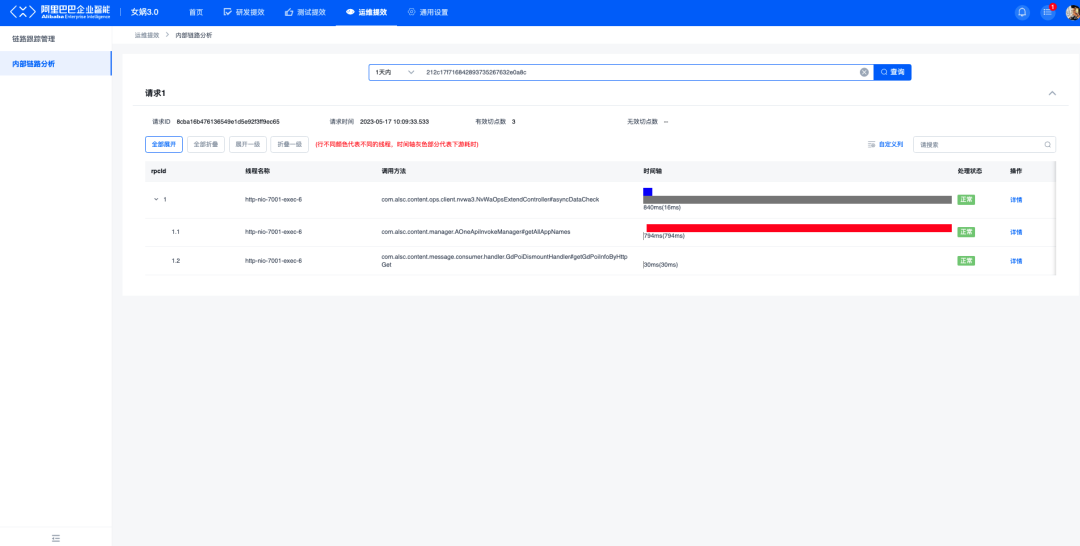
✪ 6.2.2 Acceder a BUC&ACL&AONE para autenticación de autoridad
-
Inicio de sesión de BUC: BUC es un servicio de inicio de sesión de usuario dentro del grupo. La autenticación de BUC existe de forma predeterminada para la implementación centralizada de Lego. Sin embargo, después de una implementación independiente, el BUC de Lego no puede surtir efecto debido a cambios en el nombre de dominio y el mecanismo operativo, por lo que debe solicitarlo. acceso manual por su cuenta;
-
Autenticación de permisos ACL: ACL es un servicio de reconocimiento de permisos que configura permisos de funciones y permisos de datos;
-
Autenticación de permisos de datos AONE: AONE es un servicio de administración de aplicaciones que realiza una autenticación integral de permisos de datos;
-
Extracción de información de corte de puntos de Nuwa Ops Spi: representación de página e indicaciones de operación.
✪ 6.2.3 Interfaces universales y personalizadas del lado del servidor
Banner superior (universal)
-
Interfaz de consulta de lista de aplicaciones
Página de lista de gestión de planes (general)
-
Interfaz de búsqueda de puntos
-
Interfaz del directorio del paquete Pointcut
-
Interfaz de lista de clases de Pointcut
-
Interfaz de lista de métodos de Pointcut
-
Interfaz de recuperación de planes
-
Interfaz del árbol de configuración del esquema
-
Interfaz del árbol de recopilación de soluciones
-
Interfaz de mi árbol de proyectos
-
Interfaz de modificación del estado del plan
Página de configuración de la solución (general)
-
Interfaz de inicialización
-
Interfaz de envío paso a paso
Página de herramientas (personalizada)
-
Desarrollo bajo demanda
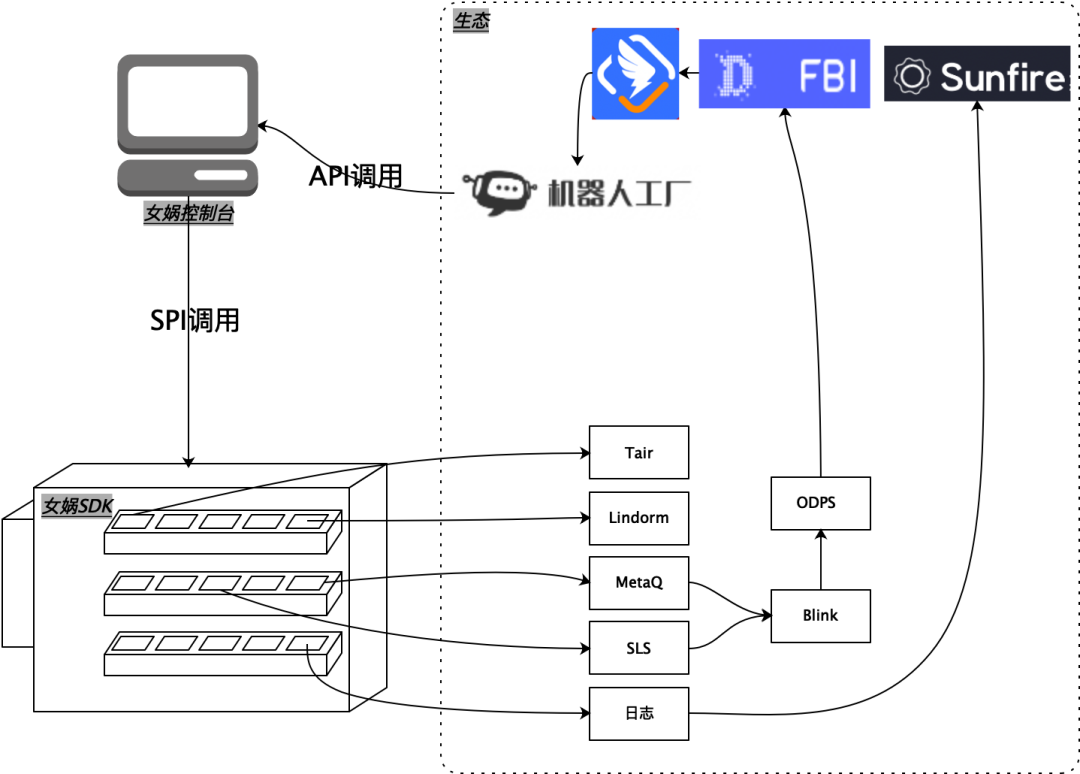
7. Diseño de puntos clave 3: una ecología
-
Ecología rica : herramientas de almacenamiento y divulgación correspondientes para diversos escenarios de mejora de la eficiencia
7.1 Modo puente de fuente de datos (RDB, caché...)
Las fuentes de datos correspondientes a la lectura y escritura de Nuwa incluyen SLS, Lindorm, Tair, Mysql, File y otros tipos de fuentes de datos.
Al mismo tiempo, el mismo tipo de fuente de datos es multiinquilino y administrado por múltiples instancias, y se puede seleccionar según sea necesario para diferentes escenarios.
-
Configuración de fuente de datos
Todas las fuentes de datos están configuradas en el diamante, dataId: nvwa.{dataSoureType}.instance.conf, y el elemento de configuración son los metadatos del enlace correspondiente.
-
Implementación de fuente de datos
El módulo de fuente de datos de Nuwa proporciona un modelo de consumo unificado.
-
Aplicaciones de fuente de datos
StoreEngine crea una instancia del motor de almacenamiento.
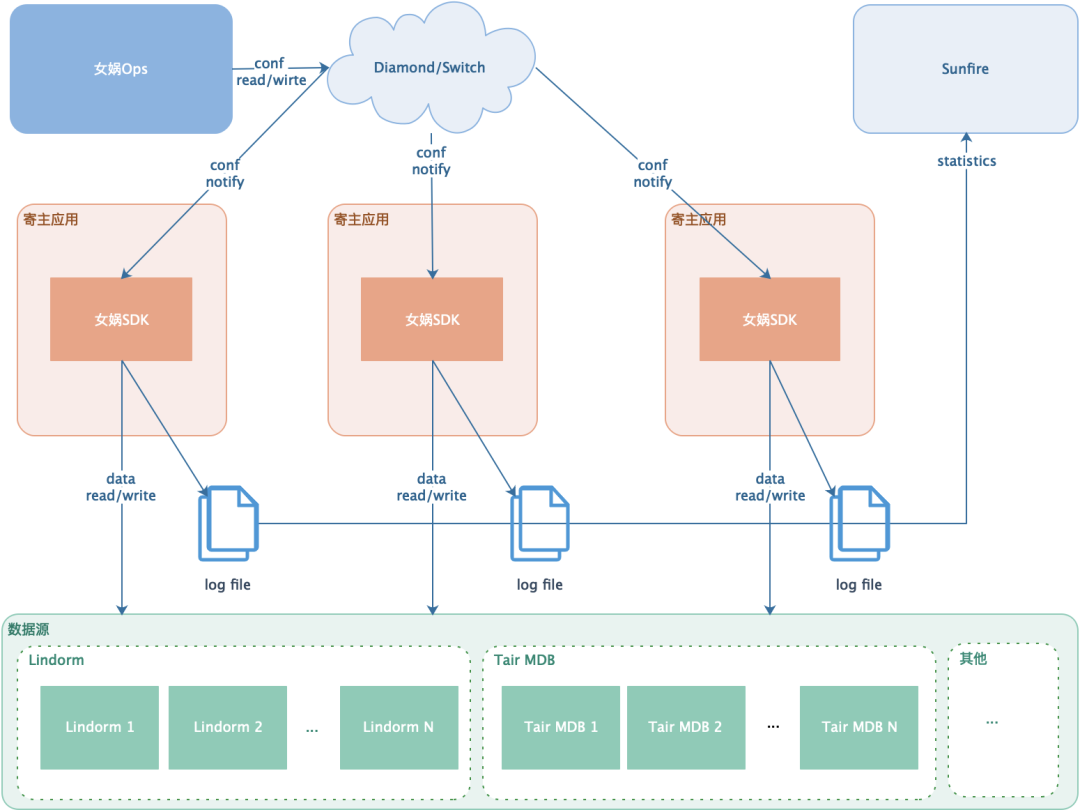
7.2 Abrir el enlace de seguimiento (Sunfire, SLS...)
Nota: Sunfire es el servicio de monitoreo y SLS es el servicio de registro.
Ruta: Nuwa Logger -> Archivo local -> Sunfire, proporciona información de seguimiento de métricas estándar para cada complemento, la imprime en el archivo de registro local y finalmente lo monitorea en Sunfire en un modo común. Se puede personalizar según los diferentes complementos. -ins y es multiinquilino. Uso compartido de enlaces en múltiples escenarios.
7.3 Abrir el enlace de datos (ODPS, FBI...)
Nota: ODPS es un servicio de archivos distribuido (equivalente a HDFS), SLS es un servicio de registro (equivalente al servicio ES en SLK), plataforma informática de transmisión Blink (equivalente a Flink) y servicio de informes visuales del FBI.
Ruta: Nuwa Logger (aplicador personalizado) -> MQ/SLS -> Blink -> Odps -> FBI -> DingTalk, para varias estadísticas en tiempo real y fuera de línea, procesadas a través de canales existentes y finalmente reflejadas en el FBI o empujando el grupo DingTalk , que se puede personalizar según diferentes complementos y compartir enlaces entre múltiples inquilinos y múltiples escenarios.
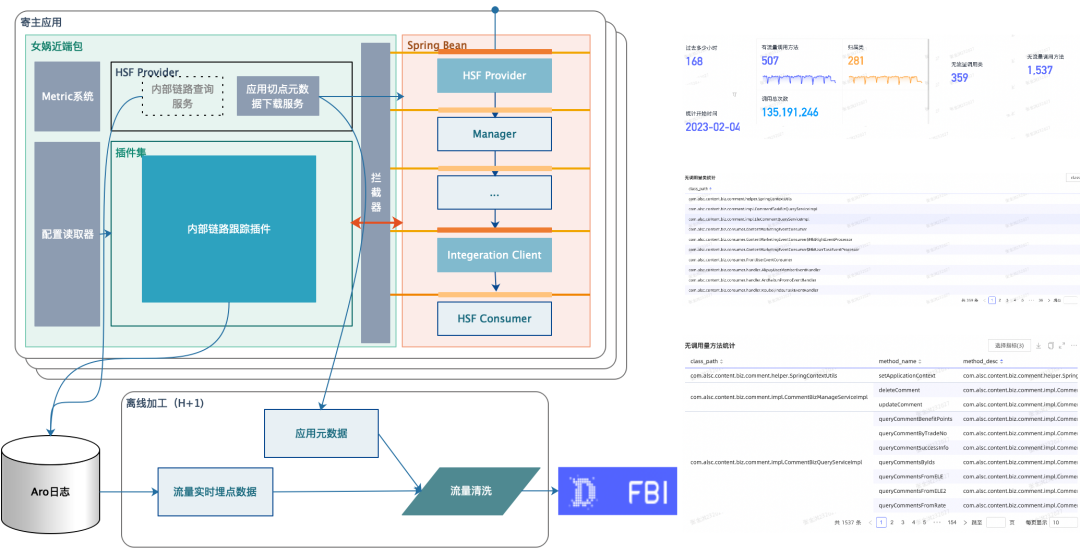
7.4 Abra el enlace de solución de problemas (Robet, DingDing...)
Ruta: DingTalk Robot -> Robot Factory -> Nuwa Console API -> Nuwa SPI, que analiza enlaces para detectar diversos problemas en la operación y el mantenimiento diarios y completa el ensamblaje estructurado y la salida de información a través de llamadas generalizadas y arreglos de datos. personalizado según diferentes complementos y uso compartido de enlaces entre múltiples inquilinos y múltiples escenarios.