数学的問題を解決する言語モデルの能力が再びアップグレードされました。
現在、大規模言語モデル (LLM) は、NLP 分野のさまざまな下流タスクの処理において優れた機能を示しています。特に、GPT-4 や ChatGPT などの先駆的なモデルは、大量のテキスト データでトレーニングされており、強力なテキスト理解および生成機能、一貫性のあるコンテキスト依存の応答を生成する機能、およびさまざまな NLP タスクにおける高い汎用性を備えています。セックス。
ただし、数学的推論における LLM のパフォーマンスは満足のいくものではありません。LLM では、複雑な算術演算、特に 8 桁を超える数値の乗算を含む演算や、小数や分数を含む演算を正確に実行することは困難です。
これに基づいて、清華大学、TAL AI Lab、Zhipu AI の研究者は共同で、複雑な算術演算を完全に実行できる新しいモデル MathGLM を提案しました。GPT-4 よりも優れた 20 億パラメータ モデルは、算術問題をほぼ 100% の精度で実行できます。
-
論文アドレス: https://arxiv.org/pdf/2309.03241v2.pdf
-
プロジェクトアドレス: https://github.com/THUDM/MathGLM#arithmetic-tasks
この研究は、十分なトレーニング データがあれば、20 億パラメータの言語モデルがデータ漏洩なくほぼ 100% の精度でマルチビット算術演算を正確に実行できることを示しています。この結果は GPT-4 を大幅に上回ります (マルチビット乗算精度はわずか 4.3%)。
この論文では、数学的推論における LLM の効率を調査するために、MathGLM という名前のモデルを提案します。
MathGLM モデルが完了する必要がある算術タスクは、基本的な算術演算と複雑な混合演算の 2 つのカテゴリに大別できます。基本的な算術演算には、2 つの数値の単純な計算を中心とした基本的な数学的タスクが含まれます。一方、複雑な混合演算には、さまざまな算術演算と数値形式 (整数、小数、分数など) の組み合わせが含まれます。表 1 は、MathGLM タスクの分類を示しています。 MathGLM の算術機能を強化するために、この論文では Transformer ベースのデコーダ専用アーキテクチャを採用し、自己回帰目標を使用して、生成された算術データ セットで最初からトレーニングします。
MathGLM の算術機能を強化するために、この論文では Transformer ベースのデコーダ専用アーキテクチャを採用し、自己回帰目標を使用して、生成された算術データ セットで最初からトレーニングします。
算数タスクの学習
算術トレーニング データ セットは、加算、減算、乗算、除算、累乗などのさまざまな演算を含むように慎重に設計されています。さらに、整数、小数、パーセント、分数、負の数などの複数の数値形式も含まれています。データセットのサイズは、100 万レコードから 5,000 万レコードまでさまざまです。
各データセットの単一の算術式は 2 ~ 10 の演算ステップで構成され、加算 (+)、減算 (-)、乗算 (×)、除算 (/)、累乗 (^ ) などのさまざまな数学演算をカバーします。図 3 は、算術データセットから抽出されたいくつかのトレーニング例を示しています。 表 2 は、それぞれ異なるパラメーター サイズを持つ 4 つの異なるタイプのモデルを含む、さまざまなサイズの MathGLM モデルの概要を示しています。最大のモデル パラメータ量は 2B で、最も強力な容量を持ち、残りのパラメータ量は 500M、100M、最小の 10M パラメータ モデルです。
表 2 は、それぞれ異なるパラメーター サイズを持つ 4 つの異なるタイプのモデルを含む、さまざまなサイズの MathGLM モデルの概要を示しています。最大のモデル パラメータ量は 2B で、最も強力な容量を持ち、残りのパラメータ量は 500M、100M、最小の 10M パラメータ モデルです。 応用数学の問題の研究
応用数学の問題の研究
この記事では、算術タスクに加えて、数学的アプリケーションの問題を解決するために、一般言語モデル (GLM、一般言語モデル) とそのチャット バージョンと呼ばれる一連の Transformer ベースの言語モデルもトレーニング (微調整) しました。トレーニング プロセスでは、中国の小学校数学の 210,000 問を含む公開中国 Ape210K データ セットが使用され、各質問の答えが直接計算されます。
数学の文章問題における MathGLM のパフォーマンスを向上させるために、この論文では、Ape210K データセットを再構築し、各数学問題の答えを段階的に計算するバージョンに変換する段階的な戦略を採用しています。図 4 は、元の Ape210K データセットとこの記事の再構成バージョンの比較を示しています。 この記事では、MathGLM をトレーニングするためのバックボーンとして、GLM-large、GLM-6B、GLM2-6B、335M パラメーターを備えた GLM-10B などの GLM のさまざまなバリアントを使用します。さらに、この記事では ChatGLM-6B および ChatGLM2-6B バックボーン ネットワークを使用して MathGLM をトレーニングします。これらのバックボーン モデルは、MathGLM に基本的な言語理解機能を提供し、数学的応用問題に含まれる言語情報を効果的に理解できるようにします。
この記事では、MathGLM をトレーニングするためのバックボーンとして、GLM-large、GLM-6B、GLM2-6B、335M パラメーターを備えた GLM-10B などの GLM のさまざまなバリアントを使用します。さらに、この記事では ChatGLM-6B および ChatGLM2-6B バックボーン ネットワークを使用して MathGLM をトレーニングします。これらのバックボーン モデルは、MathGLM に基本的な言語理解機能を提供し、数学的応用問題に含まれる言語情報を効果的に理解できるようにします。
実験
この論文では、算数タスクと数学的文章題を含む 2 つの異なるタイプの実験を設計しました。
算術タスクについては、この論文では 500M パラメーターを使用して Transformer ベースの MathGLM モデルを事前トレーニングし、そのパフォーマンスを GPT-4 や ChatGPT などの主要な大規模言語モデル (LLM) と比較しました。結果を表 3 に示します。MathGLM は他のすべてのモデルよりも優れており、算術タスクの処理において MathGLM が優れたパフォーマンスを備えていることを示しています。
パラメータが 1,000 万個しかない MathGLM-10M であっても、結果は驚くべきものです。MathGLM-10M は、広範囲の包括的な算術タスクにおいて GPT-4 や ChatGPT よりも優れたパフォーマンスを発揮します。 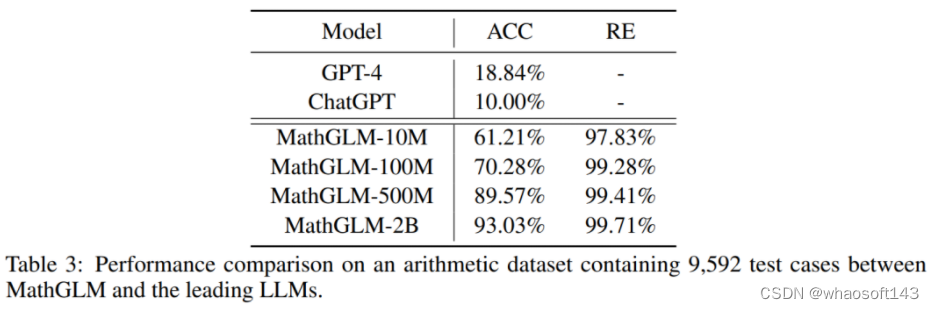 さらに、異なるパラメータ サイズで MathGLM を比較すると、MathGLM の算術性能がパラメータ数の増加に直接関係していることがわかります。この発見は、モデルのサイズが大きくなるにつれて、パフォーマンスもそれに応じて向上することを示唆しています。
さらに、異なるパラメータ サイズで MathGLM を比較すると、MathGLM の算術性能がパラメータ数の増加に直接関係していることがわかります。この発見は、モデルのサイズが大きくなるにつれて、パフォーマンスもそれに応じて向上することを示唆しています。
要約すると、複雑な算術タスクに関する研究者らの評価結果は、MathGLM が優れたパフォーマンスを備えていることを示しています。算術タスクを分解することにより、これらのモデルは GPT-4 や ChatGPT を大幅に上回ります。
さらに、この記事では GPT-4、ChatGPT、text-davinci-003、code-davinci-002、Galacica、LLaMA、OPT、BLOOM、および GLM も比較します。この記事では、前に説明した大規模なデータ セットから、100 個のテスト ケースを含むコンパクトな算術データ セットをランダムに抽出します。結果を表4に示す。ワオソフト アイオット http://143ai.com
上記の解析結果から、MathGLM は 20 億のパラメータの下で 93.03% の精度を達成し、他のすべての LLM を上回っていることがわかります。 数学的応用問題については、この論文では Ape210K データセットで実験を実施します。表 8 は、MathGLM バリアント、GPT-4、ChatGPT などを含む結果を報告します。
数学的応用問題については、この論文では Ape210K データセットで実験を実施します。表 8 は、MathGLM バリアント、GPT-4、ChatGPT などを含む結果を報告します。
結果は、GLM-10B と併用すると、MathGLM が解答精度の点で最先端の GPT-4 モデルに匹敵するパフォーマンス レベルを達成することを示しています。
さらに、MathGLM のパフォーマンスを GLM-Large、GLM-6B、および GLM-10B と比較すると、明らかな傾向が現れます。MathGLM は、算術精度と解答精度の両方で大幅な向上を示しています。 さまざまな学年で算数の問題を解くモデルの能力を評価するために、この研究では、GPT-4、ChatGPT、 Chinese-Alpaca-13B、MOSS-16B、Ziya などの K6 データセット上のいくつかのモデルのパフォーマンスをテストして評価しました。 -LLaMA -13B、Baichuan-7B、ChatGLM-6B、ChatGLM2-6B、および MathGLM-GLM-10B の結果を以下の図 8 に示します。
さまざまな学年で算数の問題を解くモデルの能力を評価するために、この研究では、GPT-4、ChatGPT、 Chinese-Alpaca-13B、MOSS-16B、Ziya などの K6 データセット上のいくつかのモデルのパフォーマンスをテストして評価しました。 -LLaMA -13B、Baichuan-7B、ChatGLM-6B、ChatGLM2-6B、および MathGLM-GLM-10B の結果を以下の図 8 に示します。