Guía de práctica de DevOps
-
- Parte 4 El segundo paso: Práctica técnica de la retroalimentación
- 17. Incorpore el desarrollo basado en hipótesis y las pruebas A/B en su trabajo diario.
- 18. Establecer procesos de revisión y colaboración para mejorar la calidad del trabajo actual.
-
- 18.1 Peligros de los procesos de aprobación de cambios
- 18.2 Los peligros potenciales de un “control excesivo del cambio”
- 18.3 Coordinación y programación de cambios
- 18.4 Revisión por pares de los cambios
- 18.5 Peligros potenciales de las pruebas manuales y la congelación de cambios
- 18.6 Mejora de los cambios de código mediante programación por pares
- 18.7 Eliminar procesos burocráticos
- 18.8 Resumen
- 18.9 Resumen de la Parte 4
Parte 4 El segundo paso: Práctica técnica de la retroalimentación
Este capítulo explora cómo el desarrollo basado en hipótesis y las pruebas A/B a través de telemetría pueden ayudarnos a alcanzar nuestros objetivos organizacionales y ganar en el mercado.
17. Incorpore el desarrollo basado en hipótesis y las pruebas A/B en su trabajo diario.
En los proyectos de software, los desarrolladores suelen pasar meses o años desarrollando funciones y realizan múltiples lanzamientos durante este período, pero nunca confirman si se cumplen los requisitos comerciales, como por ejemplo si una determinada función logra el efecto deseado, incluso si ya se ha utilizado.
Peor aún, incluso si se descubre que una función no funciona como se esperaba, se puede priorizar el desarrollo de nuevas funciones antes que su reparación, lo que da como resultado que esas funciones subóptimas nunca alcancen los resultados comerciales esperados.
17.1 Una breve historia de las pruebas A/B
Las pruebas A/B, en pocas palabras, consisten en desarrollar dos planes (como dos páginas) para el mismo objetivo, permitir que algunos usuarios usen el plan A y otros usuarios usen el plan B, registrar el uso del usuario y ver qué plan es más efectivo. .Se ajusta al diseño.
Una técnica de investigación de usuarios extremadamente poderosa es definir canales de adquisición de clientes y realizar pruebas A/B. Las técnicas de prueba A/B fueron pioneras en el marketing de respuesta directa , una de las dos categorías amplias de estrategias de marketing. El otro tipo se llama marketing masivo o marketing de marca , que suele implicar colocar la mayor cantidad de anuncios posible al público para influir en las decisiones de compra de las personas.
Ejemplos de pruebas A/B bien documentadas incluyen la recaudación de fondos para campañas, el marketing en Internet y la metodología Lean Startup. Curiosamente, el gobierno del Reino Unido también utiliza pruebas A/B para determinar qué cartas son más efectivas para recuperar impuestos atrasados.
17.2 Integración de las pruebas A/B en las pruebas funcionales
En la práctica moderna de la experiencia del usuario, la técnica de prueba A/B más utilizada es mostrar aleatoriamente a los visitantes una de dos versiones de una página en un sitio web, es decir, el grupo de control (A) o el grupo experimental (B). A partir del análisis estadístico del comportamiento posterior de estos dos grupos de usuarios, se puede determinar si existe una diferencia significativa en los resultados de los dos grupos, identificando así el grupo experimental (por ejemplo, cambios en la funcionalidad, elementos de diseño, color de fondo) y resultados (por ejemplo, tasa de conversión, tamaño promedio de pedido).
A veces, las pruebas A/B también se denominan experimentos controlados en línea y pruebas divididas. También se admiten múltiples variables durante el experimento para observar la interacción entre variables. Esta técnica se llama prueba multivariada.
"Después de evaluar experimentos bien diseñados y bien ejecutados diseñados para mejorar métricas clave, ¡sólo alrededor de un tercio de las características mejoraron con éxito las métricas clave!" En otras palabras, el impacto de los otros dos tercios puede ser Ignorarlo puede incluso hacer que el situación peor. “En el caso extremo, sería mejor para la organización y el cliente si todo el equipo se tomara unas vacaciones en lugar de desarrollar estas funciones que no tienen valor.
Hay muchas otras formas de realizar una investigación de usuarios antes de pasar al desarrollo de productos. Los métodos más baratos incluyen realizar encuestas, crear prototipos (simulados utilizando herramientas como Balsamiq o versiones interactivas escritas en código) y realizar pruebas de usabilidad. Alberto Savoia, director de ingeniería de Google, acuñó el término "creación de prototipos" para referirse a la práctica de utilizar prototipos para verificar que se está creando lo correcto. En comparación con codificar una función inútil, la investigación de usuarios es barata y fácil de implementar. Por lo tanto, en casi cualquier caso, las funciones no deben priorizarse sin validación.
Nuestra respuesta es integrar las pruebas A/B en el proceso de diseño, implementación, prueba e implementación de funciones. Garantizar que nuestros esfuerzos contribuyan a los objetivos de los clientes y de la organización y ganen en el mercado mediante la realización de investigaciones y experimentos significativos con los usuarios.
17.3 Integración de pruebas A/B en las versiones
Las pruebas A/B rápidas e iterativas son posibles mediante una implementación rápida y sencilla bajo demanda en entornos de producción, aprovechando los cambios de funciones para entregar simultáneamente múltiples versiones del software a múltiples grupos de usuarios. Lograr esto requiere una telemetría de producción integral en todos los niveles de la pila de aplicaciones.
Puede controlar la proporción de usuarios que ven la versión experimental marcando las opciones en el interruptor de funciones. Por ejemplo, podría convertir a la mitad de sus clientes en un grupo experimental y mostrarles "enlaces a artículos similares a los artículos vencidos en su carrito de compras". En el experimento, comparamos el comportamiento de usuario del grupo de control (sin elección) y del grupo experimental (con elección), quizás midiendo el número de compras realizadas durante el período.
"El propósito de los experimentos es tomar decisiones informadas y garantizar que las funciones se implementen para millones de miembros. A menudo invertimos mucho tiempo en funciones y tenemos que mantenerlas, pero no hay evidencia de que tengan éxito o se vean afectadas por los usuarios. "Acéptalo. Las pruebas A/B nos permiten determinar si vale la pena seguir invirtiendo en una característica durante el proceso de desarrollo".
17.4 Integración de pruebas A/B en la planificación de funciones
Una vez que tengamos la infraestructura para respaldar el lanzamiento y las pruebas de funciones A/B, también debemos asegurarnos de que los gerentes de producto traten cada función como una hipótesis y prueben o refuten esas hipótesis basándose en la experimentación real del usuario en producción. Los experimentos de creación deben diseñarse dentro del contexto completo de su embudo de adquisición de clientes.
El ciclo de vida del desarrollo de software (SDLC) incluye diferentes etapas desde el inicio hasta el lanzamiento del software. Define un proceso para mejorar la calidad y eficiencia del software a desarrollar. Por lo tanto, SDLC tiene como objetivo ofrecer software de alta calidad con recursos mínimos. Para evitar consecuencias graves del fracaso del proyecto, el ciclo de vida del desarrollo de software generalmente se puede dividir en las siguientes seis etapas:
- Recopilación de requisitos
- diseño
- desarrollo de software
- Pruebas y garantía de calidad
- desplegar
- mantener
17.5 Resumen
El éxito requiere no sólo implementar y lanzar software rápidamente, sino también superar a los competidores en la experimentación. El desarrollo basado en hipótesis, la definición y medición de embudos de adquisición de clientes y técnicas como las pruebas A/B hacen posible realizar experimentos de usuarios de forma segura y sencilla, lo que permite a los empleados dar rienda suelta a la creatividad, la innovación y el aprendizaje organizacional. Si bien el éxito es importante, el aprendizaje organizacional que surge de la experimentación también mantiene a los empleados motivados para lograr los objetivos comerciales y la satisfacción del cliente. El próximo capítulo mejorará la calidad de su trabajo actual mediante la investigación y la creación de procesos de revisión y colaboración.
18. Establecer procesos de revisión y colaboración para mejorar la calidad del trabajo actual.
El objetivo de este capítulo es ayudar a los desarrolladores y al personal de operaciones a reducir el riesgo de cambios antes de implementarlos en producción. Según la práctica tradicional, cuando revisamos los cambios que se implementarán, a menudo nos basamos principalmente en el proceso de revisión, revisión y aprobación antes de la implementación. Los aprobadores suelen ser de equipos externos que no comprenden el trabajo real, por lo que no pueden juzgar con precisión si el cambio es riesgoso y lleva mucho tiempo obtener todas las aprobaciones necesarias, lo que prolonga aún más el tiempo de entrega del cambio. .
GitHub Flow consta de los siguientes 5 pasos.
(1) Para implementar un nuevo requisito funcional, los ingenieros deben establecer una rama claramente nombrada basada en el tronco (por ejemplo, newoauth2-scopes).
(2) El ingeniero envía el código a la sucursal local y envía periódicamente los resultados del trabajo a la sucursal del mismo nombre en el servidor remoto.
(3) Cuando necesiten comentarios o ayuda, o cuando estén listos para fusionar el código de esta rama en el tronco, enviarán una nueva solicitud de extracción.
(4) Después de obtener las revisiones deseadas y aprobar las revisiones necesarias, el código se puede fusionar en la troncal.
(5) Una vez que los cambios de código se fusionan en el tronco, los ingenieros pueden implementarlos en el entorno de producción.
Este capítulo integrará prácticas como GitHub en su trabajo diario, donde dejaremos de depender de verificaciones y aprobaciones periódicas y las reemplazaremos con revisiones continuas por pares. Nuestro objetivo es garantizar que los desarrolladores, el personal de operaciones y el personal de seguridad de la información siempre trabajen en estrecha colaboración para que los cambios realizados en el sistema sean confiables, seguros y según lo diseñado.
18.1 Peligros de los procesos de aprobación de cambios
La interrupción de Knight Capital es uno de los contratiempos recientes más destacados en la implementación de software. El incidente de implementación de 15 minutos resultó en 440 millones de dólares en transacciones perdidas, durante las cuales el equipo de ingeniería no pudo finalizar los servicios de producción. Las pérdidas financieras pusieron en peligro las operaciones de la empresa. Para seguir operando y no poner en peligro a todo el sistema financiero, la empresa se vio obligada a vender una semana después.
Generalmente hay dos narrativas contrafácticas sobre por qué ocurrió un accidente.
- La primera narrativa es: el accidente fue causado por una falla en el control de cambios. Esto suena razonable, ya que podemos imaginar que con mejores prácticas de control de cambios, los riesgos podrían identificarse antes y evitar que los cambios se implementen en producción. Si no podemos evitar la implementación, podemos tomar medidas adicionales para lograr una detección y recuperación más rápidas.
- La segunda narrativa es que el accidente fue causado por una falla en la prueba. Esto también parece tener sentido, porque con prácticas de prueba más completas, los riesgos se pueden descubrir antes y la implementación riesgosa se puede cancelar, o al menos se pueden tomar algunas medidas para lograr una detección y recuperación más rápidas.
El pensamiento contrafactual es un término psicológico que se refiere a la tendencia de las personas a crear narrativas alternativas sobre acontecimientos de la vida que ya han ocurrido. En ingeniería de confiabilidad, el pensamiento contrafactual a menudo implica narrativas de "sistemas imaginados" en lugar de "sistemas reales".
Pero la realidad es que en un entorno cultural de comando y control de baja confianza, estas prácticas de control de cambios y pruebas aumentarán la posibilidad de que los problemas se repitan e incluso causarán consecuencias más graves.
18.2 Los peligros potenciales de un “control excesivo del cambio”
El control de cambios tradicional puede tener consecuencias no deseadas, como tiempos de entrega prolongados y reducción de la intensidad e inmediatez de la retroalimentación durante la implementación. Para comprender mejor cómo sucede esto, revisemos los controles que normalmente se implementan cuando ocurre una falla en el control de cambios.
- Agregue más preguntas para responder en el formulario de solicitud de cambio.
- Con más reautorización, como agregar un nivel más de gestión (por ejemplo, aprobación no solo del vicepresidente de operaciones sino también del CIO) o aprobación de más partes interesadas (por ejemplo, ingeniería de redes, junta de revisión de arquitectura, etc.).
- La aprobación de cambios requiere más tiempo para que las solicitudes de cambio puedan evaluarse adecuadamente.
Estos controles introducen una serie de pasos y aprobaciones adicionales, lo que agrega fricción al proceso de implementación y al mismo tiempo aumenta el tamaño de los lotes y los tiempos de entrega de la implementación. Sabemos que para el desarrollo y las operaciones, esto reduce la probabilidad de obtener resultados laborales exitosos. Estos controles también reducen la velocidad a la que recibimos retroalimentación.
Una de las creencias fundamentales del Sistema de Producción Toyota es que "la persona que mejor sabe acerca de un problema suele ser la persona más cercana al problema". Esto se vuelve aún más evidente a medida que el trabajo y los sistemas de trabajo se vuelven más complejos y dinámicos, lo cual es típico de los flujos de valor de DevOps. En este caso, hacer que personas cada vez más alejadas del trabajo realicen los pasos de aprobación pertinentes puede en realidad reducir la probabilidad de que el trabajo sea exitoso. Como se ha demostrado antes, cuanto mayor sea la distancia entre la persona que realiza el trabajo (es decir, el implementador del cambio) y la persona que decide realizar el trabajo (es decir, el autorizador del cambio), peor será el resultado del proceso de aprobación. En el Informe sobre el estado de DevOps de 2014 de Puppet Labs, un hallazgo clave fue que las organizaciones de alto rendimiento dependen más de la revisión por pares y menos de las aprobaciones de cambios externos.
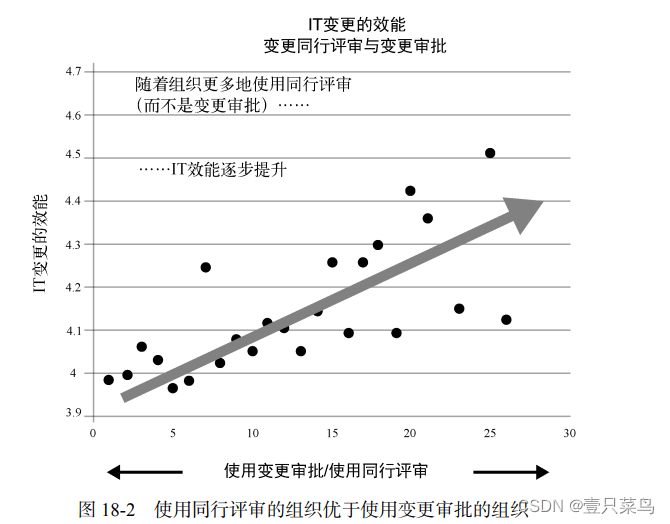
Por todas las razones anteriores, necesitamos crear prácticas de control que sean más parecidas a la revisión por pares y menos dependientes de la autorización externa y relevante de cambios organizacionales. También es necesario coordinar y programar eficazmente las actividades relacionadas con el cambio.
18.3 Coordinación y programación de cambios
Siempre que varios equipos trabajan en un sistema que comparte dependencias, puede ser necesario coordinar los cambios para garantizar que no interfieran entre sí (por ejemplo, agrupar, agrupar y programar cambios). En términos generales, cuanto menos acoplada esté la arquitectura de una organización, menos comunicación y coordinación habrá entre los equipos que la componen. Cuando la arquitectura del sistema está verdaderamente orientada a servicios, cada equipo puede realizar cambios con un alto grado de autonomía, porque es poco probable que los cambios locales causen interrupciones globales.
Para organizaciones complejas y aquellas con arquitecturas de sistemas altamente acopladas, es posible que debamos ser más cuidadosos al organizar los cambios. Los representantes de cambio de cada equipo deben reunirse. No autorizan los cambios, pero programan y serializan el trabajo de cambio para minimizar el riesgo de accidentes.
Sin embargo, siempre habrá mayores riesgos asociados con ciertas áreas, como cambios en la infraestructura subyacente (por ejemplo, cambios en los conmutadores de la red central). Dichos cambios siempre requerirán salvaguardias técnicas, como sistemas de respaldo redundantes, conmutación por error, pruebas integrales y simulación de cambios (idealmente).
18.4 Revisión por pares de los cambios
En lugar de requerir la aprobación de una organización externa antes de la implementación, la revisión por pares requiere que los ingenieros pidan a sus pares que revisen sus cambios. En desarrollo, esta práctica se denomina revisión de código, pero se aplica igualmente a cualquier cambio realizado en una aplicación o entorno, incluidos servidores, redes y bases de datos. El objetivo de la revisión por pares es reducir los errores de cambio mediante una revisión cuidadosa por parte de colegas ingenieros. Esta forma de revisión no solo mejora la calidad de los cambios, sino que también equivale a una capacitación cruzada, lo cual es muy beneficioso para el aprendizaje mutuo y la mejora de habilidades.
Un momento razonable para realizar una revisión por pares es cuando el código se envía al tronco en el sistema de control de versiones. En este momento, el cambio puede afectar a todo el equipo o tener un impacto global. Como mínimo, nuestros colegas ingenieros deben revisar nuestros cambios, pero para áreas de mayor riesgo, como cambios en la base de datos o cambios en componentes críticos del negocio sin una alta cobertura de pruebas automatizadas, es posible que se necesiten expertos en el dominio (como la seguridad de la información). , ingeniero de bases de datos) para una revisión adicional o revisiones múltiples (por ejemplo, comente con "+2" en lugar de "+1")
El principio de mantener pequeños los tamaños de lote también se aplica a las revisiones de código. Cuanto mayor sea el tamaño del lote de cambios, más tiempo les tomará a los ingenieros de revisión comprender el trabajo y mayor será la carga para ellos.
Los principios rectores para la revisión del código son los siguientes:
- Todos deben hacer que sus pares revisen sus cambios (como código, entorno, etc.) antes de enviar el código al troncal.
- Todos deben continuar monitoreando la actividad de envío de otros miembros para identificar y revisar posibles conflictos.
- Defina qué cambios son de alto riesgo y determine si requieren revisión por parte de expertos en el dominio (por ejemplo, cambios en la base de datos, módulos de autenticación sensibles a la seguridad, etc.).
- Si el tamaño del cambio enviado es tan grande que es difícil de entender (en otras palabras, no se puede entender después de leer el código varias veces o requiere una explicación por parte del autor de la confirmación), entonces el cambio debe dividirse en varios cambios más pequeños. Envíe los cambios para que queden claros de un vistazo.
Para evitar revisiones formalistas, es posible que desee verificar las estadísticas de revisión de código para determinar cuántos envíos de código pasaron la revisión y cuántos fallaron. También puede probar e inspeccionar revisiones de código específicas. Las revisiones de código tienen las siguientes formas
- Programación en parejas: los programadores trabajan juntos en parejas (consulte la siguiente sección).
- "Lado a lado": después de que un programador escribe un fragmento de código, el programador revisor lee su código línea por línea.
- Envío por correo electrónico para revisión: después de que el código se registre en el sistema de administración de códigos, el sistema enviará automáticamente por correo una copia del código a los revisores de inmediato.
- Revisiones asistidas por herramientas: tanto los codificadores como los revisores utilizan herramientas diseñadas para la revisión de código (por ejemplo, Gerrit, GitHub's Pull Request, etc.) o mediante repositorios de código fuente (por ejemplo, GitHub, Mercurial, Subversion y Gerrit, Atlassian Stash y Atlassian similares). La funcionalidad la proporcionan otras plataformas como Crucible.
Varias formas de inspección minuciosa de los cambios pueden ayudar a descubrir errores que podrían haberse pasado por alto. La revisión del código también puede ayudar en el envío y la implementación del entorno de producción de código incremental y respaldar la implementación basada en troncales y la entrega continua a gran escala.
Estricta disciplina y revisión obligatoria del código, que cubre los siguientes aspectos:
- Legibilidad del código del lenguaje (estilo de codificación obligatorio);
- Asignar la propiedad de la rama del código y ser responsable de garantizar la coherencia y corrección;
- Promover la transparencia del código y la contribución dentro del equipo.
La Figura 18-3 muestra cómo el tamaño de un cambio de código afecta el tiempo de entrega de la revisión del código. El eje x representa el tamaño del cambio de código y el eje y representa el tiempo de entrega del proceso de revisión del código. En términos generales, cuanto mayor sea el lote de cambios que requieren revisión del código, mayor será el tiempo necesario para la revisión del código. Los puntos de datos en la esquina superior izquierda representan cambios más complejos y potencialmente riesgosos que requieren más deliberación y discusión.
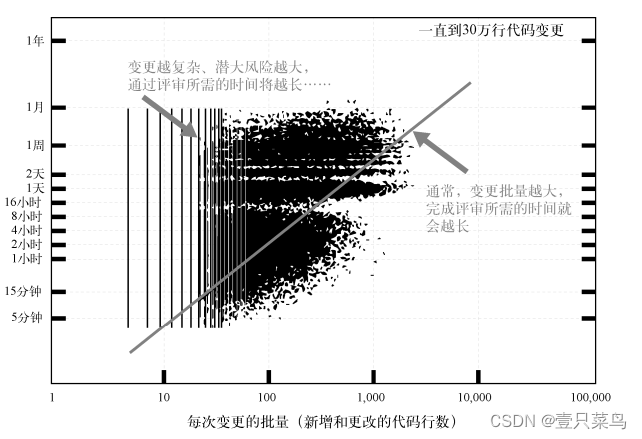
18.5 Peligros potenciales de las pruebas manuales y la congelación de cambios
Ahora, hemos incorporado la revisión por pares para reducir el riesgo, acortar el tiempo de entrega asociado con el proceso de aprobación de cambios y permitir la entrega continua a escala, como se ve en el estudio de caso de Google. Veamos una situación en la que las pruebas pueden ser contraproducentes. Cuando una prueba falla, nuestra reacción habitual es que deberíamos realizar más pruebas. Sin embargo, simplemente realizar más pruebas al final de un proyecto podría conducir a peores resultados.
Esto es especialmente cierto cuando se realizan pruebas manuales, ya que las pruebas manuales son inherentemente más lentas y tediosas que las pruebas automatizadas y, a menudo, tardan más en completar "pruebas adicionales", lo que significa que las implementaciones se implementan con menos frecuencia y, por lo tanto, el tamaño del lote de las implementaciones también aumenta. . Tanto desde una perspectiva teórica como práctica, todos sabemos que cuanto mayor sea el tamaño del lote de implementación, menor será la tasa de éxito de los cambios, el número de incidentes y el tiempo medio de recuperación (MTTR) también aumentará; este resultado es consistente. con nuestro Espera exactamente lo contrario.
No queremos programar pruebas de cambios extensas durante una congelación de cambios, sino más bien probar completamente nuestro trabajo diario como parte de un proceso de producción continuo y fluido mientras aumentamos la frecuencia de las implementaciones. De esta manera logramos una calidad integrada y podemos probar, implementar y lanzar con lotes más pequeños.
18.6 Mejora de los cambios de código mediante programación por pares
La programación en pareja es un método de desarrollo en el que dos ingenieros de desarrollo de software trabajan en la misma estación de trabajo al mismo tiempo. Es una práctica ampliamente popularizada por la programación extrema y el desarrollo ágil a principios del siglo XXI. Al igual que con las revisiones de código, esta práctica comienza durante el proceso de desarrollo, pero también se aplica a otras tareas relacionadas con la ingeniería dentro del flujo de valor. A lo largo de este libro, los términos emparejamiento y programación en pares se utilizan como sinónimos para indicar que esta práctica no es solo para desarrolladores.
En un modelo de emparejamiento común, un ingeniero actúa como conductor , el que realmente escribe el código, mientras que el otro ingeniero actúa como navegador, observador o supervisor que controla lo que está haciendo el conductor. Durante el proceso de inspección, los observadores también pueden proponer ideas de mejora y problemas que puedan surgir en el futuro en función de la dirección estratégica del trabajo. Con el observador como red de seguridad y guía, el conductor puede centrar toda su atención en los aspectos tácticos de completar la misión. Cuando dos personas tienen diferentes fortalezas, pueden aprender de las fortalezas del otro, ya sea a través de capacitación especializada o compartiendo técnicas y soluciones.
Otro patrón de programación en pares es a través del desarrollo basado en pruebas, donde un ingeniero escribe pruebas automatizadas y otro ingeniero escribe el código.
"Si tuvieran la opción, la mayoría de las personas probablemente renunciarían a las revisiones de código, y eso no es posible cuando se programa en pareja. Ambas partes del par deben comprender el código en cuestión. El emparejamiento puede ser intrusivo, pero también obliga a las personas a comunicarse a un nivel nunca antes visto. antes."
La programación en pares también puede beneficiar la difusión del conocimiento dentro de una organización y el flujo de información dentro de un equipo. Hacer que ingenieros experimentados revisen el código simultáneamente mientras los ingenieros menos experimentados lo implementan también es una forma eficaz de enseñar y aprender.
Muchas organizaciones realizan revisiones de código correctamente debido a una cultura que reconoce que revisar el código es tan valioso como escribirlo. La programación en pareja puede servir como una práctica valiosa durante tiempos de transición cuando esta cultura aún no se ha establecido.
Evaluación de la efectividad de la solicitud de extracción
Debido a que la revisión por pares es una parte importante de nuestro entorno de control, debemos asegurarnos de que funcione de manera efectiva.
- Una forma de hacerlo es revisar cualquier cambio asociado con una interrupción de la producción y revisar todos los procesos de revisión por pares relacionados.
- Otro enfoque proviene de Ryan Tomayko, CIO y cofundador de GitHub y uno de los inventores del manejo de Pull Request. Cuando le preguntaron cuál era la diferencia entre un Pull Request incorrecto y un Pull Request efectivo, dijo que tenía poco que ver con cómo resultarían en un entorno de producción. Por el contrario, un Pull Request incorrecto no proporciona suficiente contenido para el lector, y algunos incluso no proporcionan documentación que explique el propósito del cambio. Por ejemplo, una solicitud de extracción solo proporciona este texto: "Reparar tickets n.° 3616 y n.° 3841".
Cuando se le pide que describa los elementos básicos de una buena solicitud de extracción que demuestre un proceso de revisión eficaz:
- El motivo del cambio debe indicarse con suficiente detalle.
- Cómo hacer cambios
- cualquier riesgo identificado
- Respuestas
18.7 Eliminar procesos burocráticos
Hasta ahora, hemos analizado los procesos de revisión por pares y programación en pares que pueden mejorar la calidad del trabajo sin depender de la aprobación de cambios externos. Sin embargo, muchas empresas todavía tienen procesos de aprobación antiguos que pueden llevar meses. Estos procesos de aprobación extienden significativamente los plazos de entrega, lo que dificulta la entrega rápida de valor a los clientes y potencialmente agrega riesgos al logro de los objetivos organizacionales. Cuando esto sucede, debemos rediseñar nuestros procesos para lograr nuestros objetivos de forma más rápida y segura.
18.8 Resumen
Este capítulo analiza algunas prácticas técnicas que deben integrarse en el trabajo diario para mejorar la calidad de los cambios, reducir el riesgo de errores de implementación y reducir la dependencia de los procesos de aprobación. Los estudios de caso de GitHub y Target muestran que estas prácticas no solo mejoran los resultados del trabajo, sino que también reducen drásticamente los tiempos de entrega y aumentan la productividad de los desarrolladores. Estos trabajos requieren una cultura de alta confianza.
Crear condiciones que brinden a quienes implementan el cambio control total sobre la calidad de sus cambios es una parte importante de la cultura generativa y de alta confianza que nos esforzamos por construir. Además, estas condiciones nos permiten crear un sistema de trabajo más seguro en el que nos ayudamos mutuamente a lograr nuestros objetivos, más allá de cualquier límite que deba cruzarse.
18.9 Resumen de la Parte 4
La cuarta parte nos muestra que al implementar un circuito de retroalimentación, todos pueden colaborar para lograr un objetivo común, detectar problemas rápidamente cuando ocurren y garantizar que todas las funciones no solo puedan funcionar según lo diseñado a través de un mecanismo rápido de detección y recuperación. ambiente y también logra las metas organizacionales y el aprendizaje organizacional. También analizamos cómo el desarrollo y las operaciones pueden compartir objetivos, mejorando así la salud de todo el flujo de valor.
Estamos a punto de ingresar a la quinta parte, "Paso Tres: Práctica Técnica de Experimentación y Aprendizaje Continuo", con el fin de crear oportunidades de aprendizaje más tempranas, más rápidas y más económicas, a fin de crear una cultura de innovación y experimentación, para que todos puedan aprender a través de un trabajo significativo, un trabajo que ayuda a las organizaciones a tener éxito