
Stable Diffusion Quick Kit es un kit de herramientas de implementación rápida del modelo Stable Diffusion, que incluye un conjunto de códigos de muestra, scripts de implementación de servicios y una interfaz de usuario de front-end, que pueden ayudar a implementar rápidamente un conjunto de servicios prototipo de Stable Diffusion. Hemos lanzado sucesivamente los conceptos básicos del Quick Kit, el ajuste de Dreambooth, el uso y el ajuste de LoRA. Consulte el apéndice para ver los enlaces de los artículos. En este artículo, presentaremos cómo cargar Stable Diffusion XL (en lo sucesivo, SDXL) y el modelo Lora y el modelo ControlNet adecuados para SDXL a través del Stable Diffusion Quick Kit para inferencia.
01
¿Qué es la Difusión Estable XL?
(SDXL)
1.1 Descripción general de Difusión estable XL
Stable Diffusion XL es un nuevo modelo de generación de imágenes creado por Stability AI. En comparación con el modelo anterior Stable Diffusion 1.5, se han realizado principalmente las siguientes optimizaciones o mejoras:
1) Se han realizado mejoras en la codificación de texto U-Net, VAE y CLIP del Stable Diffusion 1.5 original;
2) Se agrega un modelo Refiner al modelo original para mejorar la sofisticación de la imagen a través del modelo Refiner;
3) Stability AI lanzó por primera vez la versión de prueba de Stable Diffusion XL 0.9. Según la experiencia del usuario y las imágenes generadas, aumentó el conjunto de datos de manera específica y utilizó la tecnología RLHF para optimizar y lanzar iterativamente la versión oficial de Stable Diffusion XL 1.0. .
1.2 Introducción a la infraestructura
Stable Diffusion XL es un modelo de difusión en cascada de dos etapas que consta de un modelo Base y un modelo Refiner, diseñado para mejorar la calidad y los detalles de las imágenes generadas. Entre ellos, el modelo Base es consistente con Difusión Estable y tiene las capacidades de dibujo de Vincent, dibujo de gráficos y pintura de imágenes. Después de que el modelo Base genera una imagen, el modelo Refiner se conectará en cascada después del modelo Base para refinar aún más las características latentes de la imagen generada por el modelo Base, mejorando así la calidad y los detalles de la imagen generada.
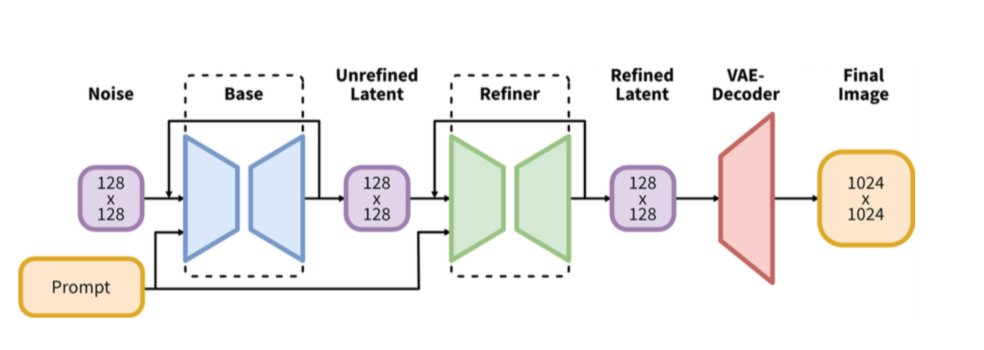
En el documento Stability AI (https://arxiv.org/pdf/2307.01952.pdf) podemos ver que el número de parámetros UNet de SDXL es 2.6B, que es mucho mayor que los 860M de SD 1.4/1.5 y el 865M. de SD 2.0/2.1.
Entre ellos, los bloques transformadores espaciales agregados (Self Attention+ Cross Attention) representan la mayor parte de los nuevos parámetros:

1.3 Modelo refinador
La mayor diferencia entre SDXL y SD 1.5/2.0 es que proporciona un modelo Refiner separado. En la etapa de inferencia de 2 etapas Stable Diffusion XL, ingrese un mensaje, genere características latentes a través de los modelos VAE y U-Net (Base), y luego dar esto La función latente agrega una cierta cantidad de ruido y, sobre esta base, el modelo Refiner se utiliza para eliminar el ruido para mejorar la calidad general y los detalles locales de la imagen. En esencia, el modelo Refiner hace el trabajo de generar imágenes a partir de imágenes.
El funcionario proporciona un conjunto de imágenes comparativas de SDXL sin refinador y con refinador. Puede ver que los detalles de las imágenes son más realistas después de usar el refinador. Las siguientes son las imágenes proporcionadas por el funcionario:


02
Cómo utilizar SDXL con difusores
En Quick Kit, utilizamos difusores HuggingFace (v0.19.3 o superior, consulte el Apéndice 2 para ver el enlace del proyecto). En la nueva versión, los difusores agregan dos nuevas interfaces Pipeline, StableDiffusionXLPipeline y StableDiffusionXLImg2ImgPipeline, para cargar modelos SDXL. También proporciona un StableDiffusionXLControlNetPipeline. Para implementar la carga del modelo SDXL ControlNet, la siguiente es la descripción del código básico:
#DiffusionPipeline
import torch
from diffusers import StableDiffusionXLPipeline, StableDiffusionXLImg2ImgPipeline
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
#加载SDXL base model
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
pipe.to("cuda")
image = pipe(prompt=prompt,output_type="latent").images[0]
#加载SDXL refiner model
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
#base model 输出,这里需output_type需要设置成为latent
images = pipe(prompt, output_type="latent").images
#refiner model 输出
images = refiner(prompt=prompt, image=images).images
#...images 保存处理
#controlnet模型初始化
def init_sdxl_control_net_pipeline(base_model,control_net_model):
controlnet = ControlNetModel.from_pretrained(
f"diffusers/controlnet-{control_net_model}-sdxl-1.0-small",
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16).to("cuda")
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
base_model,
controlnet=controlnet,
vae=vae,
variant="fp16",
use_safetensors=True,
torch_dtype=torch.float16,
).to("cuda")
return pipeDesliza hacia la izquierda para ver más
03
Usando SDXL y SDXL en Quick Kit
(Estilo Kohya) LoRA,ControlNet
La última versión de los difusores de HuggingFace es 0.19.3, que agrega dos nuevos tipos: StableDiffusionXLPipeline y StableDiffusionXLImg2ImgPipeline para coincidir con el modelo SDXL 0.9/1.0. También es compatible con el modelo SDXL Kohya-Style LoRA. Vamos a demostrarlo en la práctica.
Primero cree un SageMaker Notebook basado en la práctica práctica anterior del Stable Diffusion Quick Kit: conceptos básicos y use git para clonar el código más reciente (https://github.com/aws-samples/sagemaker-stablediffusion-quick-kit). y luego abra inference/stable-diffusion-on-sagemaker-byoc-sdxl.ipynb en sagemaker/byoc_sdxl/.
HuggingFace proporciona dos modelos Controlnet, Canny y Depth, para SDXL, y ofrece versiones pequeñas https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0-small, https://huggingface.co/diffusers/controlnet-deep -sdxl-1.0-small es aproximadamente 7 veces más pequeño que la versión estándar y se puede cargar rápidamente en difusores.
3.1 Crear punto final de SageMaker
En SageMaker Notebook (stable-diffusion-on-sagemaker-byoc-sdxl.ipynb) debemos realizar los siguientes pasos:
Actualice boto3 y sagemaker SDK en el portátil (la versión utilizada en esta prueba: boto3-1.28.39 sagemaker-2.182.0)
Compile la imagen de la ventana acoplable, el nombre de la imagen es sdxl-inference-v2
Establezca los parámetros del servicio de inferencia. Debido a que los parámetros del modelo SDXL son más grandes y el tamaño de imagen predeterminado es mayor (1024, 1024), se recomienda utilizar ml.g5.2xlarge. Los parámetros de configuración específicos se explican a continuación.
# refiner 模型和 LoRA 模型是在推理参数中设置,这里只需要设置 base 模型
primary_container = {
'Image': container,
'ModelDataUrl': model_data,
'Environment':{
's3_bucket': bucket,
'model_name':'stabilityai/stable-diffusion-xl-base-1.0' # 使用 SDXL 1.0 base 模型
}
}
# InstanceType 推理服务的机器类型 ml.g5.2xlarge
response = client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
'VariantName': _variant_name,
'ModelName': model_name,
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.2xlarge',
'InitialVariantWeight': 1
},
]
,
AsyncInferenceConfig={
'OutputConfig': {
'S3OutputPath': f's3://{bucket}/stablediffusion/asyncinvoke/out/'
}
}
)Desliza hacia la izquierda para ver más
04
prueba
Descripción de parámetros relacionados con SDXL:
sdxl_refiner, ya sea para habilitar la inferencia del refinador, se puede configurar para deshabilitar, habilitar
lora_name, lora_name nombre, debe ser único
loral_url, dirección de descarga http accesible, puede utilizar el enlace de descarga de la estación C
control_net_model, nombre del modelo ControlNet, actualmente admite modelos astutos y de profundidad 2
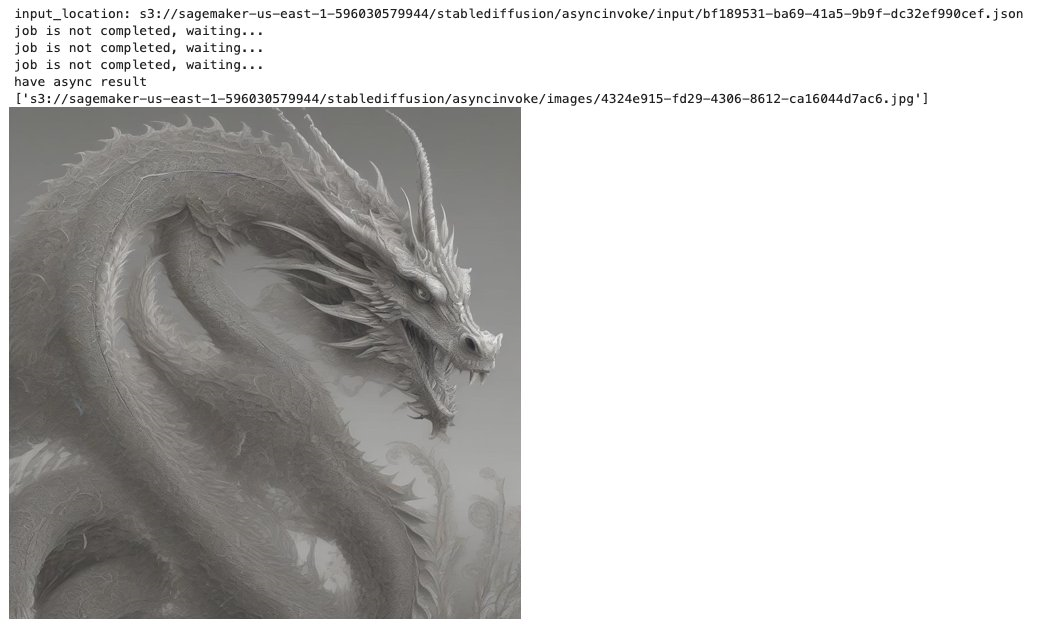
4.1 Pruebe SDXL sin usar el modelo Refiner
payload={
"prompt": "a fantasy creaturefractal dragon",
"steps":20,
"sampler":"euler_a",
"seed":43768,
"count":1,
"control_net_enable":"disable",
"SDXL_REFINER":"disable"
}
predict_async(endpoint_name,payload)Desliza hacia la izquierda para ver más
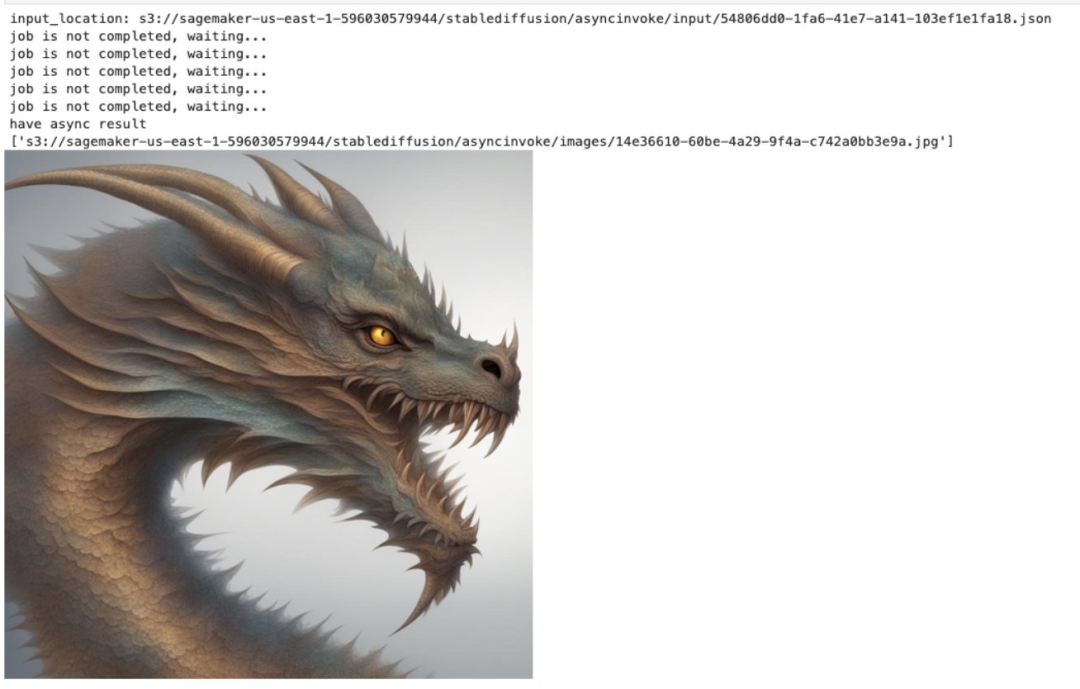
4.2 Pruebe SDXL usando el modelo Refiner
Establezca el parámetro sdxl_refiner en 4.1 para permitir el uso del modelo refinador.
payload={
"prompt": "a fantasy creaturefractal dragon",
"steps":20,
"sampler":"euler_a",
"seed":43768,
"count":1,
"control_net_enable":"disable",
"SDXL_REFINER":"enable"
}
predict_async(endpoint_name,payload)Desliza hacia la izquierda para ver más
4.3 Prueba SDXL Lora
SDXL LoRA no es compatible con el modelo SD 1.5 LoRA anterior, por lo que debe elegir el modelo LoRA entrenado por SDXL. Quick Kit admite la carga dinámica de modelos LoRA. Aquí elegimos el modelo Dragon Style LoRA en el sitio C para realizar pruebas.
El proceso de carga de LoRA es aproximadamente el siguiente: el servicio en segundo plano analiza los parámetros lora_name y lora_url, primero verifica si el archivo del modelo existe en el directorio /tmp, si el archivo no existe, usa lora_url para descargar el modelo y almacenarlo en el Directorio /tmp. La primera inferencia debe esperar a que se descargue el modelo LoRA. Si necesita cambiar el modelo LoRA, solo necesita cambiar los parámetros lora_name y lora_url en la solicitud de inferencia.
payload={
"prompt": "a fantasy creaturefractal dragon",
"steps":20,
"sampler":"euler_a",
"count":1,
"control_net_enable":"disable",
"sdxl_refiner":"enable",
"lora_name":"dragon",
"lora_url":"https://civitai.com/api/download/models/129363"
}
predict_async(endpoint_name,payload)Desliza hacia la izquierda para ver más

4.3 Pruebe SDXL ControlNet
SDXL requiere el uso de un modelo ControlNet coincidente. En este artículo probaremos los modelos astutos y de profundidad proporcionados por HuggingFace.
En el cuaderno usamos HuggingFace como ejemplo para probar la astucia y la profundidad.
Para probar Canny, configure control_net_model en "canny".
payload={
"prompt": "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting",
"steps":20,
"sampler":"euler_a",
"count":1,
"control_net_enable":"enable",
"sdxl_refiner":"enable",
"control_net_model":"canny",
"input_image":"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
}
predict_async(endpoint_name,payload)Desliza hacia la izquierda para ver más

Pruebe la profundidad, establezca control_net_model en "profundidad"
payload={
"prompt": "aerial view, a futuristic research complex in a bright foggy jungle, hard lighting",
"steps":20,
"sampler":"euler_a",
"count":1,
"control_net_enable":"enable",
"sdxl_refiner":"enable",
"control_net_model":"depth",
"input_image":"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/hf-logo.png"
}
predict_async(endpoint_name,payload)Desliza hacia la izquierda para ver más

05
Resumir
Podemos implementar rápidamente el modelo base SD XL y el servicio de inferencia del modelo Refiner en Quick Kit, y podemos cargar dinámicamente el modelo LoRA coincidente, o cargar los modelos ControlNet SDXL canny y SDXL de profundidad proporcionados por HuggingFace. En la actualidad, la comunidad de difusores se está desarrollando rápidamente. Muchas características de otras herramientas de inferencia GUI se han integrado en los difusores gracias a los esfuerzos de los contribuyentes de la comunidad. Sin embargo, todavía hay varias funciones importantes que aún están en desarrollo. Por ejemplo, la versión actual de Los difusores no admiten oficialmente la carga múltiple de LoRA. , debe implementarse a través de un script de terceros. El muestreador/programador que viene con la versión actual de los difusores es relativamente pequeño en comparación con SD WebUI. Esto es a lo que debemos prestar atención. cuando se utilizan difusores.
Referencias
Difusión estable XL
https://arxiv.org/pdf/2307.01952.pdf
nota de lanzamiento de los difusores
https://github.com/huggingface/diffusers/releases
Modelo astuto
https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0-small
Modelo de profundidad
https://huggingface.co/diffusers/controlnet-profundidad-sdxl-1.0-small
Práctica práctica del kit rápido de difusión estable: conceptos básicos
https://aws.amazon.com/cn/blogs/china/stable-diffusion-quick-kit-hands-on-practice-basics/
Práctica práctica del kit rápido de difusión estable: práctica de optimización del uso de Dreambooth para ajustar el modelo en SageMaker
https://aws.amazon.com/cn/blogs/china/stable-diffusion-quick-kit-series-model-fine-tuning-with-dreambooth-optimization-practices-on-sagemaker/
Práctica práctica del kit rápido de difusión estable: ajuste fino e inferencia de LoRA en SageMaker
https://aws.amazon.com/cn/blogs/china/lora-fine-tuning-and-reasoning-in-sagemaker/
El autor de este artículo.

Su Wei
Arquitecto senior de soluciones en Amazon Cloud Technology, centrado en la industria del juego, entusiasta de los proyectos de código abierto y comprometido con la promoción e implementación de aplicaciones nativas de la nube. Tiene más de 15 años de experiencia profesional en la industria de la tecnología de la información y se ha desempeñado como ingeniero de software senior, arquitecto de sistemas y otros puestos. Antes de unirse a Amazon Cloud Technology, trabajó para Bea, Oracle, IBM y otras empresas.

Yanjun
El arquitecto de soluciones tecnológicas en la nube de Amazon es actualmente el principal responsable de ayudar a los clientes con el diseño de la arquitectura de la nube y la consultoría técnica. Tiene un conocimiento profundo de direcciones técnicas como la contenedorización y una rica experiencia en el diseño e implementación de soluciones de migración a la nube.

¡La estrella no se perderá y el desarrollo será más rápido!
Después de seguir, recuerde destacar "Amazon Cloud Developer"

He oído, haz clic en los 4 botones siguientes
¡No encontrarás errores!
