TTS is the abbreviation of Text To Speech, which means "from text to speech". It is a technology that converts text information generated by the computer itself or input from the outside into understandable and fluent spoken Chinese (or other language speech) output, and it belongs to speech synthesis (SpeechSynthesis).
Speech plays a huge role in the development of human beings. Speech is the external form of language. It is the symbol system that most directly records people's thinking activities. It is also one of the most basic and important communication methods for human beings to survive, develop and engage in various social activities.
Letting machines speak has been a dream of mankind for thousands of years. Speech synthesis (Text To Speech) is a scientific practice that humans continue to explore and realize this dream. It is also a technical field that is constantly driven and improved by this dream.

Speech synthesis is an essential part of human-computer interaction. With the rapid development of computer computing and storage capabilities, speech synthesis technology has gradually developed from early rule-based parameter synthesis to splicing and adjustment synthesis based on small samples. It is a splicing synthesis based on large corpus that is more popular now.

At the same time, the naturalness and sound quality of synthesized speech have been significantly improved, meeting people's application needs to a certain extent, thereby promoting its application in actual systems.
The development history of speech synthesis
Before the second industrial revolution, speech synthesis was mainly based on mechanical phoneme synthesis. In 1779, the German-Danish scientist Christian Gottlieb Kratzenstein built a model of the human vocal tract so that it could produce five long vowels.
In 1791, Wolfgang von Kempelen added models of the lips and tongue, enabling it to produce consonants and vowels.
Bell Labs invented the vocoder in the 1930s, which automatically decomposes speech into tones and resonances. This technology was improved by Homer Dudley into a keyboard synthesizer and exhibited at the 1939 New York World's Fair.
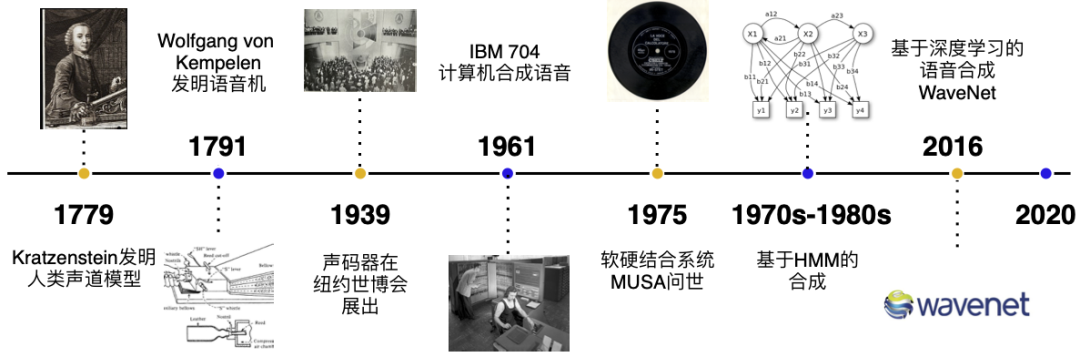
The first computer-based speech synthesis system originated in the 1950s. In 1961, IBM's John Larry Kelly and Louis Gerstman used the IBM 704 computer to synthesize speech, which became one of Bell Labs' most famous achievements.
In 1975, one of the first generation speech synthesis systems, MUSA (MUltichannel Speaking Automation), came out, which consisted of an independent hardware and supporting software. The second version, released in 1978, could also be sung a cappella. The mainstream in the 1990s was to use systems from MIT and Bell Labs and combine them with natural language processing models.
Deep learning-based technology
The current mainstream methods are divided into speech synthesis based on statistical parameters, waveform splicing speech synthesis, hybrid methods, and end-to-end neural network speech synthesis.
Parameter-based speech synthesis includes hidden Markov Model (HMM) and deep learning network (Deep Neural Network, DNN).
The speech synthesis pipeline includes three main modules: Text Frontend, Acoustic Model and Vocoder:
The original text is converted into characters/phonemes through the text front-end module; the characters/phonemes are converted into acoustic features through the acoustic model, such as linear spectrogram, mel spectrogram, LPC features, etc.; the acoustic features are converted into waveforms through the vocoder.
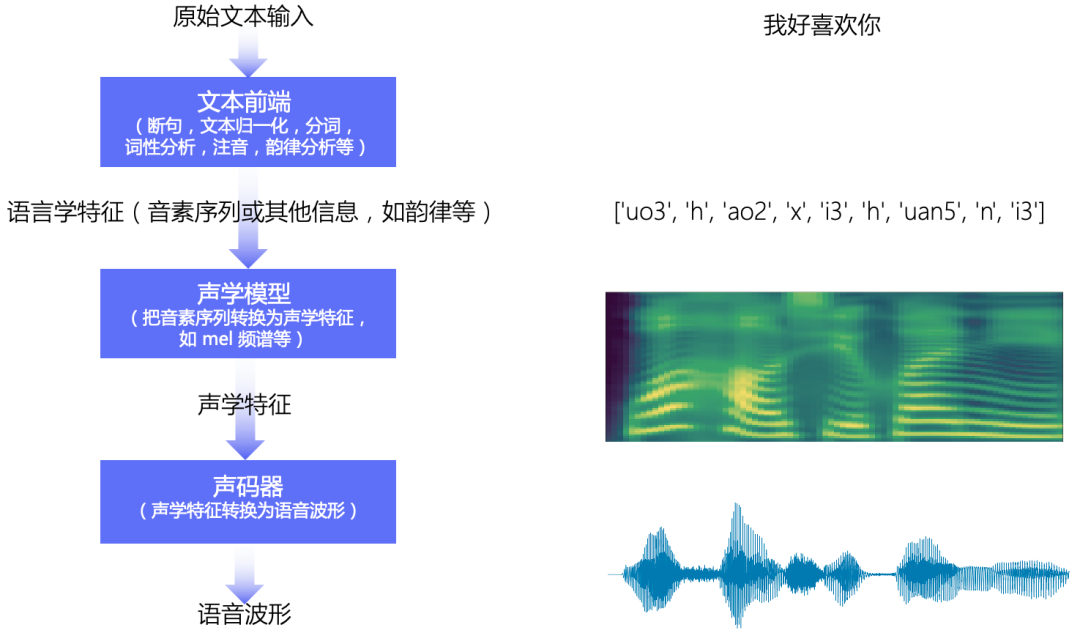
Basic flow chart of speech synthesis
Text frontend
The text front-end module mainly includes: segmentation (Text Segmentation), text normalization (TN), word segmentation (Word Segmentation, mainly in Chinese), part-of-speech tagging (Part-of-Speech, PoS), prosody prediction ( Prosody) and grapheme-to-phoneme (G2P), etc.
acoustic model
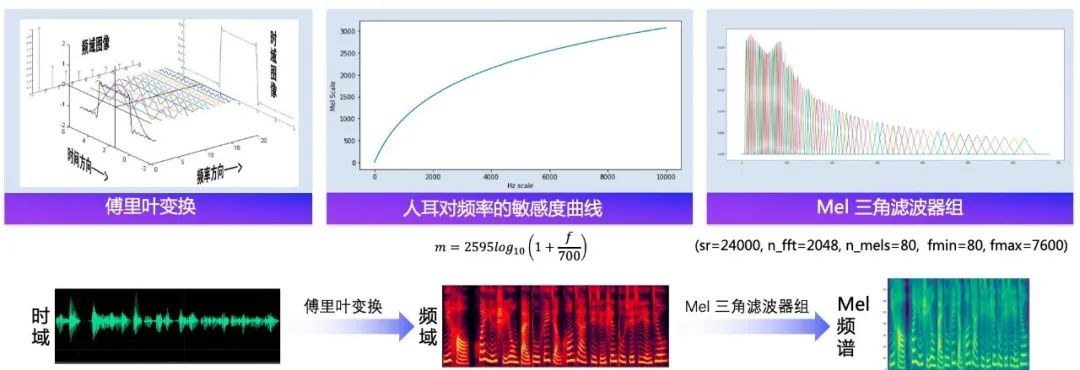
Acoustic models convert characters/phonemes into acoustic features, such as linear spectrograms, mel spectrograms, LPC features, etc. Acoustic features are measured in "frames". Generally, one frame is about 10ms, and one phoneme generally corresponds to about 5 to 20 frames.
What the acoustic model needs to solve is the "mapping problem between sequences of unequal lengths". "Unequal lengths" means that the same person pronounces different phonemes for different durations, and the same person may speak the same sentence at different speeds at different times. The duration corresponding to each phoneme is different. Different people have different speaking characteristics, and the duration corresponding to each phoneme is different.
Vocoder
The vocoder converts acoustic features into waveforms, and what it needs to solve is the "complete problem of missing information." The lack of information means that when the audio waveform is converted into a spectrogram, there is a lack of phase information; when the spectrogram is converted into a mel spectrogram, there is a lack of information caused by frequency domain compression.
Assume that the audio sampling rate is 16kHz, that is, 1s of audio has 16,000 sampling points, and one frame of audio has 10ms. Then 1s contains 100 frames, and each frame has 160 sampling points. The function of the vocoder is to convert a spectrum frame into 160 sampling points of the audio waveform, so the vocoder usually contains an upsampling module.
With the rise of the Internet of Vehicles and smart cars, more and more voice functions are being installed on cars. Xianlin Intelligent will also continue to delve into smart travel scenarios, empower intelligent Internet of Vehicles with cutting-edge AI technology, and bring more benefits to car users. Convenient, safer and warmer voice interaction experience.