Papierinformationen
name_en: Sprechen Sie Fremdsprachen mit Ihrer eigenen Stimme: Sprachübergreifende neuronale Codec-Sprachmodellierung
name_ch: Sprechen Sie Fremdsprachen mit Ihrer eigenen Stimme: Sprachübergreifende neuronale Codec-Sprachmodellierung
paper_addr: http://arxiv.org/abs/ 2303.03926
date_read: 25.04.2023
date_publish: 07.03.2023
Tags: ['Deep Learning','Speech Synthesis']
Autor: Ziqiang Zhang, Microsoft-
Code: https://github.com/microsoft/unilm
1 Feedback
Eine Erweiterung von VALL-E, bei der die Sprache in der Ausgangssprache und der Text in der Zielsprache als Hinweise dienen, sagt die Reihenfolge der akustischen Marker für die Sprache in der Zielsprache voraus, die für Sprach-zu-Sprache-Übersetzungsaufgaben verwendet werden kann. Es kann qualitativ hochwertige Sprache in der Zielsprache erzeugen und gleichzeitig die Stimme, Emotionen und akustische Umgebung unsichtbarer Sprecher bewahren. Dadurch wird das Problem ausländischer Akzente, die über die Sprach-ID gesteuert werden können, wirksam gemildert.
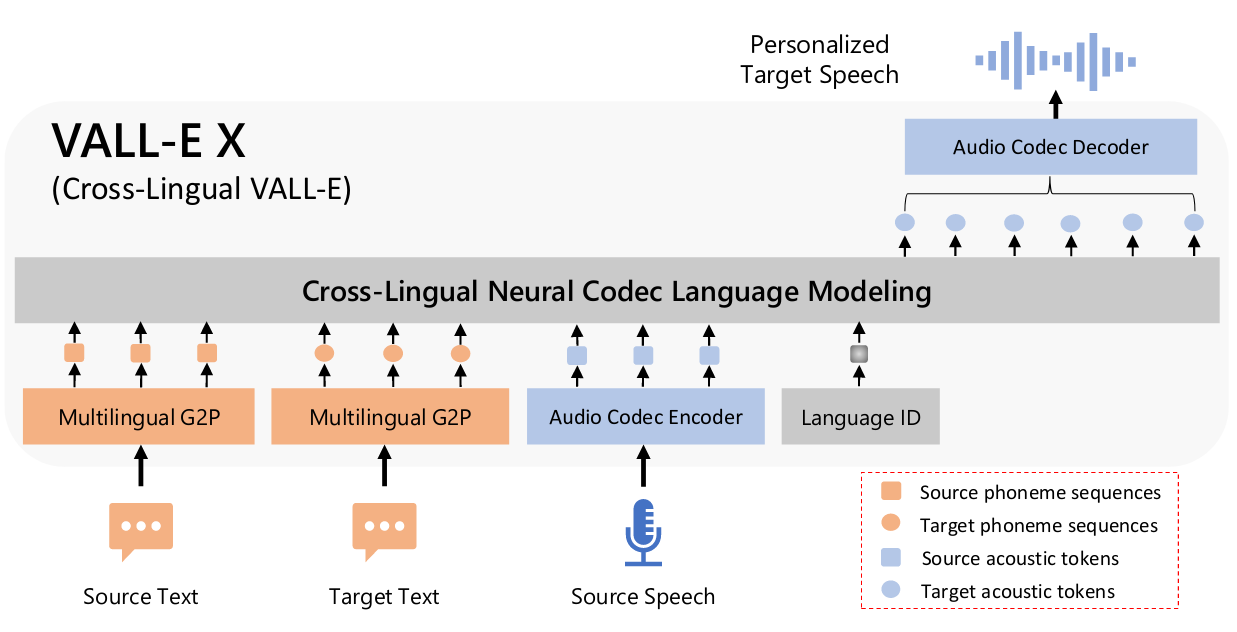
Erzeugt Zielsprache, die durch aus Quell- und Zieltexten abgeleitete Phonemsequenzen und akustische Quellmarker, die aus einem Audio-Codec-Modell abgeleitet sind, angeregt wird.

2. Einführung
Hauptbeiträge
• Vorgeschlagenes bedingtes sprachübergreifendes VALL-EX-Sprachmodell, das die Sprache der Ausgangssprache und den Text der Zielsprache als Eingabeaufforderungen verwendet, um akustische Marker der Zielsprache vorherzusagen.
• Ein mehrsprachiges kontextbezogenes Lernrahmenwerk, das die Stimme, Emotionen und den phonetischen Kontext unsichtbarer Sprecher bewahrt und sich nur auf einen Satzhinweis in der Ausgangssprache verlässt.
• Reduziert deutlich Probleme mit ausländischen Akzenten, ein bekanntes Problem bei sprachübergreifenden Sprachen.
• Anwendung von VALL-EX auf Zero-Shot-Aufgaben zur sprachübergreifenden Text-zu-Sprache-Synthese und Zero-Shot-Sprach-zu-Sprache-Übersetzung. Übertreffen Sie strenge Grundlagen in Bezug auf Sprecherähnlichkeit, Sprachqualität, Übersetzungsqualität, Sprachnatürlichkeit und menschliche Bewertung.
3 Methoden
Zusätzlich zum Modell selbst wird das G2P-Tool in Kombination verwendet, um Text in Phoneme umzuwandeln, und schließlich wird Encodec zum Generieren von Audiodaten verwendet.
3.1 Modellarchitektur
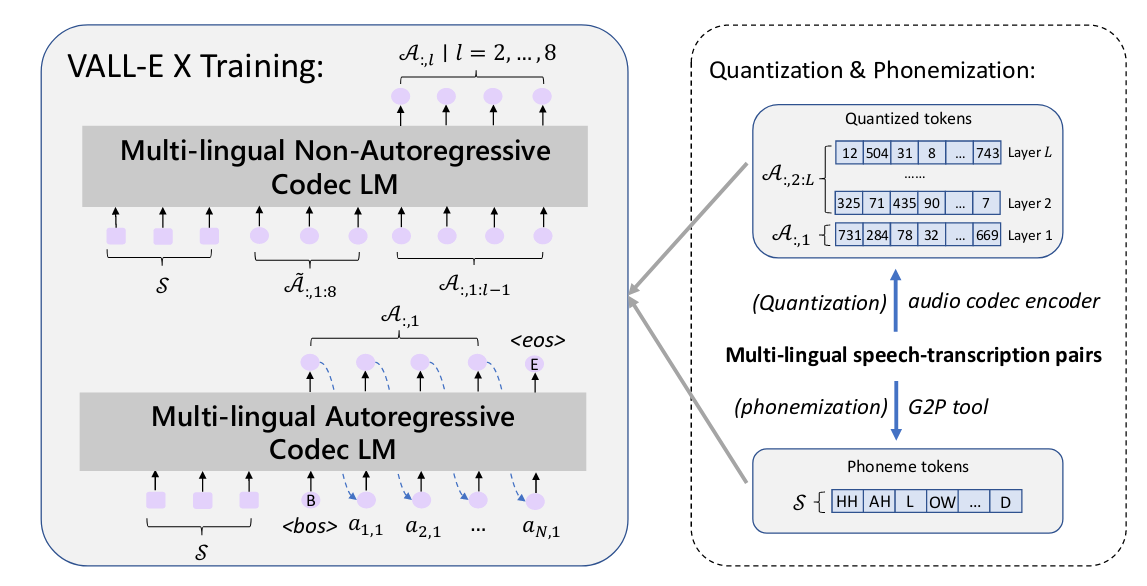
Es besteht aus einem autoregressiven Multi-Speech-Encoder und einem nicht-autoregressiven Encoder.
Mehrsprachige akustische Marker (A) und Phonemsequenzen (S) werden mithilfe von Encoder- bzw. G2P-Tools aus Sprache und Transkription transformiert. Während des Trainings werden die beiden Modelle mithilfe der Paare S und A aus verschiedenen Sprachen optimiert. Semantische Marker in diesem Artikel beziehen sich auf Phonemsequenzen.
3.2 Mehrsprachige Ausbildung
Ein zweisprachiger Sprachtranskriptionskorpus (ASR) wird mit Paaren von (Ss, As) und (St, At) verwendet, um ein mehrsprachiges Modell zu trainieren.
Darüber hinaus werden Sprach-IDs verwendet, um die sprachspezifische Sprachgenerierung in VALL-EX zu steuern. Da es mit mehrsprachigen Daten trainiert wird, kann es verwirrend sein, das passende akustische Token für eine bestimmte Sprache auszuwählen, wenn Sie die ID nicht angeben. Beispielsweise ist Chinesisch eine Tonsprache, während Englisch eine nicht-tonale Sprache ist. Dies war überraschend effektiv bei der Steuerung des korrekten Sprechstils und der Milderung von Akzentproblemen, insbesondere durch die Einbettung von Sprach-IDs in dichte Vektoren und deren Hinzufügung zu den akustisch gekennzeichneten Einbettungen.
3.3 Mehrsprachiges Denken
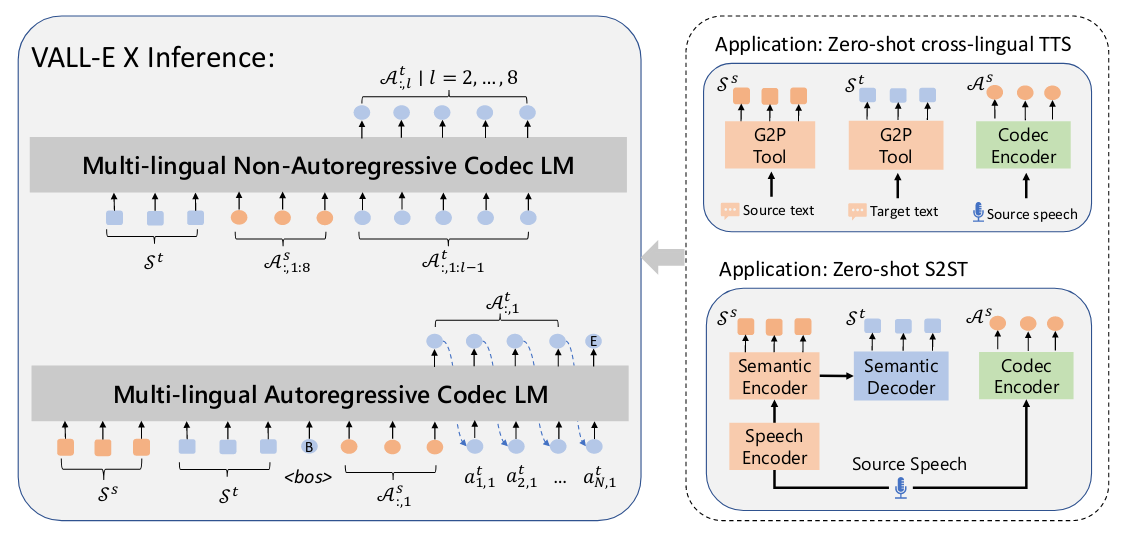
Die Eingaben für die autoregressiven und nicht-autoregressiven Modelle sind unterschiedlich; der Prozess der Sprache-zu-Sprache-Übersetzung ist rechts dargestellt.
Bei einer Quellsprache Xs generiert das Spracherkennungs- und Übersetzungsmodell zunächst ein Quellphonem Ss von einem semantischen Encoder und ein Zielphonem St von einem semantischen Decoder. Darüber hinaus wird X mithilfe des EnCodec-Encoders komprimiert, um akustische Markierungen As zu erzeugen. Anschließend werden Ss, St und As als Eingabe von VALL-EX verkettet, um die Sequenz akustischer Marker der Zielsprache zu generieren. Verwenden Sie den Decoder von EnCodec, um die generierten akustischen Markierungen in die endgültige Zielsprache umzuwandeln.
4 Relevantes Wissen
- SpeechUT: SpeechUT ist ein modalübergreifendes, vorab trainiertes Modell zur Verbindung von Sprache und Text. Es verwendet versteckte Einheiten als Schnittstelle zum Ausrichten von Sprache und Text und verbindet die Darstellungen des Sprach-Encoders und des Text-Decoders mit einem gemeinsam genutzten Unit-Encoder.
- G2P Tool ist die Abkürzung für Grapheme-to-Phoneme Tool, ein Tool zum Konvertieren von Graphemen von Wörtern in Phoneme. Die Implementierung erfolgt mithilfe eines rekurrenten neuronalen Netzwerks.