Código de codificación:
moco
pcl
Directorio de artículos
- Representación semántica para el modelado de diálogos
- PCL: aprendizaje contrastivo entre pares con diversos aumentos para incrustaciones de oraciones no supervisadas
- Atribución axiomática para redes profundas
- Comportamiento de aprendizaje abreviado de modelos NLU
- MoCo: Aprendizaje no supervisado de contraste de impulso
- Aprendizaje mutuo profundo-Aprendizaje mutuo profundo: cuando tres personas caminan juntas, debe haber un maestro.
- TRANS-ENCODER Codificador bi y cruzado de frases autosupervisado
- Espejo-Bert
- Aprendizaje contrastivo autoguiado para representaciones de oraciones BERT
- Resumen del artículo de Label Denoise: serie de capacitación conjunta
- CLARO: Aprendizaje contrastivo para la representación de oraciones
- ESimCSE
- ClasificaciónCSE
- aumento de datos
- ViLBERT
- r-cnn más rápido
- Fusión de características multimodales
- aprendizaje contrastivo
- computación semántica
Representación semántica para el modelado de diálogos
Representación de significado abstracto (AMR) para ayudar con el modelado de conversaciones
Representación de oraciones basada en diálogos
https://zhuanlan.zhihu.com/p/437790124
Mapeo de relaciones de nodo a palabra: un alineador AMR ajustado por un analizador basado en transiciones
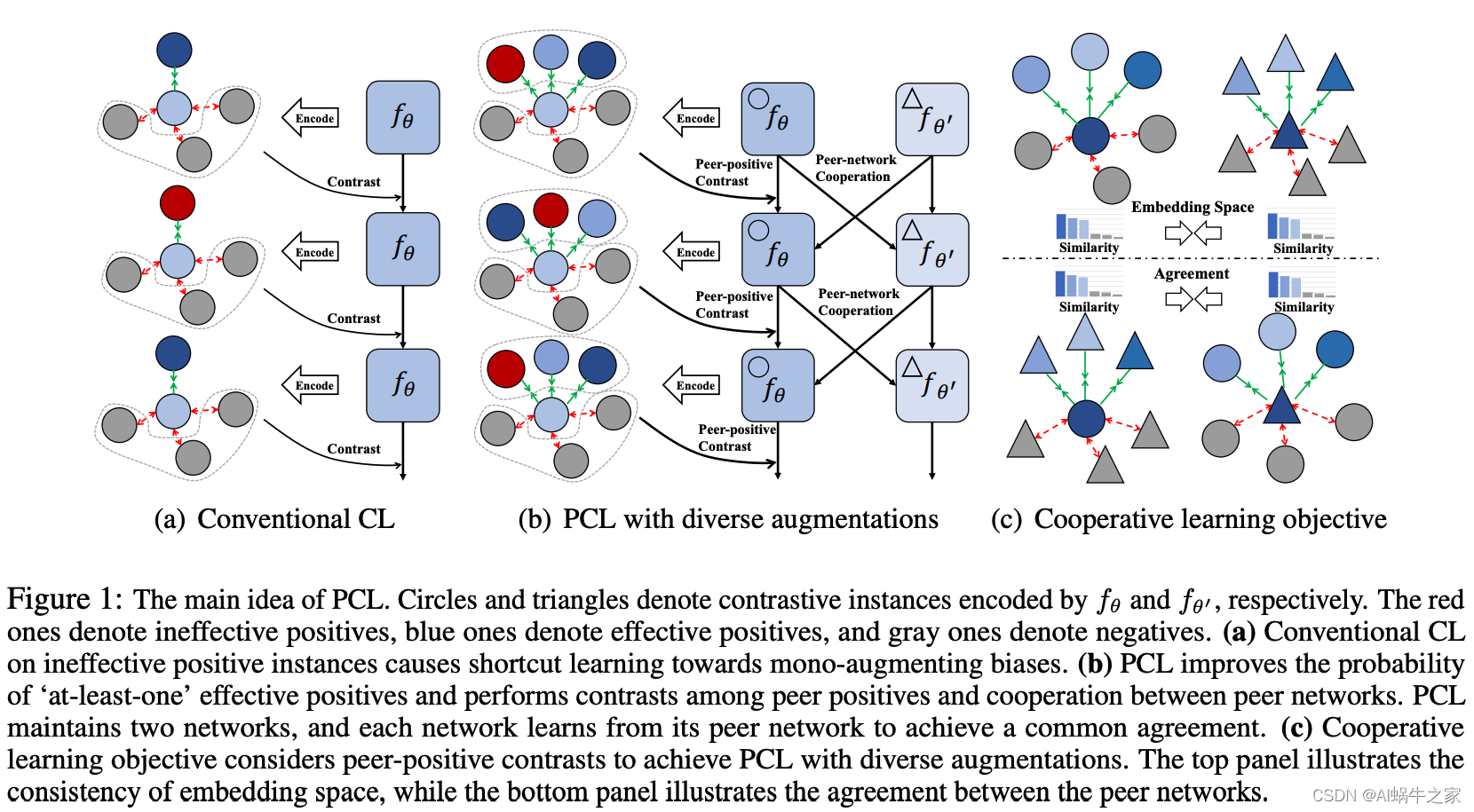
PCL: aprendizaje contrastivo entre pares con diversos aumentos para incrustaciones de oraciones no supervisadas
Dos métodos de aprendizaje comparativo para encontrar muestras positivas: discreto (formato de aumento discreto) y continuo (formato de aumento continuo):
- Formato de aumento discreto: modifique muestras positivas directamente a través de caracteres o n-gramas, como reemplazo de sinónimos, mezcla de palabras, eliminación de palabras y traducción inversa;
- Formato de aumento continuo: a través de variables ocultas, como dos abandonos en SimCSE
Motivación :
los modelos actuales utilizan métodos discretos o métodos continuos, pero todos utilizan un único método de mejora (formato monoaumento) y tienen estrategias de mejora limitadas, lo que conduce a "atajos de aprendizaje" en los métodos anteriores. Por ejemplo, un modelo entrenado basándose en dos muestras positivas abandonadas tiende a juzgarse por la longitud de la oración.
Una pequeña enciclopedia de puntos de conocimiento :
- Aprendizaje atajo:
los modelos de lenguaje previamente entrenados como BERT han mostrado un rendimiento excelente en muchas tareas de NLU, pero investigaciones recientes muestran que dichos modelos tienden a explotar el sesgo del conjunto de datos e intentan utilizar "atajos" para lograr resultados más altos. rendimiento en lugar de comprender verdaderamente el idioma. Esto a menudo conduce a un rendimiento deficiente de la generalización del modelo en muestras OOD y a una escasa solidez frente a ataques adversarios.
Considere específicamente la tarea de clasificación: muestra dada xxx , el modelo necesita aprender un mapeof ( x ) f(x)f ( x ) para predecir la etiquetayyy . Durante el proceso de formación, si algunas palabras o frases están asociadas a una determinada etiquetayyEl número de co-ocurrencias de y es mayor que el de otras palabras, y el modelo capturará dichas características para su predicción. De acuerdo con el supuesto de distribución idéntica e independiente, los conjuntos de entrenamiento, validación y prueba se muestrean a partir de la misma distribución de datos, por lo que incluso si el modelo captura tales características abreviadas para la predicción, el rendimiento en el conjunto de prueba no será deficiente. Sin embargo, cuando se expone a datos fuera de distribución (muestras OOD) y muestras adversas (muestras adversarias), el modelo mostrará una generalización y robustez deficientes porque no son necesariamente los mismos que los datos del conjunto de entrenamiento.
El método
utiliza simultáneamente múltiples métodos para mejorar muestras positivas (discretas + continuas), pero el uso de múltiples métodos de mejora también tiene un arma de doble filo: múltiples métodos de mejora pueden hacer que no se pueda garantizar la calidad de la muestra. Proponemos un nuevo marco de aprendizaje de contraste entre pares que no solo puede realizar contrastes de contraste directo ordinarios, sino también comparaciones de contraste directo.
Proponemos un nuevo marco de aprendizaje contrastante entre pares que no solo realiza el contraste positivo-negativo básico sino también un contraste positivo-positivo.
Atribución axiomática para redes profundas
-
Cómo los seres humanos hacen atribuciones
Los seres humanos suelen confiar en la intuición contrafáctica al hacer atribuciones. Cuando los humanos atribuyen cierta responsabilidad a una causa, implícitamente utilizan la ausencia de esa causa como punto de referencia para la comparación. Por ejemplo, si el motivo de querer dormir es que tienes sueño, no querrás dormir cuando no tengas sueño. -
Atribución de red profunda
Basada en el principio de atribución humana, la atribución de red profunda también requiere una entrada de referencia para simular la ausencia de causas. En muchas redes profundas, existe una línea de base natural en el espacio de entrada. Por ejemplo, en una red de reconocimiento de objetos, una imagen en negro puro es la línea de base. La definición formal de atribución de red profunda se proporciona a continuación:
Supongamos que hay una función FFF :R norte → [ 0 , 1 ] R^n \a [0,1]Rnorte→[ 0 ,1 ] , que representa una red neuronal. La entrada a la red esx = ( x 1 , . . . , xn ) ∈ R nx=(x_1,...,x_n) \in R^nX=( x1,... ,Xnorte)∈Rn , entoncesxxx en comparación con la entrada de referenciax ′ ∈ R n x'\in R^nX′∈RLa atribución de n es un vectorAF ( x , x ′ ) = ( a 1 , . . . , an ) ∈ R n A_F(x,x')=(a_1,...,a_n) \in R^nAF( x ,X′ )=( un1,... ,anorte)∈Rn , dentrode ai a_iayoes la entrada xi x_iXyoContribución al resultado de la predicción F(x). -
La importancia de la atribución
: en primer lugar, en el escenario de utilizar redes neuronales de imágenes para predecir enfermedades, la atribución puede ayudar a los médicos a comprender qué parte hizo que el modelo pensara que el paciente está enfermo; en segundo lugar, la atribución de red profunda se puede utilizar para proporcionar información para la regla. sistemas basados en ;Finalmente, la atribución también se puede utilizar para informar las estructuras de recomendación. -
Aplicación del método de gradiente integral
1. Selección de la línea de base
1.1 El paso clave al aplicar el método de gradiente integral es elegir una buena línea de base. La puntuación de la línea de base en el modelo es preferiblemente cercana a 0, lo que ayuda a interpretar los resultados de la atribución.
1.2 La línea de base debe representar una muestra completamente no informativa para que se pueda distinguir si la causa proviene de la entrada o de la línea de base.
1.3 En la tarea de imagen, puedes elegir una imagen completamente negra o una imagen compuesta de ruido. En tareas de texto, utilizar una incrustación de todos 0 es una mejor opción.
La imagen completamente negra en la imagen 1.4 también representa una entrada significativa, pero el vector completamente 0 en el texto no tiene ningún significado válido.
2. Calcule el gradiente integral.
El gradiente integral se puede aproximar eficientemente mediante suma. Solo necesita ser la línea base x ′ x'X′ axxLos gradientes de puntos suficientemente espaciados en la recta x pueden ser similares.
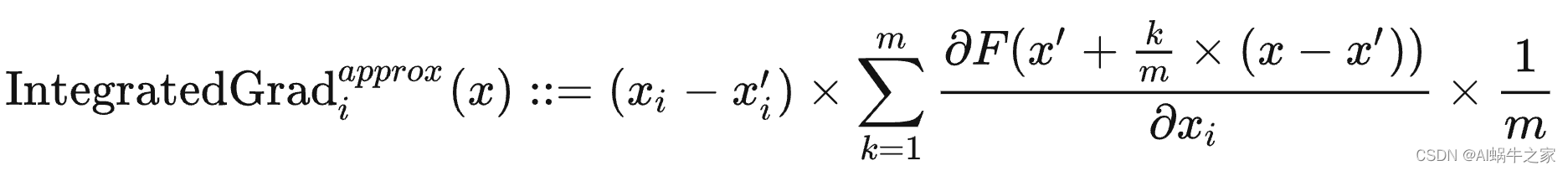
Entre ellosmmm es el orden de aproximación (el orden de expansión de Taylor),mmCuanto mayor es m , más aproximado es, pero la cantidad de cálculo también es mayor.
En la prácticammm puede estar entre 20 y 300.
Comportamiento de aprendizaje abreviado de modelos NLU
Hacia la interpretación y mitigación del comportamiento de aprendizaje abreviado de los modelos NLU
https://zhuanlan.zhihu.com/p/363904438
MoCo: Aprendizaje no supervisado de contraste de impulso
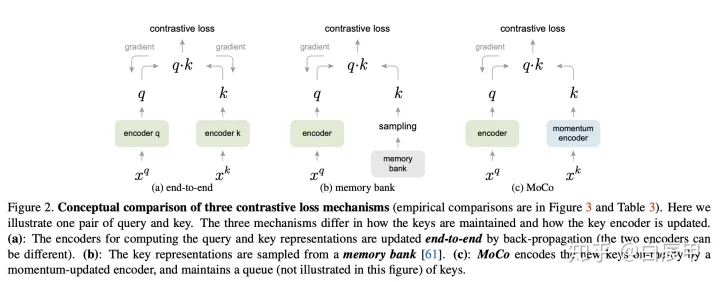
https://zhuanlan.zhihu.com/p/158023072
Aprendizaje mutuo profundo-Aprendizaje mutuo profundo: cuando tres personas caminan juntas, debe haber un maestro.
https://zhuanlan.zhihu.com/p/71192348
El algoritmo de destilación del modelo fue propuesto por Hinton et al. en 2015. Utiliza una red grande previamente entrenada como profesora para proporcionar a la red pequeña conocimientos adicionales, es decir, estimaciones de probabilidad suavizadas. Los experimentos muestran que la red pequeña puede imitar el Probabilidades de categoría estimadas por la red grande. El proceso de optimización se vuelve más fácil y muestra un rendimiento similar o mejor que las redes grandes. Sin embargo, el algoritmo de destilación del modelo requiere una red grande que haya sido entrenada previamente, y la red grande permanece fija durante el proceso de aprendizaje. Solo realiza una transferencia de conocimiento unidireccional a la red pequeña y es difícil obtener retroalimentación. Información del estado de aprendizaje de la pequeña red para mejorar el proceso de formación.Ajustes optimizados.
Intentamos explorar un mecanismo de capacitación que pueda aprender redes grandes y pequeñas más sólidas: el aprendizaje mutuo profundo, que utiliza múltiples redes para capacitarse al mismo tiempo. Durante el proceso de capacitación, cada red no solo acepta la supervisión de las etiquetas de verdad del terreno, sino que también se refiere a la experiencia Aprender de la red de pares para mejorar aún más las capacidades de generalización. A lo largo del proceso, las dos redes continuaron compartiendo experiencias de aprendizaje y logrando un aprendizaje mutuo y un progreso común.
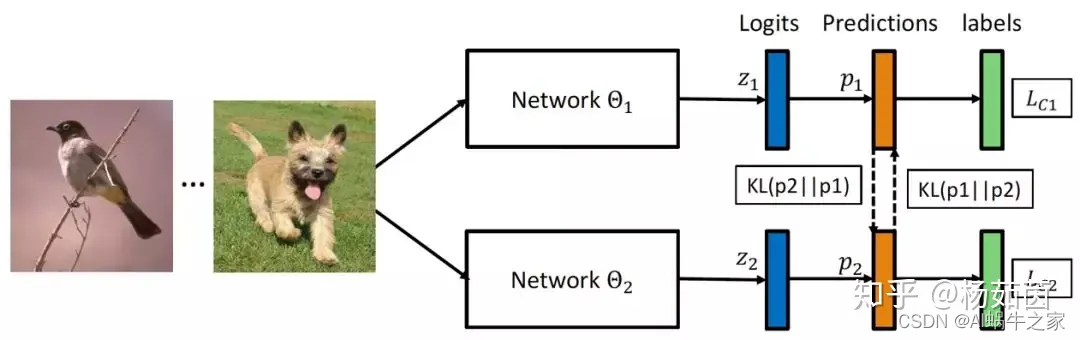

Nuestro algoritmo de aprendizaje mutuo propuesto también se extiende fácilmente a escenarios de aprendizaje multired y aprendizaje semisupervisado. Cuando hay redes K, el aprendizaje mutuo profundo utiliza las redes K-1 restantes como maestros para brindar experiencia de aprendizaje al aprender cada red. Otra estrategia es fusionar las redes K-1 restantes para obtener un maestro que brinde experiencia de aprendizaje. En el escenario de aprendizaje mutuo semisupervisado, calculamos la pérdida supervisada y la pérdida de interacción para los datos etiquetados, mientras que para los datos no etiquetados solo calculamos la pérdida de interacción para ayudar a la red a extraer información más útil de los datos de entrenamiento.
En términos generales, las redes pequeñas se benefician más de la capacitación en aprendizaje mutuo, como Resnet-32 y MobileNet. Aunque la red WRN-28-10 tiene una gran cantidad de parámetros, aún se pueden lograr mejoras de rendimiento mediante el aprendizaje mutuo con otras redes. Por lo tanto, a diferencia de los algoritmos de destilación de modelos que requieren un entrenamiento previo de redes grandes para ayudar a las redes pequeñas a mejorar el rendimiento, el algoritmo de aprendizaje mutuo profundo que proponemos también puede ayudar a las redes grandes que participan en el entrenamiento a mejorar su rendimiento.
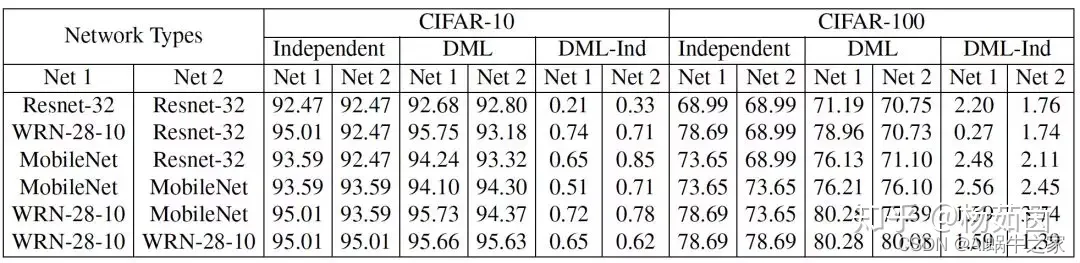
Podemos ver en la Figura 3 que aumentar el número de redes puede mejorar el rendimiento de una sola red bajo la estrategia de aprendizaje mutuo, lo que muestra que más redes de profesores brindan más experiencia de aprendizaje y ayudan a la red a aprender mejores características. Por otro lado, el desempeño de múltiples docentes independientes (DML) en el aprendizaje mutuo en múltiples redes será mejor que el de los docentes fusionados (DML_e), lo que demuestra que múltiples redes de docentes diferentes pueden proporcionar experiencias de aprendizaje más diversas y son más beneficiosas para los estudiantes. cada red de aprendizaje.
¿Cuál será el efecto de las redes heterogéneas?
TRANS-ENCODER Codificador bi y cruzado de frases autosupervisado
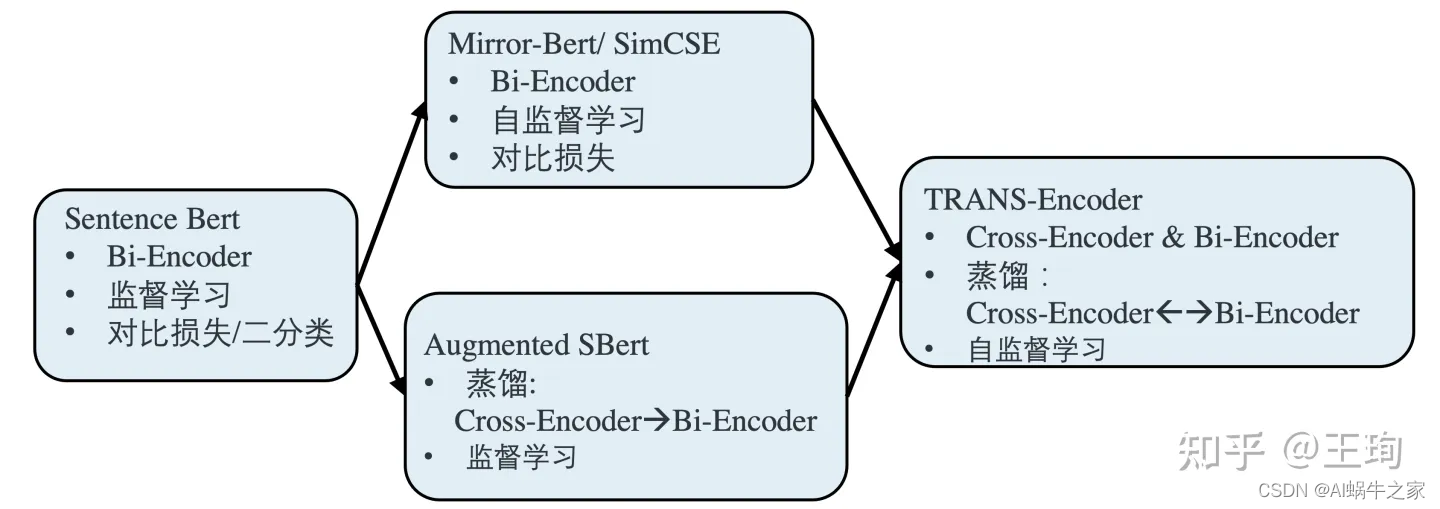
motivación:
Dado que el efecto de autosupervisión es excelente, ha igualado o incluso superado el aprendizaje supervisado en Bi-Encoder, y Cross-Encoder es generalmente más efectivo que Bi-Encoder, por lo que no puedo evitar preguntarme por qué no unir fuerzas y autocontrol. supervisión. Un Cross-Encoder está saliendo para el aprendizaje supervisado.
pregunta:
Luego viene la dificultad. No existe un marco autosupervisado listo para usar para el aprendizaje autosupervisado de un Cross-Encoder. Si insistimos en copiar SimCSE/Mirror-Bert, uniremos una oración y su aumento en el Cross-Encoder. Y deje que el modelo juzgue. ¿Es similar? Este ejemplo positivo es demasiado simple para el modelo, y lo mismo ocurre con el ejemplo negativo. Es difícil para el modelo aprender información efectiva en un diseño de tarea autosupervisado de este tipo; la razón por la que se puede usar Bi-encoder es porque las dos oraciones se pasan a través del modelo por separado y la similitud se calcula en el resultado final. Esta tarea tiene ciertos requisitos para Bi-encoder.de dificultad.
plan:
La solución al problema es combinar la destilación de conocimientos y el aprendizaje autosupervisado. Según la figura anterior, primero entrenamos un potente modelo Bi-Encoder de acuerdo con el aprendizaje autosupervisado y luego usamos el modelo Bi-Encoder como maestro para Utilice la destilación de conocimientos para entrenar un Cross-Encoder. Vale la pena señalar que, aunque Cross-Encoder es un estudiante, el límite superior de su propia arquitectura de modelo es más fuerte que el de su maestro Bi-Encoder, por lo que puede ser mejor que su predecesor. Destilación de conocimientos, su efecto de modelo es mejor que Bi-Encoder. Este es el primer paso del modelo: Bi-Encoder —> Cross-Encoder.
Luego, el segundo paso es simple: tenemos un modelo de similitud semántica de Cross-Encoder que es más fuerte que Bi-Encoder. Luego, similar a Augmented SBert, podemos usar Cross-Encoder como nuestro maestro y destilación de conocimientos para mejorar Bi-Encoder. En este punto, el camino más amplio está a la vista. Los dos pasos anteriores pueden repetirse y llevarse a cabo de forma iterativa; los dos modelos son maestros el uno del otro, se enseñan mutuamente y se fortalecen juntos.
Algunos pequeños detalles:
El artículo está inteligentemente concebido y es simple: en términos de función de pérdida, la función de pérdida de Bi-Encoder -> Cross-Encoder es la pérdida de entropía cruzada binaria BCE; la función de pérdida de Cross-Encoder -> Bi-Encoder es la pérdida de error cuadrático medio MSE. Al mismo tiempo, el diseño de la red también es muy elegante. Bi-Encoder y Cross-Encoder comparten la estructura de la red. La única diferencia es que la entrada de Bi-Encoder es una sola oración, mientras que la entrada de Cross-Encoder es [ CLS] enviado1 [SEP] enviado2 [SEP]. El método del artículo ha logrado grandes mejoras en varios puntos de referencia.
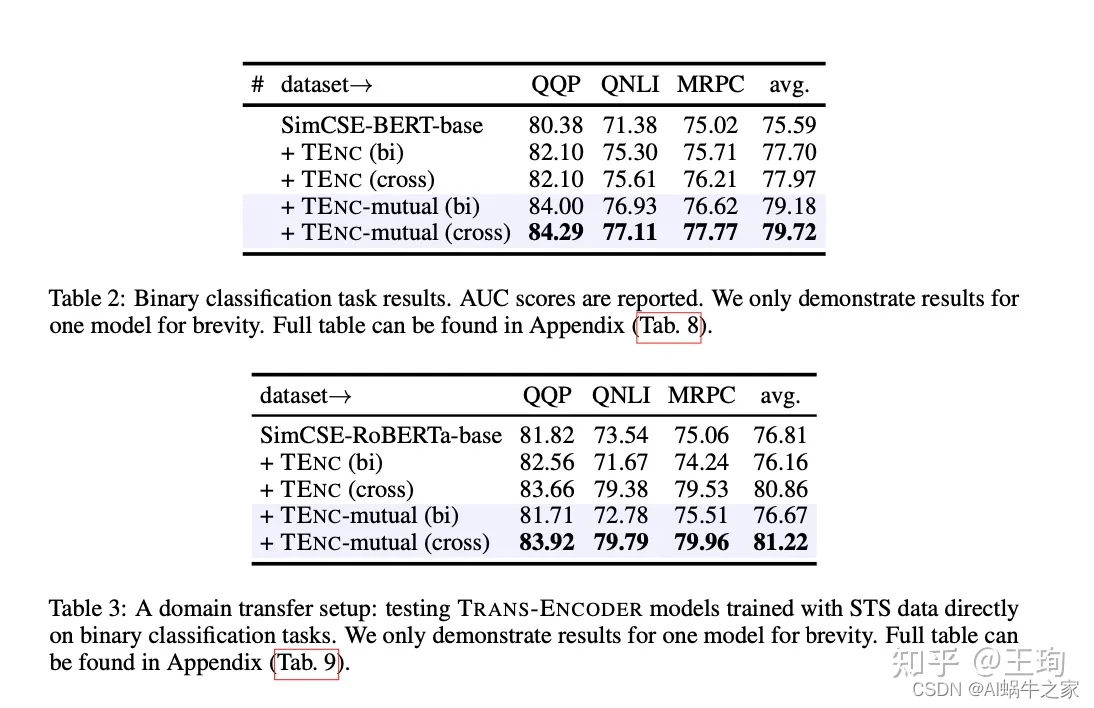
Referencia:
TRANS-ENCODER: modelo de pares de oraciones no supervisadas para autodestilación y destilación mutua.
Intercambio de artículos: codificador bi y cruzado de oraciones autosupervisado
Espejo-Bert
Antecedentes relacionados
El entrenamiento de aprendizaje contrastivo utiliza la función de pérdida InfoNCE[1] como objetivo del entrenamiento, con el objetivo de acercar la representación de oraciones similares a la oración actual dentro de un lote, alejar la representación de oraciones diferentes y medir la distancia entre representaciones de oraciones mediante coseno. similitud. . En el aprendizaje contrastivo, la clave es construir pares de ejemplos positivos diversos y de alta calidad. Aquí hay una lista de los métodos de construcción de ejemplos positivos utilizados recientemente por varios métodos de aprendizaje comparativo en la Figura 1, que se dividen principalmente en dos niveles:
- Modificaciones en el nivel de entrada de texto
Eliminación aleatoria de palabras (ConSERT[2], CLEAR[3])
Eliminación aleatoria de palabras consecutivas (ConSERT, CLEAR, Mirror-BERT)
Interrupción del orden de entrada (ConSERT, CLEAR)
Reemplazo de sinónimos (CLEAR) - Construir diferentes perspectivas a nivel de característica.
Enmascarar aleatoriamente una cierta dimensión de características (ConSERT).
Dos resultados de abandono diferentes (ConSERT, SimCSE, Mirror-BERT).
Agregar perturbación de ruido (ConSERT).
Dos modelos diferentes proporcionan características desde diferentes perspectivas (Self -Guía Contrastiva).Aprendizaje[4], CT[5])
Introducción al método
En este artículo, Mirror-BERT utiliza principalmente la eliminación aleatoria de palabras consecutivas y la estrategia de abandono para construir ejemplos positivos. Otros trabajos también han demostrado que el abandono es una forma simple y efectiva de construir ejemplos positivos para el aprendizaje contrastivo. A juzgar por trabajos recientes relacionados con el aprendizaje contrastivo, no dañar demasiado la oración original puede garantizar la calidad de los ejemplos positivos construidos. También se ha demostrado que, sin considerar la eficiencia del entrenamiento, se puede entrenar un modelo adicional para proporcionar representación de oraciones. desde otra perspectiva eficiente.

Preste más atención a los resultados de STS: en comparación con SimCSE, los resultados promedio no son tan buenos como los de SimCSE y algunas tareas son ligeramente mejores.
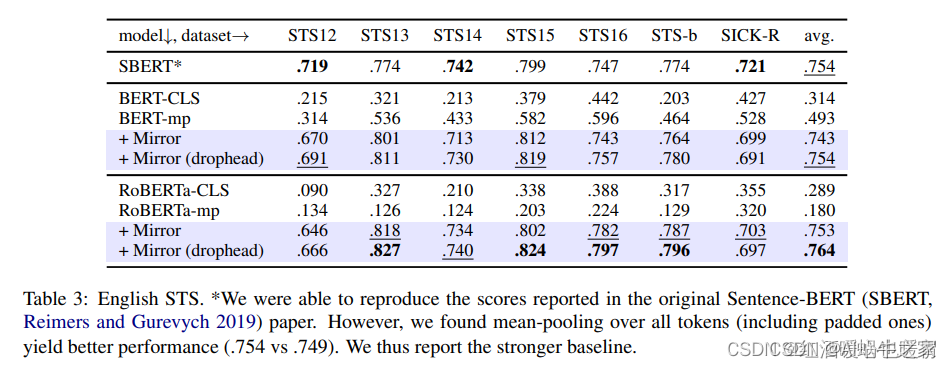
Mirror usa 10k datos en diferentes tareas. En mi impresión, SimCSE usa más datos. Después de verificar: tomamos muestras aleatorias de 1 0 6 10^610 6 oraciones de Wikipedia en inglés y ajustamos la base BERT con una tasa de aprendizaje = 3e-5,
N
= 64. En todos nuestros experimentos, no se utilizan conjuntos de entrenamiento STS. Pero mire la imagen a continuación: Mirror-Bert puede lograr los mejores resultados para la mayoría de las tareas entre 10k y 20k.
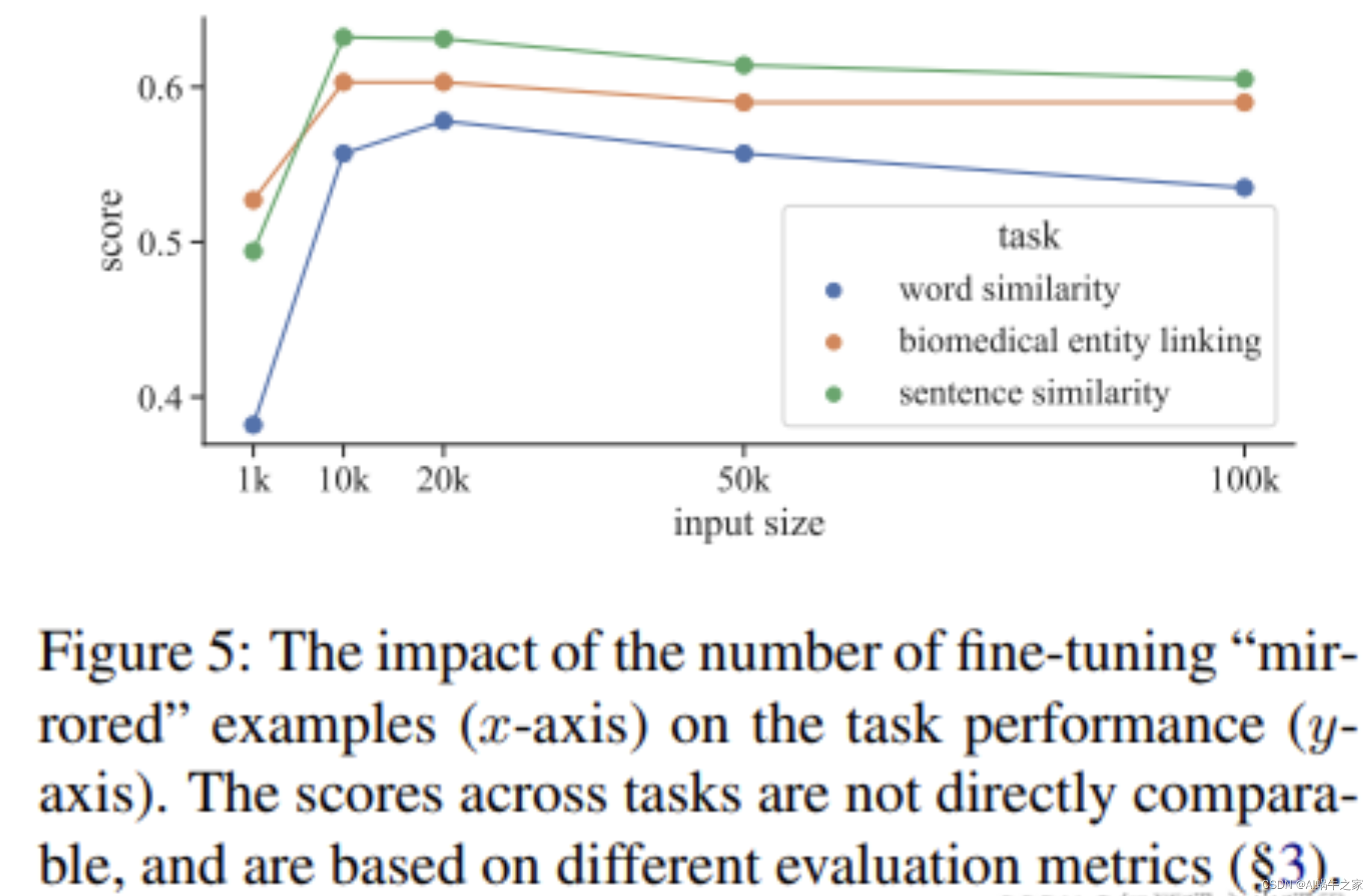
En la prueba de ablación realizada en la tarea STS, la máscara de extensión juega un papel más importante, pero el mejor efecto se logra cuando las dos se usan juntas. donde método drophead: elimina aleatoriamente las cabezas de atención en el entrenamiento de MLM como paso de regularización
¿Mirror-BERT mejora la isotropía? Eso parece

Desde la perspectiva de la mejora de datos, SimCSE es de hecho un caso especial, pero SimCSE extiende el método de comparación a supervisado y no supervisado, y el efecto es de hecho mejor que Mirror-Bert. También es obra de la diosa danqi. Si quieres leer el capítulo, te recomiendo leer SimCSE.
Enlace de referencia:
Rápido, eficaz y autosupervisado:Mirror-BERT
Aprendizaje contrastivo autoguiado para representaciones de oraciones BERT
Desde la Universidad Nacional de Seúl, la pregunta discutida es ¿cómo utilizar la propia información de BERT para comparar sin introducir recursos externos o mejorar los datos de visualización, a fin de obtener una representación de oraciones de mayor calidad?
La comparación en este artículo es: la representación de la capa intermedia de BERT y la representación final de CLS. El modelo contiene dos BERT. Los parámetros de un BERT son fijos y se utilizan para calcular la representación de la capa intermedia. El cálculo se divide en dos pasos: (1) Utilice MAX-pooling para obtener la representación del vector de oración de cada capa (2 ) Utilice muestreo uniforme: el método muestrea una representación de la capa N, el otro BERT se ajusta y se utiliza para calcular la representación de la oración CLS. Se obtienen dos representaciones de la misma oración a través de dos BERT, formando así un ejemplo positivo, y el ejemplo negativo es la representación de la capa intermedia de otra oración o la representación del CLS final.

Resumen del artículo de Label Denoise: serie de capacitación conjunta
En la investigación sobre la eliminación de ruido de etiquetas, existe un método que espera actualizar los parámetros de la red seleccionando instancias limpias/conjuntos limpios. En general, se cree que los datos con pérdidas menores son más confiables y pueden considerarse conjuntos limpios.
Enlace de referencia:
Resumen del artículo de Label Denoise: serie de capacitación conjunta
CLARO: Aprendizaje contrastivo para la representación de oraciones
CLEAR diseñó un modal de lenguaje de máscara para representar características a nivel de palabra y utilizó el aprendizaje contrastivo para representar características a nivel de oración. El aprendizaje contrastivo acerca los resultados después de la mejora de datos de la misma oración (como ejemplos positivos) y mejora los datos de diferentes oraciones y diferentes oraciones más alejadas (como ejemplos negativos). Al acercar oraciones con significados similares, se puede aprender mejor la información semántica a nivel de oración.
Las aportaciones de este artículo son las siguientes:
1. Se diseñan cuatro métodos de mejora de datos: eliminación aleatoria de palabras, eliminación de intervalos, eliminación aleatoria continua de tokens, sustitución de sinónimos y reordenamiento.
2. Diseñe una idea de aprendizaje contrastivo para representar mejor la semántica a nivel de oración.
3. Ha logrado buenos resultados en muchas tareas posteriores.
En realidad, el efecto es promedio en comparación con el último:

ESimCSE
Mediante el aprendizaje contrastivo, se utiliza un método autosupervisado para calcular la entropía cruzada de la pérdida y aprender la similitud de muestras positivas y negativas mediante la clasificación softmax. ESimCSE es una versión mejorada de SimCSE. SimCSE aprende la relación entre la coincidencia de textos eliminando dos oraciones para generar dos muestras positivas y negativas similares para el aprendizaje comparativo. ESimCSE resuelve dos problemas dejados por SimCSE:
1. Los pares de ejemplos positivos construidos por SimCSE mediante abandono contienen información de la misma longitud (motivo: incrustación de posición del transformador), lo que hará que el modelo tienda a pensar que oraciones de longitud igual o similar son semánticamente más similares
2. Un tamaño de lote mayor hará que el rendimiento de SimCSE disminuya;
Los métodos de ESimCSE para construir pares de muestras positivas: **Repetición de palabras (repetición de palabras)** y **Contraste de impulso (aprendizaje de contraste de impulso)** amplían los pares de muestras negativos.
ClasificaciónCSE
Implementación de código no oficial: https://github.com/perceivedshawty/RankCSE
El aprendizaje contrastivo no solo debe considerar si hay pares positivos y negativos entre muestras, sino que también debe considerar relaciones de similitud más detalladas. La puntuación del punto de anclaje de muestras positivas y negativas no solo puede utilizar InfoNCE para separar la representación de muestras positivas y todas las muestras negativas, sino que también debe agregar información de clasificación.
(1) objetivo de aprendizaje contrastivo estándar (§4.2);
(2) pérdida de coherencia en la clasificación que garantiza la coherencia en la clasificación entre dos representaciones con diferentes máscaras de abandono (§4.3);
(3) pérdida por destilación de clasificación que destila el conocimiento de clasificación del profesor en forma de lista

Dos tipos de clasificación: garantizar la coherencia de dos clasificaciones de abandono, utilizar el modelo de profesor para destilar la información de clasificación entre muestras al modelo de estudiante;
-
Cambiando la ecuación:
ζ info NCE = − ∑ i = 1 N logexp ( d ( f ( xi ) , f ( xi ) ′ ) / τ 1 ∑ j = 1 N exp ( d ( f ( xi ) , f ( xj ) ′ ) / τ 1 ) \zeta_{infoNCE} = -\sum_{i=1}^N log\frac{exp(d(f(x_i),f(x_i)')/\tau_1}{\sum_{ j =1}^N exp(d(f(x_i),f(x_j)')/\tau_1)}gramoen f o NCE=−yo = 1∑norteiniciar sesión _∑j = 1nortee x p ( d ( f ( xyo) ,f ( xj)′ )/t1)e x p ( d ( f ( xyo) ,f ( xyo)′ )/t1 -
Clasificación de coherencia: alinee el denominador infoNCE de dos hacia adelante. Específicamente, para una muestra, las dos distribuciones de clasificación alineadas se calculan para el emb de la primera propagación hacia adelante de la muestra y la segunda propagación hacia adelante de todas las muestras en lotes. La distribución de clasificación y la distribución de clasificación invertida. Calcule la divergencia JS de estas dos distribuciones.
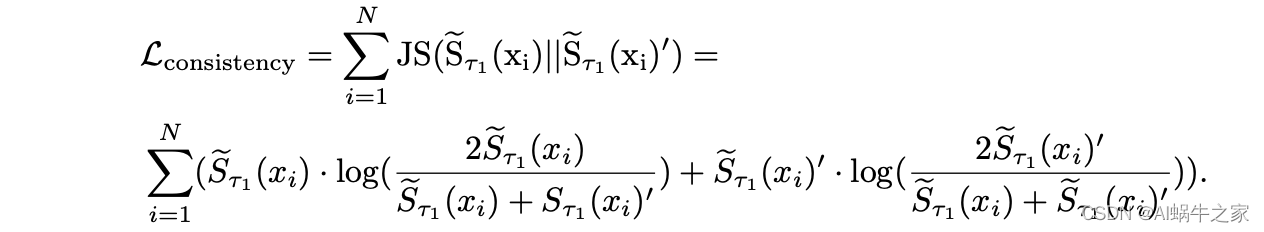
-
Destilación de clasificación de maestros: utilice el SIMCSE capacitado como maestro para obtener la distribución de clasificación calculada por el primer emb de propagación hacia adelante de cada muestra y el segundo emb de propagación hacia adelante de todas las muestras en lotes como etiquetas suaves, utilizando el método de lista. Tenga en cuenta que, dado que las puntuaciones de los puntos de anclaje y las muestras positivas son demasiado altas, estas puntuaciones se descartan. Durante la destilación se mezclan las etiquetas de los dos modelos Teacher según su peso. La pérdida ordenada se puede expresar de la siguiente manera:
ζ rango = ∑ i = 1 N rango ( S ( xi ) , ST ( xi ) ) \zeta_{rank} = \sum_{i=1}^Nrank(S(x_i), S^T(x_i))gramorango _=yo = 1∑norterango ( S ( x _yo) ,ST (xyo))
Entre ellos, N representa el número de muestras en el lote. Tenga en cuenta que no es el número de documentos correspondientes a una determinada consulta.
Específicamente, la pérdida por destilación puede usar ListNet o ListMLE:- Entre ellos, ListNet utiliza una versión simplificada de Top1:
ζ L ist N et = − ∑ i = 1 N softmax ( ST ( xi ) / τ 3 ∗ log ( softmax ( S ( xi ) / τ 2 ) ) \zeta_{ListNet } = - \sum_{i=1}^Nsoftmax(S^T(x_i)/\tau_3 * log(softmax(S(x_i)/\tau_2))gramolista neta _ _ _ _=−yo = 1∑norteso f t ma x ( ST (xyo) / t3∗log ( so f t ma x ( S ( x _ _yo) / t2)) - ListMLE maximiza directamente la estimación de máxima verosimilitud basada en el orden de la verdad fundamental, por lo que solo usa la clasificación obtenida después de calificar el modelo del maestro y no usa el modelo directamente para calificar.
ζ L ist MLE = − ∑ i = 1 N log ( π i T ∣ S ( xi ) , τ 2 ) ) \zeta_{ListMLE} = -\sum_{i=1}^N log(\pi_i^T|S (x_i),\tau_2))gramoL i s tM L E=−yo = 1∑norteregistro ( p _ _it∣ S ( xyo) ,t2))
π i T \pi_i^TPiitIndica la clasificación del modelo de maestro. Para obtener más detalles, consulte la sección de definición a continuación. También tenga en cuenta que las puntuaciones de predicción del modelo aquí no están normalizadas por softmax.
Algunos de ellos se definen de la siguiente manera:

- Entre ellos, ListNet utiliza una versión simplificada de Top1:
Definiciones :
ζ final = ζ info NCE + β ζ consistencia + γ ζ rango \zeta_{final} = \zeta_{infoNCE}+\beta\zeta_{consistency}+\gamma\zeta_{rank};gramofinal _ _=gramoen f o NCE+b gconsistencia _ _ _ _ _ _ _ _+c grango _
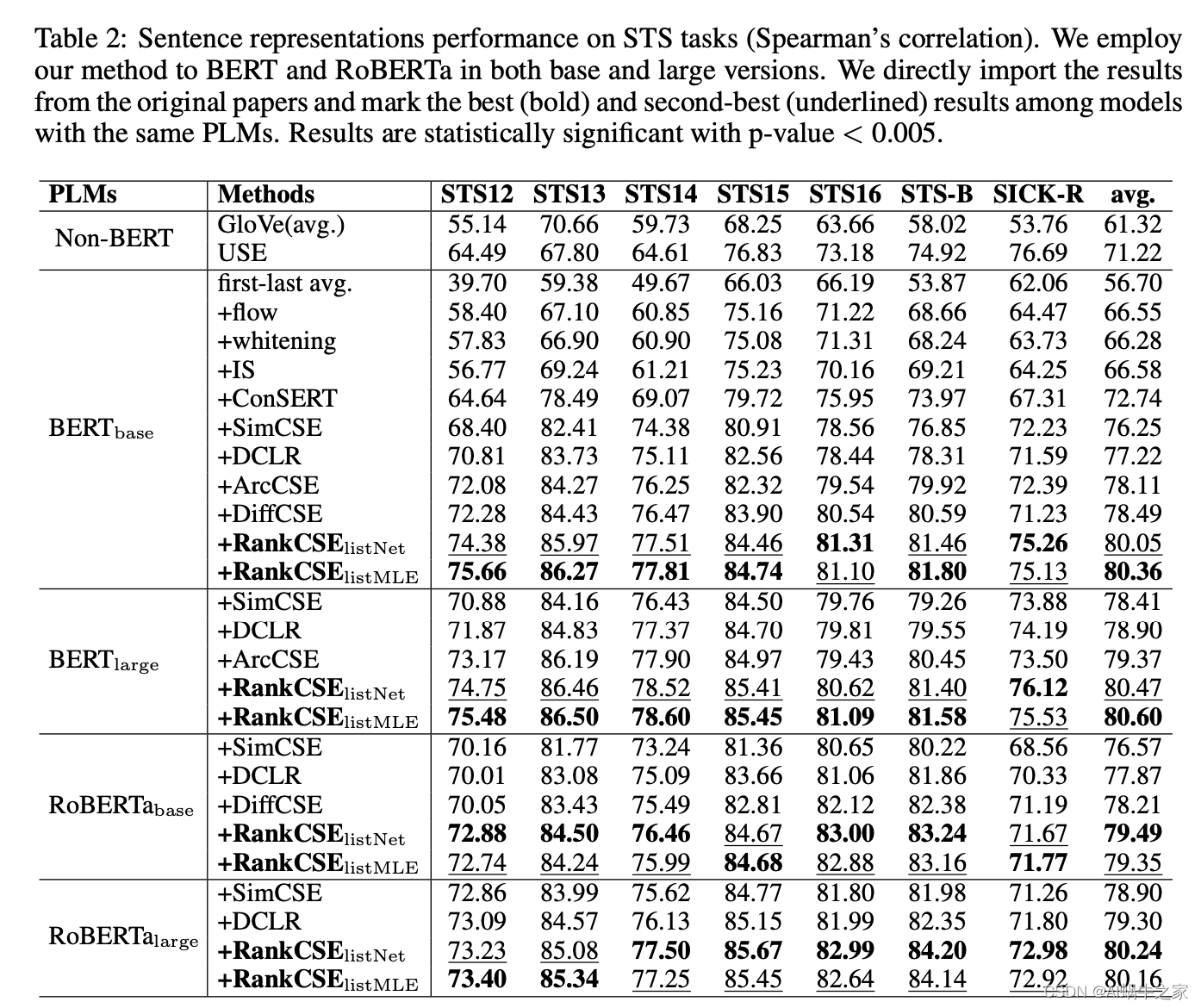
Resultados finales
aumento de datos
Aumento contextual BERT condicional
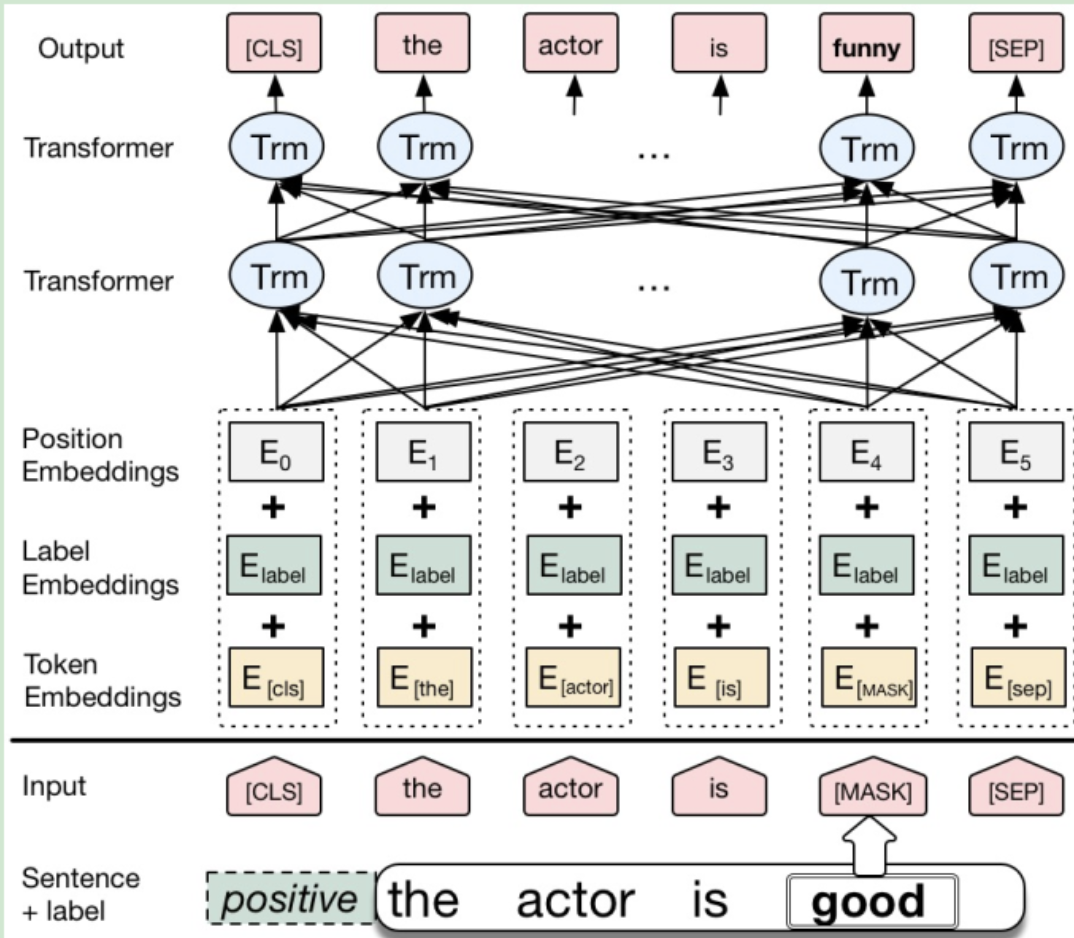
La estructura del modelo de CBert es completamente la misma que la de Bert, la única diferencia radica en la "representación de entradas" y el "proceso de capacitación". En CBert, la información de la etiqueta está representada por Segmentation Embedding. La segmentación Embedded en el texto original de Bert tiene solo dos valores, que deben ajustarse a num_classes en CBert. De esta manera, la información de la etiqueta se integra en la tarea de MLM y, al predecir palabras de reemplazo, se considera no solo el contexto sino también la información de la etiqueta, que es el MLM condicional mencionado en el artículo.
El proceso de capacitación es muy similar al de Bert, excepto que CBert usa tareas CMLM en lugar de tareas MLM al ajustar el "corpus de capacitación anotado".
El último paso es mejorar los datos de entrenamiento y realizar la tarea MLM condicional en Fine-Tune CBert en el corpus de entrenamiento. Tenga en cuenta que al predecir palabras de reemplazo, no debe seleccionar la palabra correspondiente a la mayor probabilidad, sino que debe estar en el rango TopN (u otro método efectivo) para seleccionar aleatoriamente una palabra de reemplazo para aumentar la diversidad de la distribución de datos.
https://blog.csdn.net/weixin_44815943/article/details/124122407
SBERT aumentado
El uso de codificador cruzado para etiquetar débilmente todas las combinaciones posibles de pares de oraciones generará una gran sobrecarga e incluso puede conducir a una disminución en el rendimiento del modelo. Por lo tanto, necesitamos una estrategia de muestreo adecuada para reducir los pares de oraciones con etiquetas débiles y mejorar la expresividad del modelo.
(1) Muestreo aleatorio (RS)
(2) Estimación de la densidad del kernel (KDE): el propósito es garantizar que la distribución de los datos de plata y de oro permanezca consistente. Con este fin, anotamos débilmente una gran cantidad de pares de oraciones aleatorias, pero solo conservamos ciertas combinaciones. Por ejemplo, para tareas de clasificación, solo se retienen pares de oraciones positivas; para tareas de regresión, se utiliza la estimación de densidad del kernel (KDE) para estimar las funciones de densidad continua Fgold(s) y Fsilver(s) para la puntuación s.
Sin embargo, la estrategia de muestreo de KDE no es computacionalmente eficiente y requiere una gran cantidad de muestras aleatorias. No utilizamos este método más tarde.
(3) Muestreo BM25 (BM25): utilizando el algoritmo Okapi BM25. Utilizamos ElasticSearch. Extraiga las k oraciones más similares para cada oración. Luego, estos pares de oraciones se anotan débilmente mediante un codificador cruzado y se utilizan como datos plateados. Este método funciona de manera muy eficiente. Este artículo recomienda este método.
(4) Muestreo de búsqueda semántica (SS): una desventaja de BM25 es que solo puede encontrar oraciones con vocabulario superpuesto, por lo que no se seleccionarán sinónimos ni oraciones con poca o ninguna superposición. En este método, utilizamos la similitud del coseno para seleccionar las k declaraciones más similares. También se puede utilizar Faiss.
(5) BM25 + Muestreo de búsqueda semántica (BM25-SS)
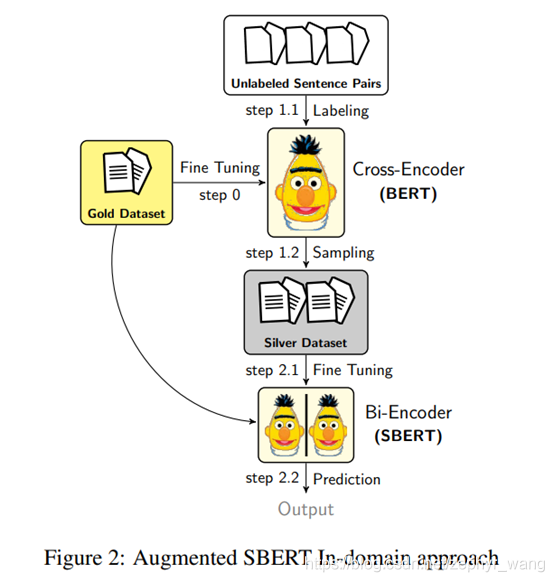
https://blog.csdn.net/zephyr_wang/article/details/119581505
ViLBERT
https://zhuanlan.zhihu.com/p/264488613
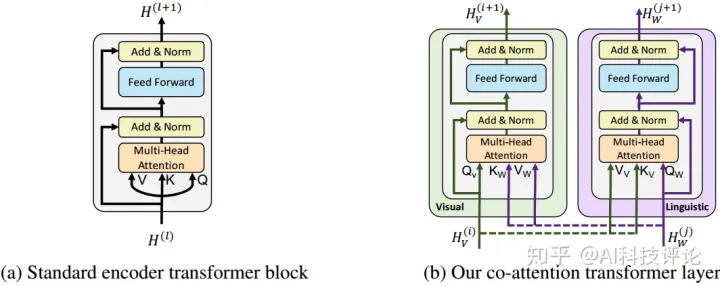

2.1 Capa transformadora de coatención
La capa transformadora de coatención presentada en este artículo se muestra en la Figura 1b. Dadas las características de visión y lenguaje, las claves y valores de la modalidad de imagen se ingresan en la unidad de atención de la modalidad de texto (y viceversa), y la unidad de atención genera características de atención agrupadas para cada modalidad en función de la otra modalidad. en el flujo de visión se expresa como atención del lenguaje basada en condiciones de imagen, y en el flujo de lenguaje, es atención de visión en condiciones de lenguaje. Al igual que BERT, la función de atención se agrega al residuo de salida inicializado.
2.2 Representación de imágenes
Genere imágenes rpn y sus características visuales basándose en una red de detección de objetos previamente entrenada. A diferencia de las palabras, el área de la imagen es innecesaria. Este documento utiliza un vector de 5 dimensiones para codificar la posición del área. Los cinco elementos son las coordenadas de la esquina superior izquierda y la esquina inferior derecha de los cuadros delimitadores normales y la cobertura del área de la imagen. .proporción y luego use un mapeo para hacerla coincidir con la dimensión y la suma de la característica visual. Utilice un token de imagen específico como comienzo de la secuencia de imágenes y utilice su salida para caracterizar la imagen completa.
2.3 Tareas previas al entrenamiento
Se utilizan dos tareas previas al entrenamiento cuando se entrena ViLBERT:
(1) Modelado multimodal de oclusión
Al igual que BERT estándar, aproximadamente el 15% de la entrada rpn de palabras e imágenes está enmascarada, y los elementos enmascarados se predicen a través de la secuencia de entrada restante. Al enmascarar la imagen, la probabilidad de 0,9 es oclusión directa y la probabilidad de 0,1 permanece sin cambios. La máscara de texto es consistente con la de Bert. Vilbert no predice directamente el valor de la característica del área de la imagen enmascarada, pero predice la distribución del área correspondiente en la categoría semántica, utilizando el resultado del modelo de detección de objetos previo al entrenamiento como verdad fundamental para minimizar la divergencia KL de las dos distribuciones. .como meta.
(2) Predecir la alineación multimodal
Como se muestra en la Figura 4-b, su objetivo es predecir si el par imagen-texto coincide con la alineación, es decir, si el artículo describe correctamente la imagen. La salida del token IMG inicial de la secuencia de características de imagen y el token CLS inicial de la secuencia de texto se utiliza como representación general de la entrada visual y de lenguaje. Tomando prestada otra estructura común en el modelo de visión y lenguaje, la salida del token IMG y la salida del token CLS son productos por elementos como representación general final. Luego use una capa lineal para predecir si la imagen y el texto coinciden.

r-cnn más rápido
https://zhuanlan.zhihu.com/p/31426458
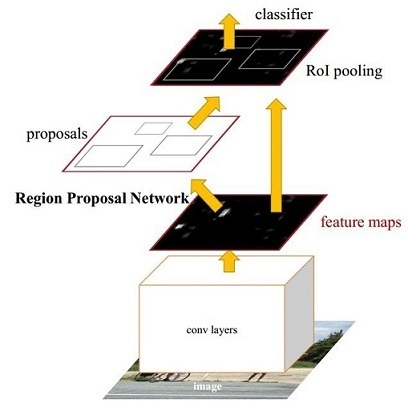
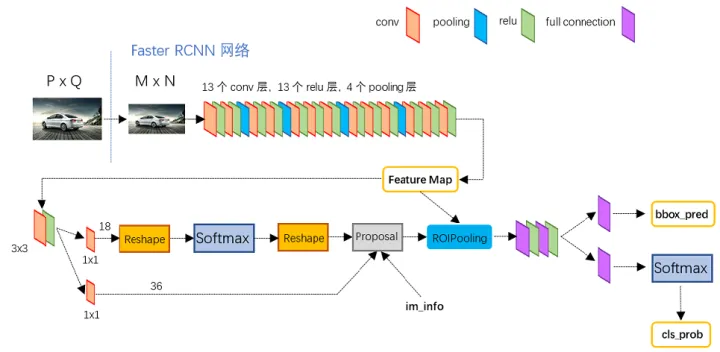
Faster RCNN en realidad se puede dividir en 4 contenidos principales:
Capas de conversión. Como método de detección de objetivos de la red CNN, Faster RCNN primero utiliza un conjunto de capas básicas conv + relu + pooling para extraer los mapas de características de la imagen. Este mapa de características se comparte para capas RPN posteriores y capas completamente conectadas.
Redes de Propuestas Regionales. La red RPN se utiliza para generar propuestas regionales. Esta capa usa softmax para determinar si los anclajes son positivos o negativos, y luego usa la regresión del cuadro delimitador para corregir los anclajes y obtener propuestas precisas.
Roy piscina. Esta capa recopila los mapas de características de entrada y las propuestas, sintetiza esta información, extrae los mapas de características de la propuesta y los envía a la capa posterior completamente conectada para determinar la categoría de destino.
Clasificación. Utilice mapas de características de la propuesta para calcular la categoría de la propuesta y, al mismo tiempo, vuelva a realizar la regresión del cuadro delimitador para obtener la posición final precisa del marco de detección.
Fusión de características multimodales
Varias operaciones de fusión multimodal.
Fusión de características bilineales
Explicación detallada, mejora y aplicación de la agrupación bilineal
Redes de atención bilineales Notas
Modelo de red de atención bilineal "Redes de atención bilineales"

aprendizaje contrastivo
https://www.cnblogs.com/xyzhrrr/p/15864522.html
Aplicación del aprendizaje contrastivo en representación semántica: recurrencia SBERT/SimCSE/ConSERT/ESimCSE
computación semántica
Comparación de los efectos de los métodos de representación semántica de oraciones.
¿Cuál es el método sota actual para la incrustación de oraciones?