Resumen : Utilice las excelentes funciones de computación estadística y gráficos estadísticos del lenguaje R para analizar modelos estadísticos multivariados. El modelo establecido en este artículo analiza principalmente la cuestión del PIB per cápita de Shanghai. Teniendo en cuenta que los datos del PIB de Shanghai comenzaron en 1998 y los datos disponibles para la búsqueda finalizan en 2020, los datos de este artículo provienen del "Anuario estadístico" de Shanghai y de la Oficina Nacional de Estadísticas de 1978 a 2020. Este artículo considera principalmente el impacto en el PIB per cápita de Shanghai desde cuatro aspectos: industria primaria, industria secundaria, industria terciaria e industria. Los resultados encontraron que la industria terciaria es el factor más importante que afecta el PIB per cápita de Shanghai.
1 Antecedentes de investigación
El PIB per cápita es una herramienta eficaz para que las personas comprendan y comprendan las condiciones macroeconómicas de un país o región, es decir, el PIB per cápita. A menudo se utiliza como indicador para medir el desarrollo económico en la economía del desarrollo y es uno de los más importantes. Indicadores macroeconómicos. , con la publicación de los datos del séptimo censo, se han mejorado aún más los datos del PIB per cápita de las ciudades de nuestro país. Entre ellos, Shanghai alcanzará un PIB de 4.321,49 mil millones de yuanes en 2021, con una tasa de crecimiento real del 8,1%. La población permanente alcanzará los 24.894,3 millones, un aumento de 10.700 personas con respecto al año pasado, y el PIB per cápita será de 173.600 yuanes. ($27,200). Este artículo utilizará el lenguaje R para estudiar los factores que influyen en el PIB per cápita de Shanghai después de esto.
El contenido principal de este artículo:
Al establecer el modelo de regresión, este artículo primero utiliza el software R para utilizar la relación lineal multivariada entre las cuatro variables independientes y la variable dependiente del PIB per cápita de Shanghai, y luego verifica el problema de multicolinealidad para obtener el modelo de regresión óptimo. Evaluar la calidad del modelo. Y divídalo según la mediana del PIB per cápita de Shanghai, una variable dependiente continua, y convierta la variable dependiente continua en una variable dependiente de 0 a 1. Si es menor que la mediana, se registrará como 0, y si es mayor o igual a la mediana, se registrará como 1. Puede ser lógicamente La regresión realiza una clasificación de verificación e intersección de 5 veces y proporciona la matriz de confusión, así como TPR, TNR, FPR, FNR y precisión ( Precisión), y finalmente da una interpretación de los resultados de la clasificación desde la perspectiva de la economía o la gestión.
2 fuentes de datos
Este artículo comienza estudiando los factores que afectan el PIB per cápita de Shanghai. Dado que Shanghai emitió un cese de recopilación de datos relevantes antes de 1978, los datos comienzan en 1978 y el anuario estadístico está disponible hasta el anuario de 2020. Por lo tanto, es completo a través del Oficina Nacional de Estadísticas. Con base en los datos relacionados con el PIB per cápita de Shanghai del anuario de la ciudad de 1978 a 2020, finalmente se excluyen las siguientes variables para posibles tendencias en el PIB per cápita de Shanghai. Este artículo selecciona cuatro factores: industria primaria, industria secundaria ; industria terciaria e industria. PIB per cápita variable dependiente (10.000 yuanes)
Los datos se muestran en la Tabla 2.1 a continuación:
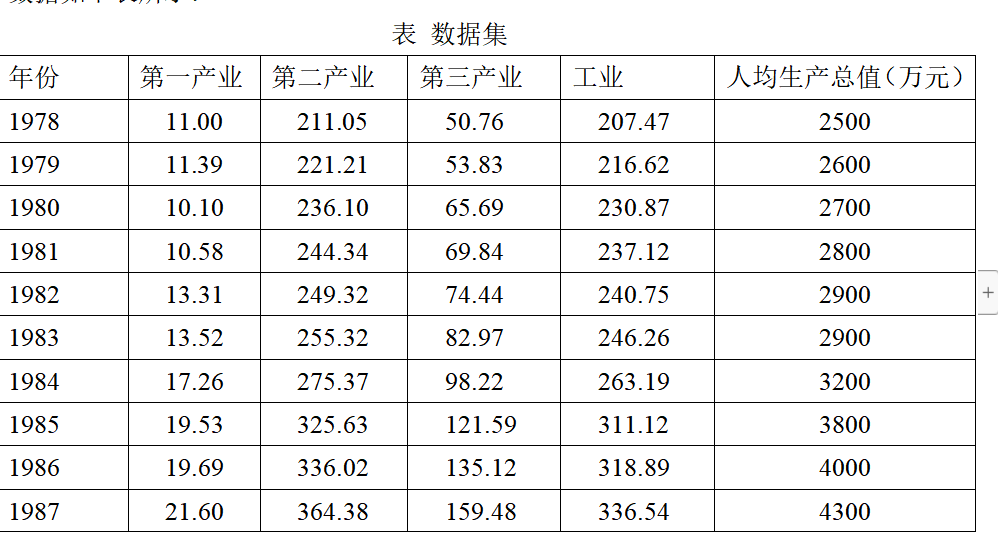
Con base en los datos recopilados, para comprender de manera más integral los factores que influyen en la tasa de crecimiento demográfico, se seleccionó el PIB per cápita (10.000 yuanes) como variable explicativa. Seleccione industria primaria, industria secundaria, industria terciaria e indicadores industriales. Teniendo en cuenta los datos recopilados, estos factores influyentes se considerarán por ahora. Sobre la base de los datos anteriores, se estableció un modelo de regresión lineal múltiple del PIB per cápita de Shanghai (10.000 yuanes).
Los datos pueden consultarse y descargarse en el siguiente sitio web:
http://tjj.sh.gov.cn/tjnj/nj21.htm?d1=2021tjnj/C0301.htm
http://tjj.sh.gov.cn/tjnj/ nj21.htm?d1=2021tjnj/C0305.htm
3 Análisis descriptivo
3.1 Análisis estadístico
Con base en los datos recopilados, el análisis estadístico se realiza mediante la descripción en el paquete psicológico del lenguaje R. Puede calcular el número de valores no faltantes, media, desviación estándar, mediana, media censurada, diferencia de mediana absoluta, valor mínimo, máximo. El valor, el rango, la asimetría, la curtosis y el error estándar de la media se muestran en la Tabla 3.1.

Figura 3.1 Tabla de análisis estadístico
Con base en la tabla anterior, se puede concluir que el PIB per cápita promedio de Shanghai de 1978 a 2020 es 4,57, la desviación estándar es 4,75, el valor mínimo es 0,25, el valor máximo es 15,58 y otra información relacionada.
3.2 Visualización de tendencias
Según la industria primaria, la industria secundaria, la industria terciaria, los indicadores industriales y el PIB per cápita son indicadores de diferentes años, se pueden dibujar los gráficos de tendencias correspondientes para ver las tendencias cambiantes en los últimos años. Los gráficos elaborados sobre las tendencias cambiantes de los indicadores anteriores se resumen en la Tabla 3.2.
Figura 3.2 Tabla de tendencias de variables

Del Cuadro 3.2 se puede concluir que las tendencias de la industria primaria, la industria secundaria, la industria terciaria, los indicadores industriales y el PIB per cápita son las mismas.
3.3 Matriz de diagrama de dispersión
Con base en el análisis de tendencias anterior, se dibuja la matriz de diagrama de dispersión relevante, que se puede dibujar a través del gráfico. Función de correlación en el paquete PerformanceAnalytics.
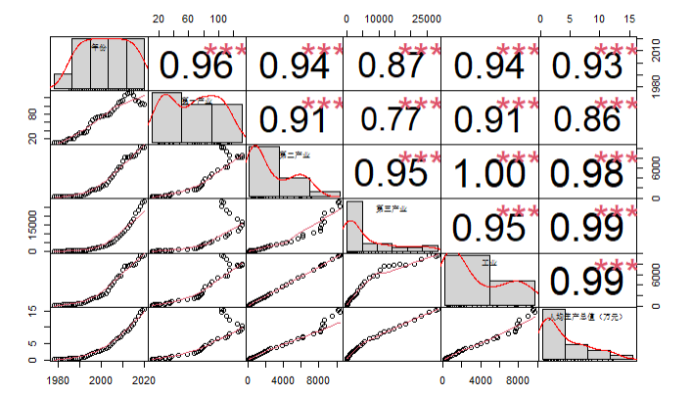
Figura 3.1 Diagrama de correlación de dispersión
De la Figura 3.1 se puede analizar que el grado de correlación entre la industria primaria, la industria secundaria, la industria terciaria, los indicadores industriales y el PIB per cápita es muy grande.
4 Análisis de regresión
4.1 Regresión lineal
La regresión generalmente se refiere a métodos que utilizan una o más variables predictivas (también llamadas variables independientes o variables explicativas) para predecir la variable de respuesta (también llamada variable dependiente, variable de criterio o variable de resultado). Normalmente, el análisis de regresión se puede utilizar para seleccionar variables explicativas que estén relacionadas con la variable de respuesta. La Figura 4.1 y la Tabla 4.1 a continuación son los resultados basados en el modelo de regresión lineal múltiple.
Tabla 4.1 Regresión lineal múltiple

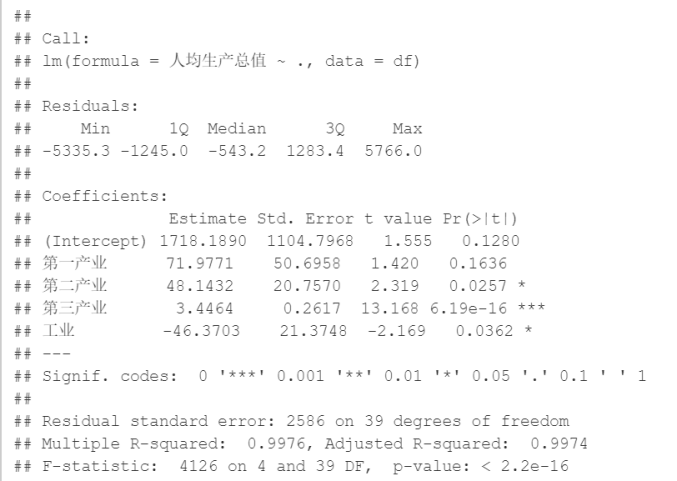
Figura 4.1 Resultados del modelo lineal
Cuando hay más de una variable predictora, el significado del coeficiente de regresión es: la cantidad en la que la variable dependiente aumentará cuando una variable predictora aumenta en una unidad y las otras variables predictoras permanecen sin cambios. Por ejemplo, en este ejemplo, si la industria terciaria aumenta en 1 unidad, se espera que el PIB per cápita aumente en 0,0003471 y su coeficiente p es significativamente diferente de 0 (p=7,7e-16). En general, todas las variables predictivas explicaron el 99,71% de la varianza del PIB per cápita. Los resultados del modelo lineal indican que el factor significativo es la industria terciaria.
4.2 Multicolinealidad
Primero, se analiza la multicolinealidad de las variables independientes en el modelo y el grado de multicolinealidad se mide mediante el Factor de Inflación de Varianza (VIF). Implementado usando la función vif() del paquete car. Bajo principios generales, vif >4 indica la existencia de problemas de multicolinealidad. El valor VIF de la variable independiente de un modelo lineal ideal está muy cerca de 1. Cuando 10≤VIF<100, hay una fuerte multicolinealidad. Cuando VIF>=100, la multicolinealidad es muy grave. La figura 4.2 es el resultado de la prueba de colinealidad.

Figura 4.2 Prueba de colinealidad
De los resultados del cálculo se puede ver que el factor de inflación de la varianza es mucho mayor que 10 y se puede determinar que existe un problema de multicolinealidad obvio. Si se descubre que existe una colinealidad obvia, es necesario eliminar la variable del modelo y restablecer un nuevo modelo.
Como la industria secundaria es principalmente industria, elegimos entre las dos variables de industria secundaria e industria.
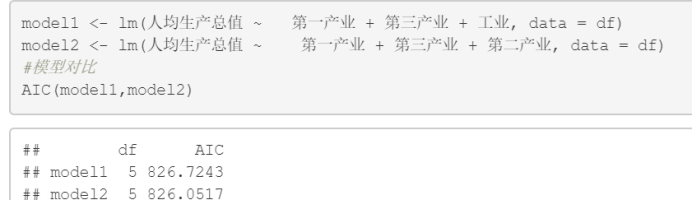
Figura 5.3 Comparación de modelos.
El valor AIC aquí muestra que el modelo de industria primaria + industria terciaria + industria secundaria es mejor. Los resultados específicos del modelo basado en el tratamiento de la multicolinealidad se muestran en la Figura 5.4 a continuación.

Figura 5.4 Modelo que trata con multicolinealidad
Los resultados basados en el modelo muestran que los factores significativos son la industria primaria, la industria terciaria y la industria secundaria. El factor más significativo es la industria terciaria.