1 Hintergrund des föderierten Lernens
In den meisten Fällen sind die Daten in den Händen verschiedener Unternehmen verstreut, und jedes Unternehmen hofft, sich anderen Unternehmen anzuschließen (unter Verwendung der von jedem Unternehmen gespeicherten Daten), um ein Modell zu trainieren, ohne seine eigenen Daten offenzulegen. Dieses Modell kann Unternehmen dabei helfen, größere Vorteile zu erzielen.
Die traditionelle Methode zum Sammeln verstreuter Daten besteht darin, ein Rechenzentrum aufzubauen und das Modell im Rechenzentrum zu trainieren. Aufgrund immer mehr gesetzlicher Beschränkungen und der Zurückhaltung der Dateneigentümer bei der Offenlegung ihrer Daten funktioniert diese Methode jedoch nach und nach nicht mehr .
2 Einführung in Federated Learning
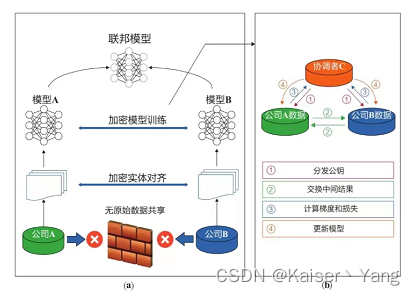
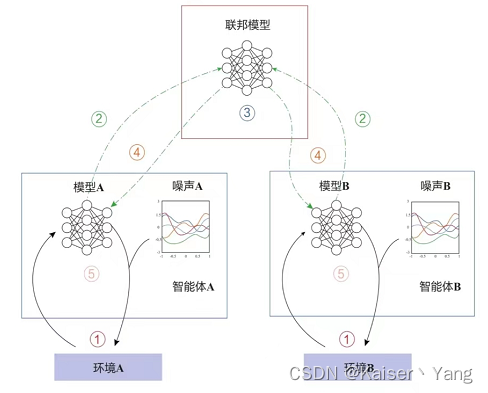
Definition: Föderiertes Lernen (föderiertes maschinelles Lernen), der vollständige Name für föderiertes maschinelles Lernen, ist eine Methode, die vorgeschlagen wird, um das Datenschutzproblem beim gemeinsamen Trainieren von Modellen zu lösen: Lassen Sie jedes Unternehmen das Modell selbst trainieren, und jedes Unternehmen wird es abschließen Modell. Laden Sie nach dem Training die Parameter jedes Modells auf einen zentralen Server hoch (es kann auch Punkt-zu-Punkt sein). Der zentrale Server kombiniert die Parameter jedes Unternehmens (er kann Farbverläufe oder seine eigenen aktualisierten Parameter hochladen) und erneut Formulieren Sie neue Parameter (z. B. durch gewichteten Durchschnitt (dieser Schritt wird als föderierte Aggregation bezeichnet)), die neuen Parameter werden an jedes Unternehmen verteilt und das Unternehmen stellt die neuen Parameter für das Modell bereit, um das neue Training fortzusetzen. Dieser Prozess kann wiederholt wiederholt werden, bis das Modell konvergiert oder andere Bedingungen erfüllt sind. Bedingungen von.
![[Die Übertragung des externen Linkbildes ist fehlgeschlagen. Die Quellseite verfügt möglicherweise über einen Anti-Leeching-Mechanismus. Es wird empfohlen, das Bild zu speichern und direkt hochzuladen (img-H8FpL0PN-1668479217904) (Federated Learning)].assets/image-20221114144201902.png )](https://img-blog.csdnimg.cn/4eb2a5b469f14705a5d4d2d80d20fcac.png)
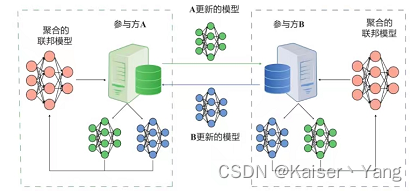
Der Effekt der Verwendung eines föderierten Lernmodells ist schlechter als der direkte Pooling von Daten für das Training. Ein solcher Effekt ist ein Verlust (in tatsächlichen Situationen ist er jedoch möglicherweise kein Verlust, der Datenverlust kann einer Regularisierung ähneln und der Effekt kann verbessert werden). Der Schutz der Privatsphäre ist akzeptabel.
3 Klassifizierung des föderierten Lernens
Um die Klassifizierung des föderierten Lernens besser zu verstehen, definieren Sie zunächst die Daten:
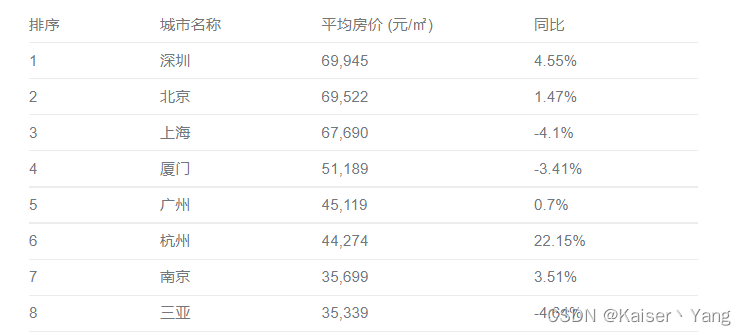
Die Daten jedes Unternehmens können als Tabelle betrachtet werden. Jede Zeile der Tabelle ist ein Beispiel mit mehreren Merkmalen und Bezeichnungen. Jede Spalte ist ein Merkmal oder eine Bezeichnung. Die folgende Abbildung kann beispielsweise ein Beispiel eines bestimmten Unternehmens sein. Zusammengestellte Immobilienpreisdaten von verschiedenen Orten:
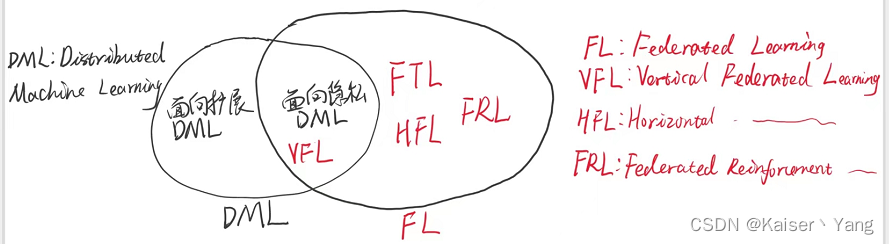
horizontales föderiertes Lernen, vertikales föderiertes Lernen und föderiertes Transferlernen werden basierend auf der Ähnlichkeit der Daten jedes Teilnehmers klassifiziert, während der Schwerpunkt des föderierten Verstärkungslernens darauf liegt, Entscheidungen zu treffen (Maßnahmen zu ergreifen). das Umfeld jeder Partei.
3.1 Horizontales föderiertes Lernen
Horizontales föderiertes Lernen bedeutet, dass die Merkmale der Daten, die jeder Partei gehören, grundsätzlich gleich sind und ihre eigenen Bezeichnungen haben. Wenn die Daten jeder Partei in einem zentralen Körper konzentriert sind, verfügt jede Partei über unterschiedliche Proben des Zentrosoms (horizontal). die horizontale Teilung des Zentrosoms).
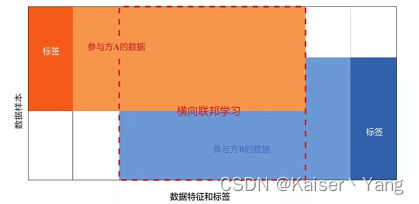
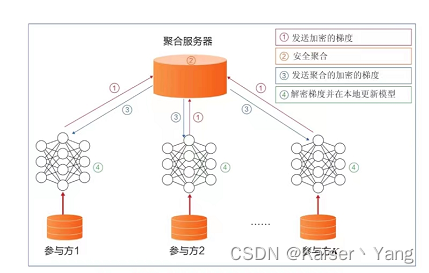
Der Prozess des horizontalen Verbundlernens (mit einem zentralen Server) lässt sich wie folgt zusammenfassen:
3.2 Vertikales föderiertes Lernen
Vertical Federated Learning bedeutet, dass die Daten im Besitz jeder Partei viele unterschiedliche Merkmale aufweisen, es jedoch viele identische Stichprobenpersonen geben kann (z. B. die Informationen derselben Person in Banken und Versicherungsunternehmen) und die Daten auch in einem Fall konzentriert sind Im zentralen Körper hat jede Partei unterschiedliche Attribute der Stichprobe (vertikal bezieht sich auf die vertikale Unterteilung des zentralen Körpers.
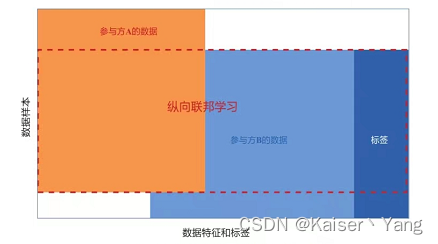
Vertikales föderiertes Lernen hat tatsächlich nur eine Partei mit Etiketten, und die sich überschneidenden Daten werden durch vertikales föderiertes Lernen trainiert.
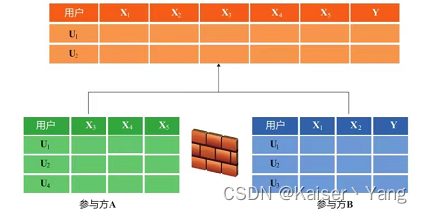
Der Prozess des vertikalen föderierten Lernens ist etwas komplizierter. Das erste, was getan werden muss, ist die Ausrichtung der Daten. Da die Daten nicht verloren gehen können, werden die verschlüsselten Daten ausgerichtet, wie in der folgenden Abbildung dargestellt: Die ausgerichteten Daten sind ungefähr wie folgt (die Operation darauf wird nur
sein) Erhalten Sie die sich überschneidenden Stichproben in den beiden Daten, nämlich U1 und U2 in der folgenden Abbildung:
Da nur eine Partei das Etikett hat, aber beide Parteien (am Beispiel von zwei Teilnehmern) dies getan haben Vorhersagen wird die Verlustfunktion hier neu definiert:
L = 1 2 ∑ ( y A ( i ) + y B ( i ) − y ) 2 L=\frac 1 2 \sum(y_A^{(i)}+y_B^{ (i)}-y)^2L=21∑ ( yA( ich ).+jB( ich ).−y )2.
Jedes Modell hat nur Parameter, die sich auf seine eigenen Eigenschaften beziehen. Nehmen wir das obige Beispiel als Beispiel, das heißt:
y A ( U 1 ) = w 3 X 3 + w 4 X 4 + w 5 X 5 y B ( U 1 ) = w 1 X 1 + w 2jA( U1)=w3X3+w4X4+w5X5jB( U1)=w1X1+w2X2
Dies ist nur ein einfaches Beispiel. Es wird tatsächlich in Form einer Matrix erstellt und enthält mehrere verborgene Ebenen.
Dies bedeutet, dass die Teilnehmer sowohl beim Training als auch bei der Vorhersage Daten koordinieren und austauschen müssen (Teilnehmer müssen ihre eigenen Vorhersagewerte und -verläufe berechnen und die Ergebnisse zur Aggregation an den zentralen Server senden).
3.3 Föderiertes Transferlernen
Federated Transfer Learning bezieht sich auf eine Situation, in der es kaum Überschneidungen in den Daten der Teilnehmer gibt (die Personen, die die Daten generieren, sind unterschiedlich, und die Eigenschaften der Daten sind ebenfalls sehr unterschiedlich). Wenn die Datenfragen in ein zentrales Gremium integriert sind , wird es eine große Anzahl von Die Position ist leere Informationen, während jeder Teilnehmer ungefähr eine unabhängige Abteilung des zentralen Gremiums besitzt.
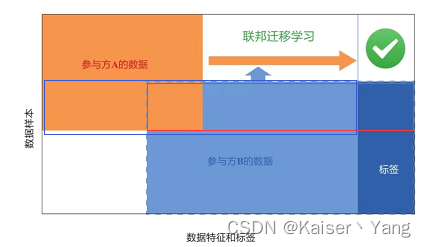
Wir definieren folgende Parameter:
- ϕ \phiϕ : Klassifizierungsfunktion, die aufui B u_i^BuichB;
- D c D_cDc: Das rote Kästchen im Bild;
- DAB D_{AB}DA B: Blaues Kästchen im Bild.
Beim föderierten Transferlernen hat nur eine Partei eine Bezeichnung. Durch föderiertes Transferlernen können die sich überschneidenden Daten verwendet werden, um die Daten der nicht gekennzeichneten Partei zu kennzeichnen.
Ein einfaches Modell ist in der folgenden Abbildung dargestellt:
Die Verlustfunktion des Modells (ohne Berücksichtigung der Regularisierung):
L = L 1 + γ L 2 L 1 = ∑ i N clog ( 1 + e − yi ϕ ( ui B ) ) L 2 = ∑ i NAB ∣ ∣ ui A − ui B ∣ ∣ F 2 \begin{aligned} &L=L_1+\gamma L_2\\ &L_1=\sum_i^{N_c}log(1+e^{-y_i\phi(u_i ^B) })\\ &L_2=\sum_i^{N_{AB}}||u_i^A-u_i^B||^2_F \end{aligned}L=L1+γ L2L1=ich∑Ncl o g ( 1+e− yichϕ ( uichB) )L2=ich∑NA B∣ ∣ uichA−uichB∣ ∣F2
Wir hoffen, zwei Teile des obigen Formeltabellennamens zu minimieren (am Beispiel eines Zwei-Klassen-Klassifizierungsproblems sind die Beschriftungswerte -1 und 1):
- L 1 L_1L1: Stellt die Nähe zum tatsächlichen Etikett dar, wenn yi = 1 y_i=1jich=Wenn 1 , wenn die obige Formel das Minimum istϕ (ui B) \phi(u_i^B)ϕ ( uichB) sollte möglichst nahe bei1 11,当yi = − 1 y_i=-1jich=Wenn − 1 , sollte es so nahe wie möglich an − 1 -1− 1;
- L 2 L_2L2: Stellt die Ähnlichkeit der beiden Modelldarstellungen dar. Die Trainingsnummernbezeichnungen für das Training der beiden Modelle sollten gleich sein, daher hoffen wir, dass die beiden Merkmalsdarstellungen so ähnlich wie möglich sind.
3.4 Föderiertes Verstärkungslernen
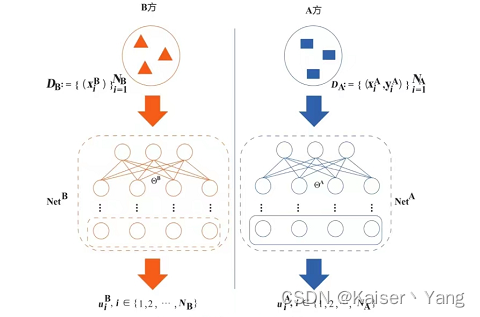
Federated Reinforcement Learning (Federated Reinforcement Learning) bezieht sich auf die Kombination von Reinforcement Learning und Federated Learning. Federated Reinforcement Learning ist in zwei Typen unterteilt: vertikal und horizontal. Die Definition ähnelt der vorherigen. Ein einfaches Modell des horizontalen Federated Reinforcement Learning. Wie unten gezeigt:
In der Abbildung oben führt jeder Teilnehmer das Training entsprechend seiner eigenen Umgebung durch. Nachdem das trainierte Modell zur Aggregation auf den zentralen Server hochgeladen wurde, gibt der Server das Modell dann zur Fortsetzung des Trainings aus.
Das einfache Modell des vertikalen föderierten Verstärkungslernens (Vertical Federated Reinforcement Learning) lautet wie folgt (die gepunktete Linie in der Abbildung zeigt an, dass es möglicherweise nicht existiert): Der Prozess in der
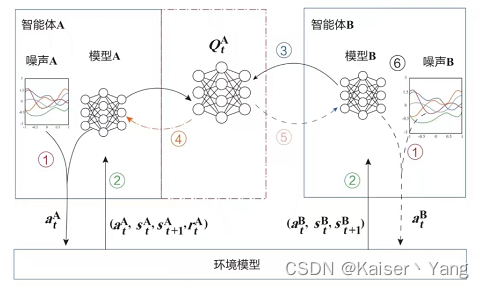
obigen Abbildung ähnelt dem Prozess des horizontalen föderierten Verstärkungslernens.
4 Föderiertes Lernen und verteiltes maschinelles Lernen

Persönlich denke ich, dass föderiertes Lernen tatsächlich eine Variante des verteilten maschinellen Lernens ist. Traditionelles verteiltes maschinelles Lernen (auch erweiterungsorientiertes verteiltes maschinelles Lernen genannt) konzentriert sich auf die Verwendung, wenn die Hardwareressourcen nicht ausreichen. Verteilte Cluster trainieren ein riesiges Modell, während sie föderiert sind Lernen bedeutet, dass sich die Daten selbst auf jedem Knoten befinden. Aus Datenschutzgründen müssen jedoch zum Lernen ähnliche Methoden wie verteiltes Lernen verwendet werden (es scheint, dass traditionelle verteilte Maschinen Der Lerneffekt sind besser als föderiertes Lernen, da traditionelles verteiltes Lernen alle hat die Daten). Das später vorgeschlagene verteilte maschinelle Lernen zur Wahrung der Privatsphäre ähnelt in gewisser Weise dem Prototyp des föderierten Lernens. Verteiltes maschinelles Lernen zum Schutz der Privatsphäre bedeutet, dass die Teilnehmer unterschiedliche Eigenschaften derselben Daten haben und hoffen, ein Modell unter der Prämisse des Datenschutzes zu trainieren (es ist ersichtlich, dass vertikales föderiertes Lernen sehr erwünscht ist). Das spätere föderierte Lernen erweitert das verteilte Lernen zum Schutz der Privatsphäre.
Das Venn-Diagramm der beiden sieht ungefähr wie folgt aus:
5 REFERENZ
„Federated Learning“ von Yang Qiang et al.