Wenyuan Xinzhiyuan Editor: LRS Tiene mucho sueño
[Introducción a Xinzhiyuan] El narrador puede generar de forma natural y controlable interacciones entre personas y escenas a partir de descripciones de texto, y es adecuado para diversas situaciones: interacción guiada por relaciones espaciales, interacción guiada por múltiples acciones, interacción entre escenas de varias personas y los tipos anteriores de combinación libre.
La generación natural y controlable de interacción entre la escena humana (HSI) juega un papel importante en muchos campos, como la creación de contenidos de realidad virtual/realidad aumentada (VR/AR) y la inteligencia artificial centrada en el ser humano.
Sin embargo, los métodos existentes tienen una controlabilidad limitada, tipos de interacción limitados y resultados generados no naturales, lo que limita seriamente sus escenarios de aplicación práctica.
En respuesta a este problema, el equipo de la Universidad de Tianjin y la Universidad de Tsinghua propusieron Narrador en el trabajo de ICCV 2023, centrándose en una tarea desafiante, que es generar de forma natural y controlable personas y escenas realistas y diversas a partir de descripciones de texto.

Página de inicio del proyecto: http://cic.tju.edu.cn/faculty/likun/projects/Narrator
Código: https://github.com/HaibiaoXuan/Narrator
Desde una perspectiva cognitiva humana, un modelo generativo ideal debería poder razonar correctamente sobre las relaciones espaciales y explorar grados de libertad interactivos.
Por lo tanto, el autor propone un modelo generativo basado en el razonamiento relacional, modelando las relaciones espaciales en escenas y descripciones respectivamente a través de gráficos de escenas, e introduciendo un mecanismo de interacción a nivel parcial que representa acciones interactivas como estados de partes atómicas del cuerpo.
En particular, beneficiándose del razonamiento relacional, el autor propuso además una estrategia de generación de múltiples personas simple pero efectiva, que fue la primera exploración de la generación interactiva de escenas de múltiples personas controlable en ese momento.
Finalmente, el autor realizó una gran cantidad de experimentos y encuestas a usuarios, demostrando que Narrador puede generar diversas interacciones de manera controlable y su efecto es significativamente mejor que el trabajo existente.
motivación del método
Los métodos existentes de generación de interacción entre el hombre y la escena se centran principalmente en la relación física geométrica de la interacción, pero carecen de control semántico sobre la generación y se limitan a la generación de una sola persona.
Por lo tanto, los autores se centran en la desafiante tarea de generar de forma controlable interacciones realistas y diversas entre escenas humanas a partir de descripciones en lenguaje natural. Los autores observaron que los humanos suelen utilizar la percepción espacial y el reconocimiento de acciones para describir de forma natural a las personas que participan en diversas interacciones en diferentes lugares.

Figura 1 El narrador puede generar de forma natural y controlable interacciones semánticamente consistentes y físicamente razonables entre el hombre y la escena, y es adecuado para las siguientes situaciones: (a) interacciones guiadas por relaciones espaciales, (b) interacciones guiadas por múltiples acciones, (c) múltiples personas interacción escena, y (d) interacción persona-escena que combina los tipos de interacción anteriores.
Específicamente, las relaciones espaciales se pueden representar como interrelaciones entre diferentes objetos en una escena o área local, mientras que las acciones interactivas se especifican mediante estados de partes atómicas del cuerpo, como los pies de una persona en el suelo, el torso inclinado, los golpecitos con la mano derecha y el descenso. .
Tomando esto como punto de partida, el autor utiliza gráficos de escena para representar relaciones espaciales y propone un mecanismo de gráfico de escena local y global conjunto (JGLSG) para proporcionar conocimiento de la posición global para la generación posterior.
Al mismo tiempo, considerando que el estado de las partes del cuerpo es la clave para simular interacciones realistas consistentes con el texto, el autor introdujo un mecanismo de acción a nivel de parte (PLA) para establecer la correspondencia entre las partes del cuerpo humano y las acciones.
Beneficiándose de la cognición observacional efectiva y la flexibilidad y reutilización del razonamiento relacional propuesto, los autores proponen además una estrategia de generación multijugador simple y efectiva, que es la primera estrategia de generación multijugador naturalmente controlable y fácil de usar en ese momento. Solución de generación de interacción de escenas (Multi-Human Scene Interaction, MHSI).
Ideas de métodos
Descripción general del marco del narrador
El propósito de Narrador es generar de forma natural y controlable interacciones entre humanos y escenas que sean semánticamente consistentes con las descripciones del texto y coincidan físicamente con la escena tridimensional.
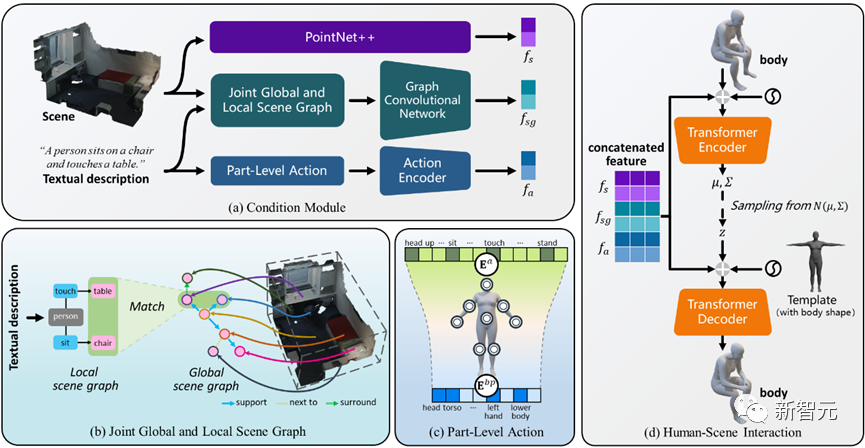
Figura 2 Descripción general del marco del Narrador
Como se muestra en la Figura 2, este método utiliza un codificador automático variacional condicional (cVAE) basado en transformador, que incluye principalmente:
1) En comparación con la investigación existente que considera escenas u objetos de forma aislada, un mecanismo conjunto de gráficos de escenas globales y locales está diseñado para razonar sobre relaciones espaciales complejas y lograr una conciencia de posicionamiento global;
2) Basado en la observación de que las personas completarán acciones interactivas a través de diferentes partes del cuerpo al mismo tiempo, se introduce un mecanismo de acción a nivel de componentes para lograr interacciones realistas y diversas;
3) Además, se introduce una pérdida bifacial interactiva en el proceso de optimización con reconocimiento de escena para obtener mejores resultados de generación;
4) Se expande aún más a la generación de interacción de varias personas y, en última instancia, promueve el primer paso en la interacción de escenas de varias personas.
Mecanismo combinado de gráfico de escena global y local.
El razonamiento de las relaciones espaciales puede proporcionar al modelo pistas sobre escenas específicas, lo que juega un papel importante para lograr un control natural en la interacción entre los humanos y las escenas.
Por lo tanto, el autor diseñó un mecanismo conjunto de gráficos de escenas globales y locales, que se implementa mediante los siguientes tres pasos:
1. Generación de gráficos de escena global: dada una escena, utilice un modelo de gráfico de escena previamente entrenado para generar un gráfico de escena global, es decir, dónde está el objeto 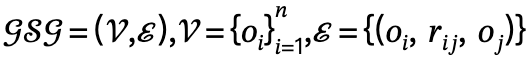 con una etiqueta de categoría, es la relación entre y , n es el número de objetos , m es el número de relaciones;
con una etiqueta de categoría, es la relación entre y , n es el número de objetos , m es el número de relaciones;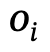
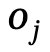
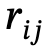
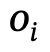
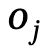
2. Generación de gráficos de escenas locales: utilice herramientas de análisis semántico para identificar la estructura de la oración descrita y extraer y generar escenas locales 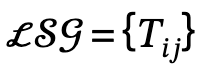 , en las que
, en las que 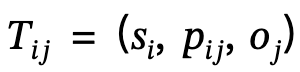 se define el triplete sujeto-predicado-objeto;
se define el triplete sujeto-predicado-objeto;
3. Coincidencia de gráficos de escena: el modelo corresponde a nodos en los gráficos de escena global y local según las mismas etiquetas semánticas de objetos y agrega automáticamente un nodo humano virtual para proporcionar información de ubicación al extender las relaciones de borde.
Mecanismo de acción a nivel de componente (PLA)
Las interacciones humanas en la escena se componen de estados de partes atómicas del cuerpo, por lo que el autor propone un mecanismo de acción detallado a nivel de partes para que el modelo pueda prestar atención a partes importantes e ignorar partes irrelevantes de una interacción determinada.
Específicamente, los autores exploran acciones interactivas ricas y diversas y asignan estas posibles acciones a cinco partes principales del cuerpo humano: cabeza, torso, brazo izquierdo/derecho, mano izquierda/derecha y parte inferior del cuerpo izquierda/derecha.
Al mismo tiempo, se utiliza la codificación one-hot (One-Hot) para representar estas acciones y partes del cuerpo respectivamente, y se conectan de acuerdo con la relación correspondiente para la codificación posterior.
Para la generación interactiva de múltiples acciones, el autor utiliza un mecanismo de atención para conocer el estado de diferentes partes de la estructura corporal.
En una combinación dada de acciones interactivas, la atención queda automáticamente protegida entre la parte del cuerpo correspondiente a cada acción y todas las demás acciones.
Tomemos como ejemplo "una persona en cuclillas en el suelo usando un gabinete", ponerse en cuclillas corresponde al estado de la parte inferior del cuerpo, por lo que la atención marcada por otras partes se bloqueará a cero.
Optimización del conocimiento de la escena
Los autores aprovechan las limitaciones geométricas y físicas para la optimización basada en escenas para mejorar los resultados de generación. A lo largo del proceso de optimización, el método garantiza que las poses generadas no se desvíen, al tiempo que fomenta el contacto con la escena y restringe el cuerpo para evitar la interpenetración con la escena.
Dada la escena tridimensional S y los parámetros SMPL-X generados, la pérdida de optimización es:
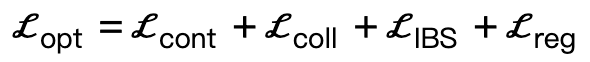
Entre ellos, 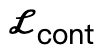 anima a los vértices del cuerpo a contactar la escena;
anima a los vértices del cuerpo a contactar la escena; 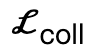 es un término de colisión basado en la distancia simbólica;
es un término de colisión basado en la distancia simbólica; 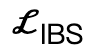 es una pérdida bipartita interactiva (IBS) introducida adicionalmente en comparación con el trabajo existente, que es un conjunto de puntos equidistantes muestreados entre la escena y el cuerpo humano;
es una pérdida bipartita interactiva (IBS) introducida adicionalmente en comparación con el trabajo existente, que es un conjunto de puntos equidistantes muestreados entre la escena y el cuerpo humano; 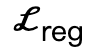 es un factor de regularización utilizado para penalizar los parámetros que se desvían de su inicialización.
es un factor de regularización utilizado para penalizar los parámetros que se desvían de su inicialización.
Interacción de escena multijugador (MHSI)
En escenarios del mundo real, en muchos casos no hay una sola persona interactuando con la escena, sino varias personas interactuando de manera independiente o asociada.
Sin embargo, debido a la falta de conjuntos de datos MHSI, los métodos existentes generalmente requieren esfuerzos manuales adicionales y no pueden realizar esta tarea de manera controlada y automatizada.
Con este fin, los autores solo utilizan conjuntos de datos de una sola persona existentes y proponen una estrategia simple pero efectiva para direcciones de generación de varias personas.
Dada una descripción de texto relacionada con varias personas, el autor primero la analiza en múltiples gráficos de escenas locales 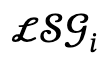 y acciones interactivas
y acciones interactivas 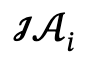 , y define el conjunto candidato como
, y define el conjunto candidato como 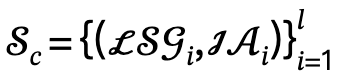 , donde l es el número de personas.
, donde l es el número de personas.
Para cada elemento del conjunto de candidatos, primero se introduce en Narrador junto con la escena 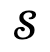 y el gráfico de escena global correspondiente , y luego se realiza el proceso de optimización.
y el gráfico de escena global correspondiente , y luego se realiza el proceso de optimización.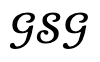
Para manejar colisiones entre personas, se introduce una pérdida adicional en el proceso de optimización 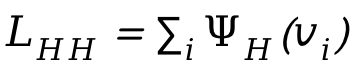 , donde
, donde 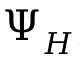 es la distancia firmada entre personas.
es la distancia firmada entre personas.
Luego, cuando la pérdida de optimización es inferior al umbral determinado en función de la experiencia experimental, el resultado generado se acepta y se actualiza agregando nodos humanos 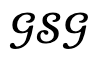 ; de lo contrario, el resultado generado se considera no confiable y se actualiza protegiendo el nodo objeto correspondiente
; de lo contrario, el resultado generado se considera no confiable y se actualiza protegiendo el nodo objeto correspondiente 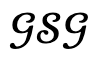 .
.
Vale la pena señalar que este método de actualización establece la relación entre los resultados de cada generación y los resultados de la generación anterior, evita un cierto grado de aglomeración y hace que la distribución espacial sea más razonable y la interacción más realista que la simple generación múltiple.
El proceso anterior se puede expresar como:
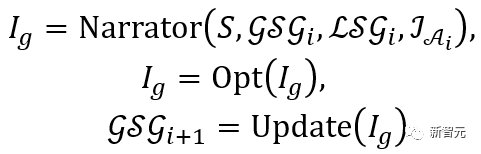
Resultados experimentales
Dado que los métodos existentes actualmente no pueden generar de forma natural y controlable interacciones entre humanos y escenas directamente a partir de descripciones de texto, el autor extiende razonablemente PiGraph [1], POSA [2] y COINS [3] a métodos adecuados para descripciones de texto, y utiliza los mismos. conjuntos de datos utilizados para entrenar sus modelos oficiales, los métodos modificados se definen como PiGraph-Text, POSA-Text y COINS-Text.

Figura 3 Resultados de comparación cualitativa de diferentes métodos
La Figura 3 muestra los resultados de la comparación cualitativa de Narrador con tres líneas de base. PiGraph-Text tiene problemas de penetración más graves debido a limitaciones en su propia representación.
POSA-Text a menudo cae en mínimos locales durante el proceso de optimización, lo que resulta en interacciones no deseadas. COINS-Text vincula acciones a objetos específicos, carece de conciencia global de la escena, conduce a la penetración con objetos no especificados y es difícil de manejar relaciones espaciales complejas.
Por el contrario, Narrador puede razonar correctamente sobre las relaciones espaciales y analizar estados corporales bajo múltiples acciones basadas en diferentes niveles de descripciones de texto, logrando así mejores resultados de generación.
En términos de comparación cuantitativa, como se muestra en la Tabla 1, Narrador supera a otros métodos en cinco indicadores, lo que muestra que los resultados generados por este método tienen una consistencia del texto más precisa y una mayor plausibilidad física.
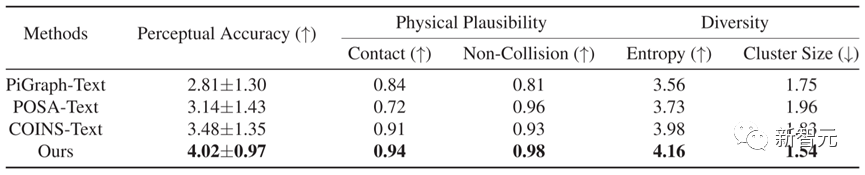
Tabla 1 Resultados de comparación cuantitativa de diferentes métodos
Además, el autor también proporciona comparaciones y análisis detallados para comprender mejor la efectividad de la estrategia MHSI propuesta.
Teniendo en cuenta que actualmente no hay trabajo sobre MHSI, eligieron un enfoque sencillo como base, es decir, la generación secuencial y la optimización con COINS.
Para hacer una comparación justa, también se introducen las pérdidas por colisión artificiales. La Figura 4 y la Tabla 2 muestran los resultados cualitativos y cuantitativos respectivamente, los cuales prueban firmemente que la estrategia propuesta por el autor es semánticamente consistente y físicamente razonable en MHSI.

Figura 4 Comparación cualitativa de MHSI con el método de generación secuencial y optimización usando COINS

Tabla 2 Comparación cuantitativa de MHSI con el método de generación secuencial y optimización con COINS
El vídeo de demostración de este trabajo es el siguiente:
Sobre el Autor

Xuan Haibiao, estudiante de maestría en la Universidad de Tianjin
Principales direcciones de investigación: visión tridimensional, visión por computadora, generación interactiva de escenas humanas.

Li Xiongzheng, candidato a doctorado de nivel 19 en la Universidad de Tianjin
Principales direcciones de investigación: visión 3D, visión por computadora, reconstrucción del cuerpo humano y de la ropa.

Zhang Jinsong, candidato a doctorado de la Universidad de Tianjin
Principales direcciones de investigación: visión 3D, visión por computadora, generación de imágenes.

Zhang Hongwen, becario postdoctoral en la Universidad de Tsinghua
Principales direcciones de investigación: Visión por computadora y gráficos centrados en el ser humano.

Liu Yebin, profesor de la Universidad de Tsinghua
Principales direcciones de investigación: infografía, visión tridimensional y fotografía computacional.
Página de inicio personal: https://liuyebin.com/

Li Kun (autor correspondiente), profesor y supervisor doctoral en la Universidad de Tianjin
Principales direcciones de investigación: visión 3D, reconstrucción y generación inteligentes.
Página de inicio personal: http://cic.tju.edu.cn/faculty/likun
Referencias:
[1] Savva M, Chang AX, Hanrahan P, et al. Pigraphs: instantáneas de interacción de aprendizaje a partir de observaciones [J]. Transacciones ACM sobre gráficos (TOG), 2016, 35(4): 1-12.
[2] Hassan M, Ghosh P, Tesch J, et al. Poblar escenas 3D aprendiendo la interacción persona-escena[C]. Actas de la Conferencia IEEE/CVF sobre visión por computadora y reconocimiento de patrones. 2021: 14708-14718.
[3] Zhao K, Wang S, Zhang Y, et al. Síntesis de interacción composicional humano-escena con control semántico[C]. Congreso Europeo sobre Visión por Computador. Cham: Springer Nature Suiza, 2022: 311-327.
Siga la cuenta pública [Aprendizaje automático y creación generada por IA], le esperan más cosas interesantes para leer
¡Una sencilla introducción a ControlNet, un algoritmo de generación de pintura AIGC controlable!
El GAN clásico debe leer: StyleGAN
 ¡Haz clic en mí para ver la serie de álbumes de GAN~!
¡Haz clic en mí para ver la serie de álbumes de GAN~!
ECCV2022 | Resumen de algunos artículos sobre Generative Adversarial Network GAN
CVPR 2022 | Más de 25 direcciones, los últimos 50 artículos de GAN
ICCV 2021 | Resumen de 35 artículos temáticos de GAN
¡Más de 110 artículos! Revisión del artículo GAN más completo de CVPR 2021
¡Más de 100 artículos! Revisión del artículo GAN más completo de CVPR 2020
Desembalaje de una nueva GAN: representación desacoplada MixNMatch
StarGAN versión 2: generación de imágenes de diversidad multidominio
Descarga adjunta | Versión china del "aprendizaje automático explicable"
Descarga adjunta | "Práctica del algoritmo de aprendizaje profundo TensorFlow 2.0"
Descarga adjunta | Intercambio de "Métodos Matemáticos en Visión por Computador"
"Una revisión de la clasificación de imágenes de muestra cero: diez años de progreso"
"Una revisión del aprendizaje de pocas muestras basado en redes neuronales profundas"
El "Libro de los Ritos·Xue Ji" dice: Si estudias solo y sin amigos, te sentirás solo e ignorante.
¡Haga clic en una taza de té con leche y conviértase en el creador de tendencias de vanguardia de la visión AIGC + CV! , ¡únete al planeta de la creación generada por IA y el conocimiento de la visión por computadora!