Departamento editorial del corazón de la máquina Wenyuan
Blind Face Restoration (BFR) tiene como objetivo restaurar imágenes faciales de alta calidad a partir de imágenes faciales de baja calidad. Es una tarea importante en el campo de la visión por computadora y los gráficos y se usa ampliamente en la restauración de imágenes de vigilancia y fotografías antiguas. Varios escenarios como Pintura interna y superresolución de imágenes faciales.
Sin embargo, esta tarea es muy desafiante porque la degradación por incertidumbre puede dañar la calidad de la imagen hasta el punto de perder información de la imagen, como desenfoque, ruido, reducción de resolución y artefactos de compresión. Los métodos BFR anteriores generalmente se basan en redes generativas adversarias (GAN) para resolver el problema mediante el diseño de varios antecedentes específicos de caras, incluidos antecedentes generativos, antecedentes de referencia y antecedentes geométricos. Aunque estos métodos han llegado a la última tecnología, todavía no logran del todo el objetivo de obtener texturas realistas y al mismo tiempo recuperar detalles faciales de grano fino.
Porque en el proceso de reparación de imágenes, el conjunto de datos de imágenes faciales generalmente se encuentra disperso en un espacio de alta dimensión y las dimensiones características de la distribución presentan una distribución de cola larga. A diferencia de la distribución de cola larga de las tareas de clasificación de imágenes, las características regionales de cola larga en la restauración de imágenes se refieren a atributos que tienen un pequeño impacto en la identidad pero un gran impacto en los efectos visuales, como lunares, arrugas y tonos de color.
Como se muestra en la Figura 1, experimentos simples muestran que los métodos anteriores basados en GAN no pueden manejar bien las muestras ubicadas en la cabeza y la cola de la distribución de cola larga al mismo tiempo, lo que resulta en un evidente exceso de suavizado y pérdida de detalles en la imagen reparada. . El método basado en modelos probísticos de difusión (DPM) puede adaptarse mejor a la distribución de cola larga y conservar las características de la cola mientras se ajusta a la distribución de datos real.
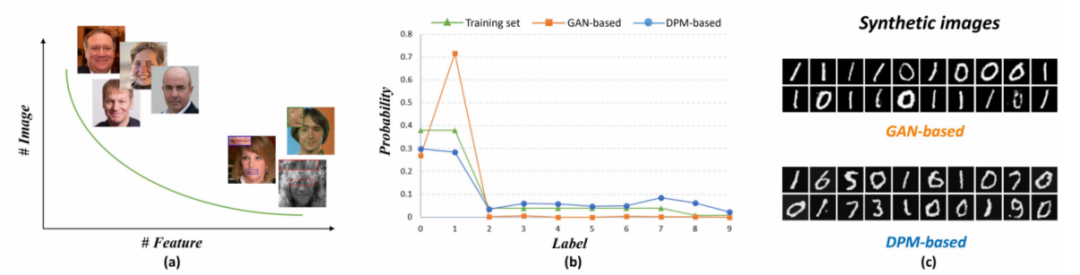
Figura 1 Prueba de problemas de cola larga basados en GAN y DPM
Investigadores del Meitu Imaging Research Institute (MT Lab) y la Academia de Ciencias de la Universidad de China propusieron conjuntamente un nuevo método de restauración de imágenes de rostros ciegos basado en DPM, DiffBFR, que realiza la restauración de imágenes de rostros ciegos y convierte imágenes de rostros de baja calidad (LQ). reparado en una imagen clara de alta calidad (HQ).

Enlace del artículo: https://arxiv.org/abs/2305.04517
Este método explora la adaptabilidad de dos modelos generativos GAN y DPM al problema de cola larga y diseña un módulo de reparación facial adecuado para obtener información detallada más precisa, reduciendo así el fenómeno de suavizado excesivo de la cara causado por el método generativo, mejorando así la reparación. precisión y exactitud. Este documento ha sido aceptado por ACM MM 2023.
DiffBFR: método de restauración de imágenes de cara ciega basado en DPM
La investigación ha encontrado que el modelo de difusión es mejor que el método GAN para evitar el colapso del modo de entrenamiento y el ajuste para generar distribuciones de cola larga. Por lo tanto, DiffBFR utiliza el modelo de probabilidad de difusión para mejorar la incorporación de información previa de la cara, en base a la cual genera HQ. imágenes dentro de un rango de distribución arbitrario. Con fuertes capacidades, se elige DPM como el marco básico de la solución.
En vista de la distribución característica de cola larga en el conjunto de datos faciales encontrado en el artículo, así como del fenómeno de suavizado excesivo basado en métodos GAN en el pasado, este estudio explora diseños razonables para adaptarse mejor a la distribución aproximada de cola larga. superando así los problemas en el proceso de reparación.Problema de suavizado excesivo. A través de experimentos simples de GAN y DPM con el mismo tamaño de parámetro en el conjunto de datos MNIST (Figura 1), el artículo cree que el método DPM puede ajustarse razonablemente a la distribución de cola larga, mientras que GAN prestará demasiada atención a la cabeza e ignorará las características de la cola, lo que da como resultado que las características de la cola no se generen más. Por lo tanto, se eligió DPM como solución para BFR.
Al introducir dos variables intermedias, se proponen dos módulos de reparación específicos en DiffBFR, adoptando un diseño de dos etapas, que primero recupera la información de identidad de la imagen LQ y luego mejora los detalles de la textura de acuerdo con la distribución de la cara real. El diseño consta de dos partes clave:
(1) Módulo de Restauración de Identidad (IRM):
Este módulo se utiliza para preservar los detalles de la cara en los resultados. Al mismo tiempo, se propone un método de muestreo truncado que agrega parte del ruido a la imagen LQ, reemplazando el método de eliminación de ruido de la distribución aleatoria gaussiana pura con la imagen LQ como condición en el proceso inverso. El artículo demuestra teóricamente que este cambio reduce el límite inferior de evidencia teórica (ELBO) de DPM, restaurando así más detalles originales. Sobre la base de pruebas teóricas, se introducen dos modelos de difusión condicional en cascada con diferentes tamaños de entrada para mejorar este efecto de muestreo y reducir la dificultad de entrenamiento de generar directamente imágenes de alta resolución. Al mismo tiempo, se demuestra además que cuanto mayor es la calidad de la entrada condicional, más cerca está de la distribución de datos real y más precisa es la imagen restaurada. Es por eso que DiffBFR primero restaura imágenes de baja resolución en IRM. .
(2) Módulo de mejora de textura (TEM):
Se utiliza para texturizar imágenes. Aquí se presenta un modelo de difusión incondicional, que es un modelo completamente independiente de la imagen LQ, lo que hace que los resultados de la restauración se parezcan más a los datos de la imagen real. El artículo demuestra teóricamente que este modelo de difusión incondicional entrenado en imágenes HQ puras ayuda a IRM a generar la distribución correcta de imágenes en el espacio a nivel de píxeles, es decir, el FID de la distribución de imágenes después de aplicar este módulo es menor que el FID antes de su uso. y obtenemos La distribución de la imagen reparada es generalmente más similar a la de la imagen HQ. Específicamente, el paso de tiempo se utiliza para truncar el muestreo y pulir la textura a nivel de píxel mientras se conserva la información de identidad.
Los pasos de inferencia de muestreo de DiffBFR se muestran en la Figura 2 y el diagrama esquemático del proceso de inferencia de muestreo se muestra en la Figura 3.

Figura 2 Pasos de inferencia de muestreo del método DiffBFR
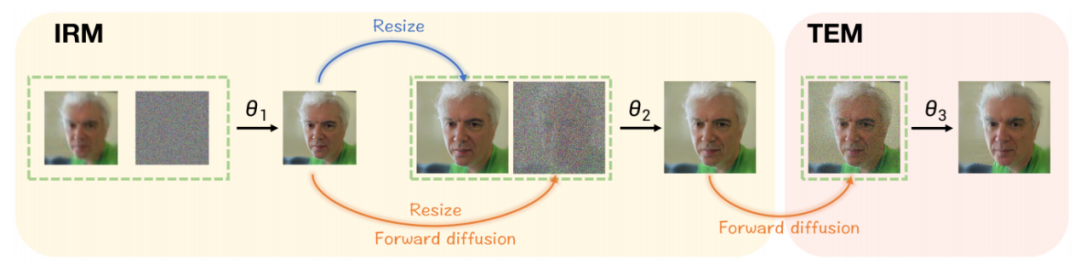
Figura 3 Diagrama esquemático del proceso de inferencia de muestreo del método DiffBFR
Resultados experimentales

Figura 4 Comparación de los efectos de visualización del método basado en GAN de BFR y el método basado en DPM

Figura 5 Comparación de rendimiento de los métodos BFR SOTA

Figura 6 Comparación de los efectos de visualización del método SOTA de BFR

Figura 7 Visualización de la comparación de desempeño de IRM y TEM en el modelo
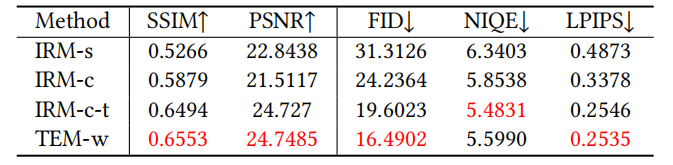
Figura 8 Comparación de rendimiento de IRM y TEM en el modelo
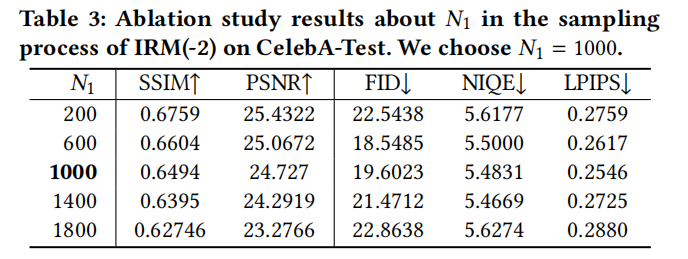
Figura 9 Comparación de rendimiento de diferentes parámetros de IRM
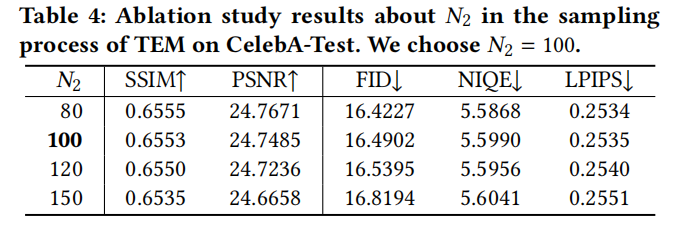
Figura 10 Comparación de rendimiento de diferentes parámetros TEM
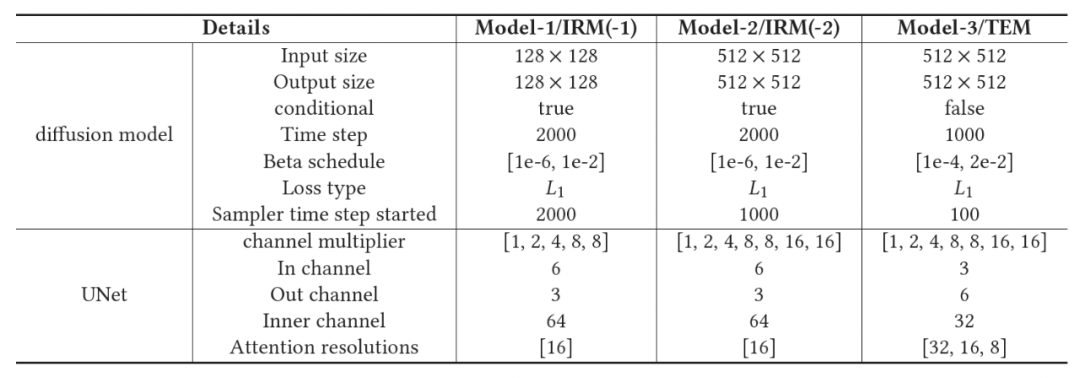
Figura 11 Configuración de parámetros de cada módulo de DiffBFR
Resumir
Este artículo propone DiffBFR, un modelo de restauración de imágenes faciales degradadas ciegas basado en el modelo de difusión, que evita los problemas del colapso del modo de entrenamiento y la desaparición de cola larga basados en métodos GAN en el pasado. Genere imágenes restauradas claras y de alta calidad a partir de imágenes faciales aleatorias gravemente degradadas incorporando lo anterior en el modelo de difusión. En concreto, se proponen dos módulos, IRM y TEM, para restaurar la fidelidad y restaurar detalles reales respectivamente. La derivación de límites teóricos y la demostración de imágenes experimentales demuestran la superioridad del modelo y se comparan cualitativa y cuantitativamente con los métodos SOTA existentes.
equipo de investigación
Este artículo fue propuesto conjuntamente por investigadores del Meitu Imaging Research Institute (MT Lab) y la Universidad de la Academia de Ciencias de China. Meitu Imaging Research Institute (MT Lab) se estableció en 2010. Es el equipo de Meitu dedicado a la investigación de algoritmos, el desarrollo de ingeniería y la producción de productos en los campos de la visión por computadora, el aprendizaje profundo, la realidad aumentada y otros campos. Desde su creación, se ha centrado en en el campo de la visión por computadora. En 2013, comenzó a implementar el aprendizaje profundo para proporcionar soporte técnico para todos los productos de software y hardware de Meitu. También proporciona servicios SaaS específicos para múltiples pistas verticales en la industria de imágenes y promueve el ecosistema de productos de inteligencia artificial de Meitu a través de cortes. Tecnología de imágenes de vanguardia. Para desarrollarse, ha participado en las principales competencias internacionales como CVPR, ICCV y ECCV, ganó más de diez campeonatos y subcampeonatos y publicó más de 48 artículos de conferencias académicas internacionales de primer nivel. Meitu Imaging Research Institute (MT Lab) ha estado profundamente involucrado en la investigación y el desarrollo en el campo de las imágenes durante mucho tiempo, ha formado una profunda reserva técnica y tiene una rica experiencia en implementación de tecnología en los campos de imágenes, videos, diseño y digital. gente.
Siga la cuenta pública [Aprendizaje automático y creación generada por IA], le esperan más cosas interesantes para leer
¡Una sencilla introducción a ControlNet, un algoritmo de generación de pintura AIGC controlable!
El GAN clásico debe leer: StyleGAN
 ¡Haz clic en mí para ver la serie de álbumes de GAN~!
¡Haz clic en mí para ver la serie de álbumes de GAN~!
ECCV2022 | Resumen de algunos artículos sobre Generative Adversarial Network GAN
CVPR 2022 | Más de 25 direcciones, los últimos 50 artículos de GAN
ICCV 2021 | Resumen de 35 artículos temáticos de GAN
¡Más de 110 artículos! Revisión del artículo GAN más completo de CVPR 2021
¡Más de 100 artículos! Revisión del artículo GAN más completo de CVPR 2020
Desembalaje de una nueva GAN: representación desacoplada MixNMatch
StarGAN versión 2: generación de imágenes de diversidad multidominio
Descarga adjunta | Versión china del "aprendizaje automático explicable"
Descarga adjunta | "Práctica del algoritmo de aprendizaje profundo TensorFlow 2.0"
Descarga adjunta | Intercambio de "Métodos Matemáticos en Visión por Computador"
"Una revisión de la clasificación de imágenes de muestra cero: diez años de progreso"
"Una revisión del aprendizaje de pocas muestras basado en redes neuronales profundas"
El "Libro de los Ritos·Xue Ji" dice: Si estudias solo y sin amigos, te sentirás solo e ignorante.
¡Haga clic en una taza de té con leche y conviértase en el creador de tendencias de vanguardia de la visión AIGC + CV! , ¡únete al planeta de la creación generada por IA y el conocimiento de la visión por computadora!