Tabla de contenido
2. Escenarios de uso de Apache Doris
2.3 Construcción de un almacén de datos unificado
2.4
Consulta
Antes de ingresar al texto principal, puede suscribirse al tema, darle me gusta, comentar y recopilar la publicación del blog, y seguir a IT Pindao para obtener contenido de blog de alta calidad.
1.Introducción a Apache Doris
Apache Doris es una base de datos analítica en tiempo real de alto rendimiento basada en la arquitectura MPP. Es bien conocida por sus características extremadamente rápidas y fáciles de usar. Solo necesita un tiempo de respuesta inferior a un segundo para devolver resultados de consultas para datos masivos . No sólo puede soportar escenarios de consultas puntuales de alta concurrencia, también puede soportar escenarios de análisis complejos de alto rendimiento . En base a esto, Apache Doris puede cumplir mejor con escenarios de uso como análisis de informes, consultas ad hoc, construcción de almacenes de datos unificados, aceleración de consultas federadas de lagos de datos, etc. Los usuarios pueden crear análisis de comportamiento del usuario, plataforma de experimentos AB, análisis de recuperación de registros y aplicaciones de usuario. como análisis de retratos y análisis de pedidos.
Apache Doris nació como un proyecto Palo en el negocio de informes publicitarios de Baidu. Fue oficialmente de código abierto en 2017. En julio de 2018, fue donado a la Fundación Apache para que Baidu lo incubara y luego fue incubado y desarrollado por miembros de la incubadora. Comité de gestión de proyectos bajo la dirección de mentores de Apache.Operaciones. Actualmente, la comunidad Apache Doris ha reunido a más de 400 contribuyentes de casi 100 empresas de diferentes industrias, y el número de contribuyentes activos mensuales se acerca a los 100. En junio de 2022, Apache Doris se graduó con éxito de Apache Incubator y se convirtió oficialmente en un proyecto de nivel superior de Apache (TLP).
Apache Doris ahora tiene una amplia gama de grupos de usuarios en China e incluso en todo el mundo. Hasta ahora, Apache Doris se ha utilizado en los entornos de producción de más de 1.000 empresas en todo el mundo. Entre las 50 principales empresas de Internet en China por mercado capitalización o valoración, Más del 80% utiliza Apache Doris durante mucho tiempo, incluidos Baidu, Meituan, Xiaomi, JD.com, ByteDance, Tencent, NetEase, Kuaishou, Weibo, Shell, etc. Al mismo tiempo, también tiene ricas aplicaciones en algunas industrias tradicionales como las finanzas, la energía, la manufactura, las telecomunicaciones y otros campos.
El sitio web oficial de Apache Doris es https://doris.apache.org.
Nota: MPP: Procesamiento masivo en paralelo, procesamiento masivo en paralelo. En términos generales, la arquitectura MPP se refiere a una base de datos distribuida. Hay múltiples nodos para el procesamiento de datos. Cada nodo tiene un disco y una memoria independientes. Las tareas concurrentes se distribuyen a cada nodo para procesar sus propios datos. Una vez completado el cálculo, los resultados finalmente se reúnen para formar el resultado final.
MPP puede verse como MPP DB y arquitectura MPP. Por ejemplo, la arquitectura Hadoop es una arquitectura MPP, que es un procesamiento distribuido a gran escala, es decir, una arquitectura de procesamiento distribuido. Sin embargo, el término MPP fue propuesto por los fabricantes de bases de datos en los primeros días. y generalmente se refiere a bases de datos distribuidas. Por lo tanto, comprender el concepto de MPP puede entenderse como MPP es un concepto de alta dimensión. MPP se puede dividir en dos conceptos: MPP DB y arquitectura MPP. Hadoop o MR es la arquitectura MPP. MPPDB es una base de datos distribuida. Estrictamente hablando, Doris es un MPP . DB es solo una base de datos distribuida comúnmente conocida como arquitectura MPP en la industria.
Apache Doris no es DorisDB. Debido a varias razones complicadas, DorisDB pasó a llamarse StarRocks, lo que significa que DorisDB es el predecesor de StarRocks. Doris era originalmente un sistema dedicado a resolver los informes estadísticos de Baidu Fengchao. Con el rápido desarrollo del negocio de Baidu, el sistema se ha repetido muchas veces y ha asumido gradualmente las necesidades de informes estadísticos y análisis multidimensional del negocio interno de Baidu. En 2013, Baidu actualizó Doris al marco MPP y llamó al nuevo sistema Palo. En 2017, el nombre se cambió a Baidu Palo y fue de código abierto en GitHub. Cuando se contribuyó a la Fundación Apache en 2018, debido a la cooperación con bases de datos extranjeras. fabricantes El nombre es el mismo, así que elegí usar el nombre original de Doris, que es el origen de Apache Doris.
En febrero de 2020, algunos estudiantes del equipo Doris de Baidu se marcharon para iniciar sus propios negocios y crearon su propio producto comercial de código cerrado DorisDB basado en la versión anterior de Apache Doris, el predecesor de StarRocks. Para obtener más información, consulte: https://www.sohu.com/a/488816742_827544.
2. Escenarios de uso de Apache Doris
Como se muestra en la figura siguiente, después de varias integraciones y procesamientos de datos, la fuente de datos generalmente se almacena en el almacén de datos en tiempo real Doris y en el almacén del lago fuera de línea (Hive, Iceberg, Hudi). Apache Doris se usa ampliamente en los siguientes escenarios.
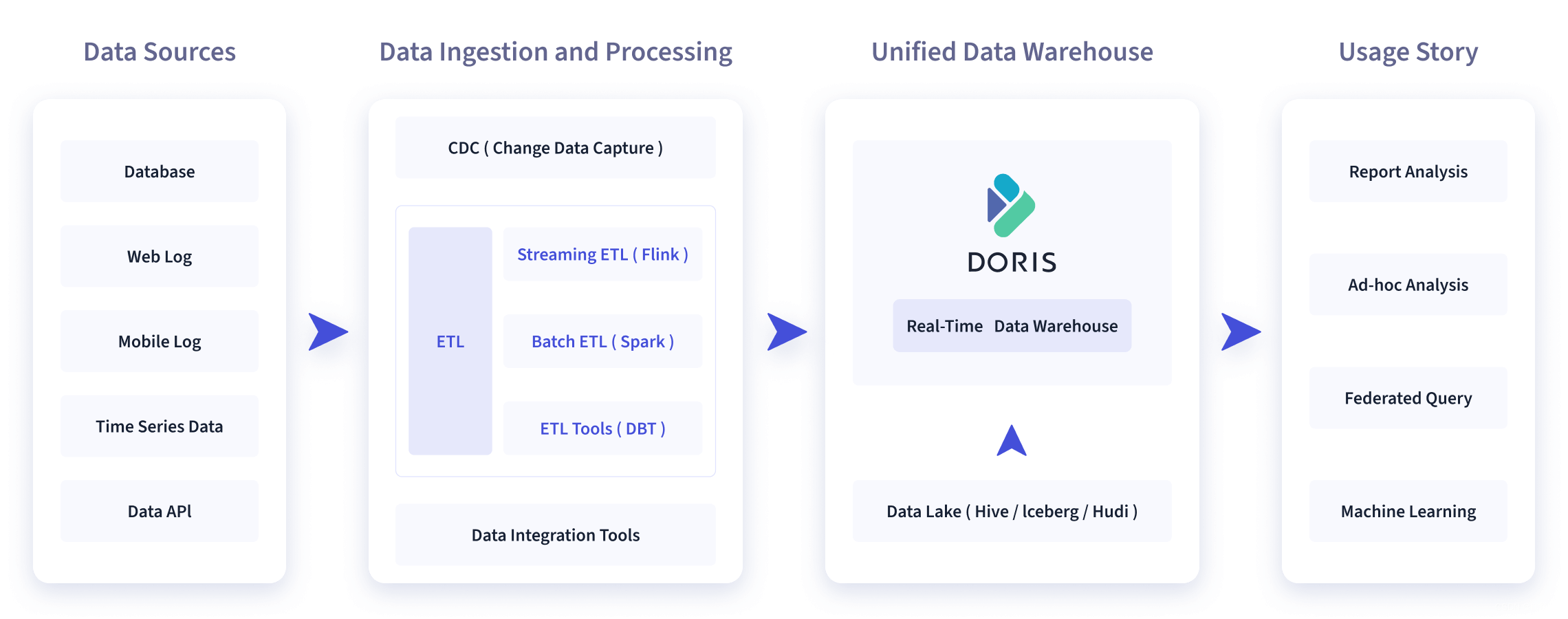
2.1 Análisis de informes
- Paneles de control en tiempo real.
- Informes para analistas y directivos internos.
- Análisis de informes altamente concurrente para usuarios o clientes (Customer Facing Analytics). Por ejemplo, el análisis de sitios para propietarios de sitios web y los informes publicitarios para anunciantes generalmente requieren miles de QPS para la simultaneidad, y la latencia de las consultas requiere una respuesta a nivel de milisegundos. JD.com, una conocida empresa de comercio electrónico, utiliza Apache Doris en informes publicitarios, escribe 10 mil millones de filas de datos todos los días, con decenas de miles de consultas simultáneas por QPS, y el retraso de consulta del percentil 99 es de 150 ms.
2.2 Consulta ad hoc
Análisis de autoservicio para analistas, el modo de consulta no es fijo y requiere un alto rendimiento. Xiaomi ha creado una plataforma de análisis de crecimiento (Growing Analytics, GA) basada en Doris, que utiliza datos de comportamiento del usuario para realizar análisis de crecimiento empresarial. El retraso promedio de las consultas es de 10 segundos, el retraso de consultas del percentil 95 está dentro de los 30 y el volumen diario de consultas SQL es decenas de miles tira.
2.3 Construcción de un almacén de datos unificado
Una plataforma satisface las necesidades de construcción de almacenes de datos unificados y simplifica la engorrosa pila de software de big data. El almacén de datos unificado construido por Haidilao basado en Doris reemplazó la antigua arquitectura compuesta por Spark, Hive, Kudu, Hbase y Phoenix, y la arquitectura se simplificó enormemente.
2.4 Consulta federada del lago de datos
A través del análisis federado de datos en Hive, Iceberg y Hudi a través de la apariencia externa, el rendimiento de las consultas mejora enormemente y evita la copia de datos.